LSTM和GRU在城市聲音分類中的應用
2020-07-01 05:35:54孫陳影沈希忠
應用技術學報 2020年2期
孫陳影, 沈希忠
(上海應用技術大學 電氣與電子工程學院, 上海 201418)
快速的城市化對人類社會提出了嚴峻的挑戰,如何建設高宜居和可持續發展的城市是一個值得重視的問題。物聯網技術的進步使我們能夠收集大量與環境和居民活動有關的城市聲學數據,如兒童游戲,道路交通,甚至開槍射擊等。通過研究動態聲音視角的內容,可以更好地了解影響公民日常生活的聲音問題,從而為提高城市生活質量奠定基礎[1-2]。
目前,隱馬爾可夫模型(hidden markov model, HMM)和人工神經網絡(artificial neural network, ANN)是語音識別的常用方法,但是在優化模型搭建、提高識別率等方面有較大的局限性[3-4]。近年來,隨著循環神經網絡(recurrent neural network, RNN)的出現和進一步的研究,其在語音識別領域的應用越來越廣泛[5-7]。例如各種識別、機器翻譯等領域, 還被用于各類時間序列預報或與卷積神經網絡相結合處理計算機視覺問題。然而,RNN自身存在的梯度消失的問題尚未得到很好地解決。文獻[8]中描述了RNN的形式,給出了相應的參數估計方法,分析了其在語音識別方面的優缺點;文獻[9]中研究了RNN在人類情感分析中的識別能力,實驗結果表明,該方法在性別獨立實驗中取得了92%的情感識別準確率,優于以往使用相同實驗數據的方法;文獻[10]中提出了基于大詞匯量會話電話語音識別的長短期記憶神經網絡(long short-term memory, LSTM)體系結構,證明了LSTM在語音識別任務的聲學建模中有很好的表現。
本文采用Mel頻率倒譜系數(Mel-frequency cepstral coefficients, MFCC)對城市聲音數據進行特征提取。為了進一步提高語音識別的準確率,同時解決RNN梯度消失的問題,本文搭建LSTM神經網絡和門控循環單元(gated recurrent unit, GRU)神經網絡并對其組成的深度神經網絡模型進行訓練。通過實驗分析,與基本的RNN網絡相比,降低了損耗,提高了語音識別的準確率。
1 特征提取
20世紀80年代,Davis等[11]首次提出了MFCC,MFCC參數是從生物學角度模擬人耳對語音的感知而提出的,受噪聲等干擾信息的影響小,同時識別率較高,是被用的最多的特征參數。通過人耳對語音的感知性能的大量研究顯示,人耳的感知能力與頻率是非線性的關系,在頻率小于1 kHz時,人耳聽到的頻率與數學上的頻率是同步增減的,而當頻率大于1 kHz時,人耳聽到的頻率與數學上的頻率不存在同比例增減的關系,而是對數關系,將人耳感受到的頻率定義為Mel頻率。Mel頻率與線性頻率的轉換關系式為
(1)
Mel頻率與數學上的頻率關系如圖1所示。

圖1 Mel頻率與線性頻率的關系圖Fig.1 Diagram of Mel frequency and linear frequency
MFCC參數的提取流程如圖2所示,提取步驟具體如下:①端點檢測,目的是從語音信號中確定說話人的開始和結束位置,去掉完全靜音的部分,留下真正有效的說話人語音信息;②預處理,預處理細分預加重、分幀和加窗;③快速傅里葉變換,通過FFT將處理域從時域轉換到頻域;④計算譜線能量,對每一幀信號計算譜線能量;⑤進行Mel濾波器組濾波,Mel濾波器組結構如圖3所示;⑥離散余弦變換,先對上一步的Mel濾波器中的輸出結果取對數,然后再做離散余弦變換,使每一維信號都保持自己的獨立性,同時降維,得到Mel頻率的倒譜系數;⑦求取差分參數,語音信號一部分是時不變的就是靜態的,另一部分是時變的就是動態的。把動、靜態特征結合起來能有效提高系統的識別性能。

圖2 MFCC參數提取流程圖Fig.2 Flow chart of MFCC parameters extraction

圖3 Mel濾波器組結構圖Fig.3 Structure of Mel filter group
維數選取根據實驗網絡和降維的需要,本文采用的MFCC參數的維數是40維,13維MFCC系數、13維一階差分參數、13維二階差分參數和幀能量。本文未涉及與其他特征提取方法的比較。
2 基于RNN的改進
RNN是一種以序列數據為輸入,在演進方向進行循環,全部節點按鏈式連接組成閉合回路的神經網絡。RNN通過每層之間的節點連接來記憶之前的信息,然后利用這些信息影響后續節點的輸出。RNN可充分利用序列數據中的語義信息和時序信息,圖4所示為RNN的簡化結構圖。
循環單元的狀態引入了其上一個時間步的真實值,使用基于上下文連接的RNN由于訓練時將學習樣本的真實值作為輸入,因此是一個可以逼近學習目標任意形式概率分布的生成模型。循環體狀態與最終輸出的維度通常不同,RNN需要一個全連接神經網絡來完成將當前時刻的狀態轉化為最終的輸出。RNN在每個時刻都有一個輸出, 因此RNN的總損失是所有時刻(或部分時刻)上的損失函數的總和。

圖4 基本RNN的簡化結構圖Fig.4 Simplified structure of the basic RNN
從理論上講RNN可以很好地解決序列數據的訓練問題,但是同時又存在梯度消失的問題,尤其是當序列很長的時候。所以,基本RNN模型通常不能直接用于應用領域。在語音識別,手寫識別以及機器翻譯等NLP領域應用比較廣泛的是LSTM模型,基于RNN模型的一個特例。
2.1 LSTM
RNN的最重要目的是學習長期的依賴性,但是理論和實踐表明很難學習并長期保存信息。為了解決這個問題,使用了一種特殊隱式單元LSTM[12](見圖5)。
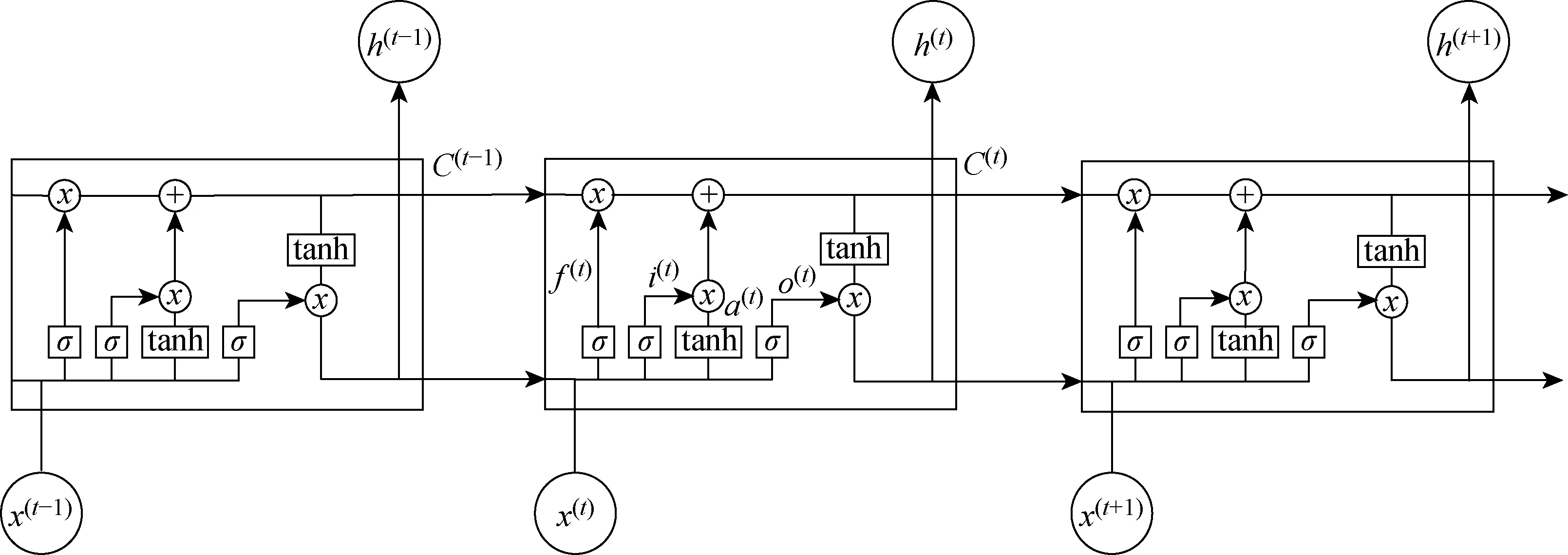
圖5 LSTM的簡化結構圖Fig.5 Simplified structure of LSTM
由圖5可見,LSTM比基本RNN復雜很多。序列索引位置t時刻,LSTM和RNN一樣有隱藏狀態h(t),但是LSTM多了一個隱藏狀態,稱為細胞狀態(cell state),記為C(t)。LSTM中還有門控結構(gate),一般包括輸入門、遺忘門和輸出門3種。則在每個序列索引位置的過程為:
(1) 遺忘門是以一定的概率控制是否忘記上一層的隱藏細胞狀態,其公式為
f(t)=σ(Wfh(t-1)+Ufx(t)+bf)
(2)
(2) 輸入門處理當前序列位置的輸入,由兩部分組成,兩者的結果相乘來更新細胞狀態。
i(t)=σ(Wih(t-1)+Uix(t)+bi)
(3)
a(t)=tanh(Wah(t-1)+Uax(t)+ba)
(4)
(3) 細胞狀態C(t)取決于前面的遺忘門和輸入門的結果,即
C(t)=C(t-1)⊙f(t)+i(t)⊙a(t)
(5)
(4) 更新輸出門輸出:
(5) 更新當前序列索引預測輸出:
(8)
LSTM作為RNN的特例,結構較為復雜。通過LSTM可以有效避免RNN的梯度消失問題,但是LSTM的歷經時間會很長,不夠高效,而且對于小型數據集來說結果不夠理想。
2.2 GRU神經網絡
LSTM的提出是為了克服RNN無法很好地處理遠距離依賴地問題,GRU是LSTM的一個變體。GRU保持了LSTM的效果同時又使結構更加簡單。圖6所示為GRU的簡化結構,只有2個門,重置門和更新門,即圖中的r(t)和z(t)。

圖6 GRU的簡化結構圖Fig.6 Simplified structure of GRU

圖7 城市聲音數據集中聲音類的分類Fig.7 Classification of sound classes in urban sound data sets
在每個序列索引位置的過程為:
(1) 重置門以一定的概率控制前一時刻信息,有利于得到時序數據中的短期依賴關系,即
r(t)=σ(Wr·[h(t-1),x(t)])
(9)
(2) 更新門控制前一時刻的狀態信息被代入到當前狀態中,有助于得到時序數據中的長期依賴關系
z(t)=σ(Wz·[h(t-1),x(t)])
(10)
(3) 候選隱含狀態用重置門來控制隱含狀態。重置門決定了是否丟棄與后來無關的過去隱含狀態,即重置門控制過去有多少信息被遺忘
(11)
(4) 隱含狀態h(t)使用更新門z(t)來對上一個隱含狀態h(t-1)和候選隱含狀態進行更新。更新門決定過去的隱含狀態在當前時刻的重要性。可以解決RNN的梯度衰減問題,并且更好地得到時序數據中間隔較大的依賴關系,即
(12)
(5) 更新當前序列索引預測輸出:
(13)
GRU通過分析LSTM架構中哪些部分是真正需要的而進行改進,將遺忘門和輸入門合成了一個更新門。同樣還混合了細胞狀態和隱藏狀態。最終的模型比標準的 LSTM 模型要簡單。理論上與LSTM相似,可以達到和LSTM相同的效果甚至更好。在實驗的過程中使用了GRU深度神經網絡,將結果與前2種作對比。
3 實驗分析
3.1 數據集
為了驗證所提出的方法,本文使用UrbanSound8K[13]數據集進行了實驗,該數據集包含10個類別的城市聲音和 8 732 個真實世界的聲音。10種聲音類別的簡要分類如圖7所示,分別為空調、汽車喇叭、兒童游戲、狗吠、鉆探、發動機、槍聲、重錘、警笛和街頭音樂。可見,該數據集包含了典型的城市噪聲和與城市生活高度相關的突發事件聲音,因此該數據集適合于測試城市語音分類算法。此外,還給出了如圖8所示表示事件類的樣本數量。該數據集還提供了10個交叉驗證集,確保訓練和測試分割之間沒有重疊。

圖8 每種聲音類的樣本數量Fig.8 Sample size per sound class
3.2 網絡搭建
循環神經網絡的訓練需要在結構(輸入數據的格式、層的數量和大小)和學習超參數(學習速率、動量、批處理大小、退出概率、應用正則化的數量)2個方面做出許多決策。由于訓練一個完整的模型需要時間,因此對所有可能的組合進行詳細的評估是不可能的。因此,最有前途的模型選擇必須基于對最重要的因素(隱藏層數、學習率、dropout)進行有限的驗證。
(1) 對于數據集的語音特征提取,本文采用MFCC,利用librosa實現,從數據集中提取MFCC特征集。
(2) 對于隱含層數量的選擇,主要從準確率、損失值及時間這三方面考慮。在其他參數不變的情況下,更改隱含層數量。由圖9可見,整個過程時間基本沒有差別,但對于準確率和損失來說,在隱層數量為3時結果最為理想。

圖9 隱含層數量對比Fig.9 Comparison of the number of hidden layers

圖10 Dropout參數對比圖Fig.10 Dropout parameter comparison chart
(3) 本文實驗在訓練時加入dropout。在預測時,會使用所有的單元,這相當于組合所有的模型,所以dropout可以有效地防止訓練中出現參數擬合過度的問題,同時組合訓練能獲得更好的組合模型。經由圖10對比,可以看到dropout不同時的效果,整個過程時間基本沒有差別,但對于準確率和損失來說,dropout為50%時效果最佳。
(4) 進一步處理是通過隱藏層,每層300個節點數,節點數太多會增加訓練的時間以及訓練容易陷入局部極小點而得不到最優點,出現“過擬合”的現象。
(5) loss函數使用交叉熵。交叉熵作為損失函數的好處是在梯度下降時能避免均方誤差損失函數學習速率降低的問題。
(6) 經過上面的實驗,本文網絡的主要參數如下:輸入維度40;輸出維度10;隱藏層3層;隱層單元數300;dropout參數0.5。網絡結構第1層為特征參數輸入層,即Mel參數集。2、3、4三層為本文所述神經網絡層,每層300個單元,dropout為50%。最后一層為全連接輸出層,與softmax結合分類輸出。網絡結構如圖11所示。
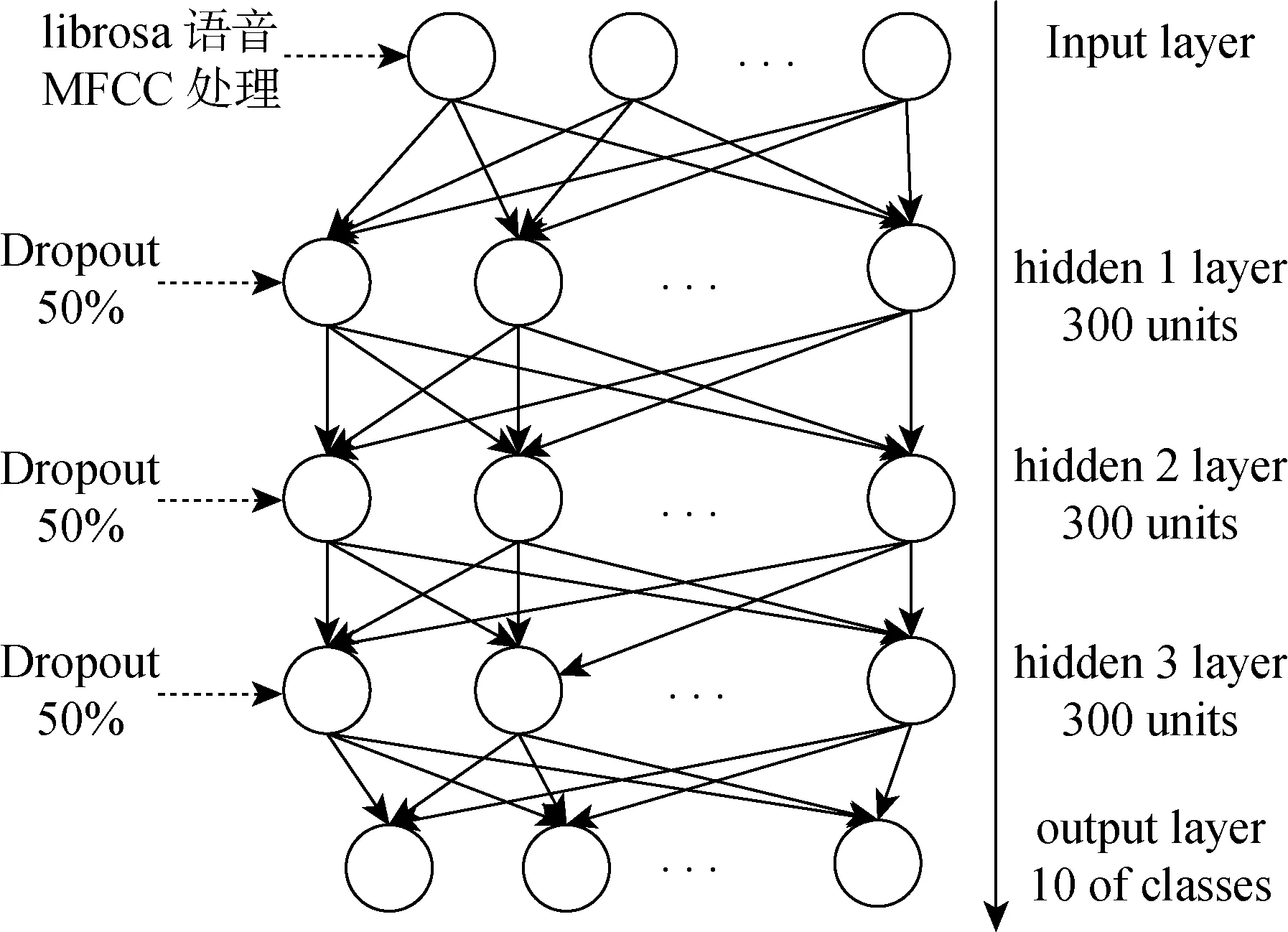
圖11 深度循環神經網絡結構Fig.11 Deep recurrent neural network structure
3.3 實驗結果分析
本文的主要目的是通過深度學習神經網絡完成對城市語音數據集UrbanSound8K的分類。主要實現方法為深度RNN(RNNs)、深度LSTM(LSTMs)和深度GRU(GRUs)。實驗在Ubuntu14.04,TensorFlow環境下實現,如圖12所示。

圖12 RNNs、LSTMs和GRUs的語音分類的準確率和損失Fig.12 Accuracy and loss of speech classification for RNNs, LSTMs and GRUs
由圖12可見,基本RNNs、LSTMs和GRUs的訓練和測試結果,將最后的結果列在表1中。
表1 RNNs、LSTMs和GRUs的訓練和測試結果
Tab.1 Training and test results of RNNs, LSTMs and GRUs

網絡類別耗時/min損失準確率/%RNNs訓練30.672.21423.94測試30.672.23621.78LSTMs訓練60.621.69976.14測試60.621.76369.82GRUs訓練20.531.49396.81測試20.231.60885.87
從時間上看LSTMs耗時是RNNs和GRUs的2倍,且GRUs相對RNNs來說具有更大的優勢,可以節省很多時間。從損失loss上看RNNs消耗較大,LSTMs和GRUs相比還是GRUs的效果好。從準確率上看RNNs的準確率太低,LSTMs也只達到了80%左右,GRUs相對來說效果最好,訓練效果可以達到96%。由上可知,GRUs在損失和準確率上比LSTMs更好,尤其是在時間方面GRUs最快速。經過上面的實驗對比,基于本文選取的數據集,GRUs在時間上更加節省,同時準確率有所提升,損失下降,實現效果最好。
對于本數據集的研究,使用相同的特征參數提取方法,與文獻[13]中使用的深度卷積神經網絡進行對比,該網絡的準確率為83.5%。經對比,本文的方法在準確率上優于文獻[14]中的深度卷積神經網絡。
4 結 語
本文通過搭建LSTM和GRU深度神經網絡分別對基于Mel頻率倒譜系數(MFCC)提取UrbanSound8K數據集的特征參數,進行語音識別的訓練和測試。實驗結果表明,本文采用的LSTMs和GRUs在損失和準確率方面比基本RNNs要好,并有效地解決了RNN的梯度消失問題。其中對于本文采用的數據集,GRUs表現更好,簡潔且更加高效。但是,本文搭建的深度神經網絡仍然還有局限性,在以后的學習中可以繼續優化或者結合其他網絡進行優化。由上述實驗表明,城市聲音的分類,對研究城市聲音對居民的影響,提高城市生活的質量有很大的意義。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
核科學與工程(2015年4期)2015-09-26 11:59:03
