
Fast-flucos:基于DNS 流量的Fast-flux 惡意域名檢測方法
2020-06-06 00:54:32韓春雨張永錚張玉
通信學報 2020年5期
韓春雨,張永錚,張玉
(1.南開大學計算機學院,天津 300071;2.中國科學院信息工程研究所,北京 100093;3.中國科學院大學網絡空間安全學院,北京 100049)
1 引言
隨著網絡的應用越來越廣泛,域名系統(DNS,domain name system)逐漸成為最重要的互聯網基礎設施之一,許多網絡上的基礎服務都與其息息相關。與此同時,惡意攻擊行為也伴隨互聯網的快速發展而不斷變化。僵尸網絡作為當下網絡環境中的最大威脅之一,能夠迅速分發并擴散大量的蠕蟲、木馬等計算機病毒進行惡意代碼(僵尸程序)的傳播[1]。起初的惡意代碼往往在程序中預置某一個域名指向其命令與控制服務器(C&C,command&control server),隨后就有黑客采用域名生成算法(DGA,domain generation algorithm)技術產生大量的無關域名來隱藏真正的C&C 域名來躲避攔截。但使用的IP 地址仍然固定,無法防止因IP 地址被封堵而直接失效。所以攻擊者又轉而使用Fast-flux 技術,它是一種通過不斷變更僵尸代理主機來隱藏惡意程序分發點并可實現負載均衡的DNS 技術。Fast-flux 網絡為攻擊者的惡意行為提供了高可用性和動態性[2],其目前被人們熟知的明顯特點總結如下[3-5]。
1) 單域名映射的IP 地址量較大,且在僵尸代理主機遷移階段IP 地址會逐漸增多。
2) IP 地址所在地理位置(國家或地區)分布較廣。
3) IP 地址變化頻度較高。
4) 通常權威映射記錄生存空間(TTL,time to live)值較短。
5) 僵尸代理主機所分布的網段數目較多。
6) 僵尸代理主機所在網絡所屬的組織機構數目較多。
然而,以上特點并非是Fast-flux 惡意域名所獨有的。以下2 種域名通常也會具有上述特征。
1) 域名循環系統(RRDNS,round-robin domain name system)。RRDNS 是一種典型的用于負載分配、實現負載均衡和高容錯率的DNS 技術,它對用戶發出DNS 請求的響應不是單條A 記錄,而是一個A 記錄列表,這就意味著這種域名也會對應很多服務主機的IP 地址。RRDNS 域名的A 記錄列表以一種循環的方式來響應連續的DNS 請求。因此,一系列向RRDNS 發出的請求會直接得到不同IP 地址的服務器響應,從而有效地實現了負載均衡。
2) 內容分發網絡(CDN,content delivery network)。CDN 是另一種可以實現負載均衡的服務系統,該系統在一定區域內的每個節點都向適合的用戶提供完全相同的響應數據。正確設計和實施的CDN 可以提高訪問遠程數據的效率,增加帶寬和冗余,同時減少時延。因此,該服務響應同一個域名的DNS 請求時,會返回大量帶有不同IP 地址的A記錄。CDN 也使用較低的TTL 值,以便在連接屬性等相關參數發生改變時快速做出相應調整。
一直以來,利用Fast-flux 技術形成的僵尸網絡依然廣泛存在,由于CDN 和RRDNS 的技術特點均與Fast-flux 相似,因此當二者對應的域名部署在DNS上時,可能會被誤檢為Fast-flux 惡意域名,這無疑增加了Fast-flux 域名檢測工作的難度[6]。而后出現的Double-flux 技術[7]使檢測工作變得更加困難,該技術是對以前Single-flux 技術的升級,其由多個flux 代理主機擔任域名解析代理,并由后端的Mothership 執行域名解析。通過flux 代理主機的快速切換,避免了以往單個被攻陷的DNS 服務器被封堵而無法繼續提供服務的情況。即使某個flux 代理主機被列入黑名單,也可通過新的flux 代理主機繼續提供服務。這兩項技術的原理分別如圖1 和圖2 所示。
從圖1 和圖2 可以看出,Double-flux 型Fast-flux網絡在結構上更加復雜,且因單點被封堵而引發故障的可能性也被大大降低。根據僵尸網絡的行為過程,無論應對哪種Fast-flux 技術,高效地檢測Fast-flux 域名都具有重大意義。
2 相關工作
在Fast-flux 僵尸網絡剛出現時,Nazario 等[8]便開始對其展開了研究,分別從Fast-flux 僵尸網絡的域名特性、域名存活時間、網絡成員信息、網絡大小、網絡重合度等方面分析了其行為。Caglayan等[9]對垃圾郵件、惡意代碼和釣魚這3 種Fast-flux僵尸網絡進行了全面的分類跟蹤分析。Hu 等[10]通過一個部署在4 個洲共計240 個節點的輕量級DNS分析DIGGER,進一步分析了Fast-flux 網絡及其他與其特性相似的網絡的IP 地址特性。Passerini 等[11]采用主動探測的方法以獲得比被動接收DNS 流量更多的Fast-flux 網絡相關信息。通過這些研究工作,人們得到了一系列較成熟的Fast-flux 域名相關特性。于是,各種檢測方法開始相繼出現。
文獻[12]通過域名對應IP 地址集合的相似性,對域名進行有監督的分層聚類分析,并采用決策樹算法,初步實現了對Fast-flux 域名的檢測。
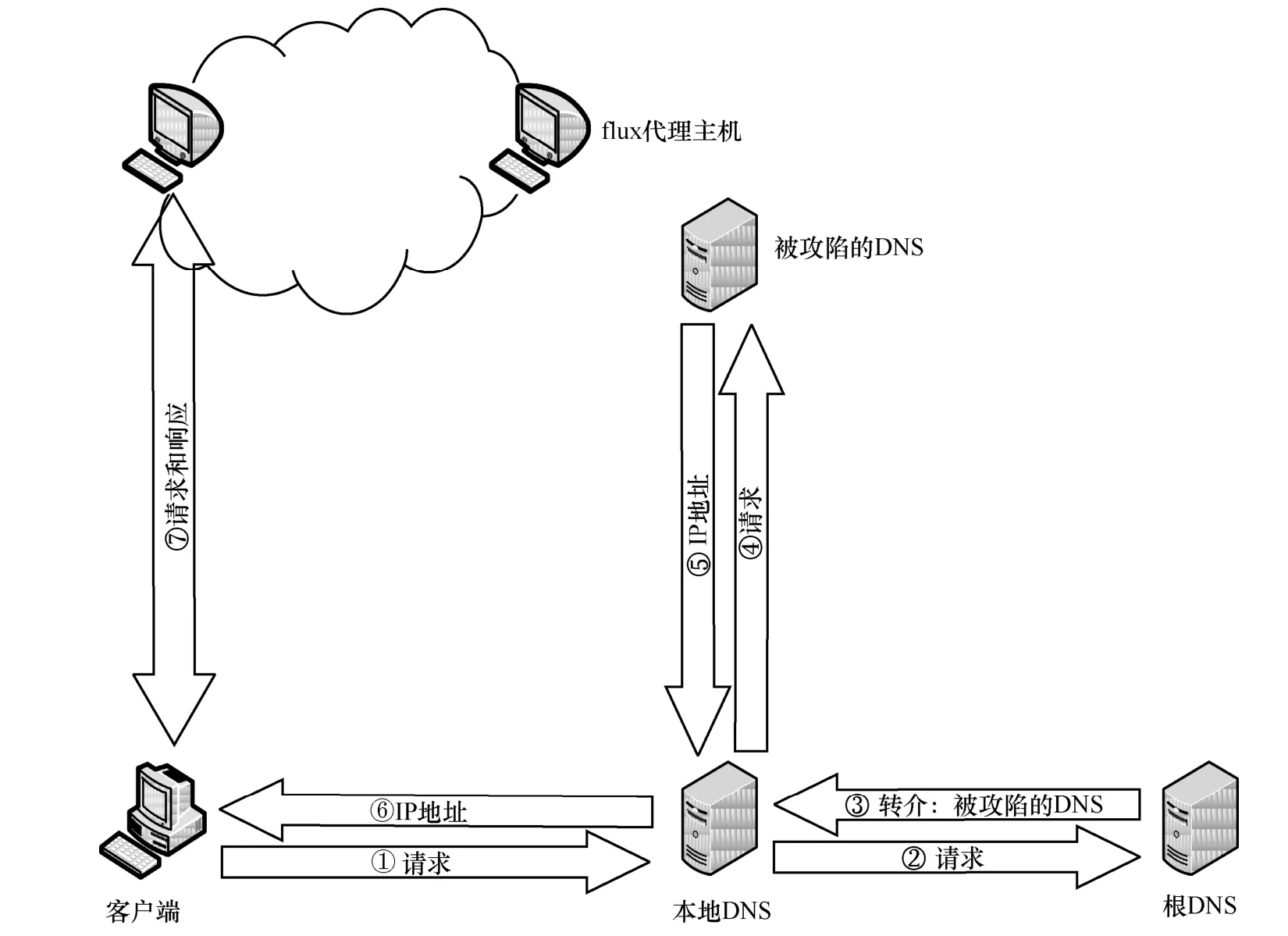
圖1 Single-flux 原理示意
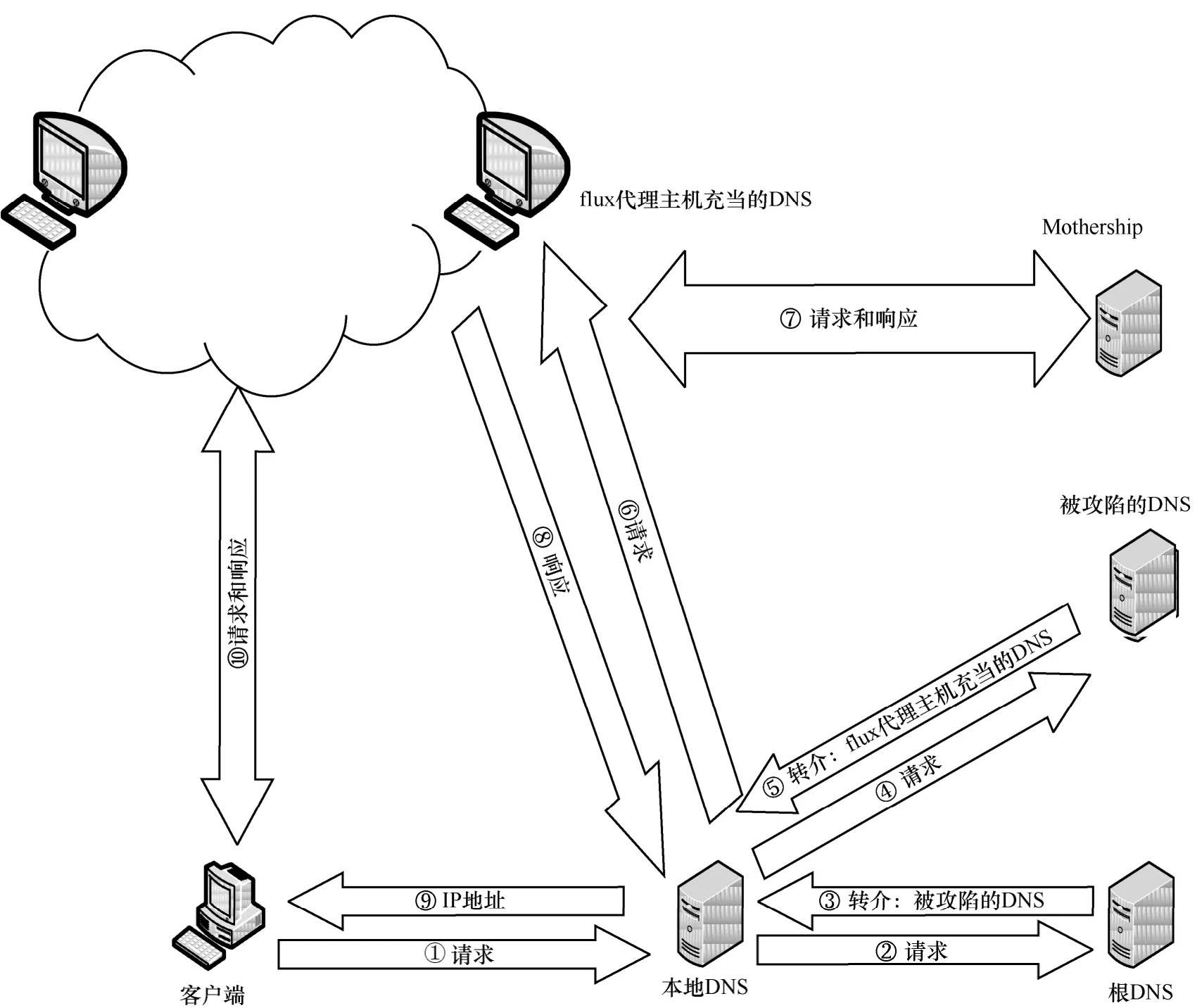
圖2 Double-flux 原理示意
文獻[13]提出了一種基于真實編碼遺傳算法的Fast-flux 域名檢測方法 GRADE(genetic-based real-time detection system),其在文中實驗的檢測結果可以達到較高的準確率,但主要利用的新特征依賴于遞歸請求往返時間標準差,而這一參數受網絡環境波動的影響較大,直接影響了其性能的穩定性。
文獻[14]提出了名為“SSFD(spatial snapshot Fast-flux detection system)”的檢測方法,其核心思想是基于空間關系檢測Fast-flux 域名。該方法引入了時區熵這一新特征,并且需要利用“空間快照”技術將樣本域名解析列表中每個IP 地址歸屬的地理位置都標記在谷歌地圖上。這使該方法對所使用的數據庫要求較高,必須先創建、維護并每晚更新一個IP 地址與歸屬地理位置相對應的數據庫,而一旦某域名的某些解析值在庫中找不到對應,又面臨“值缺失問題”,這勢必影響其檢測效果的穩定性。
文獻[15]基于3 種可用于區分Fast-flux 網絡和正常網絡的參數計算出一個線性分數指標,稱為Flux-score,用以判別Fast-flux 域名。
文獻[16]分析了當時已有的Fast-flux 網絡檢測技術,認為檢測的關鍵在于根據網絡拓撲結構選取合適的探測位置部署分布式的檢測系統,來實現對Fast-flux 網絡的協同檢測與關聯分析。
文獻[17]同樣基于訪問Fast-flux 域名時的響應時間每次都會有較大差異的特點,提出了一個通過計算FF-Score 來判定Fast-flux 域名的方法。然而該響應時間的差異性特征同樣可能受到網絡波動的干擾,從而影響檢測效果的穩定性。
文獻[18]基于決策樹算法提出了EXPOSURE檢測方法,提取了分別與時間、DNS 應答、TTL、命名相關的4 組特征。其中僅有少部分特征是針對Fast-flux 域名的特點而提取的,所以該方法在整體上可能仍然欠缺對檢測目標的針對性。
文獻[19]提出了一種聚類和有監督學習相結合的惡意域名檢測思路,強調了如何有效區分CDN域名與Fast-flux 域名,并提取了與之相關的特征,實驗達到了較高的準確率。不過該方法訓練的SVM(support vector machine)分類器所用的數據來源于教育網,可能無法穩定有效地適用于常規互聯網環境下的DNS 流量。
通過對上述文獻的分析發現,現有方法可能存在如下不足。
1) 受網絡環境波動影響較大,導致檢測結果的穩定性較差。
2) 缺乏對Fast-flux 域名的針對性,導致檢測結果的召回率或精確率不高。
3) 用于分類器訓練的DNS 流量不具有普適性。
通過分析真實DNS 流量發現,Fast-flux 域名在大部分時間極少被訪問,而在特定時間被集中訪問。這項明顯區別于CDN 等正常域名的重要特征一直沒得到有效利用。以這項發現為出發點,并結合大洲覆蓋、國家或地區距離、國家或地區向量等特征,提出了一種基于DNS 流量的Fast-flux 惡意域名檢測方法,命名為Fast-fluco(sfast-flux detection based on countries)。
3 方法介紹
Fast-flucos 包含4 個模塊:預處理、特征提取、分類器和關聯匹配。預處理模塊先從輸入的大量DNS 流量中篩除一些亂碼型域名請求記錄,再結合所發現的時間分布特性過濾出很多不可能為Fast-flux 域名的請求記錄,從而得到有效的DNS流量。特征提取模塊根據我國廣東省一段時間內DNS 流量的相應字段并結合已制作的國家或地區距離表計算出所有域名樣本的7 組特征。通過已知標簽樣本集和計算好的相關特征,分別使用各種可能的特征組合,并結合多種機器學習算法來訓練最佳分類器,從而輸出一部分Fast-flux 域名。關聯匹配模塊利用WHOIS 注冊者信息并結合特定的字符串匹配算法,根據分類器的輸出發現更多Fast-flux域名。Fast-flucos 的結構如圖3 所示。
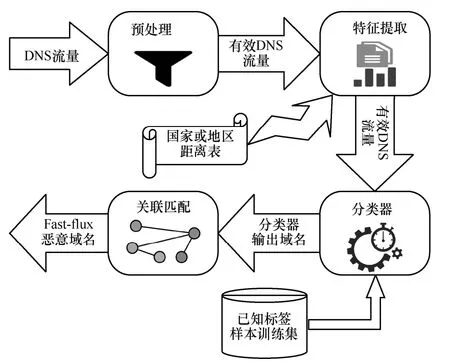
圖3 Fast-flucos 結構
圖3 的DNS 流量具體是指在特定時間段內,某地區全部由客戶端向DNS 遞歸服務器發出的DNS 解析請求的往返信息記錄,按一定的采樣率組成的DNS 解析記錄列表。每行第一列至最后一列的字段分別表示請求源IP 地址、請求目的IP 地址、DNS ID、域名、請求類型、請求分組重復次數、該時間間隔下分組采樣率、匹配標識、遞歸請求標識、權威請求標識、首個應答記錄(RR,response record)的TTL 值、當前獲得分組的時間、節點編碼、請求分組長度、應答分組長度、首個RR 的類型、服務器響應標識、省份(或省級地區)標識、通信運營商標識和首個RR 解析值(含解析IP 地址列表)。
實驗中所使用的數據主要是從我國某主流通信運營商在廣東省的DNS 流量分析所得,時間段是從2017 年12 月1 日—7 日。選取這一段DNS 流量的主要原因是,使用從微步在線等第三方平臺上獲取的樣本篩查后發現,在這大約60 萬個不重復的符合命名規范的域名中,共出現了3 022 個與已知標簽的Fast-flux 域名具有相同二級域名的樣本,這很利于域名特征的提取。還有一部分數據是直接使用的微步在線提供的域名解析歷史記錄。
3.1 預處理
通過實驗證實所發現的Fast-flux 域名的重要特性——大部分時間極少被訪問,特定時間集中被訪問。先將實驗所用的時間段內的數據按“域名”字段進行去重處理,得到的域名集合定義為First 集合。之后的步驟如下[20]。
1) 將該時間段每天的DNS 流量都以Tmin 為單元進行分片。
2) 從First 集合中選出一個域名定義為First域名。
3) 再從原DNS 流量中該First 域名出現次數最多的一天中找出其對應的Second 請求記錄。
4)計算該天內每個時間分片的count_value(計數值,表示Second 請求記錄在該時間分片中出現的總次數)。
某First 域名的Second 請求記錄,是滿足以下任意條件的DNS 請求記錄。
1) “域名”字段與First 域名完全相同。
2) 與First 域名的“首個RR 解析值”字段的交集不為空。
3) “域名”字段與First 域名具有相同的三級域名。假設count_valuei(i=1,2,3,…)表示第i個分片(window[i])的 count_value,則根據全部的count_valuei可以求出平均值,記為count_valueV,依此可計算出每個域名對應的AX 值,AX 值為所有中的最大值。上述過程可以總結為如下可以得到所有域名AX 值的算法。
算法1AX 賦值算法
輸入First 域名,已分片的DNS 流量window[]
輸出AX 值
當T取不同值時,AX 值的范圍如表1 所示。
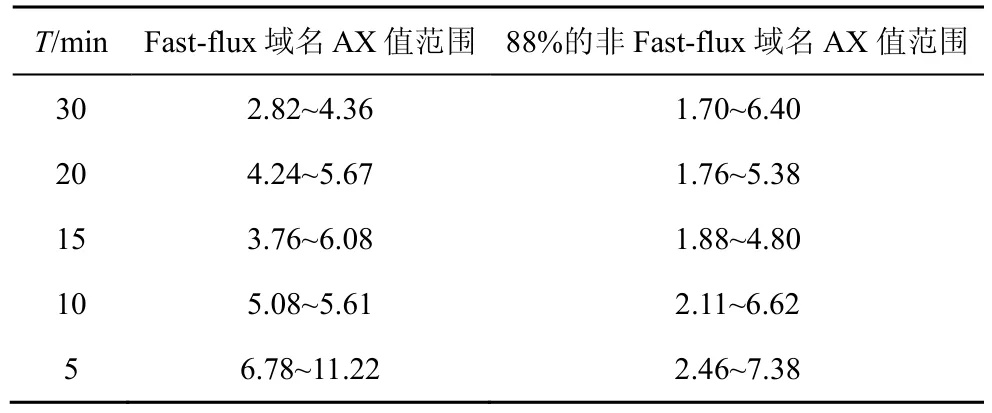
表1 當T 取不同值時AX 值的范圍
從表1 可以看出,當T=5 min 時,AX 值可以更好地表示出一個域名是否為Fast-flux 域名。這也證實了所發現的重要特性——大部分時間極少被訪問,特定時間集中被訪問。
數據預處理模塊的流程及原理如下。
1) 由Fast-flux 域名的定義可知,其在一定時間內單域名映射的IP 地址量很大,故對于待檢測的DNS 流量,將解析IP 地址數量不足NIP的域名篩除。
2) Fast-flux 惡意域名的另一個特點是IP 地址所歸屬的國家或地區分布廣,所以對于待檢測的DNS 流量,將解析IP 地址對應的國家或地區數僅為NC的域名篩除。
3)根據所發現的時間分布特性,對于待檢測的DNS 流量,將其中AX 值低于NAX的域名篩除。
為確定上述NIP、NC和NAX的取值,對來自微步在線等第三方平臺上的Fast-flux 域名樣本進行分析。最終確定了在預處理模塊中3 個參數的取值分別為NIP=12、NC=1 和NAX=6。
3.2 特征提取
根據已有工作進行歸納和改進,并結合Fast-flucos 的基本思想,擬采用以下7 組共計506 個單特征[21-23]。
1) F1 TTL 特征
①最大TTL 值。
② 最小TTL 值。
③不同TTL 值的個數。
2) F2 IP 地址特征
①解析IP 地址的個數。
② 解析IP/65536(IP 地址前兩段)的個數。
3) F3 子域名特征
①子域名的個數。
② 子域名的長度標準差。
③共享域名的個數。
4) F4 數字證書字節數
5) F5 地理特征
①解析IP 地址對應的國家或地區數量。
② 解析IP 地址對應的國家或地區涵蓋的大洲情況。
③距離指數D_Score。
6) F6 國家向量表
7) F7 時間向量表
其中,共享域名的含義簡述如下。若某域名的解析IP 地址列表中的某些IP 地址也被其他域名所解析,則這些域名稱為該域名的共享域名[24]。
TTL 特征。通過調研[19]發現,正常域名的TTL值往往在1 天以上,而惡意域名為了使自己更加隱蔽,通常會設置很小的TTL 值。有60%以上正常域名的TTL 值是在1 200 s 以上的,而惡意域名的TTL值通常會小于1 000 s,雖然Fast-flucos 只關注惡意域名中的Fast-flux 域名,但是TTL 特征仍不失為一個可靠的特征。
數字證書字節數。正常域名在注冊時通常具有完備的WHOIS 注冊信息,而惡意域名的注冊信息通常是很簡略或隨機的[19]。WHOIS 信息中有一項是數字證書,而惡意域名沒有或信息很少,所以數字證書的字節數就可以直接作為一項有力的特征。
針對Fast-flux 惡意域名的特有特點,又為每個域名定義了距離指數D_Score、206 維的國家或地區向量表和288 維的時間向量表這3 組特征。
3.2.1 距離指數D_Score
眾多已發表的論文中都提到了Fast-flux 域名的特點是映射的IP 地址歸屬的地理位置(國家或地區)分布的范圍廣并且分散度高,但是均未提及與具體的國家或地區分布頻次和量化的地理廣度信息相關的特征,所以根據Fast-flux 惡意域名樣本與非Fast-flux 域名樣本各自解析的IP 地址歸屬國家或地區(下文簡稱“解析國家或地區”)的地理廣度信息,為每個域名定義了一個特征,稱為距離指數D_Score。其表征了一個域名的解析國家或地區在地理位置分布上的廣度與分散程度,為了計算此特征,需要先獲取全部有國際頂級域名后綴的國家和地區(這里共計206 個)的行政中心的經緯度信息,并都采用弧度制表示。利用式(1)球面上兩點距離公式,便可以得到全部206 個國家或地區的兩兩間距離表。這樣,再根據式(2)便可求得某個域名的D_Score(即歐氏距離)。
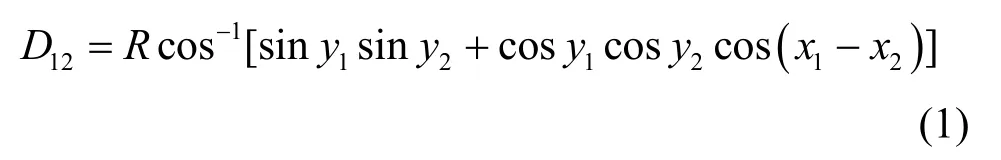
其中,R是地球半徑,(x1,y1)和(x2,y2)分別是球面上兩點的弧度制坐標。
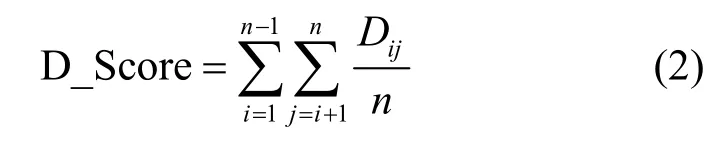
其中,Dij表示該域名中的第i個解析國家或地區與第j個解析國家或地區行政中心坐標間的球面距離,n表示該域名解析國家或地區的數量。
3.2.2 國家或地區向量表
本文統計了數量比為5 000:5 000 的正負樣本中每一個域名分別解析到206 個不同國家或地區的次數,其中正樣本選自微步在線等第三方平臺上的Fast-flux 域名樣本,負樣本是從DNS 流量中隨機選取的5 000 個不重復的非Fast-flux 域名。從統計結果可以看出,各不同國家或地區被解析到的頻次與發起解析請求的域名是否為Fast-flux 域名的關聯度很高,因此國家或地區向量表這一組特征被加入進來。該特征的具體表示形式為,對于某給定域名,獲取其所有的解析國家或地區,統計全部206 個國家或地區各自出現的次數,從而形成這個域名的國家或地區向量表,即一個206 維的向量,其每個值都表示該域名解析到對應國家或地區的次數。
3.2.3 時間向量表
基于已經過驗證的Fast-flux 域名區別于CDN等正常域名的重要特性——大部分時間極少被訪問,特定時間集中被訪問,加入時間向量表特征。若根據3.1 節中相關概念的定義和結論,將DNS 流量按照每5 min 進行分片,則該特征的具體表示形式為,對于某給定域名,獲取該域名在其出現次數最多的一天中的count_value[],即一個288 維的向量,其每個值都表示該域名在其出現次數最多的一天中對應的時間分片內的count_value。
3.3 特征選擇和分類器
根據已總結出的F1~F7 這7 組特征,分別使用各組特征的不同組合,并都使用3 種不同的機器學習方法(樸素貝葉斯、支持向量機和邏輯回歸),利用scikit-learn 的機器學習工具庫構建機器學習模型,使用引入了NumPy 包和Pandas 包的Python 語言完成實驗。在計算國家和地區間的距離時,使用了Microsoft Excel 并編寫了VBA 語言的宏。對每種特征組合情況都進行了10 折驗證計算,取10 次的平均值作為最終的檢測結果。最后列出其中平均效果最好的9 種特征組合,如圖4 所示。
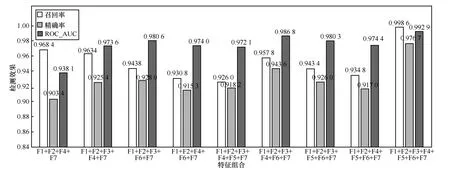
圖4 使用不同的特征組合的分類效果對比
從圖4 可以看到,在各種特征組合的情況下,使用邏輯回歸算法取得了最佳效果。特征F6 和F7在圖4 中頻繁出現,足見其重要作用。然后嘗試使用深度神經網絡在最佳特征組合條件下進行分類效果測試,先設置隱藏層的層數為2,根據人為經驗對各種神經元數組合進行實驗,得到了一組最理想的組合,即(22,5),此時10 折驗證的輸出結果顯示召回率是0.955 2、精確率是0.933 6、ROC_AUC是0.978 956。參考此結果繼續調試當隱藏層層數分別為3~7 時的情況,分別尋找最佳的檢測結果,如圖5 所示。
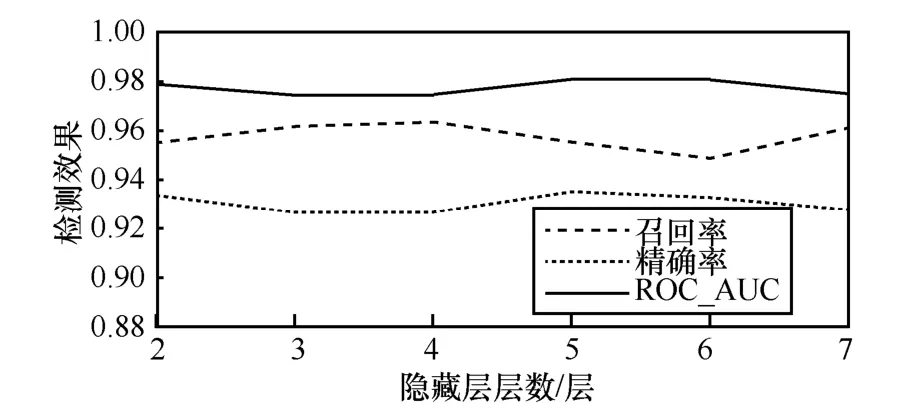
圖5 使用不同隱藏層層數的深度神經網絡的分類效果對比
從圖5 可以看出,隨著隱藏層層數的增加,檢測效果并沒有明顯變化,當隱藏層層數為5 時性能最佳,此時召回率是0.955 4、精確率是0.935 2、ROC_AUC 是0.981 0。可見,在Fast-flux 樣本數量不夠龐大、所提取的特征已經很具象化的條件下,深度學習并沒有取得比常規機器學習更好的檢測效果,使用邏輯回歸分類器已經達到了較好的性能。
3.4 關聯匹配
將從分類器得到的輸出結果和原輸入DNS 流量中的域名集合進行“關聯匹配”,具體含義如下。
1)“關聯”指的是注冊者信息關聯。在本節中定義從分類器中輸出的域名為集合C,利用C中的域名關聯WHOIS 注冊者信息來二次挖掘可能被漏檢的Fast-flux 域名。在原輸入DNS 流量中的域名集合(本節定義為集合P)中,將與C中的域名具有相同注冊者的域名都分離出來,在本節定義為集合S。
2)“匹配”指的是“0-z”化后的字符串匹配。某些個人或集體可能用不同的注冊者信息注冊了一系列域名用于惡意行為,為便于管理,其中很多域名被命名為僅字母不變而變換數字或僅數字不變而變換字母的形式,如果僅憑注冊者信息則無法發現這部分域名。事實上這些域名都普遍指向了相同的IP 地址集合,即很可能使用了Double-flux 技術用以減小單點故障的可能性。所以找到具備這種特點的域名,則可以認為其同樣是Fast-flux 域名,在實驗中也取得了良好的效果。倘若C和S中共有域名m個,待字符對比的域名有n個,則單次對比的次數將是一個時間復雜度為O(mn)的問題,為此,需要引入字符串“0-z”化的概念。
于是,“關聯匹配”算法的步驟如下。
步驟1將P中同時包含字母和數字字符的每個域名中的數字字符都變成0,成為集合P0;除頂級域名外的字母字符都變成z,成為集合P1。對字符串的這種操作稱為“0-z”化,如圖6 所示。
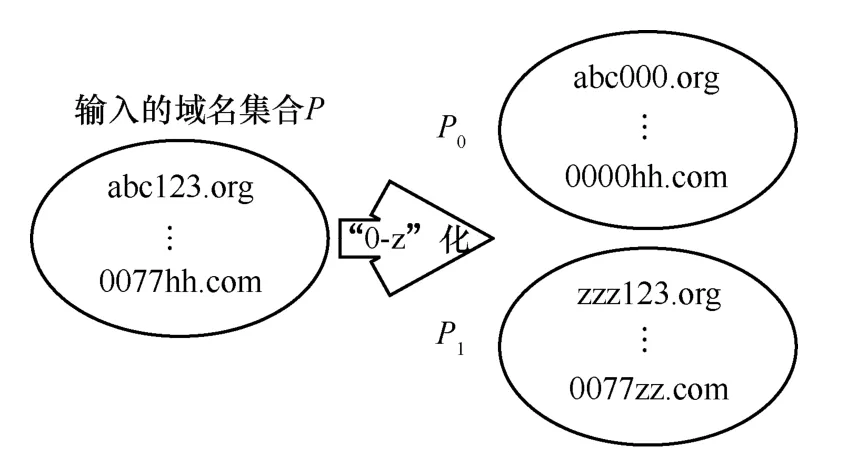
圖6 步驟1 過程
步驟2將C和S中所有同時帶有字母和數字字符的域名連接成一個長字符串T并“0-z”化,如圖7 所示。
步驟3將P0中的每個字符串分別與T0進行字符串匹配,將P1中的每個字符串分別與T1進行字符串匹配,如圖8 所示。
步驟4根據所有匹配成功的字符串,在P、P0和P1中都移除相應的域名/字符串,從P中移除的部分獨立成為集合S′。然后將S內的全部域名轉移進C中,如圖9 所示。
步驟5在P中找到所有與S′內注冊者相同的域名保存至集合S,并從P0和P1中移除相應的字符串。然后將S′內的全部域名轉移到C中,如圖10 所示。
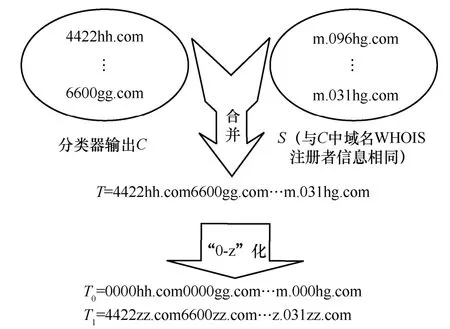
圖7 步驟2 過程

圖8 步驟3 過程
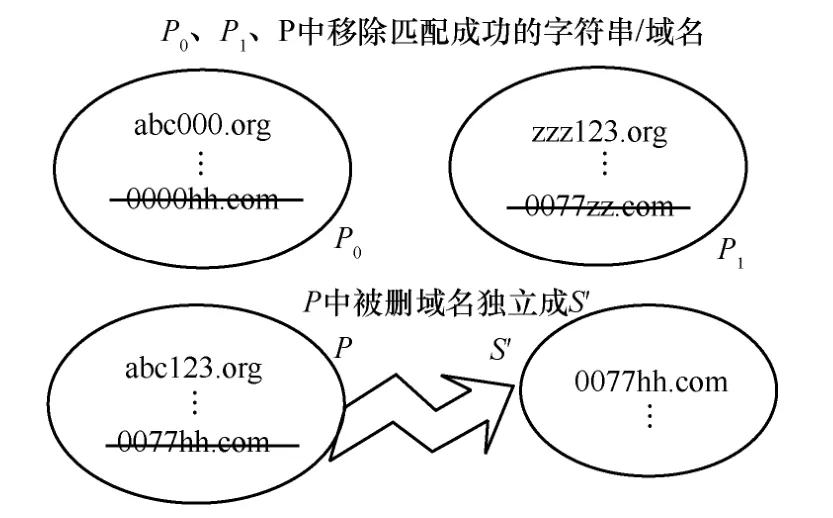
圖9 步驟4 過程
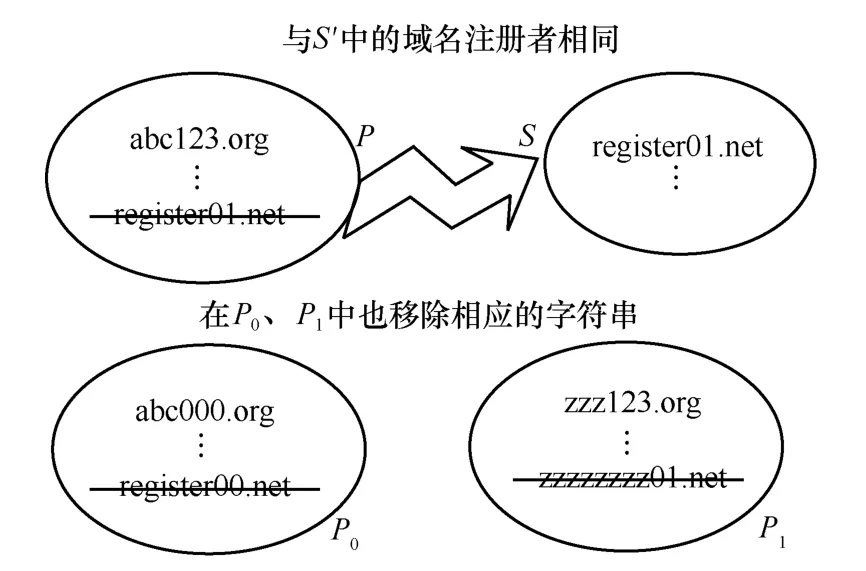
圖10 步驟5 過程
步驟6將S中所有同時帶有數字和字母字符的域名連接成一個長字符串T并“0-z”化,重復步驟3~步驟5。
步驟7重復步驟6 直到C內域名不再增加。
通過以上處理,將時間復雜度為O(mn)的逐個字符串比較問題轉化為時間復雜度為O(n)的字符串匹配問題。而且,因為在“0-z”化后的字符串中存在大量重復的字符,很利于字符串匹配算法的快速運行。整個“關聯匹配”算法就是通過WHOIS注冊者信息和特定的字符串匹配算法相互迭代,使Fast-flux 域名集合C得到不斷擴充,從而在分類器分類之后可以再發現一部分漏檢的Fast-flux 域名。
4 性能評估
4.1 分類效果
首先,通過如表2 和圖11 所示最佳特征組合的邏輯回歸分類器詳細的10 折驗證結果可以看出,模型的穩定性較好。
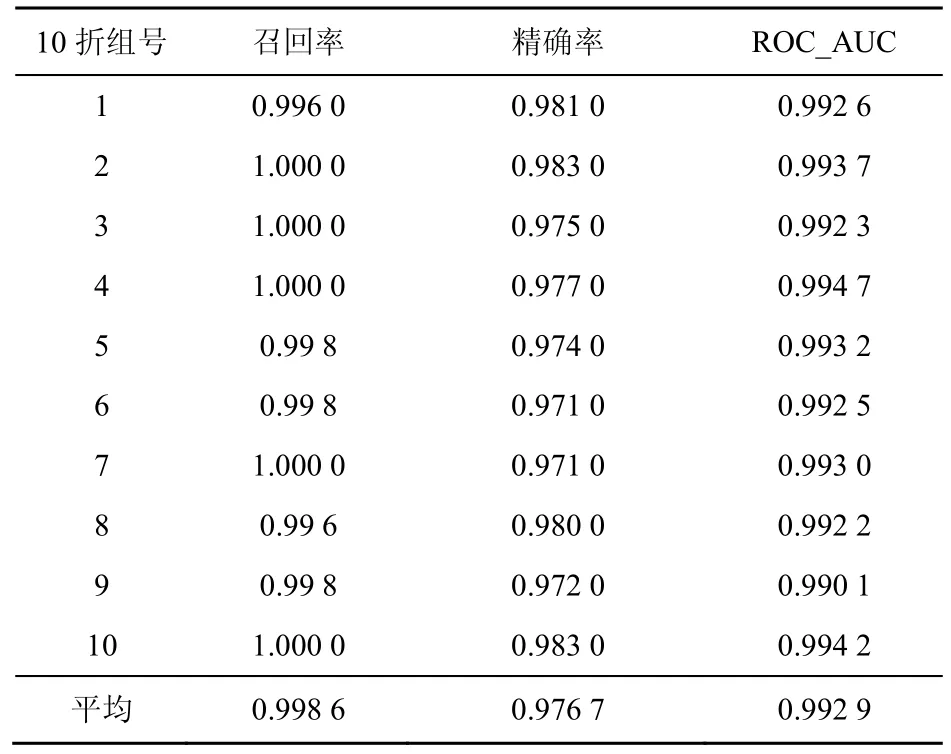
表2 Fast-flucos 分類器10 折驗證結果
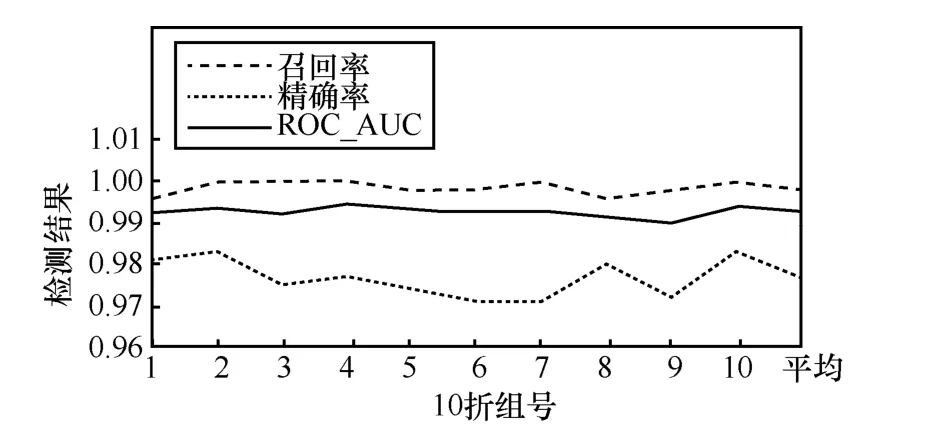
圖11 Fast-flucos 分類器10 折驗證結果
然后,在參考文獻中較知名且也同為針對Fast-flux 域名檢測的是文獻[13]提出的GRADE 方法,以此來進行對比實驗。GRADE 方法共使用4 個特征:不同的A記錄數量nA、不同的ASN 數量nASN、先前節點域名熵eDPN、往返時間標準差σRTT,再建立一個計算式:。利用真實編碼的遺傳算法并結合已知標簽的樣本確定5 個參數ω1、ω2、ω3、ω4和β的值,使當目標域名是Fast-flux 域名時對應的f(x)值均為正數,當目標域名是良性域名時對應的f(x)值均為負數。此外,又根據條件分別復現了檢測惡意域名最經典方法之一的EXPOSURE[18]和如何檢測Fast-flux 域名的文獻[19]中基于算法生成域名的檢測方法(AAGD,approach based on algorithmically generated domain)。使用相同的實驗數據,得到如圖12 所示的實驗對比結果。
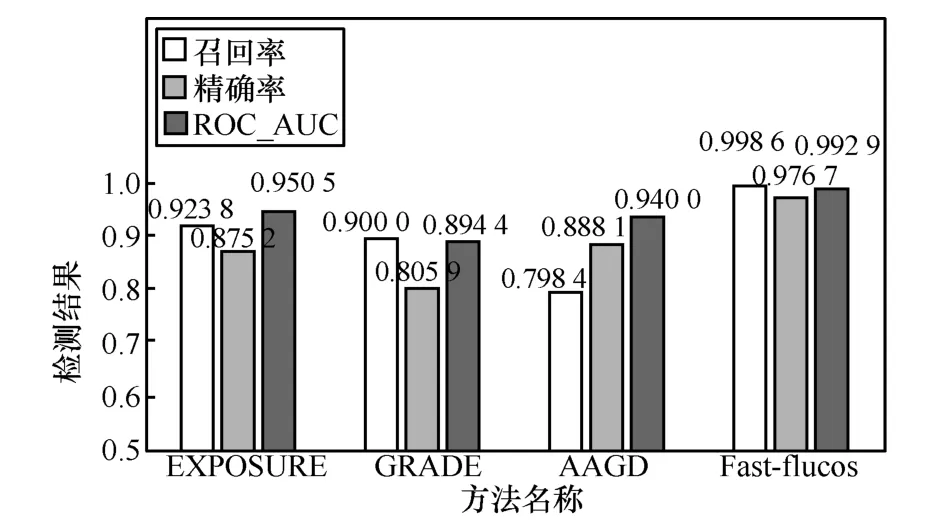
圖12 4 種方法的實驗對比結果
GRADE 方法在其原文中的準確率達到了98%,而在本實驗中的精確率卻較不理想。這說明該方法在穩定性方面稍弱一些,導致這一結果的可能原因簡述如下。
1)采用的特征過少。
2)所使用特征中的σRTT過分依賴于網絡環境的穩定性,若網絡稍有波動,則σRTT出現的偏差便會影響最終域名判定的結果。
對于EXPOSURE 的表現,很可能要歸咎于它所選用的特征對Fast-flux 域名的針對性不強。
導致AAGD 檢測效果較不理想的可能原因如下。
1)其DNS 流量數據來源于教育網環境,不能很好地適應常規網絡環境的DNS 流量。
2)雖然在特征提取方面考慮到了Fast-flux 域名,但是聚類的過程過于針對DGA 生成域名。
3)其在特征選擇環節并沒有在每組特征組合中都分別嘗試所有備選機器學習方法,可能錯失了更適合的機器學習方法。經實測發現,如果不使用SVM 算法,實際分類效果確實有了明顯的提升。
在Fast-flucos 中,根據域名解析國家或地區的頻次而生成的國家或地區向量表特征起到了很大作用,這可能與各個國家或地區的總體網絡普及度、網民數量以及網絡犯罪成本的不同有關。而Fast-flux 域名的解析國家或地區眾多,也恰恰使這種在解析國家或地區分布上的規律可以更加明顯地體現出來。
4.2 資源開銷
對各方法的內存與時間開銷進行對比,考慮到有些方法使用的特征需要在線獲取,如Fast-flucos的WHOIS 注冊者信息、GRADE 的σRTT等。而第三方網站又對用戶訪問頻率做出了一些限制,為了使算法的執行時間不被這些因素所影響,先將這些特征全部保存到本地,再使用前文的訓練數據集來執行每一個算法,得到了如表3 所示的運行結果。
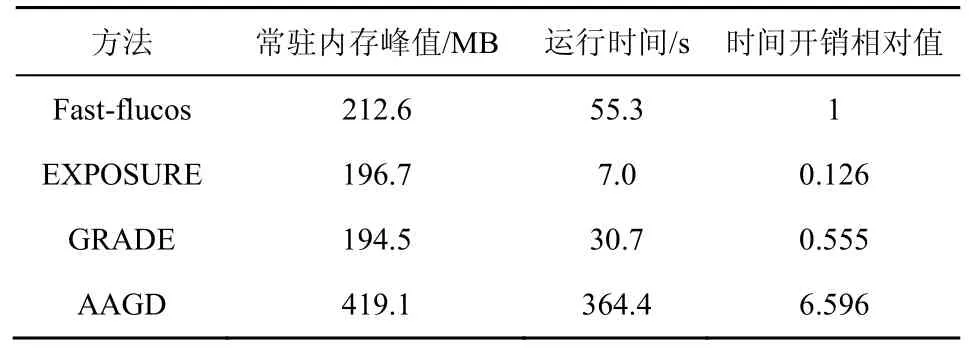
表3 不同檢測方法的資源開銷對比
為了使對比更加清晰,將Fast-flucos 的運行時間定為單位1,并以此折算出另外3 種方法的相對時間開銷。從表3 可以看出,除AAGD 外,其他3種方法的內存開銷大抵相同。AAGD 的高常駐內存峰值主要由于SVM 算法本身的內存占用就相對較高。另外,雖然EXPOSURE 的檢測效果略弱于Fast-flucos,但是在時間開銷上非常出色,而AAGD過長的時間開銷可能要歸咎于聚類的過程及運行速度相對較慢的SVM 算法。
4.3 實際測試
使用我國某主流通信運營商在上海地區于2017 年11 月 29 日的真實 DNS 流量來驗證Fast-flucos 的實際檢測效果,共輸出1 215 個域名,經第三方平臺查詢,并結合已有的Fast-flux 樣本,得到其中Fast-flux 域名一共有1 186 個,準確率約為98%,其中依靠“關聯匹配”發現的Fast-flux 域名有72 個,被誤判的域名約為29 個,主要由廣告服務網站域名等組成。這說明這兩類網站的域名在所選取的特征上可能也存在許多與Fast-flux 惡意域名相似之處,可以考慮作為未來工作的新方向。
5 結束語
因以往的Fast-flux 域名檢測方法在穩定性、針對性和對常規真實DNS 流量環境的普適性方面存在不足,提出了一種基于真實DNS 流量的Fast-flux惡意域名檢測方法——Fast-flucos。該方法由預處理、特征提取、分類器和關聯匹配4 個模塊組成。在預處理模塊加入了異常過濾步驟;在特征提取模塊加入了專門針對Fast-flux 域名檢測的D_Score、國家和地區向量表和時間向量表特征,共計提取506 個單特征;使用包括深度學習在內的多種機器學習方法進行實驗,確定最佳分類器和特征組合;關聯匹配模塊可以結合WHOIS 注冊者信息和一種簡單的字符串匹配算法借助分類器的輸出結果找出更多輸入DNS 流量中被漏檢的Fast-flux 域名。通過以上舉措,Fast-flucos 最終較好地彌補了上述不足。通過實驗與以往的方法進行檢測效果對比,發現Fast-flucos 在召回率、精確率和ROC_AUC 均高于另外3 種方法的前提下,其在內存開銷方面的表現與其他方法基本相同,僅在時間開銷上稍弱于EXPOSURE 和GRADE。最后使用我國某主流通信運營商在上海地區的真實DNS 流量進行了實際測試,準確率約為98%,這表明Fast-flucos 可以普遍適用于常規真實互聯網環境下的DNS 流量。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
意林原創版(2016年10期)2016-11-25 10:28:30
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
