基于激活-熵的分層迭代剪枝策略的CNN模型壓縮
2020-06-07 07:06:18陳程軍毛鶯池王繹超
計算機應(yīng)用 2020年5期
陳程軍,毛鶯池,王繹超
(河海大學計算機與信息學院,南京211100)
(?通信作者電子郵箱yingchimao@hhu.edu.cn)
0 引言
移動云計算作為移動互聯(lián)網(wǎng)和云計算相結(jié)合的產(chǎn)物,利用云端的存儲和計算等資源優(yōu)勢,突破移動設(shè)備的資源限制,提供卷積神經(jīng)網(wǎng)絡(luò)在移動終端部署的基礎(chǔ)條件。AlexNet[1]、VGG-16[2]、GoogleNet[3-4]、ResNet-50[5]和 DenseNet[6]等新型卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network,CNN)結(jié)構(gòu)模型在相關(guān)領(lǐng)域內(nèi)取得了較好的效果,但導(dǎo)致CNN模型朝層次增加方向發(fā)展,使大部分CNN模型都包含龐大的參數(shù)量,限制CNN模型在存儲受限的移動設(shè)備上部署。移動設(shè)備(例如智能手機、醫(yī)療工具和物聯(lián)網(wǎng))幾乎無處不在,對設(shè)備上深度學習服務(wù)的需求很高,包括對象識別、語言翻譯、健康監(jiān)控等,但目前大型深度學習模型因龐大的參數(shù)處理和存儲受限,部署到移動系統(tǒng)仍然很困難[7]。有關(guān)研究證明大稀疏模型始終優(yōu)于小密度模型,壓縮大網(wǎng)絡(luò)能取得比直接訓(xùn)練小網(wǎng)絡(luò)更好的結(jié)果[8],因此模型壓縮對于移動設(shè)備上部署CNN模型至關(guān)重要。
目前常用的模型壓縮技術(shù)分為:剪枝、量化、網(wǎng)絡(luò)分解、知識蒸餾和精細模型設(shè)計:剪枝包含基于正則化的剪枝[9]和基于重要性的剪枝,通過裁剪訓(xùn)練好的神經(jīng)網(wǎng)絡(luò)模型中冗余的權(quán)值或神經(jīng)元,減少存儲空間和加速計算;量化[10]使用位運算代替浮點運算,減少權(quán)重的比特數(shù)來壓縮模型,加速模型計算;網(wǎng)絡(luò)分解利用張量或矩陣分解技術(shù)分解原始卷積核,有效減少了運算量;知識蒸餾[11]借助大模型學習知識,指導(dǎo)小模型訓(xùn)練并代替原模型;精細模型設(shè)計重構(gòu)了輕量級神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),如 MobileNets[12]、ShuffleNet[13]等,達到較好的壓縮效果并顯著提升運算速度,但設(shè)計模型時需要較高的技巧。
上述壓縮方法中,模型剪枝策略靈活且容易實現(xiàn),旨在深度神經(jīng)網(wǎng)絡(luò)的各種連接矩陣中引入稀疏性,從而減少模型中非零值參數(shù)的數(shù)量,而稀疏性參數(shù)被證明是權(quán)衡模型準確性及其內(nèi)存使用情況的有效方法[8],具有較高的實用價值。本文采用模型剪枝策略解決CNN模型在移動設(shè)備上存儲受限的問題。CNN模型在移動云環(huán)境中的部署架構(gòu)如圖1所示,整個系統(tǒng)分為三層架構(gòu),CNN模型的訓(xùn)練在云端進行,使用權(quán)重剪枝技術(shù)壓縮訓(xùn)練好的模型,并將模型部署在移動設(shè)備和微云中。
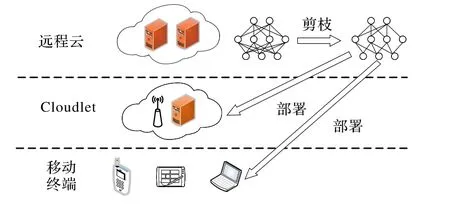
圖1 移動云環(huán)境中CNN模型的部署架構(gòu)Fig.1 Deployment architectureof CNNmodel in mobilecloud environment
針對CNN模型現(xiàn)有剪枝策略各盡不同和效果一般的問題,本文提出了一個基于激活-熵的分層迭代剪枝(Activation-Entropy based Layer-wise Iterative Pruning,AE-LIP)策略,保證模型精度在可控范圍內(nèi)的前提下有效縮減模型的參數(shù)量,使CNN模型在移動設(shè)備中的部署成為可能。本文所做的主要貢獻如下:1)提出了基于激活-熵的權(quán)值重要性評判準則,計算權(quán)值在模型中的重要性得分,并裁剪重要性得分較低的權(quán)值;2)提出了面向?qū)拥牡糁Σ呗裕褂迷囧e實驗法給每層單獨設(shè)定剪枝率和剪枝迭代次數(shù),并遵循篩選-剪枝-微調(diào)的步驟來壓縮CNN模型。
1 相關(guān)工作
1.1 權(quán)值重要性評判準則
深度神經(jīng)網(wǎng)絡(luò)存在大量冗余參數(shù),刪除其中冗余的參數(shù)是一種有效的壓縮手段[14]。模型剪枝的一般流程是通過分析權(quán)值或神經(jīng)元的重要性,剪掉重要性低的權(quán)值或神經(jīng)元,再進行模型微調(diào)。如何有效衡量權(quán)重對模型精度的影響是剪枝需解決的關(guān)鍵問題。基于Hessian矩陣的神經(jīng)網(wǎng)絡(luò)剪枝算法OBS(Optimal Brain Surgeon)[15],分析了權(quán)重變化對模型精度的影響,但計算Hessian矩陣的復(fù)雜度過高,使其在實際使用中受限制。基于幅度的剪枝方法使用權(quán)重的絕對值評判其重要性,絕對值越大的權(quán)重對模型精度的貢獻越高并優(yōu)先裁剪小權(quán)重[16],與其他剪枝方法相比,該方法簡單且容易實現(xiàn),但權(quán)重的大小難以反映權(quán)重在模型中的重要性,實驗證明基于幅度的剪枝方法會誤刪一些重要的權(quán)值,導(dǎo)致模型精度在剪枝后大幅下降[17]。針對以上問題,學者們提出了其他評判準則,例如計算兩個神經(jīng)元激活值的相關(guān)性[18]、計算每個濾波器輸出的熵值[19]、計算每個權(quán)值在下一層神經(jīng)元激活值中的貢獻度[20]等準則,作為衡量權(quán)值重要性的依據(jù)。
1.2 四類剪枝方法
根據(jù)剪枝粒度可分為連接級剪枝和神經(jīng)元級剪枝,圖2展示了兩者區(qū)別。連接級剪枝又稱為非結(jié)構(gòu)化剪枝,以權(quán)重為單位進行裁剪,例如基于神經(jīng)元相關(guān)性裁剪權(quán)重[18];神經(jīng)元級剪枝又稱為結(jié)構(gòu)化剪枝,作用于單個神經(jīng)元或濾波器,剪掉一個神經(jīng)元相連的所有權(quán)重,例如根據(jù)幾何中值對濾波器進行剪枝[21]。與神經(jīng)元級剪枝相比,連接級剪枝具有更精細的裁剪粒度,對模型精度的影響較小。連接級剪枝會讓原始網(wǎng)絡(luò)變成稀疏網(wǎng)絡(luò),權(quán)重需使用稀疏矩陣存儲,帶來額外的存儲開銷,不利于緩存優(yōu)化和內(nèi)存訪問,并且難以在通用硬件平臺上加速。結(jié)合權(quán)重和卷積核的混合剪枝方法[22],將這兩種粒度結(jié)合起來剪枝。
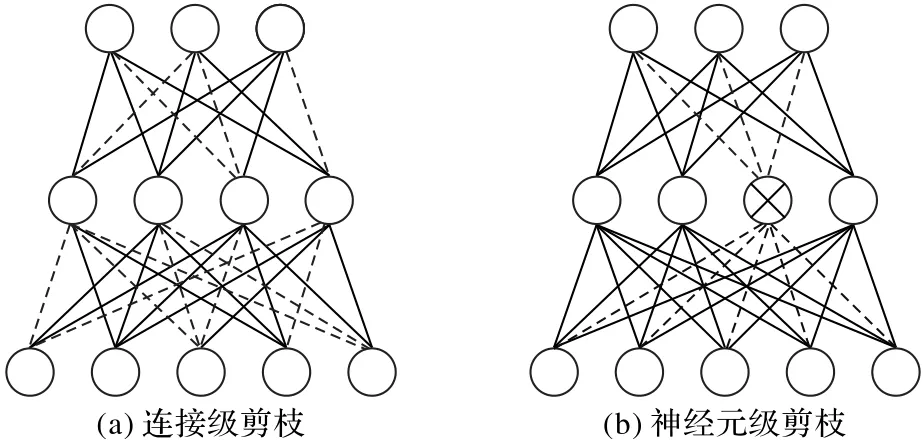
圖2 連接級剪枝和神經(jīng)元級剪枝的對比Fig.2 Comparison of connected pruningand neuronal pruning
根據(jù)剪枝是基于整個網(wǎng)絡(luò)或單層可分為全局剪枝和逐層剪枝:全局剪枝在剪枝過程中分析模型的所有權(quán)重,篩選出一定數(shù)量的權(quán)重進行裁剪,例如逐步全局剪枝方法[24];逐層剪枝為網(wǎng)絡(luò)中不同的層設(shè)置不同的剪枝比例,單獨剪枝每一層。與全局剪枝相比,逐層剪枝考慮了模型中不同層的差異,對模型精度的影響較少,但確定每層的剪枝率是待解決的難題,處理過程較為繁瑣。
根據(jù)剪枝過程是否迭代可分為單步剪枝和迭代剪枝。單步剪枝只進行一輪剪枝操作,剪枝完成后微調(diào)模型補償精度損失,例如基于神經(jīng)元連接靈敏度的單步剪枝策略[25],可以避免迭代剪枝的復(fù)雜性。單步剪枝可能一次剪掉大量參數(shù),造成模型精度的大幅下降。迭代剪枝分為多輪,每一輪剪枝都會移除一定比例的權(quán)重并微調(diào)模型,通過多輪的剪枝-微調(diào)操作完成壓縮。迭代剪枝對模型精度影響較小,但剪枝過程消耗時間更多。
根據(jù)剪枝后權(quán)重能否恢復(fù)可分為靜態(tài)剪枝和動態(tài)剪枝。模型中各個神經(jīng)元之間存在復(fù)雜的連接關(guān)系,將某些權(quán)值裁剪后可能導(dǎo)致其他權(quán)值的重要性發(fā)生變化,動態(tài)剪枝方法可以重新恢復(fù)被裁剪的權(quán)重[26]。
本文提出基于激活-熵的分層迭代剪枝策略,采用基于激活-熵的權(quán)值重要性評判準則,計算權(quán)值在模型中的重要性得分,裁剪得分低的權(quán)重。考慮模型精度的影響程度,采用影響較小的連接級剪枝;考慮模型中不同層的差異,采用試錯實驗法給每層單獨設(shè)定剪枝率并逐層剪枝;考慮模型剪枝-微調(diào)后精度損失問題,采用迭代的方式進行多輪剪枝;考慮模型剪枝后神經(jīng)元連接稀疏問題,采用靜態(tài)剪枝并使用壓縮稀疏行(Compressed Sparse Row,CSR)稀疏矩陣存儲微調(diào)后的稀疏網(wǎng)絡(luò)。
2 基于激活-熵的分層迭代剪枝
基于激活-熵的分層迭代剪枝策略主要分為基于激活-熵的權(quán)值重要性評判和面向?qū)拥牡糁刹糠謨?nèi)容,前者負責計算每個權(quán)值的重要性得分和按剪枝數(shù)量對權(quán)值排序,為后者剪枝和微調(diào)模型提供依據(jù),最后用稀疏矩陣存儲剪枝后的參數(shù),節(jié)省存儲空間。
許多研究[27-28]指出,大多數(shù)全連接層中存在大量冗余,因此本文主要修剪-微調(diào)全連接層。如圖3所示,其中權(quán)重分布指當層所有權(quán)值在各取值區(qū)間的分布情況,它們近似服從高斯分布,在0附近區(qū)間內(nèi)分布的小權(quán)重數(shù)遠多于兩端的大權(quán)重數(shù),全連接層數(shù)量級遠高于卷積層。

圖3 AlexNet模型和VGG-16模型的權(quán)重分布情況Fig.3 Weight distributions of AlexNet model and VGG-16 model
2.1 基于激活-熵的權(quán)值重要性評判
給定神經(jīng)網(wǎng)絡(luò)模型C和訓(xùn)練集D={X={x0,x1,…,x N},Y={y0,y1,…,y N}},其中集合X和Y分別表示訓(xùn)練集中的輸入和目標值。設(shè)神經(jīng)網(wǎng)絡(luò)權(quán)重集合為W=其中H為模型的總層數(shù),Ci為第i層的權(quán)重數(shù)量。訓(xùn)練神經(jīng)網(wǎng)絡(luò)的目標是通過確定權(quán)重集合W,使模型在訓(xùn)練集D上的損失L(D|W)最小化。剪枝的目標是將原模型部分權(quán)重裁剪后保留M個權(quán)重得到新的權(quán)重集合W*,使剪枝后模型的精度損失最小[17]。剪枝可以轉(zhuǎn)換為組合優(yōu)化問題,通過搜索2|W|的解空間,獲取剪枝的最優(yōu)解,如式(1)和(2)所示:

由于CNN中權(quán)重數(shù)量龐大,采用遍歷所有組合求出最優(yōu)解的方式在實際應(yīng)用中并不可行。目前大多數(shù)剪枝策略都是采用啟發(fā)式方法評估權(quán)值重要性,優(yōu)先裁剪不重要的權(quán)值,如基于激活的權(quán)值重要性評判準則[20],通過計算CNN模型在全連接層神經(jīng)元激活值的期望,衡量權(quán)值的重要性。該準則證明了高度相關(guān)的對象對于深度架構(gòu)中的后一層的活動具有更強的預(yù)測能力,通過計算神經(jīng)元連接中的相關(guān)性,刪除絕大部分較小相關(guān)性值,保留少量權(quán)重以補償激活的變化。如圖4所示全連接層的前向傳播過程:i是上一層神經(jīng)元的編號,j是當前層神經(jīng)元的編號,上一層共有n個神經(jīng)元,且神經(jīng)元的輸出為X。W j代表神經(jīng)元j與上一層神經(jīng)元連接的權(quán)重矩陣,w i為神經(jīng)元i和j連接的權(quán)重值。設(shè)激活函數(shù)f(x)為線性整流函數(shù)(Rectified Linear Unit,ReLU),根據(jù)神經(jīng)網(wǎng)絡(luò)的前向傳播公式,當f(W jTX)> 0時,神經(jīng)元j的激活值如式(3)所示,其期望值如式(4)所示,對每一個權(quán)重w i,abs(E(w i x i))的值越大,則權(quán)重w i對下一層神經(jīng)元激活值的貢獻也越大,所以可通過神經(jīng)元激活值期望的絕對值abs(E(w i x i)),衡量權(quán)值w i的重要性,即abs(E(w i x i))值越大,權(quán)值重要性越高。
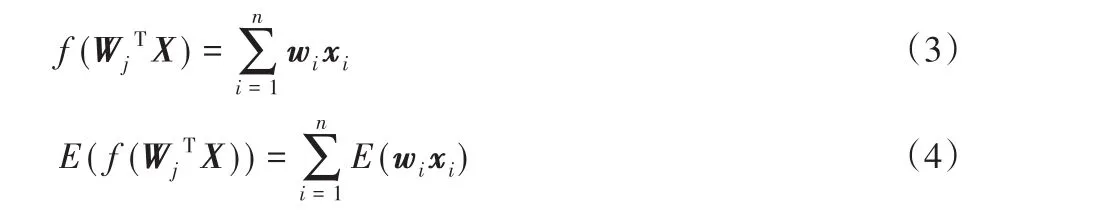
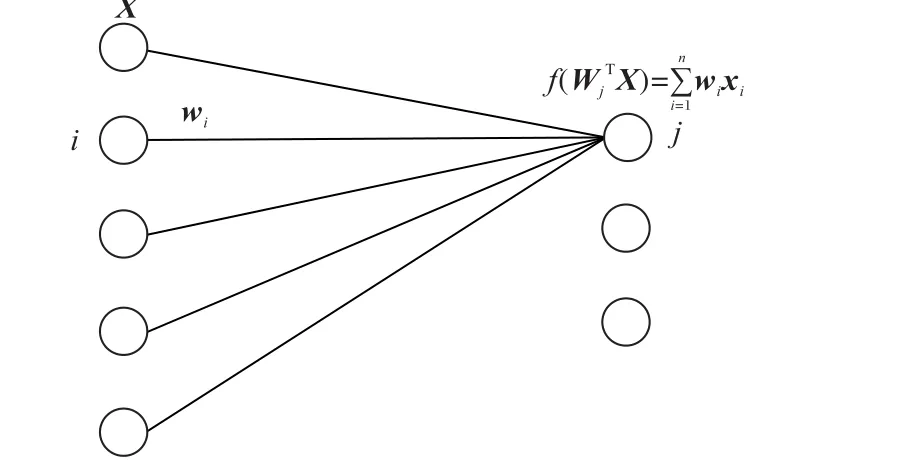
圖4 全連接層的前向傳播過程Fig.4 Forward propagation process of fully connected layers
許多啟發(fā)式剪枝算法起源于計算相對熵最小化的近似,可以通過計算信息熵來衡量權(quán)值的重要性[19]。在信息論中信息熵越高,表明系統(tǒng)越混亂,不確定程度越高,能提供的信息量也越多,即剪枝策略中信息熵越小,其權(quán)值重要性越低[29]。w i x i的信息熵較小,則不同輸入下w i x i的值集中分布在少數(shù)區(qū)間中,信息量較少,權(quán)重w i的重要性不高。設(shè)p(x i)為x i發(fā)生的概率,則離散變量X的信息熵值如式(5)所示。同理從訓(xùn)練集中隨機選取K個樣本,將w i x i的值劃分為D個區(qū)間,使用pi,z表示w i x i的值分布在區(qū)間z中的概率,根據(jù)式(5)計算得到w i x i的信息熵Hi值如式(6)所示:
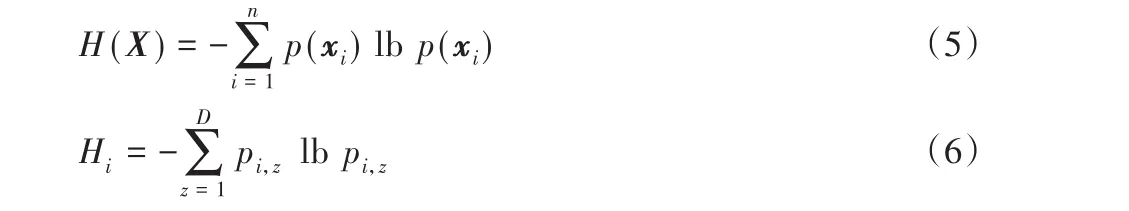
神經(jīng)元激活值期望的絕對值abs(E(w i x i))越大,權(quán)值w i重要性越高,信息熵Hi越小,權(quán)值w i重要性越低,因此激活值和信息熵關(guān)于權(quán)重重要性都呈正相關(guān)。后文實驗證明,激活值和信息熵相結(jié)合的基于激活-熵的權(quán)值重要性評判準則scorei,在保證精度的情況下,可以有效提高壓縮率。scorei可以用來衡量權(quán)值的重要性,得分越高,則權(quán)值在模型中的重要性也越高,在剪枝時優(yōu)先裁剪重要性得分較低的權(quán)值,如式(7)所示:

2.2 面向?qū)拥牡糁Σ呗?/h3>
迭代剪枝對模型精度影響較小,配合剪枝策略,可以提升壓縮精度。逐層迭代剪枝策略使用試錯實驗法測試不同剪枝率下模型的精度變化,根據(jù)精度變化趨勢確定每一層合適的剪枝率。每層剪枝采用迭代方式,每一輪遵循篩選-剪枝-微調(diào)的步驟,避免一次剪掉大量權(quán)重造成模型精度大幅下降。設(shè)模型第m層共包含Nm個權(quán)重,且該層的剪枝率為pm,指定最大迭代次數(shù)Im,則每輪迭代需要剪掉的權(quán)重數(shù)量如式(8)所示:

本文提出的基于激活-熵的分層迭代剪枝策略(Activation-Entropy Based Layer-wise Iterative Pruning,AELIP)如下所示。
算法 AE-LIP策略。
輸入 原始CNN模型E,待剪枝層1,2,…,n,待剪枝層的剪 枝 率p1,p2,…,pn,待 剪 枝 層 的 剪 枝 迭 次 數(shù)I1,I2,…,In,待剪枝層的權(quán)重矩陣W1,W2,…,W n。
輸出 剪枝后的CNN模型E*。
for eachm=0 tondo //逐層進行剪枝
for eacht=0 toImdo //迭代進行剪枝
for eachi=0 toNmdo //權(quán)重矩陣W m中權(quán)值的總個數(shù)權(quán)值的重要性得分
end for
Δsm=pm NmIm//確定剪枝數(shù)量
index=Sort(scorei,Δsm)
//按重要性得分和剪枝數(shù)量對權(quán)值排序
Set(W m,index) //將篩選出的權(quán)重置為0
Retrain(E) //微調(diào)模型
end for
end for
returnE*//返回剪枝后的模型
面向?qū)拥牡糁α鞒讨饕襟E如下:首先,使用數(shù)據(jù)集訓(xùn)練神經(jīng)網(wǎng)絡(luò),得到原始CNN模型;然后,使用試錯實驗法確定待剪枝層的剪枝率,并設(shè)置每一層的剪枝迭代次數(shù);最后,對待剪枝層逐層進行剪枝,每一層剪枝遵循篩選-剪枝-微調(diào)的步驟。從訓(xùn)練集中選取部分樣本,根據(jù)式(7)計算每個權(quán)值的重要性得分,將權(quán)值按照重要性得分從小到大排序。然后根據(jù)式(8)計算需要每一輪需要裁剪的權(quán)重數(shù)量,并將篩選出的權(quán)重置為0。最后微調(diào)模型即重新訓(xùn)練網(wǎng)絡(luò),補償剪枝后模型的精度損失,其中已被置為0的權(quán)重不會被更新。完成所有待剪枝層的剪枝操作后,則獲得壓縮后的CNN模型。
2.3 稀疏權(quán)重存儲
模型剪枝后神經(jīng)元之間的連接稀疏,通常采用稀疏矩陣存儲剪枝后的權(quán)重。常用的稀疏矩陣包括CSR、壓縮稀疏列(Compressed Sparse Column,CSC)、協(xié)調(diào)(COOrdinate,COO)、ELLPACK以及Hybrid等,其中CSR稀疏矩陣使用較為廣泛[30]。如圖5所示,CSR稀疏矩陣由非零元素、列索引和每行第一個非零元素索引三元組構(gòu)成。設(shè)非零元素個數(shù)為b,行數(shù)為u,則CSR矩陣一共需要存儲2b+u+1個元素。剪枝后模型的存儲空間由兩部分組成,包括非零權(quán)重所占用的存儲空間以及稀疏矩陣所占用的存儲空間,稀疏矩陣的存儲開銷降低了模型的壓縮率。CSR矩陣可以在稀疏度高的網(wǎng)絡(luò)中達到更高的壓縮率[8],盡管存在額外的存儲開銷,與模型大小相近的稠密網(wǎng)絡(luò)模型相比,稀疏網(wǎng)絡(luò)模型的準確率更高,并且在大規(guī)模網(wǎng)絡(luò)中表現(xiàn)尤為明顯。
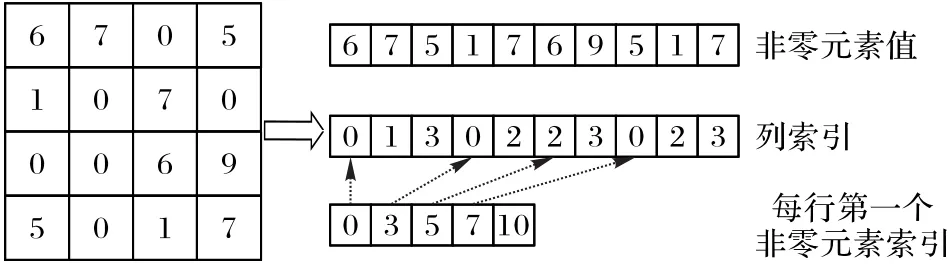
圖5 CSR稀疏矩陣存儲格式Fig.5 Storage format of CSRsparse matrix
3 實驗驗證
3.1 實驗環(huán)境與數(shù)據(jù)集
本章實驗使用Pytorch-1.0.0作為深度學習框架,實驗環(huán)境如表1所示。

表1 實驗環(huán)境Tab.1 Experimental environment
實驗使用CIFAR-10數(shù)據(jù)集訓(xùn)練和測試卷積神經(jīng)網(wǎng)絡(luò)模型。CIFAR-10是深度學習領(lǐng)域常用的一種用于普適物體識別的數(shù)據(jù)集,共包含50 000張訓(xùn)練圖片和10000張測試圖片,圖片共包含10個類別,每張圖片都是大小為32×32的彩色圖片[31]。本實驗在CIFAR-10數(shù)據(jù)集上訓(xùn)練了AlexNet和VGG-16兩種CNN模型。
AlexNet模型共有20層,其中8層含參數(shù),包括5層卷積層 conv1、conv2、conv3、conv4、conv5以及 3層全連接層 fc6、fc7、fc8。訓(xùn)練好的AlexNet模型在測試集上的準確率為77.15%。
VGG-16模型共有38層,其中16層含參數(shù),包括13層卷積層 conv1_1、conv1_2、conv2_1、conv2_2、conv3_1、conv3_2、conv3_3、conv4_1、conv4_2、conv4_3、conv5_1、conv5_2、conv5_3以及3層全連接層fc6、fc7、fc8。訓(xùn)練好的VGG-16模型在測試集上的準確率為89.63%。
3.2 實驗結(jié)果與分析
3.2.1 單層剪枝實驗
單層剪枝實驗選取AlexNet和VGG-16模型部分全連接層,在不進行微調(diào)的情況下,逐步增大剪枝率,觀察模型在測試集上準確率變化情況,其中微調(diào)可以有效補償剪枝帶來的精度損失,但對算法的優(yōu)劣不產(chǎn)生影響。本實驗通過選取基于幅度的權(quán)重剪枝[16](Magnitude)和基于相關(guān)性的權(quán)重剪枝[18](Correlation)策略與基于激活-熵的權(quán)重剪枝(Activation-Entropy)策略比較測試集上準確率變化情況,驗證本文提出的激活-熵評判準則的有效性。
如圖6所示,AlexNet和VGG-16模型由于全連接層中存在較多冗余權(quán)值,當剪枝率較低時模型精度無明顯變化。對于AlexNet模型的fc7層,當剪枝率在50%以下時,使用三種策略剪枝后的模型精度仍保持在70%~77%;當剪枝率達到95%時,全連接層中剩余的權(quán)重數(shù)量較少,剪枝后模型的精度都出現(xiàn)大幅下降。基于激活-熵的剪枝策略的精度損失大概為23.5%,基于相關(guān)性的剪枝策略的精度損失約為25.5%,基于幅度的剪枝策略的精度損失達到了26.4%。在剪枝過程中,基于幅度的剪枝方法效果最差,基于激活-熵的剪枝方法由于保留了對下一層神經(jīng)元激活值貢獻較大的權(quán)重,精度損失相對較小。對于VGG-16模型的fc7層,基于幅度的剪枝方法在剪枝率達到90%時模型精度出現(xiàn)明顯下降,剪枝率達到95%時精度只有57%左右,而基于激活-熵的剪枝策略的精度可以達到61%。綜上所述,當剪枝率較低時AlexNet和VGG-16模型的精度幾乎沒有損失,而較高的剪枝率下基于激活-熵的權(quán)重剪枝效果較好。
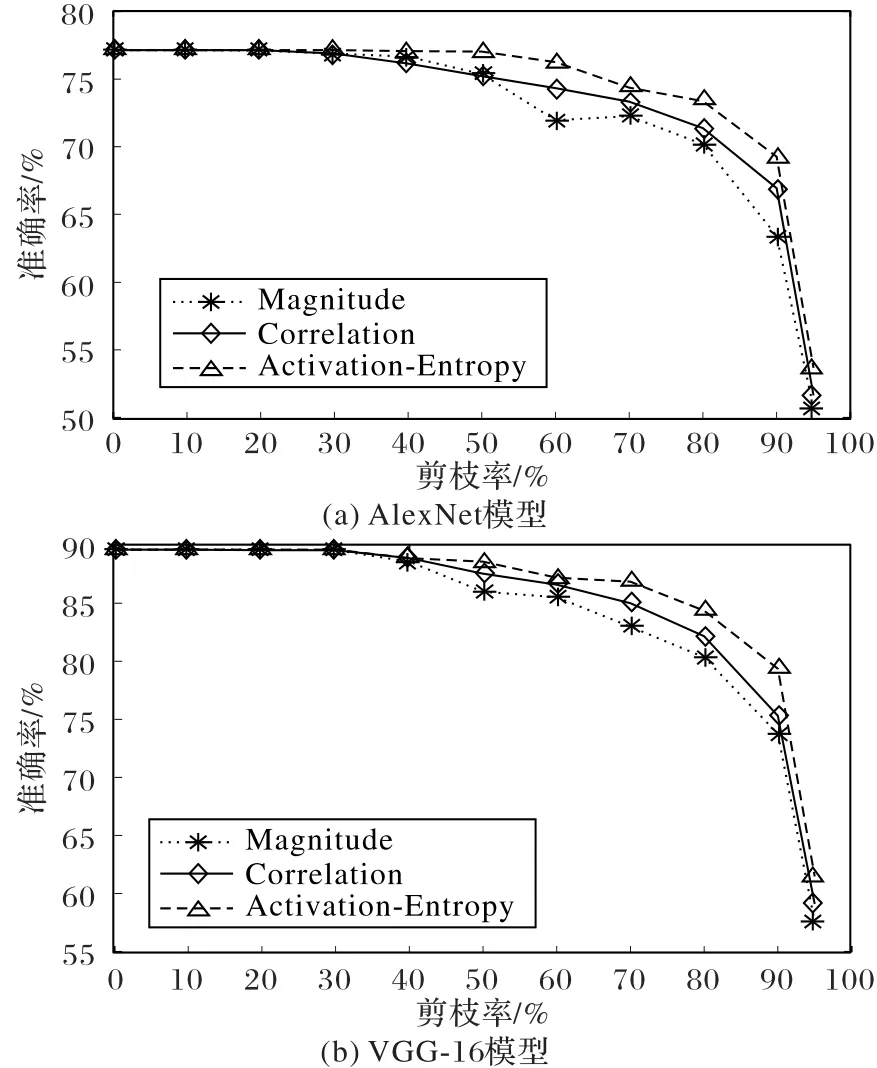
圖6 AlexNet和VGG-16模型的fc層的單層剪枝實驗結(jié)果Fig.6 Single-layer pruning experimental results of fc layer for AlexNet and VGG-16 models
微調(diào)可以有效恢復(fù)剪枝后的模型精度。微調(diào)時設(shè)學習率為1×10-4,在整個訓(xùn)練集上重新訓(xùn)練,在微調(diào)過程中被裁剪的權(quán)重值不會被更新。從圖7可以看出,當剪枝率達到95%時,AlexNet模型經(jīng)過微調(diào)后準確率從53.67%恢復(fù)到63.15%,VGG-16模型的準確率從61.49%恢復(fù)到75.46%。在模型剪枝中,微調(diào)是關(guān)鍵步驟,可以有效補償剪枝帶來的精度損失。
3.2.2 分層迭代剪枝實驗
本節(jié)實驗使用基于激活-熵的分層迭代剪枝策略對整個模型進行壓縮,比較三種剪枝策略在不同壓縮率下的模型精度變化情況,表2顯示了AlexNet和VGG-16模型的剪枝實驗結(jié)果。如表2所示,裁剪權(quán)重數(shù)量上升,模型壓縮率提高,模型準確率下降。經(jīng)重訓(xùn)練,基于激活-熵的分層迭代剪枝策略:使AlexNet模型壓縮了87.5%;準確率下降2.12個百分點,比基于幅度的權(quán)重剪枝策略提高1.54個百分點,比基于相關(guān)性的權(quán)重剪枝策略提高0.91個百分點。使VGG-16模型壓縮了84.1%;準確率下降2.62個百分點,比基于幅度的權(quán)重剪枝策略提高0.62個百分點,比基于相關(guān)性的權(quán)重剪枝策略提高0.27個百分點。
實驗結(jié)果表明,在單層剪枝實驗中,相同剪枝率下基于激活-熵的剪枝策略,比基于幅度的剪枝和基于相關(guān)性的權(quán)重剪枝策略精度損失更小。基于激活-熵的分層迭代剪枝策略能夠在模型精度損失較小的情況下有效縮減CNN模型的體積,可以解決CNN模型在移動設(shè)備上部署受限的問題。
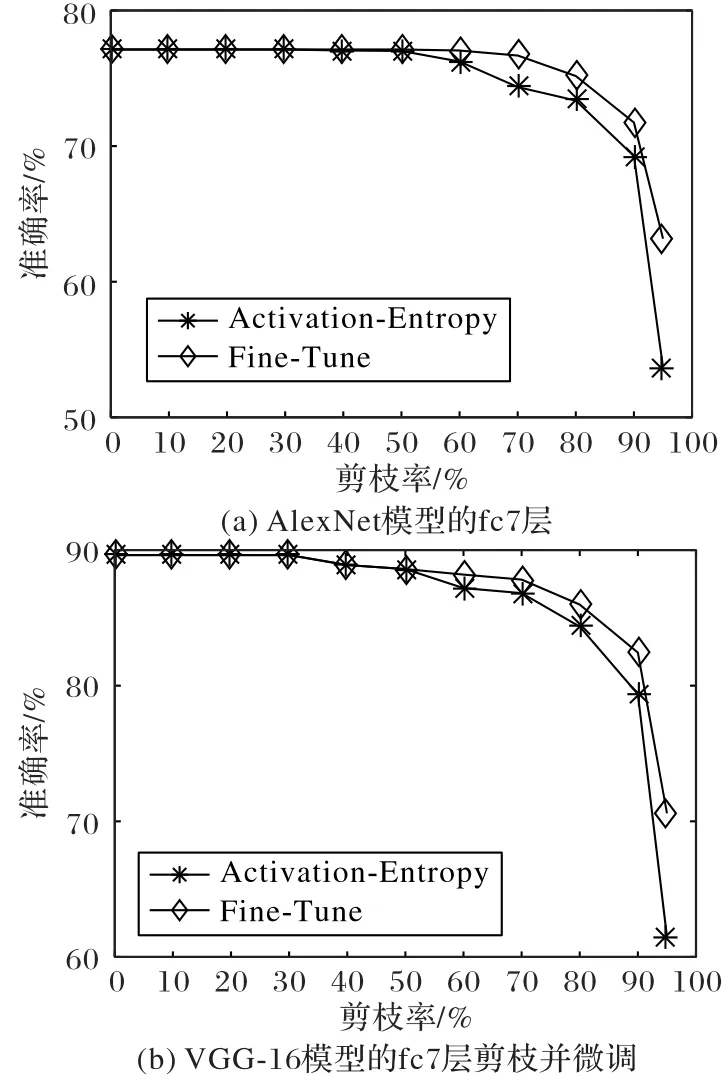
圖7 AlexNet和VGG16模型剪枝微調(diào)實驗結(jié)果Fig.7 Pruning fine-tuning experimental results of AlexNet and VGG16 models
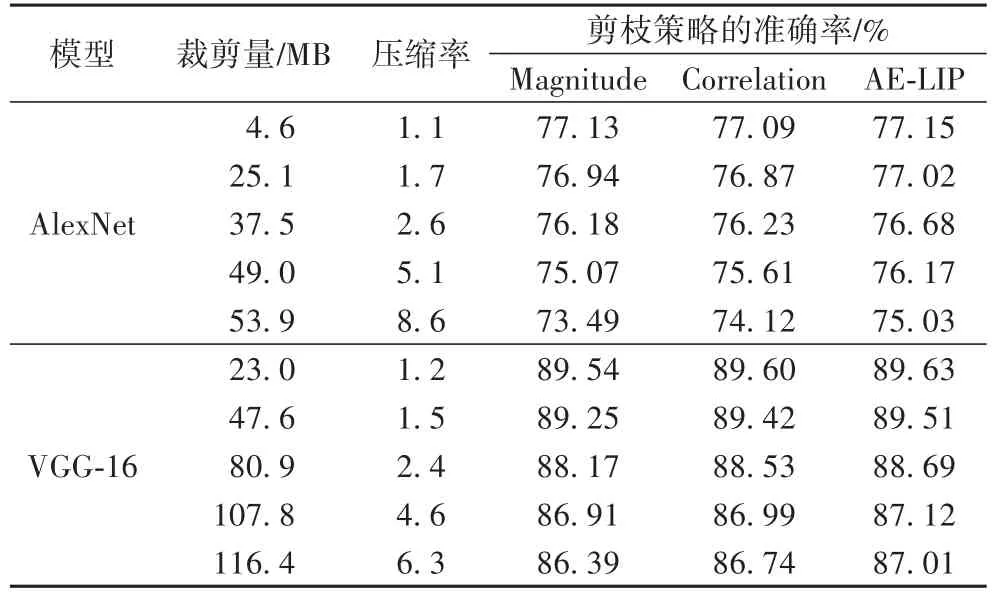
表2 AlexNet和VGG-16模型的分層迭代剪枝實驗結(jié)果Tab.2 Experimental results of layer-wise iterative pruning of AlexNet and VGG-16 models
4 結(jié)語
本文分析了現(xiàn)有研究工作中的權(quán)值重要性評判方法,提出基于激活-熵的分層迭代剪枝策略裁剪模型中的權(quán)重,并使用CSR稀疏矩陣存儲裁剪后的權(quán)重。實驗結(jié)果表明,本文提出的剪枝策略能夠在模型精度損失較小的情況下有效縮減模型的參數(shù)量,解決了模型在移動端的存儲問題,使CNN模型在移動設(shè)備中的部署成為可能。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:02
中國生殖健康(2020年4期)2021-01-18 02:58:26
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
中學生數(shù)理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
甘肅教育(2020年21期)2020-04-13 08:09:24
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
數(shù)學大世界(2018年1期)2018-04-12 05:39:14
光學精密工程(2016年6期)2016-11-07 09:07:19
