霧計算中基于DQL算法的偽裝攻擊檢測方案
2020-05-20 01:18:40涂山山于金亮
計算機工程與應用 2020年10期
關鍵詞:檢測
孟 遠,涂山山 ,于金亮
1.北京工業大學 信息學部,北京 100124
2.可信計算北京市重點實驗室,北京 100124
1 引言
在過去的十年中,由于移動互聯網流量呈指數級增長,移動設備引導著無線通信和網絡的顯著發展[1]。其中,蜂窩異構網絡、毫米波通信及多輸入多輸出(Multiple-Input Multiple-Output,MIMO)技術為下一代用戶提供了千兆無線網絡接入服務,使得處理效率低下的移動設備也能夠借助遠程云數據中心的高處理能力和大內存存儲能力運行各自的計算服務[2]。然而在云計算中,不同的用戶、應用程序會在不同的時間、位置生成和利用數據,如語音服務、視頻服務和游戲等產生的數據都與用戶的時刻位置有關,這將導致不同的應用程序需要更高的處理和存儲要求,并且不同的應用程序數據在執行時往往沒有考慮用戶的移動性[3]。當前,云服務器與終端用戶的距離較遠,而大量物聯網設備的加入使得終端迫切需要低延遲、位置感知等能力。因此,傳統云計算不再適用于新一代移動物聯網網絡,霧計算的出現彌補了新的應用場景的缺失。在霧計算網絡中,處理數據的應用程序運行于依據地理位置分布的霧節點中,大多數霧節點與終端通過無線網絡連接,霧節點之間也存在高頻率互動。然而,由于霧節點與終端用戶間的行為在無線網絡中往往容易暴露,霧計算網絡容易受到惡意用戶的偽裝攻擊。同時,現有的方法大多通過使用應用層的安全技術保護霧計算網絡,而沒有考慮物理層安全技術在霧計算網絡中的應用,缺少對無線信道移動隨機性的研究,而對物理層安全技術的研究可以增強密鑰的安全性,使密鑰基于無線信道由雙方直接生成,不需要密鑰管理中心及密鑰分發過程,并且物理層安全技術獨立于計算復雜度,能夠簡單高效地解決安全問題。因此,本文基于物理層安全(Physical Layer Security,PLS),提出一種基于DQL(Double Q-learning)算法的霧計算偽裝攻擊檢測方案,貢獻如下:
(1)設計了在靜態環境中非法節點(霧節點和終端用戶)與接收端之間的零和博弈,通過在接收端建立基于信道狀態信息(Channel Status Information,CSI)的假設檢驗,解決了用于檢測偽裝攻擊的閾值問題。
(2)提出了基于強化學習中的DQL 算法在動態環境下檢測偽裝攻擊的方案,實現了對檢測閾值的優化。
(3)通過與常用Q-learning 算法比較誤報率(Fault Alarm Rate,FAR)、漏檢率(Miss Detection Rate,MDR)、平均錯誤率(Average Error Rate,AER),證明了該方案能夠解決Q-learning 算法中的Q 值過度估計問題,降低FAR、MDR 和AER,提高偽裝檢測的準確率,增強霧節點與終端用戶間的安全性。
2 相關研究
霧計算中惡意用戶的偽裝攻擊指的是霧節點或者終端用戶使用虛假的媒體訪問控制地址(Media Access Control Address,MAC-A)冒充合法節點向其他節點發送數據,以此實現中間人攻擊和拒絕服務攻擊,從而獲取非法收益。為了識別偽裝攻擊,可以利用物理層技術實現霧節點與終端用戶間的無線網絡安全通信。物理層安全技術利用無線信道中標志著無線鏈路物理層特征的信道參數識別偽裝攻擊,這些信道參數包括信道頻率響應(Channel Frequency Response,CFR)、接收信號強度指示器(Receiving Signal Strength Indicator,RSSI)、信道狀態信息(Channel Status Information,CSI)、接收信號強度(Receiving Signal Strength,RSS)。當前,終端用戶與霧節點間的環境是動態的,移動終端不斷運動,信道也隨之改變,使得接收端難以識別非法數據包。為了應對動態環境中的偽裝攻擊問題,最新的研究利用強化學習中的算法,在動態環境中尋找用于檢測偽裝攻擊的最優閾值的方案[4]。
霧計算可以為終端用戶提供計算、存儲等服務,但是也存在很多安全問題,如數據信息、密鑰信息易泄露,易受到竊聽、干擾攻擊等。面對這些問題,研究人員提出了不同的解決方法。文獻[5]提出了一種安全可驗證的矩陣外包方案,該方案將矩陣求逆任務從客戶端交由霧服務器執行,使用混沌系統為矩陣加密,保證了矩陣在服務器端的安全。然而,此方法對身份驗證和攻擊模型的考慮較少。文獻[6]研究了一種基于5G的網絡服務鏈模型,并且針對霧層的cloudlet服務實現了處理DDoS(Distributed Denial of Service)攻擊的終端用戶身份驗證方法,但此方法使用了多個驗證票據,步驟較為繁瑣。文獻[7]提出了基于屬性加密的密鑰交換協議,結合數字簽名技術,實現了保密性、身份驗證和訪問控制。文獻[8]介紹了一種基于霧的重復數據刪除空間眾包框架,解決了終端與霧節點間任務與感知數據安全傳輸問題,但是計算復雜度較高。
綜合上述研究,由于霧計算網絡中存在偽裝攻擊,并且現有研究大多使用應用層安全技術,缺少對物理層安全的研究,因此本文提出了基于物理層安全和DQL算法檢測偽裝攻擊的方案。
3 模型構建與假設檢驗
本文構建了一個霧節點層與用戶層間的偽裝攻擊網絡模型,并且在接收端建立用于檢測攻擊的假設檢驗。
3.1 安全模型構建
本文的網絡模型面向霧節點與終端用戶,考慮霧節點與終端用戶間的無線網絡,如圖1所示。假設有a個發送端,r個接收端,h個合法節點和i個非法節點,其中:
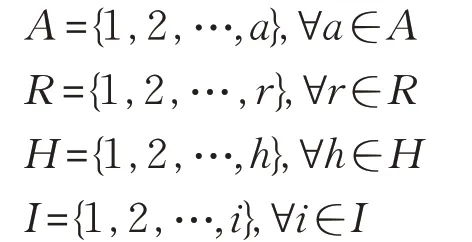
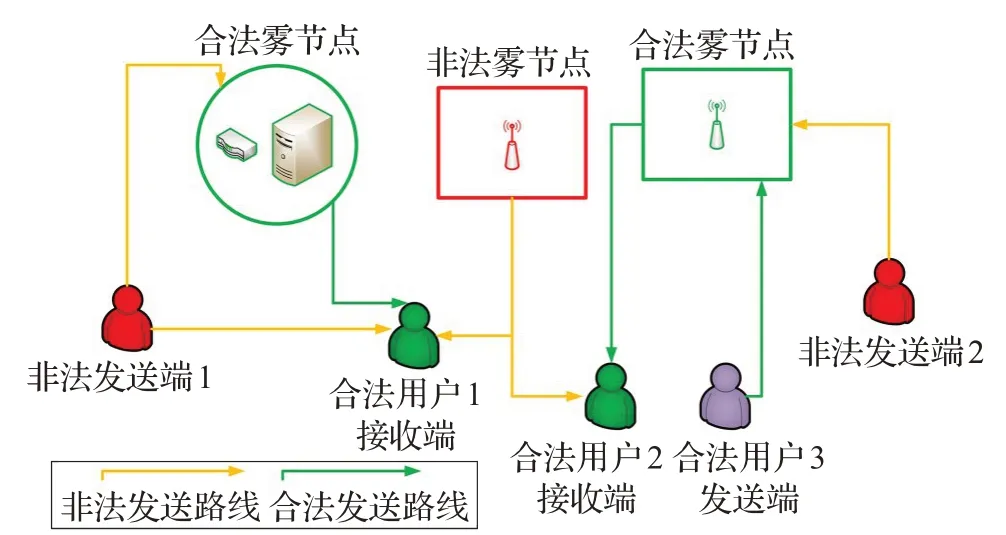
圖1 偽裝攻擊網絡模型
非法節點表示帶有虛假MAC-A 地址的節點,它可以是霧節點,也可以是終端用戶節點。同時該節點可以假冒終端用戶向霧節點或終端用戶發送數據包,也可以假冒霧節點向合法用戶發送數據包。非法用戶在一個時隙內發送一個虛假MAC-A 地址的概率為pj∈[0,1]。第a個發送端的MAC-A地址為αa∈θ,?a∈A,其中θ是表示所有MAC-A地址的集合。每個接收端收到每個數據包后均估計其相關的CSI,并提取數據包的信道向量,接收端接收的數據包的信道向量被稱為信道記錄。例如,數據包的導頻可以用于發送端的信道響應估計。因此,第a個發送端發送的第t個數據包的信道向量為,第a個發送者發送的第t個數據包的信道記錄為,x表示第t個數據包的第x個信息[9]。
3.2 假設檢驗
假設檢驗用來驗證數據包的身份,合法節點發送的數據包的信道向量為,合法節點的MAC-A 地址為,假設Η0表示MAC-A 的數據包是由合法節點發送的,假設Η1表示MAC-A的數據包是由非法節點發送的,如下所示:

物理層安全中,CSI表明了信道特征,它是唯一的,接收端提取CSI 可以驗證數據包。如果信道向量與信道記錄相同,那么發送端發送的數據包被認為是合法數據包,接收端接收;否則,數據包被認為是從非法節點發送而來,接收端拒絕接收。假設檢驗的統計量為:
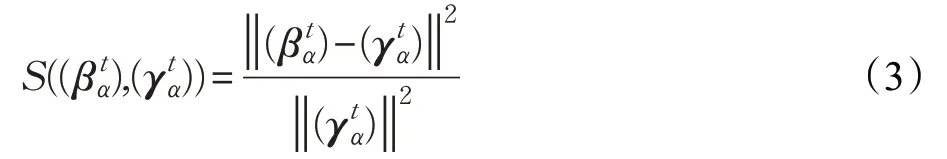

因為歐式距離的值S大于等于0,所以閾值也大于等于0。定義誤報率PA與漏檢率PB:

其中,PR為條件概率,誤報率表示合法節點發送的合法數據包被檢測為非法數據包的概率。漏檢率表示非法的數據包被檢測為合法數據包的概率。接收端接收(6)中合法節點發送的合法數據包的概率和接收端拒絕(7)中非法數據包的概率分別為[4]:

根據假設檢驗,假設測試閾值的大小影響偽裝攻擊檢測的精確率,當閾值增大時,漏檢率隨之增加,另一方面,當閾值減小時,誤報率也會增加。除了物理層安全檢測,接收方也應該設定高層數據包檢測(Higher Layer Authentication,HLA),檢測經過物理層驗證的數據包,最終接受所有通過檢測的數據包,每個數據包被接受時,,若不被接受,。
綜上所述,通過在接收端建立假設檢驗,可以為偽裝檢測設置一個檢測統計量,以便于將其與測試閾值進行比較,判斷每一個接收到的數據包是否是合法數據包。
4 靜態和動態偽裝檢測
本章主要介紹靜態檢測中基于博弈論的效用計算和動態場景中使用DQL算法檢測偽裝攻擊的方法。
4.1 靜態偽裝檢測的效用計算
在靜態偽裝檢測中,在接收端建立假設檢驗并選擇閾值檢測偽裝攻擊,使用零和博弈計算接收端的效用,其中有F個非法節點和N個接收者[10]。非法節點發送非法數據包的概率為pj∈[0,1],1 ≤j≤F,發送非法數據包的集合為Y=[pj]1≤j≤F,非法節點之間可以互相協作,假設在一個時隙中只有一個非法節點進行偽裝攻擊,接收端接收到一個非法數據包的概率為。另外,接收端接收合法數據包的收益為g1,拒絕非法數據包的收益為g0,接收端拒絕合法數據包的成本為C1,接受非法數據包的成本為C0。因此,偽裝攻擊先驗分布下偽裝檢測的貝葉斯風險[11]為:
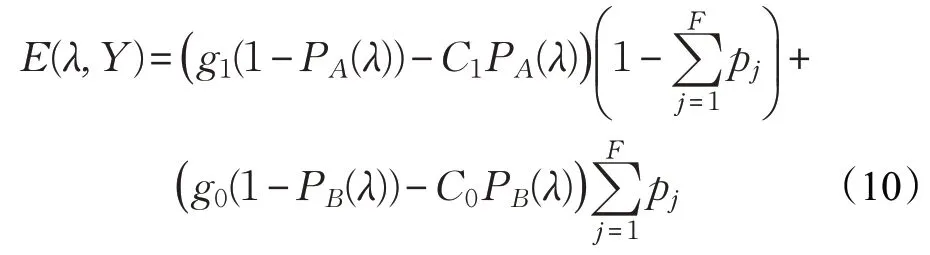
上式中第一項為合法數據包的收益,第二項為偽裝攻擊產生的收益。因此,在零和博弈中,接收端的收益為:
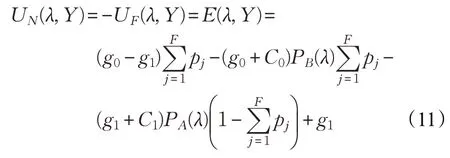
在式(11)中,λ為接收端選擇的測試閾值,λ∈[0,∞)。在實際的場景中,節點具有移動性,是動態變化的,對接收端來說,它不知道完整的信道狀態,因此,在下一節中將采用DQL算法尋找動態環境中的最優測試閾值。
4.2 動態偽裝檢測
DQL算法是強化學習算法,它改進了Q-learning算法。DQL 與Q-learning 都可以在動態環境中得到不充分信息的最優策略[12-13]。相對于Q-learning 算法,DQL解決了Q值過度估計的問題[13]。
在動態偽裝檢測中,接收端構建假設檢驗,評估每個時隙中發送來的T個數據包,利用測試閾值檢測它們的發送者是合法節點還是非法節點。將測試閾值分為L+1 級,λ∈{l/L},0 ≤l≤L ,接收端在時刻τ的狀態表示為sτ,它指的是在時刻τ-1 處的 FAR 與 MDR,表示為,其中D為接收端所有狀態的集合。因此,誤差率同樣被量化為L+1 級,它們的值與測試閾值相關。根據DQL 算法,接收端在每個狀態下選擇動作,其獲得的立即收益如下式所示:

DQL 算法使用了兩個Q 值表Q1和Q2,它們互相選擇最大Q值和動作,彌補錯誤。接收端使用ε-greedy策略在每個狀態選擇動作,以ε的概率選擇次優動作,以1-ε的概率選擇使當前狀態下最大的動作[14],概率值為:
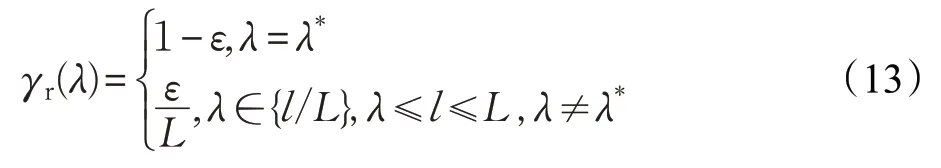
在DQL算法中,μ表示獎勵性衰變系數,μ∈(0,1),學習效率δ表示下一狀態可能帶來的收益,δ∈(0,1),更新公式如下:
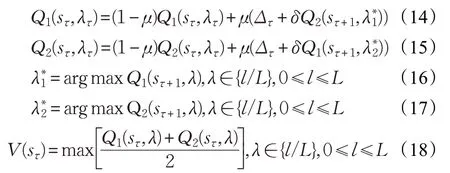
式(18)表示當前狀態中對應于各個動作下Q1+Q2的均值最大值。因此,最佳測試閾值為:
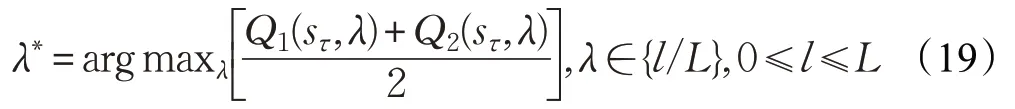
式(19)計算的是在每個狀態下使兩個Q 表收益和最大的動作。
根據上述公式,獲取最佳閾值和最大化效用的DQL算法步驟總結如下:
步驟1 初始化,給ε、μ、δ、Q1(sτ,λ)、Q2(sτ,λ) 賦初值,其中 ?λ∈{l/L},0 ≤l≤L。
步驟2τ=1,2,…,在當前狀態sτ下,選擇測試閾值λτ,用于判斷當前狀態與前一狀態間的時隙內所有數據包的合法性。
步驟3 接收端a接收到一個數據包,觀察MAC-A地址,αa∈θ,?a∈A,提取信道向量和信道記錄,即和。
步驟4 使用式(3)計算歐式距離。如果,那么將這個數據包發給HLA處理,并且,接收這個數據包;否則拒絕這個數據包。此步驟用于判斷接收到的數據包是否是合法數據包,接收合法數據包,丟棄非法數據包。
步驟5 重復步驟3 和步驟4,直到接收端處理完一個時隙中接收到的T個數據包。
步驟6 進入下一個狀態sτ+1,根據式(12)計算Δτ,以0.5的概率使用式(14)更新Q1(sτ,λτ),以0.5的概率使用式(15)更新Q2(sτ,λτ),并且使用式(18)更新V(sτ),獲取當前Q值平均值的最大值。
步驟7 返回步驟2 繼續執行,重復步驟2~步驟6,直到達到目標狀態,完成優化公式(18)、(19)所表示的最大Q值和最優測試閾值的過程。
5 仿真實驗
假設檢驗中,FAR與MDR基于DQL算法的計算公式如下[15]:
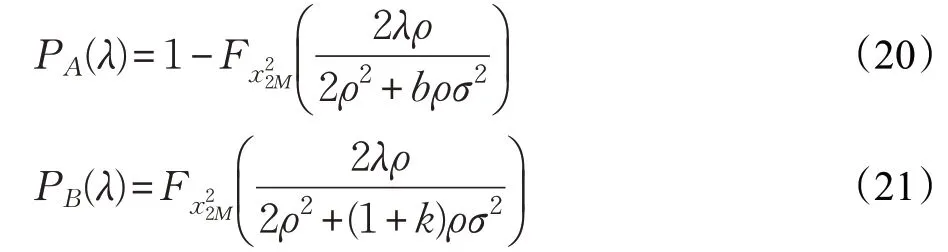
其中,Fx22M是2M自由度的累積分布函數,接收端以σ2獲得發送端的平均功率增益,ρ為合法數據包的信號與干擾加噪聲比(Signal to Interference plus Noise Ratio,SINR)。b為信道增益的相對變化,k為偽裝者的信道增益與發送端的信道增益比。
仿真實驗針對本文提出的基于DQL算法檢測偽裝攻擊的方法與基于Q-learning算法檢測偽裝攻擊的方法進行對比,并將兩種算法在FAR、MDR、AER 和最大Q值這四個方面進行比較。本文的實驗環境模擬為20 m×20 m 的房間,房間內的節點隨機分散,所有的信道增益服從常規分布ξ(0,1)[4]。假設同一時隙內接收端處理T=20 個數據包,設定信號的中心頻率為f0=2.4 GHz,其中相關的初始值設置為g1=6,g0=9,C0=4,C1=2。根據4.2 節描述的DQL 算法中參數的取值范圍,本實驗假設ε=0.5,μ=0.4,δ=0.8。同時,為了計算FAR、MDR和AER的值,本文根據實驗環境選擇了合適的初值ρ=10 dB,k=0.2,b=3 dB[4],實驗用到的初始化參數及意義見表1。
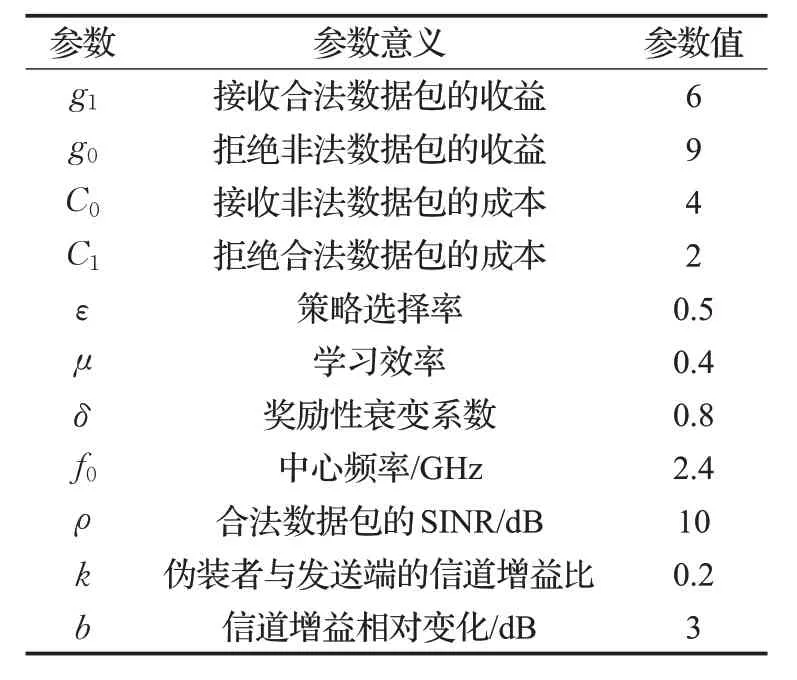
表1 仿真實驗用到的參數值及意義
在初始化參數下,1~100 次連續實驗中,基于DQL算法進行偽裝檢測和基于Q-learning算法進行偽裝檢測的FAR值對比如圖2所示。
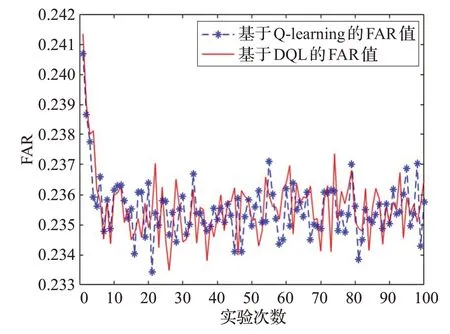
圖2 兩種算法的FAR值對比圖
隨著實驗次數的增加,算法中的閾值也在不斷變化,在DQL算法中,根據式(20),FAR值先降低,但隨后大體保持在23.3%~23.7%之間。這是因為進行多次實驗后,隨著接收端收到的比特數增加,每當選擇最優閾值檢測偽裝攻擊時,算法都會利用之前多次檢測攻擊的經驗選擇最優檢測閾值,一定實驗次數后,最優測試閾值差別減小。另外,根據霧計算無線網絡動態變化的特點,信道衰落的不同導致信道向量有所差別,因此FAR值小幅波動,但大體保持在恒定范圍內。與Q-learning算法相比,在大部分實驗次數下,DQL算法的FAR值較低,這是由于接收端使用兩個Q 表互相彌補估計誤差,增加了收益估計的準確率,使其選擇了更合理的閾值。因此,在使用基于DQL算法檢測偽裝攻擊時,接收端接收到合法數據包但將它視為非法數據包并丟棄的可能性更低,從而增加了合法數據包的接收率,提高了霧節點與終端用戶間通信的安全性。
相似地,在初始化參數下1~100 次連續實驗中,兩種算法的MDR值比較如圖3所示。
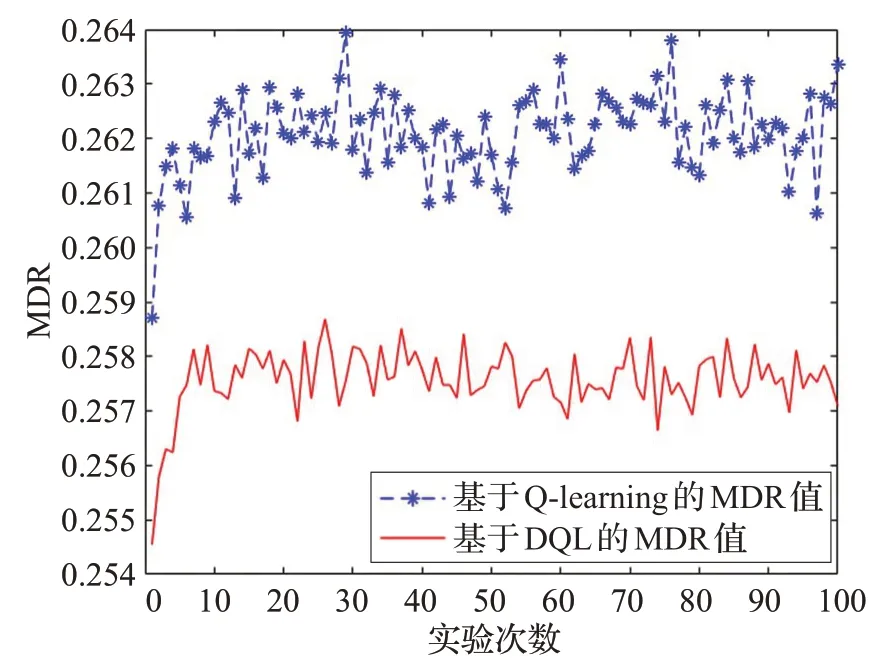
圖3 兩種算法的MDR值對比圖
很明顯,由于接收端的Q表初始值全為0,前期實驗中所選擇的最優閾值較小,隨著實驗次數的增加,當最優閾值增大時,根據式(21),與FAR 值相反,MDR 值有較小幅度的增加。一定實驗次數后,因為每次實驗的信道向量和選擇的最優閾值有微小差異,導致MDR 值在小范圍內上下波動,但其值已經穩定下來,大體保持在恒定范圍內。另外,DQL 算法的MDR 值比Q-learning算法更小,因此,在DQL 算法下,接收端接收到非法數據包但將它視為合法數據包并接受的可能性更低,增加了非法數據包的丟棄率,提高了霧層與用戶層間通信的安全性。
基于FAR和MDR值,本實驗再次比較了在ρ=10,b=0.2,k=3 時,1~100次優化測試閾值的實驗過程中兩種算法的平均錯誤率,其結果如圖4所示。
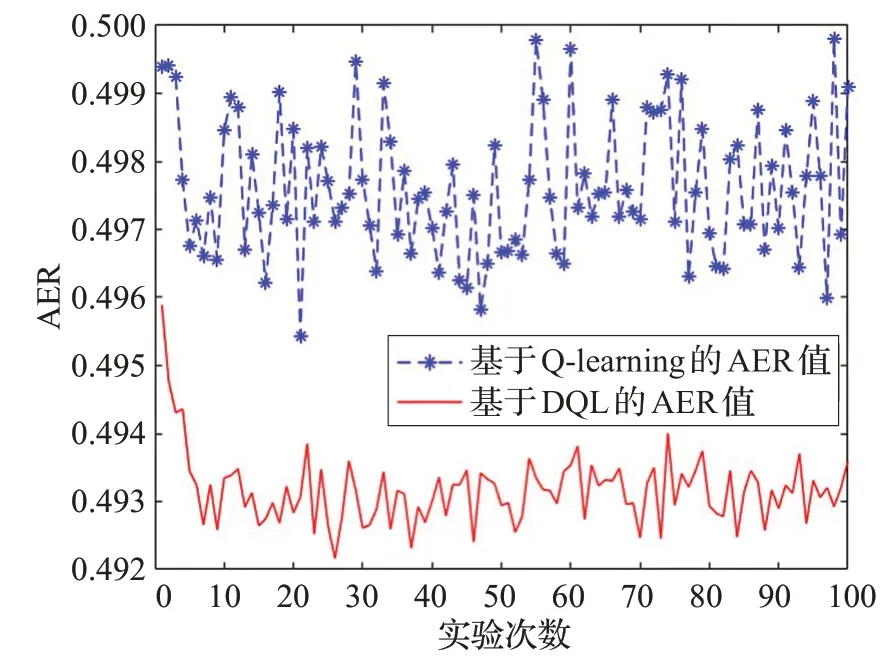
圖4 兩種算法的AER值對比圖
AER表示在固定網絡模型中,給定的初始化參數條件下偽裝檢測的平均錯誤率,計算公式如下:
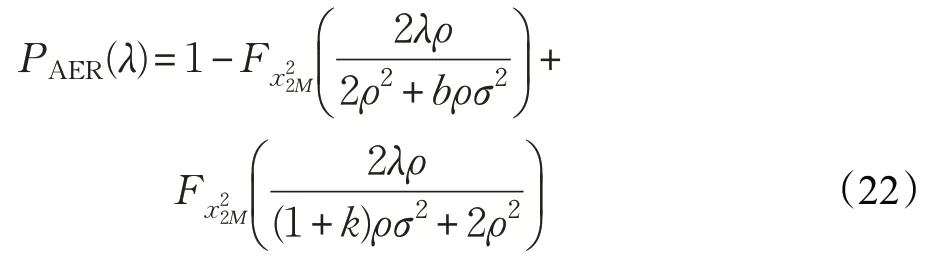
與FAR、MDR一樣,隨著接收端判斷并接收了更多比特的數據包,它學習到了許多選擇最優閾值的經驗,平均錯誤率保持在恒定范圍內。可以看到,使用DQL算法檢測偽裝攻擊的AER 值比使用Q-learning 算法檢測偽裝攻擊的AER 值小,因為AER 值是綜合FAR 值、MDR值計算得到的。因此,在接收端使用DQL算法檢測合法節點和非法節點發送的數據包的性能優于使用Q-learning算法,它可以提高偽裝攻擊檢測的精確度,減少在霧計算網絡下接收端受到偽裝攻擊的概率。
最后,本實驗比較了兩種算法在初始化參數設定下1~100 次連續實驗過程中共5 000 個狀態下的最大Q值。結合前文所述的錯誤率分析,由圖5 可以看出,在每個狀態下DQL 算法的最大Q 值比Q-learning 算法的最大Q 值小,這是由于接收端使用的DQL 算法借助兩個Q 表相互彌補收益的估計誤差,處理了Q-learning 算法存在的Q值過度估計問題,使得每個狀態下收益的估計值更加精確,從而對每個狀態下的閾值選擇產生影響。即優化了最優閾值的判斷,選擇更合適的閾值檢測數據包的合法性,進而降低了FAR、MDR 和AER 的值,減少了接收端受到偽裝攻擊的數量。綜合上述實驗,基于DQL 算法的偽裝攻擊檢測優于基于Q-learning 算法的偽裝攻擊檢測。
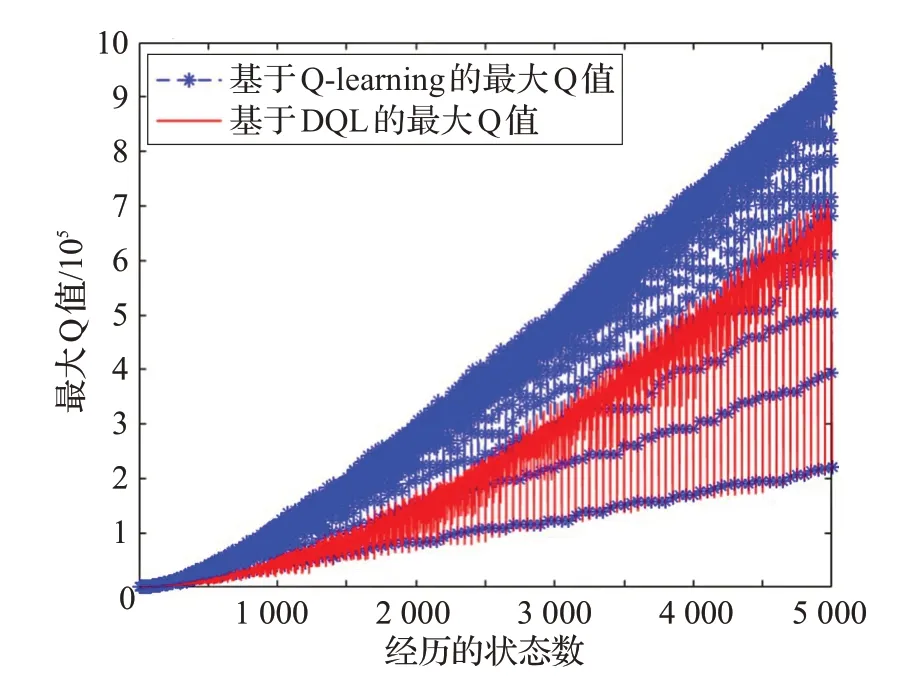
圖5 兩種算法的最大Q值對比圖
6 結束語
本文分析了霧計算網絡中霧節點與終端用戶易受到偽裝攻擊的缺陷,提出一種利用霧節點與終端用戶之間的無線信道特性檢測偽裝攻擊的方案。該方案首先在接收端建立假設檢驗,利用靜態偽裝檢測,基于零和博弈計算接收端和偽裝者的收益;其次,將假設檢驗和博弈論的方法用于動態偽裝檢測中,設計了一個基于強化學習DQL算法獲取偽裝檢測最優閾值的方案。仿真實驗結果表明,基于DQL 算法檢測偽裝攻擊能夠降低誤報率、漏檢率和平均錯誤率,其檢測性能優于使用Q-learning 算法的偽裝攻擊檢測。在未來的工作中,將繼續使用強化學習的方法解決各種安全威脅,比如竊聽攻擊、身份驗證、干擾攻擊、拒絕服務攻擊等。
猜你喜歡
中國設備工程(2022年12期)2022-07-11 04:33:00
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:36
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:34
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:50
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:48
