基于Fat-Tree的虛擬分片負載均衡算法
2020-07-06 13:34:52趙阿群趙晨輝
計算機工程與應用 2020年13期
王 莉,趙阿群 ,2,趙晨輝
1.北京交通大學 計算機與信息技術學院,北京 100044
2.東南大學 計算機網絡和信息集成教育部重點實驗室,南京 211189
1 引言
在現代互聯網應用和云計算技術的推動下,數據中心正在全球范圍內得到極大的發展。數據中心由大量服務器和交換機組成,這些服務器和交換機連接在一起形成數據中心網絡(DCN)。目前,數據中心已成為許多企業提供各種服務的關鍵基礎設施,許多應用程序都已托管在數據中心內,因此數據中心在數據傳輸方面的要求越來越高。
為了獲得高帶寬并實現容錯,數據中心網絡(DCN)通常在任意兩臺服務器之間設計有多條路徑[1-3]。多條路徑不僅可用于處理潛在的故障,還可用于提高網絡性能。特別是,當網絡的流量負載變大時,可以使用多條路徑來降低延遲并有效提高吞吐量。因此,平衡數據中心網絡上的工作負載,實現多路徑的有效使用,提高吞吐量以及減少流完成時間對于提高數據中心網絡的整體性能來說是非常重要的。
2 研究背景
目前,在工業界應用最廣泛的數據中心網絡拓撲是以交換機為中心的三層級聯的多根樹拓撲架構,稱為Fat-tree結構[4]。它具有簡單易部署等優點,同時該拓撲使得任意兩臺服務器間存在多路徑,數據包進行通信時若一個結點癱瘓底層結點還可以通過其他路徑進行轉發,具有很好的容錯性。Fat-tree 網絡拓撲結構分為三層,分別為核心層、聚合層及邊緣層,所有的服務器與邊緣層的交換機相連。如圖1為4-port胖樹模型。
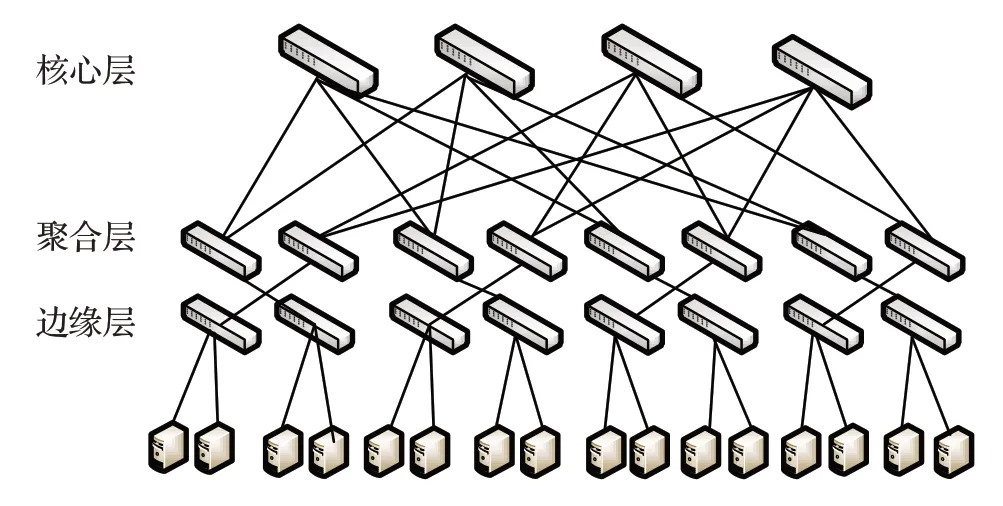
圖1 4-port胖樹網絡拓撲
一般來說,數據中心的流量可以分為兩種類型:大流,它們攜帶大量數據并且存在時間較長;小流,通常是對延遲敏感的流,它們數量很多但攜帶的數據量較少[5]。由于大流將占用大量網絡資源,因此如果沒有合理的進行大流調度,數據中心網絡可能會發生擁塞,目前已經提出了許多解決方案來調度大流[2,6-7]。
傳統的負載均衡算法是等價多路徑路由算法(ECMP)[5,8]。ECMP 易于實施,不需要在交換機上進行流量統計。然而,ECMP 還存在兩個缺點[9-10]:首先,ECMP不區分小流和大流。因此,經常發現小流排在出口端口的隊列中,遭受長排隊延遲從而影響流完成時間(FCT)[10-11]。其次,由于哈希沖突,ECMP 無法有效利用可用帶寬,從而導致“大流碰撞”的問題[12-13]。除了ECMP之外,還提出了許多其他解決方案。Hedera是利用控制器收集從數據平面交換機的流量統計信息,采用啟發式的算法對大象流進行路由[4]。SD-LB是根據網絡鏈路狀態對多路徑進行動態加權,并結合交換機中的組表信息對大象流進行分配路徑,從而緩解大象流造成的網絡擁塞[14]。Fincher是收集全網信息形成流與交換機的偏好列表,從而對所有的流分配較合適的路徑[15]。TinyFlow是將大流切分成多個小流,從而減少大流對鏈路的負載[7]。CONGA 利用了分布式技術來感知網絡狀況,依賴邊緣路由器來對網絡鏈路狀況進行擁塞探測及負載調度[16]。這些解決方案相較于ECMP 都可以提高網絡的性能,但還存在一些問題。例如Hedrea、SD-LB、Fincher在進行流處理時都需要交換機做一些額外的操作,影響交換機的轉發效率。TinyFlow等將大流切分成小流的方法則會導致數據包的重組問題,從而導致更多的開銷。CONGA則對交換機的要求過高,并且也對邊緣交換機的負載過大,不利于部署。
負載均衡算法的設計對數據中心網絡的性能有著重要影響。另一方面,隨著網絡規模和帶寬需求的增加,數據中心網絡的成本和功耗迅速增長,對于整個數據中心網絡的整體性能也會有較大影響。傳統的數據中心網絡使用的是基于交換機轉發的方式,交換機需要參與到數據包的轉發決策中,因此交換機中需要存儲并維護轉發表。文獻[17]提出了一種基于端口編址的DCN 體系架構。不同于傳統的轉發方式,該方法不需要交換機每次查表進行分組轉發。數據包在發送時就記錄了轉發路徑的所有端口號序列(PA),端口號序列是由控制平面在數據包生成時就已經計算得出。因此交換設備不需要做任何的處理,讓交換設備只專注于基于端口的轉發數據,而不用判斷任何的狀態信息,完全契合了未來網絡“胖終端,瘦網絡”的思想[17],實現了交換機“啞交換”,大大提高了轉發效率。
結合以上,本文提出了一種基于Fat-Tree 的虛擬分片負載均衡方法(Virtual Slice Load Balance,VSLB)。該方法利用基于端口編址的轉發方式,并且將大流分為多個子流,為了解決包排序的問題,本文根據文獻[8]TSO 原理將小流的上限定為64 KB,并為這些小流分別選取更優的路徑進行轉發,從而解決了大流碰撞的問題。
3 整體設計
本章主要從整體上來介紹VSLB的設計。如圖2為VSLB概述圖。
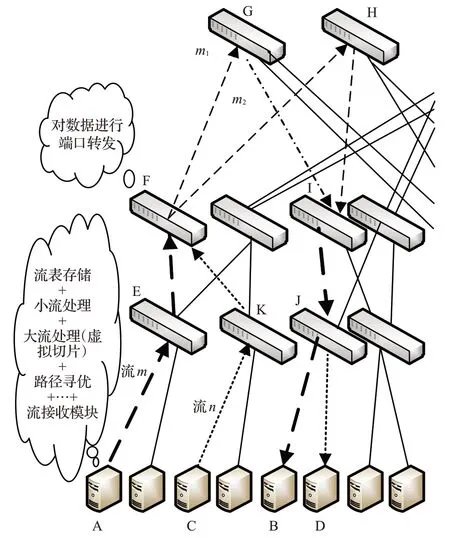
圖2 VSLB整體概述圖
圖2 為4-port Fat-Tree 的半結構圖,服務器A 向服務器B發送數據流m,服務器C向服務器D發送數據流n,假設m和n均為大流,流m沿著路徑A→E→F→G→I→J→B 發送,流n沿著 C→K→F→G→I→J→D 發送,顯然m和n在F→G→I→J鏈路發生了重合,如果兩條大流在同一時間到達,這樣就會產生“大流碰撞”的問題。本文提出的VSLB的思想是把大流進行分片處理,拆分出多個小流。如圖中所示,子流m1沿著原路徑發送,而子流m2沿著A→E→F→H→I→J→B 發送,同理流n也進行同樣的子流選路處理。在5.2節中本文還提出了基于端口編址的全路徑計算和路徑尋優的方法,確保所選路徑為網路中最優的路徑。
從圖2 還可以看出,VSLB 的幾乎所有的部署都在在服務器端,這樣就可以大大減少交換機的負載,交換機只需要進行流數據的轉發即可,從而提高整個網絡性能。
4 負載均衡設計
4.1 存儲表的設計
為了更好地對大流和小流進行決策,需要在服務器終端上部署和維護三種存儲表。三種表分別為小流輪詢表RR_M、大流輪詢表RR_E 和總的流記錄表Flow_All。其中,RR_M 的作用是維護小流的發送路徑;RR_E記錄了該大流的所有可能發送路徑,發送路徑是根據全路徑計算模塊來進行計算,并且會根據路徑探測包的探測結果對路徑做優先級的排序。全路徑計算及路徑尋優將會在下文5.2.1小節和5.2.2小節中詳細介紹;Flow_All是記錄所有經過本服務器終端出去的消息流,以便更好地維護RR_M和RR_E。
4.2 VLSB的設計
VSLB 設計部署在服務器端,本節將從單個服務器的角度進行介紹,具體詳細步驟如下:
(1)當一個流達到時,由于流是由多個數據包組成,因此每個數據包到達時,首先由包處理模塊對數據包進行包到流的映射(這里是通過Hash 來實現),得到流的“名字”,然后根據總的流存儲表Flow_All判斷該流是否存在,如果存在進入步驟(2),否則進入步驟(3)。
(2)從Flow_All 取出該流并更新此流的大小,接著判斷此時流大小是否大于64 KB,如果大于則此流被判定為“大流”,調用大流處理模塊進行處理。若小于64 KB,則此流被判定為“小流”,根據小流輪詢表取出該流的PA值,同時更新總的流記錄表,進入步驟(4)。
(3)若總的流記錄表Flow_All 中不存在該流的記錄,則判定此流為一個新流并按小流處理,調用小流處理模塊中的流初始化模塊進行處理,本文將在4.1 節中詳細介紹小流處理模塊,然后進入步驟(4)
(4)無論是進行大流處理還是小流處理,結果都會返回一串PA值,接著調用消息發送模塊,即利用服務器的發送機制進行數據包的轉發。
5 流處理模塊
上章介紹了VSLB的整體設計架構,本章主要介紹流處理模塊。流處理模塊可以拆分為分為大流處理模塊(包括全路徑計算和路徑尋優)和小流處理模塊(流初始化和地址輪詢)。這樣拆分既實現了整體方法的解耦和,并且在一定程度上提高了VSLB整體的性能。
5.1 小流處理
在一個流沒有被判定為大流之前這個流都按小流來處理。當一條流到達時,根據RR_M表來判斷此流是否存在,如果不存在則調用流初始化模塊進行初始化;若存在且此流為小流則調用地址輪詢模塊對此小流分配新的發送路徑。
5.1.1流初始化
在進行流初始化時,首先需要判斷源服務器和目的服務器是否在同一個子網內(連接同一個邊緣交換機)或者是否在同一個pod 內。表1 是針對以上不同情況RR_M 表存儲的PA值,其中RR代表 RR_M 中的實體項,x代表邊緣層交換機的上行端口,y代表聚合層交換機的上行端口,x,y∈[k/2,k-1],k值是由DCN的端口值決定。

表1 RR_M流初始化取值表
5.1.2地址輪詢
5.1.1 小節中介紹了小流初始化。如果一條流達到時,且經過驗證此流為小流,則需要對此流進行重路由,這里采用ECMP的思想來對端口進行輪詢,即讓不同的流沿著不用的路徑發送,需要對此流計算新的PA 值。計算新的PA值要根據源PA值進行判斷,表2為針對不同情況計算出的新的PA值。
如表2,分為四種情況,如果源服務器與目的服務器在同一子網,則PA為原PA值;如果在同一pod 中,則需要對對邊緣交換機的上行端口進行輪詢;如果在不同pod,則根據聚合層交換機的上行端口號是否為邊界值分兩種情況進行端口的輪詢操作。
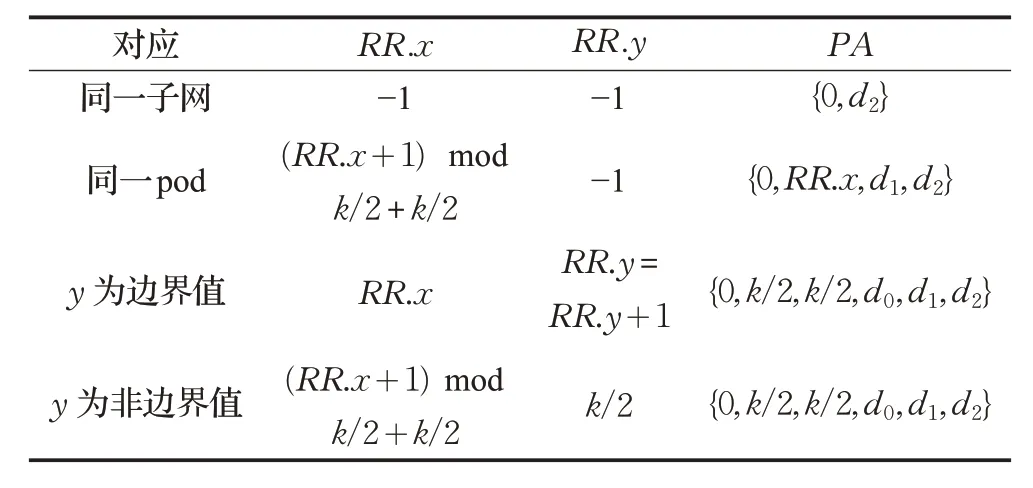
表2 RR_M地址輪詢取值表
5.2 大流處理
大流處理作為整個負載均衡算法的核心部分,不僅包含將大流拆分成多個小流,更重要的是對流做全路徑計算和路徑尋優。當一條大流達到時,按每個小流最大64 KB 來切分成多個小流并對每個小流分配最優的轉發路徑。其中路徑尋優算法采用“動態規劃”的思想,保證所選路徑能夠在有效時間內為最優的路徑。
5.2.1全路徑計算
大流處理過程中,路徑尋優模塊需要對多路徑進行路徑擁塞程度探測,因此首先要先得到這些可能的發送路徑并存儲到大流輪詢表中RR_E 中。為了快速的計算出所有的路徑,本文提出了一種全路徑的計算算法,如算法1。
算法1 全路徑計算算法
輸入:source locator and destination locator
輸出:the path array P of from source to destination
1. ifs0=d0then
2. ifs1=d1then
3.p[0]←{0,d2}
4. else
5. fori=k/2 →kdo
6.p[i-k/2]={0,i,d1,d2}
7. end if
8. else
9.index←0
10. fori=k/2 →kdo
11. forj=k/2 →kdo
12.p[index+ +]←{0,i,j,d0,d1,d2}
13. end if
14. returnp
如算法1所示,當“源”服務器和“目的”服務器在同一個子網時,路徑是唯一確定的。當不在一個子網內時,所求路徑會根據數據中心網絡的交換機端口個數k動態計算。
5.2.2 路徑尋優
路徑尋優算法采用了“消息反饋”機制,對所有可能發送的路徑進行探測處理,然后對所有反饋的探測包的往返時延進行排序處理。在這里排序策略采用的是“大頂堆”的堆排序的思想,當交換機端口數量k大到一定程度時,使用堆排序可以更好地提高排序性能。此外,大流切分為多個子流的數量要遠小于全路徑的數量,因此使用堆排序的思想還可以根據不同的交換機端口數靈活的設置“大頂堆”的節點數。具體的路徑尋優算法如算法2。
算法2 路徑尋優算法
輸入:source locator,destination locator and path arrayp
輸出:the new path arrayPof from source to destination after sort
1. ifs0=d0then
2. ifs1=d1then
3.probePath[0]←{0,d2}
4. else
5. fori=k/2 →kdo
6.probePath[i-k/2]←{0,i,d1,i,s1,s2}
7. end if
8. else
9.index←0
10. else
11. fori=k/2 →kdo
12. forj=k/2 →kdo
13.probePath[index+ +]←{0,i,j,d0,d1,i,j,s0,s1,s2}
14. end if
15. Send allprobePacketwithprobePath
16. Collect all RTT and sortpwith RTTs
17. returnp
6 仿真實驗及分析
6.1 仿真環境及評價指標
本文在OMNET++軟件上進行實驗的仿真。OMNET++是一款強大的網絡仿真工具,利用它可以構建包括交換機、鏈路和主機在內的數據中心網絡[18]。本文實驗搭建的網絡環境為16-port的Fat-tree數據中心網絡,共包含了1 024臺服務器與320臺交換機,其中交換機包括了64 臺核心交換機;128 臺匯聚層交換機及128臺邊緣交換機。整個Fat-tree網絡拓撲包含了16個pod,每一個pod包含了8臺匯聚層交換機;8臺邊緣層交換機和64 臺服務器。本文提出的VSLB 算法將與基于端口編址的ECMP(Port-Base ECMP、PB-ECMP)與基于端口編址的CONGA(Port-Base CONGA、PB-CONGA)方法進行對比,仿真結果將從平均吞吐量、小流的平均流完成時間和平均端到端時延三個方面進行評估。具體計算如下:
(1)平均吞吐量
采用單個可用服務器多次仿真的平均吞吐量。假設仿真時可用服務器為n個,進行了m次的仿真,則平均吞吐量的計算公式如公式(1)所示:

其中ATj為第j次仿真的平均吞吐量,ATj的計算如公式(2)所示:

其中Ti為第i個服務器的吞吐量,通過統計平均吞吐量,由此作為評價網絡性能的一項指標。平均吞吐量越大,說明數據中心網絡的整體性能越好,進而說明負載均衡方法越高效。
(2)小流完成時間(Flow Complete Time)
小流FCT值取多個服務器的多個小流的平均值,假設仿真時可用服務器為n個,第i(1 ≤i≤n)個服務器在一次仿真中接收了s條小流數據,共進行了m次仿真,則FCT的計算公式如公式(3)所示:

其中tj為第j此仿真的平均流完成時間,tj的計算如公式(4)所示:

其中tk為第k個小流的流完成的時間,小流的FCT 作為評估數據中心網絡的性能指標,如果負載均衡方法沒有很好地解決大流碰撞問題,則大流造成的網絡阻塞問題同時會影響小流的傳輸性能,故當FCT 值越小,負載均衡方法越好。
(3)平均端到端時延(End-to-end Delay)
數據中心網絡在一定周期內會產生很多的數據流,而從網絡層看來,這些都是大量的數據包,平均端到端時延就是計算數據包發送時延的平均值,假設可用服務器依然為n個,做m次仿真,第i臺服務器接收的數據包為s個,則:

其中τj為第j此仿真的平均時延,τj的計算如公式(6)所示:

其中ti為第i臺服務器的平均時延,ti的計算如公式(7)所示:

大量的數據包如果遇到了大流碰撞引起的鏈路帶寬問題,會產生長時間的阻塞,所以當平均端到端時延越小,則說明負載均衡的效果越好。
6.2 實驗參數設置
由于目前很難獲得實際可用的數據中心網絡的trace數據集,本文參考文獻[19]的思想,通過模擬多種通訊模式的方式來模擬實際的數據中心網絡。通訊模式主要分為兩大類,分別是One_To_One和Multi_To_Multi 模式,其中這兩類又分別包含了Stride、incoming、outgoing、Random 模式。具體模式如下,其中服務器位置標識為(s0,s1,s2),s0(s0∈[0,k-1])代表該服務器所在的pod 編號,s1(s1∈[0,k/2-1])代表該服務器所在pod 中與其相連的邊緣交換機的編號,s2(s2∈[0,k/2-1])代表該服務器是邊緣交換機連接的第幾個服務器,k代表該數據中心網絡的交換機端口數。
(1)One_To_One通信模式
Stride:每臺服務器(s0,s1,s2)向服務器((s0+1)modk,s1,s2)進行通信。
Same-pod incoming:多個 pod 的任意k24 臺服務器向集中向一個pod 中的k24 臺服務器進行隨機的一對一通信。
Same-pod outgoing:一個 pod 中的k24 臺服務器隨機的向其他任意pod 中的k24 臺服務器進行一對一通信。
Random:整個拓撲中k34 臺服務器隨機挑選一個服務器對象進行一對一通信。
(2)Multi_To_Multi通信模式
Stride:每臺服務器(s0,s1,s2)向pod((s0+1)modk)中的k24 臺服務器分別進行通信。
Same-pod incoming:多個 pod 的任意k24 臺服務器分別向一個pod中的k24 臺服務器進行通信。
Same-pod outgoing:一個pod中的k24 臺服務器分別向其他任意pod中的k24 臺服務器進行通信。
Random:整個拓撲中k34 臺服務器分別向其他k34 臺服務器進行通信。
具體模式參數設置如下:
(1)One_To_One通信模式下,鏈路寬帶和時延初始化值分別設置為1 024 Mb/s和0.05 μs,單周期內任意服務器隨機產生的大流和小流的個數比為1∶4,大流與小流總的大小比為4∶1,從而保證了大流始終占有80%左右的帶寬。每個周期的時間根據隨機產生的流的個數和大小而發生變動,仿真次數設定在10~20次。
(2)Multi_To_Multi模式下,服務器和邊緣交換機之間的鏈路帶寬初始初始化值設置為16 Mb/s,其他參數同One_To_One模式,為了實現流量突發性,參照實際數據中心網路,仿真過程中隨機產生同一個服務器發往不同目的服務器的時間差值。
6.3 實驗結果分析
(1)One_To_One
圖 3、圖 4 和圖 5 為 One_To_One 模式下,VSLB 和PB-ECMP 和PB-CONGA 在不同指標值下的實驗結果對比圖。
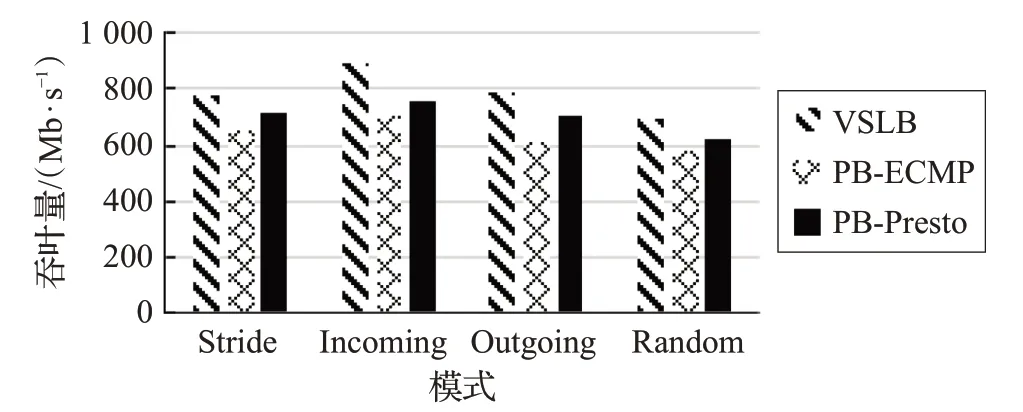
圖3 One_To_One平均吞吐量對比圖
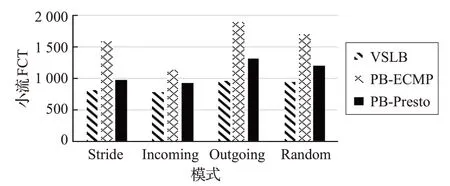
圖4 One_To_One小流FCT對比圖

圖5 One_To_One端到端時延對比圖
根據圖3、圖4、圖5 可以看出,不論是在Stride、Incoming、Outgoing,還是在 Random 模式下。VSLB 在吞吐量、小流完成時間及時延方面均優于PB-ECMP 和PB-CONGA。這是由于VSLB 對大流進行了“細粒度”的劃分處理,并且還通過路徑尋優的策略大大減少了大流碰撞的概率。相比于CONGA,VSLB 不需要總是接受鏈路的反饋包,只有在進行大流處理時,才需要進行鏈路探測,因此交換機不需要解析數據包來維護轉發表。另一方面VSLB中利用了端口編址的方法,使得交換機不需要參與轉發決策,只進行包轉發操作即可,大大加快了數據包的轉發效率。因此VSLB 在性能上都優于PB-ECMP與PB-CONGA。
(2)Multi_To_Multi模式
圖6、圖7和圖8為Multi_To_Multi模式下,VSLB和PB-ECMP在不同指標值下的實驗結果對比圖。
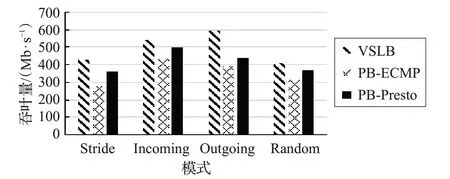
圖6 Multi_To_Multi平均吞吐量對比圖
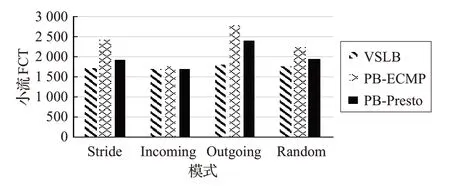
圖7 Multi_To_Multi小流FCT對比圖

圖8 Multi_To_Multi端到端時延對比圖
根據圖6、圖 7、圖 8 可以看出,在Multi_To_Multi 模式下,四種子模式的各個結果都與One_To_One 模式有所差別。這是因為在Multi_To_Multi模式下,每臺服務器都會以一對多的方式發送數據,因此會有更多的流碰撞現象發生。但從以上圖中可以看出,VSLB的性能也明顯優于PB-ECMP和PB-CONGA。
7 總結
本文針對“大流碰撞”提出了一種基于Fat-Tree的虛擬分片負載均衡算法。通過對大流進行“細粒度”的分片處理,并對切片后的子流進行路徑尋優處理,大大降低了“大流碰撞”的概率。通過實驗對比,驗證了VSLB相比于ECMP 與CONGA 能夠大大提升數據中心網絡性能。
隨著研究的逐漸深入,發現還有許多工作值得后續的關注和研究。由于本文所提出的負載均衡方法更偏向于對大流的處理,因此小流處理部分相對比較簡單,未來的工作將針對小流處理模塊提出更好的解決方法。
