變結構時態神經網絡模型在股票預測中的應用
2020-06-12 11:42:52孟志青朱涵琪
計算機工程與設計 2020年6期
關鍵詞:模型
孟志青,朱涵琪
(浙江工業大學 管理學院,浙江 杭州 310023)
0 引 言
現實生活中存在大量非平穩時序數據,用傳統的預測模型很難進行準確的預測,例如股票價格時間序列受復雜因素的影響,具有非線性和非平穩性,很難預測股票價格變化。目前國內外學者對股票時間序列提出了許多預測模型,其中典型方法有GARCH-M模型[1]、神經網絡模型[2,3]、SVM[4]等。此外,在對數據進行前期處理上,主要的方法集中在對研究變量本身以及相關變量的分析上。文獻[5]通過對輸入變量進行主成分分析,避免了變量過多、網絡結構復雜的問題。文獻[6]用粗糙集理論降低了股票價格趨勢的特征維數,簡化了預測模型。文獻[7]、文獻[8]、文獻[9]運用小波分析方法,對時間序列在預測前進行處理,將時間序列分為低頻和高頻序列。當數據呈現非線性和非平穩性時,單一的預測模型很難發現含有時間的規律變化。例如股票市場數據包含時間屬性,幾乎無法發現隨時間變化且在不同狀態上相互聯系。另外,周期的選擇是股票市場預測的重要依據。特別是用小波分析與神經網絡結合預測時[8,9],經小波變換進行伸縮和平移運算而產生的各頻率序列與原始數據相比發生了一定的變化,繼續采用固定的經驗分析周期和單一神經網絡結構進行預測已不再適用。時態數據挖掘是通過數據在時間上的重新劃分發現非線性與非平穩數據的內在規律[10,11],例如近似周期、近似關聯規則等。采用不同的時間粒度或時態型對數據進行分析時,會呈現出不一樣的變化規律。為了克服非線性和非平穩數據難以發現有規律的知識,以及盲目選擇經驗周期帶來的不必要誤差,本文設計了一種變結構時態神經網絡預測模型用于解決股票價格的預測問題。
1 數據預處理
在對股票時間進行預處理上,采用小波變換的方法,通過伸縮和平移等運算,對信號進行多尺度分析,可以由低頻到高頻逐步地觀察信號。小波分析理論與神經網絡結合,可加強對高頻序列適應能力,提高預測精確度。
一般小波變換可以分為連續小波變換和離散小波變換[12]。連續小波變換表示為:
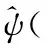
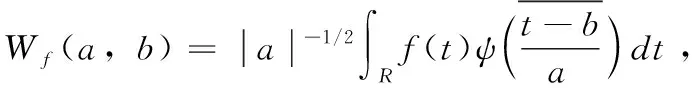
本文通過采用以多分辨率分析為基礎的Mallat算法,實現離散小波變換。基本思想是設Hjf為能量有限信號在分辨率2j下的近似,則Hjf可以進一步分解為在分辨率2j-1下的近似Hj-1f以及位于分辨率2j-1和2j之間的細節之和。將原始的時間序列被分為低頻部分和高頻部分,然后只對低頻部分進一步分解,直到達到預設的分解層數。
2 時態數據轉化表示
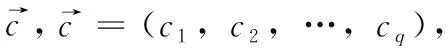
在現實世界中,我們可以將時間與實數軸聯系起來,從而將實數軸上的點代表某一時刻,并對應著點所在的實數,稱為絕對時刻。下面引入時態型定義。
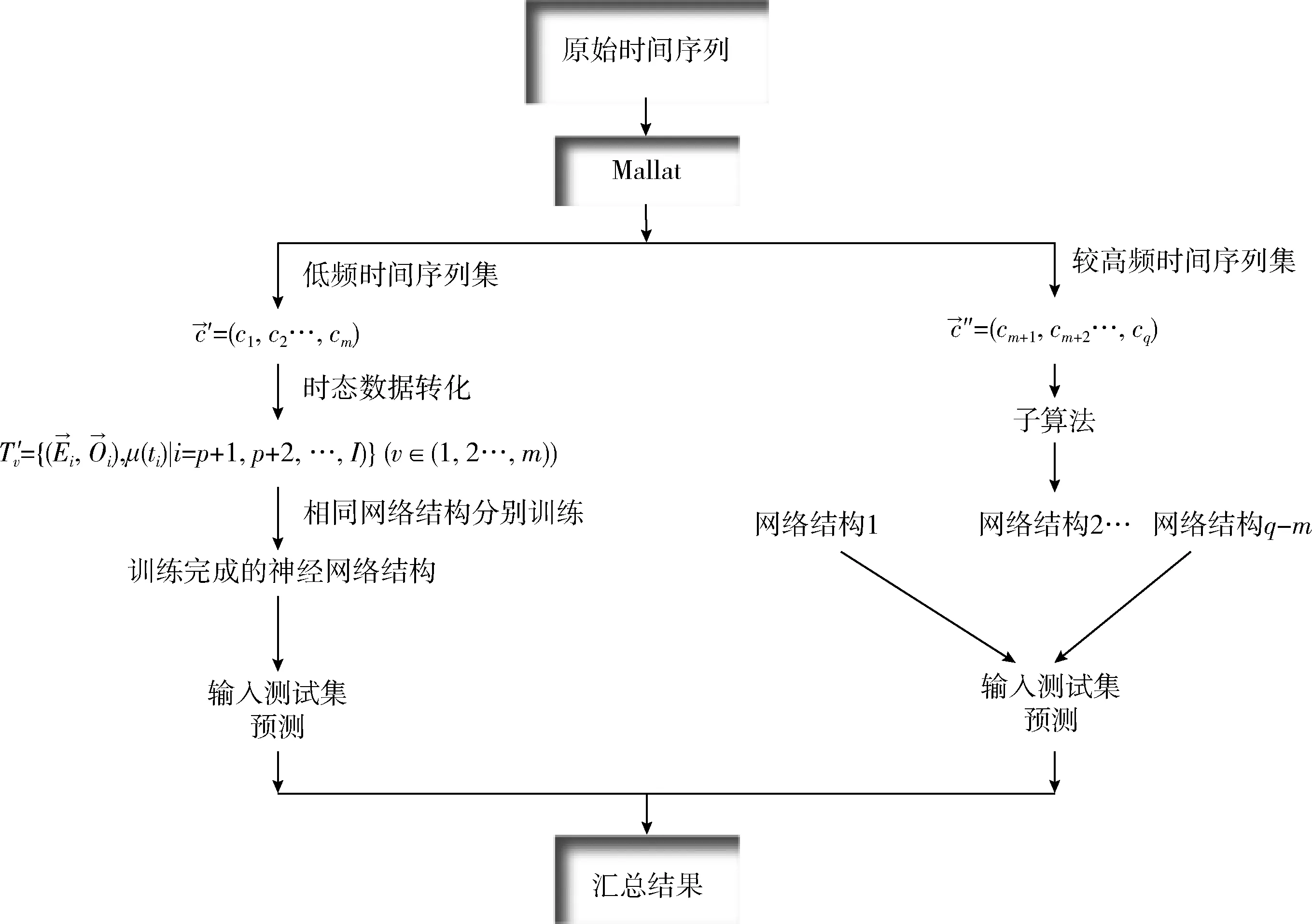
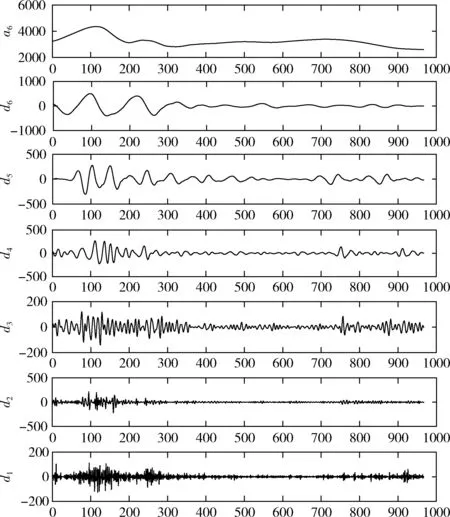
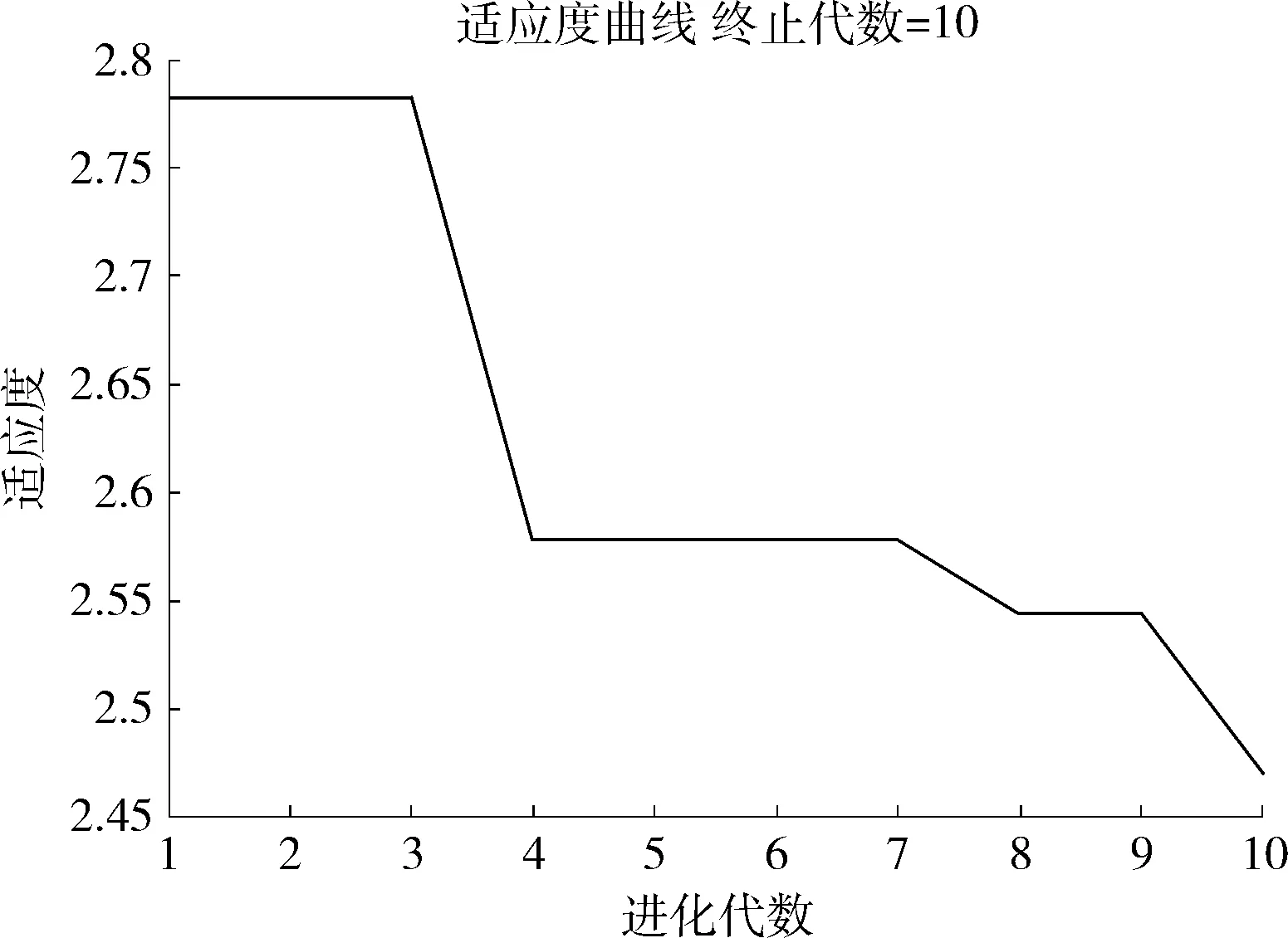
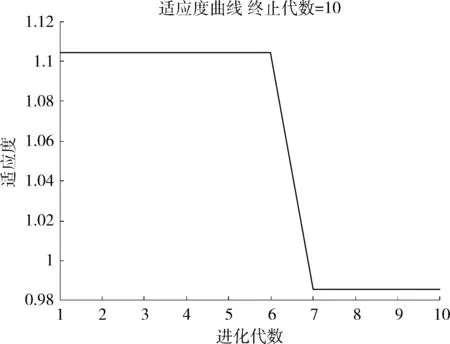
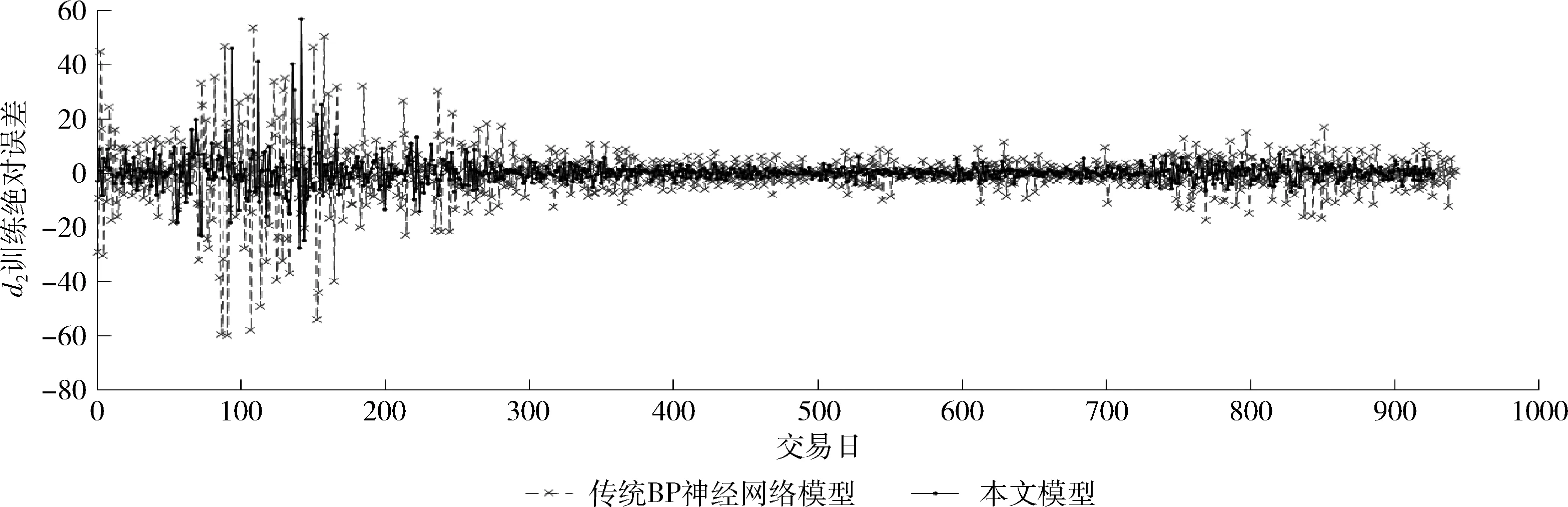
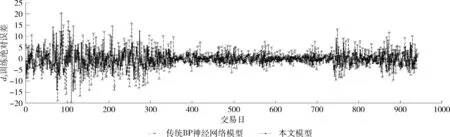
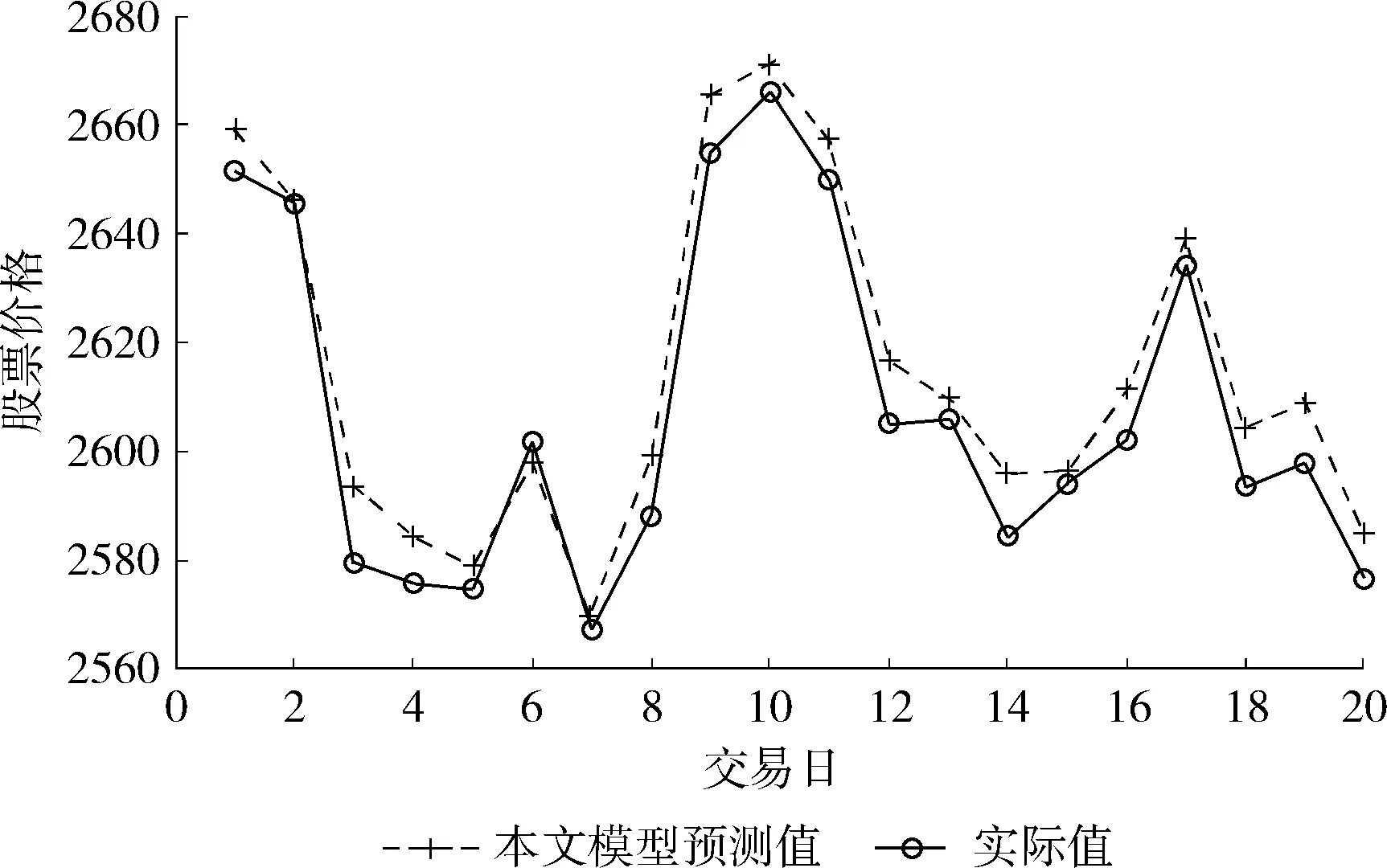
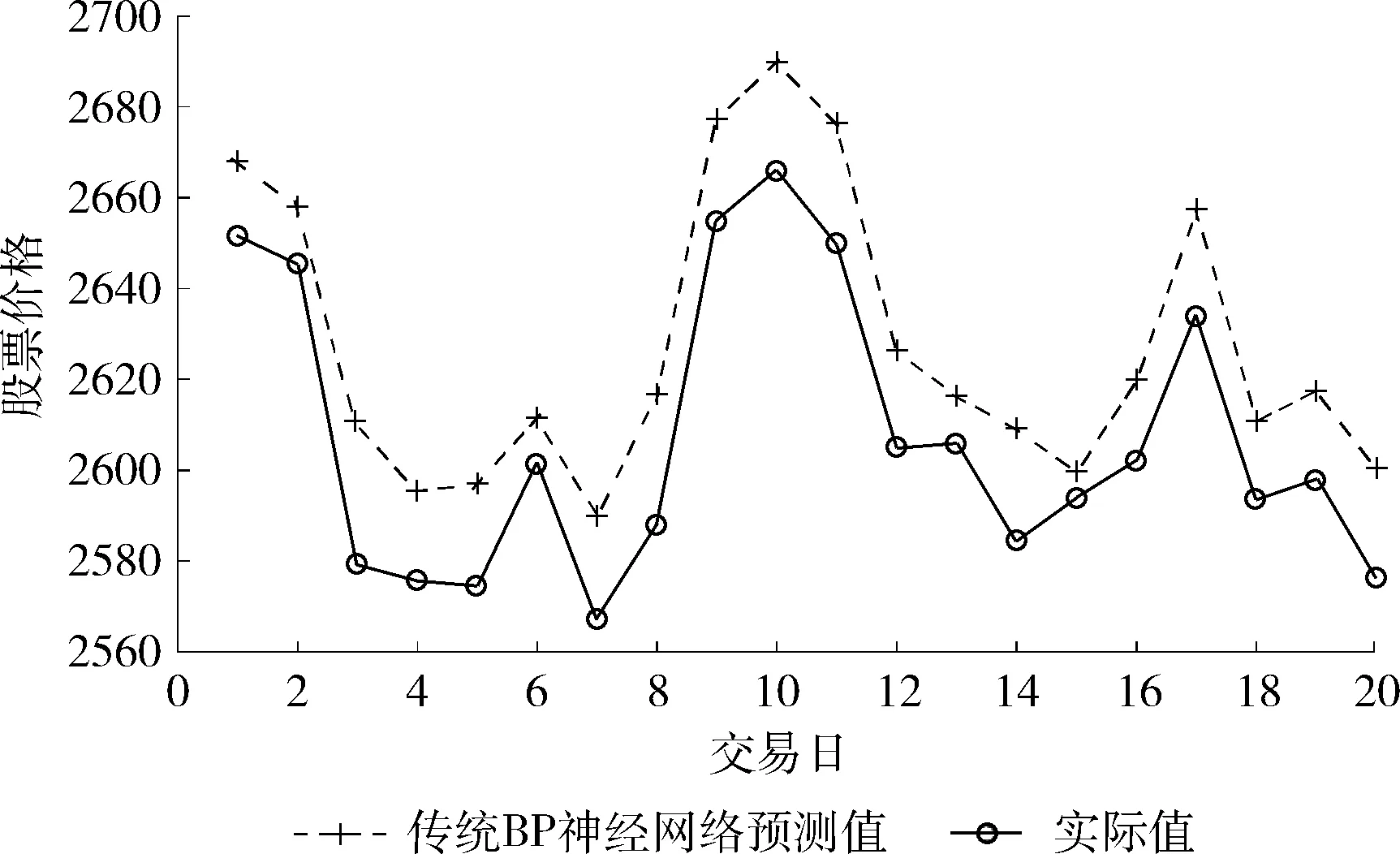
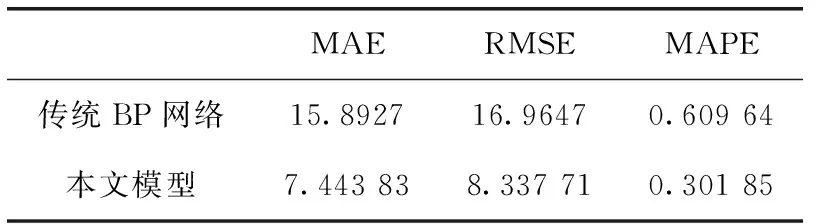
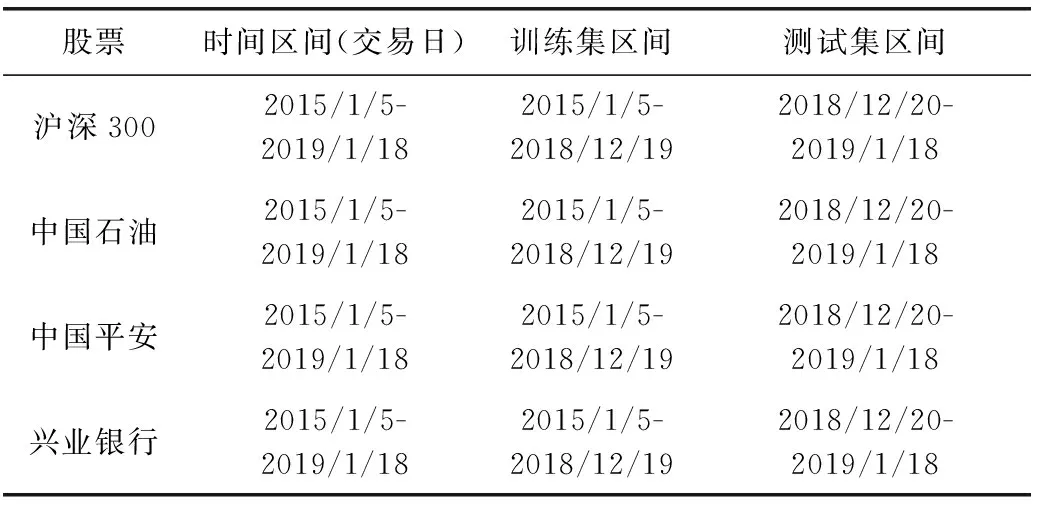
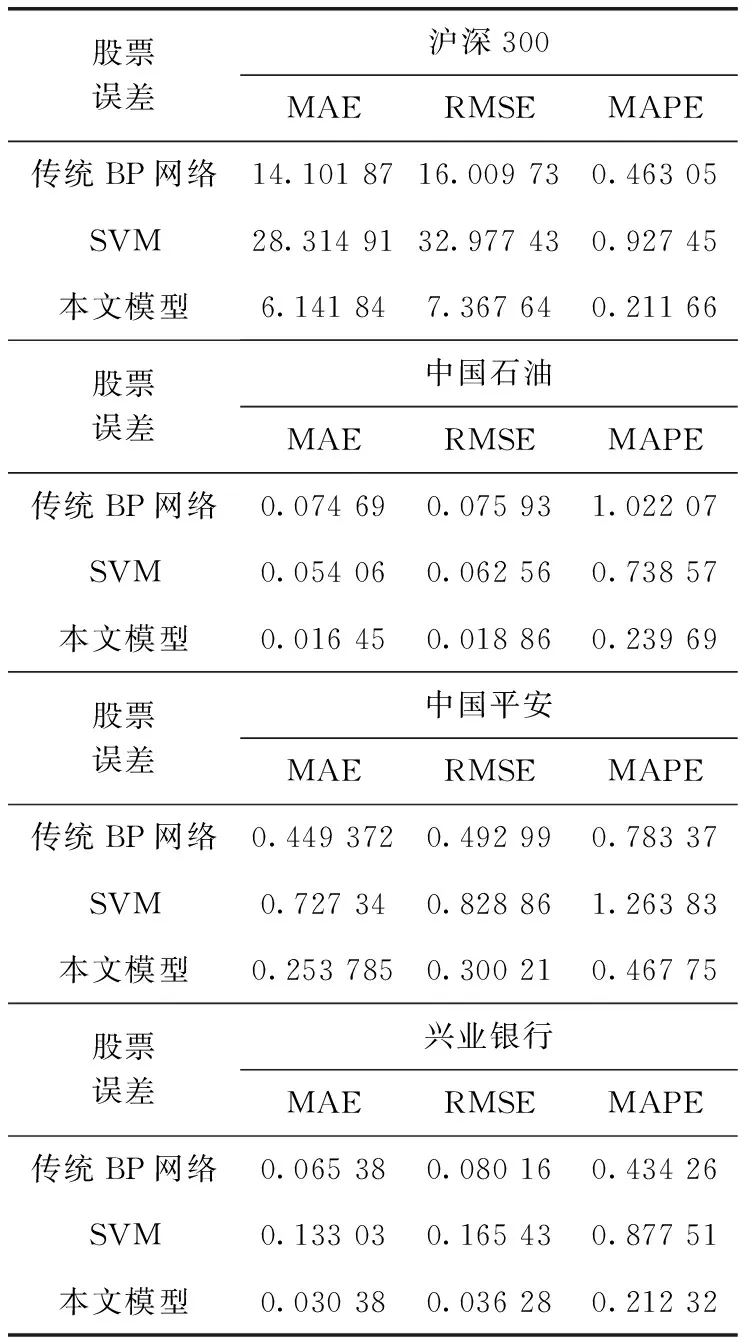
定義1[10]設μ是從絕對時刻t到絕對時間的映射,即R→2R如果μ滿足下列性質:①(非空性)t∈μ(t);②(單調性) 若t1 則稱μ為時態型,μ(t)為μ的時態因子。由此可見時態型μ是對時間軸的一個劃分,每個時態因子是一個絕對時刻的集合。時態粒度、時態序等相關具體知識參見文獻[10]。 神經網絡有多種結構類型、靈活的學習算法和驗證過程,在建模過程中不需要做一定的經濟假設,它們可以獨立學習變量中固有的關系,這在證券投資和其它金融領域十分有用。本文采用的是根據時態模型改進后的基于誤差逆傳播BP算法的前饋神經網絡。 設神經網絡輸入層p個節點數(j=1,2,…,p)和隱層L個節點數(l=1,2,…,L),輸出層M個節點數(k=1,2,…,M)。 初始化輸入層、隱層和輸出層神經元之間的權值γjl,γlk,隱含層閾值α(α=(α1,…,αl,…,αL)),輸出層閾值β(β=(β1,…,βk,…,βM)),學習率η,神經網絡訓練過程如下。 步驟1 信號的向前傳播過程: 步驟2 信號的向前傳播過程: 由于節點數需要是整數,而PSO算法是一種處理連續變量的群體尋優算法,在連續型PSO算法的位置更新過程中不能產生整數變量。因此,在初始化位置和更新位置的過程中需要對其進行四舍五入,將得到的實數取到最近的整數。具體過程如下: 首先初始化粒子群:假設在一個D維的搜索空間中,種群有n個粒子:X=(X1,X2,…Xn),其中第i個粒子表示為一個D維向量:Xi=(xi1,…,xid,…xiD),代表著第i個粒子在D維搜索空間中的位置。 xid=popmin+round(rd(popmax-popmin)), [popmin,popmax]為xid的整數范圍,round(·)表示四舍五入,rd表示(0,1)之間的隨機數;初始化第i個粒子的速度:Vi=(vi1,…,vid,…,viD),vid的范圍為[vmin,vmax]。 輸入:某一高頻序列: 時態型μ PSO算法種群數sizepop和迭代次數maxgen 分析周期最大值pmax, 最小值pmin 輸出節點數M 過程: 步驟2 初始化新的神經網絡,包括權值和閾值的初始 化、學習率η、訓練函數和傳遞函數的選取。 步驟3 將時態數據T″v帶入神經網絡模型進行訓練。 步驟4 通過上一步,得到在初始神經網絡結構下的訓練誤差w,以此作為PSO尋優算法的初始適應度值。 步驟5 repeat: (1)更新粒子速度和位置:得到新的輸入節點數p和隱層節點數L,p根據值將序列c″v轉化為新的時態數據T″v。 (2)根據上一步得到的p值和L值,初始化新的神經網絡包括權值和閾值初始化、學習率η、訓練函數和傳遞函數的選取。 (3)將時態數據T″v帶入上步確定的神經網絡進行訓練,計算誤差w,得到新的粒子適應度值。 (4)根據上步得到的粒子適應度值更新個體極值和群體極值。 until 達到迭代次數 步驟6 得出最優個體適應度值對應的粒子位置Xbest=(xbest1,xbest2)。 輸出:某一高頻序列c″v的神經網絡結構,其中:xbest1=p(輸入節點數),xbest2=L(隱層節點數)。 總體來看,變結構神經網絡時態數據預測模型實現過程如圖1所示(主算法)。 圖1 主算法流程 主算法的具體過程如下: 步驟2: (1)選定經驗周期p、隱層節點數L,初始化神經網絡,包括入節點數、隱層節點數、輸出節點數、權值和閾值初始化、學習率η、訓練函數和傳遞函數的選取。 (3)將時態數據T′v帶入神經網絡中進行訓練。 end for 步驟3: 利用子算法,得到c″v對應的神經網絡結構 end for 步驟2過程確定了較低頻序列集訓練完成的各神經網絡模型,步驟3過程確定了較高頻序列集訓練完成的各神經網絡模型。最后利用經訓練集確定好的神經網絡模型,輸入轉化后的時態數據測試集,將各頻率序列對應的神經網絡輸出結果相加,得出最終預測值。 以上就是基于時態數據的變結構神經網絡建立過程。與傳統的BP網絡不同點主要在兩點,數據按時態因子進入網絡學習,不同節點上采用不同時態數據學習,不同的輸入節點數和對應的隱層節點數不相同。 為了對模型的預測精確度進行分析,選取以下參數作為預測模型的評價標準。 (1)平均絕對誤差(mean absolute error) (2)均方根誤差(root mean square error) (3)平均絕對相對誤差(mean absolute percent error) 實驗環境:計算機處理器:Intel(R) Core(TM) i5-7200uCPU、內存4 G、256 G固態硬盤、顯示芯片:NVIDIA GeForce 940MX、64 G操作系統,實驗軟件MATLAB R2016a。 實驗數據為:從同花順采集的2015.01.05-2018.12.18期間上證指數每日的收盤價。采用單步滾動預測,用前N日的股票收盤價作為輸入數據,第N+1天的股票的收盤價作為輸出數據。2015.01.05-2018.11.20之間的交易日數據用來訓練,對未來20天交易日的股票價格進行預測。 圖2 原始序列小波分解與重構結果 為了驗證本文模型的有效性,將本模型與各頻率采用經驗周期為5的傳統BP神經網絡模型進行對比。其中兩種模型中對網絡權值和閾值優化的方法保持一致:隱含層神經傳遞函數為tansig函數,輸出層神經元的傳遞函數為purelin函數,訓練函數采用動態自適應學習率的梯度下降BP算法。當目標最小誤差小于0.01(用均方誤差MSE表示)時停止訓練。 實驗過程中,時態型μ選為天,低頻序列集的分析周期采用經驗分析周期5天,對應的隱層節點數經實驗比較確定為7。高頻序列集中相關的參數為:種群粒子數目sizepop選為30,分析周期最小值pmin為5,最大值pmax為25,迭代次數maxgen經多次實驗后選為10,從圖3、圖4和圖5可以看出,當超過10代之后,適應度變化很小甚至不再改變,同時迭代次數越多,會增加不必要的運行時間和空間。 圖3 d1序列參數尋優 經實驗最終得到d1序列上參數尋優的結果,如圖3所示。當迭代到第10代時,適應度值達到最小,其對應的最優粒子位置Xbest=(xbest1,xbest2)為Xbest=(17,11)。由于xbest1表示的是輸入節點數,xbest2表示的是隱層節點數,那么得到d1序列上的分析周期選為17,隱層節點數選為11。 d2序列上參數尋優的結果,如圖4所示。當迭代到第8代時,適應度值達到最小,其對應的最優粒子位置Xbest=(xbest1,xbest2)為Xbest=(20,6)。那么得到d2序列上的分析周期選為20,隱層節點數選為6。 圖4 d2序列參數尋優 圖5 d3序列參數尋優 d3序列上參數尋優的結果,如圖5所示。當迭代到第7代時,適應度值達到最小,其對應的最優粒子位置Xbest=(xbest1,xbest2)為Xbest=(8,11)。那么得到d3序列上的分析周期選為8,隱層節點數選為11。 圖6 d1序列訓練誤差 圖7 d2序列訓練誤差 圖8 d3序列訓練誤差 圖9 變結構模型預測 進一步將兩種模型進行最終誤差分析,在MAE、MAPE和RMSE這3個指標上本文模型比傳統模型均降低了50%-60%左右,比較結果見表1。 為了進一步驗證本文模型的適用性和有效性,另外選取了滬深300、中國石油、中國平安和興業銀行這4只股票,具體數據選取見表2。 將本文提出的模型,同時與傳統BP神經網絡模型、SVM方法進行比較。各模型和誤差分析結果見表3。從表3中可以看出,本文模型相比較于傳統BP網絡、SVM的預測誤差有明顯的降低,進一步說明了將股票數據轉化為時態數據,建立變結構模型的有效性。 圖10 傳統BP神經網絡預測 表1 誤差分析比較 表2 實驗股票數據 表3 4種股票預測結果 本文提出了一個變結構時態神經網絡模型,用于解決非線性和非平穩數據預測問題。通過實驗,使用上述模型對具有明顯時間屬性的股票價格進行預測,將股票數據轉化為時態數據集,對神經網絡進行改進,以及對經小波變換之后的各個分支序列建立變結構時態神經網絡預測模型,可以有效地降低分支序列預測誤差,從而降低整體預測誤差,對股票類似的時間序列分析具有應用價值。對于解決類似的非線性與非平穩數據預測問題具有重要的意義。 此外股票市場信息是海量的,與股票價格相關的變量和技術指標有很多,本文采用的是單變量分析,進一步可以在本實驗的基礎上采用多變量進行綜合分析以提高預測效果。3 變結構時態神經網絡設計
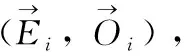
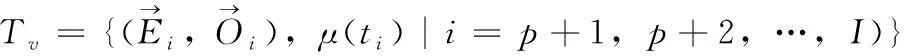
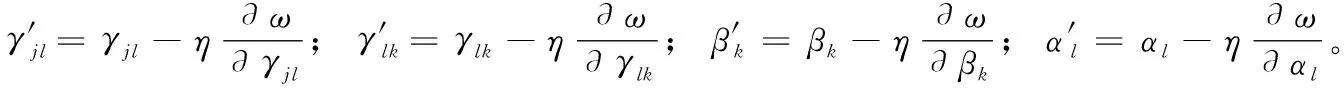
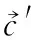
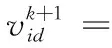

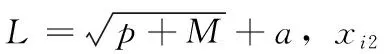
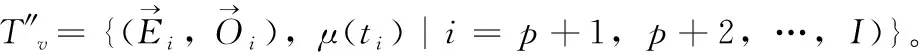
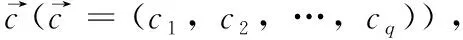
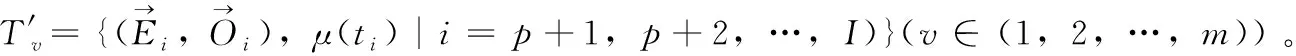
4 誤差分析
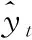
5 實 驗
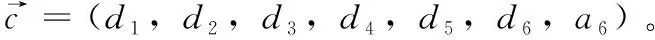


6 結束語
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
