
基于nGram2vec與詞義演化的詞相似度計算方法
2020-05-25 02:30:57汪玉珠王永濱
軟件導刊 2020年2期
汪玉珠 王永濱


摘 要:詞相似度計算在文本分類等自然語言處理眾多任務中有廣泛應用,為了提高準確率并將其應用于文本分類任務中,提出基于知網與同義詞林以及基于nGram訓練大規模語料相結合的方法,通過詞義演化技術檢測詞義變化確定兩種方法的權重,利用皮爾遜相關系數對比人工定義詞語相似度。通過實驗將該方法與基于知網和同義詞林的方法進行對比,根據隨時間改變而詞義有無變化選取15對詞語進行測試,結果表明后者比前者提高了28%。由此可以看出,基于語料與語義詞典的方法明顯比單純基于語義詞典的方法好,但仍有較大改進空間。
關鍵詞:詞相似度;nGram2vec;同義詞林;知網;詞義演化
DOI:10. 11907/rjdk. 192354 開放科學(資源服務)標識碼(OSID):
中圖分類號:TP301文獻標識碼:A 文章編號:1672-7800(2020)002-0096-04
英標:Word Similarity Calculation Method Based on nGram2vec and Word Meaning Evolution
英作:WANG Yu-zhu1,2,WANG Yong-bin1,2
英單:(1. School of Computer and Cyberspace Securit, Communication University of China;2. Key Laboratory of Smart Fusion Media of Ministry of Education,Communication University of China,Beijing 100024,China)
Abstract: Word similarity calculation is widely used in many tasks such as text classification and natural language processing. In order to improve the accuracy and apply it in text classification tasks, this paper proposes a method which combines of HowNet and synonym forest and nGram training based on large-scale corpus. The word meaning evolution technique is used to detect the change of word meaning to determine the weight of the two methods. The Pearson correlation coefficient is used to compare the similarity of the word. The experiment compares the method based on HowNet and the same word forest and the method proposed in this paper. The experiment tests 15 pairs of words according to the change of meaning with time. The result shows that the latter is increased by 0.28 than the former. It can be seen that the method based on corpus and semantic dictionary is obviously better than the method solely based on semantic dictionary, but there is still much room for improvement.
Key Words: word similarity; nGram2vec; synonym forest; HowNet; word meaning evolution
0 引言
詞語相似度方法被廣泛應用于信息檢索、詞義消歧、機器翻譯等自然語言處理(Natural Language Processing,NLP)任務中。詞是NLP任務的最小詞義單位,詞義理解是NLP任務中最為基礎的研究,自然語言的詞語之間有很復雜的關系,而詞語相似度是對詞語間復雜關系的量化。目前,詞語相似度計算方法主要分為兩類[1-3]:①基于語義資源的方法,其根據知網等語義詞典的結構設計算法計算詞相似度,是詞相似度計算的重要依據[4-7];②基于統計的方法,其借助包含有詞的語境的大規模語料庫,根據詞間信息量或詞共現頻率計算詞語相似度[8-9],這種方法假設語義相似的詞語之間具有相似的上下文信息,比較客觀。
基于語義資源的方法,雖然經過語言專家確定,但受主觀影響大,有時不能反映客觀事實,雖然幾乎包含了所有能用到的詞,但是更新比較緩慢,而且隨著信息時代的發展,會出現很多新詞或者有的詞義發生變化,這是同義詞林和知網不能及時捕捉的。而基于語料庫的方法,可以很容易捕捉到已經發生變化的詞義(可能是部分變化也可能是完全變化)并能獲取與之相似的詞,這種方法由于語料的限制不可能統計到所有的詞,但能獲取經常用到的詞,并且能捕捉到新詞。基于此,本文提出基于nGram2vec[10]與基于同義詞林和知網相結合的方法,將它們以權重方式結合,而權重設定的主要依據是詞義演化技術得到詞義變化與詞的使用頻率。主要思路是根據這兩種方法分別求出詞相似度,然后通過詞義演化技術檢測詞義變化,以確定兩種方法的權重,考慮詞義可能完全變化、完全沒有變化、部分變化(詞義的義項增加或減少了),以及通過統計得到詞的使用頻率,通過使用頻率可以知道一些發生部分詞義變化的詞,并發現哪種詞義使用更多。
具體方法分4步:①根據朱新華等[5]基于知網和同義詞林求相似度的方法,其思路是賦予兩種方法權重,權重之和為1,如果詞在某一詞典中,則基于此詞典的方法權重為1,如果都存在,權重都為0.5,如果都不存在,則表明詞不存在,直接返回相似度為0;②采用Zhao等[10]提出的nGram2vec模型訓練詞向量,實驗表明在語義相似度方面其性能和準確性較已知的Word2vec[9]等效果更好;③通過Hamilton等[12]提出的動態詞嵌入模型訓練得到詞義演化過程,進而發現詞義變化;④通過詞義變化和詞頻共同權重最終求出詞語相似度。實驗結果表明,兩種方法結合比單獨求出的結果有很大提升,在本文對比實驗中提升了28%。
1 相關工作
基于語料庫的方法比較客觀,但依賴訓練的語料庫,受數據稀疏和噪聲影響較大,基于語義資源的方法雖然簡單有效但受主觀影響較大,且更新緩慢,不能及時展現快速變化的詞義,目前也有一些研究者將兩種方法相結合進行研究。魏韡等[13]提出有向無環圖和內在信息量相結合的方法,其主要是從量上加以考慮;蔡東風等[14]提出基于語境和知網的詞語相似度算法,通過計算詞語上下文信息的模糊重要度,對數據噪聲加以改進;詹志建等[15]提出了基于百度百科的計算方法,將其既作為語義資源又作為語料,通過基于詞典的方法和基于語料庫的常用方法空間向量模型計算相似度。通過分析,將這兩種方法結合,能在一定程度上彌補各自不足,得到與客觀實際符合程度更大的詞語相似度。提出將語義資源和語料庫與詞義演變過程相結合。通過這種方式可以從更細粒度上提升準確度,包括未被收錄的、詞義發生各種變化(詞義范圍擴大縮小、詞義色彩變化、新詞義出現舊詞義消失)的詞語,可從多方面計算詞相似度。
2 方法
2.1 基于知網
知網中最主要的概念是義原,描述概念的基本單位,一般一個義原有多種解釋,每種解釋就是一個詞義,即義項,每種詞義也有多個義原,知網描述了每個詞義多個義原間的關系,是一部非常詳盡的語義詞典。基于知網的上述優勢,部分學者進行了基于知網的詞相似度計算[16-18]。
根據文獻[5]將義項相似度計算轉換為對獨立義原集合、關系義原特征結構與關系符號義原特征結構的相似度計算,義項相似度計算如式(1)所示。
其中,參數[βi(1i3)]是可調節的,且滿足:[β1+β2+][β3=1,][β1β2β3],[βi]值按照文獻[5]設置。有的詞會有多個義項,兩個詞的最終相似度如式(2)所示。
2.2 基于同義詞詞林(詞林)
詞林參考了多部詞典,人民日報語料庫中的詞頻雖然只保留了頻度超過2的部分詞語,但能夠提供較多的同義詞語,是一部具有漢語大詞表的詞林,采用基于類構建的分層結構[19]。文獻[5]提出了一個以詞語距離[d]為主要影響因素、以分支節點數[n]和分支間隔[k]為調節參數的詞相似度計算公式,如式(3)所示。
將不屬于同一個大類的詞語間的距離都處理為18,同時按從底層到高層的順序,將連接上、下兩層的四大類邊分別賦予一個權重[Wi(1i4)],且滿足:[0.5W1W2][W3W45,W1+W2+W3+W410]。
2.3 Ngram2vec
深度學習方法已經在一系列NLP任務上取得了最新成果[20],其中最基礎的工作之一是詞嵌入,經過訓練的單詞嵌入能夠反映單詞語義和句法信息。其不僅有助于揭示詞匯語義,還可用作各種下游任務的輸入以獲得更好的性能。Word2vec以其驚人的效率而廣受歡迎。Levy等[21]進一步揭示了詞嵌入的特性,發現其并不局限于Word2vec等神經網絡模型,使用傳統基于計數的方法(PPMI矩陣和超參數調整)表示單詞,也獲得了良好效果。由于Ngram是語言建模的重要組成部分,因此Zhao等[10]受到啟發,提出了一種構建Ngram共生矩陣的新方法。該方法盡可能地減少了磁盤I/O,大大減輕了Ngrams帶來的成本,并獲得了更好的性能。他們將Ngrams引入SGNS(負抽樣的Word2vec/skip-gram),在文本相似度任務上取得了較好的效果。
2.3.1 SGNS
其輸入是原始語料[T={w1,w2,?,wT}],設[W]和[C]表示單詞與上下文詞匯,[θ]是待優化參數。SGNS的參數包括兩部分:字嵌入矩陣和上下文嵌入矩陣。嵌入[w∈Rd]時,參數總數為[(|W|+|C|)?d]。SGNS的目標函數是最大化中心詞上下文的條件概率,如式(4)所示。
其中,[C(wt)={w,t-winit+win and i≠t},win]表示窗口大小。負采樣(Negative Sampling) 用來近似表示條件概率,如式(5)所示。
其中,[σ]表示Sigmoid函數,[c1,c2,?,ck]是[k]個樣本,從上下文分布提取。
2.3.2 SGNS with nGram
其與SGNS的區別在于采用不一樣的[C(w)],如式(6)所示。
其中,[wi:i+n]表示nGram[wiwi+1...wi+n-1]N是上下文nGram順序,使用詞與nGram 遠端單詞之間的距離表示中心詞和上下文nGram之間的距離。此模型允許詞與nGram重疊,在重疊情況下,nGram用作上下文,即使包含中心詞,在非重疊情況下,這些Ngrams也被排除在外。在訓練期間,中心Ngrams(包括單詞)預測它們周圍的Ngrams,中心詞nGram預測上下文nGram,如式(7)所示。
[C(wt:t+nw)]的定義如式(8)所示。
因此,模型中詞嵌入不僅受上下文nGram的影響,而且間接受語料庫中nGram類型共現統計影響。
2.4 詞義演化
詞義隨著時代發展而不斷變化和豐富,詞義演化技術有助于更好了解詞義的演化過程,包括詞義褒貶色彩變化、新詞義出現和舊詞義消亡、詞義范圍擴大和縮小等[22],比如“粉絲”一詞之前表示一種食品,后來增加了一個義項,表示追星族。Hamilton等[12]提出了一種用于量化語義變化的方法,通過評估單詞嵌入(PPMI、SVD、SGNS即Word2vec)揭示語義演化的統計規律,文中使用6種歷史語料庫,涵蓋4種語言(中文、英語、德語、法語),跨越兩個世紀,做了大量對比試驗,最終選擇使用SGNS 嵌入,它能更好地估計頻率和語義變化之間的關系。
有兩種方法量化語義變化:①測量成對詞語相似性如何隨時間變化;②測量單個詞的嵌入如何隨時間變化。
3 實驗
3.1 數據集
nGram2vec訓練語料是百度百科,它已經收錄了近? ? 1 600萬個詞條,相比通常所用的訓練語料維基百科量級要大,幾乎涵蓋了所有已知知識領域。詞義演化部分的語料除文獻中包含1950-1990年的語料外[23],還有新聞語料[24],新聞內容跨度為2014-2016年,涵蓋了6.3萬個媒體。其中涉及1998年人民日報語料[25],它是由北京大學計算語言學研究所和富士通研究開發中心有限公司共同制作的標注語料庫,此外還包括最有可能產生新詞義的新浪微博與今日頭條,抓取數據時間段為2017-2019年。
3.2 實驗與分析
將本文方法與文獻[5]方法進行對比。實驗流程為:①將獲取的百度百科語料、微博、今日頭條數據合并用Jieba進行分詞,然后統計詞頻;②用nGram2vec訓練語料得到詞向量與詞相似度a;③獲取基于詞林和知網的詞相似度b;④用文獻[12]訓練含時間的數據得到隨時間變化的詞向量與詞間相似度;⑤根據詞頻與隨時間變化的詞向量,確定a和b的權重,計算最終詞相似度;⑥計算各種方法與本文方法的皮爾森相關系數。
測試的詞包含詞義基本未變、部分變化、完全變化、現在不怎么使用,以及新產生的詞,共選取15對詞進行測試。
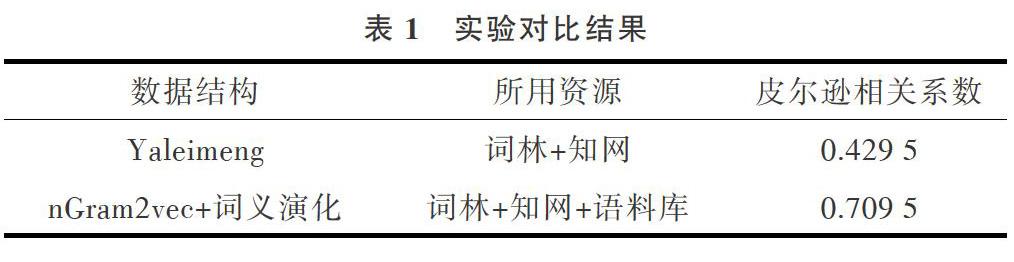
表1中的Yaleimeng[26]是實現文獻[5]的方法,其項目中用詞林+知網時得到的皮爾森系數是0.885,因為所用的測試詞的詞義基本未發生變化。在本試驗中基于詞典的方法結果僅為0.429 5,原因是詞典中很多詞的詞義都沒有,導致本該很相似的詞用此種方法計算相似度很低。Yaleimeng項目一直在更新詞庫,但是其并不統計每種詞義下的詞頻,基于詞典的方法本身默認每種詞義使用頻率相同,但事實上某些詞的詞義用得更頻繁,該特性在基于統計的模型中容易實現,這也使得本文方法在基于詞典的基礎提升了28%。
nGram2vec是一個概率模型,一句話(一個詞的上下文)出現的概率越大就越接近人類語言,相似詞在同一上下文出現的概率越相近,兩個詞的詞義就越相似,這一點彌補了上文提到的基于詞典的缺陷。在現代信息環境下,詞義變化基本上都能在互聯網中被發現,nGram2vec模型就很容易捕捉到,但知網等語義詞典不具備上述功能。
詞義演化模型將兩者優勢結合起來,可以檢測出變化詞義的詞,如果詞義未發生變化,則直接賦予基于詞典計算出的相似度權重為1,如果詞義完全變化或者是新產生的詞,其權重為0。但本實驗結果顯示皮爾遜相關系數并不太高,因為本文方法只是通過權重將兩種方法結合在一起,還有很多改進之處。
4 結語
本文通過詞義演化技術計算詞義變化,并結合基于語義資源和語料庫的方法計算詞語相似度,充分利用了語義資源在絕大部分詞義方面的專業性,彌補了語料庫中很多非常用詞的缺陷,充分利用基于語料庫的方法計算新詞、詞義有變化詞的詞義相似度,得到了更為準確與合理的結果。本實驗將兩大類方法通過權重方式相結合,權重由詞義變化和詞的各詞義使用頻率確定,但是融合得不夠完美,使模型看起來不太堅固。未來將使用仍在改進且已經被應用于各NLP任務中的貝葉斯,將語義資源作為先驗知識嵌入到基于語料庫的方法中,這樣可以使模型更堅固,并且更符合人類的貝葉斯理論思維習慣。
參考文獻:
[1] 李慧. 詞語相似度算法研究綜述[J]. 現代情報,2015,35(4):172-177.
[2] 劉萍,陳燁. 詞匯相似度研究進展綜述[J]. 現代圖書情報技術,2012,28(7):82-89.
[3] 韓普,王東波,王子敏. 詞匯相似度計算和相似詞挖掘研究進展[J]. 情報科學,2016,34(9):161-165.
[4] 劉群,李素建. 基于《知網》的詞匯語義相似度計算[J]. 中文計算語言學,2002.
[5] 朱新華,馬潤聰,孫柳,等. 基于知網與詞林的詞語語義相似度計算[J]. 中文信息學報,2016, 30(4).
[6] 呂立輝,梁維薇,冉蜀陽. 基于詞林的詞語相似度的度量[J]. 現代計算機(下半月版),2013(1):3-6.
[7] 吳思穎,吳揚揚. 基于中文WordNet的中英文詞語相似度計算[J]. 鄭州大學學報(理學版), 2010, 42(2):66-69.
[8] 呂亞偉,李芳,戴龍龍. 基于LDA的中文詞語相似度計算[J]. 北京化工大學學報(自然科學版), 2016,43(5):79-83.
[9] MIKOLOV,TOMAS.Efficient estimation of word representations in vector space[DB/OL].? https://arxiv.org/abs/1301.3781,2013.
[10] ZHAO Z, LIU T, LI S,et al.Ngram2vec: learning improved word representations from ngram co-occurrence statistics[C].? Conference on Empirical Methods in Natural Language Processing,2017.
[11] PETERS M E,NEUMANN M,IYYER M,et al. Deep contextualized word representations[DB/OL]. https://arxiv.org/abs/1802.05365,2018.
[12] HAMILTON W L,LESKOVEC J,JURAFSKY D. Diachronic word embeddings reveal statistical laws of semantic change[C]. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics,2016.
[13] 魏韡,向陽,陳千. 計算術語間語義相似度的混合方法[J]. 計算機應用, 2010,30(6):1668-1670.
[14] 蔡東風,白宇,于水,等. 一種基于語境的詞語相似度計算方法[J]. 中文信息學報, 2010,24(3):24-29.
[15] 詹志建,梁麗娜,楊小平. 基于百度百科的詞語相似度計算[J]. 計算機科學, 2013,40(6):199-202.
[16] 朱征宇,孫俊華. 改進的基于《知網》的詞匯語義相似度計算[J]. 計算機應用,2013,33(8):2276-2279.
[17] 朱新華,郭小華,鄧涵. 基于抽象概念的知網詞語相似度計算[J]. 計算機工程與設計,2017(3):664-670.
[18] 張波,陳宏朝,朱新華,等. 基于多重繼承與信息內容的知網詞語相似度計算[J]. 計算機應用研究,2018,35(10):101-105.
[19] 彭琦,朱新華,陳意山,等. 基于信息內容的詞林詞語相似度計算[J]. 計算機應用研究, 2018(2):400-404.
[20] HEATON,J. Ian goodfellow, yoshua bengio,and aaron courville: deep learning[J]. Genetic Programmingand Evolvable Machines, 2017:s10710-017-9314-z.
[21] LEVY, OMER, YOAV GOLDBERG, IDO DAGAN. Improving distributional similarity with lessons learned from word embeddings[J]. Transactions of the Association for Computational Linguistics,2015(3):211-225.
[22] 王洪俊,施水才,俞士汶,等. 詞義演化的計算方法[J]. 廣西師范大學學報(自然科學版),2006,24(4):183-186.
[23] YAO Z,SUN Y,DING W,et al. Dynamic word embeddings for evolving semantic discovery[DB/OL]. https://arxiv.org/abs/1703.00607,2017.
[24] Large scale chinese corpus for NLP[EB/OL]. https://github.com/brightmart/nlp_chinese_corpus.
[25] PeopleDaily1998[EB/OL]. https://github.com/chenhui-bupt/PeopleDaily,1998.
[26] Final_word_Similarity[EB/OL]. https://github.com/yaleimeng/Final_ word_Similarity.
(責任編輯:孫 娟)
