
經典人工智能算法綜述
2020-05-28 09:36:21陶陽明
軟件導刊 2020年3期
關鍵詞:深度學習

摘 要:人工智能算法繁多,但經得起實踐考驗的經典算法有限,常見的有樸素貝葉斯、決策樹、邏輯回歸、支持向量機、深度學習、強化學習、遺傳算法、蟻群算法、元學習等。依據人工智能算法理論基礎知識,如概率統計、集合論、空間幾何、圖論、矩陣論等加以分類,并對相應經典人工智能算法概念和主要應用領域進行概述,去除結構細化和公式展開所帶來的復雜感,揭開人工智能的神秘面紗,讓算法整體輪廓得以更清晰地呈現。
關鍵詞:人工智能算法;樸素貝葉斯;邏輯回歸;深度學習;遺傳算法
DOI:10. 11907/rjdk. 191702
中圖分類號:TP3-0 ?? 文獻標識碼:A??????????????? 文章編號:1672-7800(2020)003-0276-05
Overview of Classical Artificial Intelligence Algorithms
TAO Yang-ming
(School of Computer and Information Engineering, Nanning Normal University, Nanning 530023,China)
Abstract: The artificial intelligence algorithm has a great variety. However, the classical algorithms that can withstand practice and test are actually limited. At present, classical artificial intelligence algorithms include naive Bayes, decision tree, logistic regression, support vector machine, deep learning, reinforcement learning, genetic algorithm, ant colony algorithm, and meta-learning. The paper classifies the main theoretical basic knowledge of artificial intelligence algorithm such as mathematical probability and statistics, set theory, space geometry, graph theory, matrix theory, etc, and summarizes the classical artificial intelligence algorithm concept and main application fields of corresponding classification, and removes the structure. The refinement and formula unfolding brings a sense of complexity to beginners, uncovering the mystery of artificial intelligence, and allowing beginners to have a clear understanding of the overall outline of the algorithm.
Key Words: artificial intelligence algorithm; naive Bayes; logistic regression; deep learning; genetic algorithm
0 引言
人工智能算法起步于20世紀50年代,經過不斷發展,其種類已頗為繁多,然而經得起實踐考驗的經典算法仍很有限。目前,有依據算法結構分類的,如迭代、遞歸、貪心算法、動態策劃、分治策略等;有依據應用分類的,如回歸算法、分類算法、模式識別算法等;還有一些并沒有嚴格分類,只是就幾種大型方法進行總結和算法展開。人工智能算法通常比較復雜,依據上述分類基本上會面臨結構細化、公式代入、各種引用等,這些內容一經展開無疑十分龐雜。實際上,每種人工智能算法所依據的概念很簡單,而且很多經典庫如Python中的Gensim、TensorFlow、Scikit-Learn等都對一些常用的人工智能算法進行了封裝,初學者可在了解算法基本概念后直接對這些封裝的庫進行使用和實驗。值得注意的是,就應用而言,本文可以幫助初學者迅速理解算法精要并使用現有算法庫;就研究而言,想要創新算法乃至開發自己獨有的算法,結構細化和公式的深入理解必不可少。
1 基于集合論分類
集合論是數學學科的根基,初等數學方法有加減乘除等各種運算、映射、函數、導數等概念,高等數學有極限、積分、微分、級數等概念。基于集合論的經典人工智能算法有K-means(K均值算法)、k-NN(k近鄰算法)、Apriori算法等。
1.1 K-means算法
K-means(K均值算法)[1]是非監督學習中的經典聚類算法,主要基于“物以類聚,人以群分”概念,將未標注的樣本數據中的相似部分聚集為同一類。實現流程為:①隨機選取k個對象作為初始聚類中心;②計算每個對象與各聚類中心的距離,并將每個對象分給距離它最近的聚類中心;③重新計算聚類中心,然后重復②,直至滿足終止條件,終止條件可以為沒有對象再分給聚類中心,也可以為聚類中心的誤差平方和局部最小等。
極大似然估計在規律分布數據集中表現良好,對于含隱藏變量的數據集表現較差。鑒于此,最大期望值算法在極大似然估計中加入隱藏變量,實現步驟是:①利用隱藏變量計算出初始期望值;②使用期望值對模型進行最大似然估計;③使用②得到參數代入①重新計算期望值,重復②,直至得到最大期望值。
最大期望值算法主要運用于參數求解和優化,尤其是在機器學習領域有廣泛應用。
2.6 PageRank算法
PageRank算法[9]是Google專有算法,也稱網頁排名或佩奇算法。PageRank的理念十分簡單,即如果一個頁面被越多的其它網頁引用,其等級也越高;如果一個等級高的頁面引用了一個等級低的頁面,則該等級低的頁面等級會有所提升。
PageRank算法主要應用于網頁排名。
3 基于圖論分類
圖分為有向圖、無向圖、帶權圖、連通圖、平面圖等傳統圖結構,以及歐拉圖和哈密頓圖等一些特殊結構的圖。樹結構也是圖的一種,可以視為非連通圖。基于圖論的人工智能算法有決策樹、Adaboost、Bagging等。
3.1 決策樹
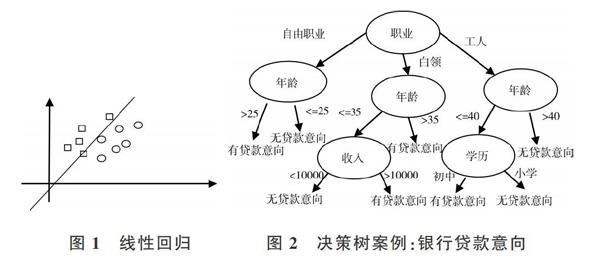
決策樹(Decision Tree)[10]是和樸素貝葉斯一樣的經典且使用廣泛的分類算法,最初使用ID3算法生成決策樹,后來在ID3的基礎上延伸出C4.5算法和CART算法。決策樹的構造步驟非常簡單:①生成整體決策樹框架;②修剪決策樹。相關案例如圖2所示。
決策樹主要應用于分類,基本上樸素貝葉斯能運用的領域,決策樹也能,如文本分類、新聞分類、病人分類等。
3.2 隨機森林
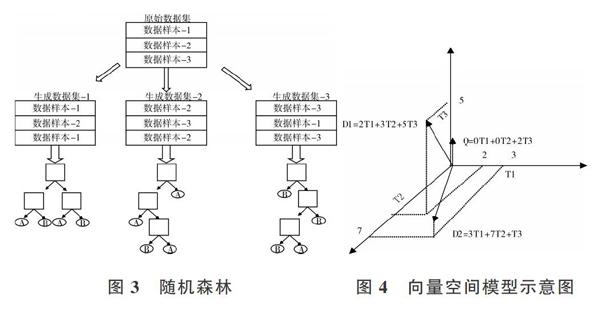
隨機森林(RandomForest)[11]由多個決策樹構成,決策樹是對整個數據集進行構建,而隨機森林先利用Bagging方法在初始數據集進行隨機抽樣并生成多個子數據集后,再分別對子數據集進行決策樹構建。需要注意的是,子數據集的數據量必須與初始數據集的數據量相同,如圖3所示。
隨機森林主要解決決策樹泛化能力弱的缺點,可以理解為“三個臭皮匠頂個諸葛亮”的概念,與決策樹一樣,主要應用領域是分類。
4 基于空間幾何分類
空間集合的概念主要是維度,如一維的線條、二維的平面、三維的立體空間、四維及以上的超空間等;再者是向量,通過向量之間的計算可以快速計算出樣本特征各種聯系、提取關鍵特征等。基于空間幾何的人工智能算法有支持向量機、空間向量模型等。
4.1 支持向量機
支持向量機(Support Vector Machines,SVM)[12]主要有3類:線性可分SVM,線性不可分SVM和非線性SVM。線性可分SVM指在二維平面內可以用一條線清晰分開兩個數據集;線性不可分SVM指在二維平面內用一條線分開兩個數據集時會出現誤判點;非線性SVM指用一條線分開兩個數據集時會出現大量誤判點,此時需要采取非線性映射將二維平面擴展為三維立體,然后尋找一個平面清晰的切開數據集。
在實際應用中,SVM不僅用于二分類,也可用于多分類。SVM在垃圾郵件處理、圖像特征提取及分類、空氣質量預測等多方面領域都有應用。
4.2 向量空間模型
向量空間模型(Vector Space Model,VSM)[13]主要應用于自然語言處理領域的文本特征提取,如圖4所示。
有3個文檔D1、D2、Q,D1和D2均含T1、T2、T3特征項,Q只含T2特征項,特征項可以理解為對文檔抽取的關鍵詞。D1=2T1+3T2+5T3的(2,3,5)表示T1、T2、T3在文檔D1中的權重,同理(3,7,1)表示T1、T2、T3在文檔D2中的權重。如果要計算D1和D2相似度,則直接計算(2,3,5)和(3,7,1)的余弦值即可。
5 基于交叉學科分類
目前,很多人工智能算法是基于交叉學科的,如通過模擬人類神經網絡的深度學習算法、基于“物競天擇適者生存”進化論概念的遺傳算法、通過觀察蟻群活動而產生的蟻群算法等。
5.1 深度學習(神經網絡)
深度學習的“深度”二字源于神經網絡隱藏層的層數可以人為增加,即整個算法的長度會不斷增加。神經網絡算法近幾年給整個計算機領域帶來了革新,同時也影響了其它學科,甚至對整個社會也產生了深遠影響。
神經網絡算法總給人一種神秘莫測的感覺,讓人望而生畏,其實神經網絡本質很簡單,大概經歷了3個階段:①簡易線性前向傳播,此時的神經網絡有另外一個名字叫“多層感知機”[14],神經元的運算本質即為簡單的矩陣相乘而已;②非線性反向傳播,就是在多層感知機的基礎上加入偏置和激活函數讓線性轉化為非線性,利用損失函數和梯度下降算法轉變前向傳播為反向傳播,通過反向傳播不斷改進參數最終使損失函數值達到預期,第二階段后期又出現多種優化算法如學習率可以改變梯度下降算法的幅度、正則化解決過擬合問題、滑動平均算法使模型更健壯等,第二階段的神經網絡稱為“人工神經網絡”[15]或者“全連接網絡”;③神經網絡進化階段,在人工神經網絡的基礎上衍生出能夠權值共享的卷積神經網絡(CNN)[16]、解決序列問題的循環神經網絡(RNN)[17]、在RNN上改進的LSTM以及其它一些遞歸神經網絡、生成式對抗網絡(GAN)、脈沖神經網絡(SNN)等,同時也衍生出一些基于神經網絡的經典模型如bi-LSTM、bert模型等。
神經網絡目前已經得到了廣泛應用,人臉識別、機器翻譯、文本分類、無人駕駛等。神經網絡在應用領域幾乎是萬能的,以至于好多科研人員已經得出“神經網絡之后再無智能算法”的結論。
雖然神經網絡算法如此強大,但目前仍有兩大問題無法解決:一是可以使用神經網絡得出想要的結果,但為何會得出這樣的結果始終無法破解,現在還沒有這方面的理論能夠說服大家,也即神經網絡的內部是個黑盒,能夠拿來用并且得出不錯的結果,可是“知其然不知其所以然”;二是神經網絡根基的反向傳播算法目前都受到質疑,尤其作為神經網絡之父的Hinton設計了Capsule算法代替反向傳播算法,之后又有研究者提出離散優化等方法取代反向傳播算法。
5.2 遺傳算法
遺傳算法[18]是模擬人類和生物的遺傳—進化機制,主要基于達爾文的生物進化論:物競天擇、適者生存和優勝劣汰。具體實現流程是:①從初代群體里選出比較適應環境且表現良好的個體;②利用遺傳算子對篩選后的個體進行組合交叉和變異,然后生成第二代群體;③從第二代群體中選出環境適應度良好的個體進行組合交叉和變異形成第三代群體,如此不斷進化,直至產生末代種群即問題的近似最優解。
遺傳算法通常應用于路徑搜索問題,如迷宮尋路問題、8字碼問題等。
5.3 蟻群算法
蟻群算法[19]的靈感來源于觀察螞蟻集體覓食行為的現象,單個螞蟻在覓食過程中會在路徑中遺留下“信息素”,螞蟻都具備判別“信息素”濃度的本能,如果在某條路徑上有高濃度的“信息素”即可判定為該路徑是最佳覓食路徑。實現流程同樣類似:①初始化參數,構建整體路徑框架;②隨機將預先設定好的螞蟻數量放置在不同的出發點,記錄每個螞蟻走的路徑,并在路徑中釋放信息素;③更新信息素濃度,判定是否達到最大迭代次數,若否,重復第二步,若是則結束程序,輸出信息濃度最大的路徑即為獲取的最佳路徑。
蟻群算法和遺傳算法類似,主要用于尋找最佳路徑,尤其在旅行商問題(TSP)上被廣泛采納。
5.4 退火算法
退火的概念來源于物理學科熱力學,指要得到固體的理想有序結晶狀態,需要先加溫加快固體內部的分子運動,再緩慢降溫降低分子運動,直至得到規則有序的結晶狀態;不可快速降溫,過快的降溫是無法得到理想結晶狀態的。如圖5所示。
退火算法(Simulated Annealing)[20]和爬山算法(Hill Climbing )有些類似,都屬于貪心算法。爬山算法的缺點是只能得到局部最優解,退火算法由于加入了隨機因素,所以在找到局部最優解后會跳出來繼續尋找,直至找到全局最優解。
退火算法在尋找最優解中被廣泛使用,如優化車間調度流程、旅行商問題等。
5.5 強化學習、遷移學習和元學習
強化學習(Reinforcement Learning)[21],也叫評價學習或再勵學習。強化學習的算法概念基于心理學的行為主義理論,即在一定環境中給有機體獎勵或者懲罰,能夠刺激有機體養成利益最大化的慣性行為。強化學習本質上是一種算法思想,需要同其它算法結合使用,比如結合神經網絡算法。
遷移學習(Transfer Learning)[22]的本質可以濃縮為“舉一反三”,此概念可以追溯到1901年的心理學家桑代克和伍德沃思,主要思想是將某個領域獲取的經驗、知識遷移到另外一個領域的學習中。需要注意的是,遷移學習和預訓練方法有本質不同,遷移學習針對的是兩個不同的數據集,預訓練方法是在原有數據集的基礎上添加新數據。
元學習(Meta Learning),也稱之為學會學習(Learning to Learn)。元學習的概念很簡單,就是利用以往學過的知識和經驗能夠自主學習并培養出新技能。由于傳統機器學習都需要靠給機器喂大量的數據才能讓機器具備一定的智能,因此元學習概念的提出是革命性的。目前,元學習相關研究處于“百家爭鳴”的狀態,有基于記憶方法、基于預測梯度方法、基于注意力機制等。
6 常見特征提取及優化方法
現實生活中的文本、圖像、語音等需要被轉化為二進制數據才能被計算機識別,因此需要對這些原始材料進行數據轉化,該過程被稱為特征提取。特征提取方法層出不窮,在特征提取過程中,涌現出了很多優化方法,使得特征提取更快、更有效。
6.1 特征提取方法
提取圖像特征最常用的方法就是二維矩陣轉化,很多工具都可以方便實現,如MATLAB、Numpy等。灰度圖片被提取為一個通道的二維矩陣,彩色圖片被提取為3個通道(RGB)的二維矩陣。
提取文本的方法非常多樣化,有基于統計方法的詞集模型和詞袋模型,有基于獨熱編碼的獨熱模型,有基于熵概念的信息增益方法,有基于神經網絡的詞向量模型等。目前,詞向量模型效果最好,基本上自然語言處理領域具備一定智能的模型或者系統都繞不開詞向量模型。
6.2 優化方法
通過特征提取方法得到的數據集經常會面臨一些問題,比如維度過大、特征稀疏且分散等。因此,需要一些優化方法對得到的數據集進行優化,用于降維的常用方法有奇異值分解(SVD)和主成分分析(PCA),常用的關鍵特征提取方法有注意力機制等。
7 結語
本文對經典人工智能算法進行了概述,并介紹了每種算法的應用領域和實際應用案例。人工智能算法所基于的理念和概念其實非常簡單,但要實現這些理念和概念就繞不開繁瑣的數學公式和復雜的算法結構。本文簡明扼要地直擊每種算法的要義,去除繁瑣的公式和復雜的算法結構設計,讓初學者快速把握算法整體輪廓,并且在最短時間內通過MATLAB、Gensim、Scikit-Learn等庫直接對實際案例進行操作。最后,介紹了數據集的特征提取和優化方法,讓初學者對人工智能算法的數據集來源有最基本的認識。
參考文獻:
[1]KANUNGO T, MOUNT D M, NETANYAHU N S, et al. An efficient K-means clustering algorithm:analysis and implementation[J].? IEEE Transactions on Pattern Analysis & Machine Intelligence,2002,24(7):881-892.
[2]ZOUHAL L M, DENOEUX T. An evidence-theoretic k-NN rule with parameter optimization[J].? IEEE Transactions on Systems Man & Cybernetics Part C Applications & Reviews,1998,28(2):263-271.
[3]陸麗娜,陳亞萍,魏恒義,等. 挖掘關聯規則中Apriori算法的研究[J]. 小型微型計算機系統, 2000,21(9):940-943.
[4]王國才. 樸素貝葉斯分類器的研究與應用[D]. 重慶:重慶交通大學,2010.
[5]李榮陸,王建會,陳曉云,等. 使用最大熵模型進行中文文本分類[J]. 計算機研究與發展,2005,42(1):94-101.
[6]杜世平. 隱馬爾可夫模型的原理及其應用[D]. 成都:四川大學, 2004.
[7]魏大成,周賢剛. 影響綜合康復治療神經根型頸椎病療效的危險因素邏輯回歸分析[J]. 中國康復醫學雜志,2009,24(9):807-809.
[8]基于極大似然準則和最大期望算法的自適應UKF算法[J]. 自動化學報,2012,38(7):1200-1210.
[9]李稚楹,楊武,謝治軍. PageRank算法研究綜述[J]. 計算機科學, 2011(b10):185-188.
[10]楊靜,張楠男,李建,等. 決策樹算法的研究與應用[J]. 計算機技術與發展, 2010,20(2):114-116.
[11]隨機森林算法優化研究[D]. 北京:首都經濟貿易大學, 2014.
[12]丁世飛,齊丙娟,譚紅艷. 支持向量機理論與算法研究綜述[J].? 電子科技大學學報, 2011, 40(1):2-10.
[13]姚清耘. 基于向量空間模型的中文文本聚類方法的研究[D]. 上海:上海交通大學,2008.
[14]王之倉. 多層感知器學習算法研究[D]. 蘇州:蘇州大學,2006.
[15]朱大奇. 人工神經網絡研究現狀及其展望[J]. 江南大學學報, 2004,3(1):103-110.
[16]卷積神經網絡研究綜述[J]. 計算機學報,2017,40(6):1229-1251.
[17]朱小燕,王昱,徐偉. 基于循環神經網絡的語音識別模型[J]. 計算機學報,2001,24(2):213-218.
[18]丁建立,陳增強,袁著祉.? 遺傳算法與螞蟻算法的融合[J]. 計算機研究與發展,2003,40(9):1351-1356.
[19]段海濱,王道波,朱家強,等. 蟻群算法理論及應用研究的進展[J]. 控制與決策,2004,19(12):1321-1326.
[20]模擬退火算法的研究及其應用[D]. 昆明:昆明理工大學,2005.
[21]高陽,陳世福,陸鑫. 強化學習研究綜述[J]. 自動化學報,2004,30(1):86-100.
[22]莊福振,羅平,何清,等. 遷移學習研究進展[J]. 軟件學報,2015,26(1):26-39.
(責任編輯:孫 娟)
收稿日期:2019-05-14
基金項目:國家自然科學基金項目(61650102);廣西自然科學基金項目(2018GXNSFBA281086);廣西高校中青年教師基礎能力提升項目(KY2016YB278);廣西高校科學計算與智能信息處理重點實驗室開放項目(GXSCIIP201603)
作者簡介:陶陽明(1987-),男,南寧師范大學計算機與信息工程學院碩士研究生,研究方向為人工智能自主學習算法設計。
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
