基于滑動語義串匹配(SMOSS)的漢語詞義消歧
2020-07-13 04:33:44黃德根
小型微型計算機系統 2020年7期
王 偉,黃德根
(大連理工大學 電信學部 計算機科學與技術學院,遼寧 大連 116033)
1 引 言
詞義消歧(WSD)是自然語言處理領域中的一個難點問題[1,2],至今仍沒得到很好解決.現在自然語言處理研究已經深入到語義分析層次,因此對于詞義消歧技術需求也就更加強烈.隨著詞義消歧研究不斷深入,研究人員提出了很多方法以提高性能,包括采用一些深度學習的方法.Dayu Yuan等人[3]采用LSTM模型的詞義消歧取得了較好效果.Alessandro Raganato等人[4]定制了從LSTM到編解碼模型一系列的神經結構并在多語種上取得好的效果.楊安等人[5]提出利用無標注文本構建的詞向量模型結合特定領域的關鍵詞信息的詞義消歧方法.Xue-Ren Sun等人[6]提出將原始詞義消歧問題轉換為文本分類問題后使用LSTM進行文本分類的消歧方法.Minh Le等人[7]對Dayu Yuan等人[3]的LSTM詞義消歧方法進行深入研究并分析優缺點.李國佳等人[8]提出在詞向量表示基礎上通過獲得多義詞的上下文窗口向量的詞義消歧方法.呂曉偉和章露露[9]提出利用向量表示的上下文和義項信息,通過融合語義相似度和義項分布頻率的詞義消歧方法.孟禹光等人[10]提出一種加入詞性特征的語境向量模型的詞義消歧方法.羅曜儒和李智[11]采用基于Bi-LSTM的語義向量表示歧義詞語義信息,在生物醫學文本中取得較好的消歧效果.此外,研究人員也提出了其他一些有特點的多種方法以提高性能.鹿文鵬和黃河燕[12]提出把歧義詞所在的句子先經過句法分析后對依存約束集合進行適配的詞義消歧方法.楊陟卓和黃河燕提出了采用語言模型優化傳統有監督消歧模型的方法[13].楊陟卓[14]提出把同一篇文章中的含相同歧義詞的句子作為歧義句的上下文語境進行消歧的方法.閆蓉和高光來[15]提出依據詞性自動調整消歧上下文邊界大小的消歧方法.ZHANG Chun-xiang等人[16]使用語義和句法信息提高了消歧性能.楊陟卓[17]通過假設歧義詞的上下文的譯文所組成的語境與原上下文語境所表述的意義相似,提出一種基于上下文翻譯的消歧方法.史兆鵬等人[18]提出利用依存句法分析提取上下文的多義詞及義項的多種特征的詞義消歧方法.WANG Xin-da等人[19]提出利用同義詞詞典選取替代詞代替目標詞,通過模擬人的語義推理過程的詞義消歧方法.Devendra Singh Chaplot等人[20]使用主題模型突破了通常詞義消歧只能在一個句子或一定窗口寬度的范圍內進行的限制,實現了把整個文檔作為上下文并以線性速度運行的詞義消歧.
本文提出了基于滑動語義串匹配的詞義消歧模型.主要特點:1)使用詞的語義碼特征建立語義模板,解決傳統詞模板因模板長度增加而導致數據稀疏的問題,而且語義模板長度可以做到更長;2)采用彈性語義層級匹配策略,相對一些只選定固定語義層級匹配的方法,增加了匹配成功率;3)采用對多個匹配成功模板的得分計算,解決了武斷選擇某個單一匹配結果所導致的錯誤率高的問題.
2 模 型
基于滑動語義串匹配(Sliding Match of Semantic String,SMOSS)的詞義消歧,主要包括兩部分:一是建立N元語義模板庫,二是基于滑動語義串匹配的詞義消歧.
2.1 采用《同義詞詞林》分類標準
一般來說,詞義消歧都是依據不同的語義分類詞典進行的,比如《知網》(HowNet)、《同義詞詞林》和《現代漢語語法信息詞典》等.本文選用哈工大研制的《同義詞詞林》擴展版,其編碼體系共有12個大類,97個中類,1400個小類,采用5級表示.比如,“中學”編碼“Dm05A08@”,表明“中學”屬于D大類,m中類,05小類,A類詞群,08原子詞群,獨立分類@.本文語義碼只使用《同義詞詞林》擴展版編碼的前四位信息(小類標準),比如“中學”編碼對應“Dm05”.
2.2 建立N元語義模板庫
第1步.按照語義詞典,標注訓練語料句子每個詞對應的語義碼;對于單義詞,由機器自動按照語義詞典的語義碼一一對應標注;對于多義詞,則根據詞所在上下文信息,由人工從語義詞典選擇最恰當的語義碼進行標注.對于由n個詞構成的句子,這n個詞對應的n個語義碼{S1,S2,…,Sn}稱為“語義碼序列”.對于語義碼序列中的一部分,則稱為“語義碼串”,簡稱語義串,比如,一個語義碼串{S1,S2,S3,S4,S5}就是n長度的語義碼序列{S1,S2,S3,S4,S5,…,Sn}中的一部分.
第2步.對每個語義碼序列,按每移動一個語義碼位置,以N個語義碼長度(本文N=5)進行切分分組,即以“寬度為N的窗口”從每一個語義序列前端開始向后滑動,每滑過一個語義碼位置,就從該窗口中抽取一個含有N個長度的語義碼串,從已經標注好的訓練語料中抽取的語義碼串,稱為“N元語義模板”.以此類推,把一個語義碼序列中所有N元語義模板都提取出來.對于每個語義碼序列中不足以按N長度劃分的結尾部分,則按實際的長度提取,直到提取模板長度為1為止.由n個詞構成的句子中可抽取n個語義模板(T1,T2,T3,…,Tn),見圖1.比如,從句子“遠在五千多年前,人類發明了文字.”提取的N元語義模板樣例,見圖2.其中“△”表明該模板是在句子的開頭位置.
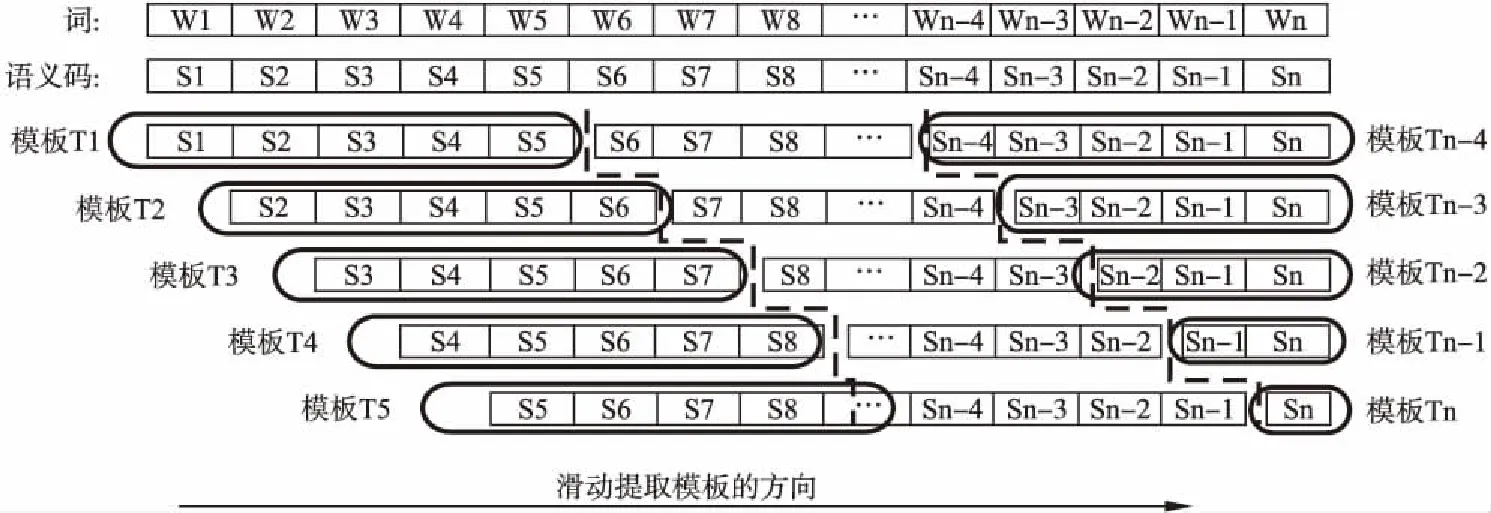
圖1 從語義標注的句子中提取N元語義模板(N=5)的示意圖

圖2 從“遠在五千多年前,人類發明了文字.”句子提取的部分N元語義模板
第3步.對語料庫中的所有標注的句子都重復以上第1步和第2步操作,直至抽取所有的N元語義模板,從而建立一個N元語義模板庫.
2.3 基于滑動語義串匹配的詞義消歧
2.3.1 填寫句子每個詞的語義碼得到語義碼序列
按照語義詞典,對于單義詞的單個語義碼,用“Sx”表示,多義詞的多個語義碼則用“Sx-1/Sx-2/Sx-3…”表示,見圖3.比如,其中的第2個詞和第6個詞是多義詞,它們的語義碼都包含兩個語義碼.圖3中語義碼序列為“S1S2-1/S2-2S3S4…Sn-1Sn”.
2.3.2 提取N元語義碼串并分組和分區
在按前一操作得到的語義碼序列上,按每N元長度(本文取N= 5)提取所有語義碼串,并對它們按水平方向分組和垂直方向進行分區.分組過程與建立N元語義模板庫時提取N元語義模板過程相似,只不過這里每一組語義碼串并不是一個N元語義模板而已.按水平方向進行分組后的n個語義碼串(C1,C2,C3,…,Cn-1,Cn)和垂直方向進行分區的5個分區(1區、2區、3區、4區、5區)的示意圖,見圖3.
2.3.3 計算語義碼串與N元語義模板的匹配得分
1)計算語義碼串中的單個語義碼的匹配得分
對于每個提取的N元語義碼串中的語義碼,在與N元語義模板庫中N元語義模板的對應位置的語義碼匹配時,兩個來源不同的語義碼是按照語義詞典的編碼格式從大類到小類的順序依次進行匹配,先分別得到大類匹配得分MatchScore_Level(1)、中類匹配得分MatchScore_Level(2)和小類匹配得分MatchScore_Level(3),見公式(1).
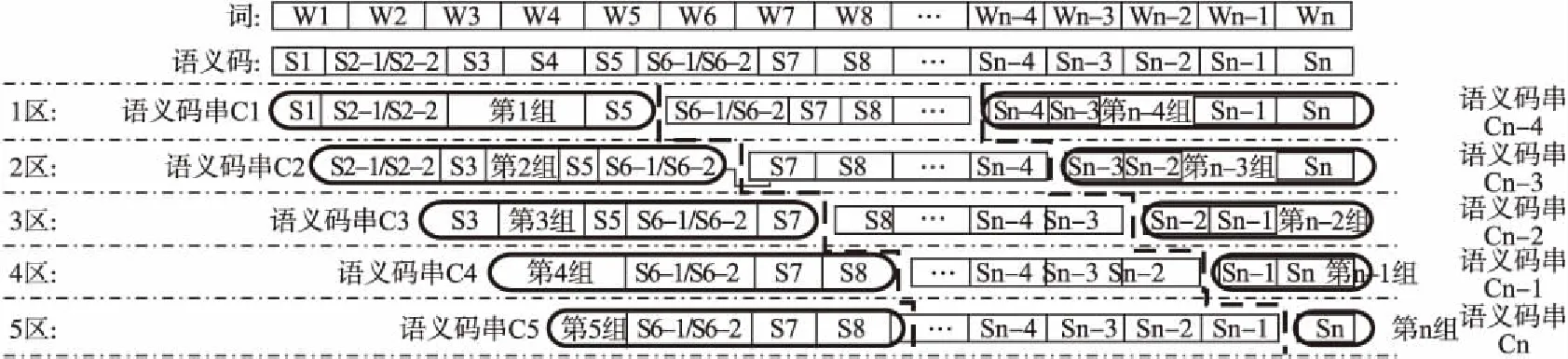
圖3 由n個語義碼構成的語義碼序列和按水平分組、按垂直分區的示意圖
(1)
其中Xs表示語義碼串的一個語義碼,Xt表示與Xs對應的N元語義模板中的語義碼;i= 1,2,3分別表示對應的語義碼層級,每個層級得分的大類Big_Score、中類Mid_Score和小類Small_Score可定義為某一個指定常數.然后通過對三種分類層級的匹配得分加權求和而得到單個語義碼的匹配得分MatchScore_Unit,見公式(2).
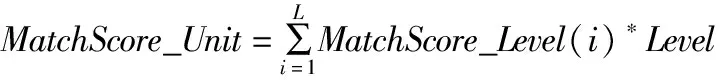
(2)
其中LevelWeight(i)為每類層級的權重,L值為加權求和時所包含的語義碼類別,本文L= 3,即包含大類、中類和小類三種類型的加權求和.
2)計算整個語義碼串的匹配得分
按照一個語義碼串從開始到結尾順序,對一個語義碼串上的每個語義碼的匹配得分進行加權求和,從而得到整個語義碼串的匹配得分MatchScore_SemanticString,見公式(3).
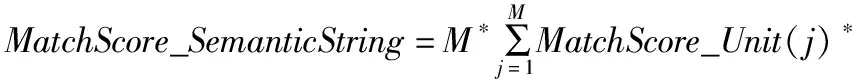
WordTypeWeight(j)*WordPositionWeight(j)
(3)
其中M表示當一個語義碼串與一個N元語義模板從開始位置向后連續匹配時,語義碼串上的語義碼的匹配得分不為0時的最大語義碼個數,M≤N,即語義碼串的最大匹配長度;WordTypeWeight(j)為每個語義碼的詞類權重(比如把語義碼對應的詞按實詞和虛詞進行區別);WordPositionWeight(j)為語義碼在模板上的位置權重(比如把語義碼的位置按居于模板中心和邊緣進行區分),本文選擇當j=1或j=M時(也即是最長語義碼的首尾兩個邊端位置),調整WordPositionWeight,其余情況不調整.
3)匹配時的未知詞和有多個匹配結果的處理
a)未知詞的語義碼處理
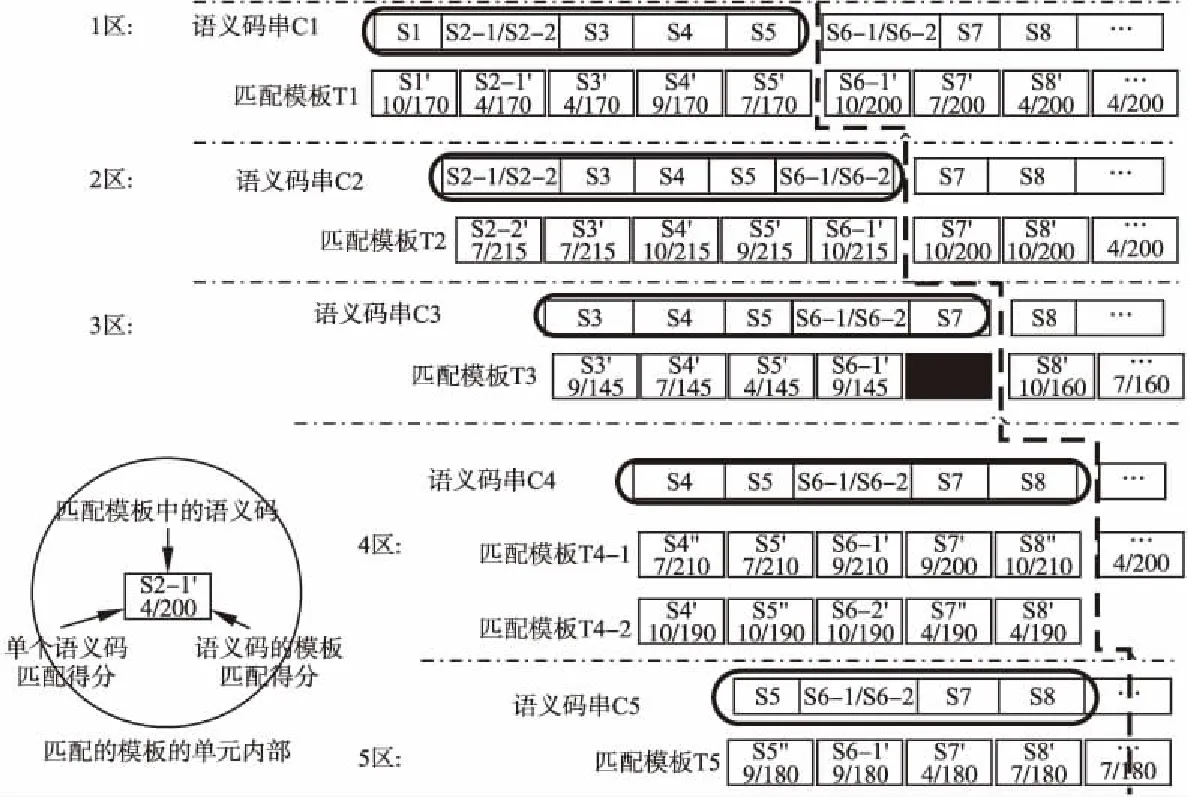
圖4 N元語義碼串與N元語義模板的匹配結果示意圖
未知詞的語義碼,本文按照詞性進行默認指定,如果為名詞,則候選語義碼“Aa00A00#,Ba00A00#,Ca00A00#,Da00A00#”;如果為動詞,則候選的語義碼“Fa00A00#,Ga00A00#,Ha00A00#,Ia00A00#,Ja00A00#”.
b)語義碼串匹配時有多個匹配結果的處理
當一個N元語義串匹配到多個N元語義模板時,一律保留這些匹配的語義模板,見圖4.其中第4個語義碼串(C4)保留了匹配成功的多個語義模板(共2個,T4-1和T4-2).另外,圖4也說明了匹配成功的長度不一定都是N長度的,比如第3個語義碼串的N元長度是5,但是最大的模板匹配長度是N-1=4,結尾語義碼(S7)的匹配為失敗(即黑色填充表示的部分).
2.3.4 按照語義碼串的匹配結果確定最終語義碼
1)得到每個區中每個詞的各種語義碼的最大得分
從第一個區開始,對每個區內所有匹配模板的語義碼按照每個詞位置進行垂直方向過濾.對于過濾后的不同類型語義碼,分別列出不同區中語義碼在模板匹配時的不同得分,見圖5.
2)得到所有區中各種語義碼的最大得分
對于每個詞位置上的所有語義碼,分別在N個區上進行垂直過濾后而得到每種語義碼的最大匹配得分,按照專門算法計算每種語義碼在所有N個區中的得分.專門算法中包括統計所有N個區對每一種語義碼的投票數,規定每個區對每種語義碼最多只有1個投票數,如果某語義碼在某區不存在,那么該區對該語義碼的投票數為0.同時考慮其他得分信息,比如在所有N個區中的在單個區中的最大得分,在所有N個區中的累計得分等,每個詞的各種語義碼的最后得分為FinalScore,見公式(4).
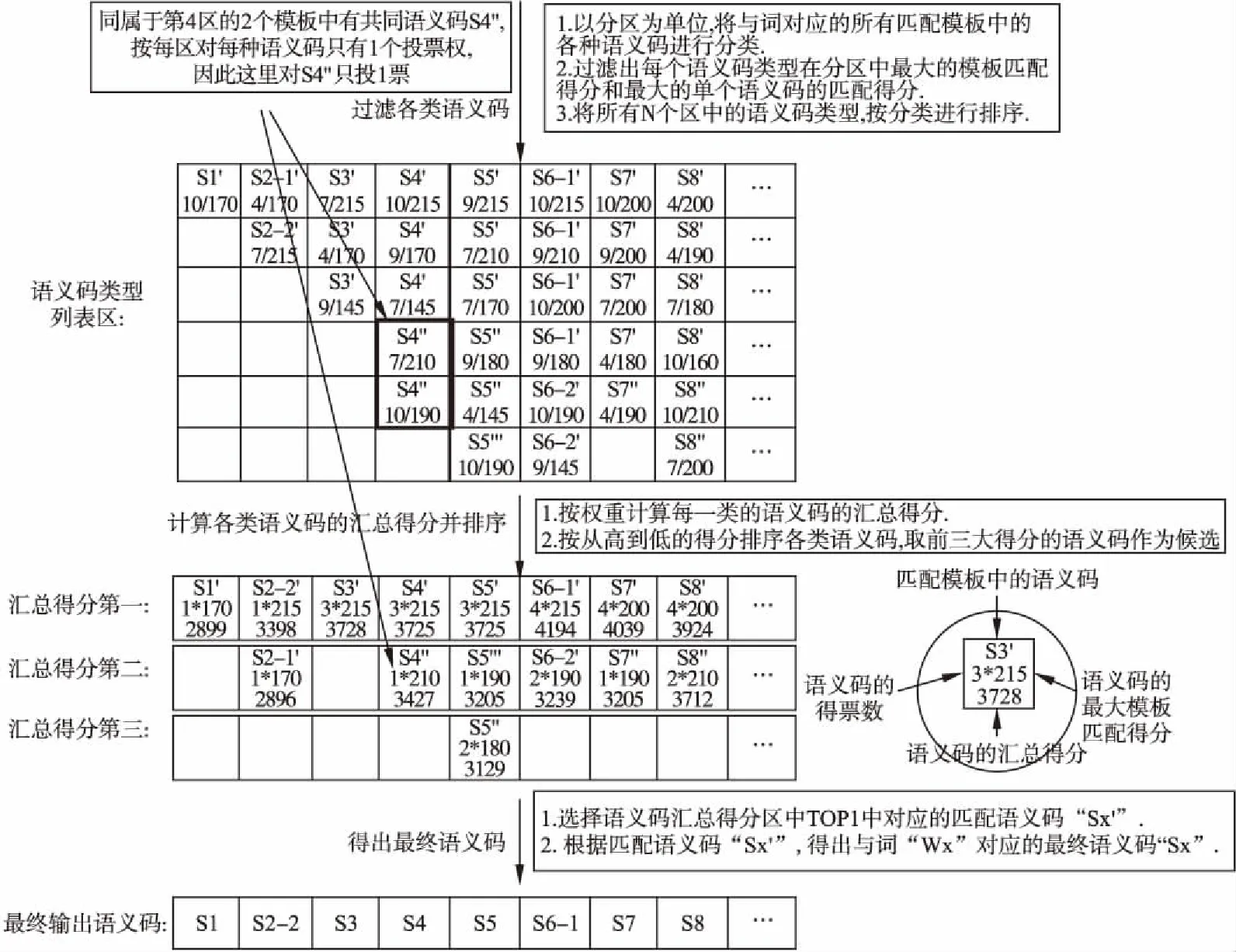
圖5 通過過濾和加權計算確定最終語義碼的示意圖
FinalScore=λ1*VoteNum+λ2*MaxScore_T+λ3*AccumulativeScore_T
(4)
其中,VoteNum為所有區對該語義碼的投票數;MaxScore_T為該語義碼在所有N個區的范圍內最大的單個區得分;AccumulativeScore_T為累計該種語義碼在所有N個區中最大得分后的匯總得分;λ1、λ2、λ3為細分權重.
3)選擇所有N個區中得分最大的語義碼為最終輸出
選擇每個詞位置上匹配得分最大的語義碼進行輸出,從句子第一個詞開始,直到輸出整個句子上所有詞的語義碼,見圖5.由于每個區中不同得分的語義碼可能有很多,本文選擇每個區中的得分由高到低的前TopX項(X值實驗選定)參與后面的計算.其中最終輸出的語義碼為“S1,S2-2,S3,S4,S5,S6-1,S7,S8…”,多義詞W2和W6消歧后的語義碼分別為S2-2和S6-1.
3 實 驗
實驗語料:為了檢驗本文方法的效果,選用國際語義評測的中英文詞匯任務SemEval-2007中的Task#5[21]進行實驗.本任務共有40個歧義詞,其中分別有19個名詞和21個動詞.評估任務共提供訓練句子2686句,測試句子935句.
實驗準備:為了有效驗證本文方法和減少標注工作量,本文僅標注了訓練句子中多義詞的左右兩邊的N-1個詞語的語義碼,因為實際提取的模板也只是使用這部分信息.按照《同義詞詞林》擴展版的語義碼和原語料給定的詞性制約,自動地預先過濾掉那些不符合詞性的候選語義碼,然后對其中單義詞進行自動標注,對多義詞進行人工標注,整個標注的工作量為1人3天.
評測標準:采用評估標準中的宏平均精度(Pmar,macro average accuracy).
其中,N為所有目標詞數,mi是對每一個特定詞所標注的正確例句數,ni是對該特定詞所有的測試例句數.
實驗結果:多種選擇方案后的實驗結果見表1.
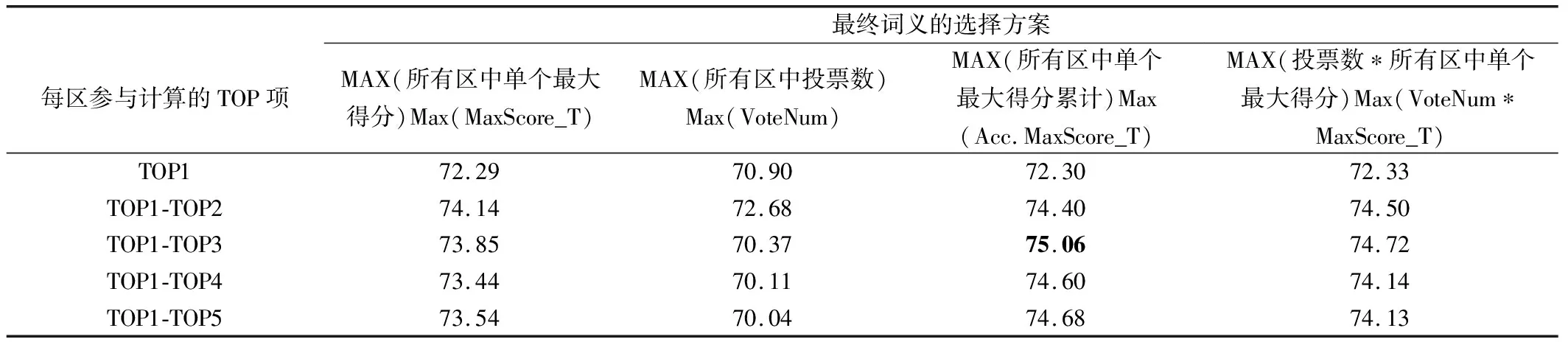
表1 多義詞消歧精度(按4種方案測試)
4 實驗結果分析
從表1結果來看,在選擇每個區參與計算的TOP項時,如果只選擇一個TOP項時,即選擇TOP1時,效果最差.隨著選擇TOP項增多,性能逐漸提高,但當TOP項數超過一定值時,性能有所下降.根據當前的實驗,選擇的TOP項數為3時比較好.產生這個問題的原因,可能是每個區參與項數太少時,會硬性攔下了正確內容,而項數太多時,干擾的噪聲又會增加,從而影響了整體性能.從所選擇的不同實驗方案來看,它們各有優勢.對于選擇所有區中的單個得分最大者,或者所有區中單個最大得分的累計得分最大者,都要好于單獨選擇投票數最大的方法.分析原因:單純五個區投票最大票數是5,當存在多個并列結果時,系統只是順序選擇并列中的第一個,從而造成了性能下降.
從結果出錯的地方來看,一些是權重值不合理造成的,這個日后可繼續優化;還有一些,就是與訓練語料中提取的所有模板都不匹配而導致的錯誤,如果連匹配最底層的一級(大類)語義碼的模板都不存在,即使想通過語義碼來擴展那也無法成行.對于這種問題,還是需要擴充相應標注語料才能解決,本文方法雖然具有“取一個詞=>得到一個語義碼=>覆蓋多個詞”的能力,并可通過彈性匹配來解決一定的數據稀疏問題,但是若整個訓練語料中連原始的同義詞都不存在,也就自然談不上擴展和覆蓋了.因此,從這個意義上講,用于訓練的語料規模還是越大越好.
5 相關研究的對比
為了與其他方法對比,表2中列出了目前已知使用SemEval-2007評測標準的一些方法.
對于表2中結果,XING[22]使用了詞性、指定詞性的詞、淺層句法分析的短語、《同義詞詞林》詞范疇信息等,該方法由于使用了外部淺層句法分析資源,因此容易受到淺層句法分析質量的影響.楊陟卓等[13]使用大規模語料(1998年半年《人民日報》和搜狗新聞數據語料庫)訓練語言模型,然后利用綜合模型進行消歧,該結果是在給定訓練語料之外再加其他外部語料進行訓練后的測試結果.楊陟卓[17]將訓練語料的上下文和測試語料的上下文分別翻譯后再通過貝葉斯消歧模型進行消歧,該方法需要依賴外部翻譯資源,因此容易受到翻譯質量的影響.本文方法除了使用《同義詞詞林》語義編碼詞典外,沒使用其他的資源和復雜特征,因此可以不受外部資源影響而獨立工作.即使在只利用語義模板本身語義信息和較少上下文標注信息(目標詞左右4個詞的語義碼),在處理過程不復雜的情況下,就取得與對比方法相接近的效果.而且,若是對于一個句子中同時有多個歧義詞需要消歧時,只要它們是在一個模板長度覆蓋內,我們方法就可一次并行地消歧多個目標詞,而不用逐個歧義詞分別模板匹配,這將大大提高消歧效率,特別適合于全文所有詞的詞義消歧.
表2 相關其他方法的對比
Table 2 Comparison with other methods

方 法PmarXINGYUN[22](2007)SRCP_WSD74.90楊陟卓,黃河燕[13](2014)Optimized_ME75.30楊陟卓[17](2017)Method_275.97本文SMOSS75.06
6 總 結
本文提出一種基于滑動語義串匹配(SMOSS)的漢語詞義消歧方法.其先從經過語義碼標注的訓練語料中提取N元語義模板,以建立語義模板庫;然后滑動地將測試句中的N元語義碼串與N元語義模板匹配,通過目標歧義詞左右兩邊N-1個語義碼的定位匹配,確定了該目標歧義詞的詞義.該方法使用詞的語義碼建立模板,比使用詞建立模板具有更好的覆蓋度,而且3級層次的語義碼格式可以更適合彈性匹配,這都有效緩解了有監督學習方法中數據稀疏的問題.從本文使用SemEval2007 Task#5評測實驗來看,即使僅使用目標詞左右N-1詞長度的語義碼信息,在沒使用其他的復雜特征和依賴復雜的外部資源的情況下,也可以達到接近于目前該標準最好的性能,充分表明該方法的簡潔性和有效性.以后我們將在優化參數上繼續挖掘潛力,以期能能更好地提高詞義消歧性能.
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
兒童故事畫報(2019年5期)2019-05-26 14:26:14
現代語文(2016年21期)2016-05-25 13:13:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
大連民族大學學報(2015年2期)2015-02-27 08:28:11
當代修辭學(2011年6期)2011-01-29 02:49:50
外語學刊(2011年1期)2011-01-22 03:38:33
