基于系統調用的智能終端惡意軟件檢測框架
2020-06-12 09:17:38陳怡西景小榮
計算機工程與設計 2020年6期
王 寧,王 丹,陳怡西,景小榮,2
(1.重慶郵電大學 通信與信息工程學院,重慶 400065;2.重慶郵電大學 移動通信技術重慶市重點實驗室,重慶 400065)
0 引 言
Android智能終端在市場中占有率高[1]主要有以下幾個因素:Android智能終端的開源性,生產商可以根據需求定制不同的系統,用戶同樣能編寫自己喜歡的應用軟件;硬件兼容性高,跨平臺特性強,Android生產商不斷推出各種設備來吸引顧客,比如平板、電視等,而且上層應用也可以向多種產品移植,用戶體驗豐富,性價比高。相比與其它操作系統的智能終端,在同樣的價格下,Android智能終端具有絕對的性價比優勢,應用豐富且開發門檻低。
然而智能終端產品質量問題被頻頻報道,特別是Android平臺下的一些惡意應用給用戶造成很多難以彌補的損失。這些惡意應用分為病毒類、木馬類、后門類、僵尸類等多種類型,它們在使用者未授權的情況下執行違法行為,進而造成數據和信息泄露,財產損失等問題,極大地影響了消費者對智能終端產品的信心。根據調研,由于Android產品軟件和硬件的各種質量問題,用戶流失比例較高,嚴重制約了該產業的發展[2]。
1 相關工作
針對上述問題,學術界和產業界的研究者越來越重視Android的安全研究。安全軟件商如360公司、騰訊公司等,以監控權限的使用、維護服務器建立惡意軟件庫等為切入點,來保護設備的安全,但這些方法都有著明顯的不足:一方面,對于多數使用者來講,它們沒有足夠專業的知識對當前軟件的安全進行判斷;另一方面,搭建惡意軟件數據庫這一方法已經很難對未知家族的惡意軟件或已知家族惡意軟件的變種進行檢測。華為應用市場審核應用時,則采用人工與機器相結合的方法確保應用的安全,但是Android惡意軟件一直層出不窮,沒有妥善地解決該問題。學術界則把惡意軟件檢測技術主要分為軟件代碼的靜態檢測和運行時的動態檢測兩種。
靜態檢測技術的主要思想在于掃描軟件的源程序或者二進制代碼,通過直接分析被檢測程序的特征,進而查詢程序的異常狀態。Wei W等[3]則通過計算單個權限(Permission)和惡意軟件之間的關聯度,分別從3方面系統地分析了以Permission為判斷規則的有效性和局限性。Daniel A等[4]收集了大量安裝包中的可獲得信息(如請求的Permission、應用組件等),反編譯后的信息(如API調用、網絡地址等),并通過支持向量機(support vector machine,SVM)分類軟件,然而此方法只在單個應用程序上性能較優。Manzhi Y等[5]對APK文件反編譯后,將文件各個部分映射成圖像,依據其產生的不同視覺特征,通過機器學習進行惡意代碼分類。目前己形成的靜態分析工具有androguard等。
然而,靜態檢測中無法對混淆代碼、加殼代碼進行分析,動態檢測技術則彌補了此缺陷,該技術是通過實時追蹤軟件在模擬器中運行時的行為特征,然后對其進行處理的過程。在所有動態檢測工作中最為著名的是Enck W等[6]提出的污點標記追蹤技術,在該方法中,當軟件的目標代碼在Dalvik虛擬機中運行時,標記相關污點數據,進而對敏感數據的流向進行跟蹤。但本地代碼中的隱私泄露問題無法得到解決。Tam K等[7]提出了一款名為CopperDroid的框架,將應用軟件放置在沙盒測試環境中,一邊與外部系統交互,一邊利用操作系統中的系統調用(system call,SC)等信息,以達到還原應用行為的目的,缺點是該框架只適用于離線分析。Stephan H等[8]綜合了API監控、內核系統調用監控、污點標記追蹤等動態分析方式,通過多種技術以觸發應用行為,從而在隱私泄露等方面的分析中取得了較好的效果,但是它對于計算資源和電量并不充裕的移動設備來說是不小的開銷。Mayank J等[9]提出了以系統調用為分析對象的動態檢測系統,并分析了良性和惡意軟件系統調用之間的相似性和差異性,該系統使檢測惡意應用程序的資源消耗更小,但是沒有考慮系統調用之間的關聯性。Xi X等[10]提出了一種基于系統調用序列的馬爾可夫鏈反向傳播神經網絡,該方法把一個系統調用序列看作一個齊次平穩的馬爾可夫矩陣,通過應用反向傳播神經網絡,比較矩陣中的轉移概率來檢測惡意軟件,但復雜度較高。因此,動態檢測時間較長,實時性不高,效率低,系統資源消耗較多。文獻[11]則提出一種基于系統調用頻率的新型惡意軟件檢測方法,但此方法并未考慮系統調用之間的相關性和整體性。相較之下,文獻[12]提出的自動分類框架將系統調用之間的相關性考慮在內,但該框架容易導致過擬合。目前已形成的動態分析工具有Droidbox等。
通過上述對惡意軟件的檢測研究現狀的分析發現,靜態檢測和動態檢測均存在著大量亟待解決的問題,動態檢測技術能由于能夠實現對加密惡意軟件進行分析,因此,更具研究價值。但是,目前基于動態檢測的惡意軟件檢測方案存在檢測準確率低等問題;其次,Android的惡意軟件檢測技術一般基于特征提取,而提取的特征種類和維度對檢測效率起著決定性的作用。考慮到這些因素,本文通過對智能終端中的惡意軟件樣本進行動態分析,提出了一種基于系統調用的惡意軟件動態檢測框架。該惡意檢測框架不但能豐富這一研究領域,而且根據仿真結果,顯示其具有很強的實用性。
2 基于系統調用序列的動態檢測框架
2.1 惡意軟件動態檢測框架描述
基于以上分析與研究,本文提出的基于系統調用序列的惡意軟件動態檢測框架,如圖1所示。該框架的內容主要分為3個階段:第一階段為特征提取:搭建沙盒測試環境,自動化安裝待檢測樣本,模擬和激發待測樣本的動態行為,同時使用檢測工具記錄動態行為的日志,進而提取出待測樣本信息;第二階段為特征預處理:將動態行為的日志信息進行預處理,該階段包括數據降維,特征標簽化處理和去冗余3個步驟;第三階段為機器學習分類處理:在學習前構建系統調用的馬爾可夫矩陣,并將結果轉化為SVM能夠識別的格式,進而將訓練集輸入進行有效實驗,得出訓練好的分類模型用于判斷。最后對惡意樣本和正常樣本的混合測試集進行檢測,得出檢測結果。
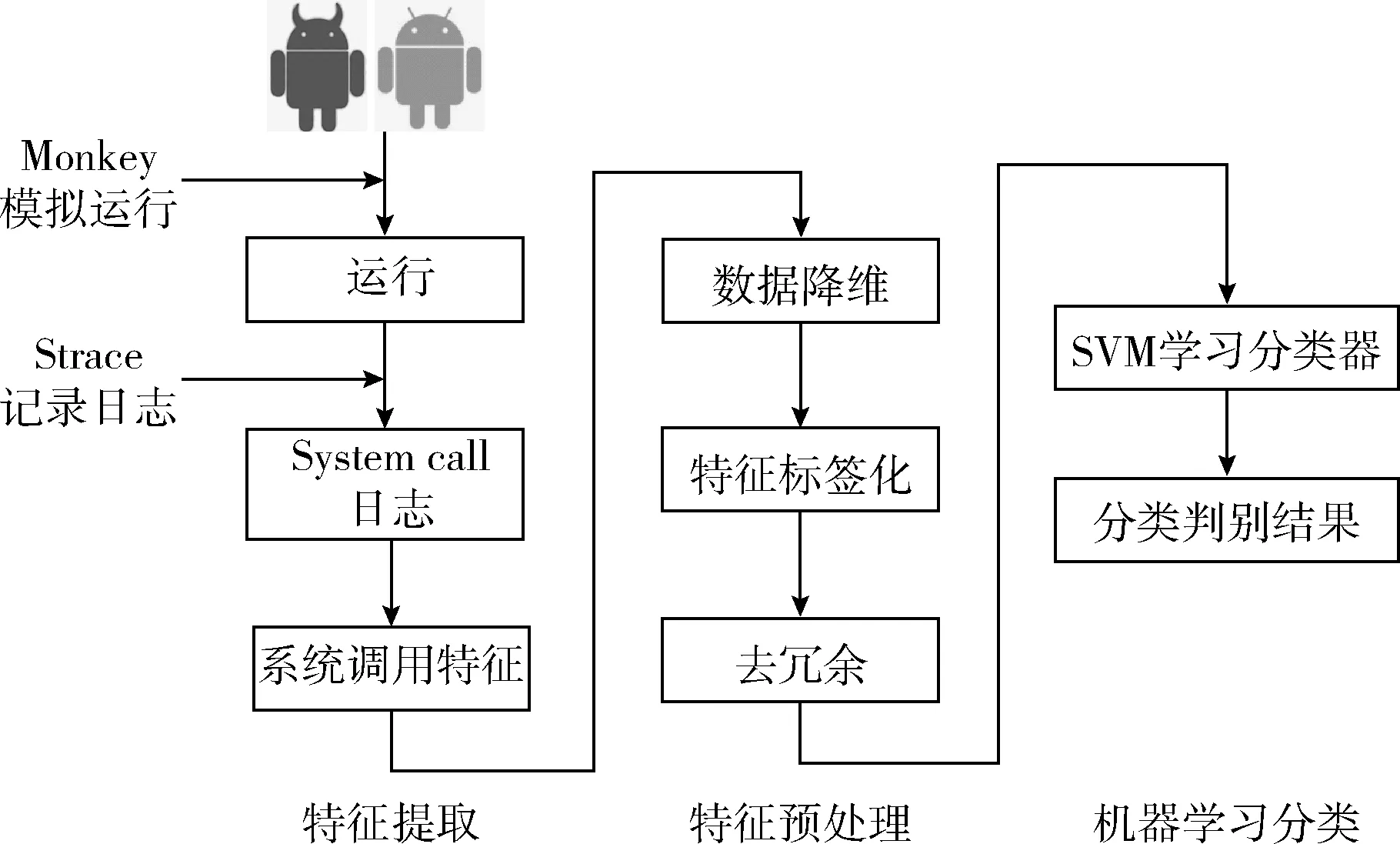
圖1 動態檢測框架
2.2 動態特征提取
在惡意軟件的動態檢測框架中,如何提取特征是整個流程的重點工作。本文通過監控并記錄系統調用完成特征提取,原因有二。其一,Android操作系統采用了分層的架構形式,其底層為Linux內核層,系統調用是Android系統與軟件之間交互的底層接口,能夠充分反映應用程序執行過程中的行為;其二,某些系統調用在惡意軟件和正常軟件的使用頻率和使用規則中存在明顯差異,例如,名為read的系統調用在樣本中的概率轉移特性和調用頻率與在正常軟件中明顯不同時,那么這一樣本是惡意樣本的可能性就越高。
其具體步驟如下:首先獲取模擬器或者Android設備的超級管理員(Root)權限,下載并安裝超級管理員軟件(Android debug bridge device,ADBD)并開啟超級管理員模式,否則設備在啟動系統用戶空間跟蹤器(Strace)命令時會警告并提示未獲得權限(permission not allowed);其次獲取待測樣本的進程身份編號(personal ID,PID),進而利用Strace命令提取系統調用的動態特征,如果設備中沒有Strace命令,則需要使用調試工具(Android debug bridge,ADB)命令將相應版本的Strace可執行文件放置于設備系統程序集緩存(bin)下,若有權限問題,則進行重新掛載,并使用命令增加工具的可執行權限即可;然后利用模擬人工操作工具(Monkey)在樣本軟件上模擬人工操作,等待程序自動運行一段時間后,殺死進程,此處需要保證每個待測樣本運行時間一致;最后將樣本日志文件以文本(TXT)格式記錄保存后,去除掉亂碼部分,同時把系統調用的參數部分全部去除,進而得到按時間順序輸出的系統調用序列。上述過程的流程如圖2所示。在實驗實施過程中使用了多個調試監控工具,表1對這些工具進行了匯總。
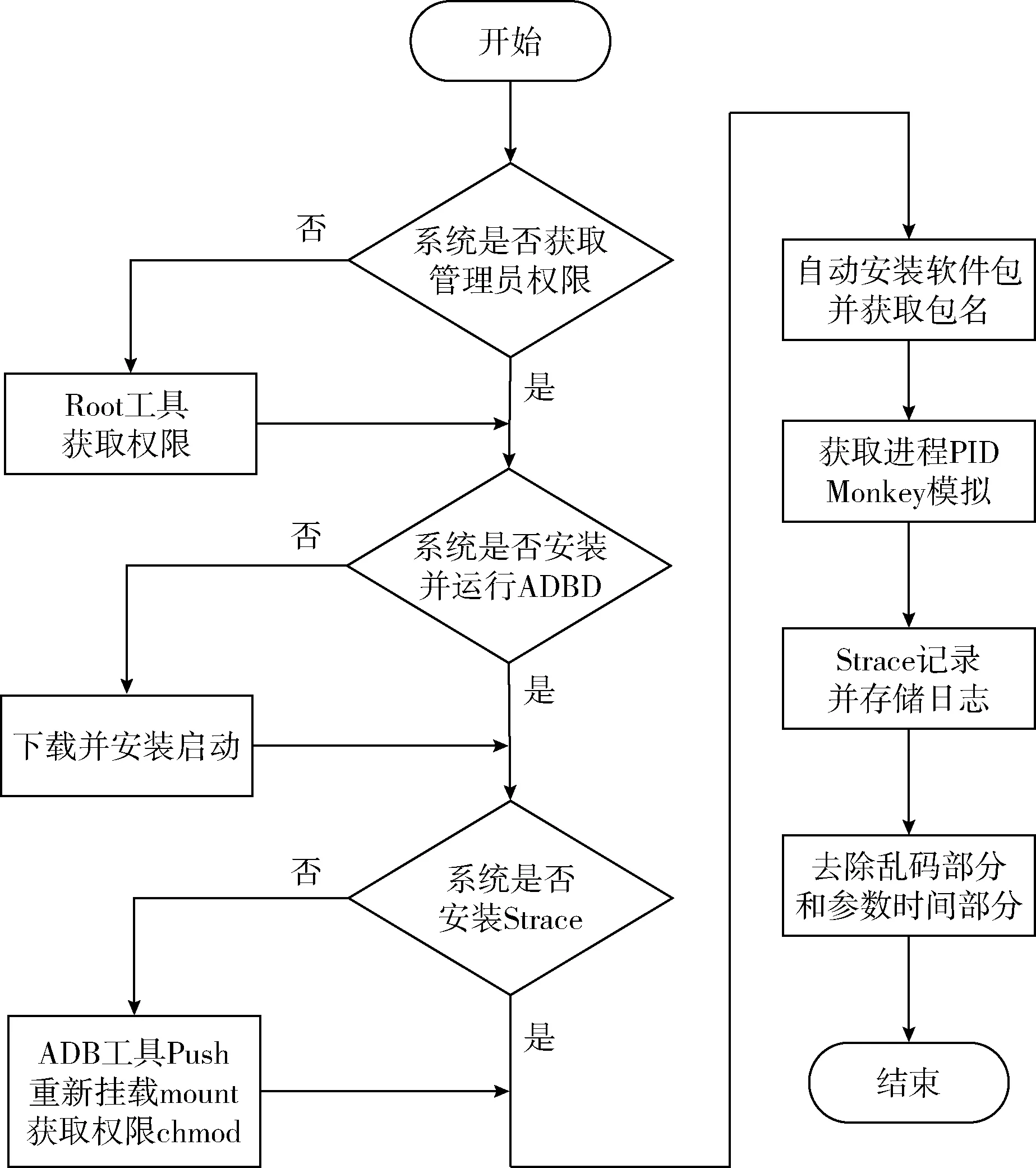
圖2 特征提取流程
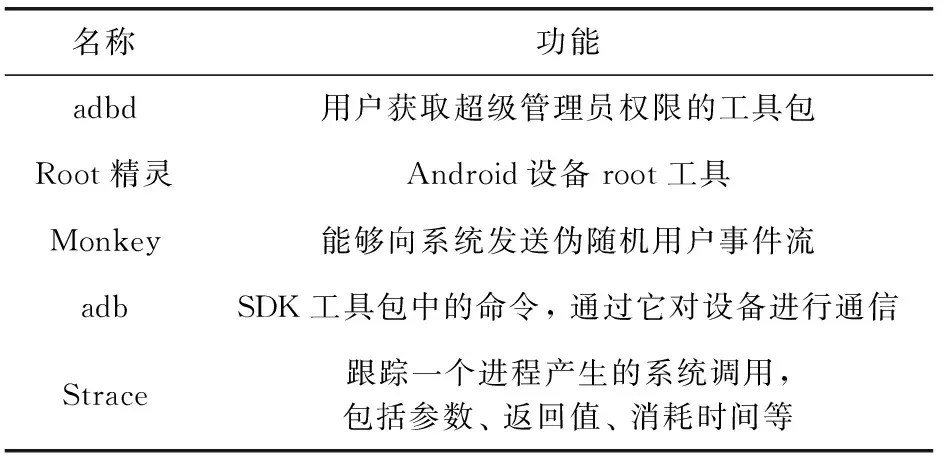
表1 工具匯總
2.3 特征預處理
特征預處理階段的目的是小幅度降低檢測率的同時大幅度降低檢測復雜度,該階段主要包含數據降維、特征標簽化和去冗余3個步驟。在數據降維和去冗余時需要選取合適的閾值,本章后續章節將具體介紹,下面將詳細描述特征預處理過程。
2.3.1 數據降維
惡意軟件檢測一般基于特征提取,而提取的特征種類和維度起著決定性的作用,特征維度過多會導致檢測時間過長,特征提取少又會導致檢測準確率下降。目前,研究人員通常以犧牲效率為代價,提取出多維度特征,換取檢測準確率的提升,如何對多維度特征篩選和降維并達到同等檢測準確率是一大難點。
本文實驗中的操作系統包含196個系統調用,由于后期需要針對系統調用構建馬爾可夫矩陣,如果不降維處理維度將高達196的平方。信息增益(information gain,IG)法是在決策樹算法中用來選擇特征的方法,它能夠很好地衡量特征為分類系統帶來信息量的多少,因此本文采用信息增益法對系統調用按照不同重要程度進行量化評分,并按評分高低對系統調用進行分類處理。定義待分類系統調用集合C的熵H(C)與某系統調用T的條件熵H(C|T)之差為系統調用T給系統帶來的信息增益IG(T),即
IG(T)=H(C)-H(C|T)
(1)
其中
(2)
(3)

(4)
(5)
將式(2),式(3),式(4)和式(5)帶入式(1),則
(6)
根據IG方法,得到全部系統調用的評分見表2,IG(T)越大,特征T對分類結果越重要。然后根據評分選擇合適的閾值(閾值的選擇在下一節我們將通過數值仿真給出),將196個系統調用分為“重要”和“無用”兩個部分,將“重要”部分作為主要特征。例如,表2中flock的評分高于rename,那么flock這一系統調用在惡意軟件和正常軟件之間差異較大,比rename更適合作為評價指標,即更“重要”。但“無用”部分也會對檢測帶來影響,由于系統調用數量較多,對于“無用”部分,屬于同一類別的系統調用合并為一類,本文將其按照屬性不同劃分為文件類,進程類,網絡管理類,內存類,系統類,進程通信類和用戶管理類7個類型,實現數據降維。
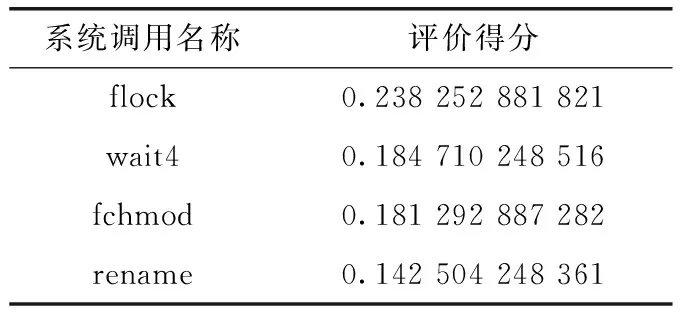
表2 工具匯總系統調用評分(部分)
2.3.2 特征標簽化
特征標簽化處理是為了使數據能夠被機器學習處理。首先,將降維后的系統調用映射為標簽值,一個標簽代表一個向量維度,映射函數表達式如下
Label=QSC
(7)
其中,Q表示從系統調用到標簽值的映射函數,Label為輸出的標簽值,一個Label代表一個維度,SC表示系統調用。在該映射函數中,“重要”部分的系統調用與標簽值一一映射,而對于“無用”部分,屬于同一類別的系統調用映射為同一個標簽值,實現多對一映射,并將所得系統調用與標簽值之間的映射關系存儲到數據庫。
其次,樣本根據數據庫中的映射關系,將按時間順序輸出的系統調用映射成Label依次輸出,從而得到標簽化的系統調用序列,如圖3所示。

圖3 標簽化的系統調用序列
2.3.3 去冗余
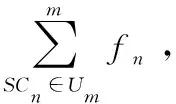
針對以上問題,本文提出了改進的TF-IDF算法和N-gram平滑算法相結合的方案對軟件中的冗余信息進行去除。在該方案中,首先使用N-gram算法,將文本劃分為多個子序列,然后用改進的TF-IDF算法評價子序列,選擇合適的閾值去除評分低的子序列,將評分高的子序列重新連接即可。具體內容如下:
首先對圖3所示的序列進行N-gram處理,根據文獻[13],N取值為3時性能較優,具體方法示例如圖4所示,Si表示系統調用,每3個相鄰的系統調用構成一個子序列,每次平滑一個單位,獲取下一個子序列,直至遍歷完樣本,并將N-gram得到子序列的順序與出現的次數保存在數據庫中待用。
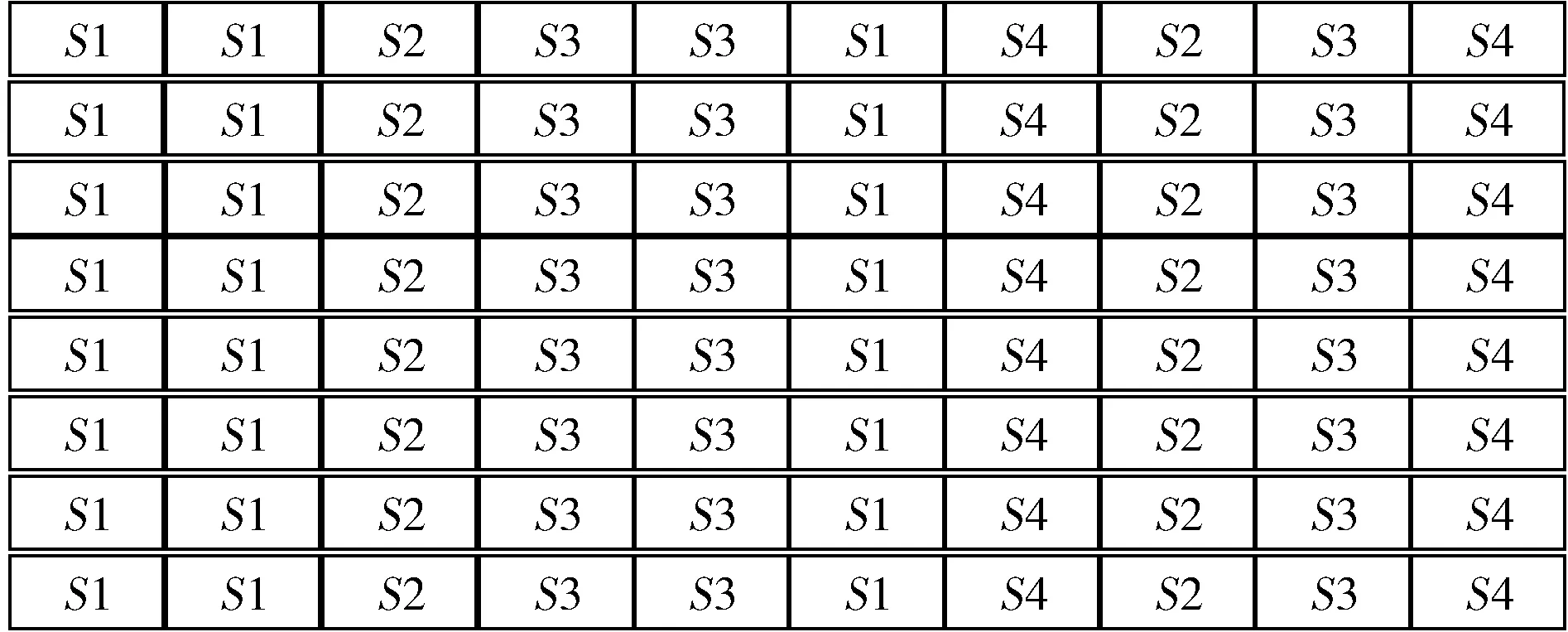
圖4 標簽化的系統調用序列
傳統的TF-IDF算法用以評估一個詞對于一個文件的重要程度。本文采用改進的TF-IDF算法對N-gram算法得到的子序列進行量化評分,以評估子序列對樣本庫的重要程度。TF是某個子序列出現的頻率,即某個子序列在樣本庫中的頻率,其計算公式如下
(8)
其中,TFj為子序列tj在樣本庫中出現的頻率;nj為子序列tj在樣本庫中出現的次數。IDF,即“反文檔頻率”,其計算公式如下
(9)
其中,IDFj表示子序列tj的反文檔頻率;|D|表示樣本庫中的樣本總數;|i:tj∈di|表示出現子序列tj的日志總數;tj∈di表示子序列tj在動態行為日志di中出現;+1是防止分母為0。最后子序列tj的評分為:TFj*IDFj。
最后根據評分從大到小選取合適的閾值(閾值的選擇在下一節我們將通過數值仿真給出),去除評分小的冗余信息,僅保留評分大的“重要數據”,并對這些子序列重新進行合并,某一樣本合并流程的偽代碼見表3,在程序執行過程中由于Index的值不同而會影響子序列的連接方式,因此在設置子序列的連接方式中,樣本首尾的兩個系統調用會直接保存,不做去冗余處理,從而得到去冗余后的系統調用序列。相比于將標簽化后的系統調用序列直接分類處理,去冗余能夠在一定幅度上提高檢測結果。

表3 子序列連接方式
2.4 機器學習分類
通常情況下,在SVM中,用樣本點與超平面之間的距離來表示分類的準確率。最大化該距離的平均值則是SVM的目的。如圖5所示,黑點和白點分別代表不同類別的樣本,通過兩條虛線之間的超平面以完成分類,但僅僅實線部分所表示的超平面能夠取得最大的區分間隔,使分類器達到最優的分類目的,即實線代表的超平面為決策最優超平面。SVM的邊界為兩條虛線上的3個樣本,它們是找尋最優分類超平面的重要依據,被稱為支持向量。本文中Android惡意軟件的檢測判別是一個二分類問題,而SVM正是一種特殊的二類分類模型,并且該模型在解決樣本量較小以及高維度識別問題方面具有優勢,因此適用于軟件檢測領域。
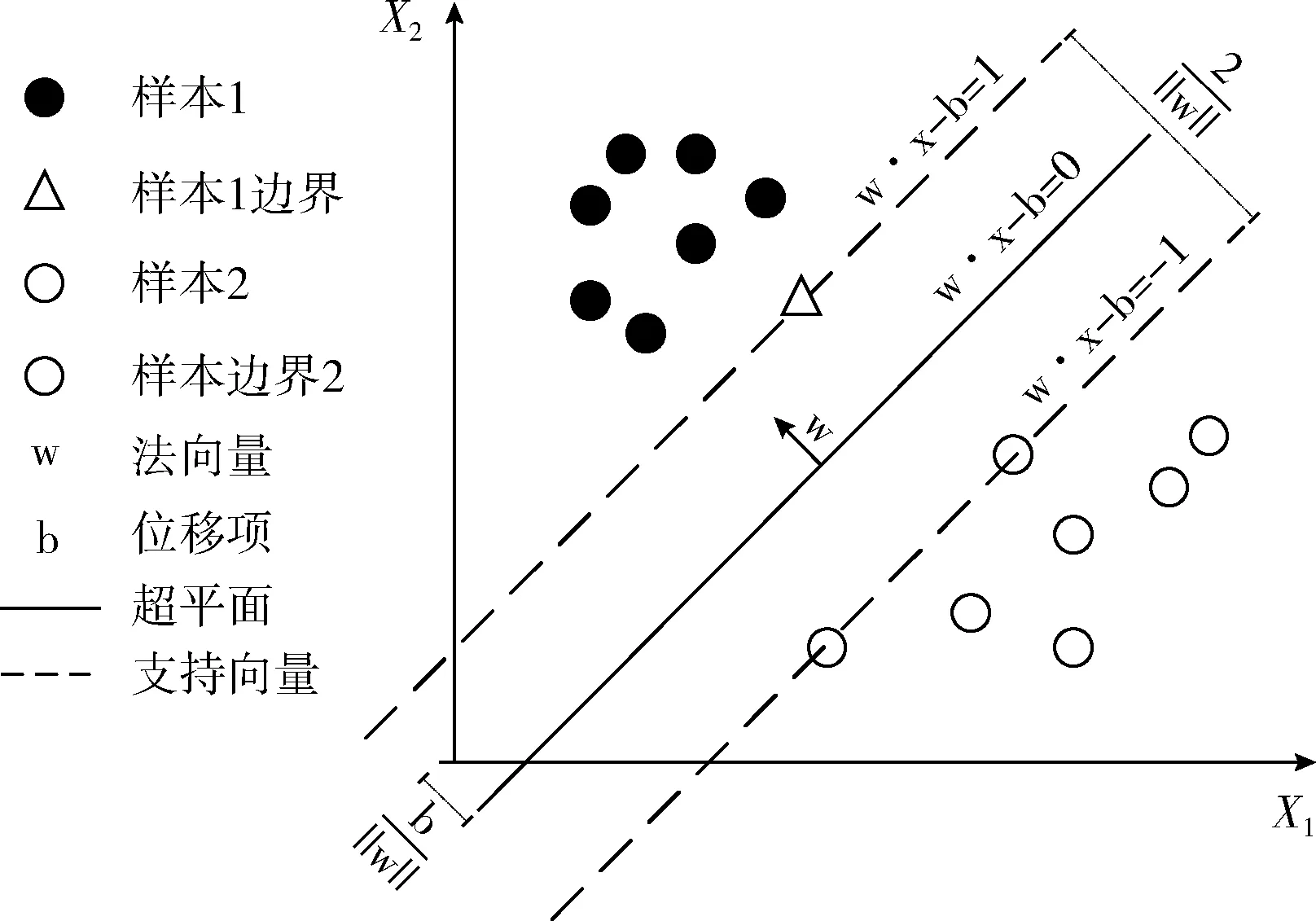
圖5 SVM原理
由于直接訓練樣本會導致復雜度過高,每個應用程序的系統調用序列都可表示為一個離散的馬爾可夫矩陣,因此在訓練測試樣本之前首先構建馬爾可夫矩陣以最大程度地還原系統調用序列的原始結構。假設預處理階段得到M個標簽值,在標簽化后的系統調用序列中,則每個樣本中的系統調用之間的概率轉移關系可以用一個M*M的矩陣表示為
(10)
其中,pl,q是指樣本調用標簽l對應的系統調用后,再調用標簽q對應的系統調用的概率,pl是標簽l對應的系統調用轉移到其它系統調用的概率矢量。接著將數據轉化為SVM能夠識別的格式,即p1…pl…pM,將其作為支持向量機的輸入,最后把正常軟件和惡意軟件的混合訓練集部分導入到系統中,惡意樣本標記為1,正常樣本標記為0,進行有效性實驗訓練,從而得出訓練好的分類模型用于判斷;最后樣本檢測,進而得出檢測結果。
3 實驗結果及分析
3.1 數據集和評判指標
本文實驗數據集中的非惡意軟件來源于小米官方網站,其Android安裝包通過Scrapy爬蟲獲取得到;而實驗數據集中的惡意軟件來源于國外開源網站VirusShare。用到的分類模型工具包為LIBSVM。
根據學術界的規則,在惡意軟件的判別標準中,主要包括以下幾個度量:判別準確率ACC(accuracy),真陽性率TPR(true positive rate),假陽性率FPR(false positive rate)。其中ACC定義為
(11)
TPR定義為
(12)
FPR定義為
(13)
在上述公式中,TP(true positive)表示是惡意軟件且分類判別正確的樣本數量;FN(false negative)表示是惡意軟件但分類錯誤的樣本數量;TN(true negative)表示是正常軟件且判定正確的樣本數量;而FP(false positive)表示是正常軟件但分類錯誤的樣本數量,所有的待測應用都可以歸屬為以上4類之一,ACC表示所有被分類正確的樣本占總樣本的比例,TPR表示惡意樣本的分類準確率,而FPR表示正常樣本的分類錯誤率。TP與TN越大,FN與FP越小分類效果越好。其次當TPR相等時,FPR越小檢測效果越好;當FPR相等時,TPR越大檢測效果越好;ACC越大,分類的準確率越高;這些度量可以完善衡量本文方法的優越性。
3.2 實驗結果
本實驗從1026個惡意樣本和1034個良性樣本分別隨機選取800個樣本組成訓練集,剩下的部分組成測試集。
在閾值選擇方面,保留的系統調用數量越多,檢測準確率越高,但復雜度也會隨之增高。本文同時兼顧復雜度和檢測準確率,以犧牲小幅度檢測準確率為代價,換取復雜度的大幅度降低。具體而言,本方案根據評分高低,從高到低分別選取數量為20、40、60、80、100、120和140的系統調用進行標簽化處理,未被選取的部分不做處理,從而得到系統調用和檢測準確率之間的關系如圖6所示。
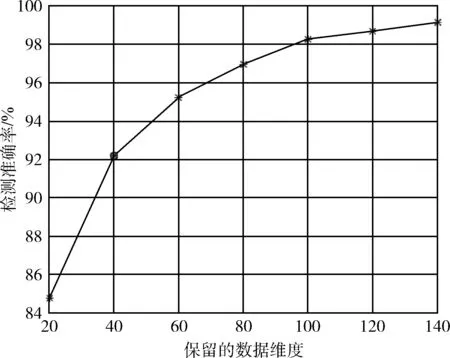
圖6 系統調用數量-檢測率關系
根據圖6,可發現系統調用數量在40時檢測準確率超過90%,故本文以此為轉折點,選取數量40為閾值,對應的檢測準確率為92.1%,接著按照屬性的不同合并“無用”命令組成文件類等7種類型的系統調用,因此通過特征映射后共有47個標簽用以檢測,從而進一步提高檢測準確率,可達到96.9%。
在去冗余的閾值選擇方面,根據評分高低,子序列可劃分為“重要”與“冗余”兩個部分,但兩部分的臨界點未知。在本文中,評分越高數據越重要,評分低的子序列為冗余量,因此按照評分從低到高進行系統調用去除,最后得到去冗余后的系統調用序列。冗余數據的去除量和檢測準確率之間的關系如圖7所示。
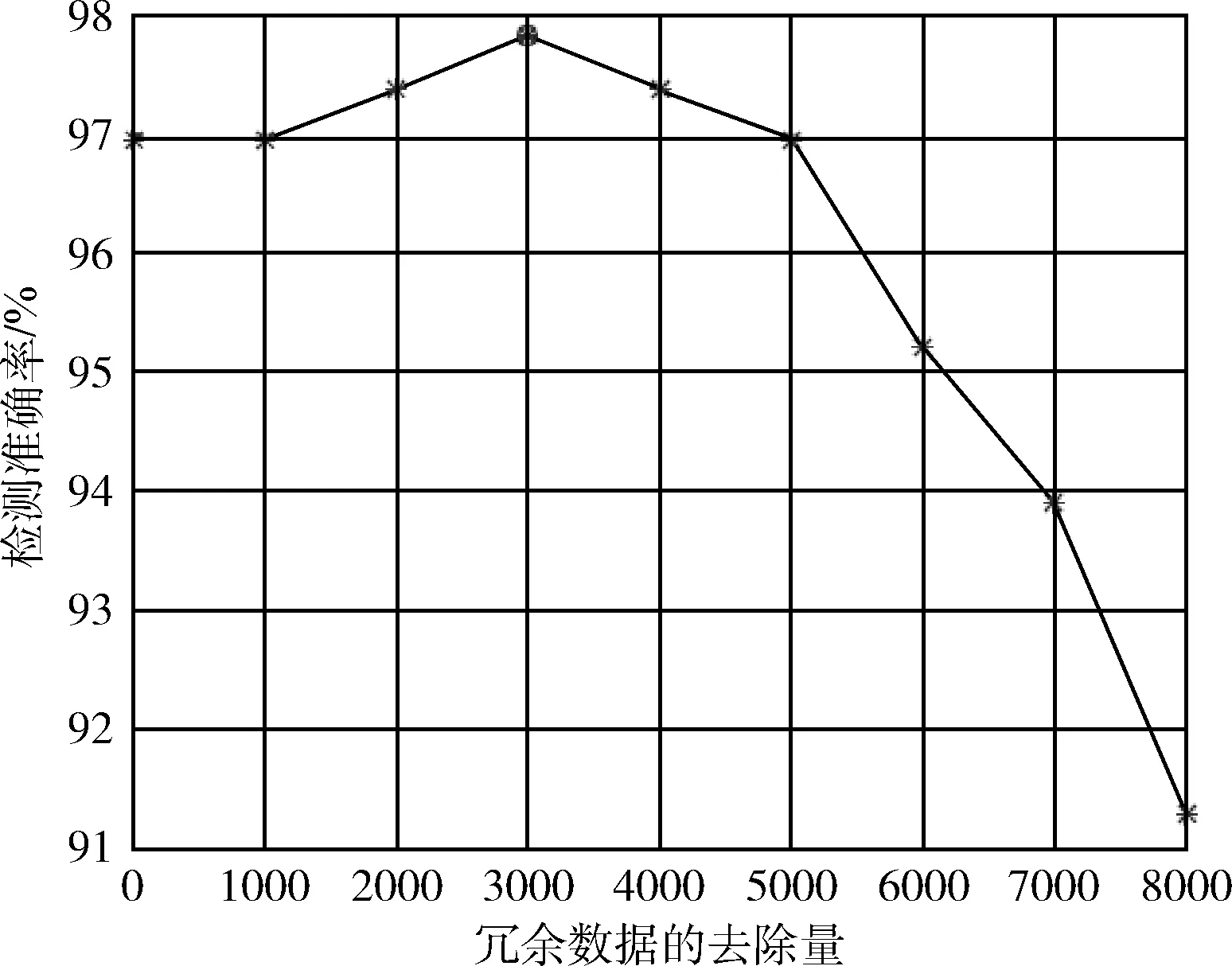
圖7 冗余數據的去除量-檢測準確率關系
根據圖7,冗余數據的去除量,即數據庫中的子序列較少時對檢測準確率無影響,接著檢測準確率會隨著冗余數據去除量的增加而提高,在去除3000個冗余子序列時檢測準確率達到峰值,之后,檢測準確率會隨著冗余數據去除量的增加而降低,這是因為去除的數據包含了重要信息而非冗余,所以檢測率會下降。因此選取閾值為3000。實驗得到的分類結果中,ACC為97.8%,TPR為97.4%,FPR為1.7%。
實驗結果表明本文經過預處理后的檢測結果既能保證較優的檢測效果,又能大幅度降低檢測復雜度。
3.3 對比分析
現有的文獻提出了多種不同的檢測軟件的框架,表4解析了以系統調用為特征的檢測結果,下面將具體進行比較分析。
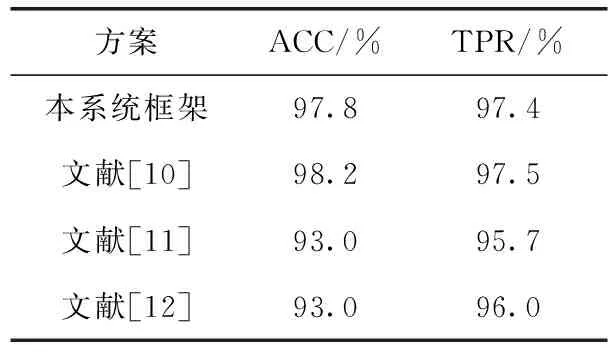
表4 本方案與其它方法的比較
文獻[11]提出的基于系統調用頻率的新型惡意軟件檢測方法檢測率達到93%,但此框架由于未考慮系統調用之間的相關性和整體性,無法充分保證分類的準確性。文獻[12]提出的自動分類框架雖然提高了TPR,但該框架仍未考慮整體性,特征向量冗余量太大,容易導致過擬合,故檢測率并未得到提高。文獻[10]所提框架構建了系統調用的馬爾可夫矩陣,考慮到了系統調用的整體性,因此檢測和TPR均有所提高。但文獻[10]使用了196個系統調用,構建馬爾可夫鏈矩陣訓練復雜度高達196的平方,增加了機器學習過程中的訓練時間。本文的檢測框架相較于文獻[10]提出的數據降維方案在降低檢測復雜度的同時,仍可以達到與未降維近乎一致的檢測準確率,表4直觀反映出本文所提出的方案優于其它檢測方案。
4 結束語
本文通過對Android惡意軟件樣本進行動態分析,進而提出了一種動態檢測框架。在該檢測框架中,首先模擬運行智能終端的樣本提取系統調用特征,然后使用信息增益的方法篩選系統調用,對系統調用進行數據降維和標簽化處理,最后將系統調用序列構建為馬爾可夫矩陣并利用SVM對樣本進行分類。系統調用可以最根本地反映應用軟件的行為,將其構建為馬爾可夫矩陣可以挖掘出系統底層中系統調用之間的聯系。
實驗結果表明,本文給出的檢測框架對惡意軟件的檢測效果明顯優于現有的幾種檢測方法。但在特征提取過程中,monkey工具向系統發送偽隨機用戶事件流不能挖掘全部的軟件行為,因而存在一定的局限性,將來還需研究其它可能的方式挖掘其行為,以提高檢測效果。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
