基于預訓練模型的機器閱讀理解研究綜述
2020-06-09 07:17:54張超然裘杭萍王中偉
計算機工程與應用 2020年11期
張超然,裘杭萍,孫 毅,王中偉,2
1.陸軍工程大學 指揮控制工程學院,南京210007
2.中國人民解放軍73658部隊
1 引言
機器閱讀理解(Machine Reading Comprehension,MRC)是一項測試機器理解自然語言的程度的任務,要求機器根據給定的上下文回答問題。早期的MRC系統可以追溯到20 世紀70 年代,其中最著名的是Lehnert[1]提出的QUALM系統。但是當時構建的系統非常小,并且僅限于手工編碼的腳本,很難推廣到更廣泛的領域。在20世紀80年代和90年代,對MRC的研究大多被忽視。20世紀90年代末,Hirschman等人[2]提出了Deep Read系統,并創建了一個閱讀理解數據集,數據集包含了120個來自三至六年級素材的故事。使用這些來構建和評估一個基線系統,該系統包括基于規則的詞袋方法以及附加的自動化語言處理(詞干提取、名稱識別、語義類識別和代詞解析等)。這些系統在檢索正確句子時達到了30%~40%的準確率。由于這些系統需要依靠大量的手工規則或特性,導致泛化能力弱,在包含更多類型文章的大型數據集上性能會急劇下降。
由于之前提出的數據集規模比較小,以及基于規則和基于機器的方法的局限性,早期的MRC 系統表現不佳,很難用于實際應用。自2015年以來,隨著神經網絡的發展,經過預訓練的詞向量技術(如Word2Vec、Glove、FastText等)[3-5]也取得了一定的進步,對詞語以及文章的表示有了很大的提升,另外Seq2Seq 結構[6]的神經網絡和Attention注意力機制[7]的提出使得設計更復雜的網絡模型成為可能。DeepMind研究人員Hermann等人[8]提出了一種新穎而代價小的解決方案,用于為學習閱讀理解模型創建大規模的有監督訓練數據,構建了CNN/Daily Mail數據集。他們還提出基于注意力的LSTM模型the attentive reader,the impatient reader,它們在很大程度上優于傳統自然語言處理(Natural Language Processing,NLP)方法。
2016 年Chen 等人[9]研究了上述的數據集并證明了一個簡單、精心設計的神經網絡模型能夠將CNN 數據集的性能提升到72.4%,Daily Mail 數據集的性能提升到75.8%。與傳統的基于特征的分類器相比,神經網絡模型能夠更好地識別詞匯匹配和釋義。但由于數據的創建方法和一些其他誤差,數據集有噪聲限制了進一步的發展。
為了解決這些限制,斯坦福大學Rajpurkar等人[10]收集了Stanford Question Answering Dataset(SQuAD)數據集。數據集包含536 篇維基百科文章的10 萬個問答題,每個問題的答案都是對應閱讀段落的文本。該數據集質量高且能夠可靠地評估,成為了領域的中心基準。推動了一系列新的閱讀理解模式,截至2018年10月,表現最好的單一的BERT[11]模型系統實現了91.8%的F1值,已經超過人類的成績91.2%。
隨著GPT[12]、BERT等預訓練模型的出現,以及在閱讀理解任務上的強大性能提升,誕生了一批優秀的預訓練語言模型。在SQuAD 數據集之后,斯坦福大學又發布了SQuAD2.0[13]數據集,相比之前增加了一些不存在答案的問題,增加了難度。微軟亞洲研究院發布了來源于真實應用場景的數據集MS MARCO[14],國內百度公司發布了基于百度搜索和百度知道的中文DuReader數據集[15]。近年來國內也出現了在法律、軍事等方面的閱讀理解數據集,擴寬了閱讀理解的應用,也增加了一些難度。
2 基于預訓練模型的MRC
2.1 問題定義
傳統的閱讀理解是通過閱讀給定的文章來回答相關的問題。隨著機器學習與深度學習的技術發展,近年來將機器閱讀理解作為一個有監督任務來進行學習訓練,訓練樣本集D 可以用三元組的形式定義如下:
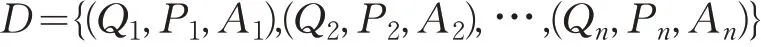
具體的任務是給定一個三元組(Qi,Pi,Ai),根據問題Qi={q1,q2,…,qm}和與其對應的文章Pi={p1,p2,…,pn}進行自然語言理解,推理預測得到答案Ai。其中,qj與pj分別是問題與文章的字或者詞的表示,m 與n分別代表問題與文章的長度。根據數據集及機器閱讀理解任務的不同,答案Ai的形式也有所區別,抽取型任務的答案一般出現在原文Pi中,而描述型任務的答案可以是整個字典中的任意字符。
在預訓練語言模型出現之前,基于深度學習的機器閱讀理解可以分為多個模塊[16],主要包括詞嵌入層、編碼層、匹配層以及答案選擇層,機器閱讀理解的發展依靠各個模塊的結合。然而,這種方式的組合存在一定的缺點,傳統的詞向量無法解析一詞多義的問題,注意力模塊的網絡結構比較復雜,且對長文本的處理比較吃力,即使ELMO[17]等動態詞向量的出現,對模型的效果提升也比較有限。
GPT、BERT 等預訓練模型提升了機器閱讀理解的性能,在某些數據集上超越了人類的表現。預訓練模型前期通過語言建模在大量自然語言上進行半監督訓練,如掩碼預測、句子關系的預測,以及自然語言的多任務訓練等。通過在大量文本上進行預訓練,得到強健的語言模型,可以捕獲句子間更深層次的關聯關系。在做機器閱讀理解任務時,只需要設計適合具體任務的網絡拼接到預訓練模型網絡上進行微調即可,基于預訓練模型的機器閱讀理解與傳統結構對比如圖1所示。
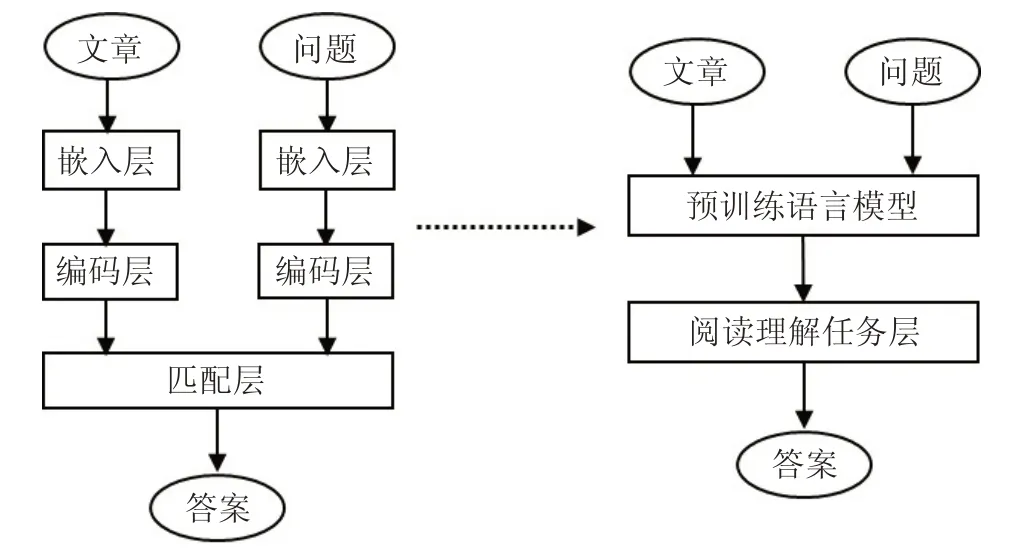
圖1 機器閱讀理解模型結構對比
2.2 預訓練模型
預訓練語言模型屬于遷移學習,遷移學習在計算機視覺領域中已經很流行,因為它可以建立精確的模型,耗時更短。利用遷移學習,不是從零開始學習,而是從之前解決各種問題時學到的模式開始。這樣就可以利用以前的學習成果(例如VGG[18]、MobileNet[19]等圖像處理模型),避免從零開始,可以把它看作是站在巨人的肩膀上。
近年來NLP 領域的一些研究者也嘗試通過遷移學習的方式建立預訓練語言模型,將在通用領域通過無監督方法學到的知識遷移到有監督任務上,誕生了一批優秀的預訓練語言模型。由于NLP 領域本身無監督數據存在很多,具有天然優勢。只需要設計合適的語言模型,在無監督數據集上進行大量訓練,即可得到健壯的語言模型。在做具體的有監督任務時,可以將學到的語言知識遷移到各個NLP任務上。
常見的預訓練語言模型結構如圖2 所示[11],有編碼輸入層、網絡結構層、編碼輸出層。預訓練語言模型的區別主要體現在網絡結構層以及預訓練時對語言建模的任務。如ELMO使用雙向LSTM結構,BERT、GPT使用Transformer[20]結構。與LSTM相比,Transformer中引入self-attention 結構與多頭注意力機制,可以捕獲更多的文本信息,同時Transformer 可以做到并行化計算以及設計更深的神經網絡。本文將近年來出現的預訓練語言模型根據建模方式、模型結構、模型介紹等進行整理,如表1所示。
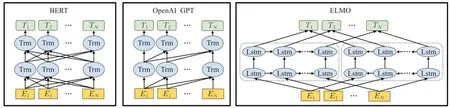
圖2 常見預訓練語言模型結構
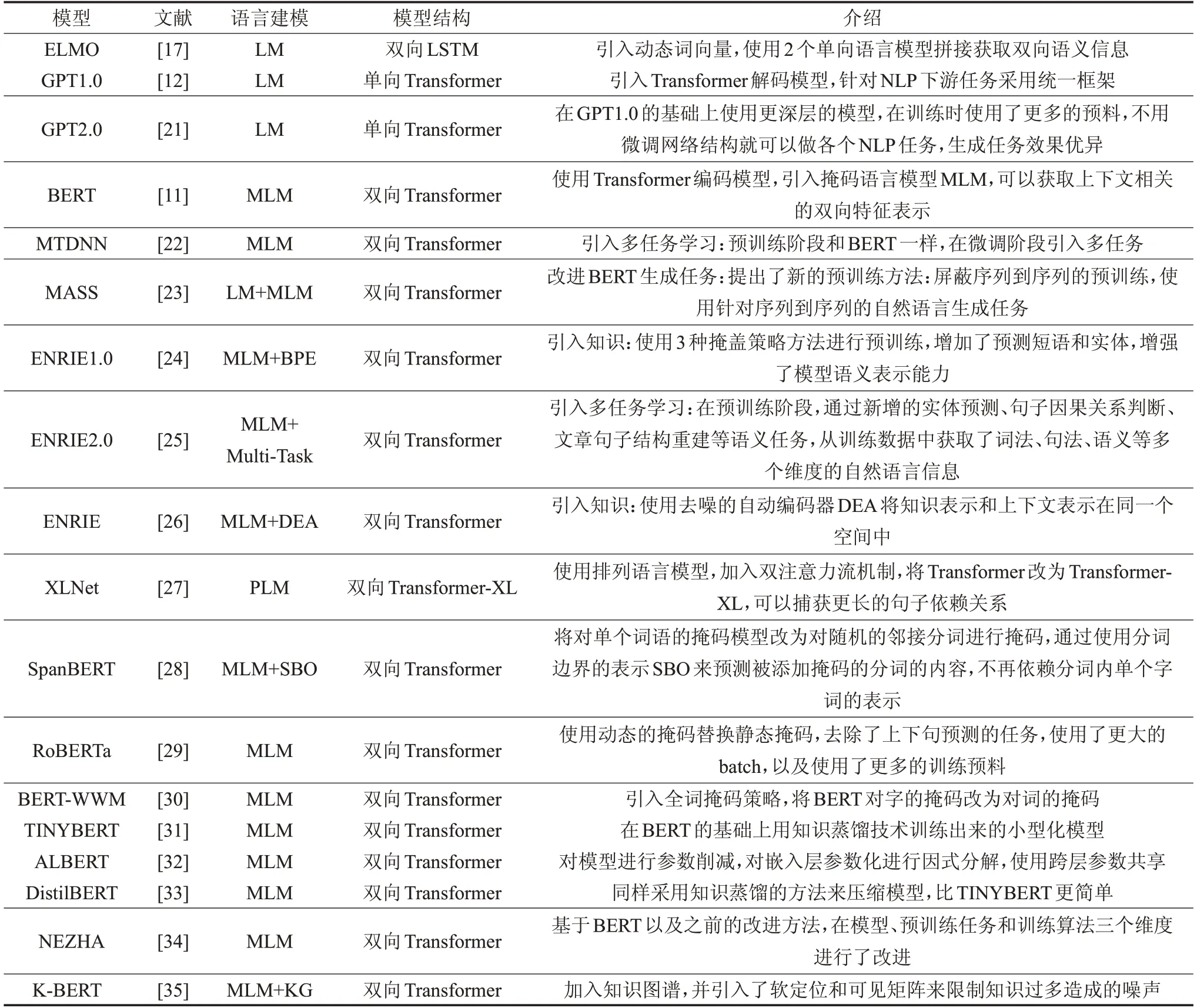
表1 預訓練語言模型對比
在ELMO以前解決閱讀理解的思路是通過Word2Vec等獲取固定的詞向量,或者隨機初始化詞向量,將字詞的表征送入神經網絡。ELMO 將通過預訓練得到的字詞表征以及網絡結構信息保存,在具體的閱讀理解任務時,把學到的句子特征信息也能應用到具體的任務。GPT 引入Transformer 解碼模型,并使用單向的語言模型,針對NLP下游任務采用統一框架。BERT結合GPT與ELMO的優勢,引入Transformer編碼模型,采用雙向的語言模型,訓練時增加了掩碼語言模型MLM[11]以及判斷句子順序的任務,可以獲取更多的語言表征。MASS[23]改進BERT 生成任務,提出了屏蔽序列到序列的預訓練方法,使用針對序列到序列的自然語言生成任務。百度公司提出的ENRIE1.0[24]和清華大學提出的ENRIE[26]模型引入外部知識到預訓練過程,MTDNN[22]以及ENRIE2.0[25]引入多任務學習到預訓練過程。XLNet[27]使用排列語言模型,加入雙注意力流機制,將Transformer改為Transformer-XL[36],可以捕獲更長的句子依賴關系。RoBERTa[29]使用動態的掩碼替換靜態掩碼,去除了上下句預測的任務,使用了更大的batch,以及使用了更多的訓練預料。BERT-WWM[30]引入全詞掩碼策略,將BERT對字的掩碼改為對詞的掩碼。TINYBERT、ALBERT以及DistilBERT等[31-33]通過對模型進行蒸餾獲取小型化模型,方便模型的部署。NEZHA[34]通過對在模型、預訓練任務和訓練算法三個維度進行了改進,K-BERT[35]加入知識圖譜,并引入了軟定位和可見矩陣來限制知識過多造成的噪聲。
2.3 模型使用方法
經過預訓練得到的語言模型具有強大的語言表征能力,但應用到機器閱讀理解任務上還需要進行領域微調、任務微調等方法。將預訓練語言模型遷移到機器閱讀理解任務上有以下幾種方法:
(1)領域微調
由于具體的機器閱讀理解任務與通用領域的數據存在差別,在具體任務之前,可以在任務數據上進行領域增量學習,使得最終的語言模型更靠近目標任務。具體做法,可以將目標任務的數據進行處理,處理為預訓練任務需要的輸入格式,然后進行增量訓練。
ELMO 以及GPT 系列[12,21]等采用自回歸語言模型的預訓練方法,BERT 采用基于去噪自編碼器方法進行訓練,構建掩碼預測與上下句預測任務,MASS 需要構建序列到序列的自然語言生成任務,ERNIE與BERT衍生系列[24-35]進行領域微調時可參考具體的預訓練任務進行設計。XLNet 加入了排列語言模型通過最大化所有可能的因式分解順序的對數似然,學習雙向語境信息,用自回歸本身的特點克服BERT 的缺點。設計好任務后將數據送入模型,設置好模型基本參數,當模型的損失降下來時即代表模型在目標領域微調完成。通過領域微調可以較好地應對目標數據集較小的情況,在公共領域數據集上獲取較好的語言模型,然后在目標數據集上進行微調獲取與數據集相關的特征。
(2)解決長度限制
由于機器閱讀理解任務很多篇章都會超過預訓練模型的最大長度限制,如BERT模型單條最大處理文本長度為512個字符,因此絕大多數情況下需要做截斷或者更換模型結構等操作。
①篩選最相關段落
將輸入段落根據長度限制進行分段,段和段之間有重疊部分,保證不遺漏重要信息。然后設計一個段落分類網絡,輸入問題和段落,以答案是否在這個段落里為標簽進行訓練,針對數據集中篇章比較長的問題有很大幫助。
②滑動窗口
由于預訓練模型單次能處理的最大文本長度為512,當輸入序列大于這個長度時,設定一個滑動窗口,將超過512的輸入序列進行分段,在第二段保留滑動窗口大小的文本長度以便于模型能連續處理上下文信息,不至于把段落信息完全分開。在最終答案選擇的時候,選擇在包含最大上下文的序列中輸出答案。
③使用Transformer-XL
Transformer-XL 架構在Vanilla 提出的Transformer基礎上引入了兩點創新:循環機制和相對位置編碼,以克服Transformer存在難以處理長文本的缺點。Transformer-XL的另一個優勢是它可以用于單詞級和字符級的語言建模。通過Transformer-XL 可以提升模型在長文本上捕捉信息的能力以及加快模型的推理速度。
(3)任務微調
根據數據集的特點設計不同的微調網絡結構,使得模型可以充分利用已訓練好的網絡參數,加快在有監督任務上的訓練速度,提高準確率,基于BERT 模型的預訓練任務和機器閱讀理解的微調結構如圖3所示[11]。左側是預訓練過程,經過預訓練得到較好的模型參數。右側是用于機器閱讀理解的微調示意圖,將問題與包含答案的上下文經過編碼輸入神經網絡,神經網絡的參數由預訓練得到的模型進行初始化。
預訓練模型中做有監督任務微調時最低層共享一個公共架構,通過調節高層的任務架構來實現不同任務的微調。ELMO 微調時考慮雙向LSTM 無監督模型的高層任務架構。GPT系列通過目標任務訓練模型后,將參數調整到監督目標任務中。BERT系列任務微調除了輸出層之外,在預訓練和微調中使用了相同的體系結構,相同的預訓練模型參數用于初始化不同下游任務的模型。百度提出的ERNIE模型預訓練時構建無監督預訓練任務和多任務學習進行增量的更新,微調階段可以有效地利用預訓練學習的知識。由于BERT 預訓練過程需要掩碼一部分輸入,忽略了被掩碼位置之間的依賴關系,易出現預訓練和微調效果的差異。XLNet用自回歸本身的特點克服BERT的缺點,還融合了當前最優自回歸模型Transformer-XL。
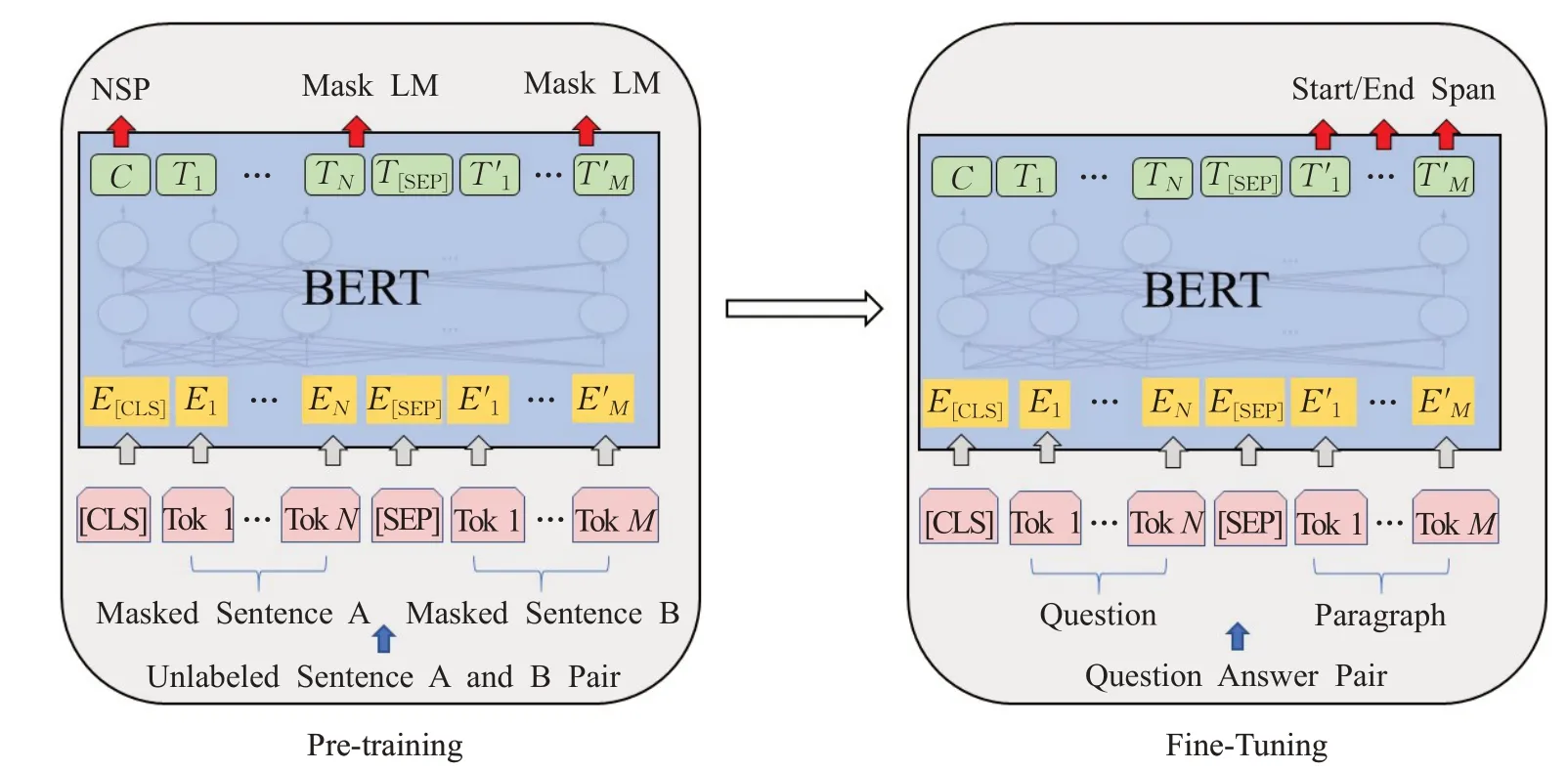
圖3 預訓練與機器閱讀理解任務微調
2.4 數據集
近年來發布的各種大型、真實的數據集推動了機器閱讀理解領域的快速發展。大規模數據集的出現使得端到端神經機器閱讀理解模型的訓練成為可能。從單詞表示、注意力機制到預訓練語言模型,神經網絡模型發展迅速,甚至在某些數據集上超越了人類的表現。每個機器閱讀理解數據集通常由文檔和測試文檔理解能力的問題組成。問題的答案可以通過從文檔中查找或提供的候選答案里來獲得。在這里根據答案的格式,可以大致將數據集分為四種類型,即完形填空、多項選擇、抽取型、描述型數據集。與此同時,還不斷有新的數據集出現,其中包含了更多樣化的任務,測試了更復雜的理解和推理能力。
本文將數據集根據語言、數量、來源等特征進行整理,如表2 所示,并將機器閱讀理解相關數據集獲取方式進行匯總托管于GitHub(https://github.com/crlgdx/MRCDataset)。
2.5 評價方法
對于不同的MRC 任務,有不同的評估指標。要評估完形填空和多項選擇任務,最常見的評價指標是準確率。在抽取型任務中通常使用EM(精確匹配)和F1 值進行評價,在描述型任務中,因為自由做答不局限于原始上下文,所以ROUGE-L[48]和BLEU[49]被廣泛使用。
EM 算法的思想與準確率類似,用于評估預測的答案是否與參考答案完全匹配。F1值計算方式是一種模糊匹配,將預測的答案短語切成詞后與參考答案共同計算準確率與召回率,即便預測答案和參考答案不是完全匹配也可能得分。Rouge 是評估自動文摘以及機器翻譯的一組指標。它將通過機器自動生成的摘要或翻譯與參考答案進行比較計算,得出相應的分值,以衡量自動生成的摘要或翻譯與參考答案之間的“相似度”。BLEU最初用于評估翻譯性能。在應用到MRC任務時,BLEU評分主要衡量預測答案與標準答案之間的相似性。
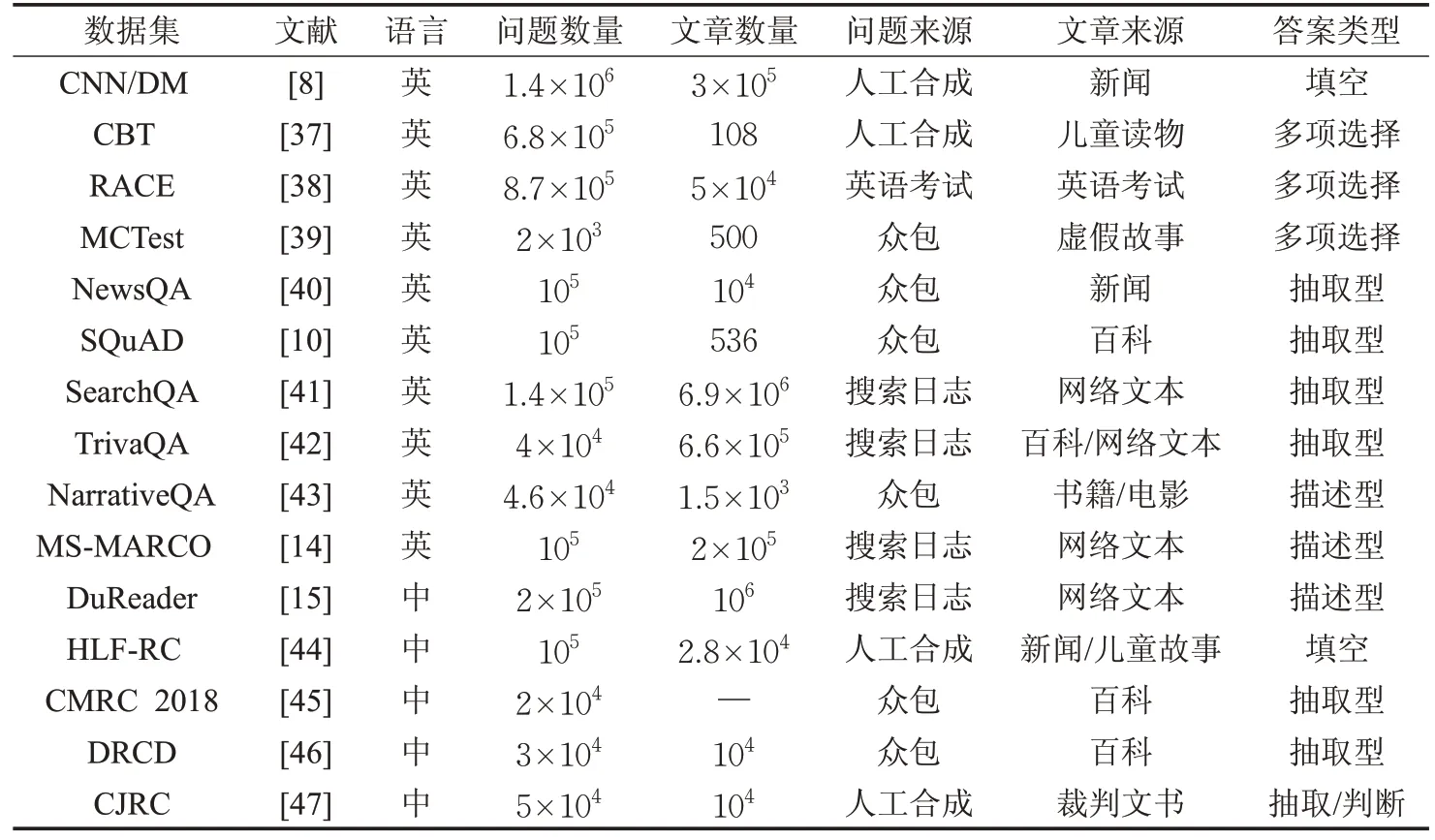
表2 機器閱讀理解數據集匯總
3 性能分析
早期的機器閱讀理解采用模塊分離的方式進行設計,通過詞嵌入層、編碼層、匹配層以及答案選擇層各個模塊共同組合進行機器閱讀。而早期的詞向量技術和網絡結構不夠成熟,限制了模型的表達與計算能力。預訓練語言模型的發展使多個NLP 任務取得了明顯的進步,增強了語言表征能力,同時也推動了機器閱讀理解的進步。
表3和表4將當下預訓練模型相關論文中提到的數據集以及性能得分進行匯總,表3 是目前比較常見的SQuAD 1.1和SQuAD 2.0數據集。通過對比可以看出預訓練模型優于傳統模塊分離方式的性能,帶來絕對的效果提升。在XLNet 以及后續的BERT 系列的改進版本中性能逐漸提升,說明預訓練模型還需要進一步發展。表4 匯總了預訓練模型在相關中文數據集上的表現,由表中CMRC、DRCD、DuReader數據集的表現可以看出描述型任務的數據集比抽取型任務的數據集要更復雜、更困難。再通過CMRC與CJRC數據集的性能對比,可以看出專業性較強的任務也會更復雜。CMRC是通用領域的數據集,而CJRC是法律領域的數據集,預訓練模型在專業知識較強的領域上還有很大的提升空間。
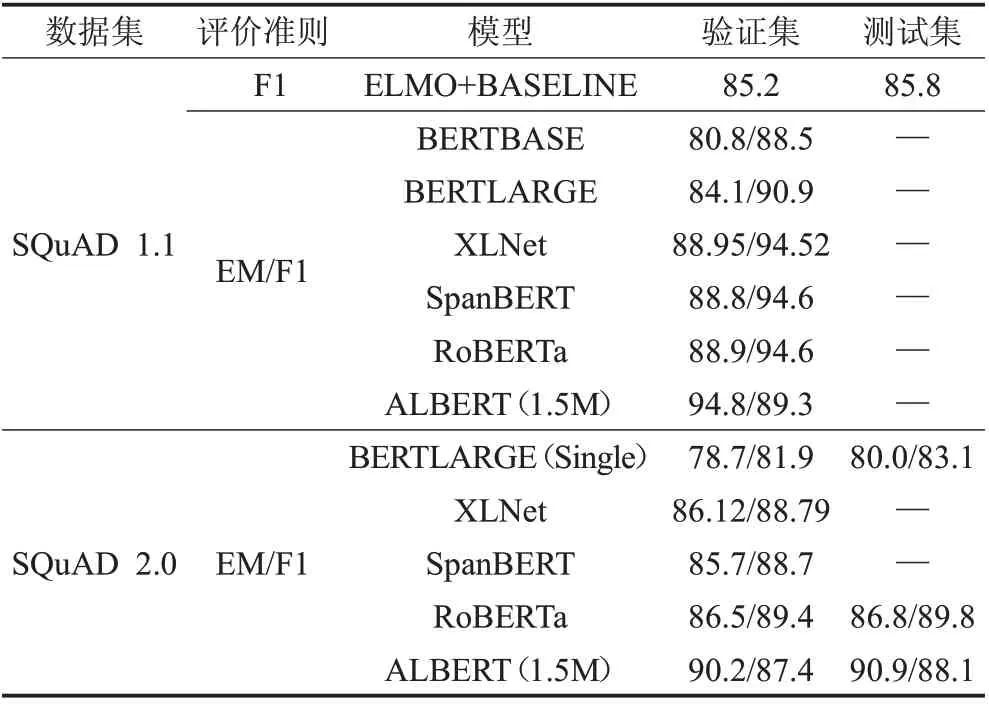
表3 預訓練模型在英文數據集上的性能表現 %
4 研究趨勢
(1)模型輕量化
在預訓練模型技術的推動下,模型的網絡結構越來越復雜,參數也越來越多。復雜的網絡帶來了性能提升的同時,也帶來了應用的困難。首先模型需要在大量的無監督數據集上進行預訓練,需要大量的時間以及巨大的運算資源。按照BERT論文里描述的參數,其基礎版模型的設定在消費級的顯卡Titan x 或GTX 1080ti(11 GB RAM)上,需要近幾個月的時間進行預訓練,同時還會面臨顯存不足的問題。其次,復雜的網絡結構很難做到實時的響應,而用戶的需求一般需要在秒級內進行響應,這對服務器的性能也提出很大的要求。
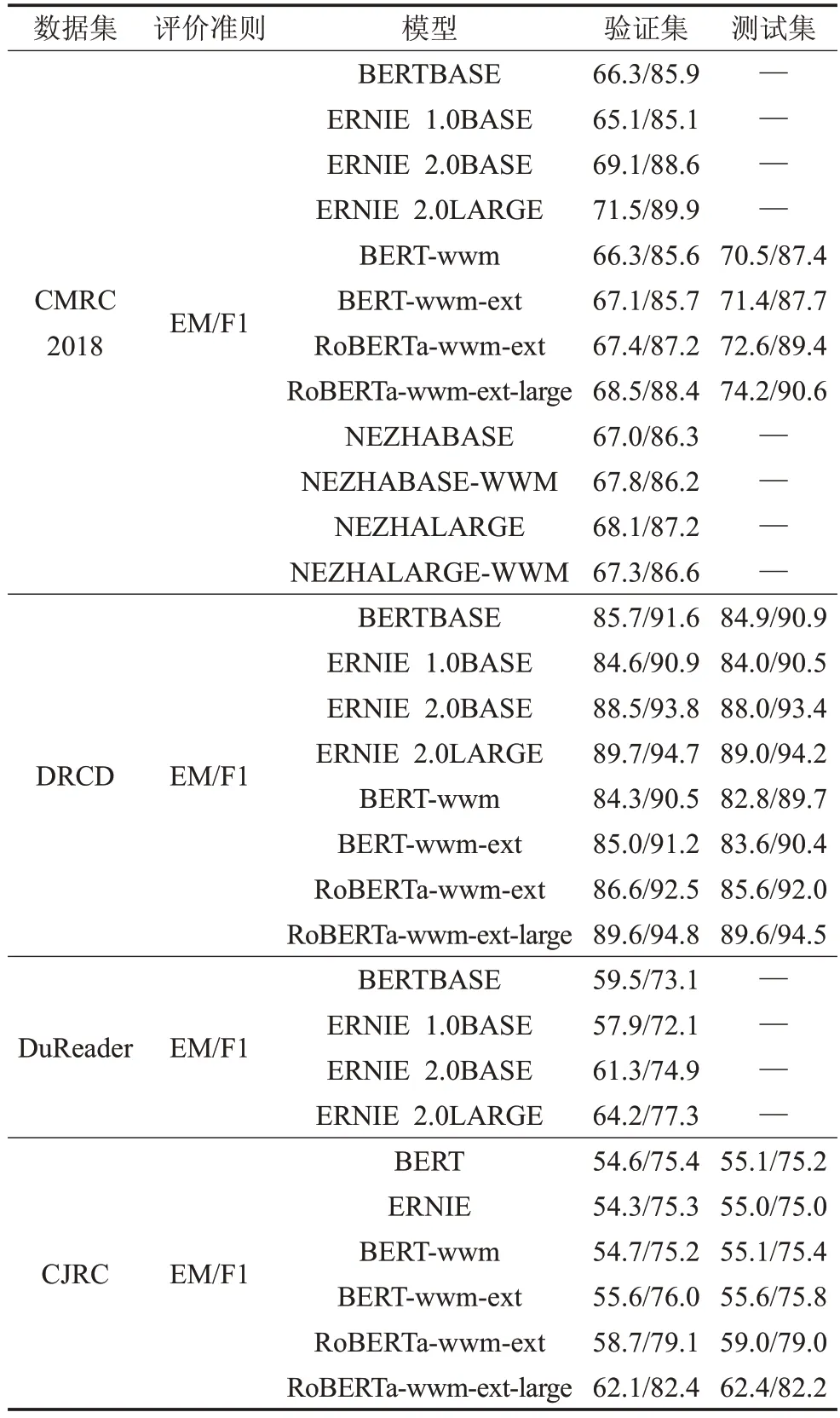
表4 預訓練模型在中文數據集上的性能表現%
針對模型參數較大,網絡復雜的情況,研究員也提出了一些新的模型,如對網絡蒸餾、嵌入層因式分解、跨層網絡參數共享等。
ERNIE Tiny 是一個小型化ERNIE[24],通過采用淺層模型,將12層的ERNIE Base模型壓縮為3層,線性提速4 倍,但效果也會有較大幅度的下降;增加隱藏層的數量,模型變淺帶來的損失可通過隱藏層的增大來彌補。由于ERNIE采用的框架對于通用矩陣運算的最后一維參數的不同取值會有深度的優化,因此增加將隱藏層大小不會帶來速度線性的增加;縮短輸入文本長度,ERNIE Tiny 是首個開源的中文詞粒度的預訓練模型。這里的短是指通過詞粒度替換字粒度,能夠明顯地縮短輸入文本的長度,而輸入文本長度是和預測速度有線性相關;為了進一步提升模型的效果,ERNIE Tiny扮演學生角色,利用模型蒸餾的方式在Transformer 層和Prediction層去學習教師模型ERNIE模型對應層的分布或輸出,這種方式能夠縮近ERNIE Tiny 和ERNIE 的效果差異。
在ALBERT[32]中通過對Embedding層進行因式分解,縮減網絡參數,由于在BERT 中,字詞Embedding 與Encoder輸出的Embedding維度是一樣的。但是ALBERT作者認為,詞級別的Embedding是沒有上下文依賴的表述,而隱藏層的輸出值不僅包括了詞本身的意思還包括一些上下文信息,理論上來說隱藏層的表述包含的信息應該更多一些,因此應該讓隱藏層大于嵌入層,所以ALBERT的詞向量的維度小于Encoder輸出維度。跨網絡層的參數共享是提高參數使用效率的另一種方法,共享參數的方法有多種,例如只跨層共享前饋網絡參數,或只共享注意力參數。
(2)結合外部知識
像BERT 這樣的無監督預訓練語言表示模型已經在多個NLP 任務中取得了最先進的結果。這些模型是在大型開放域語料庫上預先訓練的,以獲得一般的語言表示,然后在特定的下游任務中進行微調,以吸收特定領域的知識。然而,由于訓練過程與微調領域的數據集存在差異,對于某些需要相關領域知識很強的問題,在公共領域訓練的模型將會比較吃力。
針對預訓練與微調差異較大的問題可以結合外部知識進行輔助微調,如結合專家知識,結合領域內已有的知識圖譜幫助模型獲取更多領域相關的知識。當閱讀一個特定領域的文本時,普通人只能根據上下文來理解單詞,而專家則可以用相關的領域知識進行推理。
為了使模型充分利用外部知識,清華大學Zhang等人[26]認為知識結構中的信息實體可以通過外部知識增強語言表征,利用大規模的文本語料庫和知識庫來訓練一個增強的語言表示模型。百度公司Sun等人[24]提出的ERNIE 1.0 通過建模海量數據中的詞、實體及實體關系,學習真實世界的語義知識,增強了模型語義表示能力。后來提出基于持續學習的語義理解預訓練框架ERNIE 2.0[25],使用多任務學習增量式構建預訓練任務。通過新增的實體預測、句子因果關系判斷、文章句子結構重建等語義任務,ERNIE 2.0語義理解預訓練模型從訓練數據中獲取了詞法、句法、語義等多個維度的自然語言信息,極大地增強了通用語義表示能力。北京大學Liu等人提出了一種基于知識圖譜的語言表示模型K-BERT[35],該模型將三元組作為領域知識注入到句子中。基于知識圖譜的閱讀理解突破了回答問題所需的知識范圍僅限于給定上下文的限制。因此,借助外部世界的知識,可以在一定程度上縮小機器理解與人類理解之間的差距,提高系統的可解釋性。
(3)任務數據多樣性
由于預訓練時通常在有限的語料庫下進行訓練,因此,通過進一步對其他語料庫進行預訓練,增加多樣性可以提高通用性,在微調階段使用來自不同的語料庫可以作為輔助任務。向MRC添加語言建模目標的好處是它可以避免災難性的遺忘,并保持從培訓前任務中學到的最有用的功能。此外,通過合并其他NLP任務(例如自然語言推理和段落排名)的監督數據集可以學習到更好的語言表示形式。
近年來,隨著機器閱讀理解的發展,相關的中文數據集也逐漸增多。人們對各種信息的需求也日益增加,數據集逐漸擴展到各個領域,出現了針對法律案件[47]、軍事信息等相關的數據集。數據集的多樣性可以豐富機器閱讀理解任務,同時也帶來更多可能。
現有的模型對于存在噪聲的例子還很脆弱,這將成為在現實世界中部署這些模型時所面臨的一個嚴重問題。而且目前的大多數工作都是對同一個數據集分割進行訓練和評估,如果在一個數據集上訓練模型,并在另一個數據集上進行評估,由于它們的文本來源和構造方法不同,性能將顯著下降。需要考慮如何創造更好的對抗訓練示例并且將它們加入到訓練過程中對遷移學習和多任務學習進行更多深入的研究,建立跨數據集的高性能模型。
(4)合適的評估指標
評估指標是衡量機器閱讀理解水平的清晰指標,但是目前對模型性能的評價大多在比較單一的任務上。模型在某一個數據集上性能比較好時,在其他數據集上效果往往會比較差。在單一任務或者單一數據集上性能的提升是否意味著模型取得了真正的進步?如何判斷閱讀理解模型與真正的人類閱讀理解水平之間的差距是一個比較有挑戰的問題。
評價模型性能時可以參考人類的閱讀理解考試[50],因為這些問題通常是由專家學者共同策劃和設計,以測試人類閱讀理解能力的不同水平。在構建自然語言理解系統時,使計算機系統與人類評價系統保持一致是一種正確的方法。在未來,對模型的評價不能只在一個數據集上進行測試,需要將許多閱讀理解數據集結合起來,作為一個通用的標準進行評估,這將有助于更好地區分哪些模型是對閱讀理解真正的進步。
5 機器閱讀理解應用
(1)輔助決策
機器閱讀理解技術作為人工智能領域重要的研究方向,主要是讓機器讀懂文本、理解語義、挖掘推理出關鍵信息,幫助人類從海量碎片信息中獲取所需知識。在數據大爆炸的時代,如何快速地獲取用戶關心的信息幫助用戶進行決策是一個有挑戰的任務。尤其是面對專業性比較強的領域,如醫生的診斷記錄,金融行業的歷史數據,法院的判決書等,這些都需要用戶具備較多的相關知識儲備,需要前期大量的準備工作,消耗大量的人力物力。在知識賦能的信息化時代,通過機器閱讀理解可以快速地搜集用戶所關心的資料,幫助用戶分析問題解決問題,并給出合理的建議。因此,將機器閱讀理解引入專業性較強的領域,可以幫助用戶更好地決策,更有效地工作。
(2)社區問答
網絡技術的飛速發展推動了互聯網中的用戶生成內容的規模不斷增長,作為一種新的網絡信息資源,高質量的用戶生成內容的研究和應用價值正逐漸顯現。由問題和其答案組成的問答對是用戶生成內容的典型代表,是用戶之間以互聯網為媒介的知識分享行為的直接產物。傳統的社區問答主要基于檢索去匹配用戶的問題并尋找答案,這樣得到的答案往往包含大量的噪聲,而通過與機器閱讀理解相結合的方式可以從包含著大量噪聲信息的網絡社區內容中自動識別和抽取問答信息,快速精準地得到用戶所關心的答案。
(3)聊天機器人
智能聊天機器人,是一種通過自然語言模擬人類進行對話的程序,可以對外提供客戶服務、對內進行業務輔助,實現全方位的效能提升,降本增效。目前,特定場景和領域的聊天機器人已經展現出了很高的自然語言理解與處理能力,例如:小度、Siri、小愛同學等。智能聊天機器人除了可以閑聊以外,還可以用在問答作為問答機器人,回答專業領域的問題。未來,與機器閱讀理解相結合的技術將使得聊天機器人能夠更準確地識別用戶的問題和意圖。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
文苑(2020年4期)2020-05-30 12:35:30
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
瘋狂英語·新策略(2017年8期)2017-05-31 08:13:46
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
少兒科學周刊·少年版(2015年4期)2015-07-07 21:11:17
