
基于共享圖和部分復制策略的分布式存儲因果一致性模型
2020-06-06 00:54:34田俊峰楊萬賀龐亞南張俊濤
通信學報 2020年5期
田俊峰,楊萬賀,龐亞南,張俊濤
(1.河北大學網絡空間安全與計算機學院,河北 保定 071002;2.河北省高可信信息系統重點實驗室,河北 保定 071002)
1 引言
云存儲是當今互聯網服務的重要組成部分[1]。為了給用戶提供高效率和可擴展的服務,云存儲采取分布式數據存儲方式,將數據中心部署在不同位置實現大數據存儲,數據中心之間的數據一致性成為保證數據可用的關鍵[2]。
數據一致性一般分為強一致性和弱一致性[3]。在理想情況下,對任何數據的更新在其所有副本中立即可見稱為強一致性。強一致性雖然有簡單的語義,但是引發了高時延和不允許網絡分區現象;多個節點的狀態沒有充分同步但仍可以處理讀寫操作稱為弱一致性。弱一致性對數據的及時更新沒有要求,難以為用戶提供最新的數據[4]。因果一致性是介于強一致性和弱一致性中間的協議[5],既可以有效解決高時延和網絡分區等問題,也能保證數據的及時更新。
目前,基于因果一致性協議的模型成為構建地理復制數據存儲中有吸引力的模型[6]。在地理復制數據存儲中,分布在不同地理位置的數據中心通過網絡時鐘協議(NTP,network time protocol)更新當前的節點時鐘,不同數據中心利用數據復制策略完成數據同步[7]。Agrawal 等[8]對分布式存儲系統中的數據復制策略進行了分類,詳細闡述了地理復制模型中的數據一致性方法,數據復制策略分為完全復制策略和部分復制策略。
基于完全復制策略的因果一致性模型要求每個數據中心都存儲完整的數據集,本地數據中心寫入數據需要向其他所有遠程數據中心同步數據[9]。例如,文獻[10]模型在完全復制策略的基礎上,僅依靠單一標量時間戳實現對因果關系的追蹤。文獻[11]提出通用穩定向量和混合邏輯時鐘相結合的全局穩定策略,提高了模型的吞吐量。文獻[12]提出數據中心穩定向量和混合邏輯時鐘相結合的全局穩定策略,解決了操作時延問題,降低了數據的更新可見時延。但數據中心穩定向量中的條目包含所有數據中心,增加了元數據開銷,數據中心之間的同步開銷大。
隨著數據中心存儲的數據量迅速增長,為降低數據中心之間的同步開銷,基于部分復制策略的因果一致性模型得到了廣泛應用[13]。基于部分復制策略的因果一致性模型要求每個數據中心存儲完整數據集的子集,本地數據中心寫入數據僅需向部分遠程數據中心同步新數據。文獻[14]模型中的每個數據中心都設置序列化器,利用時間戳對操作進行序列化,實現了操作的高并發性,并降低了操作時延。但是,該模型取消了數據中心之間的全局穩定。文獻[15]模型利用共享樹表示數據中心之間的拓撲關系和部分元數據作為標簽,數據中心之間的所有更新操作都通過共享樹和標簽實現,提高了數據的可見性和系統的吞吐量,但是造成了數據中心之間的元數據傳播開銷。Xiang 等[16]提出的模型是對數據中心之間的全局穩定方法進行擴展,利用全局穩定時間戳和物理時鐘的全局穩定策略實現模型的全局穩定性。該模型降低了元數據開銷,提高了系統的吞吐量,但會產生操作時延,從而造成較高的更新可見時延。
為了有效降低操作時延并權衡元數據傳播開銷和遠程更新可見性能,本文提出一種基于共享圖和部分復制策略的分布式存儲因果一致性模型(CCSGPR,causal consistent model for distributed data stores based on shared graph and partial replication strategy),利用共享圖表述數據中心之間的拓撲關系,通過共享穩定向量和混合邏輯時鐘相結合的全局穩定策略實現因果一致性。本文主要工作如下。
1) CCSGPR 使用部分復制策略實現分布式數據存儲,每個數據中心存放完整數據集的子集,利用共享圖表示數據中心之間的鄰接關系,元數據通過同步消息和心跳信息傳播,僅需在有鄰接關系的部分數據中心傳播,降低元數據傳播開銷和數據遠程更新可見時延。
2) 提出一種全局穩定策略,該策略使用混合邏輯時鐘標記操作的時間戳,可為新數據標記滿足因果依賴關系的混合邏輯時間戳,避免寫入數據操作時延。同時,在混合邏輯時鐘的基礎上提出了共享穩定向量,該向量僅由2 個時間戳構成,這降低了元數據開銷,通過選取遠程數據中心中時間戳的最小值為遠程更新穩定的界限,避免讀取數據操作時延。
2 背景介紹
2.1 基于部分復制策略的分布式模型
分布式模型采取多版本鍵值存儲方式,一個鍵對應一個版本鏈,版本鏈包含鍵的多個版本,每個版本又包括鍵對應的值和元數據,寫(PUT)操作會為鍵的版本鏈增加一個新版本,模型定期處理版本鏈中的舊版本[17],數據存放在不同的數據中心,用戶可以在不同的數據中心完成數據的寫入、更新或下載[18]。基于部分復制策略的分布式模型如圖1 所示。由圖1 可知,完整數據集被分為m個子集,每個數據中心存儲完整數據集的子集;每個數據中心由n個分區(服務器)構成,所存儲的數據子集根據哈希函數按鍵分配到n個分區。服務器完成寫入數據操作后,為對應的鍵創建一個新版本,新版本僅需同步到部分數據中心,數據中心之間通過點對點FIFO(first in first out)通道進行通信。
基于部分復制策略的分布式模型包含以下2 個基本操作。
1) PUT→(k,v)。PUT 操作將值v賦給鍵k標識的數據。若鍵k標識的數據存在,創建一個值為v的新版本;否則,創建一個鍵為k且初始值為v的新數據。
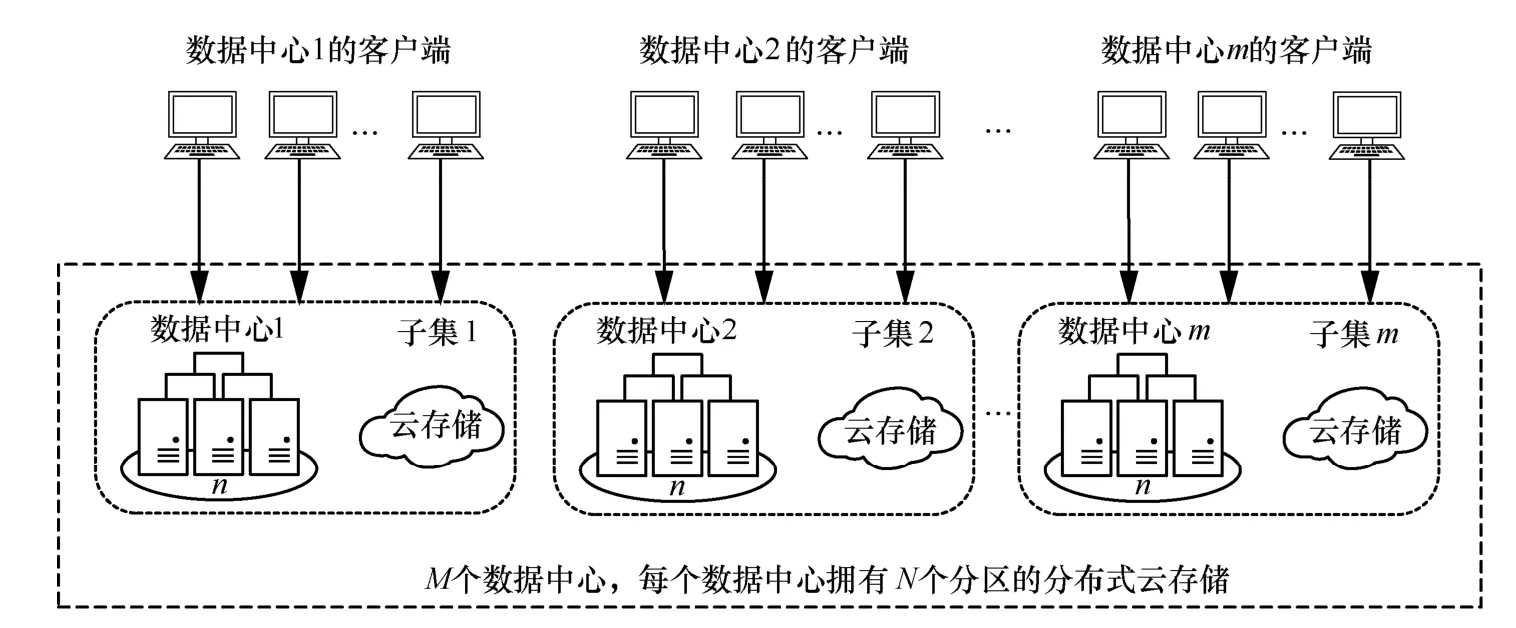
圖1 基于部分復制策略的分布式模型
2) val←GET(k)。GET 操作返回鍵k標識的數據的值v,返回的值v需滿足因果一致性。
2.2 因果一致性
因果一致性根據 2 個操作之間的happens-before 關系[19]定義,要求服務器返回的值與因果關系定義的順序一致。對于2 個任意操作a1和a2,若滿足以下條件,稱a1因果依賴于a2,記作a1→a2。
1)a1和a2是同一線程中的操作,a1發生在a2之前。
2)a1為寫數據操作,a2為讀數據操作,且a2讀a1寫的值。
3) 存在其他操作a3,其中a1→a3,a3→a2。
定義1數據穩定性。若鍵k標識的數據可以被客戶端c讀取,且該數據的依賴項也可被客戶端c讀取,則稱該數據具有穩定性。
定義2全局穩定性。分布式存儲模型劃定一個時間戳界限,該時間戳范圍內的所有數據都具有穩定性,則稱分布式存儲模型在該時間戳具有全局穩定性。
定義3更新可見時延。鍵k標識的數據在其原始數據中心寫入的時刻到該數據在此數據中心具有穩定性的時刻間隔稱為更新可見時延。
定義4并發操作。存在2 個操作a1和a2,若a1既不因果依賴于a2,a2也不因果依賴于a1,則稱a1和a2為并發操作。
定義5沖突操作及其處理規則。若a1和a2是對鍵k標識的同一數據進行并發寫操作,則稱a1和a2為沖突操作。沖突操作造成鍵k標識的同一數據產生2 個相互沖突的版本,相互沖突的版本按照不同的順序同步到遠程數據中心,這會造成數據中心之間的不一致性問題。基于部分復制策略的分布式模型使用最后更新為準(last-writer-wins)規則[20]處理數據的沖突操作。該規則規定,對于鍵k標識的同一數據的2 個寫入操作,規定時間戳大的操作為后發生的,從而寫入的值為時間戳大的操作所確定的值,若2 個操作的時間戳相等,則通過數據的寫入數據中心ID 來解決沖突。
3 共享圖
共享圖(shared graph)是無權無向圖,由頂點的有窮非空集合和頂點之間邊的集合組成,記作Gs=(Vs,Es),其中Vs={1,2,3,...,n}為頂點集合;Es為邊的集合,包含實線邊和虛線邊2 種,實線邊集合記作E1(Gs),虛線邊集合記作E2(Gs)。CCSGPR使用共享圖表述分布式結構,頂點i∈Vs代表數據中心i;若數據中心i和數據中心j存在共享鍵,則存在實線邊(i,j)∈E1(Gs),若存在客戶端c可以訪問數據中心i和數據中心j,則存在虛線邊(i,j)∈E2(Gs)。
Ni表示與數據中心i存在實線連接的數據中心集合;Pi表示與數據中心i存在虛線連接的數據中心集合;Ki表示存儲在數據中心i的鍵的集合;Kij=Ki∩Kj表示數據中心i和數據中心j的共享鍵。數據中心鄰接關系的共享圖如圖2 所示。由圖2 可知,共享圖Gs由i、V1、V2、V3、V4、V5頂點組成,2 個數據中心的共享鍵標記在圖中的實線邊上,存在客戶端c可以訪問數據中心i、V2、V3和V5,因此,頂點i、V2、V3和V5之間存在虛線邊,如Ni={V1,V4},Pi={V2,V3,V5},。
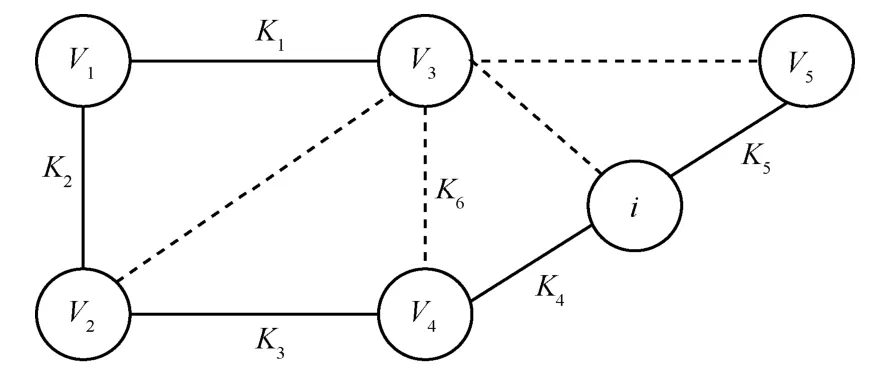
圖2 數據中心鄰接關系的共享圖
在部分復制數據存儲中,每個數據中心只存放完整數據集的任意子集,本文利用共享圖表述數據中心之間的鄰接關系,取消數據中心之間額外的同步開銷,本地數據中心i寫入新數據僅需向Ni集合中其他遠程數據中心發送數據同步消息和心跳信息,若數據中心i存儲的子集不包含待讀取的數據,則向Pi集合中其他數據中心發送遷移操作。元數據利用數據同步消息和心跳信息實現傳播,通過共享圖拓撲結構,元數據不需要傳播到所有的數據中心,同時,允許不同數據中心的服務器之間直接傳播數據同步消息和心跳信息,降低元數據同步開銷,以提供高吞吐量并降低遠程更新可見時延。
4 全局穩定策略
目前,基于部分復制策略的因果一致性模型取消了傳統的依賴項檢查信息,通過NTP 實現服務器的同步,并利用全局穩定時間戳(GST,global stable timestamp)和物理時鐘相結合的全局穩定策略實現模型的全局穩定性(見2.2 節的定義2)。
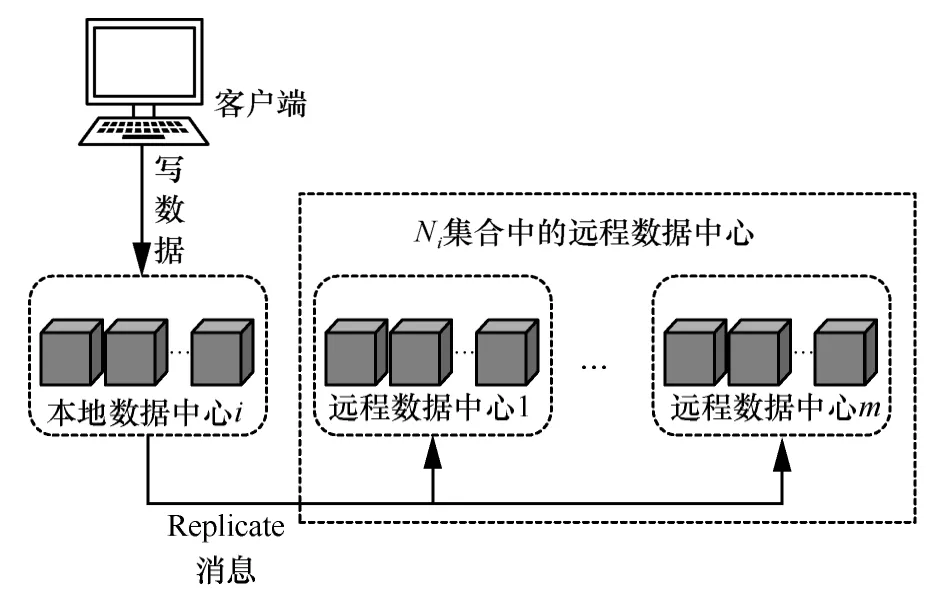
較目前的因果一致性模型,CCSGPR 提出了一種共享穩定向量和混合邏輯時鐘相結合的全局穩定策略。首先,CCSGPR 用混合邏輯時鐘(HLC,hybrid logical clock)代替物理時鐘來跟蹤時間的進展,完成時間戳的更新。混合邏輯時鐘結合了物理時鐘和邏輯時鐘[21],其時間戳t由一個物理組件t.p和一個邏輯組件t.l 組成,記作 其次,記某數據的寫入時間戳為t,因果一致性模型全局穩定的界限為T,規定僅當t CCSGPR 在共享圖拓撲結構的基礎上,利用混合邏輯時鐘有效避免了寫操作時延,同時,共享穩定向量僅包含2 個時間戳,其根據選取最小值的原則,避免了讀取操作時延,降低了元數據開銷和數據中心之間的同步開銷。 CCSGPR 協議是在分布式存儲中穩定運行的通信協議,在操作滿足因果一致性要求的前提下,為用戶提供安全快速的寫入、查詢和存儲服務。 圖3 CCSGPR 中數據中心之間的心跳同步 元數據是描述數據屬性的信息,用來支持歷史數據、資源查找、文件記錄、指示存儲位置等功能,元數據開銷和效率是衡量系統性能的重要指標,如Facebook 中,元數據比數據本身大,大型元數據會增加通信和存儲開銷[22]。分布式模型中,采取多版本鍵值存儲方式,用d表示元組,該元組包括 客戶端c維持SSVc,SSVc僅由2 個時間戳組成。客戶端c還維持依賴向量(DV,dependency vector)DVc,存儲遠程數據中心的依賴項,以保證后續操作滿足因果一致性。 CCSGPR 協議中包含6 個基本操作:GET 操作、PUT 操作、數據同步操作、更新共享穩定向量操作、心跳機制操作和遷移操作。 5.2.1 GET 操作 客戶端c發起讀取數據操作,存儲該數據的服務器響應操作,如算法1 所示。其具體流程如下,客戶端c發起 算法1數據中心m中客戶端c的操作 5.2.2 PUT 操作 客戶端c發起寫數據操作,服務器響應寫操作,如算法2 所示。其具體流程為,客戶端c發起 算法2服務器響應客戶端c的請求操作 5.2.3 數據同步操作 分布式存儲系統由不同節點(數據中心)協同為用戶提供存儲、查詢服務的平臺,所以服務器完成PUT 操作后,其他數據中心要同步最新數據,即本地數據中心i寫入新數據后,需向Ni集合中的數據中心發送同步數據信息。服務器間的數據同步如圖4 所示。由圖4 可知,數據中心i中的服務器發送Replicate 消息到其他數據中心(算法2 中的Replicate 算法),Ni集合中的數據中心接收Replicate消息后,服務器將數據的新版本增加到該數據的版本鏈中,更新其PV 中服務器對應的條目,即設置,完成服務器間的數據同步。 圖4 服務器間的數據同步 5.2.4 更新共享穩定向量操作 一個數據中心內的服務器定期更新全局穩定向量SSV,規定每過θ時間間隔(θ的具體時間在仿真實驗中設置),服務器之間彼此共享其分區向量PV,并計算SSV 為所有服務器的分區向量PV中的最小值(算法3 的更新共享穩定向量算法),從而確保該數據中心數據穩定界限內的數據在所有服務器內可讀。 5.2.5 心跳機制操作 算法3服務器的時鐘管理和心跳機制操作 5.2.6 遷移操作 如算法2 所示,客戶端c發起讀取數據操作,數據中心m作為響應客戶端c操作的本地數據中心,若數據中心m存儲的數據子集不包含待讀取的數據,則根據共享圖表示的數據中心之間的鄰接關系,向Pm集合中其他數據中心發送遷移操作,完成讀取數據操作。其具體流程為,數據中心m的服務器向Pm集合中的數據中心發送遷移操作請求,包括數據中心的ID 和;數據中心i中的服務器響應遷移操作請求,更新其共享穩定向量,完成遷移操作。 本節對現有的因果一致性模型進行對比分析,表1 為各因果一致性模型的比較。文獻[10]模型和文獻[11]模型基于完全復制策略,較文獻[10]模型,文獻[11]模型使用混合邏輯時鐘與通用穩定向量相結合的全局穩定策略,降低了操作時延,但增加了元數據開銷。文獻[10]模型和文獻[16]模型都使用物理時鐘與全局穩定時間戳相結合的全局穩定策略,較文獻[10]模型,文獻[16]模型使用部分復制策略,有效降低了遠程更新可見時延,但操作時延仍然較高。CCSGPR 基于部分復制策略,使用混合邏輯時鐘與共享穩定向量相結合的全局穩定策略,在保證元數據開銷小的基礎上,有效降低了操作時延,定量對比結果詳見以下實驗內容。 CCSGPR 使用Java 實現,采用Berkeley DB 進行鍵值數據的存儲和檢索。Berkeley DB 數據庫是以key-value 為結構的嵌入式數據庫,既有關系型數據庫中的完整 ACID(Atomicity,Consistency,Isolation,Durability)事務語義支持,也提供NoSQL中簡單的數據庫編程接口。為驗證本文所提方法的有效性,在數據一致性HBU-Cluster 平臺上實現分布式鍵值存儲仿真實驗,并與經典的基于完全復制策略文獻[11]模型和基于部分復制策略文獻[16]模型進行實驗對比。數據一致性HBU-Cluster 平臺是項目組為因果一致性測試設計的仿真平臺,該平臺為分布式鍵值存儲管理框架,使用Google 的Protocol Buffer將數據因果一致性協議結構化,并集成Yahoo的YCSB(Yahoo! Cloud Serving Benchmark)基準測試模塊作為性能測試工具。仿真實驗中服務器的配置是Windows10 x64,Intel Core i5-4590,3.3 GHz,16.00 GB 內存,256 GB 固態磁盤存儲。根據現有模型的性能測試,仿真實驗采取傳統的測試方法從模型吞吐量、操作響應時間和遠程更新可見時延3 個方面進行定性對比。 根據實際基于Internet 的應用設置,在仿真實驗中設置默認參數如下:數據中心數目為4,分區數目為6,讀寫比例為3:1。客戶端依據uniform 記錄選擇策略訪問分區數據,服務器之間采取NTP同步方法,每次實驗前都同步時鐘。CCSGPR 中的混合邏輯時間戳使用64 位編碼,其中48 位設置為物理部分,16 位設置為邏輯部分,通過這些設置,混合時間戳可以編碼多達216個邏輯事件,可以跟蹤到微秒的物理時間,有效避免了由于邏輯部分已經達到最大值,但又必須增加其邏輯部分以保證因果一致性導致分區發生的阻塞等待。規定分區之間每5 ms 交換分區向量PV,若分區在1 ms 內未接收更新數據操作和同步數據操作,則該分區接收心跳信息。 吞吐量是單位時間內模型更新鍵值的總量,是衡量模型性能的一項重要指標。本節實驗采取分別增加數據中心和分區數目的傳統實驗方式評估模型的吞吐量性能。 首先,分析數據中心數對模型吞吐量的影響,控制分區變量,設置每個數據中心的分區數為6,客戶端向本地數據中心發送讀寫請求,數據中心之間定期同步數據。圖5(a)描述了數據中心數2~12 所對應吞吐量的變化情況,隨著數據中心數的增加,文獻[11]模型的吞吐量變化明顯,而文獻[16]模型和CCSGPR模型的吞吐量變化較小。其原因是文獻[11]模型基于完全復制策略,數據中心增加導致數據同步開銷增大,從而降低了模型的吞吐量。文獻[16]模型和CCSGPR 基于部分復制策略,僅模型中的部分數據中心同步數據,模型的吞吐量變化不大。當數據中心數為8 時,CCSGPR 比文獻[11]模型提高了23.47%的吞吐量性能,比文獻[16]模型提高了14.43%。與文獻[11]模型相比,文獻[16]模型和CCSGPR 使用部分復制策略,提高了模型的吞吐量。與文獻[16]模型相比,CCSGPR 的全局穩定策略中使用混合邏輯時鐘避免了操作時延,實現了更高的吞吐量。 表1 不同因果一致性模型的比較 其次,分析分區數對模型吞吐量的影響,控制數據中心數變量,設置數據中心數為4,改變數據中心的分區數量。圖5(b)描述了分區數2~32 對應吞吐量的變化情況,隨著分區數的增加,模型的吞吐量呈上升趨勢,吞吐量性能提高了18.93%。與文獻[11]模型和文獻[16]模型比,CCSGPR 利用共享圖表述數據中心之間的鄰接關系,其分區向量PV 僅存儲具有鄰接關系的部分數據中心元數據,元數據通過同步消息傳播,降低了元數據開銷,實現了吞吐量的提升。 根據傳統測試操作響應時間的實驗方式,本節實驗分兩部分來測量模型操作的響應時間,第一部分分區之間不設置時鐘偏差,通過改變數據中心分區數的方式觀察模型操作響應時間的變化情況;第二部分在一臺物理設備上部署2 個虛擬服務器,以循環方式發送2 000 個操作請求,人為地控制服務器之間的時鐘偏差值,準確分析服務器之間的時鐘偏差對操作響應時間的影響。 圖5 不同數據中心數和不同分區數的吞吐量 圖6 不同分區數和不同時鐘偏差的操作響應時間 圖6(a)描述了模型中操作響應時間隨分區數的變化情況,圖6(b)描述了模型中操作響應時間隨分區之間的時鐘偏差值的變化情況。隨著分區數和分區之間的時鐘偏差值的增加,模型的操作響應時間也會增加,與文獻[11]模型和CCSGPR 相比,文獻[16]模型的全局穩定策略中使用物理時鐘,受分區之間的時鐘偏差影響大,產生了較高的操作時延。文獻[11]模型和CCSGPR 的全局穩定策略中使用混合邏輯時鐘,當分區之間存在時鐘偏差時,可為操作提供符合因果依賴關系的時間戳,有效避免了操作時延。與文獻[11]模型比,CCSGPR 的分區向量中僅同步共享圖Ni集合中的數據中心所對應分區的元數據,受分區總數目變化影響較小,其共享穩定向量規定選取遠程數據中心中時間戳的最小值,劃定數據可讀的下限,降低了11.72%操作響應時間。 遠程更新可見性時延指的是本地數據中心寫入的數據同步到遠程數據中心的時間間隔,在衡量模型性能中也占據著重要地位,即使只有幾毫秒的時延,也會導致讀取錯誤的過時數據而造成異常。 遠程更新可見性時延是由服務器接收的最小時鐘值決定,首先通過人為地控制服務器之間的時鐘偏差值的方式,分析時鐘偏差對遠程更新可見時延的影響。其次服務器之間不設置時鐘偏差,增加模型中數據中心數目,觀察遠程更新可見時延的變化情況。 圖7(a)描述了遠程更新可見時延隨時鐘偏差值的變化情況,圖7(b)描述了遠程更新可見時延隨數據中心數目的變化情況。結果表明,遠程更新可見性時延受服務器之間的時鐘偏差影響,隨時鐘偏差值呈線性增長,其節點接收心跳信息值的數量隨數據中心數線性增加,遠程更新可見時延也會增加。與文獻[11]模型比,文獻[16]模型和CCSGPR 基于部分復制策略,遠程更新僅在部分數據中心之間同步,降低了遠程更新可見時延。較文獻[16]模型,CCSGPR 降低了28.57%的遠程更新可見時延。文獻[11]模型中使用通用穩定向量UST,一個數據中心對應向量中的一個時間戳,遠程更新規定所有遠程數據中心都完成同步才可見,模型的遠程更新可見性時延取決于本地數據中心同步到所有遠程數據中心的時間,受數據中心數影響較大。文獻[16]模型中使用全局穩定時間戳GST,模型的遠程更新可見性時延取決于本地數據中心(即數據寫入的數據中心)同步到其時延最大的數據中心的時間,數據中心數的增加會產生更小的全局穩定時間戳,從而造成遠程更新可見時延增加。CCSGPR 中使用SSV,向量中僅包括本地數據中心的時間戳t1和遠程數據中心的時間戳t2,模型的遠程更新可見性時延取決于本地數據中心i與共享圖Ni集合中數據中心同步的時間。由于CCSGPR 模型其SSV 中遠程數據中心時間戳t2的選取最小值原則,隨著數據中心數的增大,CCSGPR 的遠程更新可見時延會略高于文獻[16]模型。 圖7 不同時鐘偏差和不同數據中心數的遠程更新可見時延 本文提出了基于共享圖和部分復制策略的分布式存儲因果一致性模型CCSGPR,該模型以部分復制策略為前提,利用共享圖表示數據中心間的鄰接關系。此外,利用混合邏輯時鐘標記符合因果關系的時間戳,共享穩定向量選取遠程數據中心心跳時間戳的最小值作為數據穩定的下限,以降低操作時延。通過數據一致性平臺對CCSGPR 進行吞吐量、操作響應時間和遠程更新可見時延驗證,在降低操作響應時間的同時,權衡了遠程更新可見性能和元數據開銷。但CCSGPR 未考慮敏感數據惡意篡改等安全問題,實現可信約束下的分布式存儲因果一致性模型是未來要做的工作。5 CCSGPR 協議
5.1 元數據
5.2 操作






6 仿真實驗與結果分析
6.1 對比分析
6.2 仿真實驗設置
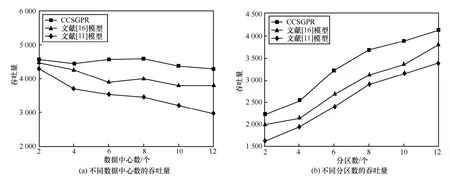
6.3 吞吐量

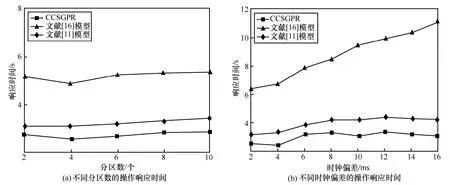
6.4 操作響應時間
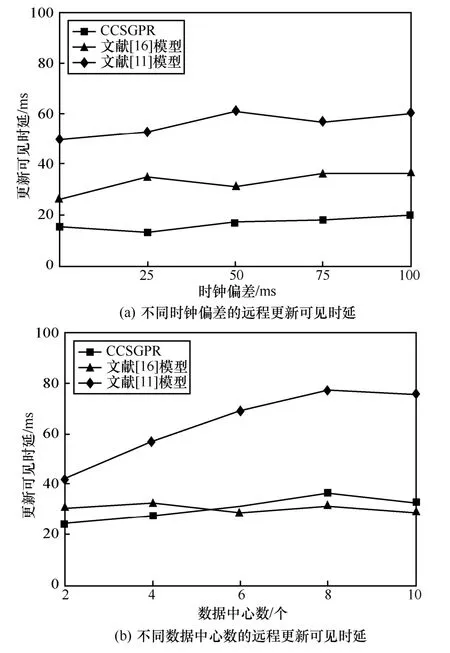
6.5 遠程更新可見時延
7 結束語
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38公民與法治(2022年5期)2022-07-29 00:47:28教學考試(高考物理)(2021年5期)2021-11-08 10:31:22歷史教學問題(2021年4期)2021-11-05 07:02:34中醫眼耳鼻喉雜志(2021年1期)2021-07-22 07:38:14中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50數學物理學報(2020年2期)2020-06-02 11:29:24中國公共安全(2017年11期)2017-02-06 05:28:08光學精密工程(2016年6期)2016-11-07 09:07:19燕山大學學報(2015年4期)2015-12-25 02:19:49
