
基于鏈路容量的多路徑擁塞控制算法
2020-06-06 00:54:36王竹袁青云郝凡凡房梁李鳳華
通信學(xué)報(bào) 2020年5期
王竹,袁青云,郝凡凡,房梁,李鳳華
(1.中國(guó)科學(xué)院信息工程研究所,北京 100093;2.中國(guó)科學(xué)院大學(xué)網(wǎng)絡(luò)空間安全學(xué)院,北京 100049)
1 引言
隨著移動(dòng)互聯(lián)網(wǎng)的迅速發(fā)展及終端接入模塊的微型化,越來(lái)越多的終端設(shè)備具備(如電子發(fā)票終端、多模移動(dòng)通信終端等)多種網(wǎng)絡(luò)接入模式(如Wi-Fi、4G/5G、衛(wèi)星通信等)。用戶可根據(jù)不同網(wǎng)絡(luò)場(chǎng)景下的不同需求,通過(guò)不同接入方式使用電子發(fā)票、移動(dòng)通信、視頻會(huì)議等網(wǎng)絡(luò)信息服務(wù)。然而目前傳輸控制協(xié)議(TCP,transmission control protocol)模式僅可利用其中一種網(wǎng)絡(luò)接口進(jìn)行數(shù)據(jù)傳輸,這降低了網(wǎng)絡(luò)資源利用率,無(wú)法滿足海量電子發(fā)票數(shù)據(jù)、音視頻等高效傳輸要求。因此,為了充分利用網(wǎng)絡(luò)資源,多路徑傳輸技術(shù)應(yīng)運(yùn)而生。國(guó)際互聯(lián)網(wǎng)工程任務(wù)組(IETF,Internet Engineering Task Force)于2009 年提出多路徑傳輸協(xié)議(MPTCP,multipath TCP)[1],該協(xié)議在繼承TCP 的基礎(chǔ)上,利用多接口技術(shù)建立多條鏈路,提升網(wǎng)絡(luò)帶寬利用率,降低服務(wù)中斷風(fēng)險(xiǎn)。近年來(lái),MPTCP 的研究逐步從傳統(tǒng)的Internet拓展到數(shù)據(jù)中心[2]、云平臺(tái)[3]、衛(wèi)星網(wǎng)絡(luò)[4]等新的應(yīng)用場(chǎng)景。在工業(yè)界,MPTCP 已得到初步應(yīng)用,Linux 發(fā)行版已實(shí)現(xiàn)MPTCP,三星Galaxy 系列智能手機(jī)、iPhone Siri 等產(chǎn)品均支持MPTCP。理論與工程的相互促進(jìn)為MPTCP 的完善注入了源源不斷的動(dòng)力。
與傳統(tǒng)TCP 相同,擁塞控制是MPTCP 的關(guān)鍵技術(shù)之一,對(duì)MPTCP 的性能有著重要影響。因此,需要對(duì)MPTCP 的應(yīng)用場(chǎng)景進(jìn)行分析,對(duì)MPTCP的擁塞控制進(jìn)行優(yōu)化,從而實(shí)現(xiàn)高效、可靠的多路徑傳輸。設(shè)計(jì)MPTCP 擁塞控制算法會(huì)面臨兩方面挑戰(zhàn):在多路徑傳輸環(huán)境下,每條子流均單獨(dú)維護(hù)擁塞窗口,導(dǎo)致MPTCP 多條流會(huì)過(guò)多地?fù)屨紟挘瑖?yán)重時(shí)會(huì)導(dǎo)致TCP 流無(wú)法正常工作;在鏈路質(zhì)量差異較大的異構(gòu)網(wǎng)絡(luò)環(huán)境下,多路徑傳輸穩(wěn)定性變差,帶寬利用率下降。
近年來(lái),學(xué)者在多路徑擁塞控制算法方面提出了多種解決方案,包括基于分組丟失的多路徑擁塞控制算法[5-7]、基于時(shí)延的多路徑擁塞控制算法[8-10]、基于瓶頸公平性的多路徑擁塞控制算法[11-13]等。但上述算法存在無(wú)法分辨噪聲、分組丟失嚴(yán)重、帶寬競(jìng)爭(zhēng)能力弱、共享瓶頸子流集合誤判等缺陷。
為解決現(xiàn)有工作的不足,滿足海量電子發(fā)票數(shù)據(jù)及相關(guān)用戶數(shù)據(jù)傳輸?shù)母咝裕疚脑O(shè)計(jì)了適用于反饋調(diào)節(jié)擁塞的多路徑擁塞控制框架,在BBR(bottleneck bandwidth and round-trip propagation time)算法[14]反饋調(diào)節(jié)擁塞窗口和發(fā)送速率的思想基礎(chǔ)上,通過(guò)建立M/M/1 緩存隊(duì)列模型調(diào)節(jié)接收端緩存隊(duì)列對(duì)發(fā)送端吞吐量進(jìn)行約束,實(shí)現(xiàn)了基于鏈路容量的多路徑擁塞控制(MPLC,multipath congestion control based on link capacity)算法,提升了多路徑傳輸?shù)膸捓寐剩WC了多路徑傳輸公平性。本文主要貢獻(xiàn)如下。
1) 設(shè)計(jì)了多路徑擁塞控制框架,將擁塞控制狀態(tài)和TCP 狀態(tài)分離,便于多級(jí)反饋調(diào)節(jié)擁塞的多路徑擁塞控制算法的設(shè)計(jì)與實(shí)現(xiàn)。
2) 設(shè)計(jì)了MPLC 算法,將BBR 算法中根據(jù)鏈路容量反饋調(diào)節(jié)發(fā)送窗口和發(fā)送速率的思想引入多路徑擁塞控制,提升了多路徑傳輸帶寬利用率。
3) 設(shè)計(jì)了M/M/1 緩存隊(duì)列模型,通過(guò)調(diào)節(jié)接收端緩存隊(duì)列對(duì)發(fā)送端吞吐量進(jìn)行約束,解決了多路徑傳輸占用帶寬過(guò)高的問(wèn)題,保證了MPLC 算法公平性。
4) 在NS3(Network Simulator Version 3)仿真平臺(tái)上實(shí)現(xiàn)了MPLC 算法,實(shí)驗(yàn)結(jié)果證明,MPLC算法實(shí)現(xiàn)了MPTCP流與TCP流競(jìng)爭(zhēng)帶寬資源的公平性,比BALIA(balanced linked adaptation)算法[15]的帶寬利用率提升了9.5%,比EWTCP(equally weighted TCP)算法[16]的響應(yīng)時(shí)間減少了1.25 s。
2 相關(guān)工作
隨著多路徑傳輸?shù)目焖侔l(fā)展,多路徑擁塞控制面臨的問(wèn)題引起了研究者的廣泛關(guān)注。本節(jié)主要對(duì)現(xiàn)有基于分組丟失、基于時(shí)延、基于瓶頸公平性的多路徑擁塞控制算法,以及其他方式的多路徑擁塞控制算法進(jìn)行介紹。
基于分組丟失的多路徑擁塞控制算法[5-7]根據(jù)鏈路是否發(fā)生分組丟失來(lái)判斷網(wǎng)絡(luò)擁塞狀況。Wischik 等[5]提出semi-coupled 擁塞控制算法,基本思想是通過(guò)多路徑總擁塞窗口和侵略因子調(diào)整子流擁塞窗口增長(zhǎng)模式,實(shí)現(xiàn)負(fù)載均衡,但不足是假設(shè)子流往返時(shí)延(RTT,round-trip time)相同。考慮到子流RTT 差異對(duì)其吞吐量的影響,Raiciu 等[6]提出LIA(linked increase algorithm),在計(jì)算聯(lián)合擁塞窗口時(shí)通過(guò)引入權(quán)重因子,動(dòng)態(tài)調(diào)整子流對(duì)帶寬侵占能力,但沒(méi)有對(duì)權(quán)重因子做出限制。當(dāng)權(quán)重因子較大時(shí),LIA 會(huì)侵占過(guò)多的帶寬資源。Khalili 等[7]在LIA 的基礎(chǔ)上提出OLIA(opportunistic linked increase algorithm),從最優(yōu)化資源池和均衡擁塞響應(yīng)能力角度出發(fā),為優(yōu)質(zhì)路徑提供更大的擁塞窗口變化加速度,從而使資源得到更充分的利用。該算法對(duì)網(wǎng)絡(luò)狀態(tài)變化反應(yīng)較快,易于侵占過(guò)多帶寬資源,TCP 友好性較差。
基于時(shí)延的多路徑擁塞控制算法根據(jù)鏈路中數(shù)據(jù)分組傳輸?shù)腞TT 變化來(lái)判斷網(wǎng)絡(luò)擁塞狀態(tài)。Cao 等[8]將基于時(shí)延變化估計(jì)網(wǎng)絡(luò)中緩存的數(shù)據(jù)分組數(shù)量來(lái)調(diào)節(jié)擁塞窗口的思想引入MPTCP 中,實(shí)現(xiàn)了較好的擁塞均衡,但該算法與其他算法共存時(shí)帶寬競(jìng)爭(zhēng)能力較弱。Gonzalez 等[9]通過(guò)引入加性增長(zhǎng)乘性減少策略,設(shè)計(jì)了混合時(shí)延的多路徑擁塞控制算法,增強(qiáng)了帶寬競(jìng)爭(zhēng)能力,但帶寬利用率低于其他多路徑擁塞控制算法。Li 等[10]在綜合考慮時(shí)延和吞吐量對(duì)擁塞窗口影響的基礎(chǔ)上,設(shè)計(jì)了最小化子流時(shí)延差異和基于遺傳算法的速率分配方案,提升了吞吐量,但與其他擁塞控制算法相比,難以保證算法公平性。
基于瓶頸公平性的多路徑擁塞控制算法通過(guò)瓶頸檢測(cè)來(lái)區(qū)分共享瓶頸子流集合與非共享瓶頸子流集合,再對(duì)共享瓶頸子流集合與非共享瓶頸子流集合采取不同的擁塞控制策略。Hassayoun 等[11]提出基于瓶頸公平性的動(dòng)態(tài)窗口耦合算法,該算法通過(guò)檢測(cè)子流分組丟失相關(guān)程度,劃分共享瓶頸帶寬子流集合和非共享瓶頸帶寬子流集合,使共享瓶頸子流集合保持TCP 友好性,使非共享瓶頸子流集合可以獨(dú)立地與TCP 流競(jìng)爭(zhēng)帶寬資源,從而達(dá)到提升吞吐量、保持算法公平性的目的。但其檢測(cè)子流的方法會(huì)對(duì)共享瓶頸帶寬子流產(chǎn)生誤判,從而導(dǎo)致算法性能下降。Ferlin 等[12]提出多路徑共享瓶頸檢測(cè)算法,通過(guò)計(jì)算單向時(shí)延的方差、偏度、關(guān)鍵頻率這3 個(gè)統(tǒng)計(jì)量來(lái)判斷共享瓶頸帶寬子流,但由于3 個(gè)統(tǒng)計(jì)量的門(mén)限值通過(guò)經(jīng)驗(yàn)值獲取,因此導(dǎo)致應(yīng)用場(chǎng)景受限。Zhang 等[13]提出基于時(shí)延趨勢(shì)線性回歸方法檢測(cè)共享瓶頸子流集合的方案,可以有效地預(yù)測(cè)共享瓶頸帶寬子流。但當(dāng)網(wǎng)絡(luò)環(huán)境差異較大時(shí),該方案可能會(huì)帶來(lái)誤判。
除了上述多路徑擁塞控制算法外,Xue 等[17]將網(wǎng)絡(luò)編碼引入多路徑擁塞控制中,設(shè)計(jì)了“couple+”的擁塞控制方案,使編碼子流可以及時(shí)發(fā)現(xiàn)擁塞,進(jìn)行負(fù)載均衡,但實(shí)際應(yīng)用中需要考慮編解碼器的設(shè)計(jì)問(wèn)題。Trinh 等[18]針對(duì)無(wú)線多媒體傳感器網(wǎng)絡(luò)提出節(jié)能型的多路徑擁塞控制算法,基本思想是采用低能耗的路徑傳輸數(shù)據(jù),同時(shí)保證良好的服務(wù)質(zhì)量級(jí)別,綜合考慮節(jié)能和路徑特征來(lái)調(diào)節(jié)擁塞窗口,以兼顧節(jié)能與服務(wù)質(zhì)量,但需考慮應(yīng)用場(chǎng)景,這給實(shí)際應(yīng)用帶來(lái)不便。Xu 等[19]將深度學(xué)習(xí)算法引入網(wǎng)絡(luò)研究中,保證了TCP 友好性,提升了高動(dòng)態(tài)網(wǎng)絡(luò)的穩(wěn)健性,但學(xué)習(xí)規(guī)則并未全面考慮實(shí)際網(wǎng)絡(luò)的復(fù)雜性。Sun 等[20]通過(guò)使用SDN/NFV(software defined network/ network function virtualization)上的段路由轉(zhuǎn)發(fā)MPTCP 子流,為終端用戶提供優(yōu)化的端到端QoE(quality of experience),但流量分配需要大量的轉(zhuǎn)發(fā)機(jī)制,這導(dǎo)致存儲(chǔ)資源消耗過(guò)多,成熟的應(yīng)用有待方案進(jìn)一步優(yōu)化。
在上述的擁塞控制算法中,基于分組丟失的擁塞控制算法無(wú)法區(qū)分擁塞分組丟失和噪聲分組丟失,造成算法性能下降;基于時(shí)延的擁塞控制算法與其他擁塞控制算法并存時(shí),往往帶寬競(jìng)爭(zhēng)能力較弱;基于瓶頸公平性的擁塞控制算法在檢測(cè)共享瓶頸帶寬子流時(shí),由于網(wǎng)絡(luò)環(huán)境的復(fù)雜往往會(huì)帶來(lái)誤判;其他方式的擁塞控制算法通常需要修改現(xiàn)有協(xié)議,或針對(duì)特殊網(wǎng)絡(luò)環(huán)境進(jìn)行設(shè)計(jì)。因此擁塞控制算法廣泛運(yùn)用還有待進(jìn)一步發(fā)展。
3 預(yù)備知識(shí)
3.1 MPTCP 概述
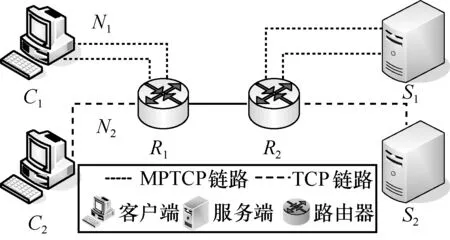
MPTCP 是TCP 的擴(kuò)展[21]。支持MPTCP 的多模終端設(shè)備可以利用多個(gè)網(wǎng)絡(luò)接口建立多條網(wǎng)絡(luò)鏈路,提升吞吐量和網(wǎng)絡(luò)連接彈性。多路徑傳輸場(chǎng)景如圖1 所示,支持MPTCP 的終端設(shè)備(如智能手機(jī)、電腦等)利用3G/4G、Wi-Fi、IP 等接入方式與應(yīng)用服務(wù)器間建立多條網(wǎng)絡(luò)鏈路,并選擇其中一條或多條鏈路進(jìn)行數(shù)據(jù)收發(fā)。
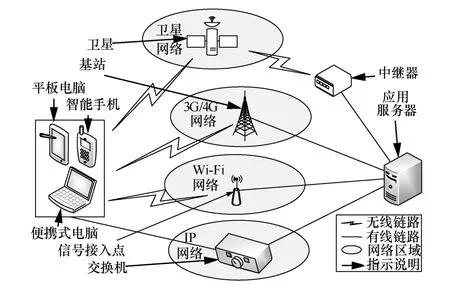
圖1 多路徑傳輸場(chǎng)景
與TCP 相比,MPTCP 在實(shí)現(xiàn)TCP 確認(rèn)應(yīng)答、校驗(yàn)和、擁塞控制等功能的基礎(chǔ)上,增加了路徑管理、數(shù)據(jù)分組調(diào)度、子流接口等功能。在擁塞控制方面,TCP 中的經(jīng)典擁塞控制算法會(huì)經(jīng)歷慢啟動(dòng)、擁塞避免、快速重傳、快速恢復(fù)等過(guò)程,若直接用于MPTCP中會(huì)導(dǎo)致多路徑流侵占帶寬過(guò)多。因此,為實(shí)現(xiàn)多路徑聯(lián)合擁塞,多路徑擁塞控制算法通常會(huì)對(duì)擁塞避免階段的增窗策略進(jìn)行調(diào)整,其目標(biāo)[6]如下。
目標(biāo)1MPTCP 連接的總吞吐量不應(yīng)該小于其最好路徑上的單TCP 連接的吞吐量。
目標(biāo)2與僅使用任一單路徑TCP 流相比,多路徑流不應(yīng)該對(duì)其共享的任何資源占用過(guò)多。
目標(biāo)3在滿足目標(biāo)1 和目標(biāo)2 的前提下,MPTCP需將最擁塞路徑上傳輸?shù)臄?shù)據(jù)轉(zhuǎn)移到其他路徑。
3.2 BBR 算法分析
BBR 算法[14]通過(guò)測(cè)量鏈路最大可用帶寬Bmax和最小往返時(shí)延Tmin,計(jì)算當(dāng)前傳輸速率PacingRate 和擁塞窗口Cwnd,以調(diào)節(jié)數(shù)據(jù)發(fā)送量,從而形成反饋調(diào)節(jié)機(jī)制。當(dāng)算法達(dá)到穩(wěn)定狀態(tài)時(shí),系統(tǒng)將工作在擁塞控制最優(yōu)點(diǎn)[22],鏈路中傳輸?shù)臄?shù)據(jù)量Inflight(發(fā)送端已經(jīng)發(fā)送,但未確認(rèn)的數(shù)據(jù))為Bmax與Tmin的乘積,即帶寬時(shí)延積(BDP,bandwidth-delay product)。相比于TCP 中其他擁塞控制算法,BBR 算法減少了緩沖區(qū)排隊(duì)數(shù)據(jù)分組,降低了傳輸時(shí)延,提升了帶寬利用率。
BBR 算法的主要調(diào)控參數(shù)PacingRate 和Cwnd的計(jì)算式分別為
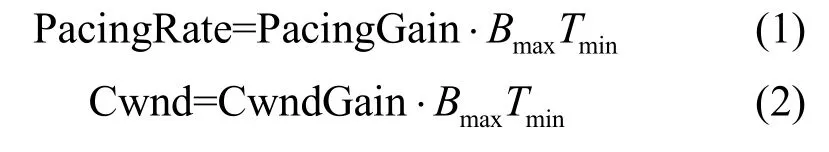
其中,PacingGain 表示發(fā)送速率增益因子,用于調(diào)節(jié)算法不同運(yùn)行狀態(tài)下的發(fā)送速率;CwndGain 表示擁塞窗口增益因子,用于調(diào)節(jié)算法不同運(yùn)行狀態(tài)下的發(fā)送窗口。
BBR 算法的運(yùn)行狀態(tài)轉(zhuǎn)移如圖2 所示,包括4種運(yùn)行狀態(tài)[14]:Startup、Drain、ProbeBW 和ProbeRTT。通過(guò)4 種運(yùn)行狀態(tài)可以準(zhǔn)確測(cè)量出Bmax和Tmin,運(yùn)行狀態(tài)的工作過(guò)程具體如下。
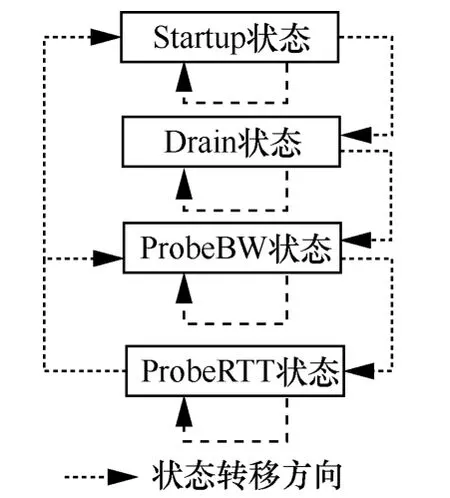
圖2 BBR 算法運(yùn)行狀態(tài)轉(zhuǎn)移過(guò)程
1) Startup 狀態(tài)。采用慢啟動(dòng)方式搶占帶寬,在檢測(cè)到帶寬被占滿3 次后進(jìn)入Drain 狀態(tài)。
2) Drain 狀態(tài)。將Startup 狀態(tài)占用的接收端緩沖區(qū)排空,之后進(jìn)入ProbeBW 狀態(tài)。
3) PrbeBW 狀態(tài)。探測(cè)時(shí)長(zhǎng)為10 s,根據(jù)發(fā)送速率增益數(shù)組[m,n,k,k,k,k,k,k]周期性改變PacingGain(其中m> 1,默認(rèn)值為;n< 1,默認(rèn)值為;k默認(rèn)值為1。PacingGain=m表示增加數(shù)據(jù)發(fā)送量,PaingGain=n表示減小數(shù)據(jù)發(fā)送量,PaingGain=k表示平穩(wěn)發(fā)送數(shù)據(jù)),以測(cè)量Bmax,之后進(jìn)入ProbeRTT 狀態(tài)。
4) ProbeRTT 狀態(tài)。探測(cè)時(shí)長(zhǎng)為200 ms,窗口減小為4 個(gè)TCP 分段大小,以探測(cè)Tmin。若此狀態(tài)結(jié)束時(shí),帶寬仍被占滿,則進(jìn)入Startup 狀態(tài),否則返回ProbeBW 狀態(tài)。
3.3 研究思路與目標(biāo)描述
在網(wǎng)絡(luò)傳輸系統(tǒng)中,TCP 友好性可表述為“在相同條件下,非TCP 流相比于TCP 流不應(yīng)消耗過(guò)多的帶寬資源[23]”。共享資源池如圖3 所示,S1—D1的MPTCP 雙流和S2—D2的TCP 單流共享9 Mbit/s瓶頸帶寬,理想公平情況下,MPTCP 流和TCP 流各占4.5 Mbit/s 帶寬資源。但實(shí)際中MPTCP 有兩條路徑傳輸數(shù)據(jù),而TCP 流僅一條路徑傳輸數(shù)據(jù),因此MPTCP 流占6 Mbit/s 帶寬資源,而TCP 流占3 Mbit/s 帶寬資源,從而導(dǎo)致MPTCP 流相對(duì)于TCP流搶占過(guò)多的帶寬資源。這破壞了TCP 友好性,會(huì)帶來(lái)網(wǎng)絡(luò)服務(wù)質(zhì)量變差的問(wèn)題,嚴(yán)重時(shí)會(huì)造成網(wǎng)絡(luò)癱瘓。
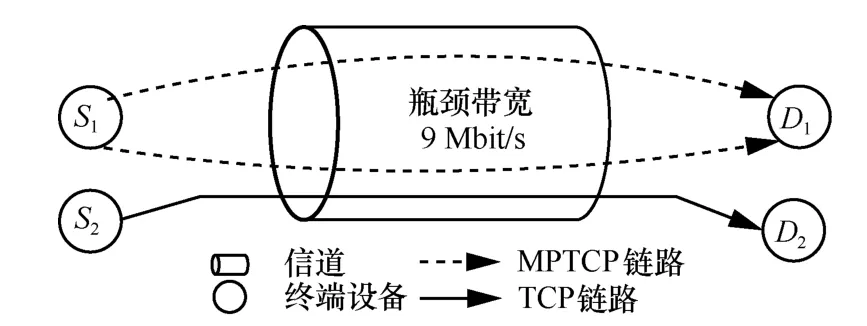
圖3 共享資源池
為充分利用帶寬資源,保證多路徑傳輸?shù)挠押眯院凸叫裕疚难芯克悸啡缦隆?/p>
1)為提升多路徑傳輸效率,根據(jù)BBR 算法傳輸時(shí)延低、吞吐量高的特性,將BBR 算法根據(jù)鏈路容量反饋調(diào)節(jié)發(fā)送速率和發(fā)送窗口的設(shè)計(jì)思想引入多路徑擁塞控制中,設(shè)計(jì)基于鏈路容量的多路徑擁塞控制算法,保證多路徑傳輸充分利用帶寬資源。
2)為保證多路徑傳輸?shù)挠押眯院凸叫裕O(shè)計(jì)M/M/1 緩存隊(duì)列模型,對(duì)基于分組丟失的擁塞控制算法通過(guò)緩沖區(qū)溢出分組丟失判斷擁塞和BBR 算法不占用緩沖區(qū)而根據(jù)帶寬延時(shí)積調(diào)節(jié)擁塞的做法進(jìn)行折中,通過(guò)按一定比例占用接收端緩沖區(qū)對(duì)發(fā)送端吞吐量進(jìn)行調(diào)節(jié),并通過(guò)多級(jí)反饋模型,動(dòng)態(tài)調(diào)節(jié)發(fā)送端的數(shù)據(jù)發(fā)送量,保證算法公平性。
基于上述研究思路,本文要達(dá)到的基本目標(biāo)為保證MPTCP 流與TCP 流競(jìng)爭(zhēng)帶寬的公平性,實(shí)現(xiàn)帶寬資源的充分利用,提升動(dòng)態(tài)環(huán)境下算法的響應(yīng)能力。
4 多路徑擁塞控制算法設(shè)計(jì)
4.1 多路徑擁塞控制框架
多路徑擁塞控制框架主要設(shè)計(jì)思想是將發(fā)送端TCP 狀態(tài)與多路徑擁塞控制算法狀態(tài)進(jìn)行分離,便于反饋調(diào)節(jié)擁塞的多路徑擁塞控制算法的設(shè)計(jì)。
多路徑擁塞控制框架如圖4 所示,主要包括子流監(jiān)測(cè)模塊、網(wǎng)絡(luò)監(jiān)測(cè)模塊、擁塞控制模塊等。子流監(jiān)測(cè)模塊的主要功能是監(jiān)測(cè)子流數(shù)據(jù)分組收發(fā)情況,計(jì)算相關(guān)通信參數(shù),如往返時(shí)延、發(fā)送窗口等。網(wǎng)絡(luò)監(jiān)測(cè)模塊的主要功能是維護(hù)每條鏈路的TCP 狀態(tài),監(jiān)測(cè)多路徑傳輸子流的數(shù)據(jù)發(fā)送量。擁塞控制模塊的主要功能是利用通信參數(shù)調(diào)節(jié)子流發(fā)送窗口和發(fā)送速率,利用上一輪子流的數(shù)據(jù)發(fā)送量預(yù)估接收緩沖區(qū)占有量,進(jìn)而調(diào)節(jié)當(dāng)前子流數(shù)據(jù)發(fā)送量。
在多路徑擁塞控制框架中,發(fā)送端相當(dāng)于多模客戶端,接收端相當(dāng)于服務(wù)端,發(fā)送端與接收端通過(guò)MPTCP 建立多條鏈路,并利用擁塞控制算法維護(hù)多條鏈路數(shù)據(jù)收發(fā)管理。其中,擁塞控制算法包括兩級(jí)反饋調(diào)節(jié),分別是子流級(jí)反饋調(diào)節(jié)和連接級(jí)反饋調(diào)節(jié)。子流級(jí)反饋是指發(fā)送端通過(guò)接收端反饋的ACK(acknowledge character)情況,更新子流通信參數(shù),再通過(guò)預(yù)估鏈路容量調(diào)節(jié)子流發(fā)送窗口和發(fā)送速率。連接級(jí)反饋是指發(fā)送端通過(guò)檢測(cè)所有子流的數(shù)據(jù)發(fā)送量,預(yù)估接收端緩沖區(qū)占有量,再根據(jù)擁塞控制算法原理調(diào)節(jié)子流的數(shù)據(jù)分配量,維持多路徑傳輸?shù)墓叫浴?/p>
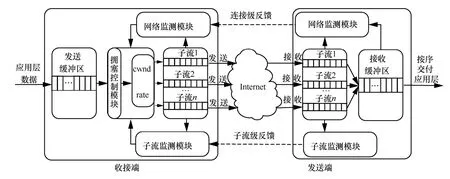
圖4 多路徑擁塞控制框架
4.2 MPLC 算法基本原理
MPLC 算法在BBR 算法4 種運(yùn)行狀態(tài)的基礎(chǔ)上,通過(guò)調(diào)節(jié)每條鏈路向網(wǎng)絡(luò)中傳輸?shù)臄?shù)據(jù)量,實(shí)現(xiàn)多路徑聯(lián)合擁塞控制。
MPLC 算法調(diào)節(jié)鏈路中傳輸?shù)臄?shù)據(jù)量基本原理如圖5 和圖6 所示,其中圖5 展示的是傳輸?shù)臄?shù)據(jù)量與往返時(shí)延關(guān)系,圖6 展示的是傳輸?shù)臄?shù)據(jù)量與發(fā)送速率關(guān)系。其中,Inflight 表示網(wǎng)絡(luò)中傳輸?shù)臄?shù)據(jù)量,α表示Inflight 的調(diào)節(jié)因子,BufSize 表示接收端緩存大小,DeliveryRate 表示發(fā)送端的數(shù)據(jù)發(fā)送速率。通過(guò)分析圖5 與圖6,可得出以下結(jié)論。
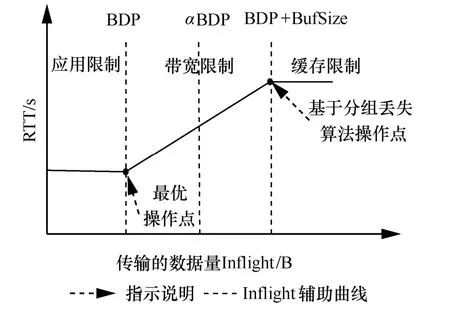
圖5 傳輸?shù)臄?shù)據(jù)量與往返時(shí)延關(guān)系
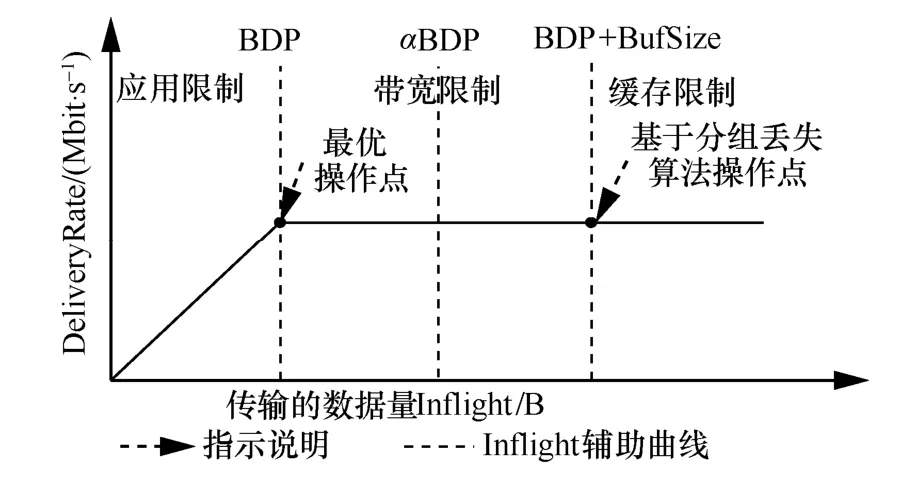
圖6 傳輸?shù)臄?shù)據(jù)量與發(fā)送速率關(guān)系
1) 當(dāng)Inflight ≤BDP時(shí),隨著Inflight 增加,DeliveryRate 增大,RTT 不變,此時(shí)RTT 與物理鏈路傳輸時(shí)延相等。
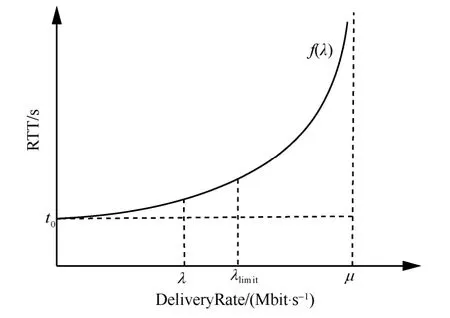
2)當(dāng)BDP 3)當(dāng)Inflight>BDP+BufSize 時(shí),隨著Inflight 增加,鏈路中傳輸?shù)臄?shù)據(jù)量將超過(guò)接收緩沖區(qū)可承載的數(shù)據(jù)量上限,導(dǎo)致分組丟失。 MPLC 算法維持BDP 1) 當(dāng)發(fā)送端向網(wǎng)絡(luò)中發(fā)送的數(shù)據(jù)量大于BDP時(shí),將導(dǎo)致接收端緩沖區(qū)排隊(duì)數(shù)據(jù)分組增多,數(shù)據(jù)分組傳輸時(shí)延增大。上述方法雖然約束了多路徑傳輸效率,但有利于維護(hù)MPTCP 流與TCP 流競(jìng)爭(zhēng)帶寬的公平。 2) 當(dāng)發(fā)送端向網(wǎng)絡(luò)中發(fā)送的數(shù)據(jù)量小于 BDP+BufSize 時(shí),不容易造成接收端因緩沖區(qū)溢出而發(fā)生分組丟失,避免了發(fā)送端發(fā)送數(shù)據(jù)過(guò)多所導(dǎo)致的分組丟失問(wèn)題,提升了網(wǎng)絡(luò)傳輸效率。 MPLC 算法的4 個(gè)階段如圖7 所示,具體如下。 圖7 MPLC 算法4 個(gè)階段 1) Startup 階段。采用慢啟動(dòng)方式搶占帶寬,在檢測(cè)到帶寬被占滿3 次后進(jìn)入Drain 階段。 2) Drain 階段。將Startup 階段占用接收緩沖區(qū)的數(shù)據(jù)按比例排空,使Inflight 回退到大于BDP 的某個(gè)位置。 3) ProbeBW 階段。設(shè)置探測(cè)時(shí)長(zhǎng)為固定時(shí)間段(默認(rèn)為10 s,可根據(jù)網(wǎng)絡(luò)環(huán)境調(diào)整),并設(shè)置發(fā)送速率增益數(shù)組為[1+β,1?β,1,1,1,1,1,1](β< 1,表示PacingGain 調(diào)節(jié)因子),并根據(jù)增益數(shù)組周期性調(diào)節(jié)PacingRate,以探測(cè)最大可用帶寬。 4) ProbeRTT 階段。設(shè)定探測(cè)時(shí)長(zhǎng)為固定時(shí)間(默認(rèn)為200 ms,可根據(jù)網(wǎng)絡(luò)環(huán)境調(diào)整),將發(fā)送窗口減小為4,一方面是探測(cè)最小RTT 值,另一方面是排空ProbeBW 階段在接收緩沖區(qū)累積的數(shù)據(jù),避免緩沖區(qū)溢出而丟失分組。 為了清晰地描述Inflight 所占用接收緩沖區(qū)的規(guī)律,本節(jié)引用排隊(duì)論中的基本規(guī)律對(duì)接收端緩存隊(duì)列進(jìn)行建模。 在通信網(wǎng)絡(luò)中,網(wǎng)絡(luò)中的數(shù)據(jù)分組會(huì)按照一定規(guī)律進(jìn)入網(wǎng)絡(luò)中間節(jié)點(diǎn)(如路由器、交換機(jī)等)。當(dāng)節(jié)點(diǎn)無(wú)法及時(shí)處理時(shí),數(shù)據(jù)分組便會(huì)進(jìn)入節(jié)點(diǎn)緩沖區(qū)進(jìn)行排隊(duì),待數(shù)據(jù)被處理完后便離開(kāi)節(jié)點(diǎn)緩沖區(qū)。其基本過(guò)程是數(shù)據(jù)達(dá)到、排隊(duì)等待、數(shù)據(jù)處理、離開(kāi),滿足排隊(duì)系統(tǒng)的基本屬性。 對(duì)于網(wǎng)絡(luò)中的數(shù)據(jù)流,數(shù)據(jù)分組到達(dá)緩沖區(qū)的穩(wěn)態(tài)概率與泊松過(guò)程的概率趨勢(shì)一致[24],且網(wǎng)絡(luò)流量可用基于馬爾可夫調(diào)制泊松分布的參數(shù)模型進(jìn)行精確估算[25]。對(duì)于MPTCP 傳輸鏈路,每條子流都滿足M/M/1 的排隊(duì)系統(tǒng),其中第一個(gè)M 表示數(shù)據(jù)分組到達(dá)服從泊松分布,第二個(gè)M 表示服務(wù)器服務(wù)時(shí)間服從負(fù)指數(shù)分布,1 表示只有一個(gè)服務(wù)器提供服務(wù)。下面對(duì)基于M/M/1 緩存隊(duì)列模型中使用的符號(hào)及其含義進(jìn)行說(shuō)明,如表1 所示。 表1 基于M/M/1 緩存隊(duì)列模型中的符號(hào)及其含義 令n(n 圖8 接收端緩存隊(duì)列數(shù)據(jù)分組狀態(tài)轉(zhuǎn)移 設(shè)Pn為系統(tǒng)達(dá)到穩(wěn)定時(shí)接收端緩存隊(duì)列中有n個(gè)數(shù)據(jù)分組的概率,則根據(jù)圖8 可得系統(tǒng)狀態(tài)平衡方程為 根據(jù)系統(tǒng)狀態(tài)平衡方程,在接收端緩存無(wú)限大的條件下,數(shù)據(jù)分組的排隊(duì)時(shí)延t可表示為 數(shù)據(jù)分組傳輸?shù)耐禃r(shí)延等于傳輸時(shí)延、排隊(duì)時(shí)延及處理時(shí)延三者之和,其中傳輸時(shí)延和處理時(shí)延之和用t0表示,結(jié)合式(4),RTT 可表示為 根據(jù)MPLC 算法,數(shù)據(jù)分組到達(dá)率λ即是MPLC 算法中發(fā)送端的DeliveryRate。結(jié)合式(5)可以得到發(fā)送速率與往返時(shí)延的關(guān)系,如圖9 所示。圖9 中曲線f(λ)與橫坐標(biāo)軸所圍成的面積即是發(fā)送端一次向網(wǎng)絡(luò)中發(fā)送的數(shù)據(jù)量W,其計(jì)算方法為 根據(jù)MPLC 算法,鏈路一次向網(wǎng)絡(luò)中發(fā)送的數(shù)據(jù)量即是網(wǎng)絡(luò)中傳輸?shù)臄?shù)據(jù)量Inflight。結(jié)合式(6)可得,Inflight 計(jì)算式為 根據(jù)MPLC 算法可知,α> 1。另外,根據(jù)MPTCP 體系結(jié)構(gòu)[1]推薦的多路徑接收緩沖區(qū)大小為2(sum(BWi))RTTmax,其中BWi表示多路徑流第i條路徑的帶寬,RTTmax表示多路徑流中往返時(shí)延最大值。對(duì)2(sum(BWi))RTTmax進(jìn)行不等式放縮可得,2sum(BWi)RTTmax≥2BWiRTTi=2BDP,其中RTTi表示第i條路徑的往返時(shí)延。當(dāng)鏈路中傳輸?shù)臄?shù)據(jù)量占滿瓶頸帶寬和接收緩沖區(qū)時(shí),將達(dá)到BDP 的3倍,因此可得α上限最小取值為3。 圖9 DeliveryRate 與RTT 的關(guān)系 MPLC 算法為調(diào)節(jié)每條鏈路向網(wǎng)絡(luò)中發(fā)送的數(shù)據(jù)量,以實(shí)現(xiàn)多路徑聯(lián)合擁塞控制,需對(duì)MPLC 算法的Drain 階段排空下限進(jìn)行設(shè)置,對(duì)ProbeBW 階段發(fā)送速率增益數(shù)組切換條件進(jìn)行調(diào)整。 MPLC 算法的Drain 階段排空下限設(shè)置如算法1所示。首先獲取當(dāng)前的運(yùn)行狀態(tài)、網(wǎng)絡(luò)中傳輸?shù)臄?shù)據(jù)量、預(yù)估帶寬時(shí)延積,然后對(duì)當(dāng)前的運(yùn)行狀態(tài)進(jìn)行判斷,若處于Drain 狀態(tài),則直到Inflight 值小于αBDP 時(shí),才進(jìn)入ProbeBW 階段。 算法1Drain 階段的排空下限設(shè)置方法 輸入傳輸數(shù)據(jù)量調(diào)節(jié)因子α 輸出排空完成情況drainComplete MPLC 算法的ProbeBW 階段發(fā)送速率增益按增益數(shù)組周期循環(huán)如算法2 所示。首先獲取當(dāng)前算法運(yùn)行狀態(tài),若為ProbeBW 階段,根據(jù)發(fā)送速率增益值,對(duì)增益切換條件進(jìn)行檢測(cè),在滿足增益切換條件的情況下,進(jìn)入下一階段。其中增益切換條件需滿足如下條件之一。 條件1PacingGain>1,滿足探測(cè)時(shí)長(zhǎng),且向網(wǎng)絡(luò)中發(fā)送的數(shù)據(jù)量 Inflight 值超過(guò)α(1+β)BDP。 條件2PacingGain<1,滿足探測(cè)時(shí)長(zhǎng),或滿足向網(wǎng)絡(luò)中傳輸?shù)臄?shù)據(jù)量Inflight 值小于αBDP。 條件3PacingGain=1,且滿足探測(cè)時(shí)長(zhǎng)。 算法2ProbeBW 階段發(fā)送速率增益按增益數(shù)組循環(huán)方法 輸入傳輸數(shù)據(jù)量調(diào)節(jié)因子α,發(fā)送速率增益調(diào)節(jié)因子β 輸出進(jìn)入下一階段標(biāo)志nextState 4.5.1 公平性分析 對(duì)于多路徑擁塞控制,每條鏈路都獨(dú)立運(yùn)行相同的擁塞控制算法。在這種情況下,MPTCP多路徑流相比于TCP 單路徑流會(huì)搶占過(guò)多的帶寬資源,因此保持MPTCP 流對(duì)TCP 流競(jìng)爭(zhēng)帶寬的公平性變得十分重要。此公平性[6]可概述為MPTCP 流的總吞吐量不應(yīng)該小于其最好路徑上單TCP 流的吞吐量;且與僅使用任一單路徑TCP流相比,多路徑流不應(yīng)該對(duì)其共享的任何資源占用過(guò)多。 根據(jù)公平性原則,MPTCP 流獲得的吞吐量應(yīng)等于TCP 流最優(yōu)路徑獲得的吞吐量,因此單位時(shí)間內(nèi)二者傳輸數(shù)據(jù)量相等,即 其中,R表示多路徑子流集合,λi表示第i條子流的數(shù)據(jù)發(fā)送速率。 根據(jù)MPLC 算法可以得到,單位時(shí)間內(nèi)TCP單路徑傳輸?shù)臄?shù)據(jù)量極大值如式(9)所示,MPTCP多路徑傳輸?shù)臄?shù)據(jù)量極大值如式(10)所示。 其中,BDPTCP表示TCP 單路徑的帶寬時(shí)延積,BDPi表示多路徑第i條子流的帶寬時(shí)延積。對(duì)于共享瓶頸的MPTCP 流與TCP 流,二者在瓶頸帶寬處所占帶寬資源大小相等,即,并且二者接收端緩沖區(qū)大小相等。因此,通過(guò)對(duì)式(9)和式(10)進(jìn)行推導(dǎo)可以得出式(8),即 MPLC 算法滿足MPTCP 多路徑傳輸公平性原則。 另外,根據(jù)MPLC 算法在ProbeBW 階段遍歷速率增益數(shù)組[1+β,1?β,1,1,1,1,1,1]調(diào)節(jié)發(fā)送速率的特點(diǎn),MPTCP 多路徑子流發(fā)送的數(shù)據(jù)量受限于預(yù)估的瓶頸帶寬。對(duì)于多路徑中第i條子流在網(wǎng)絡(luò)中傳輸?shù)臄?shù)據(jù)量應(yīng)滿足式(11)所示的不等式。 4.5.2 抗分組丟失性能分析 根據(jù)MPLC 算法4 個(gè)運(yùn)行狀態(tài),ProbeBW 階段占整個(gè)算法運(yùn)行周期的絕大部分時(shí)間(約占整個(gè)周期的98%)。從吞吐量的角度分析,要使算法的吞吐量不急劇下降,其ProbeBW 階段帶寬搶占量不應(yīng)該小于分組丟失量。 在ProbeBW 階段,發(fā)送速率按照增益數(shù)組[1+β,1?β,1,1,1,1,1,1]周期性進(jìn)行調(diào)節(jié),增益為1+β表示增大數(shù)據(jù)發(fā)送量,增益為1?β表示減小數(shù)據(jù)發(fā)送量,增益為1 表示平穩(wěn)發(fā)送數(shù)據(jù)。結(jié)合式(7),對(duì)于利用MPTCP 建立多條鏈路傳輸數(shù)據(jù)的網(wǎng)絡(luò)系統(tǒng),可以估算出在增益為1+β時(shí)的數(shù)據(jù)增量為 假設(shè)第i條路徑上的分組丟失率為Pi,在增益為1+β時(shí),分組丟失數(shù)據(jù)量表示為 由于Δ1>Δ2,結(jié)合式(12)和式(13),因此分組丟失率應(yīng)滿足式(14)所示的不等式。 另外,根據(jù)MPLC 算法連接級(jí)反饋特點(diǎn),多路徑傳輸?shù)臄?shù)據(jù)量應(yīng)該滿足式(15)所示的不等式。 根據(jù)式(15)可知,MPLC 算法限制 Inflight上限小于,避免了大量數(shù)據(jù)填充接收端緩沖區(qū),緩解了接收端緩沖區(qū)溢出導(dǎo)致的分組丟失現(xiàn)象,因此MPLC 算法相對(duì)于基于分組丟失的擁塞控制算法具有更好的抗分組丟失性能。 4.5.3 系統(tǒng)效率分析 效率是指單位時(shí)間完成的工作量。在MPTCP多路徑傳輸條件下,系統(tǒng)效率可表示為單位時(shí)間傳輸?shù)臄?shù)據(jù)量。定義多路徑傳輸系統(tǒng)效率為E,則系統(tǒng)效率計(jì)算式為 對(duì)于多路徑傳輸系統(tǒng),設(shè)子流往返時(shí)延向量可表示為(RTT1,RTT2,… ,RTTn),子流的數(shù)據(jù)發(fā)送速率向量可表示為(λ1,λ2,…,λn),子流在往返時(shí)延內(nèi)可以傳輸?shù)臄?shù)據(jù)量向量可表示為(W1,W2,…,Wn),子流傳輸時(shí)延和數(shù)據(jù)處理時(shí)延之和的向量可表示為 (t1,t2,…,tn)。根據(jù)系統(tǒng)效率定義,MPTCP 多路徑傳輸系統(tǒng)總效率等于各個(gè)子流效率之和,可表示為 結(jié)合式(5)和式(6),將子流往返時(shí)延表達(dá)式和子流一次向網(wǎng)絡(luò)中發(fā)送的數(shù)據(jù)量表達(dá)式代入式(17),可得 根據(jù)式(18),對(duì)系統(tǒng)效率函數(shù)E求一階導(dǎo)數(shù)E′和二階導(dǎo)數(shù)E′,可得E′< 0,故E′為單調(diào)遞減函數(shù)。其中,E的一階倒數(shù)E′表示為 為驗(yàn)證MPLC 算法公平性、分組丟失率對(duì)吞吐量的影響、動(dòng)態(tài)環(huán)境下算法響應(yīng)能力,本文在NS3網(wǎng)絡(luò)仿真平臺(tái)上設(shè)計(jì)并實(shí)現(xiàn)了MPLC 算法[26]。另外,實(shí)驗(yàn)測(cè)試中的數(shù)據(jù)調(diào)度算法采用Linux 中默認(rèn)的輪詢調(diào)度算法。 為測(cè)試MPLC 算法公平性,采用圖10 所示的共享瓶頸帶寬、圖11 所示的非共享瓶頸帶寬的實(shí)驗(yàn)拓?fù)鋄15,27]。在圖10 與圖11 中,客戶端、服務(wù)端連接路由器的線路表示接入帶寬,路由器與路由器連接的線路表示瓶頸帶寬。另外,根據(jù)圖11 所示的拓?fù)浣Y(jié)構(gòu)進(jìn)行了分組丟失率對(duì)吞吐量的影響、動(dòng)態(tài)環(huán)境下算法響應(yīng)能力的實(shí)驗(yàn)測(cè)試。 圖10 共享瓶頸帶寬的實(shí)驗(yàn)結(jié)構(gòu) 圖11 非共享瓶頸帶寬的實(shí)驗(yàn)拓?fù)浣Y(jié)構(gòu) 實(shí)驗(yàn)仿真參數(shù)如表2 所示,為了滿足4G/5G應(yīng)用高帶寬低時(shí)延的發(fā)展趨勢(shì),其中瓶頸帶寬為100 Mbit/s,往返時(shí)延為5 ms;另外,分組丟失率P、MPTCP 流的對(duì)數(shù)N1、TCP 流的個(gè)數(shù)N2、傳輸數(shù)據(jù)量調(diào)節(jié)因子α、發(fā)送速率增益調(diào)節(jié)因子β為可變參數(shù),其他值為不變參數(shù)。 表2 實(shí)驗(yàn)仿真參數(shù) 為了評(píng)估不同協(xié)議占用網(wǎng)絡(luò)帶寬資源的公平性,利用吞吐量等價(jià)比[28]來(lái)衡量?jī)煞N協(xié)議之間的公平性。對(duì)于協(xié)議a和協(xié)議b,在時(shí)間尺度δ下吞吐量等價(jià)比函數(shù)定義為 在共享瓶頸帶寬條件下,仿真測(cè)試結(jié)果如圖12所示。在非共享瓶頸帶寬條件下,仿真結(jié)果如圖13所示。圖12 和圖13 分別展示了MPTCP 流吞吐量與TCP 流吞吐量隨時(shí)間的變化趨勢(shì)。 圖12 共享瓶頸帶寬條件下仿真結(jié)果 在時(shí)間尺度δ=10 s條件下,利用式(20)分別計(jì)算10 s、20 s、30 s、40 s、50 s、60 s 時(shí)刻的MPTCP 流和TCP 流的吞吐量在共享瓶頸帶寬和非共享瓶頸帶寬條件下的等價(jià)比,其結(jié)果如圖14所示。由圖14 可知,在共享瓶頸帶寬條件下,MPTCP 流與TCP 流的吞吐量等價(jià)比接近1,表明MPTCP 流與TCP 流競(jìng)爭(zhēng)帶寬資源的公平性,實(shí)現(xiàn)了MPTCP 對(duì)TCP 的友好性。在非共享瓶頸帶寬條件下,MPTCP 流與TCP 流的吞吐量等價(jià)比接近0.8,表明MPTCP 流比TCP 流在競(jìng)爭(zhēng)帶寬資源中具有一定優(yōu)勢(shì),表明MPTCP 具有較好的TCP友好性。 將MPLC 算法與BALIA 算法在不同分組丟失率下的吞吐量進(jìn)行對(duì)比。通常分組丟失率小于1%認(rèn)為網(wǎng)絡(luò)環(huán)境是“好的”,分組丟失率在1%~2.5%認(rèn)為是可以接受的[29]。因此設(shè)計(jì)分組丟失率取值為0、0.01%、0.1%、1%、5%。實(shí)驗(yàn)拓?fù)淙鐖D11 所示,參數(shù)如表2 所示,其中N1=1、N2=0,兩條路徑分組丟失率P設(shè)置如表3 所示,其他參數(shù)保持不變。 圖14 MPTCP 流與TCP 流的吞吐量等價(jià)比 表3 兩條路徑上MPTCP 的分組丟失率 按照表3 的分組丟失率參數(shù)值,固定其中一條路徑分組丟失率,變化另外一條路徑分組丟失率,分別測(cè)量MPLC 算法和BALIA 算法分組丟失率對(duì)吞吐量的影響,結(jié)果如圖15 所示,圖15(a)表示在路徑1 沒(méi)有分組丟失(即P1=0)的情況下,路徑2分組丟失率P2按照表3 變化時(shí),MPLC 算法和BALIA 算法吞吐量的變化情況。圖15(b)~圖15(e)分別表示路徑1 在其他分組丟失條件下,2 種算法的對(duì)比情況。此處僅以圖15(a)為例進(jìn)行分析。在路徑2 的分組丟失率P2=0的條件下,MPLC 算法吞吐量為179.4 Mbit/s,帶寬占用率為89.7%。BALIA算法吞吐量為160.3 Mbit/s,帶寬占用率為80.2%。相比BALIA 算法,MPLC 算法帶寬利用率提升了9.5%,并且MPLC 算法和BALIA 算法的吞吐量都隨著分組丟失率的增加而降低,且在相同分組丟失率情況下,MPLC 算法的吞吐量是BALIA 算法吞吐量的1.12~11.3倍,故MPLC 算法分組丟失容忍能力優(yōu)于BALIA 算法。 實(shí)驗(yàn)拓?fù)淙鐖D11 所示,參數(shù)如表2 所示,其中N1=1、N2=5,其他參數(shù)保持不變。為了測(cè)試動(dòng)態(tài)環(huán)境下算法響應(yīng)能力,在程序運(yùn)行25 s 后,撤出TCP 流,觀察MPTCP 流搶占帶寬的變化情況,結(jié)果如圖16 所示。由圖16 可知,在0~25 s 時(shí),MPTCP 流與TCP 流競(jìng)爭(zhēng)帶寬資源并達(dá)到穩(wěn)定;在25 s 時(shí),TCP 流撤離,MPTCP 流感知到可用帶寬增加,在27 s 時(shí)占滿帶寬并達(dá)到穩(wěn)定。故MPLC 算法對(duì)帶寬變化反應(yīng)時(shí)間大約為2 s。 對(duì)比MPLC 算法與其他多路徑擁塞控制算法對(duì)網(wǎng)絡(luò)帶寬變化的響應(yīng)能力[15],其對(duì)比結(jié)果如表4所示。在多路徑擁塞控制算法EWTCP[16]、OLIA[7]、BALIA[15]中,EWTCP 算法對(duì)帶寬變化響應(yīng)速度最快,為3.25 s;而MPLC 算法對(duì)帶寬變化響應(yīng)速度為2.0 s,所以MPLC 算法較EWTCP 算法響應(yīng)時(shí)間減小了1.25 s。 圖15 分組丟失率對(duì)BALIA 算法和MPLC 算法吞吐量的影響 圖16 MPLC 算法對(duì)帶寬變化的響應(yīng)能力 表4 幾種多路徑擁塞控制算法對(duì)帶寬變化的響應(yīng)速度 傳統(tǒng)的多路徑擁塞控制算法主要依據(jù)擁塞窗口、往返時(shí)延判斷網(wǎng)絡(luò)擁塞狀態(tài),新興的多路徑擁塞控制算法嘗試使用人工智能或SDN 方法輔助多路徑擁塞控制,而本文將TCP 單路徑傳輸中根據(jù)鏈路容量調(diào)節(jié)發(fā)送速率的思想引入多路徑傳輸,提出基于鏈路容量的多路徑擁塞控制算法,為現(xiàn)有的多路徑擁塞控制提供了新的實(shí)現(xiàn)方案,有效提升了多接入模式環(huán)境下電子發(fā)票等數(shù)據(jù)的傳輸效率。 本文針對(duì)多路徑擁塞控制帶寬資源利用不充分、分配不公平的問(wèn)題,首先設(shè)計(jì)了反饋調(diào)節(jié)擁塞的多路徑擁塞控制框架;然后在聚合多路徑鏈路容量基礎(chǔ)上,設(shè)計(jì)M/M/1 緩存隊(duì)列模型調(diào)控發(fā)送端MPTCP 子流吞吐量;最后根據(jù)接收端數(shù)據(jù)處理情況,利用多級(jí)反饋動(dòng)態(tài)調(diào)節(jié)發(fā)送端的數(shù)據(jù)發(fā)送量。通過(guò)NS3 仿真實(shí)驗(yàn)結(jié)果表明,MPLC 算法保證了公平性,提升了帶寬利用率和動(dòng)態(tài)環(huán)境下算法響應(yīng)能力。考慮到未來(lái)工作,可以根據(jù)MPLC 算法的反饋調(diào)節(jié)機(jī)制,設(shè)計(jì)合理的數(shù)據(jù)調(diào)度算法,進(jìn)一步提升多路徑傳輸性能。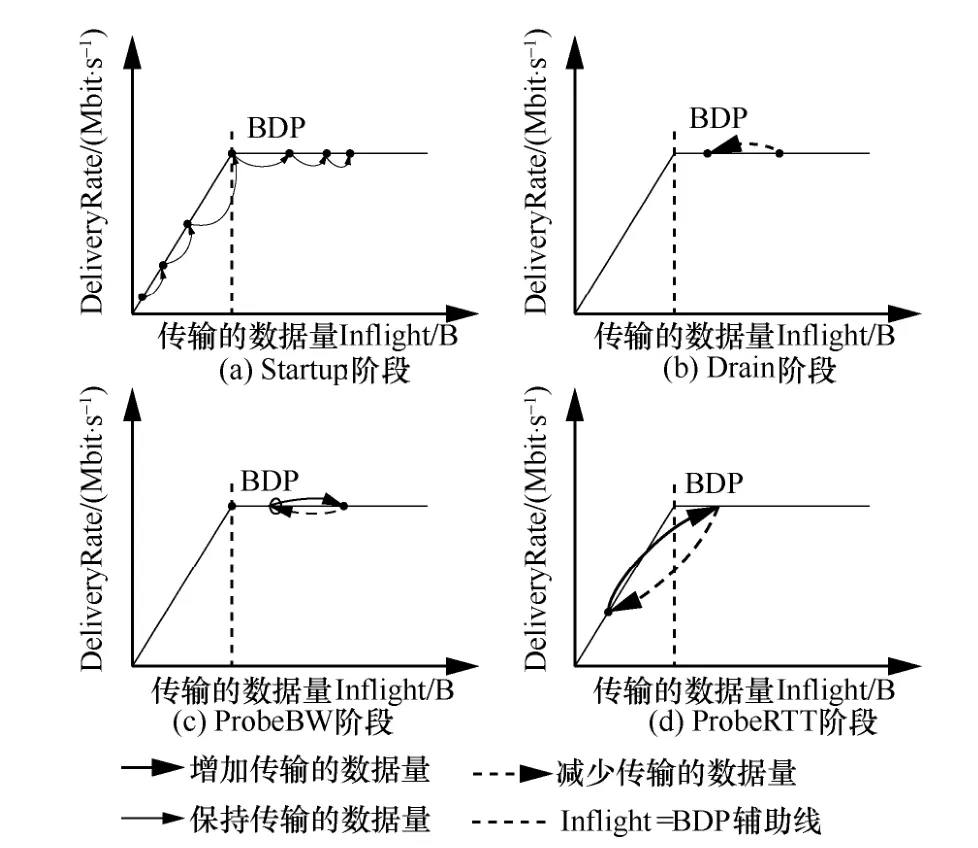
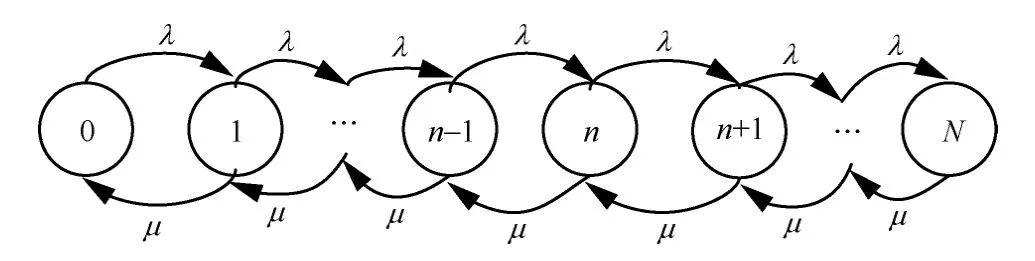
4.3 基于M/M/1 緩存隊(duì)列的傳輸數(shù)據(jù)量求解

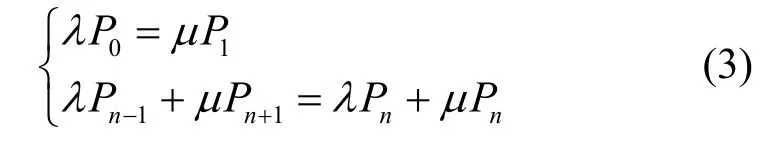

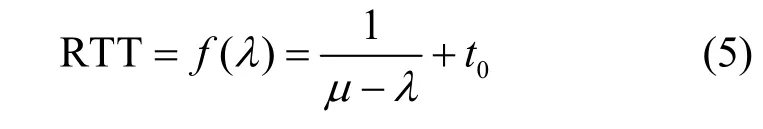
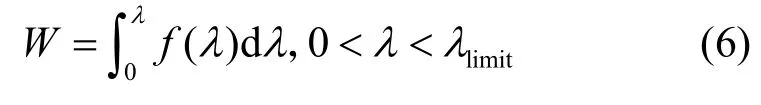
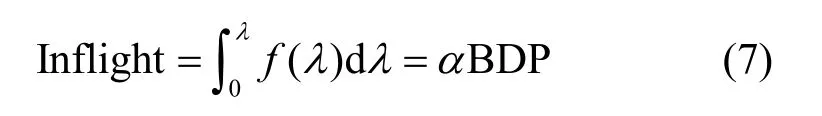
4.4 MPLC 算法描述


4.5 理論分析
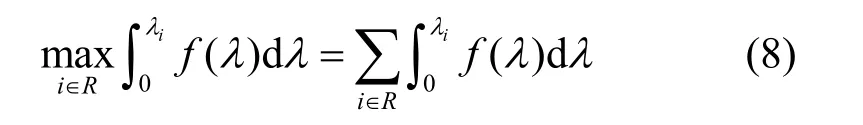

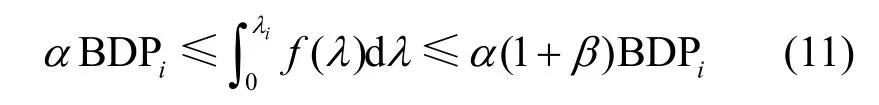
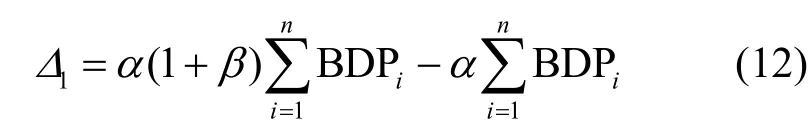
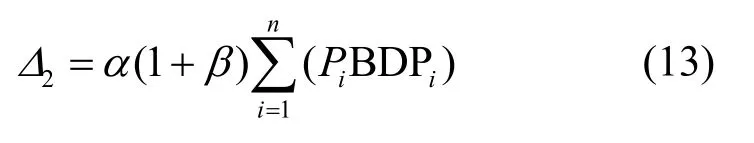
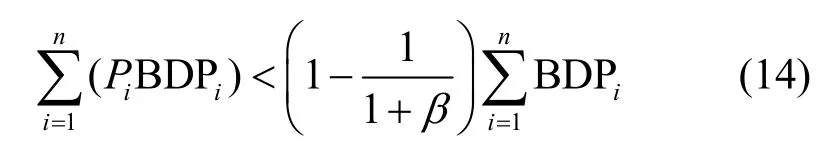
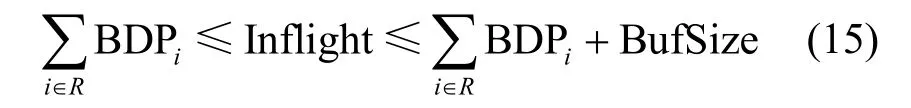

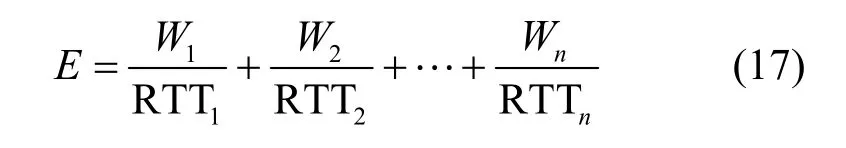
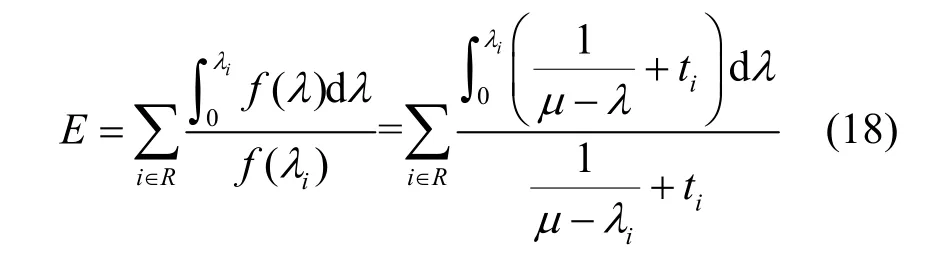
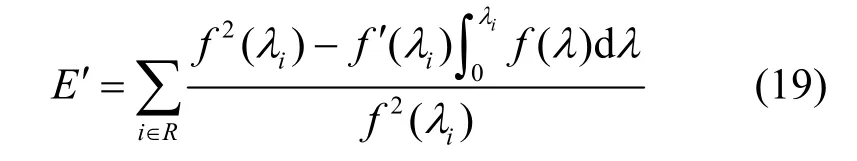
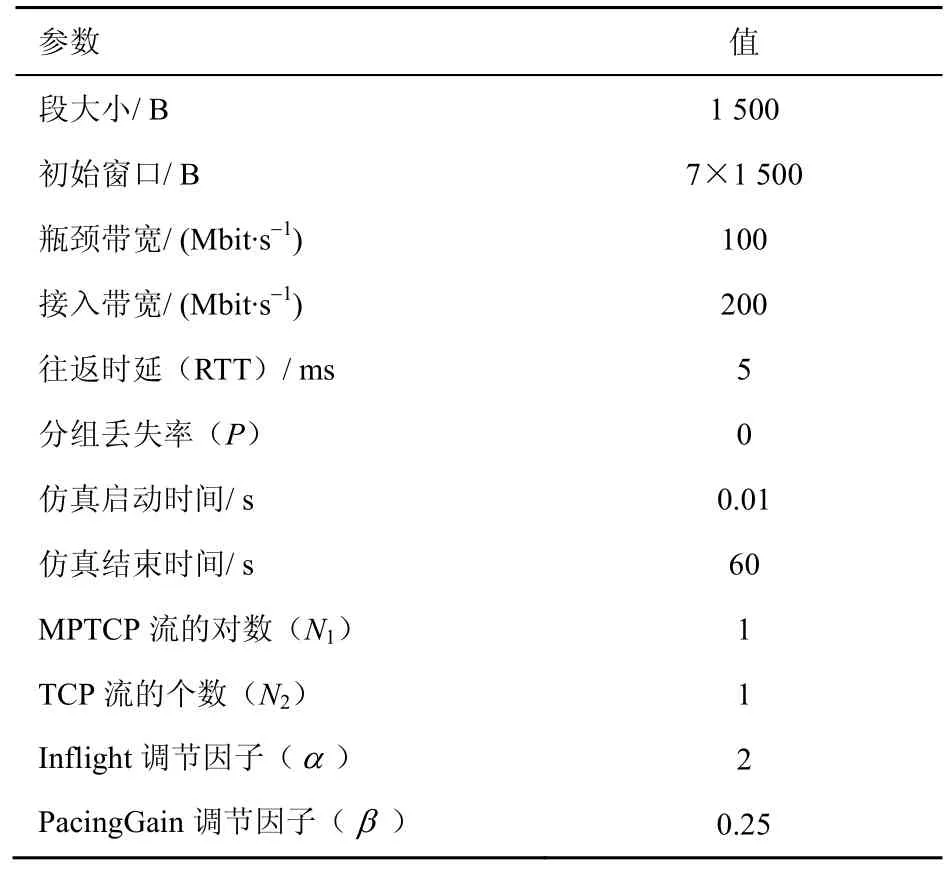
5 實(shí)驗(yàn)及分析
5.1 擁塞算法測(cè)試場(chǎng)景
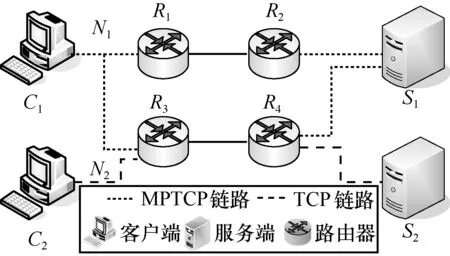
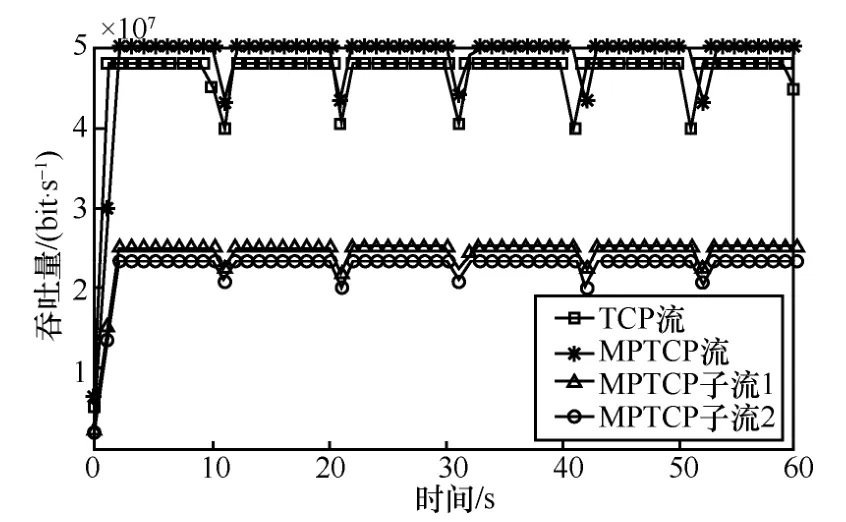
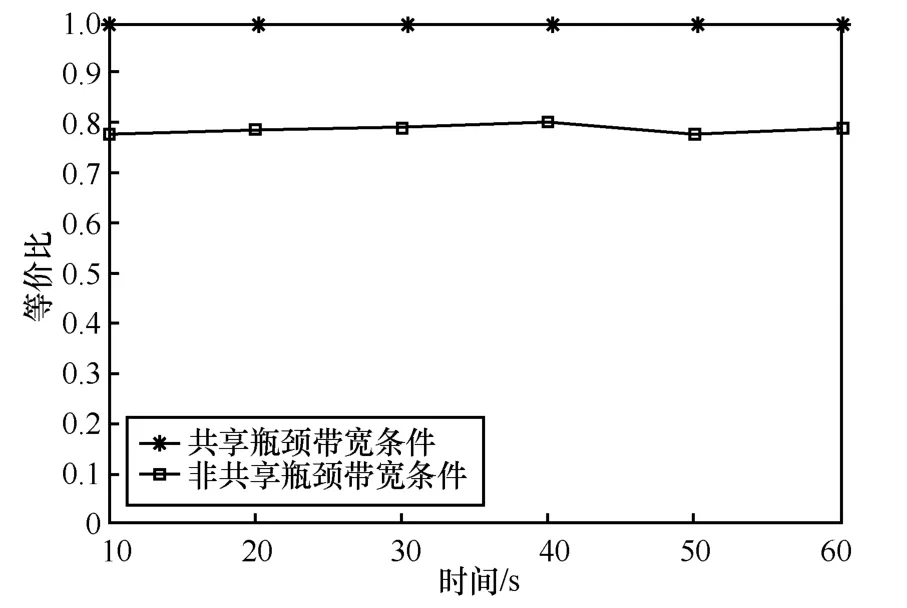
5.2 公平性評(píng)估
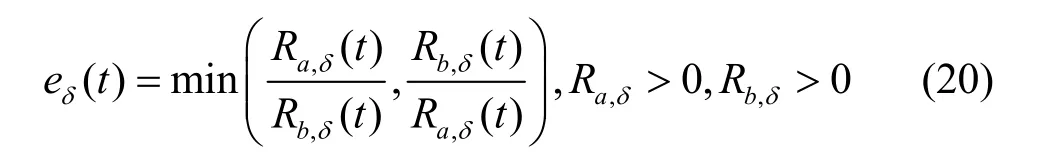
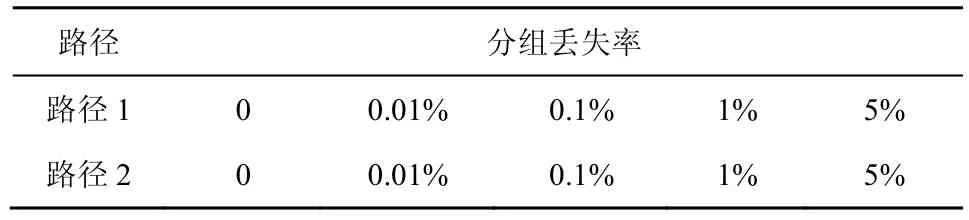
5.3 分組丟失率對(duì)吞吐量影響評(píng)估
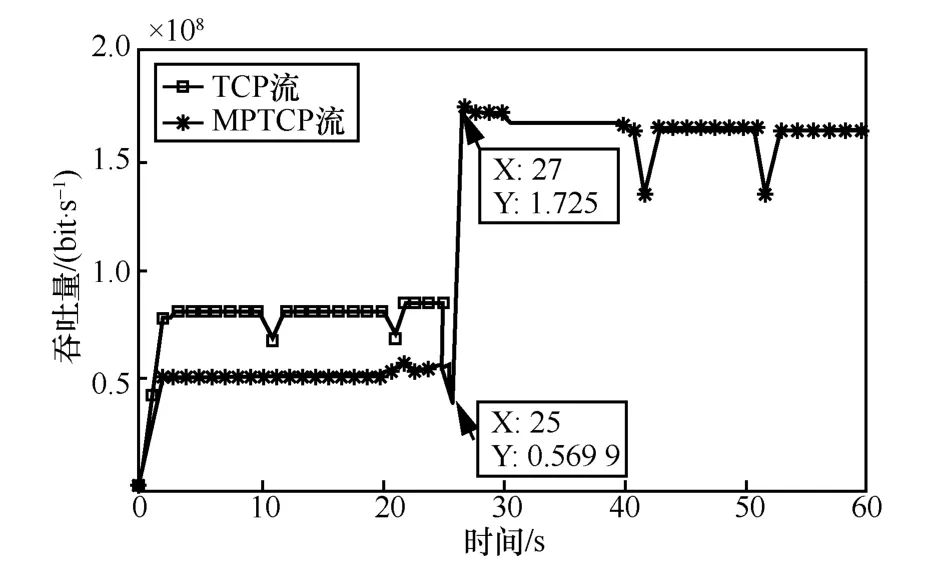
5.4 動(dòng)態(tài)環(huán)境下算法響應(yīng)能力評(píng)估


6 結(jié)束語(yǔ)
