基于貝葉斯優化的心臟病診斷模型
2020-06-04 11:03:14杜一平
呂梁學院學報 2020年2期
杜一平
(呂梁學院 數學系,山西 離石 033001)
心臟病的診斷是一個分類問題,數據挖掘中基于分類的模型有很多,如KNN、logistic回歸、決策樹、支持向量機、神經網絡等.而近幾年集合多個學習器的集成學習模型在各方面表現出其優越性,得到人們的追捧.如隨機森林、AdaBoost算法.隨機森林是對多個決策樹的并行組合,AdaBoost則是對其進行串行迭代.單個學習器的準確率只依賴于自身單一參數的選擇,而集成學習模型雖然有更強的泛化能力,但往往有數量眾多的參數需要進行選擇.如果參數多且其取值空間非常大,想要進行參數擇優就是一個難題.遍歷整個參數空間,往往是不現實或者是效率極低的.而如果用隨機搜索的方法則很有可能遺漏最優值.對于參數集的選擇問題,貝葉斯優化框架是一個非常有效的辦法[1].
1 貝葉斯優化框架
貝葉斯優化實質就是在對目標函數具體形式不知的情況下,根據已有的采樣點來估計函數最大值的一種算法.與遍歷搜索算法相比,迭代次數少,粒度小[2].優化流程如圖1:
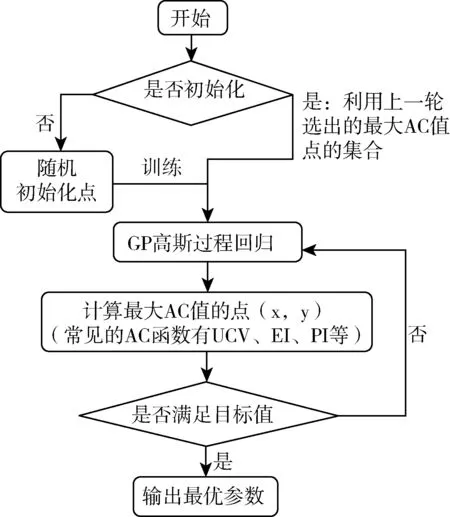
圖1 貝葉斯優化流程
貝葉斯優化流程有兩個主要模塊,概率代理模型(Probabilistic Surrogate Model)和采集函數(Acquisition Function).
1.1 概率代理模型
概率代理模型顧名思義就是用一個概率模型來代理目標函數f(·).模型更新由式(1)得出.
(1)
其中,D={(x1,f1),(x2,f2),…,(xn,yn)}表示已采集樣本點,p(f)為f的先驗分布,通過貝葉斯公式得出p(f|D)為f的后驗分布.具體的代理模型根據參數的不同情況,可以分為參數模型和非參數模型.參數模型就是由參數w來決定f(·),它的參數量在更新過程中是不變的.而非參數模型的參數量會隨著數據量的變化而變化.相比較,非參數模型要更靈活、更具擴展性.非參數模型中應用最廣泛的是高斯過程(GP)[3].
高斯過程本質是一個多元正態分布,在貝葉斯優化中,一般假設:
(2)

y|X,σ2~N(y|m,K+σ2~I)
(3)
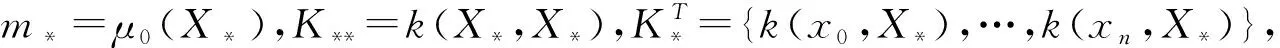
(4)
1.2 采集函數
采集函數的目的是在參數空間中得出下一個評估點,使其能提升函數性能.常見的采集函數有:UCB、PI、EI三種.本文中采用PI函數,其形式為:
PI(X)=p(f(X)≥f(X+)+v)
(5)
式(5)中f(X)為目標函數,f(X+)為目前為止最優的目標函數,μ(x),σ(x)是f(X)后驗分布的均值和協差陣,v權衡系數,避免陷入局部最優.采集函數過程就是選取新的X,使PI(x)最大,一般這個過程使用蒙特卡洛模擬方法[4].
2 貝葉斯優化的心臟病分類模型
文章選取UCI心臟病數據集Heart,數據集中有303條數據,15個屬性,其中Ca表示患有心臟病可能性.部分數據如下:

表1 Heart數據集5個樣本數據
2.1 數據預處理
在R中導入數據集Heart,發現有少量缺失值,直接進行剔除,剩余297條數據.對變量RestBP、Chol、Thalach、MaxHR進行標準化處理.數據集中描述心臟病可能性的變量Ca是一個連續型變量,創建一個AHD變量,將Ca二值化.當Ca的值大于等于0.5時,AHD取Yes,反之取No.以AHD作為分類變量,建立分類模型.
2.2 建立分類模型
本文采用當下流行的集成學習中的隨機森林算法建立分類模型.隨機抽取50個樣本作為測試集,其余為訓練集.隨機森林模型參數主要有兩個[5]:第一個是樹的數量Ntree,數量過多過擬合的風險增大,數量太少又欠擬合,其范圍確定為(1,120).第二個是建樹時隨機抽取的屬性個數Dtree,取值范圍(1,14).接下來用貝葉斯優化算法對參數進行優化.
首先確定目標函數.對于每組參數所對應的模型,在訓練集上進行5折交叉驗證,平均誤差為目標函數f,每組參數組合為變量X,代入貝葉斯優化框架中進行迭代計算,參數優化流程見表2.

表2 參數優化流程
2.3 結果分析
本文采用R語言中MIBayesOpt程序包.它提供了支持貝葉斯優化方法的計算框架,輔助支持向量機、隨機森林等模型進行參數優化.計算框架中采用GP+PI模型,即高斯過程結合PI函數的優化模型,對隨機森林模型的參數進行優化搜索,搜索迭代次數為100次,得出最優參數組合(Ntree,Dtree),測試集準確率達到93.44.接著采用隨機選取的方法,隨機選出100組參數組合,得出其準確率最高的組合為(Ntree,Dtree)=(110,6).將兩組參數代入隨機森林模型在測試集上分別測試分類準確率.表3和表4分別代表兩種模型的在測試集上的性能,結果匯總如表5.
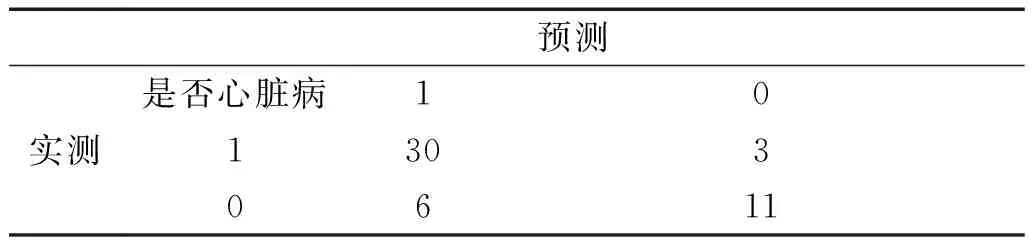
表3 隨機搜索模型混淆矩陣
表4貝葉斯優化模型混淆矩陣
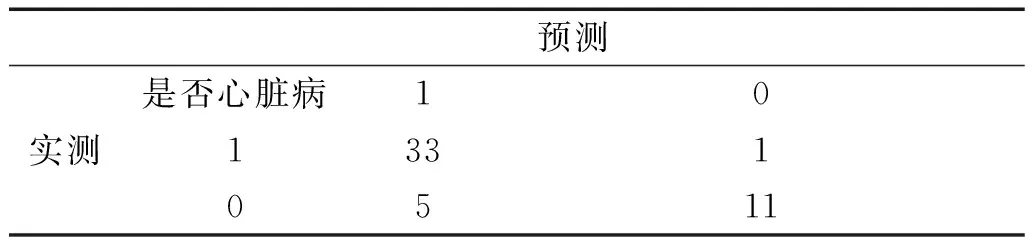
預測實測 是否心臟病1013310511

表5 結果比較
由實驗結果可以得出,貝葉斯優化尋參方法與隨機搜索方法相比,在迭代次數相同的情況下,在測試集上準確率要更高.因此隨機搜索最優參數還是具有一定的盲目性,而貝葉斯優化尋參方法是隨著數據模型變化趨勢,有目的的尋找最優參數,效率更高.
3 結束語
本文首先簡要介紹了貝葉斯優化框架的理論知識,隨后將其框架應用于隨機森林分類算法的參數尋優過程中.最后經Heart數據集實證分析,得出其方法在調參方面的優越性.貝葉斯優化框架也可以廣泛應用于其他機器學習模型的參數調優中.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
