基于Adaboost集成模型的城市短期供水量預(yù)測方法
2020-05-19 05:12:16高赫余吳瀟勇
凈水技術(shù) 2020年5期
高赫余,王 圣,吳瀟勇
(上海城投水務(wù)<集團(tuán)>有限公司供水分公司,上海 200444)
供水量預(yù)測分為長期預(yù)測和短期預(yù)測,長期預(yù)測是指對未來一周、一個月乃至一年的預(yù)測,而短期預(yù)測可以細(xì)化到未來1 h、1 d的預(yù)測[1]。本文主要研究的是短期預(yù)測,即日供水量預(yù)測和時供水量預(yù)測。在管網(wǎng)中水壓和供水量能滿足用戶的前提下,根據(jù)模型所預(yù)測的日與時供水量優(yōu)化供水模式,使水管網(wǎng)在能耗最小、漏損最小的情況下,保證給水質(zhì)量,同時,能夠達(dá)到優(yōu)化調(diào)度的目的[2]。
由于我國需水量數(shù)據(jù)可靠性低,且時間系列較短,用傳統(tǒng)的預(yù)測方法如灰色預(yù)測、時間序列[3]、回歸分析以及定額法等不僅工作量大,精度也很難保證[4]。隨著現(xiàn)在計算機(jī)硬件及軟件的發(fā)展,機(jī)器學(xué)習(xí)和深度學(xué)習(xí)模型已經(jīng)廣泛地應(yīng)用在工業(yè)界中。如王盼等[5]采用隨機(jī)森林算法構(gòu)建需水預(yù)測模型;BAI等[6]采用多尺度相關(guān)向量回歸方法構(gòu)建城市日供水量需求預(yù)測模型;郭冠呈等[7]采用雙向長短時神經(jīng)網(wǎng)絡(luò)構(gòu)建了短期供水量預(yù)測;SHABANI等[8]通過對混沌時間序列進(jìn)行相空間重構(gòu),并結(jié)合支持向量機(jī)模型構(gòu)建城市水量需求預(yù)測模型。這些回歸模型能高精度的擬合非線性函數(shù),從而能在訓(xùn)練樣本上得到預(yù)測結(jié)果,但是,易引發(fā)過擬合,泛化性能較差,在測試樣本上往往不理想,無法在實(shí)際中得到較好的推廣應(yīng)用。
目前,集成學(xué)習(xí)在工業(yè)界和學(xué)術(shù)界受到越來越多的關(guān)注,所謂集成學(xué)習(xí)即訓(xùn)練多個弱回歸模型,對最終的結(jié)果進(jìn)行聯(lián)合決策[5]。目前,集成模型主要有Bagging策略、隨機(jī)森林模型、Adaboost等策略。其中,隨機(jī)森林中,各個決策樹相互獨(dú)立,每個決策樹在樣本堆里隨機(jī)選一批樣本,隨機(jī)選一批特征進(jìn)行獨(dú)立訓(xùn)練,各個決策樹之間無聯(lián)系;Bagging是在決策樹的基礎(chǔ)上并行生成一系列決策樹,相比于隨機(jī)森林,Bagging是選取全部特征屬性進(jìn)行訓(xùn)練;相比于以上兩種流行的集成模型,Adaboost模型建立的多個弱學(xué)器之間均相互聯(lián)系,使得最終的預(yù)測值盡量接近真實(shí)值,且有很強(qiáng)的泛化能力[9]。本文首次采用Adaboost集成模型構(gòu)建水量預(yù)測模型,通過對供水量原始數(shù)據(jù)的預(yù)處理,并引入天氣、日期、空氣質(zhì)量以及人為構(gòu)造的屬性等信息[10],使模型具有更好的泛化能力。與傳統(tǒng)的研究方法如BP神經(jīng)網(wǎng)絡(luò)模型[11-14]、決策樹模型、隨機(jī)森林模型、支持向量機(jī)模型[8]相比,Adaboost模型的精度和效率更高。
1 回歸建模
1.1 Adaboost模型
Adaboost 算法是機(jī)器學(xué)習(xí)中一種重要的特征分類算法,主要解決分類問題和回歸問題。目前,該算法已經(jīng)運(yùn)用到電力系統(tǒng)負(fù)荷預(yù)測、交通量預(yù)測,得到了不錯的預(yù)測效果。
Adaboost 算法通過對同一個訓(xùn)練集訓(xùn)練不同的弱學(xué)習(xí)器,然后將這些弱學(xué)習(xí)器組合形成強(qiáng)學(xué)習(xí)器,通過組合使弱學(xué)習(xí)器互補(bǔ),從而使組合后的強(qiáng)學(xué)習(xí)器有較強(qiáng)的泛化能力。其核心思想是重視預(yù)測誤差大的樣本和性能好的弱學(xué)習(xí)器,即提高訓(xùn)練集中訓(xùn)練效果差的樣本權(quán)值和學(xué)習(xí)能力強(qiáng)的弱學(xué)習(xí)器權(quán)值,降低訓(xùn)練效果好的樣本權(quán)值和學(xué)習(xí)能力弱的弱學(xué)習(xí)器權(quán)值[15]。
正是由于Adaboost 算法核心思想的特性:重視預(yù)測誤差大的樣本和性能好的弱學(xué)習(xí)器,對于基礎(chǔ)數(shù)據(jù)不夠完善、不夠準(zhǔn)確、不夠豐富的數(shù)據(jù)集有很好的適用性,能夠在水務(wù)行業(yè)短期供售水量的預(yù)測中取得較好的應(yīng)用效果。
1.2 評價標(biāo)準(zhǔn)
對于水量預(yù)測,本文研究更加關(guān)注預(yù)測的結(jié)果和真實(shí)的供水量之間的誤差大小,因此,采用平均絕對值誤差(mean absolute error)作為評價指標(biāo),數(shù)學(xué)定義如式(1)。
(1)
其中:nsamples——樣本數(shù)量;
yi——真實(shí)值;

另外一種可作為參考的指標(biāo)為平均相對誤差(mean relative error),數(shù)學(xué)定義如式(2)。
(2)
2 日水量預(yù)測模型
2.1 數(shù)據(jù)描述
本節(jié)水量數(shù)據(jù)來源于上海市城投水務(wù)(集團(tuán))有限公司供水分公司,自2015年11月3日—2019年11月30日共1 489條日供水?dāng)?shù)據(jù)。
上海市城投水務(wù)(集團(tuán))有限公司供水分公司包括黃浦區(qū)、徐匯區(qū)、長寧區(qū)、閔行區(qū)、楊浦區(qū)、虹口區(qū)、閘北區(qū)、普陀區(qū)、寶山區(qū)、松江區(qū)、青浦區(qū)11個行政區(qū)的全部或部分地域,下設(shè)11個供水管理所、36個供水管理站,供水面積高達(dá)1 034 km2,在裝表數(shù)450余萬只,供水管網(wǎng)總長16 205 m。
考慮到原始數(shù)據(jù)所包含的特征只有供水日期,單一的特征會造成較差的擬合結(jié)果。因此,本文進(jìn)一步考察并挖掘影響供水量的多方面因子,同時,將日期信息進(jìn)一步細(xì)化,對特征進(jìn)行組合擴(kuò)展,衍生出一系列影響供水量的特征,結(jié)合這些特征因子和實(shí)際供水量訓(xùn)練Adaboost模型。
圖1為該市實(shí)際供水量的變化情況。由圖1可知,該市供水量為300萬~500萬t,且不具有周期性,局部波動較大,與日期之間無明顯的線性關(guān)系,因此,需挖掘其他影響因子。
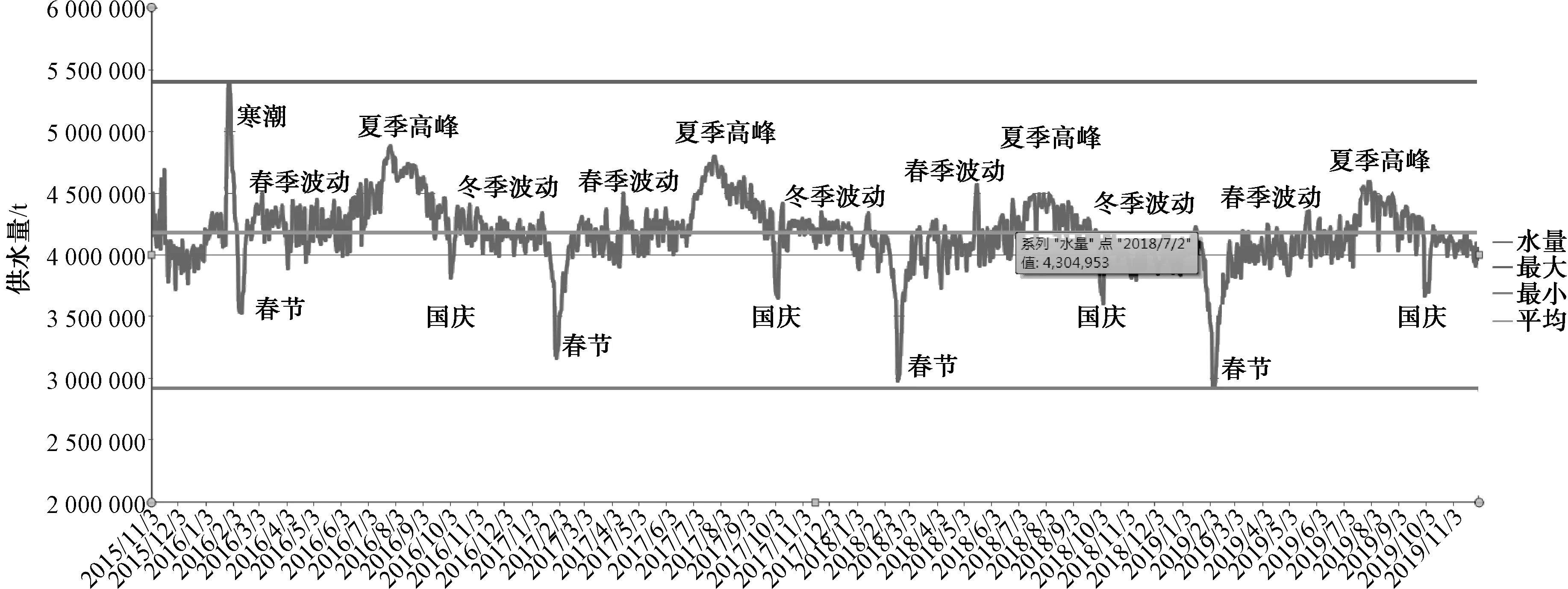
圖1 供水量趨勢Fig.1 Trend of Water Supply Demand
2.2 供水因子的選取與解釋
2.2.1 異常數(shù)據(jù)處理
2015年11月3日—2016年3月1日的數(shù)據(jù),由于上海市幾十年一遇寒潮的影響,波動非常劇烈,不具備普遍規(guī)律予以刪除。對于缺失的數(shù)據(jù),采用以下補(bǔ)全方法:
(a) 對于某一天數(shù)據(jù)的缺失,以這一天前后兩天的平均值代替;
(b) 對于某兩天水量差距巨大的數(shù)據(jù),這兩天的數(shù)據(jù)以這兩天數(shù)據(jù)的平均值代替。
2.2.2 特征選取
本節(jié)研究的重點(diǎn)是日供水量預(yù)測,根據(jù)預(yù)測結(jié)果調(diào)整每天的供水調(diào)度,所以,需要挖掘?qū)┧坑杏绊懙囊蜃印=Y(jié)合以上考慮,本文考察了星期、月、日、四季、日最高溫度、日最低溫度、日平均溫度、天氣、轉(zhuǎn)天氣、風(fēng)向、風(fēng)力、空氣質(zhì)量指數(shù)、空氣污染程度、節(jié)假日情況這14個影響因子,同時,根據(jù)人為構(gòu)造,對數(shù)據(jù)進(jìn)行深度挖掘,定義了溫度等級、溫差、取對數(shù)、開根號、求E、多項式運(yùn)算6個影響因子,且將日期信息深度挖掘,可從日期中抽取該日期屬于一周內(nèi)的第幾天、一個月內(nèi)的第幾天、一年內(nèi)的第幾天3個影響因子。通過特征擴(kuò)展,將原本單一的特征構(gòu)造為22特征,即星期、月、日、四季、日最高氣溫、日最低氣溫、日平均氣溫、天氣、轉(zhuǎn)天氣、風(fēng)向、風(fēng)力、節(jié)假日、空氣質(zhì)量指數(shù)、空氣污染程度、溫度等級、取對數(shù)、開根號、多項式、Day_of_week、Day_of_month、Day_of_year、溫差等。
考慮到特征的相關(guān)性,通過Pearson相關(guān)系數(shù)法計算得到各特征與水量之間的相關(guān)性,并通過相關(guān)較高的數(shù)值型變量進(jìn)一步挖掘得到取對數(shù)、開根號、求E及多項式4維特征值,由于現(xiàn)有特征維度未必能夠充分地描述目標(biāo)變量,通過現(xiàn)有數(shù)據(jù)構(gòu)造新特征。此方法叫做特征構(gòu)建,用于擴(kuò)大特征維度,從而盡可能的提高預(yù)測精度。
2.2.3 Pearson相關(guān)系數(shù)
Pearson能幫助理解特征和響應(yīng)變量之間關(guān)系的方法,該方法衡量的是變量之間的線性相關(guān)性,結(jié)果的取值為[-1,1], -1表示完全的負(fù)相關(guān),+1表示完全的正相關(guān),0表示沒有線性相關(guān)。本文采用Pearson相關(guān)系數(shù)檢驗各個特征與觀測值之間是否存在線性關(guān)系。一是Pearson速度快,易于計算;二是通過Pearson相關(guān)系數(shù)篩選特征可以降低特征維度,在實(shí)際應(yīng)用中便于使用[16]。
2.3 試驗及結(jié)果分析
2.3.1 特征確定
通過Pearson相關(guān)系數(shù)計算特征相關(guān)性,并對其中高度相關(guān)的特征數(shù)據(jù)進(jìn)行深度挖掘。圖2為不同特征與供水量之間的相關(guān)性指數(shù)(對于負(fù)相關(guān)的特征取其絕對值)。
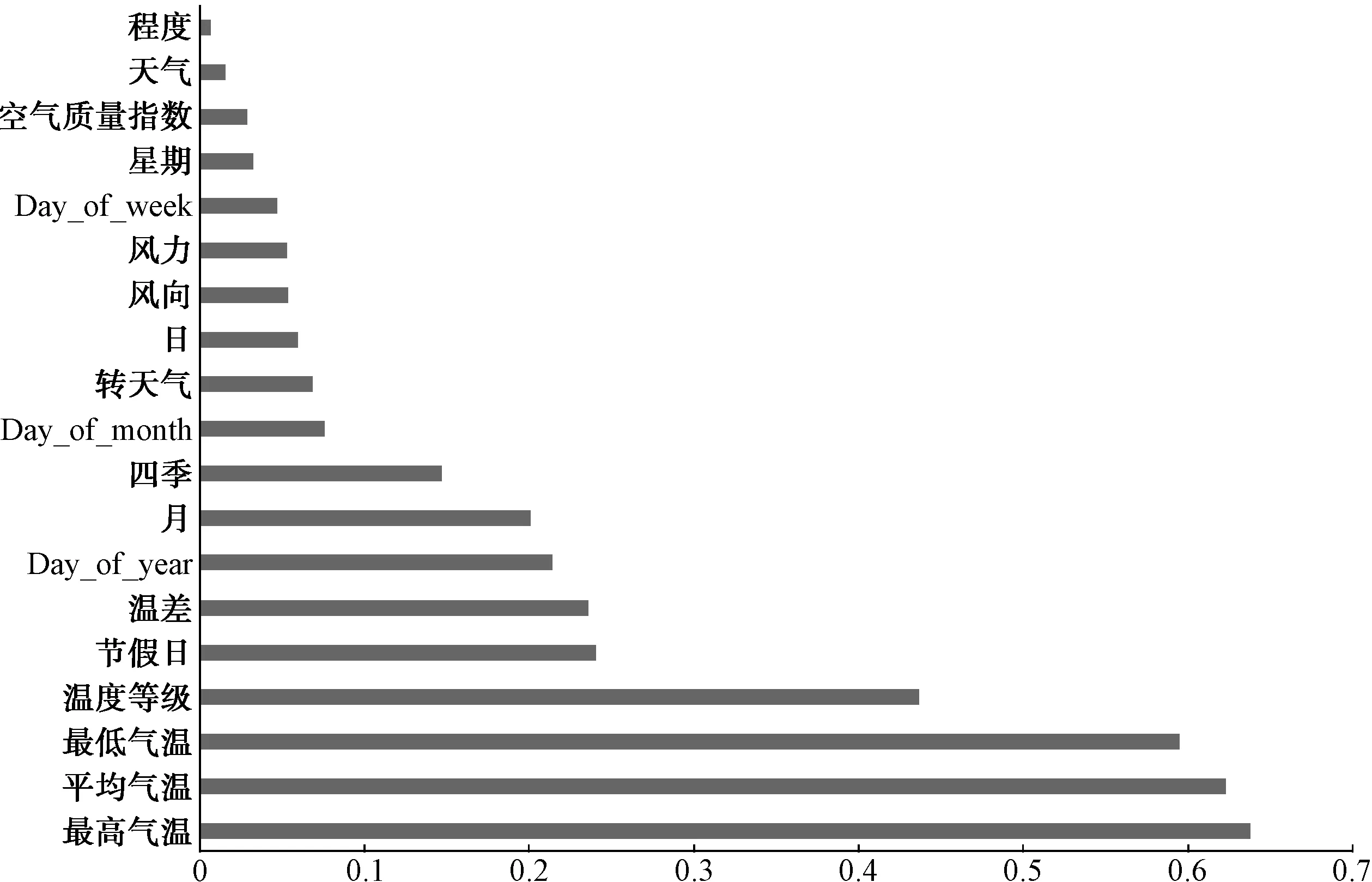
圖2 Pearson相關(guān)系數(shù)Fig.2 Pearson Correlation Coefficient
表1為不同的相關(guān)系數(shù)對應(yīng)的相關(guān)性。

表1 相關(guān)性Tab.1 Correlation

通過深度挖掘構(gòu)造的4維特征通過Pearson相關(guān)系數(shù)法計算后得到較好的相關(guān)性(圖3),可以最終使用。
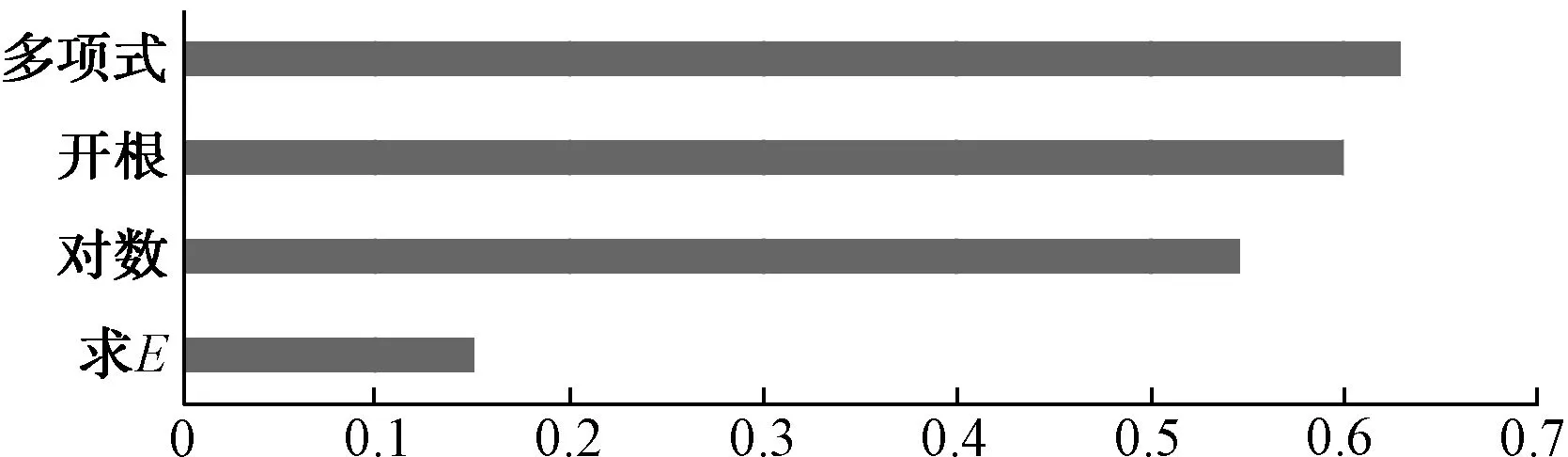
圖3 Pearson相關(guān)系數(shù)Fig.3 Pearson Correlation Coefficient
通過圖2及圖3相關(guān)性計算結(jié)果,選取相關(guān)系數(shù)大于等于0.15的特征,最終得到13維特征:最高氣溫、平均氣溫、最低氣溫、溫度等級、節(jié)假日、溫差、月、四季、開根號、取對數(shù)、求E、多項式、Day_of_year。
2.3.2 結(jié)果比較
將整體數(shù)據(jù)劃分為測試集和訓(xùn)練集。分別使用決策樹[17]、BP神經(jīng)網(wǎng)絡(luò)、支持向量機(jī)、隨機(jī)森林,以及Adaboost建立水量預(yù)測模型。對于相同的測試集,不同的模型有不同的擬合曲線,分別計算以上5種模型的相關(guān)統(tǒng)計量。表2為各種模型在測試集上的平均相對誤差和平均絕對誤差。
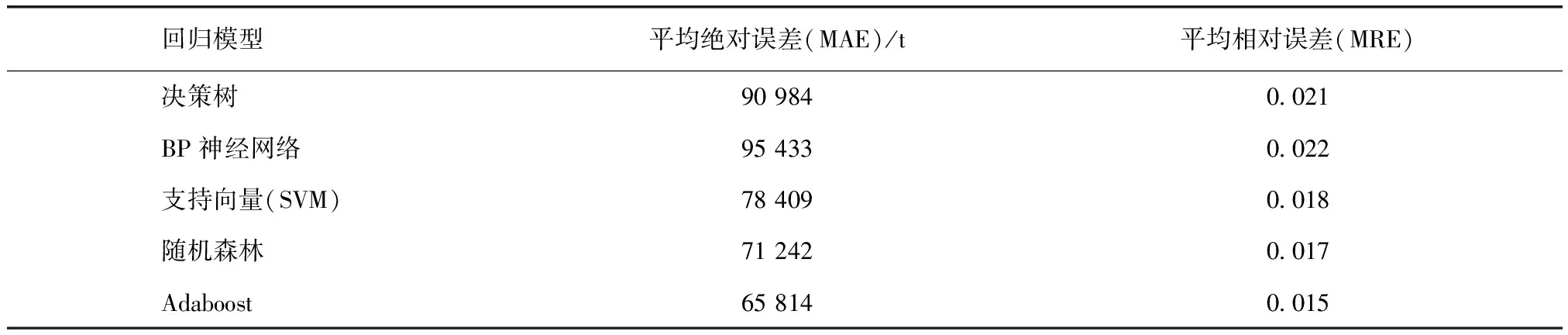
表2 結(jié)果比較Tab.2 Comparison of Results
由表2可知,在相同的測試集上,Adaboost表現(xiàn)結(jié)果最佳,平均絕對誤差為65 817 t,平均相對誤差為0.015,與其他4種傳統(tǒng)模型相比有較大的提升。
驗證的結(jié)果表明,Adaboost平均預(yù)測誤差為65 817 t/d,平均相對偏差為1.5%。與現(xiàn)在流行的BP神經(jīng)網(wǎng)絡(luò)和隨機(jī)森林預(yù)測模型相比有顯著的提升,平均絕對誤差分別降低44 602 t和8 952 t,平均相對誤差分別降低1.0%和0.3%。
3 時水量預(yù)測模型
3.1 數(shù)據(jù)描述
本節(jié)水量數(shù)據(jù)均來源于上海市城投水務(wù)(集團(tuán))有限公司供水分公司,自2017年01月01日—2019年6月30日共21 864條時供水?dāng)?shù)據(jù),每天從1時—24時共24條數(shù)據(jù)。
原始數(shù)據(jù)所包含的特征只有供水日期,單一的特征會造成較差的擬合結(jié)果。因此,本文進(jìn)一步考察并挖掘影響供水量的多方面因子,同時,將日期信息進(jìn)一步細(xì)化,對特征進(jìn)行組合擴(kuò)展,衍生出一系列影響供水量的特征,結(jié)合這些特征因子和實(shí)際供水量訓(xùn)練Adaboost模型。
3.2 供水因子的選取與解釋
本節(jié)研究的重點(diǎn)是時供水量預(yù)測,根據(jù)預(yù)測結(jié)果調(diào)整1 d之內(nèi)每小時的供水調(diào)度,所以需要挖掘?qū)┧坑杏绊懙囊蜃印=Y(jié)合以上考慮,本文考察了四季、星期、月、日、時間、小時氣溫、最高氣溫、最低氣溫、平均氣溫、天氣、轉(zhuǎn)天氣、風(fēng)向、風(fēng)力、空氣質(zhì)量指數(shù)、空氣污染程度、節(jié)假日情況16個影響因子,同時,根據(jù)人為構(gòu)造,對數(shù)據(jù)進(jìn)行深度挖掘,定義了氣溫等級、時溫度等級、取對數(shù)、開根號、求E、多項式運(yùn)算6個影響因子,并將日期信息深度挖掘,可以從日期中抽取該日期屬于一周內(nèi)的第幾天、一個月內(nèi)的第幾天、一年內(nèi)的第幾天3個影響因子。通過特征擴(kuò)展,將原本單一的特征構(gòu)造為25維的特征,即:星期、月、日、四季、最高氣溫、最低氣溫、平均氣溫、天氣、轉(zhuǎn)天氣、風(fēng)向、風(fēng)力、節(jié)假日、空氣質(zhì)量指數(shù)、空氣污染程度、溫度等級、取對數(shù)、開根號、多項式、Day_of_week、Day_of_month、Day_of_year、小時氣溫、求E、時間。
考慮到特征的相關(guān)性,通過Pearson相關(guān)系數(shù)法計算得到各特征與水量之間的相關(guān)性,并對小時氣溫特征進(jìn)一步挖掘得到取對數(shù)、開根號和求E這3個特征值,對相關(guān)性較高的數(shù)值型變量進(jìn)行多項式計算,得到1個特征值。
通過Pearson相關(guān)系數(shù)計算特征相關(guān)性,并對其中高度相關(guān)的特征數(shù)據(jù)進(jìn)行深度挖掘,圖4為不同特征與供水量之間的相關(guān)性指數(shù)(對于負(fù)相關(guān)的特征取其絕對值)。
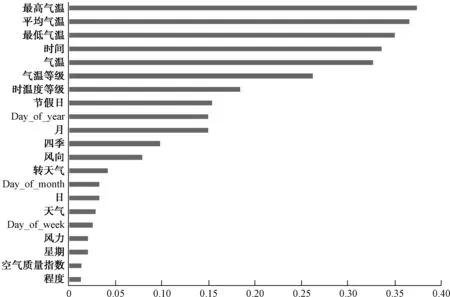
圖4 Pearson相關(guān)系數(shù)Fig.4 Pearson Correlation Coefficient
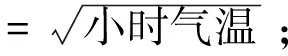
選取相關(guān)性最強(qiáng)的前3個特征,進(jìn)行多項式運(yùn)算得到:多項式=3×最高氣溫+2×平均氣溫+最低氣溫。
通過Pearson相關(guān)系數(shù)法計算得到開根號、取對數(shù)、求E和多項式運(yùn)算4維特征有較好相關(guān)性,可以最終使用。通過圖4及新構(gòu)造特征相關(guān)性計算結(jié)果,選取相關(guān)系數(shù)大于等于0.15的特征,最終得到的13維特征:最高氣溫、平均氣溫、最低氣溫、溫度等級、節(jié)假日、氣溫等級、氣溫、時間、開根號、取對數(shù)、求E、多項式、Day_of_year。
3.3 結(jié)果比較
將整體數(shù)據(jù)劃分為測試集和訓(xùn)練集。分別使用決策樹[17],線性回歸,支持向量機(jī),隨機(jī)森林,以及AdaBoost建立水量預(yù)測模型。對于相同的測試集,不同的模型有不同的擬合曲線,分別計算以上5種模型的相關(guān)統(tǒng)計量。表3為各種模型在測試集上的平均相對誤差和平均絕對誤差。
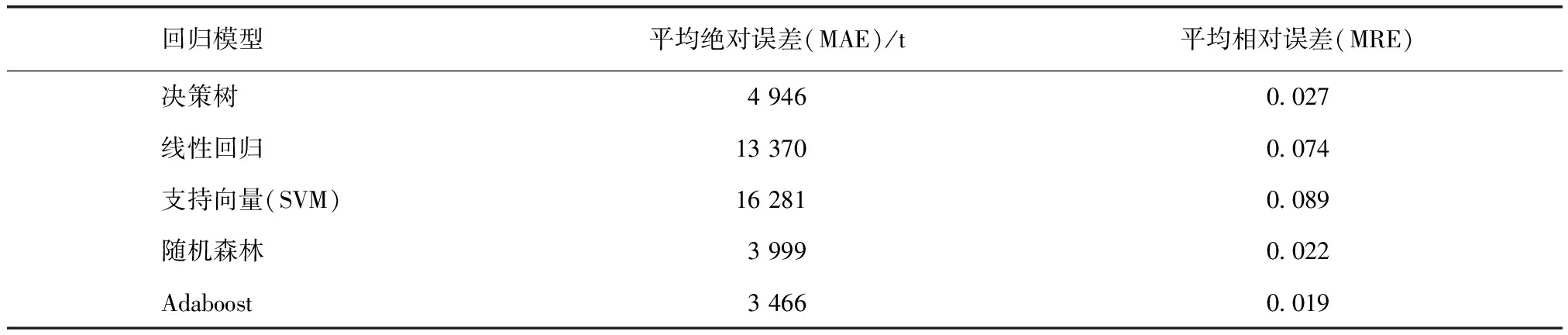
表3 結(jié)果比較Tab.3 Comparison of Results
驗證的結(jié)果表明,Adaboost平均預(yù)測誤差為3 466 t/h,平均相對偏差為1.9%。與現(xiàn)在流行的決策樹和隨機(jī)森林預(yù)測模型相比有顯著的提升,平均絕對誤差分別降低1 480 t和533 t,平均相對誤差分別降低0.8%和0.3%。
4 結(jié)語
上述日水量模型和時水量模型的建模通過特征選取、相關(guān)性分析和數(shù)據(jù)建模3個核心步驟,得到較高精度的模型。其中,特征選取所確定的特征因子均為天氣、溫度和日期等與供水量息息相關(guān)的公司外部數(shù)據(jù),相對于以往通過歷史水量數(shù)據(jù)增長率簡單的預(yù)測未來水量和通過員工經(jīng)驗進(jìn)行供水調(diào)度的方式,此模型具有客觀、動態(tài)、準(zhǔn)確、方便和快速的特征,最后數(shù)據(jù)建模通過橫向?qū)Ρ韧怀隽薃daboost 算法在短時供水量預(yù)測中的優(yōu)越性。
通過此模型進(jìn)行短期的供水量預(yù)測,可以根據(jù)天氣、氣溫和日期等影響用戶用水習(xí)慣的因素準(zhǔn)確快速計算得到未來1 h和1 d的供水量,依據(jù)模型數(shù)據(jù),配合老員工的經(jīng)驗合理供給區(qū)域內(nèi)水量及水量調(diào)度,可以減少水量損失,提高經(jīng)濟(jì)效益。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學(xué)小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
