基于多源數(shù)據(jù)融合的共享教育數(shù)據(jù)模型研究
2020-05-21 02:49:38武法提黃石華
電化教育研究 2020年5期
武法提 黃石華

[摘? ?要] 人工智能教育時(shí)代,傳統(tǒng)的教育數(shù)據(jù)共享方法無法滿足海量教育數(shù)據(jù)共享的時(shí)效性,進(jìn)而影響智能教育系統(tǒng)響應(yīng)的即時(shí)性與智能性,文章提出了一種基于多源數(shù)據(jù)融合的共享教育數(shù)據(jù)模型的建模方法。該建模方法首先對(duì)多源數(shù)據(jù)融合的概念、融合方法等內(nèi)容進(jìn)行分析,并對(duì)多種異構(gòu)數(shù)據(jù)源的數(shù)據(jù)共享特性進(jìn)行剖析,提取出“學(xué)習(xí)者、時(shí)間、空間、設(shè)備、事件”五維數(shù)據(jù)共享特性來對(duì)多源異構(gòu)的教育數(shù)據(jù)進(jìn)行數(shù)據(jù)融合分析;然后再結(jié)合國際通用的xAPI(Experience API)數(shù)據(jù)規(guī)范,對(duì)融合后的數(shù)據(jù)進(jìn)行規(guī)范化分析,生成通用的教育數(shù)據(jù)交換格式;最后,基于該數(shù)據(jù)交換格式,探討了共享教育數(shù)據(jù)模型的總體架構(gòu)及實(shí)現(xiàn)路徑,并構(gòu)建一個(gè)可重用、可共享的教育數(shù)據(jù)模型,以期為今后開展基于大數(shù)據(jù)的數(shù)據(jù)共享的研究提供一套切實(shí)可行的實(shí)踐指導(dǎo)框架。
[關(guān)鍵詞] 數(shù)據(jù)特性; 多源數(shù)據(jù)融合; xAPI規(guī)范; 數(shù)據(jù)共享模型
[中圖分類號(hào)] G434? ? ? ? ? ? [文獻(xiàn)標(biāo)志碼] A
[作者簡(jiǎn)介] 武法提 (1971—),男,山東鄆城人。教授,博士,主要從事智能學(xué)習(xí)系統(tǒng)設(shè)計(jì)研究。E-mail:wft@bnu.edu.cn。
一、問題的提出
人工智能教育時(shí)代,數(shù)據(jù)收集與共享是智能教育過程中非常重要的一個(gè)環(huán)節(jié)[1],數(shù)據(jù)的共享程度直接影響著智能教育系統(tǒng)響應(yīng)的即時(shí)性和智能性。而隨著云計(jì)算、移動(dòng)互聯(lián)網(wǎng)、大數(shù)據(jù)、人工智能等“新技術(shù)”的日漸成熟,這些“新技術(shù)”賦予了智能學(xué)習(xí)終端設(shè)備全方位感知和采集數(shù)據(jù)的能力,能夠捕捉學(xué)習(xí)者全范圍、全過程的學(xué)習(xí)行為數(shù)據(jù),形成海量的教育大數(shù)據(jù),呈現(xiàn)出多源性、多模態(tài)、多樣性的特點(diǎn)。這些“新技術(shù)”雖然給人們的數(shù)據(jù)獲取帶來極大便利,但也出現(xiàn)海量教育數(shù)據(jù)資源與各異構(gòu)數(shù)據(jù)源難以獲取所需數(shù)據(jù)之間的矛盾,以及異構(gòu)數(shù)據(jù)之間數(shù)據(jù)共享的時(shí)效性較差等問題,而如何打通各異構(gòu)數(shù)據(jù)源的“數(shù)據(jù)壁壘”,構(gòu)建一個(gè)高度共享互通的教育數(shù)據(jù)模型,在提升海量教育數(shù)據(jù)共享的時(shí)效性的同時(shí),也為智能教育系統(tǒng)提供更客觀、全面、完整的數(shù)據(jù)支撐,則是當(dāng)前教育發(fā)展迫切需要解決的問題之一。基于此,文章提出一種基于多源數(shù)據(jù)融合的共享教育數(shù)據(jù)模型的建模方法,通過采用多源數(shù)據(jù)融合方法對(duì)海量異構(gòu)教育數(shù)據(jù)進(jìn)行特征級(jí)數(shù)據(jù)融合,再結(jié)合國際通用的xAPI(Experience API)學(xué)習(xí)數(shù)據(jù)規(guī)范,構(gòu)建一個(gè)可重用、可共享的教育數(shù)據(jù)模型,以提升海量教育數(shù)據(jù)共享的時(shí)效性,實(shí)現(xiàn)各異構(gòu)數(shù)據(jù)源之間數(shù)據(jù)的高度共享與互通。
二、多源異構(gòu)教育數(shù)據(jù)的數(shù)據(jù)融合分析
(一)多源數(shù)據(jù)融合的方法分析
數(shù)據(jù)融合最早應(yīng)用于軍事領(lǐng)域,它是一種多層次、多方面的數(shù)據(jù)處理過程, 用于處理多源數(shù)據(jù),對(duì)信息進(jìn)行自動(dòng)檢測(cè)、聯(lián)合、相關(guān)、估計(jì)和合成[2],主要是為了實(shí)現(xiàn)較為準(zhǔn)確的位置推斷和身份估計(jì),進(jìn)而對(duì)戰(zhàn)場(chǎng)狀況、威脅程度和重要水平作出及時(shí)完整的評(píng)價(jià)[3]。后來在傳感器、地理空間、情報(bào)分析等多個(gè)領(lǐng)域得到了應(yīng)用與發(fā)展,尤其是互聯(lián)網(wǎng)時(shí)代,多源數(shù)據(jù)融合逐漸成為大數(shù)據(jù)領(lǐng)域的重要研究方向[4]。通過多源數(shù)據(jù)融合,可以實(shí)現(xiàn)多源信息的交叉印證,可以達(dá)到數(shù)據(jù)信息的相互補(bǔ)償,并可以有效地減少數(shù)據(jù)量,以獲取確定數(shù)據(jù)和深層次的語義知識(shí)[4-5]。人工智能教育時(shí)代,教育大數(shù)據(jù)的生態(tài)逐漸形成,海量的教育數(shù)據(jù)呈現(xiàn)多源異構(gòu)特性,而多源數(shù)據(jù)融合方法為解決新時(shí)代教育大數(shù)據(jù)的共享互通提供了一種新的解決思路,為構(gòu)建一個(gè)重用、共享的教育數(shù)據(jù)模型提供了可行的實(shí)踐視角。
而目前常見的多源數(shù)據(jù)融合方法主要有數(shù)據(jù)級(jí)融合、特征級(jí)融合和決策級(jí)融合等三種[6]。數(shù)據(jù)級(jí)融合是屬于最底層的數(shù)據(jù)融合,它是對(duì)原始數(shù)據(jù)經(jīng)過簡(jiǎn)單預(yù)處理之后直接進(jìn)行關(guān)聯(lián)和融合,融合之后才作數(shù)據(jù)特征提取;特征級(jí)融合是先對(duì)數(shù)據(jù)進(jìn)行特征提取,再對(duì)數(shù)據(jù)進(jìn)行關(guān)聯(lián)融合;決策級(jí)融合是先對(duì)各數(shù)據(jù)源進(jìn)行決策,然后再將這些決策進(jìn)行關(guān)聯(lián)融合,最終獲得整體一致性的決策結(jié)果[7-9]。這三種數(shù)據(jù)融合方法的融合過程如圖1所示。通過比較這三種數(shù)據(jù)融合方法,可以看出,數(shù)據(jù)級(jí)融合雖然能夠最大程度上保留原始數(shù)據(jù)的特征,但融合的代價(jià)較高,時(shí)效性也較差,無法滿足人工智能教育時(shí)代對(duì)數(shù)據(jù)的即時(shí)性等要求;決策級(jí)融合雖然具有很高的容錯(cuò)性和時(shí)效性,但它是以具體決策需求為出發(fā)點(diǎn)進(jìn)行的數(shù)據(jù)融合,面對(duì)人工智能教育時(shí)代復(fù)雜多變的教育大數(shù)據(jù)環(huán)境,難以制定出具體適配的決策以進(jìn)行數(shù)據(jù)融合;而特征級(jí)融合在保證即時(shí)性的同時(shí),也能夠最大程度上給出決策所需的特質(zhì)信息,其融合結(jié)果也具有較高的精度,由于教育大數(shù)據(jù)不像圖像數(shù)據(jù)具有融合的高精度,特征級(jí)融合方法很好地契合了人工智能教育時(shí)代教育大數(shù)據(jù)分析的要求。基于此,文章將采用特征級(jí)數(shù)據(jù)融合方法來構(gòu)建共享教育數(shù)據(jù)模型。
(二)異構(gòu)多源教育數(shù)據(jù)的共享數(shù)據(jù)特性的提取
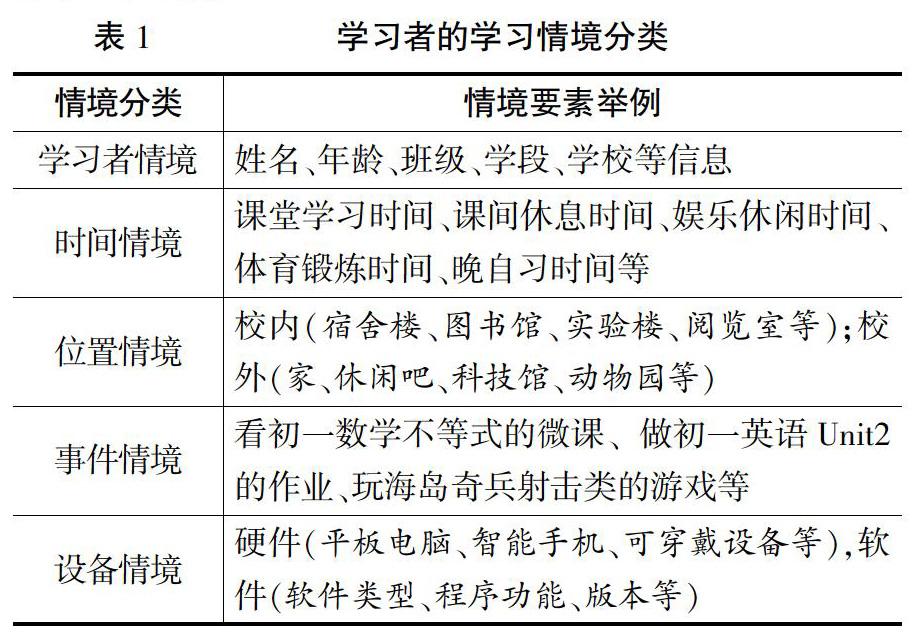
為了提高數(shù)據(jù)融合之后的數(shù)據(jù)重用度,文章的多源教育數(shù)據(jù)融合方法是通過提取各異構(gòu)數(shù)據(jù)源的數(shù)據(jù)共享特性來進(jìn)行特征級(jí)數(shù)據(jù)融合。而數(shù)據(jù)共享特性的提取過程,其實(shí)質(zhì)就是從各異構(gòu)數(shù)據(jù)源學(xué)習(xí)者所產(chǎn)生的學(xué)習(xí)行為數(shù)據(jù)中提取學(xué)習(xí)情境特性的過程。縱觀以往的學(xué)習(xí)情境的信息特性描述,不同學(xué)者從不同的視角將情境信息特性劃分為不同的類型。以下是相關(guān)學(xué)者對(duì)情境信息特性劃分的典型觀點(diǎn):如DEY[10]認(rèn)為,情境信息包括位置、時(shí)間和周圍環(huán)境等顯式感知的情境信息,同時(shí)也包括社會(huì)關(guān)系、習(xí)慣、消費(fèi)水平和喜好等蘊(yùn)含感知的情境信息。Lieberman[11]等人將情境分為用戶情境、環(huán)境情境和應(yīng)用情境三大方面,其中,用戶情境包括活動(dòng)、位置和描述等情境;環(huán)境情境包括時(shí)間、亮度、溫度、天氣、資源等情境;應(yīng)用情境包括功能、維護(hù)、能源等情境。岳瑋寧[12]等人將情境信息分為自然環(huán)境、設(shè)備環(huán)境、用戶環(huán)境三大類。顧君忠[13]等人從用戶為中心的視角,將情境信息分為計(jì)算情景、用戶情境、物理情境、時(shí)間情境和社會(huì)情境等情境。而人工智能教育時(shí)代不同數(shù)據(jù)源的學(xué)習(xí)數(shù)據(jù)具有很明顯的時(shí)空特性,且學(xué)習(xí)者的學(xué)習(xí)交互離不開設(shè)備的支持。基于上述的情境信息特性分析,文章將各異構(gòu)數(shù)據(jù)源的共享數(shù)據(jù)特性提取為學(xué)習(xí)者情境、時(shí)間情境、位置情境、設(shè)備情境和事件情境5個(gè)維度情境信息特性(見表1)。
表1? ? ? ? ? ? ? ? ?學(xué)習(xí)者的學(xué)習(xí)情境分類
(三)基于共享數(shù)據(jù)特性的特征級(jí)數(shù)據(jù)融合
以上5個(gè)維度的學(xué)習(xí)情境信息特性很好地表征了各異構(gòu)數(shù)據(jù)源的共享數(shù)據(jù)特性,通過這5個(gè)共享數(shù)據(jù)特性,可以準(zhǔn)確地描述各異構(gòu)數(shù)據(jù)源中學(xué)習(xí)者真實(shí)的學(xué)習(xí)生活場(chǎng)景,進(jìn)而可以很好地實(shí)現(xiàn)異構(gòu)數(shù)據(jù)之間的無縫對(duì)接。這5個(gè)共享數(shù)據(jù)特性代表5個(gè)數(shù)據(jù)維度,組合后可以構(gòu)成學(xué)習(xí)者真實(shí)的學(xué)習(xí)場(chǎng)景:“學(xué)習(xí)者情境 + 時(shí)間情境 + 位置情境 + 設(shè)備情境 + 事件情境 ≌ 學(xué)習(xí)場(chǎng)景”,它描述了“學(xué)習(xí)者、什么時(shí)間、什么地點(diǎn)、基于什么設(shè)備、做了什么事情”。基于這5個(gè)數(shù)據(jù)維度,采用特征級(jí)數(shù)據(jù)融合方法對(duì)教育數(shù)據(jù)進(jìn)行融合。其特征級(jí)數(shù)據(jù)融合主要經(jīng)過各數(shù)據(jù)維度的語義特征的分層提取、分層語義的特征級(jí)數(shù)據(jù)融合、跨維度跨分層的關(guān)聯(lián)語義的特征級(jí)數(shù)據(jù)融合等融合過程,如圖2所示。
(1)各數(shù)據(jù)維度的語義特征的分層提取,主要是對(duì)這5個(gè)不同數(shù)據(jù)維度進(jìn)行語義特征的分層提取,確定各數(shù)據(jù)維度的語義屬性,并確定各數(shù)據(jù)維度語義同級(jí)、上下級(jí)的多層語義邏輯關(guān)系。如時(shí)間維度的語義屬性可以分為工作日和節(jié)假日大類語義信息,工作日又可以細(xì)分為課堂學(xué)習(xí)時(shí)間、自習(xí)時(shí)間等不同粒度的語義信息。
(2)分層語義的特征級(jí)數(shù)據(jù)融合,主要是將各異構(gòu)數(shù)據(jù)源的教育數(shù)據(jù),按照這些分層語義分類,采用相應(yīng)的細(xì)粒度融合策略進(jìn)行特征級(jí)數(shù)據(jù)融合,生成能準(zhǔn)確描述學(xué)習(xí)者學(xué)習(xí)特征的場(chǎng)景數(shù)據(jù),并消除數(shù)據(jù)結(jié)構(gòu)和相同語義聚集在同一粒度上的不一致與冗余關(guān)系。
(3)跨維度、跨分層的關(guān)聯(lián)語義的特征級(jí)數(shù)據(jù)融合,主要是為了更客觀、精準(zhǔn)地描述學(xué)習(xí)者的學(xué)習(xí)特征,根據(jù)不同維度、不同層面的相似語義,對(duì)這些具有關(guān)聯(lián)語義的數(shù)據(jù)進(jìn)一步進(jìn)行特征級(jí)融合,生成具有深層次語義知識(shí)的場(chǎng)景數(shù)據(jù)(如學(xué)習(xí)者的學(xué)習(xí)習(xí)慣等)。
三、xAPI規(guī)范對(duì)5維特征融合數(shù)據(jù)的
規(guī)范化分析
(一) xAPI規(guī)范與5維特征融合數(shù)據(jù)的融合分析
在得到5維特征融合的教育數(shù)據(jù)后,接下來就需要對(duì)這5維特征融合數(shù)據(jù)進(jìn)行規(guī)范化分析,而學(xué)習(xí)數(shù)據(jù)規(guī)范的選擇是實(shí)現(xiàn)數(shù)據(jù)格式規(guī)范的關(guān)鍵。縱觀以往學(xué)習(xí)數(shù)據(jù)規(guī)范標(biāo)準(zhǔn)的發(fā)展,主要經(jīng)歷了以下幾個(gè)階段[14-16]:無標(biāo)準(zhǔn)階段、AICC(The Aviation Industry CBT Committee)標(biāo)準(zhǔn)階段、SCORM(Sharable Content Object Reference Model)標(biāo)準(zhǔn)階段。AICC標(biāo)準(zhǔn)雖然在一定程度上解決了課程資源的共享問題,但采用這種學(xué)習(xí)數(shù)據(jù)規(guī)范開發(fā)的課程資源遷移性不好,不一定能在不同的平臺(tái)上運(yùn)行。SCORM標(biāo)準(zhǔn)是目前最為廣泛應(yīng)用的學(xué)習(xí)數(shù)據(jù)規(guī)范標(biāo)準(zhǔn)[17],但這種標(biāo)準(zhǔn)只是針對(duì)課件等學(xué)習(xí)內(nèi)容的數(shù)據(jù)規(guī)范,無法對(duì)課件學(xué)習(xí)以外的學(xué)習(xí)過程數(shù)據(jù)進(jìn)行記錄,也無法實(shí)現(xiàn)跨平臺(tái)的數(shù)據(jù)共享與互通[18],尤其是在面對(duì)人工智能教育時(shí)代動(dòng)態(tài)多變的教育環(huán)境時(shí), SCORM標(biāo)準(zhǔn)難以解決新時(shí)代下多元異構(gòu)數(shù)據(jù)的高度共享性問題。為了破除SCORM標(biāo)準(zhǔn)的局限,美國ADL(Advanced Distributed Learning)組織推出了xAPI(Experience API)數(shù)據(jù)規(guī)范,它不但兼容SCORM標(biāo)準(zhǔn),而且可以記錄幾乎任何一種學(xué)習(xí)或行為,并且可以跨平臺(tái)進(jìn)行數(shù)據(jù)共享與交換[15],xAPI規(guī)范的這種優(yōu)勢(shì)很好地契合了人工智能教育時(shí)代復(fù)雜多變的教育環(huán)境。
xAPI規(guī)范的核心部件主要有兩個(gè)[15,19]:Statement屬性和LRS(Learning Record Store)學(xué)習(xí)記錄存儲(chǔ)。其中,Statement是定義了xAPI數(shù)據(jù)格式的語法,LRS是定義了學(xué)習(xí)記錄庫(LRS)的數(shù)據(jù)的存儲(chǔ)形式。根據(jù)Statement的“執(zhí)行者(Actor)+ 動(dòng)詞(Verb)+ 對(duì)象(Object)”的聲明結(jié)構(gòu),以及聲明結(jié)構(gòu)Result、Context、Timestamp、Stored、Authority等其他擴(kuò)展屬性。xAPI規(guī)范的Statement聲明結(jié)構(gòu)很好地契合了5維特征融合數(shù)據(jù)的數(shù)據(jù)描述,可以生成5維特征融合數(shù)據(jù)的Statement聲明結(jié)構(gòu),即“學(xué)習(xí)者(Actor)、時(shí)間情境(Time)、空間情境(Local_Context)、設(shè)備情境(Device_Context)、事件情境(Verb+ Object+Result)”,以Statement的屬性來進(jìn)行數(shù)據(jù)封裝,生成通用的數(shù)據(jù)交換格式。然后再通過xAPI規(guī)范的另一個(gè)核心部件——LRS學(xué)習(xí)記錄庫,將數(shù)據(jù)融合的規(guī)范化教育數(shù)據(jù)傳送到LRS中進(jìn)行記錄并保存起來,實(shí)現(xiàn)LRS之間的數(shù)據(jù)共享和交換。xAPI規(guī)范對(duì)5維特征融合數(shù)據(jù)進(jìn)行規(guī)范化的運(yùn)行機(jī)制如下(如圖3所示):當(dāng)不同數(shù)據(jù)源的學(xué)習(xí)活動(dòng)或?qū)W習(xí)行為需要被跟蹤記錄時(shí),xAPI就會(huì)發(fā)出特征級(jí)數(shù)據(jù)融合的Statement表述格式,封裝成JSON或XML等通用數(shù)據(jù)格式傳遞到LRS中,LRS負(fù)責(zé)記錄和存儲(chǔ),并與其他獨(dú)立的LRS交換和共享這些學(xué)習(xí)經(jīng)歷記錄,一個(gè)LRS可以與其他獨(dú)立的LRS共享這些學(xué)習(xí)記錄,LRS也可以獨(dú)立存在,也可以存在于不同的數(shù)據(jù)源中。
(二)5維特征融合數(shù)據(jù)的通用數(shù)據(jù)規(guī)范格式分析
基于上述xAPI規(guī)范對(duì)5維特征融合數(shù)據(jù)進(jìn)行規(guī)范化的運(yùn)行機(jī)制,為了構(gòu)建一個(gè)高度共享的教育數(shù)據(jù)模型,還需要對(duì)5維特征融合數(shù)據(jù)的數(shù)據(jù)規(guī)范格式進(jìn)行分析,生成通用、標(biāo)準(zhǔn)的數(shù)據(jù)交換格式。根據(jù)前面分析得到的5維特征融合數(shù)據(jù)的數(shù)據(jù)結(jié)構(gòu):“學(xué)習(xí)者(Actor)、時(shí)間情境(Time)、空間情境(Local_Context)、設(shè)備情境(Device_Context)、事件情境(Verb+ Object+Result)”,再結(jié)合 xAPI規(guī)范Statement聲明結(jié)構(gòu)的規(guī)范化描述,由此得到5維特征融合數(shù)據(jù)的通用數(shù)據(jù)規(guī)范格式:“Actor(學(xué)習(xí)者) + Time(時(shí)間情境) + Local_Context (位置情境) + Device_Context(設(shè)備情境) + (Verb + Object +? Result + T-span)(事件情境)”。該通用數(shù)據(jù)格式映射出學(xué)習(xí)者的狀態(tài)為:“{學(xué)習(xí)者} 附學(xué)習(xí)者的個(gè)人語義標(biāo)簽 | {某個(gè)時(shí)間點(diǎn)} 附時(shí)間分類語義標(biāo)簽 | {某個(gè)地點(diǎn)} 附地點(diǎn)分類語義標(biāo)簽,{使用什么設(shè)備} 附設(shè)備分類語義標(biāo)簽 | {做了某事,結(jié)果如何,耗時(shí)多少} 附主題事件分類語義標(biāo)簽”。其實(shí)例化后為:“小明{分類語義標(biāo)簽:初一} | 10:00{分類語義標(biāo)簽:課堂學(xué)習(xí)} | 在北二附{分類語義標(biāo)簽:學(xué)校教1樓} | 使用HUAWEIPad {分類語義標(biāo)簽:平板電腦} |做作業(yè):有理數(shù){分類語義標(biāo)簽:初一數(shù)學(xué)第一單元}|得分:95{分類語義標(biāo)簽:優(yōu)秀}”。由此得到5維特征融合數(shù)據(jù)的數(shù)據(jù)格式規(guī)范是以“誰在什么時(shí)間、什么地點(diǎn)、使用什么設(shè)備、做了什么事情”對(duì)學(xué)習(xí)者經(jīng)歷數(shù)據(jù)進(jìn)行描述,其生成的通用數(shù)據(jù)格式(JOSN格式)如圖4所示:
圖4? ?5維特征融合數(shù)據(jù)的通用數(shù)據(jù)格式
四、共享教育數(shù)據(jù)模型的構(gòu)建
(一)共享教育數(shù)據(jù)模型的總體流程框架設(shè)計(jì)
數(shù)據(jù)模型是描述數(shù)據(jù)類型、數(shù)據(jù)聯(lián)系、語義約束的集合,它的構(gòu)成主要有3個(gè)部分:數(shù)據(jù)類型、數(shù)據(jù)聯(lián)系、語義約束[20]。其中,數(shù)據(jù)類型描述了數(shù)據(jù)的邏輯結(jié)構(gòu),數(shù)據(jù)聯(lián)系定義了操作數(shù)據(jù)的方法,語義約束規(guī)定了數(shù)據(jù)的語義規(guī)則。基于此,文章將共享教育數(shù)據(jù)模型也劃分為數(shù)據(jù)描述、數(shù)據(jù)語境、數(shù)據(jù)共享3個(gè)部分(如圖5所示)。其中,數(shù)據(jù)描述是用于實(shí)現(xiàn)對(duì)信息資源的表示、發(fā)現(xiàn)、共享和重用;數(shù)據(jù)語境是數(shù)據(jù)信息所屬主題的標(biāo)注;數(shù)據(jù)共享是對(duì)數(shù)據(jù)交換格式進(jìn)行規(guī)范化。
圖5? ?共享數(shù)據(jù)模型的結(jié)構(gòu)
基于圖5所示的共享數(shù)據(jù)模型結(jié)構(gòu)的邏輯關(guān)系,結(jié)合上述分析得到5維特征融合數(shù)據(jù)的通用數(shù)據(jù)規(guī)范格式,由此可以設(shè)計(jì)出共享教育數(shù)據(jù)模型的總體流程框架,如圖6所示。該總體流程框架是通過對(duì)各異構(gòu)數(shù)據(jù)源的數(shù)據(jù)特性進(jìn)行歸類分析,剖析出不同數(shù)據(jù)源的共享數(shù)據(jù)特征,提取為“學(xué)習(xí)者+時(shí)間情境+空間情境+設(shè)備情境+事件情境≌學(xué)習(xí)場(chǎng)景”5維數(shù)據(jù)特征并進(jìn)行特征級(jí)數(shù)據(jù)融合,結(jié)合xAPI通用數(shù)據(jù)規(guī)范,將融合后的教育數(shù)據(jù)轉(zhuǎn)換為通用的教育數(shù)據(jù)格式規(guī)范,生成規(guī)范化的共享數(shù)據(jù)格式存儲(chǔ)于LRS中,并對(duì)模型中5個(gè)獨(dú)立數(shù)據(jù)維度進(jìn)行組合分析,構(gòu)建一個(gè)可重用、可共享的教育數(shù)據(jù)模型。該模型不但有利于各異構(gòu)數(shù)據(jù)源的數(shù)據(jù)共享與分析,而且能完整地體現(xiàn)學(xué)習(xí)者真實(shí)學(xué)習(xí)活動(dòng)全貌,從而為更深層次發(fā)掘?qū)W習(xí)者的學(xué)習(xí)需求和學(xué)習(xí)狀態(tài)提供強(qiáng)有力的數(shù)據(jù)基礎(chǔ)。
(二)基于多源數(shù)據(jù)融合的共享教育數(shù)據(jù)模型的實(shí)現(xiàn)路徑
基于上述共享教育模型的總體流程框架分析,共享教育數(shù)據(jù)模型的實(shí)現(xiàn)路徑主要經(jīng)過離散和異構(gòu)數(shù)據(jù)的規(guī)范化運(yùn)算、模型數(shù)據(jù)屬性與語義唯一性運(yùn)算、模型數(shù)據(jù)的形式化描述等3個(gè)關(guān)鍵運(yùn)算環(huán)節(jié)。
1. 離散、異構(gòu)數(shù)據(jù)的規(guī)范化運(yùn)算環(huán)節(jié)
離散、異構(gòu)數(shù)據(jù)的規(guī)范化運(yùn)算主要是將各異構(gòu)數(shù)據(jù)源的學(xué)習(xí)行為軌跡數(shù)據(jù),轉(zhuǎn)換為結(jié)構(gòu)化的教育數(shù)據(jù)規(guī)范的過程。該運(yùn)算環(huán)節(jié)首先基于上述分析得到的5維特征數(shù)據(jù)融合的數(shù)據(jù)規(guī)范格式,將采集到離散、異構(gòu)的學(xué)習(xí)者學(xué)習(xí)活動(dòng)軌跡數(shù)據(jù),再調(diào)用xAPI規(guī)范中間件的Statement聲明和動(dòng)作者描述接口,轉(zhuǎn)換為結(jié)構(gòu)化的學(xué)習(xí)行為數(shù)據(jù),封裝成“Actor + Time + Local_Context + Device_Context + (Verb + Object +? Result + T-span)”的規(guī)范化描述的通用、標(biāo)準(zhǔn)數(shù)據(jù)規(guī)范格式,傳遞到LRS中進(jìn)行記錄與保存,生成規(guī)范化的教育數(shù)據(jù)集。其規(guī)范化過程如圖7所示。
2. 模型數(shù)據(jù)屬性的語義處理與唯一性運(yùn)算
為了便于各異構(gòu)數(shù)據(jù)源理解數(shù)據(jù)位置之間的關(guān)聯(lián)關(guān)系,以發(fā)掘?qū)W習(xí)者潛在的學(xué)習(xí)行為模式和學(xué)習(xí)規(guī)律,需要對(duì)模型的數(shù)據(jù)屬性作進(jìn)一步的語義化處理與唯一性運(yùn)算。該運(yùn)算環(huán)節(jié)主要是對(duì)模型的數(shù)據(jù)屬性打上語義標(biāo)簽,并對(duì)模型數(shù)據(jù)的語義進(jìn)行唯一性計(jì)算的過程。首先對(duì)模型中5維融合數(shù)據(jù)的數(shù)據(jù)屬性進(jìn)行分類語義化處理,即對(duì)5個(gè)相對(duì)獨(dú)立的各數(shù)據(jù)維度,根據(jù)各數(shù)據(jù)維度的語義分類,給每一個(gè)數(shù)據(jù)維度的屬性打上分類語義的標(biāo)簽,如時(shí)間數(shù)據(jù)維度以“天”為粒度的時(shí)間語義分類:早讀時(shí)間、課堂時(shí)間等語義分類,生成具有分類語義的規(guī)范化數(shù)據(jù)集;然后對(duì)模型數(shù)據(jù)的語義進(jìn)行唯一性計(jì)算,即去除具有分類語義的規(guī)范化數(shù)據(jù)中的重復(fù)數(shù)據(jù),以保證模型中的數(shù)據(jù)沒有相同語義的數(shù)據(jù)記錄,進(jìn)而提升學(xué)習(xí)行為分析結(jié)果的準(zhǔn)確性。其模型數(shù)據(jù)屬性的語義規(guī)范化過程見表2。
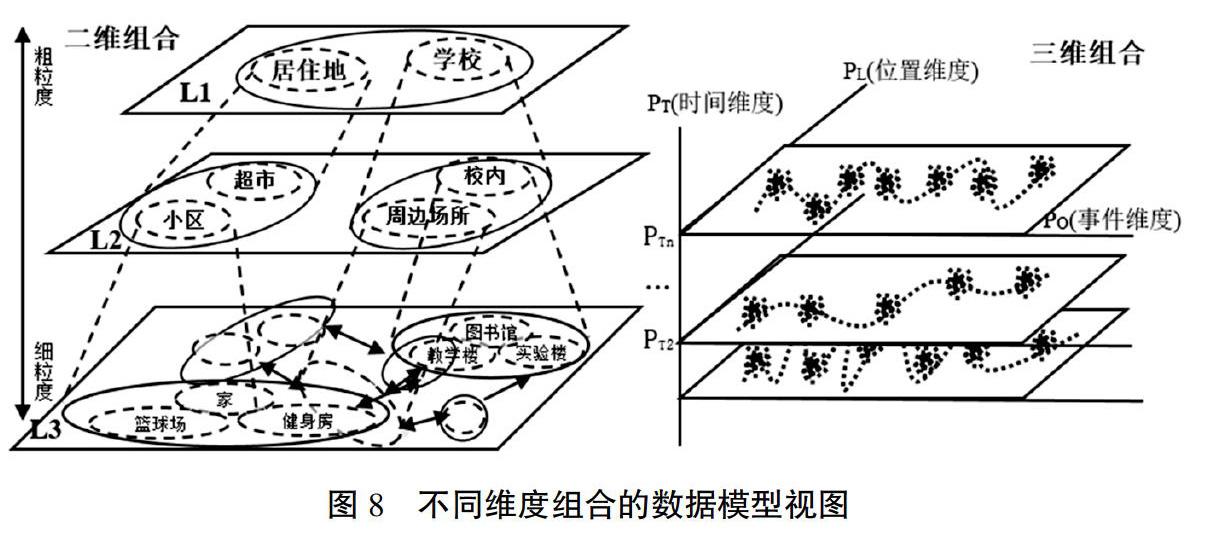
3. 模型數(shù)據(jù)的形式描述
為了構(gòu)建一個(gè)靈活性強(qiáng)、重用度高的共享教育數(shù)據(jù)模型,以減少LRS之間的數(shù)據(jù)交換量,并滿足不同數(shù)據(jù)源對(duì)不同數(shù)據(jù)視圖的需求,還需要對(duì)模型的數(shù)據(jù)進(jìn)行形式化描述。該環(huán)節(jié)是基于模型數(shù)據(jù)屬性與語義唯一性運(yùn)算環(huán)節(jié)計(jì)算的結(jié)果,對(duì)模型中的學(xué)習(xí)者情境數(shù)據(jù)進(jìn)行形式化描述,并進(jìn)一步對(duì)這些獨(dú)立的數(shù)據(jù)維度進(jìn)行多維度組合,以構(gòu)建一個(gè)多維度的共享教育數(shù)據(jù)模型。針對(duì)構(gòu)成數(shù)據(jù)模型的5個(gè)獨(dú)立數(shù)據(jù)維度,由于學(xué)習(xí)者維度是靜態(tài)化的信息數(shù)據(jù),其形式化描述在模型中不作標(biāo)注,由此,模型的學(xué)習(xí)情境數(shù)據(jù)描述可以用4元組Preference來表示,各元組既相互獨(dú)立又相互聯(lián)系,以構(gòu)成不同組合的多維度的共享教育數(shù)據(jù)模型,這4元組分別是:時(shí)間情境維度、位置情境維度、設(shè)備情境維度和事件情境維度,依次用字符表示為PT、PL、PD、PO,每一個(gè)元組是由序偶對(duì)
上述的形式化描述公式,以時(shí)間情境維度為例,
五、結(jié)? ?語
人工智能教育時(shí)代,構(gòu)建一個(gè)可重用、可共享的教育數(shù)據(jù)模型,以規(guī)范人工智能教育環(huán)境下多源異構(gòu)的教育數(shù)據(jù),實(shí)現(xiàn)各異構(gòu)數(shù)據(jù)的高度共享,是當(dāng)今時(shí)代教育發(fā)展亟需解決的問題之一。文章提出的基于多源數(shù)據(jù)融合的共享教育數(shù)據(jù)模型,通過對(duì)多源異構(gòu)教育數(shù)據(jù)進(jìn)行數(shù)據(jù)融合,結(jié)合xAPI學(xué)習(xí)數(shù)據(jù)規(guī)范,對(duì)融合后的教育數(shù)據(jù)進(jìn)行規(guī)范化描述,生成通用、標(biāo)準(zhǔn)的數(shù)據(jù)交換格式,在此基礎(chǔ)上,構(gòu)建了一個(gè)可共享、可重用的教育數(shù)據(jù)模型,實(shí)現(xiàn)了各異構(gòu)數(shù)據(jù)源之間的數(shù)據(jù)共享與交換,便于智能教育系統(tǒng)獲取更全面、完整的學(xué)習(xí)記錄數(shù)據(jù),以提升數(shù)據(jù)共享的時(shí)效性,進(jìn)而使得學(xué)習(xí)行為分析的結(jié)果更客觀、及時(shí)、準(zhǔn)確,有利于提升智能教育系統(tǒng)響應(yīng)的即時(shí)性與智能性。

- 電化教育研究的其它文章
- 區(qū)域教育大數(shù)據(jù)分析架構(gòu)與展示設(shè)計(jì)研究
- 學(xué)習(xí)幻肢與神經(jīng)全景敞視:腦機(jī)接口技術(shù)應(yīng)用于教育的主要倫理挑戰(zhàn)
- 疫情時(shí)期學(xué)生居家學(xué)習(xí)方式、學(xué)習(xí)內(nèi)容與學(xué)習(xí)模式構(gòu)建
- 理論與實(shí)踐的融合:職前教師實(shí)踐能力培養(yǎng)探尋
- 基于工作室的大學(xué)生專業(yè)實(shí)踐創(chuàng)新能力培養(yǎng)模式研究
- 信息化變革中校長(zhǎng)角色的個(gè)案研究