基于BLSTM 的語音識別解碼優化算法探討
2020-07-04 08:53:32郭川玉蘇一敏
科學技術創新 2020年18期
郭川玉 蘇一敏
(深圳航天科創實業有限公司,廣東 深圳518000)
1 概述
語音識別領域發展中,長期奮力追求的研究目標在于實現識別準確率上的“人類對等”。微軟團隊在研究語音識別技術方面付出較大的努力,且取得了良好的進步,以神經網絡為基礎的聽覺和語言模型,促進語音識別的出錯率顯著下降,而引進CNN-BLSTM (convolutional neural network combined with bidirectional long-short-term memory,帶有雙向LSTM 的卷積神經網絡)模型,能夠有效提升語音建模實施效果。在語音識別領域中,需要重點解決的一個問題在于解碼優化算法,從BLSTM出發,將能夠起到良好效果。
2 語音識別的基本情況
語音識別(Automatic Speech Recognition,ASR)是一種交叉學科,是指讓機器通過分析和理解過程把語音信號轉變為相應的文本或命令的尖端技術。在語音識別領域之中,涉及到了較多方面的內容,如信號處理、概率論和信息論、人工智能、模式識別、發聲機理和聽覺機理等。
在構建智能語音技術服務平臺的過程中,需要著重強化語音識別引擎,使其表現出較多技術特性:(1)擁有廣泛的可識別內容。對于新聞、紀錄片等方面媒體形式來說,語音技術關系到較多行業領域之中,想要確保語音能夠得到全面覆蓋,需要發揮語音識別引擎的作用,構建起大型的語言模型,從而強化可識別內容的范圍和準確性。(2)具有較高的識別準確率。為實現這一目標,需要積極引進最新的DNN(深層神經網絡)算法,可以大約降低30%錯誤率。(3)擁有快速的識別速度。積極構建起完善系統的解碼網絡,包含詞典、語言模型以及聲學共享音字集,這其中需要引進解碼器核心和有限狀態機(WFST)解碼網絡。(4)可以定制領域模型。語音識別系統應用中,要能夠全面結合用戶的實際特點,制定出專門性的語言模型。(5)使得時間索引達到現實。從識別系統出發,可以全面精確到字詞,還能夠引進倒排索引,便于多媒體信息檢索活動的順利實施。(6)支持多語種。引擎核心算法和語種之間不具備聯系,能夠移植到相關語種中。積極借助于機器學習訓練和人工標注方式,識別多個語種類型。(6)支持多音頻格式。多個錄音系統綜合應用,形成綜合性的音頻,如8K16bit GSM610、8K16bit pcm、8K4bit vox、8K4bit alaw 等。
3 基于BLSTM 語音識別解碼優化算法的可行性
3.1 BLSTM 的基本情況
BLSTM(Bidirectional Long Short-term Memory),是指雙向長短時記憶神經網絡,當前自動語音識別中積極應用這一網絡方式,實施聲學建模活動。BLSTM 的基本結構單元如下圖所示,從其中能夠看出,其中存在著輸入門、忘記門以及輸出門這三個門結構。
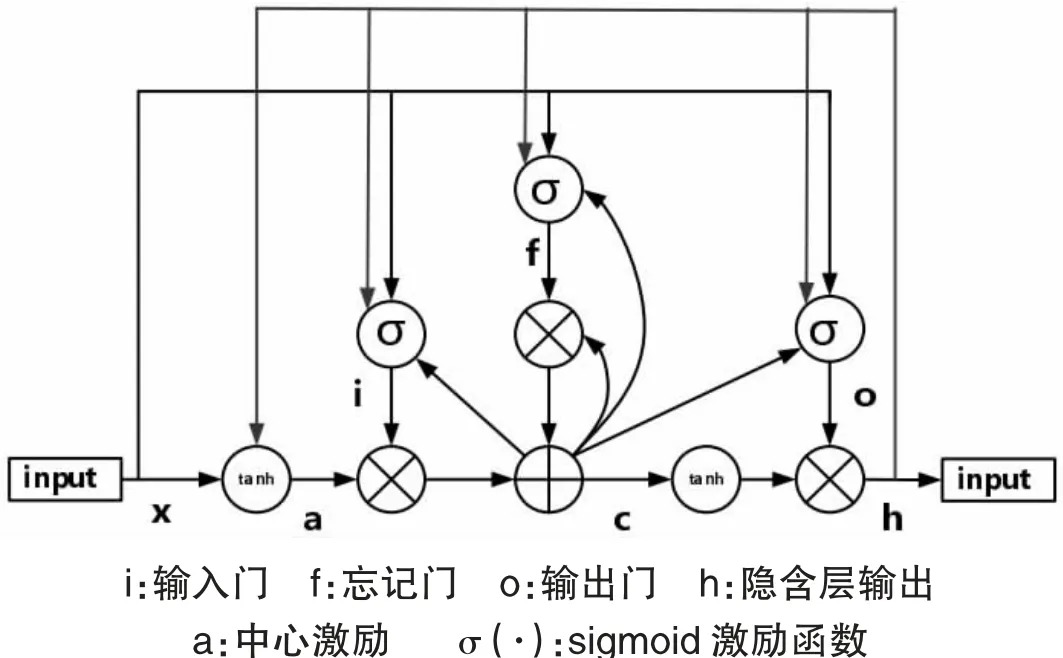
圖1 BLSTM 基本結構單元圖
結合BLSTM 的基本結構單元,實現準確計算各項結構參數的目標,需要采用科學可行的計算方式,即為:

3.2 應用可行性
以往經常使用到的聲學建模方法應用中,存在著一些不足,積極引進BLSTM 方式,將其作為語音識別系統的重要基礎,將能夠強調良好效果。需要注意到的是,BLSTM 實際應用中還需要整句遞歸計算每一幀的后驗概率,這其中會產一些缺陷性問題,如解碼存在著延遲現象,無法切實保障實時率,無法保證好這類神經網絡在實時場景中的有效應用。針對這種情況,需要從BLSTM 出發,積極研究語音識別解碼優化算法,將能夠起到良好效果,更好發揮BLSTM 的優勢和作用,支持語音識別系統的有效運行。
4 基于BLSTM 的語音識別解碼優化算法
4.1 解碼優化算法情況
語音識別系統設計和應用過程中,積極引進BLSTM,將能夠更好轉變以往神經網絡中的不足之處,提升語音識別準確性和時效性。但是需要注意到的是,以BLSTM 作為基礎的語音識別系統運行中,還存在著一些解碼延遲的問題。BLSTM 實際開展解碼活動的過程中,解碼器需要達到一定狀態后才能夠實施后續解碼作業,即是當到達整音頻之后才能夠完成的,這是因為前向傳播時間反方向的時候,需要有末尾的歷史信息作為支持。由此能夠看出,BLSTM 所存在著的延時問題,無法支持實時語音識別活動的開展。
(1)通過latency-controlled BLSTM(LC-BLSTM,延時控制-雙向LSTM),能夠有效應對和解決這一問題。這些算法能夠切分整句,使其轉變為若干個Chunks。將左右上下幀添加到每個Chunk 之中,將Chunk 作為重要的計算單位,推進前向計算活動的順利實施,從而能夠有效控制BLSTM 的延遲情況,使其保持在一個Chunk 的時長,不僅具有同等的準確率,還能夠有效避免延遲問題的發生。
(2)現階段在BLSTM 網絡方式應用的過程中,還可以積極引進CPSC 算法,這是按照上下文相關塊實施解碼的算法,能夠全面綜合給各個環節,支持解碼優化活動的順利實施。具體引進CPSC 算法的過程中,首先,要能夠按照固定窗長,針對語音幀序列進行細化和切分,使其形成較多個Chunk。其次,需要開展Chunk 拼接活動,使其形成具有一定長度的上下文,而在實施解碼活動的過程中,每個Chunk 都是最小的單元。再次,在實際開展拼接活動的過程中,上下文之間會產生重復計算現象,為有效解決這一問題,CPSC 算法以狀態拷貝為重要基準,將能夠起到良好效果。最后,在具體應用環節中,需要針對每一個Chunk 初始幀的BLSTM-Cell 狀態實施初始化處理,這其中就需要使用到上一個Chunk 最后一幀的BLSTM-Cell 狀態情況,如此循環往復。整個操作進行當中,左上文擴展所產生的計算開銷被取消,從而整個系統的實時率得以顯著上升。
4.2 實驗分析
從狀態拷貝方法出發,積極實施上下文相關塊的解碼算法活動,能夠起到良好效果,可以將其應用在實踐環節實施驗證。將這一方法應用在2.0 小時中文電話對話語音測試集中,能夠發現在固定Chunk 大小的基礎上,當合理增加上下文幀數,將能夠有效降低識別字的錯誤率,需要注意到的是,隨著重復計算幀數有所增加,提升了實時率。而如果固定上下文幀數,增加Chunk 的大小,不會降低識別字的錯誤率,而實時率則有所降低。積極引進狀態拷貝的CPSC 算法,在保證語音識別精度的前提下,能夠使得識別速度加快到0.3~0.4 倍,效果顯著。
5 結論
現階段人機語音通信活動,充分適應人們的實際生產生活需求,在建立語音系統的過程中,語音識別技術和語音合成技術是關鍵技術手段。積極發揮BLSTM 的優勢,以狀態拷貝為基礎的上下文相關塊解碼算法,將能夠起到良好效果。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
少先隊活動(2022年5期)2022-06-06 03:45:04
房地產導刊(2022年5期)2022-06-01 06:20:14
家庭科學·新健康(2022年3期)2022-05-10 00:32:13
中老年保健(2021年2期)2021-08-22 07:31:10
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
