交通標志識別方法綜述
2020-05-20 01:18:30伍曉暉田啟川
計算機工程與應用 2020年10期
伍曉暉,田啟川 ,2
1.北京建筑大學 電氣與信息工程學院,北京 100044
2.北京建筑大學 建筑大數據智能處理方法研究北京市重點實驗室,北京 100044
1 引言
現代社會經濟發展迅速,汽車給人類帶來了很大的便利,自動駕駛、無人駕駛也逐步進入商業應用,交通標志識別對行車安全至關重要,因此必須解決交通標志的識別問題。然而交通標志識別容易受到天氣變化、遮擋、光照強度變化等影響,這給無人駕駛的應用帶來了很大的安全風險。針對交通標志所處環境的復雜性,設計一個準確率高、實時性能好、魯棒性強的交通標志識別系統至關重要。
交通標志識別系統分為交通標志檢測和交通標志識別,而交通標志檢測常見的方法有基于顏色的方法、基于形狀的方法、基于多特征融合的方法和基于深度學習的方法。基于深度學習的方法具有較明顯的優勢。交通標志識別常用的方法有基于模板匹配的方法、基于機器學習的方法、基于深度學習的方法。從準確率方面來說,基于深度學習的交通標志識別率更高一些。
本文分別從交通標志檢測與交通標志識別兩方面進行闡述,分析其包含的算法的原理、步驟、特點和性能;對公開的交通標志數據庫進行了羅列和說明;相比傳統的交通標志檢測與識別算法,深度學習算法有助于解決光照變化、部分遮擋等情況下的交通標志識別難題;分析基于深度學習的交通標志檢測和識別需要解決的問題,并對其未來的發展趨勢進行了展望。
2 交通標志檢測方法
交通標志的檢測是交通標志識別系統中的關鍵技術。本文根據交通標志檢測的發展歷程,將典型的檢測方法分為四大類:基于顏色的方法、基于形狀的方法、基于多特征融合的方法和基于深度學習的方法。
2.1 基于顏色的交通標志檢測
現在國外應用最廣的是德國交通標志數據庫,本文僅例舉了中國和德國交通標志示例。中國和德國的有些交通標志僅存在細微差別,但是還有一些交通標志具有完全不同的表示形式,例如警告標志。中國的警告標志是黑色邊框黃色內層,而德國的警告標志是紅色邊框白色內層,紅色視覺感強烈,而黃色色調相對來說會更加溫和。將檢測與識別方法應用于交通標志應該考慮到這些細節。
中國的交通標志顏色主要有紅色、黃色和藍色,如圖1所示。

圖1 中國交通標志顏色示例
德國的交通標志顏色主要有紅色、黑色和藍色,如圖2所示。

圖2 德國交通標志顏色示例
顏色是交通標志的基本屬性,學者們一開始便使用顏色信息來檢測交通標志。
(1)RGB顏色模型方法
相機采集到的圖像一般是RGB 圖像,直接在RGB圖像上進行顏色分割會減少計算量。Benallal 等人[1]發現從日出到日落的光照條件下,RGB 各分量之間的差異明顯,比較兩個RGB 分量就可以分割交通標志。顏色分割公式為:IFRi >Gi &Ri-Gi≥ΔRG;Ri-Bi≥ΔRB,則像素是紅色;ELSE IFGi >Ri &Gi-Ri≥ΔGR;Gi-Bi≥ΔGB,則像素是綠色;ELSE IFBi >Gi &Bi-Gi≥ΔBG;Bi-Ri≥ΔBR,則像素是藍色;其余像素是白色或黑色。RGB 顏色空間對光照變化比較敏感,但是光照變化對RGB各分量之間的差異影響較小。直接對相機采集到的RGB圖片進行分割,可以減少計算量,從而極大地提高速度,滿足算法實時性要求。算法也存在一定的缺點:當交通標志所處的環境比較復雜時,交通標志可能會和背景噪聲混合在一起,算法不能達到良好的檢測效果。
(2)HSI顏色模型方法
HSI顏色空間由美國色彩學家Munseu在1915年提出,用色調、飽和度和強度三分量來描述圖像,從而使圖像表示更接近于人類的視覺感知。朱雙東等人[2]利用HSI顏色空間對光照不太敏感的特點,將RGB彩色交通標志圖像轉換到HSI 彩色空間,再進行閾值分割,但是去噪效果不理想。HSI 顏色空間中的S 空間(色彩飽和度空間)可以消除光照對圖像的影響,申中鴻等人[3]在交通標志圖像S空間的灰度直方圖信息的基礎上,用倒溯組內標準差法來選取全局圖像分割閾值,實驗結果表明該方法比HIS 空間色彩判斷法和迭代閾值法分割效果更好。HSI顏色空間具有光照不變等特性,因此魯棒性好,但是將RGB 轉換到HSI 顏色空間具有一定的計算量,需要借助硬件處理來提高實時性。
2.2 基于形狀的交通標志檢測
中國的交通標志形狀主要有三角形、圓形和矩形,如圖3所示。

圖3 中國交通標志形狀示例
德國的交通標志形狀主要有三角形、圓形和矩形,如圖4所示。

圖4 德國交通標志形狀示例
形狀檢測最常見的方法是使用某種形式的霍夫變換[4]。方向梯度直方圖(Histogram of Oriented Gridients,HOG)是檢測形狀的可接受選擇之一[5],其表示梯度圖像的方向。在HOG 中,基本思想是將圖像劃分為單元格并在該單元格內累積邊緣方向的直方圖。最后,生成特征以通過組合直方圖條目來描述對象。HOG變換法具有旋轉縮放不變性的優點,但運算量太大。Paulo等人[6]首先通過將Harris角點檢測器應用于感興趣的區域,然后在該區域的6 個預定義控制區域中搜索角落的存在來檢測三角形和矩形符號。Gavrila 使用基于距離變換的模板匹配進行形狀檢測[7],首先找到原始圖像中的邊緣,其次建立距離變換(Distance Transform,DT)圖像,最后將模板與DT圖像匹配。許少秋等人利用邊緣信息來檢測形狀[8],首先使用離散曲線演變方法濾除邊緣噪聲,然后分解邊緣曲線并且移除與邊緣無關的部分,最后用正切函數描述形狀與模板進行匹配。算法具有較強的魯棒性,但計算過程較為繁瑣。谷明琴等人針對車輛行駛環境中難以檢測的交通標志[9],計算邊緣轉向角這樣尺度不變性的形狀特征,用無參數形狀檢測子來檢測圖像中的圓形、三角形和矩形等,檢測率達到95%以上。
2.3 基于多特征融合的交通標志檢測
交通標志顏色和形狀都有特殊的規定,易受到環境的影響,僅僅依靠單種特征可能導致交通標志檢測失敗。因此將顏色和形狀等多特征融合的方法更有利于交通標志檢測,從而提高交通標志檢測算法的準確率。
湯凱等人提出一種顏色特征、形狀特征和尺度特征的多特征協同方法[10],采用支持向量機(Support Vector Machine,SVM)對融合特征分類獲得檢測結果。此方法對提取的閉合輪廓曲率直方圖鏈碼進行尺度歸一化處理,但是小尺度曲率直方圖易受到邊緣噪聲的影響,會使尺度較小的交通標志難以檢測。常發亮等人提出一種基于高斯顏色模型和HOG 與SVM 結合的快速交通標志檢測算法[11],比單獨使用高斯顏色模型檢測效果有所提升,但是高維的HOG描述子增加了SVM分類器訓練的難度。沙莎等人提出一種多通道融合的交通標志檢測方法[12],結合RGB 和HIS 顏色通道的信息,對交通標志進行分割。算法結合RGB和HIS 彩色空間的分割結果,彌補了對HIS空間中S空間分割造成交通標志信息缺失的缺點,提高了交通標志檢測的準確率。
1998 年Itti 等人模仿靈長類動物早期視力特性,提出一種視覺注意系統[13],在復雜的自然環境中可以快速地檢測到交通標志。之后,很多學者在此基礎上提出交通標志圖像顯著性目標檢測算法。劉芳等人提出一種基于自底向上和自頂向下相結合的視覺注意機制的交通標志檢測方法[14]。根據兩種注意模型提取顏色、亮度、朝向、形狀特征,生成顯著圖,從中找到交通標志區域,但是檢測速度特別慢,無法滿足實時應用的要求。
由于文獻[13]生成的顯著圖分辨率低,保留的空間頻率范圍有限,Achanta 等人提出圖像顯著性的頻率調諧方法[15]。該算法提高了圖像檢測的準確率和實時性,比傳統顏色分割方法濾除圖像噪聲的能力更強,定位圖像更精準。余超超等人[16]首先采用文獻[15]的頻率調諧顯著性分割方法,然后設定輪廓周長閾值來過濾干擾,接著用凸殼處理方法濾除高維信息,最后用傅里葉描述子分析輪廓,并與標準數據庫進行比對來檢測交通標志。此方法魯棒性強,滿足交通標志檢測實時性要求,但也存在一定的不足,比如濾除高維信息會使非交通標志區域更平滑,從而造成誤檢;另外也沒有分解輪廓,無法準確檢測連在一起的交通標志。
道路交通標志環境復雜,融合多特征檢測交通標志會彌補單個特征的不足,提高交通標志的檢測準確率。
2.4 基于深度學習的交通標志檢測
深度學習完全不同于前面的方法,它通過訓練和學習來提取特征,從而實現交通標志的檢測。
基于候選區域提取的目標檢測算法檢測精度高,RCNN(Regions with CNN features)就是由Girshick 等人提出的一種基于候選區域的目標檢測算法[17],它包含豐富的特征層次結構,用于精確的對象檢測和語義分割,通過使用深度卷積神經網絡(Convolutional Neural Network,CNN)對對象提議進行分類,實現了出色的對象檢測精度。但是,因為它重復提取并存儲每個候選區域的特征,花費了大量的計算時間和存儲資源。同時RCNN 使用區域拉伸將每個候選區域統一成227×227的尺寸,影響CNN 提取特征的質量,降低了檢測精度。He等人提出了空間金字塔匯集網絡(SPP-Net)[18]。SPP-Net不再單獨提取每個候選區域的特征,而是計算整個輸入圖像的卷積特征映射,再在特征圖上取出對應于不同候選區域的特征,處理速度比RCNN 提高了24~102 倍。為消除網絡的固定大小約束,SPP-Net 在最后一個卷積層后添加一個空間金字塔池化層(Spatial Pyramid Pooling,SPP),SPP合并特征并生成固定長度的輸出,然后將其輸入到全連接層(或其他分類器)中,提升了CNN提取特征的質量。SPP-Net也有明顯的缺點,它的訓練是多階段的,而不是端到端的方法。Fast RCNN實現了在共享卷積特征上訓練的端到端檢測[19],并提高了準確性和速度。Fast RCNN訓練非常深的VGG16網絡比 RCNN 快 9 倍,與 SPPnet 相比快 3 倍,并在 PASCAL VOC 2012上實現了更高的mAP。與SPP-Net不同,Fast RCNN把SPP層替換成RoI Pooling層。RoI Pooling層是SPP層的一個特例,將不同尺度的特征圖下采樣到一個固定的尺度。此外,Fast RCNN將候選區域分類損失和位置回歸損失統一在同一個框架中,實現多任務損失函數,降低了訓練所需的存儲空間。Faster RCNN引入了一個區域候選網絡(Region Proposal Network,RPN)[20],替換了Fast RCNN 采用的選擇性搜索方法,它與檢測網絡共享全圖像卷積特征,從而實現了幾乎無成本的區域提議。為了將RPN與Fast RCNN對象檢測網絡統一起來,引入了一種訓練方案,該方案在區域提議任務的微調和物體檢測的微調之間交替,同時保持提議的固定。FPN(Feature Pyramid Network)在特征金字塔上使用RPN網絡提取候選區域[21],通過將深層特征與淺層特征相融合,在特征金字塔的多個尺度上進行預測,從而加強了淺層特征圖的語義,提高了小目標的檢測精度。
為了提高檢測速度,Redmon等人提出YOLO網絡,將檢測框架設置為單個回歸問題[22],直接從整個圖像預測邊界框坐標和類概率。YOLO 網絡可以快速識別圖像中的對象,但它很難精確地定位某些對象,尤其是小對象。SSD 網絡在特征圖上使用小卷積核來預測邊界框位置中的對象類別和偏移[23],采用多尺度特征圖預測,在不同尺度的特征圖上直接提取預設數目default box進行預測,比YOLO網絡檢測更快,而且精度更高。
為獲取位置更精確的檢測邊界框,Jiang 等人提出IoU-Net網絡[24],使用網絡訓練IoU(Intersection-over-Union)分支,提取每個邊界框的定位置信度,從而提升了定位的精度。還提出PrRol-Pooling,解決了Faster RCNN中Rol Pooling 取整運算時一定程度丟失位置信息的問題。但是IoU-Net 網絡還存在一定的局限性:IoU 與常用的損失沒有強相關性;如果兩個對象不重疊,則IoU值始終為零且無法優化,并且不會反映兩個形狀彼此之間的距離;IoU無法準確區分兩個對象的對齊方式。為此,Rezatofighi 等人提出用 GIoU(Generalized Intersection over Union)損失函數作為邊界框回歸分支的損失[25],可以提升2%~14%的準確度。
卷積神經網絡結構復雜,參數太多,會導致無法應用到實際場景中檢測交通標志。因此Aghdam等人[26]提出一種輕量級的卷積神經網絡,該網絡使用膨脹卷積實現滑動窗口方法,使用數據集中的統計信息來加快網絡前向傳播的速度,在德國交通標志檢測數據庫(German Traffic Sign Detection Benchmark,GTSDB)上測試得到99.89%的精確度,在NVIDIA GTX 980 GPU硬件上運行每秒可以檢測定位37.72張高分辨率圖像。
交通標志會被樹木、建筑物、旁邊行駛的車輛等遮擋,且交通標志還會被其他交通標志遮擋,這給交通標志定位帶來一定的挑戰。為了解決檢測目標被遮擋的問題,Wang等人提出Repulsion Loss來約束檢測器的推薦區域[27]。Repulsion Loss 包括兩部分:縮小提案與其指定目標之間的距離的吸引項;使目標與周圍的非目標對象保持距離的排斥項。Repulsion Loss的計算公式為:
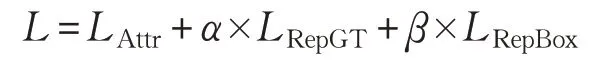
其中,LAttr是吸引項,需要一個預測框接近其指定目標,LRepGT是排斥項,直接懲罰預測框移動到其他地面真實物體,LRepBox是排斥項,要求每個預測框遠離具有不同指定目標的其他預測框。具有Repulsion Loss 的檢測器不僅顯著提高了遮擋情況下的檢測精度,也使得檢測結果對非極大值抑制(Non-Maximum Suppression,NMS)閾值的敏感性降低。
基于深度學習的交通標志檢測方法通過訓練大數據來學習特征,具有很強的特征表達能力,不容易受到光照、遮擋等與交通標志無關的外界因素的影響,比傳統的交通標志檢測方法泛化能力更強,準確率更高。
3 交通標志識別方法
當檢測出交通標志之后,再提取交通標志的特征對交通標志進行分類識別。交通標志分類的方法比較多,目前主流的方法主要有基于模板匹配、機器學習和深度學習的方法。
3.1 基于模板匹配的交通標志識別
模板匹配廣泛應用于模式識別領域中,它的算法較為簡單。將預先已知的小模板在大圖像中平移來搜索子圖像,通過一定的算法在大圖像中找到與模板最匹配(相似)的目標,確定其坐標位置[28]。為了減少傳統模板匹配算法的計算量,提高算法的運行效率,唐琎等人提出一種快速的模板匹配算法[29]。一開始取較少的點參與模板匹配,通過相關系數的比較來逐步增加參與匹配的點的數目,記錄已運算過的像素并保存步長變化前的運算結果,保證不進行重復計算。馮春貴等人提出一種改進的模板匹配方法對限速標志進行識別[30]。首先將交通標志與傳統模板進行匹配,如果匹配不成功,再抽取限速標志字符的邊緣信息,最后用邊緣模板匹配限速標志,與傳統模板匹配算法相比較,識別率由80.95%提高到95.24%。
3.2 基于機器學習的交通標志識別
基于模板匹配的方法的識別結果易受到圖像扭曲、遮擋、損壞等影響,難以兼顧計算量和魯棒性的要求,因此基于機器學習的交通標志識別是一種比較流行的方法。目前的算法主要是采用“人工提取特征+機器學習”,即提取一些能夠表示或描述交通標志信息的特征,再結合機器學習算法進行識別。常用的人工提取特征有尺度不變特征變換(Scale Invariant Feature Transform,SIFT)、ORB(Oriented Fast and Rotated BRIEF)特征、Gabor 小波特征和方向梯度直方圖(HOG)特征。常用的機器學習分類器有支持向量機(SVM)、BP(Back Propagation)神經網絡、極限學習機(Extreme Learning Machine,ELM)和最近鄰算法(K-Nearest Neighbor,KNN)。
胡曉光等人[31]提出使用SIFT 方法提取標志的局部特征,然后使用SVM進行訓練得到分類模型,在采集的測試影像集上的識別率為93%,在Intel Core 2Q6600系統上平均識別時間為0.44 s。文獻[32]發現SIFT算法特征獲取時間較長,帶來很大的計算負擔,于是提出ORB 算法,經實驗對比發現,它的計算速度比SIFT 快100 倍。胡月志等人采用基于ORB 全局特征與最近鄰的交通標志快速識別算法[33],在公開的德國交通標志識別數據庫(German Traffic Sign Recognition Benchmark,GTSRB)上測試,一個交通標志的平均識別時間為2 ms,算法識別準確率達到91%。對比文獻[31,33]實驗結果發現,ORB 特征提取的識別率略低于SIFT 特征提取的識別率,但是實時性卻遠遠超過了后者。
谷明琴等人[34]提出用Gabor 小波提取交通標志特征,用線性支持向量機來分類交通標志,在GTSDB數據集上測試,識別率達到95.6%。甘露等人[35]用Gabor 濾波提取圖像紋理特征,同時用小波不變矩提取形狀特征,將融合特征輸入BP神經網絡分類,識別率比文獻[34]算法提高了3%左右。文獻[36]采用HOG-Gabor特征融合與softmax分類器的交通標志識別方法,在GTSRB數據庫上的識別率為97.68%,比單獨采用HOG 特征識別率提高了0.57%,比單獨采用Gabor 特征識別率提高了0.14%,識別每張圖片耗時0.08 ms。分析文獻[34-36]發現,類別單一的特征提取具有一定的局限性,不能很好地描述交通標志的特征,基于特征融合的算法能夠提高交通標志的識別率。文獻[36]對線性判別分析(Linear Discriminant Analysis,LDA)、SVM、softmax 三種分類器性能進行了比較,對于高維度Gabor 特征,softmax 分類器識別率比其他兩種分類器更高,識別時間更短,實驗結果表明LDA、SVM分類器更適合低維度特征識別。
2004 年Huang 等人[37]提出簡單高效單隱層前饋神經網絡學習算法——極限學習機(ELM)。ELM算法比BP網絡、SVM學習得更快,且具有良好的泛化能力。徐巖等人提出一種基于PCA(Principal Component Analysis)-HOG 和極限學習機模型的交通標志識別算法[38],在GTSRB數據庫上測試,識別率可達97.69%,耗時0.16 ms便可識別一張交通標志。徐巖等人在文獻[38]的基礎上,融合ELM 和AdaBoost 分類器識別交通標志[39],在GTSRB 數據庫上識別率為99.12%,單張交通標志的識別時間為7.1 ms。實驗結果表明,分類器融合的分類算法能夠使識別效果更好,還能提高模型的泛化能力和魯棒性,而識別時間也變長。
3.3 基于深度學習的交通標志識別
深度學習具有強大的特征學習能力,深度卷積神經網絡(CNN)是深度學習在計算機視覺上應用最廣的模型之一。深度卷積神經網絡不需要設計手工特征,輸入模型的圖像通過監督學習來完成特征提取和分類,識別率高于AdaBoost和SVM等傳統算法。
Sermanet 等人[40]提出多尺度CNN 應用于交通標志識別任務,達到99.17%的準確率。Ciresan 等人[41]使用多列深度卷積神經網絡(Multi-Column Deep Neural Network,MCDNN)在GTSRB數據集上獲得99.46%的準確率,但是運算量大,在系統Core i7 950(3.33 GHz)4個GTX 580型顯卡的GPU上訓練具有25列的MCDNN需要37 h,單張圖片的識別時間為690 ms。盡管前兩個網絡的準確度很高,但它們的計算效率不高,需要在硬件上進行大量的乘法運算,采用的激活函數計算效率也不高,Aghdam 等人[42]為減少計算量,選用線性整流函數(Rectified Linear Unit,ReLU)激活函數,然后將兩個中間卷積池化層劃分成兩組,使得中間層的參數數量減半。網絡模型去除了神經網絡冗余參數,同時也提高了交通標志識別的準確率和實時性,算法的識別率提高到99.51%。Jin等人[43]提出了一種鉸鏈損失隨機梯度下降(Hinge Loss Stochastic Gradient Descent,HLSGD)方法訓練CNN,HLSGD 方法比之前網絡模型所使用的隨機梯度下降(Stochastic Gradient Descent,SGD)方法訓練得更快,收斂更穩定,在GTSRB上的識別率為99.65%,在系統 12 核 Intel?Core i7-3960X(兩臺 Tesla C2075 GPU,3.3 GHz)上的訓練時間大約為7 h。
文獻[43]的準確率已經比較高,但是需要學習大量的參數,訓練時間還是比較長。為此,Natarajan 等人[44]提出一種低復雜度的加權組合的4 個并行的CNN 網絡來識別交通標志,在GTSRB 數據集上的準確率為99.59%,當在NVIDIA 980 Ti GPU系統上運行時,可在10 ms內識別出交通標志圖像。Li等人[45]使用具有不對稱內核的高效且強大的CNN 作為分類器,用1×n卷積和n×1 卷積替換n×n卷積,減少了內核參數,并且降低了卷積的運算量,分類效果好,在GTSRB數據集上準確率為99.66%,在NVIDIA GTX 1080 GPU系統(單個GPU,2 GB內存)上每張交通標志圖像的識別時間為0.26 ms。
LeNet-5 網絡是一個7 層的神經網絡,網絡模型較為簡單,對交通標志這種多類別的圖像分類識別,準確率不高,因此研究者通過增加網絡的深度來提高準確率。汪貴平等人[46]在傳統LeNet-5卷積神經網絡的基礎上引入Inception 卷積模塊組,改變卷積核的大小和數目,并且增加網絡的深度,引入批量歸一化算法來防止隨著網絡層次加深而引起的過擬合和梯度消失等問題。改進的LeNet-5 網絡在BelgiumTSC 交通標志數據集上的識別率為98.51%。
基于深度學習的交通標志識別方法通過訓練大數據來學習特征,比采用人工設計特征的傳統方法更有優勢,準確率明顯提升。該算法有助于解決光照變化、部分遮擋等情況下的交通標志識別難點問題。
4 交通標志的數據庫
為了滿足交通標志檢測與識別研究的需要,研究機構和學者們采集了交通標志數據庫。交通標志數據庫在交通標志識別系統中起了非常重要的作用,它是衡量和比較交通標志識別系統算法優劣的基礎。2011 年以前公開的交通標志數據庫是較小規模的數據庫,隨著深度學習的興起,大規模的交通標志數據庫開始出現。為學者今后研究算法所需數據庫提供參考,列出了一些流行并且公開可用的交通標志數據庫,如表1所示。
這些公開的交通標志數據庫由攝像機在各種光照條件下、標志形狀變化以及遮擋等條件下拍攝的,交通標志樣本種類較為豐富,其中BTSD數據庫和Lisa數據庫包含視頻。研究人員常用GTSDB 和GTSRB 數據庫來進行交通標志的檢測與識別。
5 分析與展望
本文對交通標志檢測與識別方法進行了詳細的介紹和分析,由于人工提取特征具有一定的主觀性且難以選擇,隨著大規模交通標志數據庫的出現和計算機硬件性能的提升,深度學習有著越來越明顯的優勢。深度學習通過學習訓練大量帶有標簽的交通標志數據庫,可以自發學習分類交通標志,在復雜背景情況下檢測識別交通標志仍然能夠達到很高的準確率。然而基于深度學習的交通標志檢測和識別方法仍然有很大的提升空間,未來可以在以下幾個方面進一步研究:
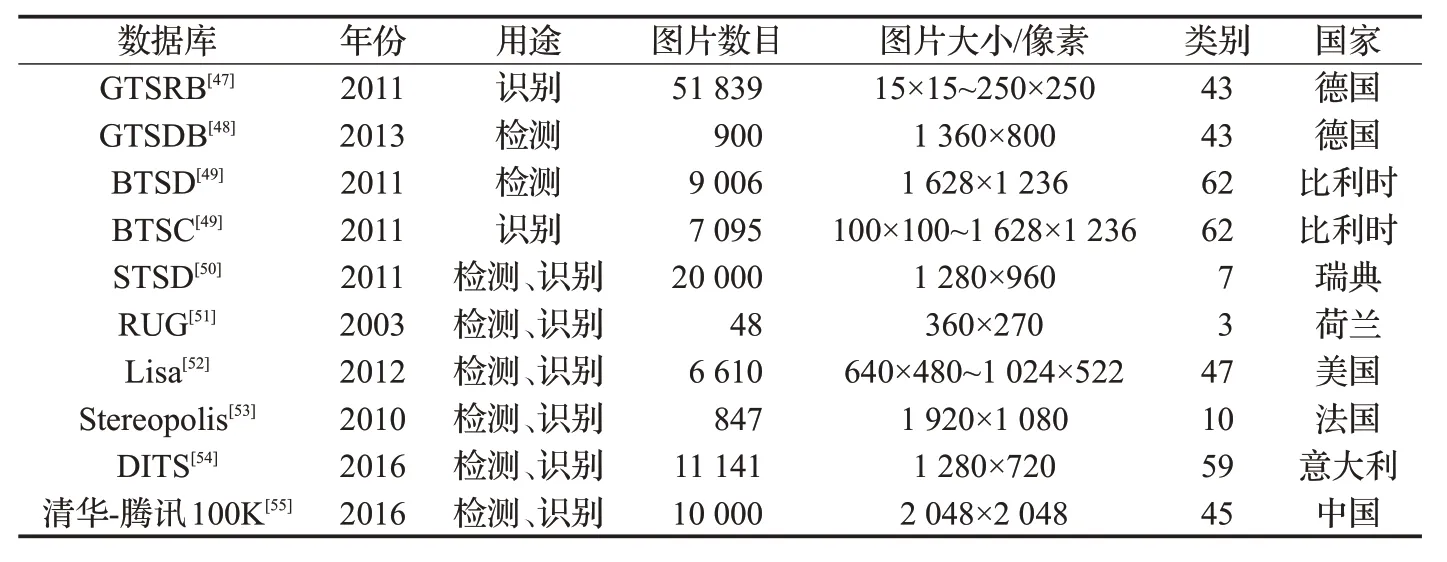
表1 已公布交通標志數據庫的對比
(1)卷積神經網絡達到一定層數后再加深層次,訓練時間更長,準確率降低,對硬件的要求也會更加嚴格。如何在不影響準確度的情況下,尋找裁剪神經網絡大小的規律來實現網絡模型的壓縮是研究的重點。
(2)交通標志會被樹木、建筑物、旁邊行駛的車輛等遮擋,這給交通標志檢測和識別帶來一定的挑戰。文獻[27]利用Repulsion Loss一定程度上提高了被遮擋對象的檢測精度,但是還有提升的空間。根據被遮擋交通標志的特點,如何設計深度學習網絡模型來檢測識別交通標志是未來需要關注的問題。
(3)隨著卷積神經網絡層次的加深,梯度的傳播會變得更加困難,在訓練時可能會有梯度消失、梯度爆炸情況出現,批量歸一化和殘差連接算法的出現使這種情況得到了一定的改善,如何設計算法有助于梯度的傳播是一個重要的研究方向。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
海峽科技與產業(2016年3期)2016-05-17 04:32:12
財經(2016年3期)2016-03-07 07:44:46
