基于機器學習的P2P網絡借貸違約風險識別模型比較
——以“人人貸”為例
2020-07-25 04:41:00裴曉偉張馨予
江蘇科技信息 2020年16期
裴曉偉,張馨予
(南京郵電大學經濟學院,江蘇南京 210023)
0 引言
近年來,P2P網絡借貸市場中由信息不對稱所引發的借款人違約問題日益嚴重。自2017年起,眾多平臺相繼因為借款人違約引發平臺資金鏈斷裂而爆雷,使P2P平臺和投資者慘遭損失。2018年,隨著監管措施進一步加強,問題平臺全面爆發,此后P2P存量平臺持續減少。至2019末,P2P網絡借貸平臺正常運營數量僅剩343家,網貸行業總體貸款余額同比2018年下降了37.69%[1]。總體來看,P2P網絡借貸生態已經轉向無擔保化和嚴監管方向發展,相應地,對平臺的風險控制和風險定價能力的要求逐漸走高。P2P網絡借貸依托于互聯網,已經積聚了量級巨大的借貸交易數據,因此,如何通過對這些大數據進行深度挖掘,從而識別借款人的違約風險,成為網貸平臺和學者們近年來研究的重點。其中,機器學習在大數據分類問題中的優異表現為P2P網絡借貸違約風險識別提供了新的思路。
本文將以“人人貸”平臺的借貸數據進行實證分析,分析4種主流的機器學習算法——CART決策樹、支持向量機、BP神經網絡和隨機森林在P2P網絡借貸違約風險識別中的適用性,并對4種算法的預測效果進行比較。
1 文獻綜述
國內外許多學者已經將機器學習算法運用到P2P網絡借貸違約風險的識別中,并取得了實質性的成果。
國外方面,Harris[2]發現在進行違約風險識別時,集群支持向量機比傳統支持向量機在分類效果上展現出更好的優勢。Jing[3]對來自Lending Club的借貸數據進行SMOTE采樣,并運用深度神經網絡(DNN)對其進行違約風險評估,發現DDN的預測精度顯著高于多層感知機(MLP)。國內方面,安英博等[4]發現基于Stacking集成學習方法構建的違約風險識別模型可以綜合單一機器學習模型的長處,預測效果更好,且可以減少對非違約用戶的誤判。張晨[5]基于Lending Club的個人信貸數據,使用隨機森林和Easy Ensemble方法進行模型構建,發現隨機森林模型在違約風險識別中的預測效果好于Logistic回歸,且Easy Ensemble方法可以提升隨機森林模型在不平衡數據上的分類表現。
從上述文獻研究中,發現許多學者多基于某個或某類模型來進行違約風險評估,或者注重對某一類機器學習算法的優化,關于多種機器學習算法在評估P2P網絡借貸違約風險時的性能對比方面研究較少。
2 實證分析
2.1 數據來源與預處理
(1)數據來源。本文選取“人人貸”作為數據源平臺,考慮到P2P網絡借貸期限短則3個月,長則36個月,因此,本文運用Python爬蟲程序爬取了“人人貸”平臺2016年1月至12月的散標數據,共32 081個樣本。本文只保留“還款完成”和“標的違約”的樣本,分別對應因變量——“違約情況”中的“違約”與“不違約”,其中違約樣本為210個,非違約樣本為26 342個。
(2)特征變量確定。對于自變量,本文結合變量間的相關系數矩陣,剔除了原始數據集中無意義、意義表達一致以及有唯一性的特征變量。此外,考慮到信用變量“成功借款次數”“申請借款次數”和“還清筆數”單獨存在時可解釋性較差,本文重新構造了“成功借款比率”與“清償比率”并取代了之前的3個特征,其中:

經過上述篩選和處理,本文所選用的自變量共有30個,其中,描述借款信息的有:標的總額、投資人次、年利率、期限、標的類型和借款性質;衡量借款人基本信息的有:性別、年齡、學歷、婚姻狀況、收入、房產、房貸、車產、車貸、工作時間、公司性質、公司規模、公司行業、居住地區、工作認證和收入認證;衡量借款人信用信息的有:信用額度、借款總額、信用評級、成功借款比率、清償比率、待還本息、逾期次數、累計逾期金額。
(3)獨熱編碼(one-hot coding)與歸一化。對于數據集中的無序分類變量,其標簽數值大小無實際意義,本文對其進行了獨熱編碼,用一組比特位表示一個無序分類變量的不同類別。此外,為了縮短BP神經網絡模型和SVM模型的訓練時間,提高求解的收斂速度和精度,本文對具有較強稀疏性的數據集采用絕對值最大標準化方法將數據壓縮至[0,1]范圍內。
2.2 評價指標選取
考慮到本文數據的非平衡性,在模型性能評估指標的選取上,本文將重點參考適用于評價非平衡數據集上分類器性能的AUC和Fβ指標,其中由于在違約風險識別中將潛在違約借款人貸前評估為正常借款人往往比將正常借款人評估為潛在違約借款人具有更大的風險,即召回率要比查準率更加重要,因此Fβ具體將選用F2,同時將查準率(Precision)和召回率(Recall)作為輔助參考指標。
2.3 模型構建
由2.1可知,本文數據為非平衡數據,考慮到重采樣會破壞數據的比例信息,對數據集的分布改變較大,因此本文采用代價敏感學習方式來處理非平衡數據,即用不同權重的代價來區分各分類錯誤,以達到類別加權損失值近似的效果,從而達到整體代價最小。對于以下4種分類模型,本文通過設置各分類模型中的類別權重參數進行代價敏感學習,類別權重ωi計算方式如式(3)所示:

其中:ni表示第i類樣本的個數,Nclass表示類別個數,n為樣本總數。
2.3.1 CART決策樹模型
決策樹(Decision Tree)是一種由節點和有向邊組成的以樹形結構來展示決策規則和分類結果的機器學習模型[6],具有可解釋性強、分類速度快的優點。因其在節點處選擇特征時所依據的標準不同,決策樹可分為ID3、C4.5和CART。鑒于CART決策樹可以處理連續和分類兩種自變量類型,同時適用于大樣本,因此本文選擇CART決策樹。
CART決策樹使用基尼系數(Gini coefficient)作為選擇節點處分類特征的標準,對于給定的樣本集合D,基尼系數的計算如公式(4)所示:

其中:Ck是D中屬于k類的子集數量。給定特征條件下樣本D的基尼系數為依據該特征值所劃分的兩子集基尼系數的加權平均值。
本文將數據集按照7∶3的比例劃分為訓練集和測試集,對訓練集使用CART決策樹算法進行訓練,為了避免模型過擬合,本文利用網格搜索來尋找樹模型最大深度的最優取值,以便對決策樹進行“剪枝”,最終確定當樹的最大深度為6時,測試集的F2最大,尋優過程如圖1所示。CART決策樹模型中AUC為0.980 8、F2為0.931 9,召回率為 0.963 0、查準率為0.825 4。
此外,本文根據剪枝后的決策樹得出了各個特征的重要性程度,重要性由高到低依次為信用評級、清償比率、累計逾期金額、借款期限、逾期次數、公司性質和成功借款比率,其余特征變量在決策樹模型中重要性均接近于0。其中,信用評級的特征重要性高達0.91,是判斷借款人是否會違約的重要依據。結合決策樹的決策規則可以得出,信用評級在B及B以上的借款人違約風險較小,信用評級在B以下的借款人中,具有以下一個或幾個特征的,如在非國家機關和非事業單位工作、借款期限大于15個月、無車產或清償比率小于0.4等的借款人違約風險較大。

圖1 CART決策樹最大深度尋優過程
2.3.2 BP神經網絡模型
BP神經網絡是一種按誤差逆向傳播算法訓練的多層前饋神經網絡。其基本過程為,輸入層信號經由隱含層正向傳播,在輸出層計算得到誤差,再將誤差按照梯度下降的方式反向傳遞,修正各層的權值和偏置。其中,訓練集被整個網絡訓練的次數稱為epoch,網絡中各層權重的更新次數隨epoch的增加而增加,epoch過高可能導致模型過擬合。
本文運用Python的Keras高層神經網絡API來構建3層BP神經網絡,對訓練集進行訓練,因為已有理論證明,3層BP神經網絡可逼近任意復雜度的函數。對于隱含層節點數,先用經驗公式確定初始值,根據下述經驗公式,可求得本文中隱含層初始節點數為8。

其中:l代表隱藏層的節點數,n代表輸入層的節點數,k代表輸出層的節點數,i代表0~9之間的任意常數。
本文進一步運用網格搜索確定隱含層節點數和epoch的最優值,其中節點數的取值范圍為8~15,epoch的取值范圍為0~20。最終確定epoch的最優取值為16,隱含層節點數的最優取值為9,具體的參數尋優過程如圖2—3所示。最終確定的BP神經網絡模型中,AUC為0.940 5、F2為0.894 5、Recall為0.881 6、Precision為0.950 4。
2.3.3 支持向量機模型

圖2 BP神經網絡epoch尋優過程

圖3 BP神經網絡隱含層節點數尋優過程
支持向量機(SVM)是一種應用廣泛的二分類機器學習算法,其基本思路是求解能夠正確劃分訓練數據集并且實現幾何間隔最大化的分離超平面。針對非線性及高維數據,SVM可利用核函數將原始空間的數據映射到高維空間,在新的特征空間完成分類,基本的SVM模型如下:

其中:w為法向量,ξ(i)為松弛因子,C為懲罰系數,C越高,對誤差容忍度越小,模型越容易過擬合。
本文使用在非線性分類中效果較好的高斯徑向基(rbf)核作為核函數,該核函數的表達式為:

其中:γ定義了單個樣本對整個分類超平面的影響,γ越大,越容易被選擇為支持向量。
本文對訓練集使用SVM算法進行訓練,利用網格搜索對初步模型中的懲罰系數C和γ進行調優,最終確定懲罰系數C的最優取值為1.2,γ為0.062,參數尋優過程如圖4、5所示優化后的模型中AUC為0.999 2、F2為0.911 6、Recall為0.942 9、Precision為0.804 9。
2.3.4 隨機森林模型

圖4 SVM中參數C尋優過程

圖5 SVM中參數γ尋優過程
隨機森林(Random Forest)是一種以CART決策樹作為基礎分類器、運用Bagging方法組合成多顆決策樹進行預測的集成學習算法。隨機森林模型集成了每棵決策樹的分類結果,并通過“投票”的方式輸出票數最多的分類結果作為最終預測結果。相較于決策樹而言,隨機森林通過引入隨機選擇屬性的方式有效地提高了模型的泛化能力。
本文對訓練集使用隨機森林算法進行訓練,并使用網格搜索對每棵樹的最大深度進行尋優,確定隨機森林中單顆樹的最大深度的最優取值為7,最終模型在測試集上的分類表現良好,AUC為0.999 8、F2為0.981 6、Recall為0.999 7、Precision為0.915 3。同時,本文得出了隨機森林模型中各個特征的重要性程度,由高到低依次為逾期次數、信用評級、累計逾期金額、標的類型、年利率、標的總額、投資人次、借款總額、信用額度、借款期限、待還本息、清償比率和公司規模,其余特征變量重要性均為接近于0。
2.4 模型比較
由表1可知,綜合來看,隨機森林模型的性能最好,CART決策樹次之,支持向量機和BP神經網絡分別位列三、四名。單獨來看,4種機器學習方法的AUC均在0.9以上,F2均在0.85以上,表明4種機器學習模型都可以對借款人是否會違約做出很好的判斷。此外,BP神經網絡模型的查準率最高,達95.04%,顯著高于其他3類模型,但召回率較低,僅為88.16%。隨機森林模型和CART決策樹模型的召回率較高,分別為99.97%和96.30%。
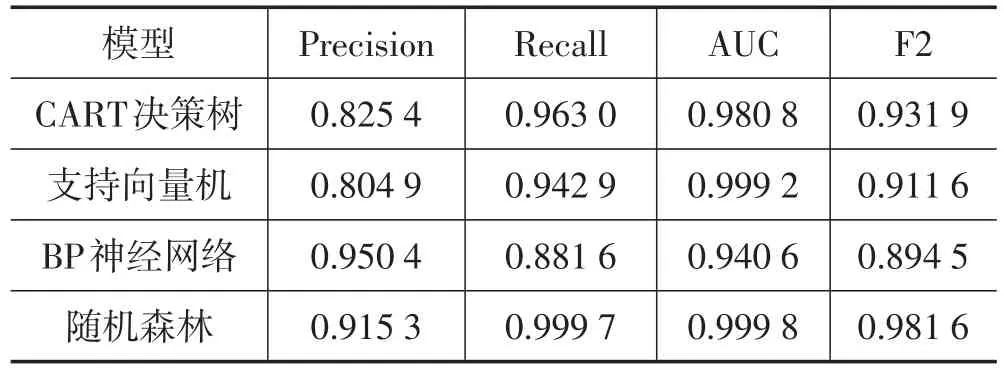
表1 4種模型性能比較
3 結語
本文以“人人貸”平臺借貸數據為例,對包含借款人基本信息、借款人信用信息和借款標的信息3個方面共30個特征變量的借貸數據,利用4種主流機器學習算法建立P2P網絡借貸借款人違約風險識別模型,并對各模型的性能進行對比,得出以下結論:
第一,機器學習算法在多維度借貸數據下的違約風險識別中適用性較強,各評價指標如AUC、F2等均較高,可以有效地利用借款人貸前數據預測借款人的違約情況。第二,相比于SVM和BP神經網絡模型,CART決策樹模型和以隨機森林為代表的集成學習方法在P2P網絡借貸違約風險識別中性能較優,可解釋性強,兩類樹模型的召回率均達到96%以上,F2達到93%以上,其中隨機森林模型綜合性能在4類模型中表現最優。第三,結合兩類樹模型,發現借款人信用評級、清償比率、累計逾期金額、借款期限、逾期次數這5個變量對違約的影響較大,年利率、標的類型、借款期限和標的總額等變量也會對違約產生影響。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
