基于深度神經網絡的藥物蛋白虛擬篩選
2020-05-21 03:33:01周世英李福東姜定
軟件工程 2020年5期
關鍵詞:特征提取
周世英 李福東 姜定
摘? 要:藥物的研發是一種投入成本高、耗費時間長且成功率較低的一種研究,為了在藥物開發階段可以快速獲得潛在的化合物,針對性地提出一種基于深度神經網絡的藥物蛋白虛擬篩選的方法。首先從給定數據集中學習如何提取相關特征,獲取配體原子和殘基類型進行特征分析,快速識別活性分子和非活性分子,然后使用降維方式和K折驗證等方法對藥物篩選的模型進行處理,最后通過分析富集因子和AUC值驗證誘餌化合物與分子蛋白的互相作用驗證模型的可靠程度,實驗結果表明所提出的篩選方法具有很好的可行性和有效性,有效地加快了虛擬篩選過程。
關鍵詞:深度神經網絡;虛擬篩選;特征提取
中圖分類號:TP391? ? ?文獻標識碼:A
Abstract: Drug development is a kind of research with high input cost, long development cycle and low success rate. In order to quickly obtain potential compounds in the drug development stage, the paper proposes a deep neural network based virtual screening method for drug proteins. First, by learning how to extract the features from a given data set, the ligand atoms and the residue type are acquired to conduct characteristic analysis. After fast identification of active and inactive molecules, the dimension reduction method and the K-fold validation method are used to process the drug screening model. Finally, by analyzing enrichment factors and the interaction between AUC value bait compounds and molecular protein, the reliability of the model is verified. The experiment proves the feasibility and effectiveness of the proposed screening method which can effectively speed up the virtual screening process.
Keywords: deep neural network; virtual screening; feature extraction
1? ?引言(Introduction)
虛擬篩選已經成為現代藥物開發過程中的一個重要輔助工具[1],它可以在成千上萬的候選化合物藥物中篩選出與所需的藥物目標結合的新型化合物,得到可以激活或抑制選定蛋白的小分子。一般來說虛擬篩選方法可以分為基于受體的虛擬篩選和基于配體的虛擬篩選,前者通過對已知具有相同作用機理的化合物進行定量構效(QSAR)關系研究,依照藥效團模型對化合物數據庫進行搜索以得到最佳的構象。后者主要應用分子對接技術,實施這種篩選需要獲知藥物作用靶標的分子結構,通過分子模擬手段計算化合物庫中的小分子與靶標結合的能力,預測候選化合物的生理活性。雖然虛擬篩選的準確性有待提高,但是其快速廉價的特點使之成為發展最為迅速地藥物篩選技術之一。
到目前為止,隨著新的分子生物學技術的出現,藥物開發產生了完全性的改變和演變,出現了神經網絡等可以增強虛擬篩選能力的方法,可以訓練基于輸入和輸出對生成分類器。Adam[2]將可學習的原子卷積和softmax操作分別應用于每個分子的基礎上建立了一種用于基于結構的虛擬篩選的深度學習架構,該架構可以生成固定大小的蛋白質和小分子指紋并進行進一步的非線性變換,通過計算它們的內積并用于預測結合勢得到篩選的效果。該方法的篩選效率較高,檢索速度快,但在針對不同特征的權重值方面存在著局限性,本文通過使用了深度神經網絡來改進虛擬篩選的結果,提出了一種DL的虛擬篩選,它以深度神經網絡為基礎,可以大量的小分子化合物進行分類篩選并排除不具有活性的小分子化合物,本文其余部分的結構如下。
2? 基于深度神經網絡藥物蛋白虛擬篩選算法構建(Construction of virtual screening algorithm for drug protein based on deep neural network)
2.1? ?數據采集
A Directory of Useful Decoys(DUD)是由加州大學舊金山分校藥物化學系的Irwin和Shoichet實驗室所歸納的藥物數據集,它用于測試基于配體的誘餌對接算法,DUD是迄今為止用于對虛擬篩選程序進行基準測試的最大,最全面的公共數據集。DUD含有40個受體蛋白酶,每種蛋白酶的配體中都有幾十到幾百個分子從而組成了2950種配體。又從商業可用化合物ZINC數據庫中對每個配體檢索到36個誘餌以模擬相關配體的某些物理性質,它們在物理性質上類似于特定的配體,如分子量、cLogP和氫鍵基團的數量,但在拓撲結構上卻截然不同,從而形成了一個包含98266種化合物的數據庫。使用的數據集包括復雜晶體的PDB代號和結構活性物的數量,誘餌數及不同的化學類型數。我們使用以下九個具有代表性的受體用于后續分析[3]。
2.2? 深度神經網絡算法的構建
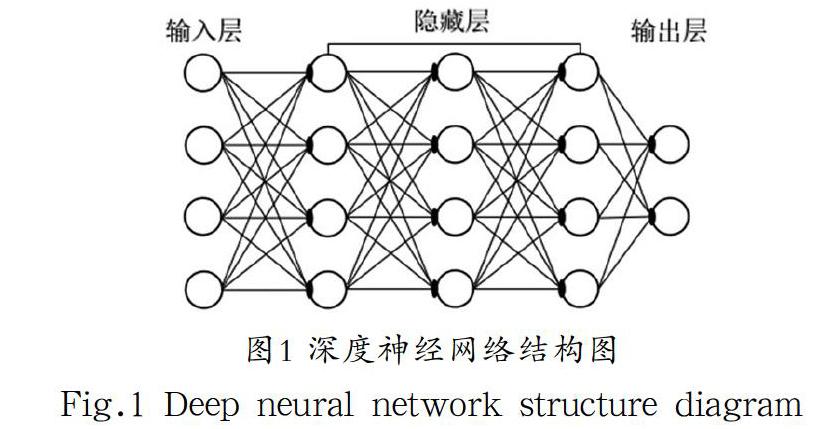
深度神經網絡(DNN)是一種多層神經網絡,它包含一個輸入層、一個輸出層和多個隱藏層,層與層之間通過前向或反饋連接方式相互結合,其中隱藏層可以根據模型需要設置層數以追求最佳的效果,連接強度使用權重因子表達,神經元通過給定的數據集按照一定的規則對網絡連接權重進行學習,通過多次訓練以達到最佳的實際結構,本文的隱藏層包括三層,是一個全連接層序列,以每個化合物的特征為輸入并沿著網絡層依次計算,每一層通過前一層中的輸入值乘以當前隱藏層中每個單元的權向量計算加權和,其網絡拓撲結構如圖1所示。本研究還通過在網絡中使用詞嵌入(word Enbedding)、Adam算法和K折交叉驗證進行訓練和網絡優化。
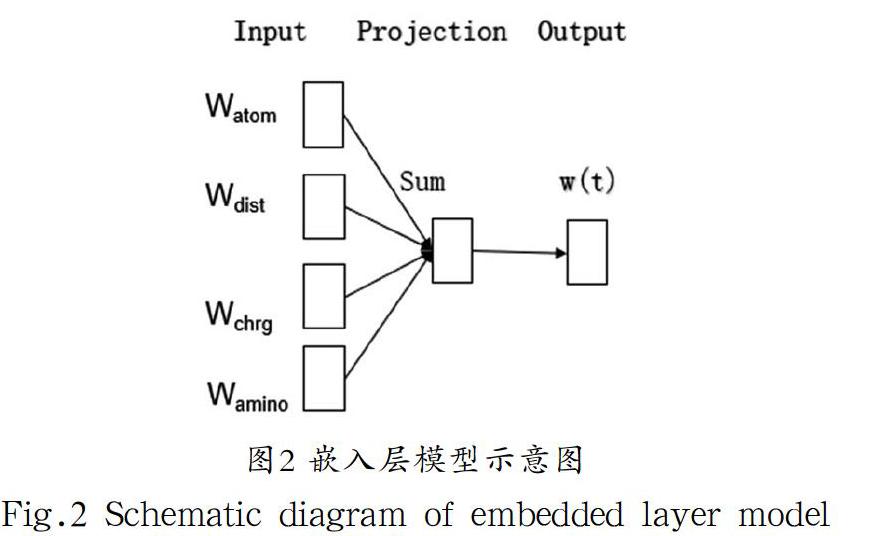
(1)特征提取:詞嵌入是自然語言處理(NLP)語言模型與表征學習技術的統稱,它可以將高維度數量的詞嵌入到低維度的向量空間中,數據被映射為實數域上的向量,它可以對分子數據的特征進行進一步地進行信息抽取,從蛋白質復合物中提取相關信息得到相關特征,通過相似量的表達得到數據處理,這里輸入層使用來自的信息包括Watom、Wdist、Wchrg和Wamino這四個特征量,既原子類型、相關距離、原子的電荷和氨基酸類型,這些特征量矩陣構成一個隱層的權重矩陣,使用詞嵌入可以在很大程度上對數據維度縮減,有益于增加后續網絡訓練的收斂性,并且最大程度上保留了原分子的信息以確保篩選的正確性。嵌入層模型如圖2所示。
(2)Adam算法:Adam算法[4]是一種可以替代傳統隨機梯度下降(SGD)過程的一階優化算法,它能基于訓練數據迭代地更新神經網絡權重,不同于傳統的隨機梯度下降Adam算法通過計算梯度的一階矩估計和二階矩估計為不同的參數設計獨立的自適應性學習率進行迭代的方式對神經網絡進行更新。Adam算法同時獲得了適應性梯度算法(AdaGrad)和均方根傳播算法(RMSProp)這兩種隨機梯度下降擴展式的優點,通過維持每個參數的學習率以改善稀疏梯度的性能,自適應地保持學習速率。
(3)交叉驗證:交叉驗證是一種評估泛化性能的統計學方法,他比單次劃分訓練集和測試集的方法更加全面穩定,最常用的交叉驗證方法是K折交叉驗證(K-fold cross-validation),其中K是由用戶指定的數字,文中將數據集劃分為相等的五部分,每一部分叫作折(fold)。在實驗過程中對數據集中化合物具有活性值設為1,沒有活性值設為0,分別對應標記1和0標簽,以40個藥物相關靶標蛋白質對應的活性非活性化合物作為基準測試數據集進行5折交叉驗證,對這個神經網絡訓練過程重復40次,每次用不同的一組DUD的40個受體作為測試受體打分,基于結構的虛擬篩選,需要蛋白質的結構信息來將配體候選體停靠在目標物的結合口袋中。在這里,大量的小分子被篩選來對抗目標蛋白的結構。然后利用評分函數對蛋白質與化合物的結合能力進行評估分類。
研究中基于深度神經網絡的藥物蛋白虛擬篩選訓練步驟具體如下:
(1)將(DUD)蛋白酶數據進行預處理和篩選,考慮交叉富集相似關系去除相似的蛋白酶。
(2)通過原子綁定類型、相鄰原子距離和原子電荷作為特征進行篩選。
(3)采用DNN神經網絡對網絡結構進行調整。
(4)使用K折驗證在平均性能的基礎上對模型進行準確評估。
(5)計算富集因子和誤差和精度,得到篩選結果。如圖3所示。
3? 實驗結果及分析(Experimental results and analysis)
虛擬篩選結果評價是一項十分重要的工作,由于缺乏標準的評價準則,對應的篩選結果差距也十分大,主流評價標準是使用富集因子(Enrichment Factor, EF)和AUC(Area Under Curve),即ROC曲線下的面積[5]。
3.1? ?富集因子
富集因子是評估分子對接性能的重要指標,主要考察對接計算所使用的參數是否從包含活性分子和誘餌分子的數據庫中將活性分子通過打分的形式篩選出來。本文通過這種方法驗證對接方法是否有效。其計算公式為:
式中,TP代表預測正確的正樣本數,TN代表預測正確的負樣本數,FP代表預測錯誤的負樣本數,FN代表預測錯誤的正樣本數。模型的靈敏性分析SE(sensitivity)用于評估正樣本的預測正確率,特效性分析SP(specificity)用于評估負樣本的預測正確率。Nt為所有化合物分子個數,Ns是取樣化合物數量,total actives為取樣重活性化合物的個數,total molecules為測試集中所有活性化合物的個數,EFX%為打分結果前x%分子的個數(本文設定為2%),對于同一數據集式中total actives/total molecules的值是固定的。當EF>1時,說明該方法具有顯著地活性化合物的富集能力,得到的結果是有效地,而且其富集能力隨著EF的值得增加而增加。如表2所示,除了ace蛋白外,我們的DL篩選方法均能得到驗證[6]。
3.2? ?AUC值
AUC是計算ROC曲線下的面積(area under curve),該值可反映虛擬篩選方法的效果。一般認為該值為0.7—1時具有一定的篩選效果,由于ROC曲線一般都處于y=x這條直線的上方,所以AUC正確的取值范圍在0.5—1。而且AUC越接近1.0,檢測方法真實性越高。當AUC值等于0.5時,則真實性最低,說明無應用價值,得到的結果如表3所示。
將我們建立的模型的預測結果與文獻[6]預測的結果進行比較,以便檢驗我們模型的預測水平。文獻使用DOCK、RosettaLigand(RL)和AutodockVina(ADV)這三種篩選軟件進行篩選操作,計算結果如表2和表3所示。由于數據的特性問題研究中使用的DL方法與其他相比選取的靶點蛋白富集因子除ace外均大于1,證明對接得到的前期活性分子可被使用,可以驗證對接方法及參數適用于該體系。但是需要指出的是直接和不同模型的預測結果相比較不太合理,因為不同的模型采用了不同驗證方法和篩選特征。通過實驗結果對比可得可知DL這種研究所得到的富集因子和AUC值均能得到較好的結果,深度神經網絡相比其他三種傳統方法的篩選效果穩定性提高了很多。
4? ?結論(Conclusion)
本文在這項工作中引入的深度神經網絡的方法進行虛擬篩選方法的開發,有效考慮關鍵數據中的有效特征,通過提取目標原子種類、原子距離、電荷和氨基酸類型增強了虛擬篩選的正確性,這種方法大大減輕了人為干預,可以為后續的對接實驗、蛋白活性實驗等操作打下了基礎。通過比較同類型的虛擬篩選所得到的富集因子和AUC值均表現出較好的結果,研究結果表明,建立深度神經網絡模型在虛擬篩選方面的操作是成功的,研究中的DL方法對加快設計和發現藥物有著極其重要的意義。
參考文獻(References)
[1] Kristy A Carpenter,David S Cohen.Deep learning and virtual drug screening[J].Future.Medicinal.Chemistry,2018,10(21):2557-2567.
[2] Adam Gonczarek,Jakub M.TomczakInteraction prediction in structure-based virtual screening using deep learning[J].Computers in Biology and Medicine,2017(100):253-258.
[3] Andreas Jahn,Georg Hinselmann.Optimal assignment methods for ligand-based virtual screening[J].Journal of Cheminformatics,2009(1):1-14.
[4] 楊觀賜,楊靜,李少波,等.基于Dopout與ADAM優化器的改進CNN算法[J].華中科技大學學報(自然科學版),2018,46(07):122-127.
[5] 楊國兵,李澤榮,饒含兵.機器學習方法用于建立乙酰膽堿酯酶抑制劑的分類模型[J].物理化學學報,2010,26(12):3351-3359.
[6] Marcelino Arciniega,Oliver F.Lange.Improvement of Virtual Screening Results by Docking Data Feature Analysis[J].Journal of Chemical Information and Modeling,2014(54):1401-1411.
猜你喜歡
艦船科學技術(2022年15期)2022-09-14 09:21:50
電子制作(2019年15期)2019-08-27 01:12:00
電子制作(2018年19期)2018-11-14 02:37:08
自動化學報(2017年7期)2017-04-18 13:41:09
自動化學報(2017年11期)2017-04-04 02:52:58
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
計算機工程(2015年4期)2015-07-05 08:28:02
機電信息(2015年3期)2015-02-27 15:54:46
機械工程師(2015年10期)2015-02-02 01:13:49
