基于GWO-LSTM的網約車需求短時預測模型
2020-06-04 03:56:00許倫輝郭雅婷
自動化與儀表 2020年5期
許倫輝,郭雅婷
(華南理工大學 土木與交通學院,廣州510641)
網約車服務,指以互聯網技術構建服務平臺,整合供需,通過移動設備與應用連接出行乘客與車輛和駕駛員的服務[1]。2018年,我國主要城市的網約車應用總滲透率高達11%[2]。海量的網約車數據,為出租車供需研究提供了新思路,也為新形勢下提高差異化出行的供需匹配效率提供了研究基礎[3]。
1 網約車需求分析
1.1 網約車供需研究現狀
從供需平衡角度,出租車供需研究分供給預測、需求預測與供需缺口預測三類。
1)供給預測 常采用經典的供需函數關系開展宏觀研究。
2)供需缺口預測 適用于區域內供不應求的情況,如文獻[4]基于時空數據挖掘的深度學習網約車需求預測模型。
3)需求預測 與交通流預測類似,即網約車出行需求的時空狀態分布預測,分為模型驅動、數據驅動兩類。其中,模型驅動主要通過建立交通各項參數間的數學模型以實現交通流預測[5];數據驅動即機器學習,通過對大數據進行智能計算以挖掘數據的隱含信息。文獻[6]提出單個、組合及提升等多種決策樹算法進行網約車數據的短時需求預測;文獻[7]用LASSO(least absolute shrinkage and selection operator)進行數據特征排序,建立基于隨機數森林算法的預測模型;文獻[8]以紐約市出租車數據為基礎,提出長短期記憶神經網絡LSTM 的出租車需求模型。然而,傳統LSTM 在網絡參數尋優中采用反向傳播BPTT(back propagation through time)算法,復雜度高且存在易收斂于局部最優解。故在此,針對上述缺陷,提出了采用收斂速度快、全局搜索能力強的灰狼優化算法對長短期記憶網絡進行參數優化,建立GWO-LSTM 網約車出行需求短時預測模型進行改進。
為把握乘客出行需求特性,以滴滴出行2016年1月份M 市的訂單數據作為研究對象,進行數據分析。該數據含30 d日均40 萬條的訂單量、66 個出行區域、各區域內信息點PoI(point of information)類別及數量、道路擁堵程度與天氣狀況等。通過對超出定義時空范圍內數據進行刪除,短時間內重復訂單數據識別與剔除、噪聲平均化填充等操作進行數據清洗。對出行數據進行區域匹配、15 min 時間分片的短時需求量統計。
1.2 網約車需求時變規律
在工作日與非工作日,居民對網約車需求的時變規律如圖1所示,圖中將一天24 h 分為0~95 共96 個時間段,每個時段15 min。在工作日,居民對于網約車的出行需求趨勢與城市交通早晚高峰一致。7:30—9:30 為早高峰,需求量最大;17:00—19:00為晚高峰。其中周一和周五較其他工作日需求量要大。周末白天無明顯早高峰,總體變化平穩;人們傾向于下午至夜間出行,總需求量與工作日相差不大。

圖1 工作日與非工作日網約車需求時變圖Fig.1 Time-varying graph of demand for network booking taxi on weekdays and non weekdays
1.3 網約車需求區域分布規律
網約車需求的區域分布與土地利用類型相關,土地利用情況主要反映在POI 數量及類型上。通過對比分析各區域數據,主要變化類型如圖2所示。
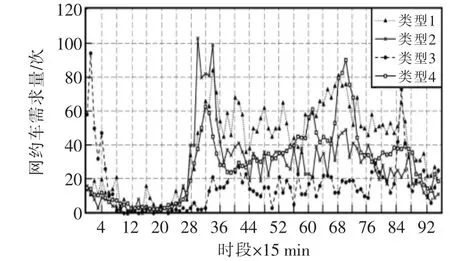
圖2 典型區域網約車需求時變圖Fig.2 Time-varying graph of demand for network booking taxi in typical regions
圖中,類型1 為商住混用型,該類區域早高峰與晚高峰對于網約車需求量較大且數量相當;類型2 為以居住用地為主的典型區域,網約車需求以通勤出行為主,需求數劇增;類型3 主要為休閑娛樂類服務場所用地,以夜間需求為主;類型4 主要為商務用地,相較于其它區域,晚高峰的網約車需求量較大。
1.4 影響因素相關性分析
網約車需求量受時間、空間、交通擁堵狀況、天氣、溫度與污染指數等外部因素的影響。選用spearman 相關系數進行分析,即
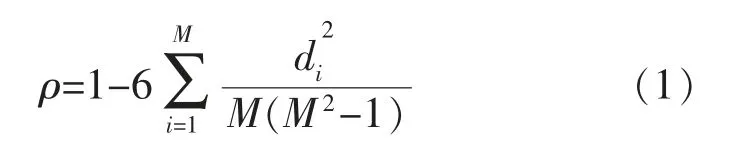
相關性分析結果見表1。
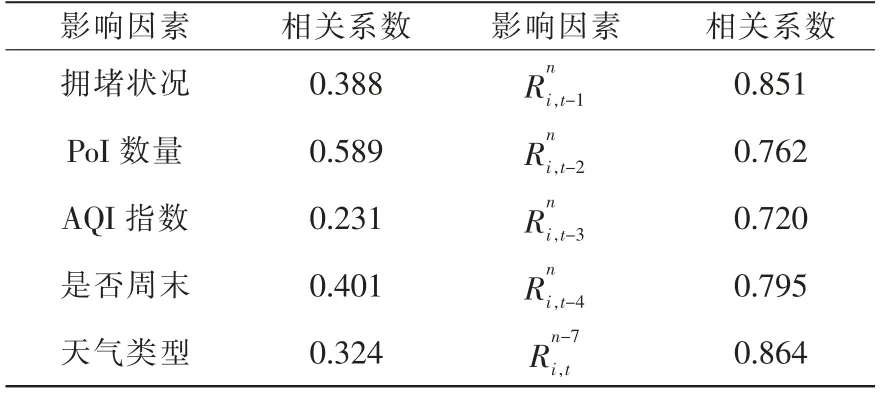
表1 網約車需求的影響因素相關性分析Tab.1 Correlation analysis of influencing factors of demand for network booking taxi
2 網約車需求短時預測模型
2.1 長短期記憶神經網絡
循環神經網絡RNN(recurrent neural networ)是以序列數據為輸入,在序列的演進方向進行遞歸且所有循環單元按鏈式連接的遞歸神經網絡[9]。基于RNN 進行改進,通過引入靈活可控的自循環設計,LSTM 產生了讓梯度能夠可持續長期流動的途徑,可從輸入的歷史數據中學習長時間的計算記憶信息。
LSTM 內部結構如圖3所示,遺忘門ft,輸入門it,記憶單元ct和輸出門ot組成了LSTM 的內部結構,其中σ 為激活函數sigmoid。
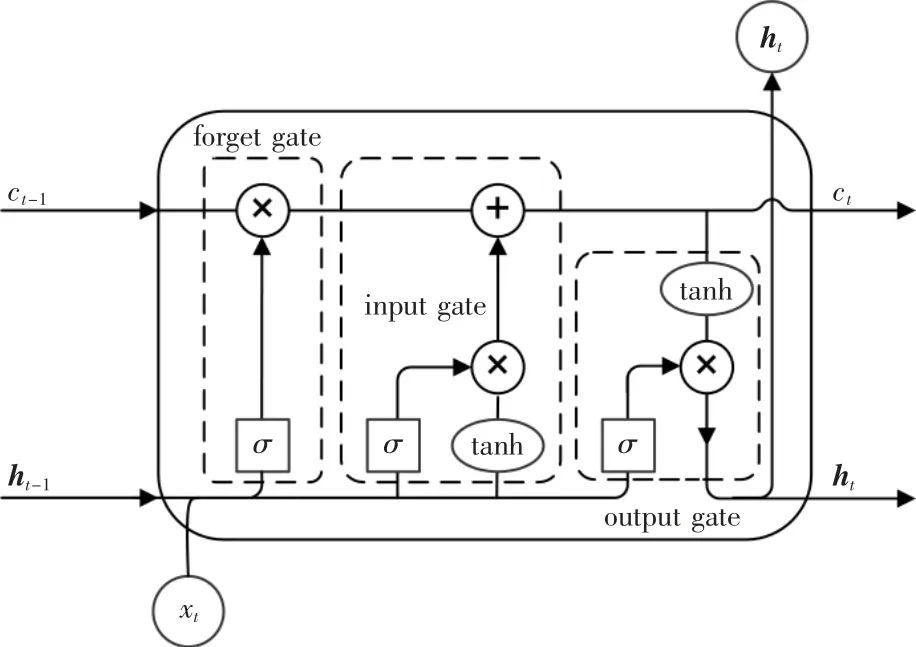
圖3 LSTM 內部結構Fig.3 LSTM internal structure
具體計算如下:
遺忘門ft決定保留或丟棄歷史信息,輸出區間為[0,1],其中1 表示保留,0 表示全部丟棄。ft為
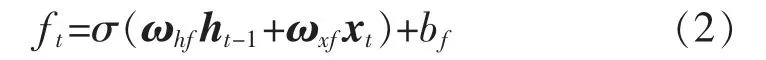
輸入門it添加當前時刻有效輸入,決定了xt添加到信息流中的程度,sigmoid 函數部分決定需輸入的值。tanh 函數部分創建臨時狀態ct′為
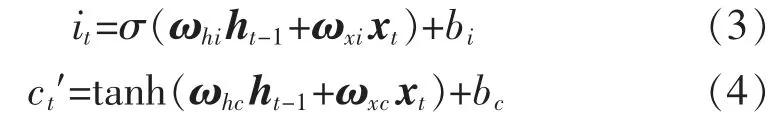
記憶單元ct更新網絡細胞狀態:

輸出門ot控制可用于下一層網絡更新而輸出的信息:
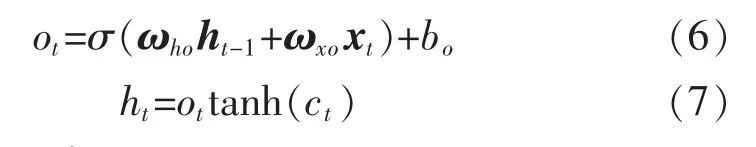
式(2)~式(7)中:ωhf,ωxf,bf,ωhi,ωxi,bi,ωhc,ωxc,bc,ωho,ωxo,bo分別為門限單元中相應下標的權重矩陣和偏置量。標準LSTM 采用式(2)~式(7)進行計算得到模型輸出數據,并利用基于時間的BPTT 算法訓練以求解上述參數。但在試驗過程中,BPTT 算法常收斂于局部最優解,且計算復雜度較高。
2.2 灰狼優化算法
灰狼優化算法根據灰狼群體協作機制,模擬灰狼捕食獵物以實現目標,具有較強的收斂性、參數少、易實現,且能收斂于全局最優解[10]。在一定數量的群體中,按照職責分工,灰狼被分為α,β,δ 及ω共4 個等級。α 是唯一的領導者,負責群體決策;β級狼輔助領導者管理狼群,也是領導者替補;δ 服從α 與β 的命令,負責偵察、捕獵及看護等;最底層ω服從上級安排并維系種族平衡。
GWO 優化的算法步驟包括尋找、跟蹤、包圍、狩獵以及攻擊獵物等。圍獵時,群體中每一只狼即為潛在解,按照等級,α,β,δ,ω 優先級依次遞減。其他個體根據前三只狼的位置,計算與其距離,并不斷靠近更新位置以完成尋優。在Q 維空間中,各個體Wi=(wi,1,wi,2,…,wi,q)組成狼群Wi={W1,W2,…,WN}。有
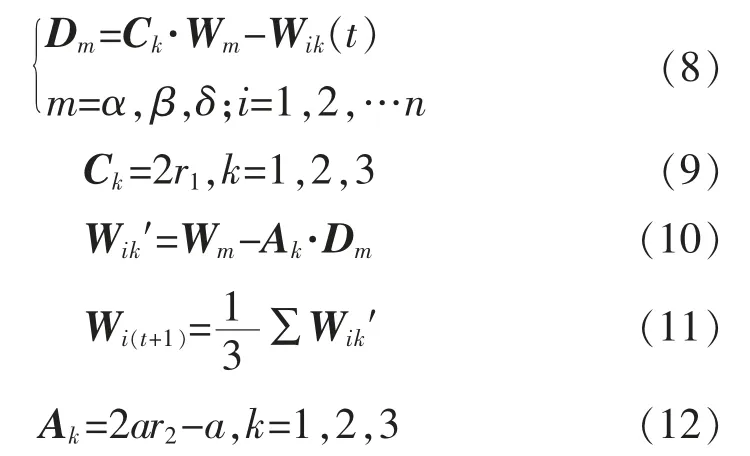
其中
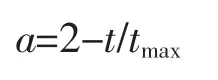
式中:Dm為灰狼Wi在第t 次迭代時分別距離α,β,δ狼的位置;Ck,Ak為系數向量;r1,r2均為[0,1]的隨機取值;Wik′為灰狼向α,β,δ 靠近時移動的矢量;Wi(t+1)為向3 只高等級灰狼移動的矢量的平均值,得到灰狼Wi下一次迭代的移動值;a 為收斂因子,隨迭代次數t 的增加線性減小,取a 值范圍[0,2]。
2.3 GWO-LSTM 網約車需求預測模型
基于GWO-LSTM 的網約車需求預測流程如圖4所示,該預測模型由數據處理、參數優化、網絡訓練與數據預測四大部分構成。參數優化部分采用GWO 算法優化LSTM 網絡中的參數,使模型得出的預測值最大限度逼近真實值。為得到最小目標函數,適應度函數設為
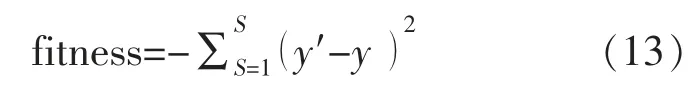
式中:y′為實測數據;y 為模型輸出;S 為訓練長度。

圖4 基于GWO-LSTM 的網約車需求預測流程Fig.4 Flow chart of forecasting demand for network booking taxi based on GWO-LSTM
訓練數據時,先確定LSTM 中輸入層的歷史數據步長lookback、隱藏層單元個數hidden 及預測步長predstep;確定GWO 的迭代次數、維度以及灰狼個數。通過隨機分布函數,對灰狼位置進行種群初始化,并分解為LSTM 網絡所求的權重矩陣與偏置值等未知參數。將參數代入網絡中計算相應的輸出值y 并根據式(13)計算各個體的適應度值。對比適應度值,標記其中適應度最佳的前3 個體位置為Wα,Wβ,Wδ。當迭代次數不斷迭加,由計算式(8)~式(12)更新每一個體的位置,并多次計算適應度值,直至迭代結束。返回全局最佳的Wα即為LSTM 記憶網絡參數最優解。最終,將測試數據輸入到最優參數解的訓練網絡中,得到預測結果,將均方根誤差RMSE(root mean square error)與平均絕對誤差MAE(mean absolute error)作為模型評估指標。其計算如下:
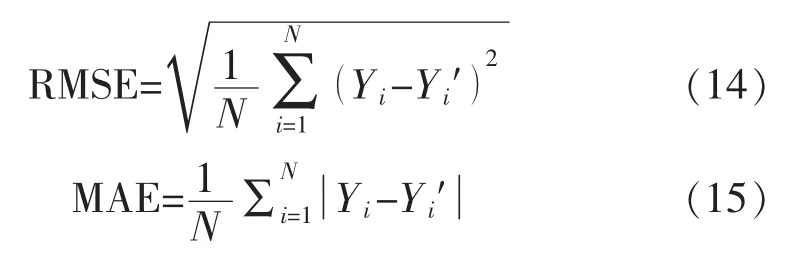
式中:Yi′為測試集實測數據;Yi為預測數據。
3 算例分析
3.1 網約車需求量數據處理
試驗仍以滴滴平臺M 市2016年1月份的訂單數據為例,70%為訓練數據,30%用作預測。通過初步數據分析,區域劃分、時間分片得網約車需求量時間序列。采用spearman 相關系數法對網約車需求量的影響因素進行相關性分析,選定PoI 數量與5個歷史時間段數據為輸入指標,并采用min-max 標準化方法對數據進行歸一化處理,即

3.2 試驗對比模型及平臺搭建
對比預測模型為標準LSTM 和BPNN。標準LSTM 通過BPTT 算法尋找最優參數解,而本文模型采用灰狼優化算法尋找最優參數。BP 神經網絡為多層前饋神經網絡,在網絡訓練過程中以誤差逆傳播的方法最小化誤差,并調整優化連接權值以減小預測誤差。
這3 個對比模型均使用python 語言編程實現。為建立預測模型而搭建實驗平臺的軟硬件信息如下:系統為Windows 10(64 位),處理器為AMD Ryzen 7 PRO 2700U,內存為8.0 GB;程序語言版本為Python 3.6.7,開發環境采用Anaconda 包jupyter 1.0.0。深度學習框架采用CPU 版tensorflow 2.0 中的keras 2.3.1。
3.3 模型訓練參數優化
訓練過程如下:
步驟1確定lookback,hidden 與predstep,歷史數據步長為6 (區域PoI 數量qp及5 個歷史時間網約車需求量,預測步長為1,即當前預測時間段網約車需求量。由經驗法則,隱藏神經元數量為
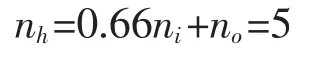
步驟2確定灰狼算法搜索空間維度、迭代次數及個體數:設灰狼個體數為50,迭代次數為800。GWO-LSTM 訓練網絡參數優化誤差曲線如圖5所示。
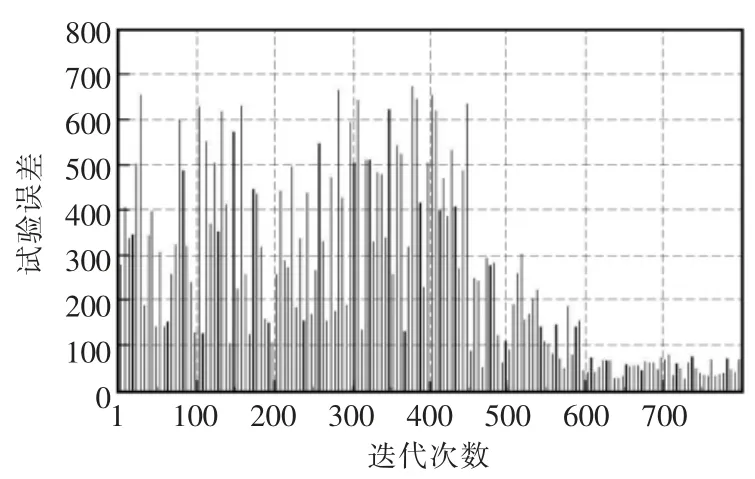
圖5 GWO-LSTM 訓練網絡參數優化誤差曲線Fig.5 Error curve of training network parameter optimization in GWO-SLTM
當迭代次數大于600 時,誤差值逐漸變小且趨于穩定; 搜索空間維度為LSTM 各權重矩陣與偏置量的維度之和。如ωxi,維度hidden*lookback 為30,其他參數依此類推,因此得到灰狼群體中搜索空間維度為
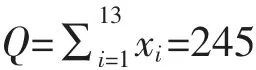
步驟3初始化種群操作,采用隨機分布函數對群體進行初始化,即為Wij~U(uj,lj)。其中,uj,lj分別為分布區間的上、下界,將得到的初始種群值分解為LSTM 參數。
步驟4當迭代次數≤800 時,計算每個灰狼個體參數相應的輸出值y 及適應度值,對比各適應值并排序,取得最佳的3 個個體,依次標記為Wtα,Wtβ,Wtδ,其中t 為當前迭代次數。更新其余灰狼位置,并迭代當前步驟,直至迭代結束,尋找到最優解Wα′,進而分解為LSTM 網絡參數。
步驟5預測階段,將測試集數據輸入到網絡中,得到預測值與實際值進行誤差計算,即得模型預測準確度。
3.4 模型預測結果分析
GWO-LSTM,標準LSTM 和BPNN 三種模型對示例區域全天網約車需求量預測結果的對比如圖6所示。3 種模型預測趨勢與真實數據變化趨勢均呈一致性;在早晚高峰等起伏較大的時間段,3 種模型均體現了不同程度的預測偏差。相對地,所提出的GWO-LSTM 模型相較其他模型,誤差較小,預測精準度較高,預測效果較優。其數值表現見表2。
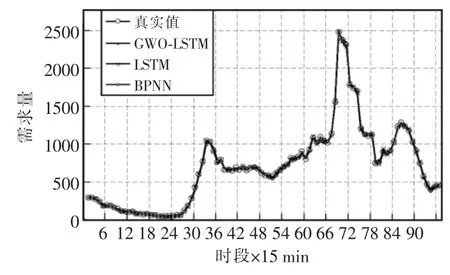
圖6 預測結果對比Fig.6 Comparison of prediction results
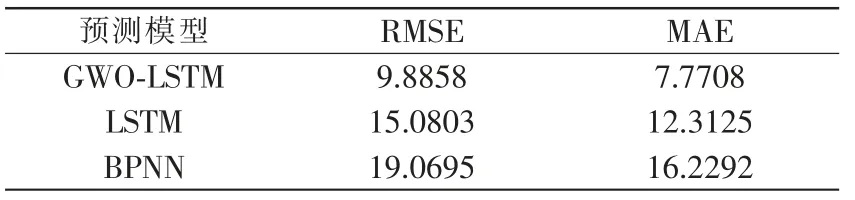
表2 預測結果評價Tab.2 Evaluation of prediction results
對于模型評估指標RMSE 與MAE 而言,數值越小則表明模型預測效果越好。由表2可知,GWO算法改進的LSTM 預測值的RMSE 為9.8858,相對于傳統的LSTM 網絡提升了34.45%,相對于BP 神經網絡提升了48.16%; 在MAE 方面,GWO-LSTM預測結果相對于真實值為7.7708,相較LSTM 提升了36.89%,相較于BPNN 提升了52.12%,預測效果顯著。
4 結語
基于實際數據,分析了網約車需求時空分布特性及影響因素與網約車需求量的相關性;針對標準LSTM 模型在時序數據預測中存在的問題,提出了GWO 改進LSTM 網絡參數的網約車短時需求預測模型,并對模型效果進行實例驗證。結果表明,該模型相較于標準LSTM 和BPNN,預測效果均有較大提升;尋優過程中,灰狼優化算法有種群多樣性差與后期收斂速度慢等缺陷,將對灰狼優化算法進行改進以優化模型。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
