改進的偏向寫調度的混合內存緩沖區調度策略
2020-07-23 13:53:22汪令輝
湖南工業大學學報 2020年4期
關鍵詞:頁面
劉 兵 ,汪令輝,張 銳,崔 瑩,段 峰
(1.中國科技大學 計算機科學與技術學院,安徽 合肥 230027;2.銅陵職業技術學院 信息工程系,安徽 銅陵 244061;3.銅陵有色金屬集團公司,安徽 銅陵 244000)
隨著大數據、人工智能等技術的發展,數據的處理量越來越大,這對計算機的主存儲器提出了越來越高的要求。當前,以動態隨機存取存儲器(dynamic random access memory,DRAM)為主的主存儲技術也面臨著較大的挑戰,主要面臨的問題為DRAM 存儲集成已達極限,且能耗也是一個重要問題。人們從軟件和硬件等方面提出了多種方式,希望彌補這一缺點,比如通過非易失存儲(non-volatile memory,NVM)來解決這一問題。非易失存儲具有較高的集成度、非易失、低能耗、字節尋址等特點。非易失存儲器有電阻隨機存儲器ReRAM[1]、自旋磁存儲器[2]、相變存儲器[3](phase change memory,PCM)等。其中,PCM 具有良好的可擴展性,有望成為新一代的主流技術。
1 研究背景和相關工作
1.1 PCM的相關特性
相變存儲器是一種硫族化合物,分為晶體狀態和非晶體狀態。它具有寫的不對稱性,PCM寫1(SET)的時候,要施加一個時間長、電壓低的電脈沖,溫度在結晶點以上、融化點以下,導致其結晶,物質從非晶態到晶態轉化。PCM寫0(RESET)的時候,要施加一個電壓高、時間短的電脈沖,當溫度上升到溶點后,再經過一個淬火(降溫速率大于109 K/s)的過程,物質從晶態到非晶態轉化。
相變存儲器在晶態和非晶態時,其阻抗是不同的,當施加一個電壓時,對應的電流不同,從而可以判斷為0或1。PCM讀的過程中,電流通過時產生的熱量很小,不會引起晶態的變化。
PCM和DRAM 相比較,具有存儲密度大和無空閑功耗的優點。DRAM的工藝制程是PCM的4倍,所以在相同的芯片面積下,PCM可以增加更大的容量;DRAM 空閑時,需要通過不斷地刷電來保持數據,而PCM為非易失性存儲設備,不需要刷電。
PCM和DRAM 相比較,也有它自身的缺點,主要如下:
1)PCM的讀操作時間是DRAM的2倍,功耗相差不大;
2)PCM的寫操作時間是DRAM的10倍,PCM寫功耗比DRAM 大;
3)PCM的寫次數為108~1 012,DRAM幾乎無限,寫次數為大于1 015。
1.2 PCM在內存中的應用
1.2.1 混合內存架構
目前,針對PCM的特性,許多研究者嘗試結合二者的優點,提出了混合內存[4-9]的概念。混合內容的主要架構方式包括層次架構和平行架構兩種。
1)層次架構。該方式下,DRAM 作為PCM的緩存,所有的請求都先訪問DRAM,當請求沒有選中是時,再訪問PCM。這種架構方式的優點是利用DRAM 彌補PCM的寫不足,同時利用PCM 增加存儲密度,利用其非易失性存儲特點,減少空閑能耗。
2)平行架構。該方式中PCM和DRAM的同一層混合使用,整個內存由兩者共同組成,統一編址,數據只放在PCM或者DRAM中的一個中,如將寫傾向較高的頁面放在DRAM中,將讀傾向較高的頁面放在PCM中。
在層次架構下,當出現對內存需要較大的調用時,會增大DRAM和PCM 交換的工作量,系統效率較大下降,并且會增大PCM的磨損。平行架構中,根據PCM 也是字節尋址的特點,將DRAM和PCM統一地址空間,但由于二者的讀寫等特性不一樣,為了降低能耗并延長PCM的使用時間,緩沖區的管理算法就顯得尤為重要。
1.2.2 平行架構緩沖區管理算法
已有關于混合內存的緩沖區管理算法主要有LRU-WPAM(least recently used with prediction and migration)[10-11]和CLOCK-DWF(clock with dirty bit and write frequency)[12]。其中,CLOCK-DWF算法對CLOCK 算法進行了改進,通過記錄每個頁面的寫次數來判斷讀傾向和寫傾向,從而調度寫傾向在DRAM中,讀傾向在PCM中;LRU-WPAM算法以最近最少使用(LRU)算法為基礎,增加了一個頁面讀寫預測機制,從而進行頁面的調度。
在LRU-WPAM的緩沖區管理中,當緩沖區頁面未命中時,與LRU算法一樣,選擇緩沖區最近最少使用的頁面進行置換;當緩沖區中頁面命中時,首先根據讀寫請求修改頁面權值,然后判斷是否達到閥值,并根據權值決定是否將頁面移動到PCM或者DRAM中,如果目標存儲器上沒有空閑空間,在DRAM中選擇讀子隊列尾部頁面釋放,在PCM上選擇寫子隊列尾部頁面釋放。
在CLOCK-DWF的緩沖區管理中,首先,將DRAM和PCM分別組成一個環狀隊列;然后,根據數據訪問時的讀寫類型,將寫請求的頁面存放在DRAM中,讀請求頁面存放在PCM中。當DRAM空閑空間不足時,將“寫”冷頁寫入PCM,當PCM空閑空間不足時,用CLOCK頁面調度的算法對頁面進行調度。
2 FWLRU混合內存緩沖區調度策略
在上述算法的混合內存管理中,根據“寫”熱頁和“讀”熱頁的判斷,調度頁面在PCM或者DRAM中存儲。如果所在頁面當前存儲和判斷的結果不一致,則需要進行PCM和DRAM的頁面遷移。根據以上調度算法,主要會造成以下幾個問題:
1)頻繁地在PCM和DRAM中進行頁面遷移,要消耗大量的系統資源。同時,當PCM和DRAM中的空閑空間不足時,需要從二者中選擇頁面進行釋放,釋放的頁面可能就是即將訪問的頁面,這樣就會將緩沖區原先命中的訪問變成沒有命中,造成緩沖區命中率下降。
2)將“讀”熱頁從DRAM中遷入PCM,遷移寫入時實際上增加了PCM的寫,與減少PCM寫的初衷不一致。
3)當頁面的訪問是讀傾向較多的時候,按照LRU-WPAM、CLOCK-DWF算法的要求,都要遷移進入PCM,這樣反而造成PCM寫的增加。
另外,根據A.R.Alameldeen 等的研究[13-15],內存數據訪問具有明顯的局部性,局部數據的訪問達到40%以上,有些情況下甚至超過60%。
針對以上情況,本文提出一種偏向寫調度緩沖區調度策略(favors write least recently used,FWLRU)的混合內存緩沖區調度策略,主要進行了以下兩個方面的優化:
1)只進行“寫”熱頁的調度,而不進行“讀”熱頁的調度。混合內存的主要目的是充分利用PCM的高存儲密度和低能耗這兩個優點來優化內存,避免PCM讀寫不均衡、寫有限等缺點。DRAM和PCM在讀上區別并不大,如果強制將所有大于權值的讀傾向頁移動進入PCM,將增加PCM的寫操作,特別是如果讀操作較多時,寫的次數將更多。但是如果不進行讀頁面的調度,對系統性能將沒有什么影響。所以在FWLRU算法中只考慮將“寫”熱頁調度進入DRAM,而不進行“讀”熱頁的調度。
2)“寫”熱頁采取PCM和DRAM頁面互換的原則進行遷移。在將“寫”熱頁從PCM 置換到DRAM 過程中,當DRAM 空間不夠時,如果采取淘汰策略,有可能淘汰的頁面就是下一次就要訪問的頁面,這樣就把將要訪問的頁面淘汰掉了,從而把原本命中的操作變成了不命中,降低了命中率。而FWLRU算法中,不進行頁面的淘汰,只是將PCM頁面的DRAM中的頁面采取互換原則,以此避免淘汰可能將要被訪問的頁面,提高頁面的命中率。
2.1 訪問行為記錄
FWLRU混合內存緩沖區調度策略中使用了3個LRU隊列:DRAM讀隊列(DR)、DRAM寫隊列(DW)、PCM寫隊列(PW)。
LRU隊列在緩沖區中按照訪問時間組成隊列,其中,最近訪問位于隊列首部,最長時間訪問位于隊列尾部。DR隊列記錄DRAM中頁面的讀操作,DW隊列記錄DRAM中的寫操作,PW 隊列記錄PCM中的寫操作,都按照最近訪問原則從前至后排列。
2.2 PCM中“寫”熱頁和DRAM中頁面的互換
FWLRU 偏向寫調度的緩沖區調度策略中,當緩沖區塊命中時,修改頁面的權值,如果是“讀”命中,權值增加;如果是“寫”命中,權值減少。將權值和“讀寫熱頁判定標準”閥值進行比較,若頁面權值小于閥值,則說明是一個“寫”熱頁。根據緩沖區和內存空間的物理地址(internal memory address)映射,查看這個頁面的物理地址是在DRAM中還是在PCM中,如果在PCM中,要進行PCM和DRAM 空間頁面的互換,同時將頁面加在LRU隊列首部。和“讀寫熱頁判定標準”閥值比較,如果大于閥值,則說明是一個“讀”熱頁,不進行操作。
同時,根據讀寫操作,如果是寫,那么根據物理地址的映射,加入到DW或者PW 隊列的頭部;如果是DRAM讀寫,那么加入到隊列的頭部,并修改頁面的權值。
“寫”熱頁將執行頁面從PCM寫入DRAM,如果DRAM 空間有空閑,那么直接寫入;如果DRAM空間已滿,那么將DR隊列尾部頁面和“寫”熱頁互換,如圖1所示。頁面互換時,不進行DRAM頁面的淘汰,這樣可以避免將有可能即將訪問的頁面淘汰掉,把頁面原本的命中操作變成不命中操作,從而降低緩沖區的頁面命中率。
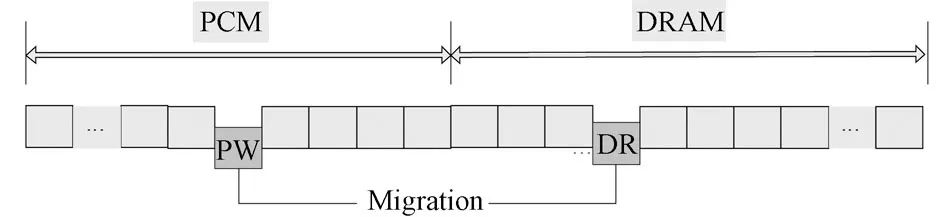
圖1 PCM寫熱頁與DRAM中DR隊列尾部頁面互換Fig.1 Exchange of PCM hot page and DR queue tail page in DRAM
2.3 調度流程
算法1 描述了混合內存緩沖區調度策略的調度流程。算法中IMAddr(internal memory address)為頁面從緩沖區映射到內存的物理地址,物理地址根據字節地址范圍劃分為DRAM和PCM 區域。頁面如果判定是“寫”熱頁,且IMAddr在PCM中時,執行2.2所述頁面互換工作。緩沖區頁面訪問類型為“讀”時,修改頁面權值加1,同時將頁面序列加入到LRU和DR隊列頭部。
算法1 混合內存緩沖區調度策略流程


算法完成后,返回IMAddr值。
3 實驗結果及分析
3.1 實驗方法
本實驗采用在ubuntu 18.04系統上架設GEM5[16]模擬器仿真,同時安裝NVMain[17-18]模擬相變存儲器,從而實現DRAM和PCM 混合實驗環境。系統采用SE(系統調用)模式,PCM的延遲數據參照F.Bedeschi的研究[19],DRAM的延遲參照Micron的測試[20]。每個頁面大小設定為固定值4 kB,DRAM和PCM的比例采取固定配置形式,按照1∶4 配置,整體存儲空間按照實驗需要進行增大或減少。
本實驗選用的數據集由真實數據和合成數據兩部分構成,其中真實數據出自于安徽蕪湖某電商網站交易系統的某日交易記錄,該數據集對數據庫進行了356 733次讀和115 790次寫操作;合成數據來自開源軟件DiskSim,版本為4.0。DiskSim 進行磁盤讀寫模擬,同時改變配置參數,設置局部性讀寫不同的比例來得到系列數據集,挑選其中具有代表性的4個數據組參與混合內存實驗。局部性(Locality)中“80%/20%”,指80%的數據發生在20%的空間上。具體實驗數據集測試參數見表1。
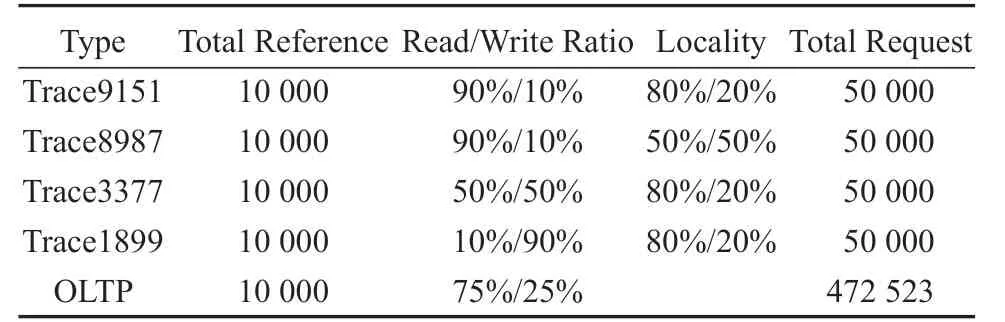
表1 實驗數據集Table1 Experimental data set
3.2 頁面命中率
將FWLRU混合內存緩沖區調度策略和LRU、LRU-WPAM、CLOCK-DWF在模擬器上進行了頁面命中率檢測。圖2給出了5組測試數據集在內存頁面逐漸增大的情況下,4種不同的緩沖區調度下頁面未命中的數量。

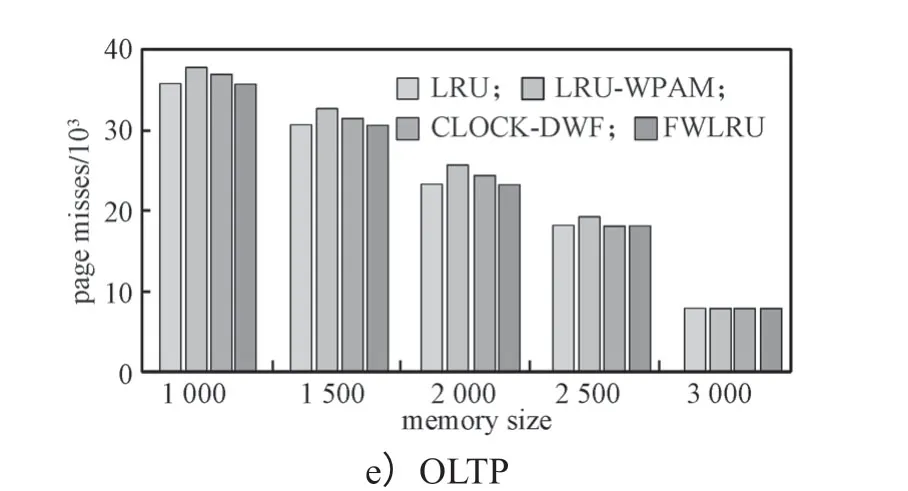
圖2 不同調度策略下的命中率實驗結果Fig.2 Experiment results of hit rate under different scheduling
分析圖2所示實驗結果數據,可得出以下結果:
1)從圖2a至2e的5組類型數據的實驗情況看,隨著內存容量逐漸增大,頁面未命中的數量明顯減小。可見內存容量的大小對命中率有著直接的影響,容量越大,命中率越高。
2)從命中率情況看,FWLRU算法的命中率比LRU-WPAM和CLOCK-DWF的要高,接近LRU算法的。這和FWLRU算法中不進行頁面的淘汰有關,只是將“寫”熱頁從PCM到DRAM的互換,防止了將即將訪問的頁面淘汰而造成的命中率下降。
通過實驗結果對比可以看出,相對于LRUWPAM和CLOCK-DWF算法,FWLRU算法提高了頁面的命中率。
3.3 PCM寫次數
設定內存空間大小固定為1GB(DRAM 與PCM的比值為1∶4)的情況下,對PCM在FWLRU、LRU、LRU-WPAM、CLOCK-DWF 4種策略下的寫總次數進行實驗模擬,結果如圖3所示。
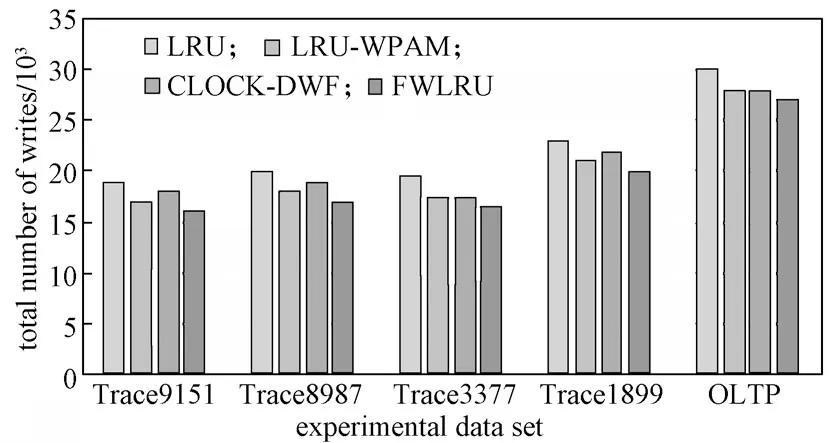
圖3 不同調度策略下的PCM寫次數實驗結果Fig.3 Experiment results of PCM write times under different scheduling
通過圖3所示實驗數據可以看出,LRU 由于不考慮兩種存儲介質的不同,沒有進行“寫”熱頁和“讀”熱頁的調度,所以PCM寫的次數最多;LRU-WPAM和CLOCK-DWF 考慮了PCM和DRAM 這兩種存儲介質,并進行了將“寫”熱頁存放在DRAM、“讀”熱頁存放在PCM上,導致PCM寫的數量有所降低,但將“讀”熱頁集中到PCM上,移動的過程也增加了PCM的寫,并且對讀比例大的頁面進行訪問,反而有可能加大PCM的寫。FWLRU 考慮讀操作上DRAM和PCM的區別不大,故不進行“讀”熱頁的移動,只將“寫”熱頁互換到DRAM中,所以PCM寫的次數比LRU-WPAM和CLOCK-DWF的有所降低。實驗結果證明,FWLRU 對PCM 進行了優化,寫的次數減少。
4 結論
非易失性存儲材料PCM 是解決DRAM的存儲密度和降低能耗的好材料,但是PCM 具有讀寫不對稱和寫有限等缺點,許多研究者提出以多種混合內存的緩沖區調度策略來解決這一問題。本文在混合內存架構的基礎上,提出了一種偏向寫調度的混合內存緩沖區調度策略。
1)只將“寫”熱頁從PCM 置換進DRAM,沒有將“讀”熱頁寫入PCM,避免了調度過程中或者頻繁調度中對PCM的寫,特別是讀偏向較多的頁面;
2)PCM和DRAM 采取頁面互換的形式,不從DRAM中淘汰頁面,避免了將可能即將訪問的頁面淘汰,將命中操作變成沒有命中操作的情況,提高了頁面訪問的命中率。
3)本文從緩沖區調度入手來解決PCM讀寫不對稱、寫有限等問題。但是冷熱頁的劃分還是采取簡單的權值計數方式,這種冷熱頁劃分方式是否過于簡單還有待考證;而且沒有對PCM的磨寫均衡進行考慮,這是下一步研究的方向。
猜你喜歡
文萃報·周五版(2025年2期)2025-02-14 00:00:00
大灰狼畫報·益智版(2024年3期)2024-12-09 00:00:00
保健醫苑(2022年1期)2022-08-30 08:39:14
電腦愛好者(2022年3期)2022-05-30 10:48:04
工業設計(2016年1期)2016-05-04 03:58:09
通信技術(2012年4期)2012-02-15 07:10:35
電腦愛好者(2011年11期)2011-06-22 08:20:18
網絡安全技術與應用(2011年3期)2011-03-14 06:44:46
赤峰學院學報·自然科學版(2010年11期)2010-09-21 11:30:50
河北軟件職業技術學院學報(2010年3期)2010-06-06 07:18:42
