融合擊鍵內容和擊鍵行為的持續身份認證
2020-06-12 09:17:38宋禮鵬鄭家杰
計算機工程與設計 2020年6期
王 凱,宋禮鵬+,鄭家杰
(1.中北大學 大數據學院 大數據與網絡安全研究所,山西 太原 030051;2.中北大學 大數據學院,山西 太原 030051)
0 引 言
擊鍵動力學認證[1]作為一種不需要額外設備且不影響用戶正常工作的認證方式被廣泛應用于用戶身份認證領域[2]。文獻[3]中指出21%的數據泄露涉及到內鬼或網絡間諜。因此,靜態身份認證成功后需要持續監測計算機使用者的身份,這種認證方式為持續認證[4]。
針對擊鍵動力學的持續身份認證研究,Alsultan A等[5]要求志愿者輸入在線報紙中的內容;張得旭等[6]采集用戶使用通訊軟件聊天時的擊鍵數據;李福祥等[7]規定志愿者輸入較短的字符串。由于用戶每天的擊鍵狀態受當天的工作要求或者身體的疲勞程度甚至情緒的影響[8],有一定的隨機性,而以上工作均對用戶的擊鍵行為進行了限制,因此并不能完全反應出用戶在現實生活中的擊鍵習慣。何斯譯等[9]考慮到擊鍵時間特征隨時間的變化,設計出雙更新算法減小了誤報率;Kim J等[10]采用8等級時間間隔特征為用戶的持續身份認證建模,但這些研究僅基于時間維度提取擊鍵特征,認證準確率存在可進一步提升的空間。
本文在數據的采集過程中并不對用戶擊鍵的時間和內容加以限制,考慮到連續擊鍵事件更能反應出用戶固有的擊鍵習慣,提出將連續擊鍵事件中各后置擊鍵的頻次作為擊鍵內容特征,并在現有的擊鍵時間間隔特征的基礎上通過將其排序得到擊鍵行為特征,最后采用融合算法結合擊鍵內容域和擊鍵行為域的子分類器。實驗結果表明,比較于現有的認證模型,該方法將用戶持續身份認證的準確率提高了3.7%至4.7%。
1 持續身份認證模型
本文研究用戶在連續擊鍵狀態下的擊鍵習慣,在特征構造階段分別處理擊鍵內容域和擊鍵行為域,然后為這兩個域訓練子分類器,最后根據改進的Yager證據合成理論[11]在決策階段融合各域的子分類器得到用戶的持續身份認證模型。具體過程如圖1所示。

圖1 持續身份認證模型
1.1 特征提取
1.1.1 擊鍵內容特征
本文創建包含所有鍵值的擊鍵表KeyTable={key1,key2,…,keyD},D為鍵值種類的個數。從用戶擊鍵序列中取出n個連續擊鍵事件組成的序列L,記錄各連續擊鍵事件中后置擊鍵的鍵值(例如擊鍵事件A→B,記錄鍵值B),得到長度為n的鍵值序列
Key={k1,k2,…,kn}
統計各按鍵在Key中出現的次數
(1)
其中,keyi∈KeyTable,對應擊鍵表中位置i處的鍵值,i=1,2,…,D。函數I為指示函數,即kj=keyi時為1,否則為0。由此得到連續擊鍵序列L上的擊鍵內容特征
Keyf={c1,c2,…,cD}
1.1.2 擊鍵行為特征
擊鍵行為特征考慮用戶在時間維度上所反應的擊鍵習慣。
(1)現有的擊鍵行為特征:現有的方法根據擊鍵按下和抬起時的時間戳計算單個擊鍵的持續時間間隔(Duration)和連續擊鍵的時間間隔(DD_time、DU_time、UD_time、UU_time),如圖2所示。從這些時間屬性上可以反應出不同用戶在擊鍵速度上的差異。文獻[6]把鍵盤分為不同區域,考慮用戶在各區域中的擊鍵順序將擊鍵序列上的5種時間間隔分別排序,并分為8個速度等級,將各等級的均值組成5×8的特征樣本。
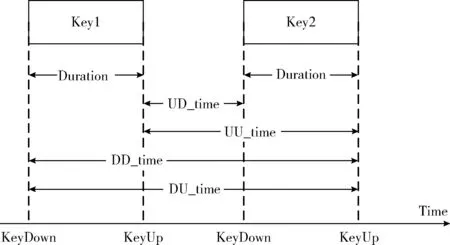
圖2 擊鍵時間間隔的5種類型
(2)本文的擊鍵行為特征:考慮到從不同長度的擊鍵序列中提取固定等級的時間間隔特征會丟失掉用戶在較長的擊鍵序列中擊鍵速度上的細節,因此本文并未采用劃分速度等級的方式對擊鍵序列進行壓縮。
首先從用戶擊鍵序列中提取出n個連續擊鍵事件組成的序列L,由于Duration為單鍵的持續時間間隔,因此只考慮連續擊鍵事件的后置擊鍵按下至抬起的時間差,通過計算得到Duration的擊鍵時間間隔序列
Dur={t1,t2,…,tn}
然后將Dur從小到大排序得
同理可得到其它的擊鍵時間間隔序列,即Dd*、Du*、Ud*、Uu*。最后,將這5種時間間隔序列組成連續擊鍵序列L上的擊鍵行為特征
Timef={Dur*,Dd*,Du*,Ud*,Uu*}
1.2 子分類器
本文引入集成學習中的極端梯度提升(extreme gra-dient boosting,XGBoost)算法[12]分別為用戶的擊鍵內容域和擊鍵行為域訓練子分類器。該子分類器為二分類模型,類別為用戶本身(正常用戶)和其他用戶(異常用戶)。
XGBoost分類器由T棵最優的CART樹(分類回歸樹)組成,每棵CART樹的訓練數據為上輪迭代后產生的模型預測值與真實值之間的殘差,該樹的目標函數為
(2)
其中,t表示當前迭代的步數,函數L為損失函數,函數Ω為正則項,C為前t-1棵樹的復雜度之和,在訓練第t棵CART樹時,它為常數。通過不斷地迭代增加新的CART樹,模型的準確率逐漸提高。可設置最高迭代次數T或錯誤率小于σ時停止迭代。
1.3 融合子分類器
本文將擊鍵內容域和擊鍵行為域上的子分類器進行決策融合。使用1.2節中的兩個子分類器分別對擊鍵內容和擊鍵行為樣本進行檢測,得到的概率向量作為這兩個域的mass函數。由改進的Yager證據合成理論得到證據框架(或假設空間)為Θ={o1,o2},其中o1={用戶本身},o2={其他用戶}。
證據的整體沖突因子為
(3)
其中,mi(Aj)表示證據i中事件為Aj的概率,n為證據的個數。
證據i與j之間的沖突因子為
(4)
證據的可信度為
(5)
其中
(6)
由此可以得到事件o1的合成概率為
m(o1)=p(o1)+kεq(o1)
(7)
其中
(8)
(9)
同理得事件o2的合成概率m(o2)。若m(o1)>m(o2),則最終決策判定當前計算機的使用者為用戶本身,否則為其他用戶。
2 實驗結果與分析
本文采集內網中19名用戶的擊鍵數據,為每個用戶訓練持續身份認證模型。當使用XGBoost算法訓練子分類器時,本文提出的擊鍵行為特征在現有擊鍵行為特征的基礎上提高了認證模型的準確率。融合擊鍵內容域和擊鍵行為域的子分類器后,認證模型的準確率得到進一步提高。此外,實驗還比較了其它集成學習算法訓練子分類器時,現有認證方法和本文提出的認證方法下持續身份認證模型的準確率,結果表明本文提出的認證方法具有一定的適用性。
2.1 數據采集分析
本文采集用戶的擊鍵信息包括擊鍵內容、擊鍵時間戳、擊鍵窗口名、ASCII碼等。實驗主要使用擊鍵內容和擊鍵時間戳信息。數據采集的周期為2018年12月至2019年2月,共計19名用戶。
連續擊鍵事件大多在很短的時間內發生,“思考”和“生活作息”所產生的時間間隔并不與連續擊鍵的時間間隔處于同一量級,因此需要排除過長的時間間隔數據。1000 ms和2000 ms內的擊鍵時間間隔分布如圖3所示。單鍵的持續時間間隔(Duration)分布上近似于正態,雙鍵的時間間隔(DD_time、DU_time、UD_time、UU_time)分布上具有明顯的“長尾效應”,這5種時間間隔分布都在500 ms內達到峰值。由于用戶快捷鍵(如Ctrl+c、Ctrl+v等擊鍵組合)的使用,導致雙鍵的第二個擊鍵按下和抬起有可能發生在第一個擊鍵抬起前,因此UD_time和UU_time會有負值出現。時間間隔在1000 ms和2000 ms內的擊鍵事件占總擊鍵事件的比例見表1。1000 ms內占比最少的UD_time達到80.2%,由此可見,時間間隔在1000 ms內的擊鍵信息已經涵蓋了用戶的大多數擊鍵行為。2000 ms內占比最少的UD_time達到88.7%,本文在實驗中分析時間間隔在2000 ms內的用戶擊鍵信息。
所有用戶連續擊鍵的后置擊鍵頻率如圖4所示,其中Back鍵發生的次數最多,占總擊鍵次數的10.79%,其次為空格鍵,占總擊鍵次數的7.87%。也有一些擊鍵極少出現,如F3、F4、F5等。圖5展示了5名用戶在擊鍵時間間隔限制為2000 ms時連續擊鍵的后置擊鍵頻率。從圖中可看出不同用戶在擊鍵頻率上所反應出的擊鍵內容差異。Numpad0至Numpad9為鍵盤右側的數字鍵,用戶1和用戶3幾乎不使用這些擊鍵,而用戶5使用的相對較多;用戶2和用戶4偏向于使用上下左右的控制鍵;用戶3使用Back鍵的頻率相對其它擊鍵而言要高很多;盡管各用戶對A、I、N、U、Space、Back鍵的使用較多,但他們各自使用的頻率也有差異。無論從整體還是局部,每個用戶都可以從擊鍵頻率中反應出他們在擊鍵內容上的獨特性。
2.2 實驗及方案對比
本文為連續擊鍵數據量達到5萬的19名用戶建立單獨的持續身份認證模型,以下實驗結果中的準確率為所有用戶的準確率均值。實驗將用戶的擊鍵數據以8∶2的比例分為訓練數據和測試數據。考慮到正負樣本不均衡的情況,本文隨機選擇其他用戶的擊鍵樣本為負樣本,設置訓練數據和測試數據的正負樣本比例為1∶1,結果展示10次實驗的均值。由于持續擊鍵身份認證總希望在較短的時間或較短的擊鍵序列中判斷出計算機使用者的身份,過長的擊鍵序列并不會達到及時認證的效果,因此本文只分析了擊鍵序列長度在500以內的情況。
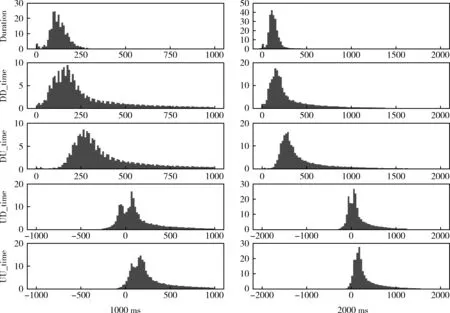
圖3 擊鍵時間間隔分布(單位:萬次)
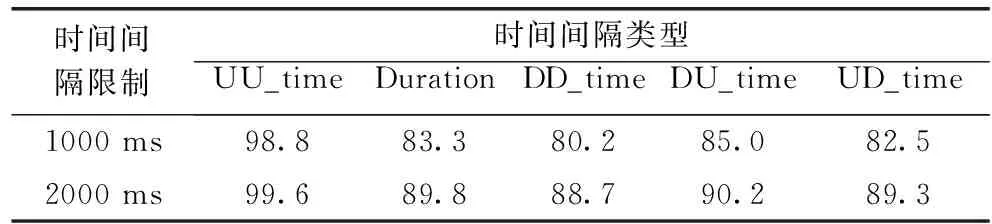
表1 用戶擊鍵事件占比/%
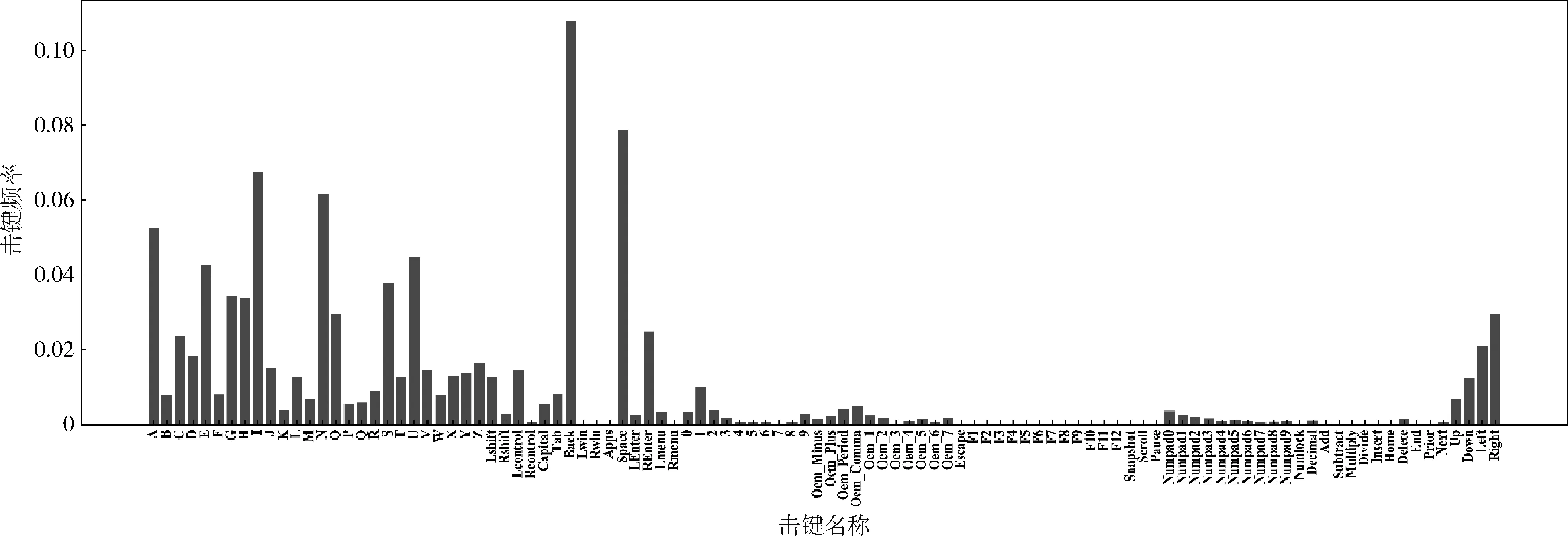
圖4 用戶的擊鍵頻率
圖6展示了在不同長度的擊鍵序列下,擊鍵行為域的XGBoost子分類器的準確率。可看出,本文采用的擊鍵行為特征在該分類器下的效果要優于現有的擊鍵行為特征,身份認證的準確率提高了1.2%至2.3%。擊鍵序列長度為200時,準確率最高,達到了92.8%。
圖7展示了融合擊鍵內容域和擊鍵行為域的子分類器后的持續身份認證模型的準確率。對于不同長度的擊鍵序列,該模型的準確率在現有擊鍵行為分類器的基礎上提高了3.7%至4.7%。其中,擊鍵序列長度為100時,提升效果最為明顯。表明本文提出的認證方法可提高用戶持續身份認證的準確率。
圖8為本文提出的擊鍵內容域和擊鍵行為域的子分類器與融合后的持續身份認證模型的準確率對比圖。隨著連續擊鍵序列長度的增加,擊鍵內容分類器的準確率也在增加。在連續擊鍵序列長度相同的條件下,擊鍵行為分類器要優于擊鍵內容分類器,融合子分類器后的認證模型要優于單獨域下的認證模型。
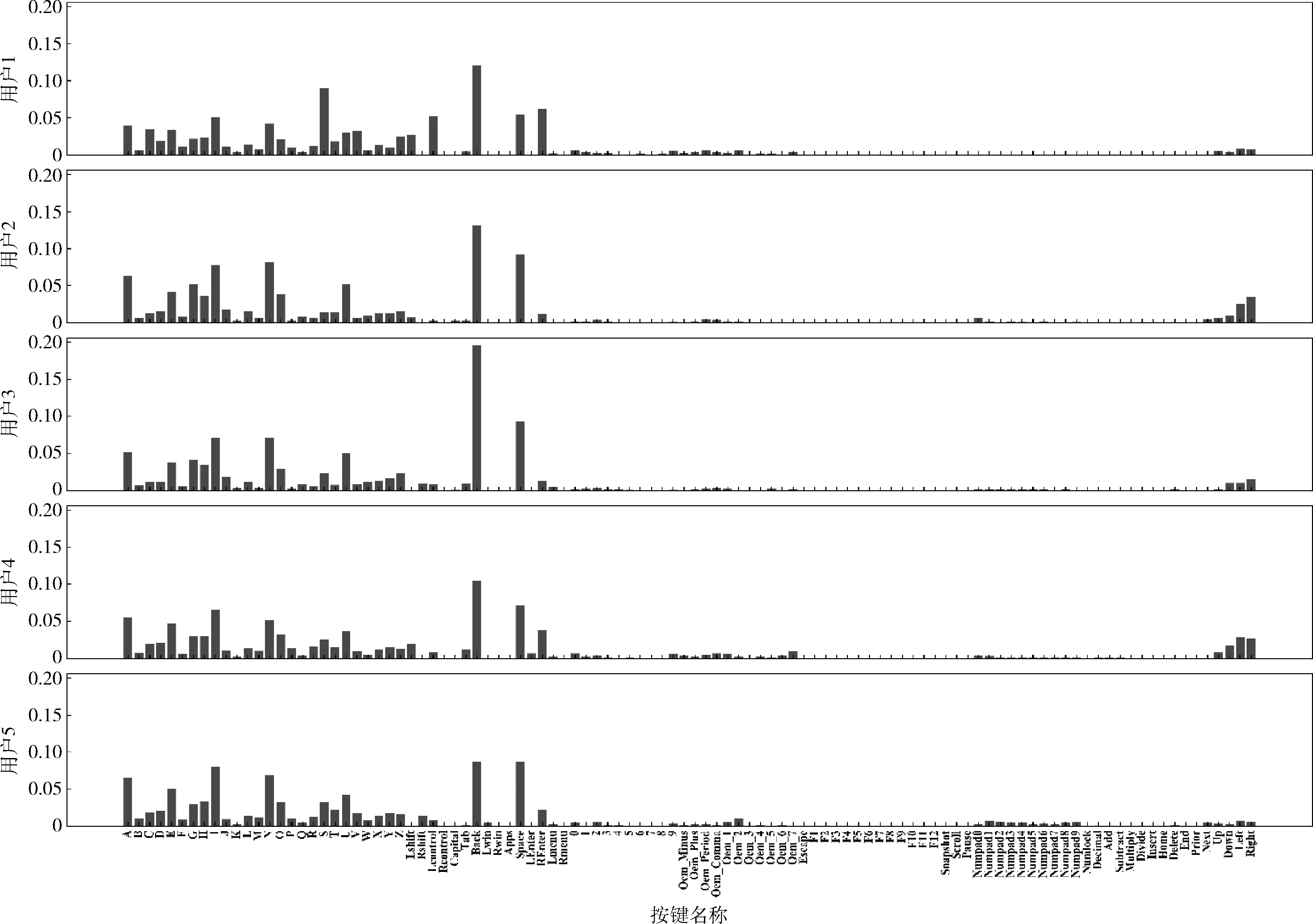
圖5 5名用戶的擊鍵頻率
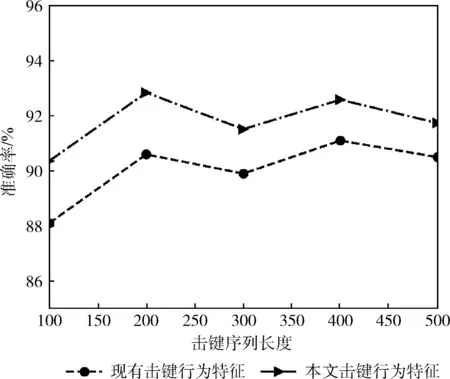
圖6 擊鍵行為域的XGBoost子分類器

圖7 現有分類器與融合分類器
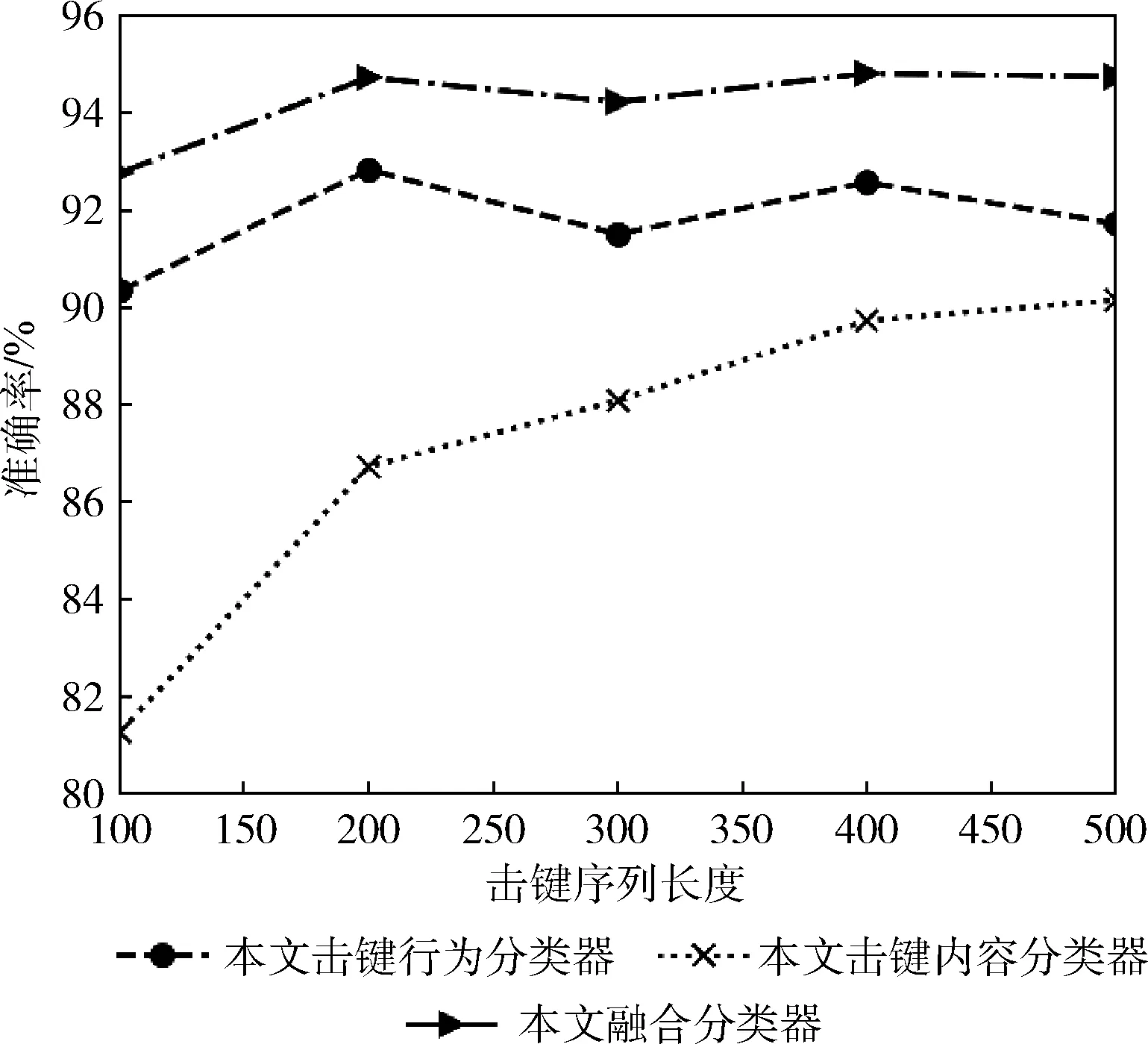
圖8 子分類器與融合分類器
融合后的身份認證模型的詳細評估指標見表2,其中展示了FRR(錯誤拒絕率)和FAR(錯誤接受率)信息
(10)
(11)
FRR較大時,認證系統會給計算機的正常用戶帶來不便;FAR較大時,認證系統可能無法有效阻擋異常用戶的入侵。擊鍵序列長度為100時,持續身份認證系統檢測的周期較短,可及時反饋計算機使用者的身份,但準確率相對較低,FRR值和FAR值相對較高;擊鍵序列長度為200時,較高的準確率和較短的認證周期具有很好的實用價值;擊鍵序列長度為400時準確率最高,達到94.83%;擊鍵序列長度為500時,模型的FAR值僅為0.79%,具有很高的安全性。
此外,實驗測試了使用RF(隨機森林)和自適應增強(adaptive boosting,AdaBoost)[13]算法訓練子分類器時認證模型的效果。從表3和表4中可看出,與現有認證方法相比,采用本文的認證方法后,持續身份認證模型的準確率都得到了不同程度的提升。表明本文提出的基于擊鍵行為和擊鍵內容的認證方法有較強的適用性。
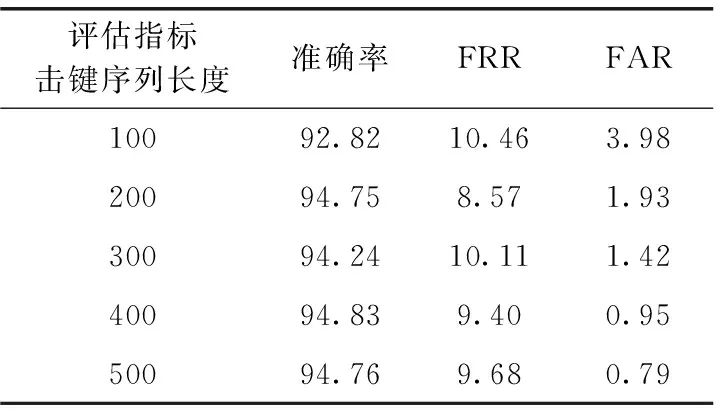
表2 融合后的持續身份認證模型/%
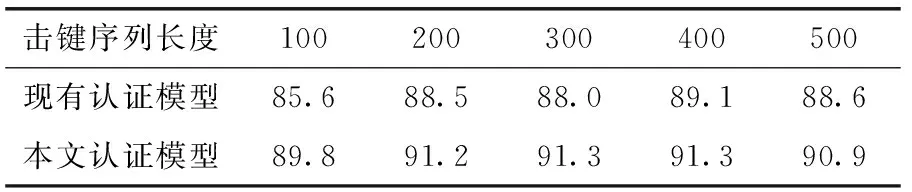
表3 RF準確率/%
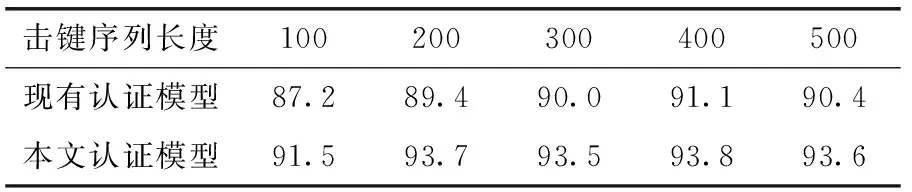
表4 AdaBoost準確率/%
3 結束語
針對現有擊鍵特征下用戶持續身份認證的準確率較低的問題,本文在完全自由的內網環境中采集數據,提出了基于擊鍵內容域和擊鍵行為域的特征提取方法,使用XGBoost算法訓練子分類器,并根據改進的Yager證據合成理論在決策上融合了各域的子分類器。實驗結果表明,該方法可以提高用戶持續身份認證的準確率,增強了內網的安全性。
在未來的研究中將擴大擊鍵數據采集的用戶范圍,并延長采集周期,分析各域的擊鍵特征在時間上的穩定性。此外將嘗試結合新域的數據,以進一步提高用戶持續身份認證的準確率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
