面向RDF圖的多模式匹配方法
2020-07-06 13:34:48孫云浩李逢雨李冠宇邢維康
計算機工程與應用 2020年13期
孫云浩,李逢雨,李冠宇,韓 冰,邢維康
大連海事大學 信息科學技術學院,遼寧 大連 116026
1 引言
在語義網中,資源描述框架[1](Resource Description Framework,RDF)是一種基于圖的數據模型,用于Web端的信息共享。給定一個數據圖G和一個模式圖Q,模式匹配(子圖同構)問題是指搜索數據圖G 中所有同構于模式圖Q 的數據子圖。多模式匹配問題是對模式匹配問題的一種擴展,其主要的挑戰是多個模式圖之間的并行策略。為了提高匹配執行效率:一方面,對于存在包含關系的多個模式圖,需要避免對公共查詢子圖的重復計算;另一方面,在匹配執行過程中,盡量減少候選數據子圖的量。因此,本文提出一種面向RDF 圖的快速多模式匹配方法。
模式匹配問題是一種子圖同構問題。子圖同構問題是一種典型的NP 完全問題,隨著數據圖規模的不斷增大,匹配的時間效率呈指數級變化。在面向RDF 圖匹配處理中,大部分的研究者將RDF 數據存儲到關系表中。Hexastore 采用一種基于索引的解決方案,將RDF 數據直接存儲在B+樹[2]。SW-Store 通過模式集合中的常量標簽將RDF數據存儲到一系列的垂直分片表中[3],然后,通過構建關系表的索引快速地定位到需求的表。Jena 和Sesame 是基于圖數據庫的思想[4-5],其抽離出RDF數據的概念構成屬性表。基于關系表的研究者采用了相似的匹配策略。首先,其通過模式集合的有界標簽來縮減對數據關系表的搜索空間;其次,過濾表中不需要的RDF數據,以便于達到對局部結果的存儲,降低匹配處理過程的執行代價;最后,對局部結果進行連接運算,最終形成匹配的子圖集合。然而,由于RDF數據的索引構建和預處理會有大量的時間消耗,因此,對于RDF數據的匹配處理具有相當大的延遲。
面向一般圖的子圖同構算法主要分為三類,基于樹搜索[6-7]、基于約束傳播[8-9]和基于圖索引[10-11]的子圖同構算法。其中,基于圖索引的子圖同構算法與基于關系表的模式匹配算法類似,通過構建圖索引,減少搜索空間,快速搜索到模式圖的匹配子圖。然而,這種方法需要對整個數據集進行全存儲,從而導致大量的時間消耗和存儲代價。基于樹搜索的子圖同構算法利用可行性規則對一個樹型搜索空間中不需要的候選集進行裁剪,以達到快速匹配的目的。基于約束傳播的子圖同構算法是將子圖同構問題同構于約束傳播問題,其目的是找尋那些分配到滿足共同約束的變量集中的值。其主要的思想是基于局部約束的傳播特性,節點或者邊的一致性會傳播到圖中的其他部分。因此,在圖中只有很少的候選集被保留。
多模式匹配問題是對模式匹配的一種擴展,其主要的挑戰是多個模式圖之間的并行執行策略。多模式匹配處理過程主要包括多模式圖匹配序列優化和匹配策略。多模式圖匹配序列優化一般通過計算多個模式圖之間的包含關系構建多模式圖的依賴圖或者依賴樹。文獻[12]通過計算多個模式圖之間的包含關系,生成最小依賴樹,并利用依賴樹的執行序列進行多模式匹配,一定程度上減少了候選集規模。文獻[13]提出多模式圖的依賴圖構建和優化方法,其通過一個啟發式算法制定模式圖執行序列,減少了冗余計算以及候選集緩存。多模式圖匹配策略主要的挑戰是候選集的計算代價。文獻[14]提出一個動態解決方法。該方法能夠避免形成冗余候選集,并且可以在形成最大候選集之前到達結果集。文獻[15]提出一種最大公共子圖的優化算法,通過代價模型計算確保匹配代價最小。文獻[16]通過提出的三元節點標簽序列計算分組因子,從而得到模式包含映射,通過模式包含映射得到模式執行序列。
本文提出一種面向RDF 圖的快速多模式匹配算法。首先,在D-Tree 構建算法中加入剪枝策略,通過剪枝策略使得構建的D-Tree最優。其次,提出節點分片表的概念。為了編排多個模式圖之間的執行序列,構建了一種多模式圖的依賴樹。然而,包含關系是一種單一、抽象的表示,它不足以表示多個查詢節點間的交叉關系。因此,提出了一個NFT的概念,用來表示節點間的執行關系。最后,提出一個基于D-Tree 和NFT 的多模式匹配算法,通過遍歷一次RDF 數據圖就可以得到多個模式圖匹配的數據子圖。當然,本文方法同樣適用其他的所有有標簽、無標簽的圖結構,對于無標簽的圖,可以對其定點和邊進行唯一標識。如通過統一字典編碼技術對屬性圖編碼等。
2 依賴樹和節點分片表
2.1 問題定義
定義1(基本模式圖)一個基本模式圖p(Vp,Ep,Lp,?p,varp)是一個有向標簽圖,其中Vp表示節點集;Ep表示有向邊集;是一個有向函數,表示從u到v的一條有向邊,其中u,v∈Vp;Lp表示邊和節點標簽集;varp表示一個標簽變量集;表示一個將節點和邊映射到對應標簽的標簽函數。在一個模式集中,不存在任意一個模式圖同構于模式p,則p為基本圖模式。
定義2(數據圖)一個數據圖是一個有向標簽圖,其中Vd表示節點集;Ed表示多個有向邊集;是一個有向函數,表示從u到v的一條有向邊,其中u,v∈Vd;Ld表示邊和節點標簽集;?d:Vd?Ed→Ld表示一個將節點和邊映射到對應標簽的標簽函數。
基本模式圖與數據圖區別在基本模式圖的標簽可以為變量,變量標簽指的是常量標簽的一個集合,也可以稱為標簽的值域。因此,給定一個常量標簽c和一個變量標簽v,如果c是v值域內的一個常量,那么c∈v。
定義3(子圖同構)給定一個基本模式圖p(Vp,Ep,Lp,?p,varp)和一個數據圖當且僅當存在一個雙射函數f:Vp→Vd滿足:
子圖同構處理方法是找尋所有滿足子圖同構的節點對。給定一個基本模式圖中節點vp和數據圖中的節點vd,如果f(vp)=vd并且滿足定義3中(1)和(2),那么搜索到的節點對為(vp,vd)。多模式匹配問題是對模式匹配的一個擴展,其側重于多個模式圖之間的并行執行策略。因此,避免多個模式圖之間的重復計算問題是本文研究的重點。
定義4(多模式匹配問題)給定一個基本模式圖集和一個數據圖d,m∈N+。給定任意的一個基本模式圖p∈P,多模式匹配指的是依次地搜索d中同構于p所有匹配的數據子圖。
圖1 描述的是多個模式圖以及它們之間的公共子圖。圖(a)表示多個基本模式圖,圖中符號分別表示頂點和邊的標簽,“?”表示當前標簽為變量。任意一個基本模式圖都不同構于其他的基本模式圖。圖(b)表示多個基本模式圖的公共子圖,其中p6為模式圖p1、p2、p4和p5的公共子圖。
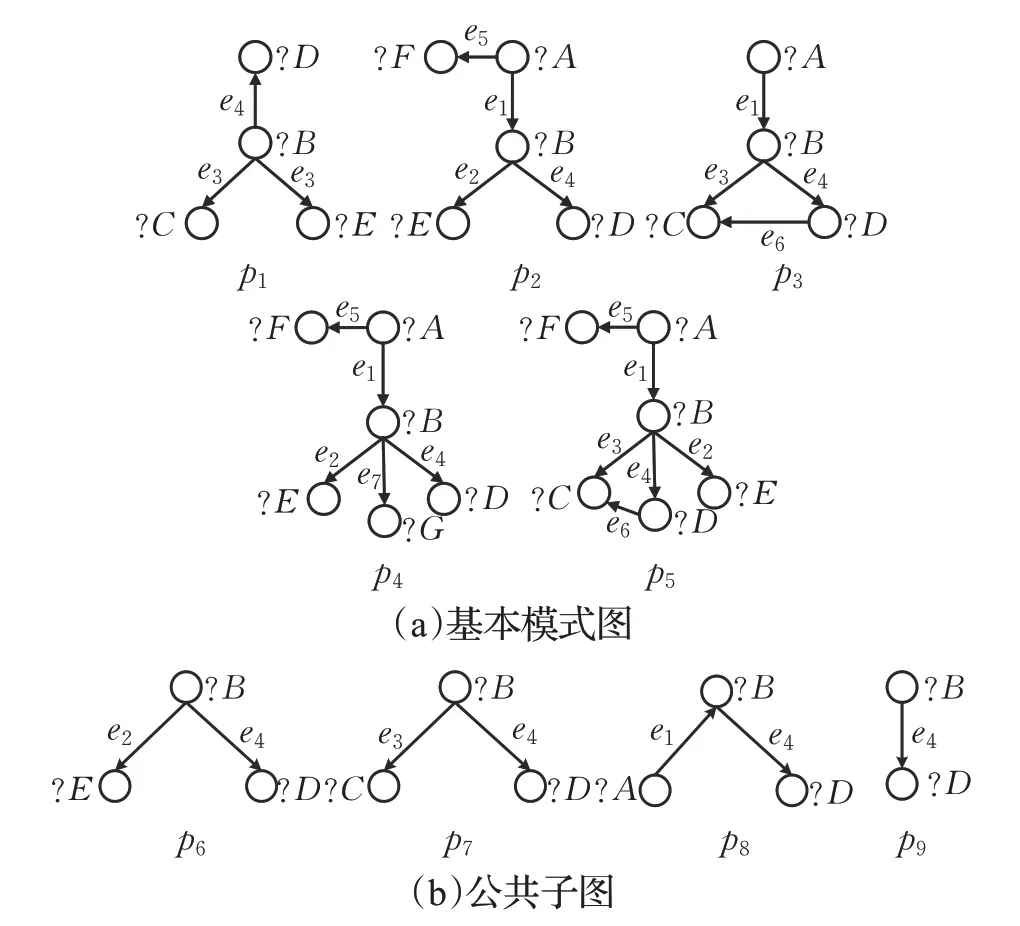
圖1 基本模式圖及其公共子圖
2.2 依賴樹
依賴樹的構建能夠清晰地描繪出多個基本模式圖之間的依賴關系。大部分研究者通過計算多個基本模式圖之間的公共查詢子圖,依靠基本模式圖與公共查詢子圖的包含關系構建依賴樹和依賴圖。然而,并不是所有的公共查詢子圖都要構建到最終的依賴樹或者依賴圖中的,因為公共查詢子圖可能存在重疊的部分或者多個公共查詢子圖依賴一個相同的基本模式圖集。因此,提出一種公共子圖的裁剪策略。
依賴樹的構建過程主要包括依賴圖的生成和生成樹的構建。依賴圖的生成是通過計算多個基本模式圖之間的公共查詢子圖,依靠基本模式圖與公共查詢子圖的包含關系構建依賴圖,生成樹的構建是通過代價評估模型對依賴圖的剪枝操作,為了能夠清晰地表述出代價評估模式,給出了殘差圖的定義。
定義5(殘差圖)給定兩個模式圖pa和pb,并且pa子圖同構于pb,那么pb相對于pa的殘差圖為pb-pa,包含pb中除去子圖同構于pa部分后剩余部分的節點和邊。這些頂點和邊被稱之為殘差點和殘差邊。依賴樹索引構建過程分為以下幾步:
(1)依賴圖生成(算法1,2~9 行),目的是找到模式間的包含關系。首先采用子圖同構算法找尋多個基本模式圖的子圖同構關系,若存在子圖同構關系,則構造它們之間的依賴關系。若不存在子圖同構關系,則計算多個基本模式圖之間的公共查詢子圖,然后構造基本模式圖與公共查詢子圖之間的依賴關系。
圖1 所示的模式圖集構建的依賴圖如圖2(a)所示。依賴圖為一個有向圖,圖中每條邊連接的兩個節點間具有子圖同構關系,如p1子圖同構于p4。圖(a)中,p6也子圖同構于p4,但是由于p6通過p1連接到p4,因此省略p6指向p4的邊。圖中實線節點表示模式集中存在的節點,虛線節點表示加入到模式集中的最大公共子圖。
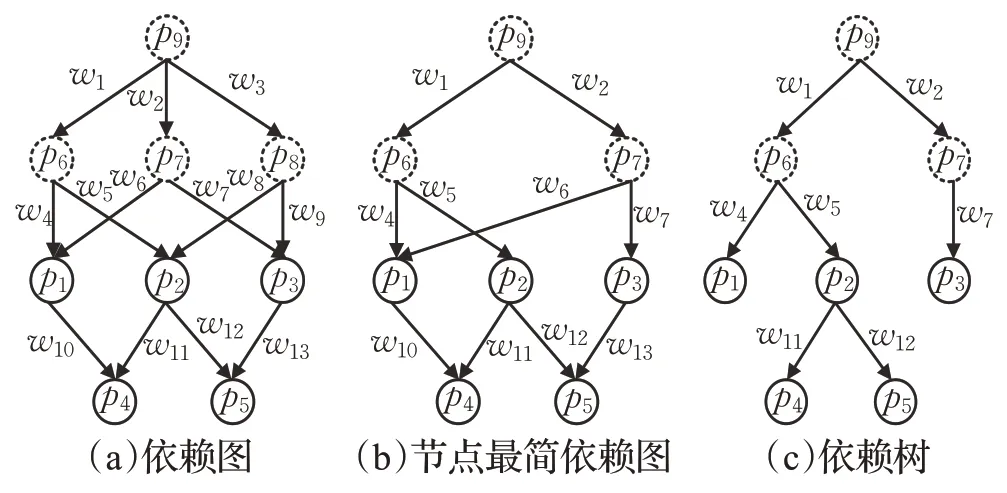
圖2 依賴樹構建過程
算法1 BuildDTree(P,?)
Input:pattern graph setP={p1,p2,…,pn},user specified parameter for VFT building
Output:D-Tree
1.InitialT=?
2.for each petternpiinPdo
3. for each patternpjinPdo
4.if(SubgraphIsomorphism(pi,pj))then
7. end if
8. end for
9.end for
10.CutRedundantEdge(T)
11.ReturnT
依賴圖構建時間復雜度為O(N2),N為模式圖的個數。
(2)代價評估模型,目的是對依賴圖的冗余節點和邊進行裁剪操作。根據定義5,生成樹的代價函數表示為:
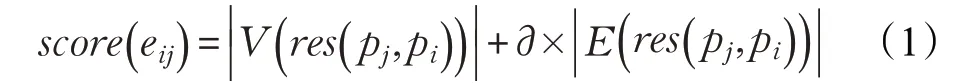
其中,eij為基本模式圖pi到pj的一條有向邊和表示中節點和邊的數量。?為人為給定的參數。通過公式(1),可以為每條邊賦予一個代價,表示基于pi的匹配結果執行pj匹配的代價。為了對節點進行評估,本文設計了一個權重函數,對虛線節點代價評估。權重函數構建為:

定義6(可裁剪節點)給定虛線節點pi,若其滿足以下條件:①;②,則稱其為可裁剪節點。其中,parent[pj]表示pj的父親節點。
例1(可裁剪節點舉例)如圖2 所示,節點p6有兩個孩子節點分別為p1、p2,p1有兩個父親節點分別為p6、p7,p2有兩個父親節點分別為p6、p8,因此p6滿足定義6 中兩條約束為可裁剪節點,在其同一層次中p7、p8也為可裁剪節點。
(3)依賴樹構建,目的是為了最小化整體的匹配代價,減少重復計算。這一步對依賴圖進行節點和邊的裁剪,裁剪后的依賴圖稱為依賴樹。裁剪節點時,由于虛線節點不需要結果集的輸出,因此只對虛線節點及其相連的邊進行裁剪。由出度為零的節點出發向上遍歷,若某個節點為可裁剪節點,且同層次(從根節點向下遍歷路徑長度相同的節點為同一層次)上有多個可裁剪節點時,比較這些節點的權重,將權重最大的節點裁剪掉,直到這一層無可裁剪節點為止。重復此裁剪過程,直到依賴圖中不存在可裁剪節點,則停止裁剪。圖2(a)中可裁剪節點為p6、p7、p8,設 ?=0.5,則分別為4.5、3.5、5,p8權重最大,將p8及其相連節點裁剪,此時p6、p7不再是可裁剪節點,且同層以及依賴圖都無可裁剪節點,則停止裁剪,得到圖2(b)。裁剪邊時,使用最小生成樹算法,對于每個節點只保留代價最小的入度邊,以此保證每個節點只有一個父節點。裁剪邊后得到圖2(c)。時間復雜度為O(N),N為模式圖的個數。
依賴樹的存儲引入了模式邊表(圖3)的形式。模式邊表(PE 表)分為三列,第一列表示所有依賴樹中的節點(基本模式圖或者公共模式圖),第二列表示第一列中節點的父節點,第三列表示第一列中節點與第二列中父節點的殘差邊。
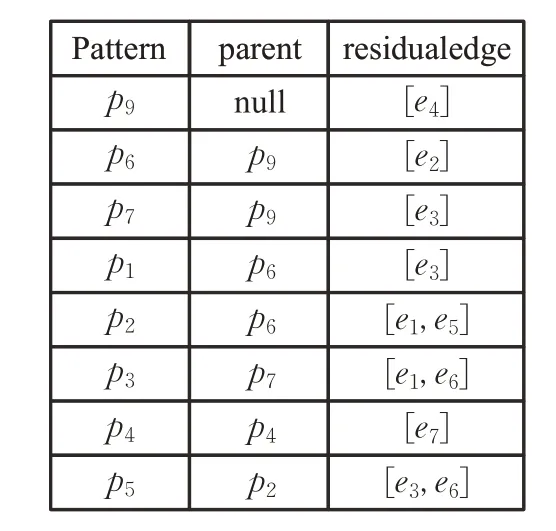
圖3 模式邊表
2.3 節點分片表
依賴樹是對多個基本模式圖之間依賴關系的一種描述。這種依賴關系可以以理解為對殘差邊的抽象。通過這些依賴關系可以有效地制定多個基本模式圖之間的執行序列。然而,很難在這些單一的,抽象的依賴關系中發掘出有助于匹配效率的輔助信息。因此,提出了一個可以細化、實例化依賴關系的節點分片表。首先,給出了內部邊和外部邊的定義。
定義7(內部邊和外部邊)由D-Tree根節點依次向下遍歷,給定兩個模式圖p1、p2,p1∈D-Tree,p2∈D-Tree且。存在節點,且存在節點,,邊e(u,v)為節點u、v的內部邊,記為i-edge。存在節點,且存在節點則為節點u的外部邊,節點w的內部邊,記為o-edge。
NFT由內部節點片表(簡寫為iNFT)和外部節點分片表(簡寫為oNFT)組成,其中包含內部邊的為iNFT和包含外部邊的為oNFT。NFT 包含兩列:節點和邊。在NFT 每行中,節點列只存放一個節點v,邊列存放與v節點相連的內部或外部邊,因此iNFT和oNFT被形式化為和
NFT 是基于D-Tree 構建的(算法2、算法3)。在DTree 中,由于沒有其他節點同構于根節點,因此根節點的節點和邊被直接存入iNFT 中(算法3 的5、6 行)。給定一個節點p1(不是根節點),它的父親節點p2和一個節 點u∈Vp2,存 在 節 點v∈Vp1,使 得e(u,v)∈Ep1,,則為u的外部邊,v的內部邊。u和被存入oNFT(算法3的8、9行),v和e(u,v)被存入iNFT。算法偽代碼如下:
算法2 NFT(P,?)
Input:pattern graph setP={p1,p2,…,pn},user specified parameter for NFT building
Output:NFT={nft1,nft2,…,nftn}
1.Initial NFT=?
2.T=BuildPatternTree(P,?)
3.P← {b|a=root,child[a]}
4.for each patternpinPdo
5.nft←sub-NFT(p,T,NFT)
6. NFT←NFT ∪nft
7.end for
8.return NFT
例2(NFT 構建過程舉例) 圖 2 為 D-Tree 構建的構建過程,圖4表示的是NFT表。p9:由于p9為根節點,p9中節點?B、?D以及邊e4被存入iNFT中。p6:對于p9中節點 ?B,在p6中存在節點?E,使得e2={?B,,因此e2為節點?B的外部邊;對于p6中節點?E,在p6中存在節點?B,使得,因此e2為節點?E的內部邊。
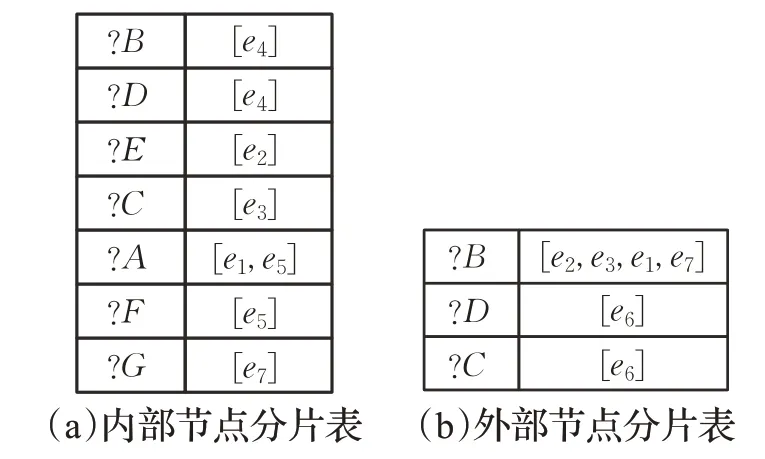
圖4 節點分片表
3 多模式匹配算法
描述多模式匹配算法前,首先給定基本模式圖與數據圖之間的節點關系。給定數據圖中的任意節點vd,模式圖中存在節點vp與vd匹配,則vd是vp的一個實例,被表示為節點對(vp,vd)。給定數據圖的任意兩個節點,模式圖中存在節點,滿足的一個實例,的一個實例,且的一個三元組實例。
算法3 sub-NFT(P,T,NFT)
Input:pattern graph setP,PatternTreeT,NFT
Output:NFT
1.Initial NFT=?
2.for each patternpinPdo
3. for eachvin patternpdo
4. ifv?NFT then
5.E(v)={e|eu,v,u∈V(v)} is i-edge
6. iNFT (v)←E(v)∪iNFT(v)
7. else
8.E(v)={e|eu,v,u∈V(v)}-iNFT(v) is o-edge
9. oNFT (v)←E(v)∪oNFT(v)
10. end if
11. end for
12. if child[p]≠? then
13.P=child[p]
14. sub-NFT(P,T,NFT)
15. end if
16.end for
17.return NFT
多模式匹配算法基于D-Tree和NFT,多模式匹配結果是通過先序遍歷D-Tree 逐步得到的。得到根節點proot的結果集分為以下幾步:
(1)給定proot中的一個固定節點,在數據圖中獲得一個的實例節點vd,并且把它做為一個初始的數據節點。固定節點是由和D-Tree得到的。若節點為固定的,當且僅當固定節點由函數確定。
(2)順序遍歷vd的一階鄰居節點獲得節點序,并設置為下一跳遍歷的初始數據節點。下一跳遍歷數據圖時,給定一個初始數據節點和由它獲得的節點,存在節點vp,滿足是vp的一個實例且則被寫入p9的結果集中。若,則被存入臨時結果集Temp中。
算法4 Multi-pattern Matching(D,P,?)
Input:pattern graph setP={p1,p2,…,pn} ,Data graph setD={d1,d2,…,dn};user specified parameter for VFT building
Output:matching set ofp
1.Initialize Temp=? ,VFT=? ,set=?
2.VFT,collectionlable=VFT(P,?)
3.for eachdinDdo
4. get any nodev∈basicpattern ind
5. Temp←addnode(v,d,VFT,Temp)
6. While Temp≠? do
7. while Tempinnode≠?do
8. TraverseInnerNode (Temp,NFT)//遍 歷 內 部 節點,并存到Temp中
9. end while
10. ifTempinnode≠V(basicpattern) then
11. traverse the next data graph
12. end if
13. basicset←d∪ basicset
14. whileTempoutnode≠?do
15. TraverseOuterNode(Temp,NFT)//遍歷外部節點,并存到Temp中
16. end while
17. ifpiin collectionlable ∈Tempinnodethen
19. end if
21. end while
22.end for
23.return set
(3)執行proot匹配,直到沒有新的三元組實例被加入到結果集中。
孩子節點結果集獲得過程不同于根節點,需要通過父親節點的結果集和臨時結果集來獲得,主要分為以下幾步:
(1)將父親節點的結果集復制到孩子節點中。
(2)給定孩子節點pchild的一個固定節點,在數據圖中找到的一個實例節點vd,并把它做為臨時結果集中的初始節點。若節點為固定的,當且僅當固定節點由函數確定。
(3)順序遍歷vd的一階鄰居節點獲得臨時結果集的節點序,并設置為下一跳遍歷的初始數據節點。下一跳遍歷臨時結果集時,給定一個初始數據節點和由他獲得的節點,存在模式節點vp,滿足是vp的一個實例且,則被寫入pchild的結果集中。在臨時結果集上重復執行一跳遍歷,直到沒有新的三元組實例被添加到臨時結果集中。
(4)將臨時結果集上最終的初始化數據節點做為數據圖上的初始數據節點,并執行(2)、(3)兩步獲得孩子節點結果集。
(5)重復執行(1)~(4)直到獲得所有模式的結果集為止。

圖5 面向RDF圖多模式匹配過程
例3(面向RDF 圖多模式匹配過程)多模式匹配過程如圖5 所示。圖(a)表示一個待匹配的數據圖,圖(b)、(c)表示D-Tree進行多模式匹配過程中結果集的變化,其中Result表示結果集,Temp表示臨時結果集。
p9:由于p9是D-Tree的根節點,它的匹配過程只需要借助內部表。首先,,從?C、?D中任意選擇一個節點做為固定模式節點。假設?B為固定模式節點,在數據圖中b1為?B的實例節點,并把b1設置為一個(a)的初始數據節點。通過一跳遍歷b1,三元組實例被寫入p9的結果集中,三元組實例被寫入臨時結果集。之后,順序的得到d1、d2并將它們設置為下一次遍歷的初始節點。通過一跳遍歷d1、d2,三元組實例被寫入p9的結果集中,三元組實例被寫入臨時結果集中。
p6:p6的匹配過程需要借助內部表和外部表。由于p6為p9的父節點,把p9的結果復制到p6的結果集中。圖5中由于圖片大小問題,將不復制結果,只顯示新遍歷得到的結果。首先,由公式得到固定節點為?B,b1為?B的實例節點,并把b1設置為臨時結果集的一個初始數據節點。通過一跳遍歷b1,三元組實例被寫入p6的結果集中,之后獲得節點e1,由于e1在結果集中不存在,因此將其做為下一次遍歷的初始節點。由于,三元組實例被寫入p6的結果集中。至此,p6的結果集便得到了。其他模式的模式匹配過程與p6相似。通過M-PM 算法,通過遍歷一次數據集便可得到所有模式圖的結果集。
將本文多模式匹配算法分別與基本多模式匹配算法、文獻[12]的多模式匹配算法以及文獻[16]多模式優化算法進行比較。其中,基本多模式匹配思想是將DTree 中父節點的匹配結果集做為其孩子節點的輸入的局部結果集,因此,它能夠很好地降低父節點與孩子節點之間重疊部分的計算。假設模式圖集大小為n,數據集數量(指三元組模式的數量)為m,基本多模式匹配的時間復雜度為。文獻[12]中多模式匹配算法(MPT),分為基本模式匹配和擴展模式匹配兩步,每次將基本模式的匹配結果集作為擴展模式匹配的輸入,因此仍然有一部分數據圖需要多次遍歷,時間復雜度為,且其每次都需要對中間結果進行保存,大大增加了空間復雜度,其空間復雜度為。而此多模式匹配算法不需要對中間結果進行保存。文獻[16]中多查詢優化算法(MQO),通過模式包含映射確定一個多模式匹配序列,匹配時多個父模式的匹配結果集作為子模式的匹配數據集,因此時間復雜度為同時需要對中間結果進行緩存,空間復雜度為。本文多模式匹配算法的時間復雜度為因此本文的多模式匹配效率高于其他三個多模式匹配算法。
4 實驗結果與分析
4.1 實驗設置
基本模式圖集。在選擇模式集時,基本模式圖之間的殘差圖是一個重要影響因素。在D-Tree 中,非葉節點的殘差圖與模式子圖重疊部分相關聯。D-Tree 的深度不斷增加,越靠近根節點的模式圖,匹配執行的次數越多。
數據集:實驗中,選擇一個仿真數據集。DBpedia 2015A描述了運動和運動事件的相關信息,它包含20個三元組模式的30 000多個RDF三元組實例。由于現有較大的真實數據集中三元組模式種類較少(如DBpedia、WikiData、YAGO),很難反映模式圖殘差邊數量對多模式匹配效率的影響,因此,對三元組模式圖進行了仿真擴展,用于提高三元組模式的維度,生成了一個基于DBpedia 2015A的仿真數據集,它包括300個三元組模式的300萬個RDF三元組實例。
為了得出多模式匹配與D-Tree深度、寬度以及殘差邊數量之間的關系,同時為了更準確的進行實驗,合成的數據集要符合現實世界中觀察到的一般特征,如模式、結構、大小、分布等。在生成仿真數據集時,首先采用文獻[17]中的方法對原始數據進行一定的擴展,為某些實例引入新的謂詞,增加三元組模式的個數,同時刪除某些三元組,這個過程生成了更加現實和復雜的數據集,增加了邊的多樣性,符合現實世界的現狀和特征。
其次,采用一個隨機生成器對上一步生成的數據集進行規模擴展。以數據圖節點數N和最終數據集大小S作為輸入,每次隨機選擇S/N個節點作為核心數據節點,對于每個核心數據節點v,選擇10~15 個與v距離為5 跳的節點,并且用邊將它們隨機連接起來,重復多次,直到達到需要的數據大小。
實驗配置:實驗環境為Intel Xeon 5118,擁有24 GB RAM。
4.2 實驗分析
在自己生成的仿真數據集上進行實驗,分析D-Tree具有不同深度、寬度以及深度改變時的多模式匹配效率。
圖6 描述具有相同深度不同寬度D-Tree 的執行時間,圖7 描述具有相同寬度不同深度D-Tree 的執行時間。根節點包含80 個三元組模式,并且每個孩子節點比其父親節點多10 條邊。隨著深度的增加,本文算法時間消耗與基本多模式匹配算法、MPT算法、MQO算法相比分別提高約70%、50%、30%的時間效率。由于子圖同構是一個NP 完全問題,其隨著數據的規模不斷增加呈現指數級的時間復雜度,因此,在圖6 和圖7 中,隨著深度和廣度的增加,三元組模式的數量也在不斷的增加。從線性的變化趨勢中,可以發現其近似于指數型的變化,然而,由于三元組模式圖的數量遠遠小于數據圖數量,因此,實驗線性的指數型變化不夠明顯。
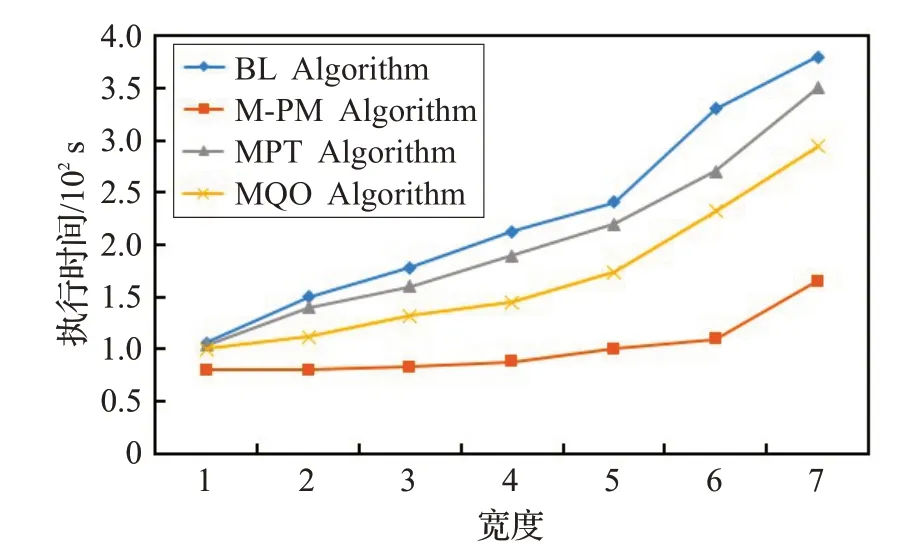
圖6 不同寬度D-Tree的執行時間
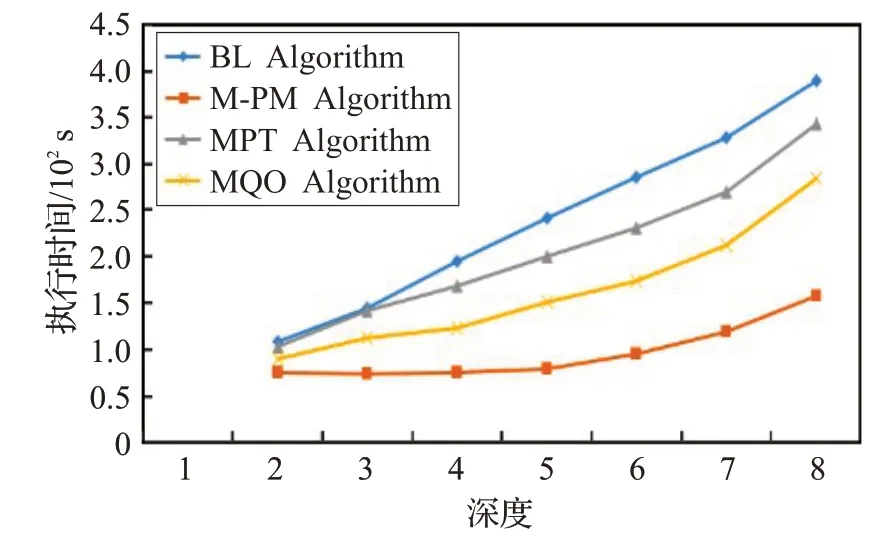
圖7 不同深度D-Tree的執行時間
從圖6和圖7綜合來看,當寬度和深度相同時,算法執行時間相同,因此算法的執行時間受深度和廣度的影響相似。
采用相同數量的三元組模式和殘差邊,改變殘差邊在D-Tree中不同深度位置,執行時間如圖8所示。隨著D-Tree深度改變,深度越深,模式間殘差邊越少,本文算法比其他多模式匹配算法波動小,更加穩定。而其他算法隨著深度的增加,執行的時間消耗呈現增大。因為,深度越高,公共部分的重復計算的次數越多,然而,其對本文算法的影響微乎其微。因此,本文算法僅與殘差邊的數量有關。
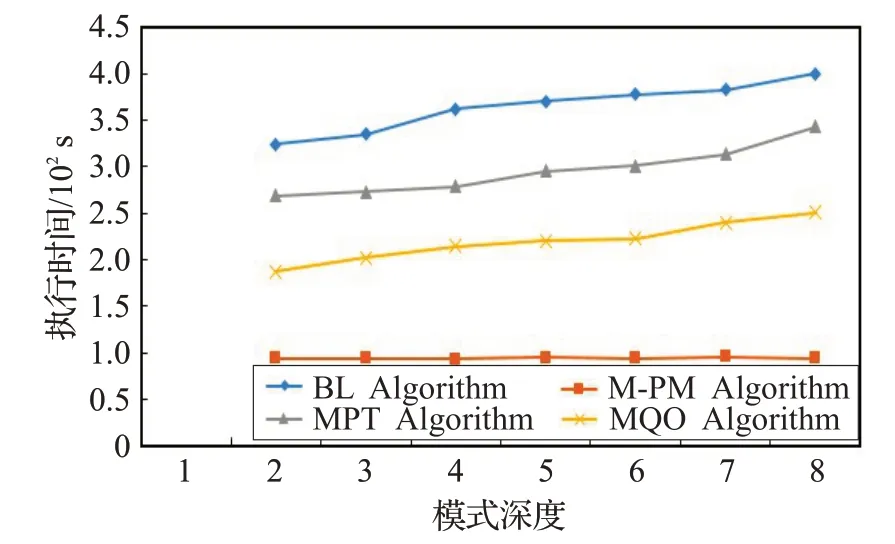
圖8 模式圖深度改變的執行時間
為增加實驗的真實性和可靠性,在仿真數據集Wet-Div 上進行對比實驗,如圖9 所示。WatDiv 是一個關于電子商務的合成數據集,包括購買產品并撰寫評論的用戶,以及提供產品的零售商等。本文采用擴展因子為30,生成有300萬個RDF三元組的數據集。
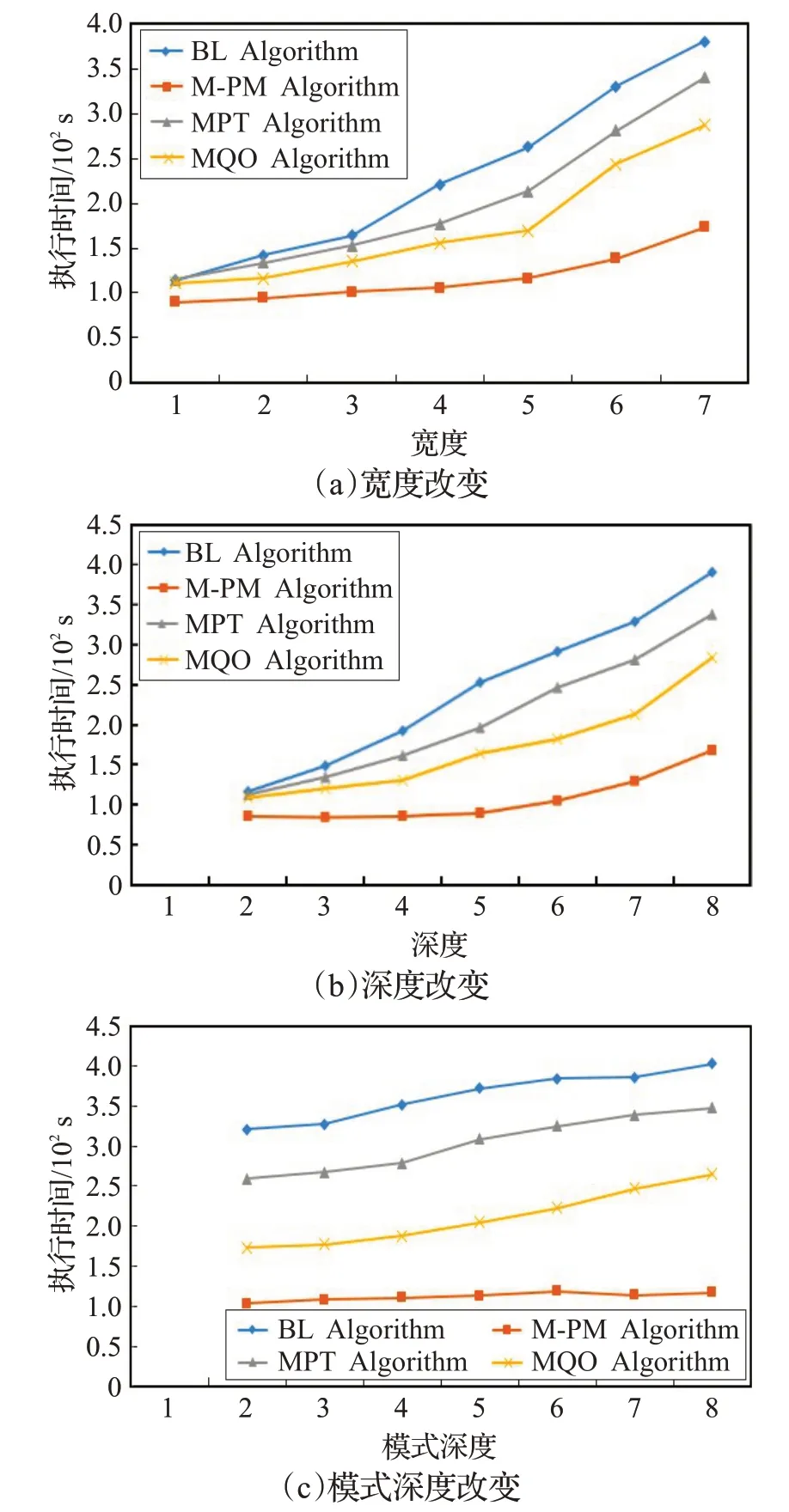
圖9 仿真數據集WatDiv實驗
為增加實驗的真實性和可靠性,同樣在真實數據集YAGO上進行對比實驗(如圖10),采用的數據集中包含900多萬個三元組模式。
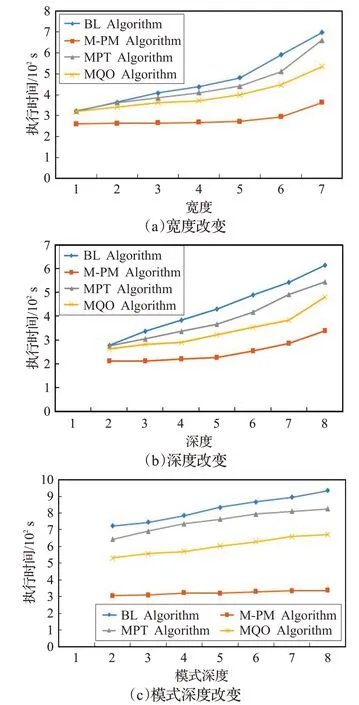
圖10 真實數據集YAGO實驗
由圖9、10 在仿真數據集WatDiv 以及真實數據集YAGO上的實驗可以看出,在仿真和真實數據集上本文算法同樣優于其他算法,且算法時間復雜度只與殘差邊的多少有關,與D-Tree的深度、寬度無關,當深度改變時本文算法更加穩定。
5 結束語
本文提出了一種面向RDF 圖的多模式匹配方法。為了表示模式間的依賴關系,減少重復計算,它構建了樹形索引結構(依賴樹),制定了模式間的執行序列。同時利用節點分片表,表示節點間的執行序列,根據節點序和模式序進行多模式匹配,進一步減少了重復計算,而且能在很大程度上提高模式匹配的效率。盡管此種算法很大的優點,但仍有許多可改進之處,故在今后的研究中會對此算法進行進一步的優化并增加真實數據的實驗評估。
