基于電子病歷系統的腦血管病專科大數據科研平臺設計與應用
2020-07-07 06:06:58林琳王韜甘偉邢玉龍
中國卒中雜志 2020年6期
關鍵詞:模型
林琳,王韜,甘偉,邢玉龍
作者單位
1100070 北京首都醫科大學附屬北京天壇醫院信息中心
2北京嘉和海森健康科技有限公司
近年來,腦血管病已成為我國致死率最高的慢性非傳染性疾病之一,對人民健康和社會經濟造成了巨大危害[1]。與此同時,優質醫療資源總量的不足及其在地區間分布的不平衡,也加劇了醫療服務供給與腦血管病患者需求間的矛盾。為緩解腦血管病醫療資源及診療技術水平發展的不均衡,提升對腦血管疑難病、急危重癥患者的救治能力,首都醫科大學附屬北京天壇醫院秉承《“健康中國2030”規劃綱要》中關于腦血管病防控的精神,基于在神經系統疾病方面的臨床積累和科研發展,探索了以腦血管病專科大數據科研平臺為支撐,通過臨床-科研一體化模式提升醫院腦血管病臨床診療水平和科研能力的新思路、新方法,也為推進區域內醫療衛生協同發展、帶動區域整體醫療水平提升提供了重要參考。
腦血管病專科大數據科研平臺是以大數據及人工智能技術為依托,通過對院內業務系統海量臨床數據以及院外診療信息的采集、整理、分析、挖掘,為科研人員提供真實可靠的數據資源和高效便捷的科研工具,提升科研效率和質量,并通過成果轉化輔助臨床決策、改善診療水平。
1 腦血管病專科大數據科研平臺架構
腦血管病專科大數據科研平臺主要包括數據采集層、數據治理層、數據模型層和數據服務層。平臺采用大數據架構,基于Hadoop集群以及相關大數據技術,從臨床業務系統、實驗室信息系統、生物樣本庫以及院外隨訪、電子數據獲取系統(electronic data capture system,EDC)中采集各類疾病相關數據,集成、整合后形成科研數據中心;再利用深度學習技術挖掘數據特征,構建多種數據模型;最后,結合大數據處理引擎,提供數據檢索與挖掘、數據可視化、數據質量監測、臨床決策輔助等數據應用服務,支持醫院腦血管病臨床研究及診療協作。具體如圖1所示。
1.1 數據采集層 通過提取-轉化-下載(extract-transform-load)工具從醫院數據中心及外部EDC系統等抽取、集成患者診療相關數據,包括電子病歷、檢驗報告、隨訪、基因檢測等。通過對患者就診過程的追蹤和信息積累,可很好地解決數據稀疏、偏倚等問題,可使數據更加可靠、及時、公正,排除數據分析可能造成的偏差[2]。
1.2 數據治理層 由于原始數據量大且形式多樣、結構各異,為正確獲取數據價值,還需對采集的數據做進一步治理,包括:數據清洗、量化、自然語言處理及質量控制等,使業務數據變為可直接利用的標準化數據集,即科研數據中心的數據。
1.3 數據模型層 在科研數據中心基礎上,利用深度學習技術,建立不同維度的數據分析模型,包括:疾病模型、癥狀模型等基礎模型;知識圖譜、時間序列等融合模型;診斷推薦、治療方案推薦等深度挖掘模型。通過對不同數據間深層次關聯關系的分析,為后續的數據服務提供支撐。
1.4 數據服務層 利用上述數據模型,平臺搭建了一系列大數據引擎,如:科研知識轉化引擎、搜索引擎、數據挖掘引擎、可視化引擎等,最終實現一體化科研服務和臨床決策支持、疾病預后智能預測、科研知識庫以及真實世界研究等功能應用,提高科研效率和質量的同時,也提升了臨床醫師的決策精準度。
2 腦血管病專科大數據科研平臺的主要功能
2.1 一體化科研服務 所謂“一體化科研服務”,即指臨床醫師可通過平臺一站式完成從問題挖掘、病歷招募,到數據挖掘和統計分析的全流程科研工作(圖2)。
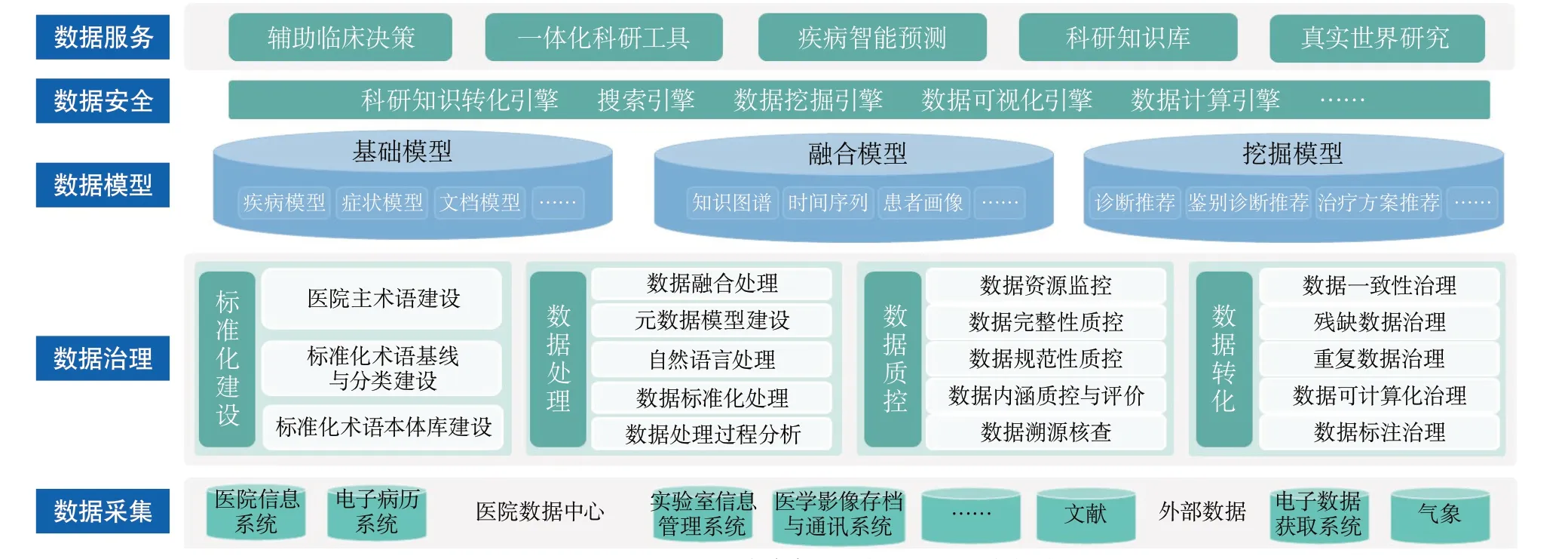
圖1 腦血管病專科大數據科研平臺架構

圖2 一體化科研服務流程示意圖
問題挖掘:即基于選定的科研變量,自動進行多維度統計統計,如:患者分布、疾病分布、癥狀詞云等,幫助醫師更好地聚焦科研問題。
病例招募:平臺可提供基于全樣本的病例篩選服務,幫助醫師快速建立專病庫,并支持數據精確檢索、全文檢索以及外部數據導入等。
數據質控:針對可能存在的數據缺失、異常值等現象,平臺支持對數據進行完整性、規范性等檢測;對質量較差的數據,針對不同問題分門別類,給出數據質控報告,使數據問題透明化;同時,還可支持數據溯源原始病歷,通過問題反饋促進醫師病歷書寫質量提升。
數據處理:在數據進入統計模型之前,可利用平臺自動進行量化和智能轉化;同時對于質控發現的問題數據,可通過數據填補、自定義變量等進行有效治理,保證數據的準確性及可靠性。
統計建模:完善的統計學分析工具和靈活的自定義統計模式對于科研人員非常重要[3]。為此,平臺基于R語言,集成了多種醫學統計模型,操作者可自由定義分析的變量以及分析模式,導出不同形式的統計分析圖表,直觀地發現數據所體現出來的研究價值。
2.2 疾病預后智能預測 研究者通過疾病數據進行影響因素分析、主成分分析、決策樹挖掘等,從中提取出重點疾病特征,繼而利用深度學習技術進行模型訓練,搭建出疾病智能預測引擎。當臨床診療過程中觸發該規則時,即可實時提醒醫師疾病發展進程中出現復發、死亡、傷殘或并發癥等的概率,從而指導臨床治療,提高決策水平。
2.3 科研知識庫 平臺通過數據挖掘產生的知識模型,如本體庫、語義網絡規則語言(semantic web rule language)以及疾病推理機制等,經過沉淀形成科研知識庫,將進一步輔助臨床,對于優化疾病診療標準、提升診療服務效率和縮短醫師學習曲線等都具有重要意義[4]。
2.4 臨床決策支持 科研的最終目的是回歸臨床、指導實踐。通過對大數據的挖掘、分析,如:相似病例分析、治療有效性分析、疾病相關性分析等[5],可以對臨床診治的療效、并發癥等給予循證醫學的證據支持,從而指導臨床實踐,提高醫療質量。
2.5 真實世界研究 真實世界研究是指在臨床真實條件與現實環境下,基于較大樣本量(覆蓋具有代表性的更廣大受試者),比較和選擇不同醫療手段的過程及其結局研究。由于其樣本數據量較大,單純依靠手工處理不僅費時費力,質量也難以保證。大數據科研平臺對于海量數據的采集、處理、分析優勢,使其成為真實世界研究的有力助手。
3 腦血管病專科大數據科研平臺應用成效
首都醫科大學附屬北京天壇醫院神經腦血管病專科大數據科研平臺自2017年正式部署上線后,應用效果良好。以疾病預測為例,科研人員在日常急診接診過程中,持續積累了2012年5月-2019年6月完成前循環腦梗死急診取栓手術的患者共379例,利用患者ID號經平臺查詢后,抽取其相關數據,并進行標準化和融合處理,建成“前循環腦梗死急診取栓專病數據庫”。在此基礎上,利用平臺的智能特征篩選功能,選出包括收縮壓、心房顫動、高血糖、腦梗死體積、尿蛋白陽性在內的5個有顯著意義變量;再自動匹配多因素Logistic回歸模型及ROC曲線,形成取栓后顱內出血發生風險預測模型(Logit=2.172+0.341×收縮壓+1.623×心房顫動+1.120×高血糖+1.856×腦梗死面積+0.677×尿蛋白陽性)。結果顯示,該模型ROC曲線下面積為0.749,靈敏度為0.751,特異度為0.820,具有較好的預測效能。
4 總結
隨著科學技術的發展和循證醫學理念的不斷加深,如何通過高質量的臨床研究,有效進行疾病病因和預防因素的探索,并將療效和安全性更好的干預措施盡快轉化至臨床,成為臨床研究人員面臨的主要問題[6]。
基于此,首都醫科大學附屬北京天壇醫院在醫院數據中心基礎上建立了腦血管病專科大數據科研平臺。該平臺打破了傳統以單個科室、單個項目獨立建設為主的應用模式,形成統一、開放的全新科研體系,不但加快了全院數據的共享、利用,也實現了靈活、自定義的臨床科研一體化科研流程,減輕了科研人員的工作負擔,提高了數據錄入的便利性及利用效率,對提高科研及臨床水平都具有重要意義,同時也為推動區域內醫療服務質量的提升起到示范作用。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
