
基于分塊的移動邊緣計算密文檢索方法
2020-08-02 05:09:36王娜鄭坤付俊松李劍
通信學(xué)報 2020年7期
王娜,鄭坤,付俊松,李劍
(1.北京郵電大學(xué)計算機(jī)學(xué)院,北京 100876;2.北京郵電大學(xué)網(wǎng)絡(luò)安全學(xué)院,北京 100876)
1 引言
隨著云計算應(yīng)用的逐漸普及,越來越多的企業(yè)和用戶選擇將數(shù)據(jù)存儲在云服務(wù)器上,云計算極大地方便了數(shù)據(jù)的存儲和使用[1-2],但是隨著時代的進(jìn)步,海量數(shù)據(jù)帶來的通信負(fù)擔(dān)和計算壓力使現(xiàn)有的云計算在很大程度上已經(jīng)不能夠滿足用戶的需求。與此同時,物聯(lián)網(wǎng)的崛起和5G 時代的到來,帶動了移動邊緣計算和霧計算的快速發(fā)展[3-8]。移動邊緣計算和霧計算通過在網(wǎng)絡(luò)的邊緣設(shè)置一些邊緣服務(wù)器,可以實現(xiàn)快速響應(yīng)用戶的需求或是提前進(jìn)行一部分?jǐn)?shù)據(jù)處理來減輕云服務(wù)器的通信負(fù)擔(dān)或者計算壓力。
移動邊緣計算上的密文檢索與云計算上的密文檢索大體上是相似的,不同之處在于邊緣計算環(huán)境下,若干個移動邊緣服務(wù)器分布在網(wǎng)絡(luò)的邊緣,數(shù)據(jù)使用者選擇最近的邊緣服務(wù)器發(fā)送查詢請求,由邊緣服務(wù)器負(fù)責(zé)計算文檔與查詢的相關(guān)性,將排好序的查詢結(jié)果返回給云服務(wù)器,云服務(wù)器再將對應(yīng)的加密文檔發(fā)送給用戶,這種方式減輕了云服務(wù)器的計算壓力。同云服務(wù)器一樣,邊緣計算也被認(rèn)為是半可信的、“誠實而好奇”的實體[5],云服務(wù)器上的數(shù)據(jù)隱私安全問題[9-11]在邊緣服務(wù)器上同樣存在,數(shù)據(jù)需要在上傳給云服務(wù)器、邊緣服務(wù)器之前進(jìn)行加密,這樣一來便限制了數(shù)據(jù)的使用[12-13],所以尋找一個可以應(yīng)用于移動邊緣計算的密文檢索方案是十分有必要的。
2 相關(guān)工作
現(xiàn)有的可搜索加密方案大多是基于云計算環(huán)境的研究,在移動邊緣計算上的方案很少。而邊緣計算可以認(rèn)為是云計算的拓展,所以本文方案主要是與現(xiàn)有的云計算上的可搜索加密方案進(jìn)行比較。
早些時候,可搜索加密方案集中在單關(guān)鍵詞檢索的研究[14-16],由于單關(guān)鍵詞的搜索結(jié)果過于粗糙,用戶為了獲得更加準(zhǔn)確的檢索結(jié)果,通常會輸入多個關(guān)鍵詞進(jìn)行檢索,尤其是在云計算的按使用收費(fèi)機(jī)制下,返回高相關(guān)性的文檔是有必要的,不僅節(jié)省了流量,也方便了用戶的使用,基于這些原因,支持多關(guān)鍵字排序的密文檢索方案陸續(xù)被提出。
Cao 等[17]提出了安全的、多關(guān)鍵字可排序的密文檢索方案(MRSE,multi-keyword ranked search over encrypted cloud data),該方法基于安全k 最近鄰(kNN,k-nearest neighbor)技術(shù)[18],利用可逆矩陣來加密索引和查詢向量,通過計算查詢向量與文檔向量的內(nèi)積得到文檔在本次查詢下的相似性得分,但該方法對每一個無關(guān)的關(guān)鍵詞都進(jìn)行了計算,在檢索效率上有改進(jìn)的空間。Sun 等[19]在此基礎(chǔ)上提出了基于多維B 樹的索引結(jié)構(gòu),使用貪婪的深度優(yōu)先搜索來加快檢索效率,但是該方法的檢索效率與查詢的關(guān)鍵詞分布情況有關(guān),當(dāng)關(guān)鍵詞分布在多維B 樹的底部時查詢效率嚴(yán)重退化,在一定程度上影響了數(shù)據(jù)使用者的體驗。Fu 等[20]提出了基于二叉樹的索引結(jié)構(gòu),該方法自下而上建樹,通過中間節(jié)點存儲輔助向量來標(biāo)識關(guān)鍵詞是否出現(xiàn),出現(xiàn)為1,未出現(xiàn)則為0,在檢索過程中排除不包含查詢向量的子樹,這種方法過濾掉了不包含查詢關(guān)鍵詞的文檔,只對包含查詢關(guān)鍵詞的文檔計算相關(guān)性得分,從而加快查詢。Xia 等[21]同樣提出了基于二叉樹的索引結(jié)構(gòu),該方法也是自下而上構(gòu)建索引樹,但中間節(jié)點存儲的是其孩子節(jié)點關(guān)鍵詞權(quán)值的最大值,在檢索過程中利用貪婪的深度優(yōu)先搜索過濾掉文檔的最大可能得分小于當(dāng)前閾值的子樹,以此加快檢索。這2 種基于二叉樹的檢索方法沒有考慮到文件之間的相似性,葉子節(jié)點是隨機(jī)放置的,因此在檢索效率上還有提升的空間。文獻(xiàn)[22-24]采用聚類的方法,利用基于k-means的方法自頂向下構(gòu)建層次聚類索引樹,該方法效率較高,但會存在一些檢索誤差。文獻(xiàn)[25-26]采用了兩段式的索引結(jié)構(gòu)來提升查詢效率,在查詢的第一階段篩選掉無關(guān)的文檔,在第二階段計算剩余文檔的相關(guān)性得分,效率較高,但在第一階段其檢索模式是“半保護(hù)的”,會暴露查詢陷門的隱私。文獻(xiàn)[27-29]引入了布隆過濾器來過濾不包含查詢關(guān)鍵詞的文檔,效率較高,但會有一定的誤差。
綜上所述,現(xiàn)有的各種檢索方案都是從過濾低相關(guān)性文檔的角度進(jìn)行改進(jìn)來提高檢索效率,而本文從過濾無關(guān)關(guān)鍵詞的角度進(jìn)行改進(jìn),提出一種分塊的多關(guān)鍵字排序密文檢索方案。本文的創(chuàng)新如下。
1) 由于只需要加密和發(fā)送包含查詢關(guān)鍵詞的分塊,與其他加密和發(fā)送整個字典長度的查詢向量方法相比,減少了數(shù)據(jù)使用者的計算開銷和通信開銷。
2) 通過分塊過濾掉大部分無關(guān)的關(guān)鍵詞,大幅減少了邊緣服務(wù)器計算文檔相似性得分時的計算量,提升了查詢效率。
3) 通過理論分析和仿真實驗,證明了所提方法在保證一定安全性的同時提升了查詢效率。
3 問題描述
3.1 系統(tǒng)模型
系統(tǒng)模型如圖1 所示,各部分功能介紹如下。
1) 云服務(wù)器
云服務(wù)器存儲數(shù)據(jù)擁有者上傳的密文文檔集合和對應(yīng)的加密后的索引,將索引分發(fā)給所有的邊緣服務(wù)器,接收邊緣服務(wù)器傳來的查詢結(jié)果索引號,將對應(yīng)的加密文檔發(fā)送給指定的數(shù)據(jù)使用者。
2) 邊緣服務(wù)器
邊緣服務(wù)器存儲云服務(wù)器傳來的加密后的索引,接收數(shù)據(jù)使用者傳來的查詢陷門,利用查詢陷門和索引計算出最相關(guān)的K個文檔索引編號,發(fā)送給云服務(wù)器。
3) 數(shù)據(jù)擁有者
數(shù)據(jù)擁有者擁有明文文檔集合F,基于明文文檔集合構(gòu)建可搜索加密索引I,對明文文檔加密得到密文文檔集合C,將加密后的索引I和密文文檔集合C上傳的云服務(wù)器,負(fù)責(zé)對數(shù)據(jù)使用者發(fā)放檢索密鑰和文檔解密密鑰。
4) 數(shù)據(jù)使用者
數(shù)據(jù)使用者從數(shù)據(jù)擁有者獲得密鑰,生成查詢陷門T,上傳查詢陷門給邊緣服務(wù)器,得到云服務(wù)器返回的K個文檔,利用數(shù)據(jù)擁有者發(fā)來的密鑰來解密文檔得到想要的明文文檔。
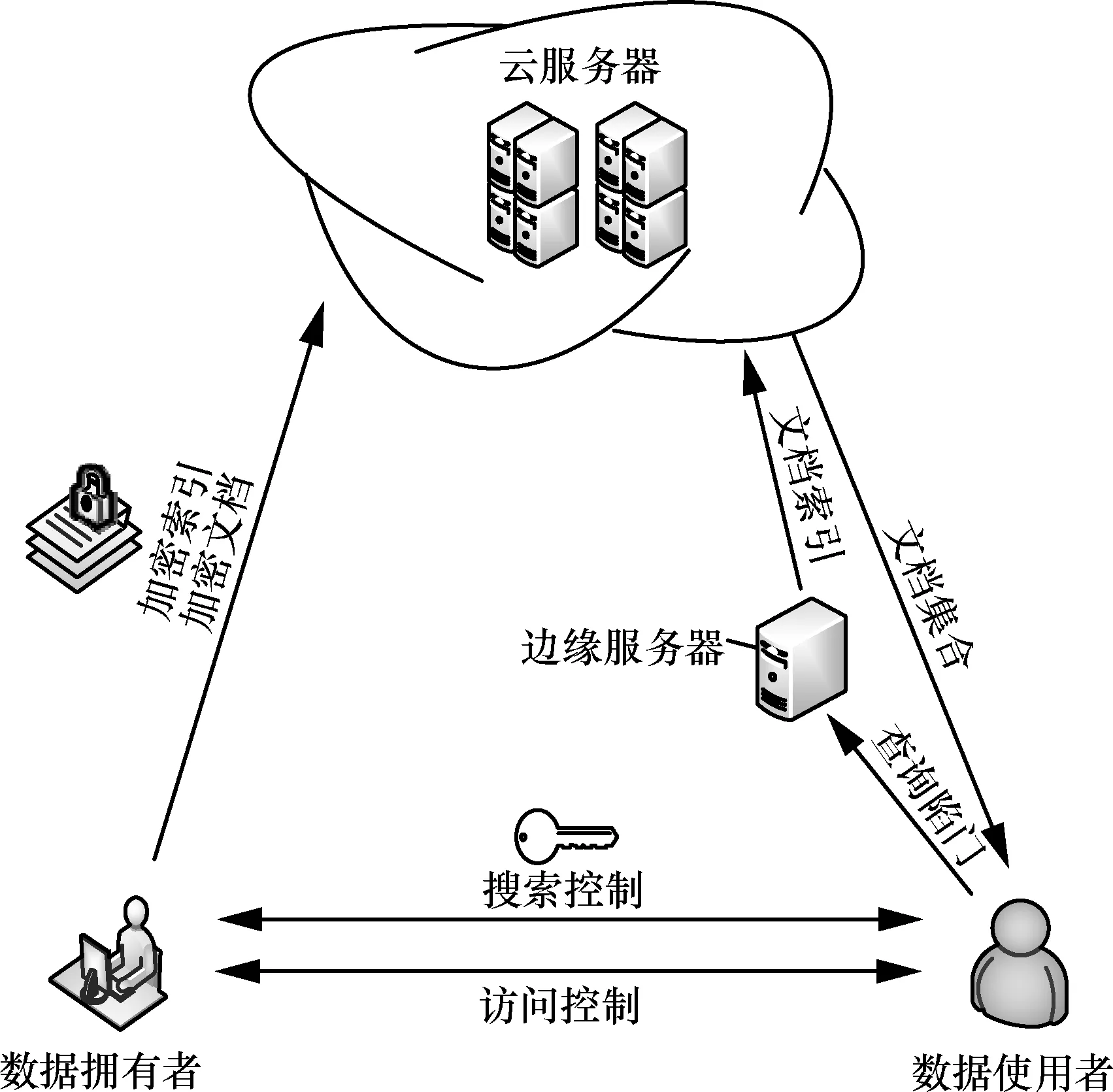
圖1 系統(tǒng)模型
3.2 威脅模型
本文假設(shè)云服務(wù)器和邊緣服務(wù)器是“誠實而好奇”的:服務(wù)器會按照規(guī)定執(zhí)行指定的操作,同時對存儲其上的數(shù)據(jù)和收到的查詢是好奇的,會試圖根據(jù)得到的信息進(jìn)行推理、分析文檔數(shù)據(jù)和用戶的隱私,但不會對數(shù)據(jù)進(jìn)行惡意篡改、破壞。
根據(jù)云服務(wù)器和邊緣服務(wù)器能夠獲得的有效信息,本文考慮以下2 種威脅模型。
1) 已知密文模型,云服務(wù)器能夠獲得密文文檔集合、密文索引。除此之外,云服務(wù)器不知道任何其他信息,云服務(wù)器只能發(fā)動密文攻擊。同樣,邊緣服務(wù)器只能獲得加密的查詢陷門,不知道其他信息。
2) 已知背景知識模型,在已知密文模型的基礎(chǔ)上,邊緣服務(wù)器還會根據(jù)用戶的查詢請求,統(tǒng)計分析用戶查詢記錄中的隱含信息,結(jié)合已有的相關(guān)背景知識,試圖挖掘出一些其他有用信息,如用戶的關(guān)鍵詞查詢偏好、關(guān)鍵詞被使用的頻率、文檔與關(guān)鍵詞之間的關(guān)聯(lián)關(guān)系等。
3.3 符號說明
表1 為本文主要符號說明。

表1 主要符號說明
4 預(yù)備知識
4.1 TF×IDF
TF×IDF 是一種統(tǒng)計方法,其中TF 是詞頻,表示關(guān)鍵詞出現(xiàn)的頻率,TF 值越大,說明關(guān)鍵詞在文檔中越具有代表性。IDF 是逆文檔頻率,計算方法是文檔總數(shù)除以包含該詞語的文檔數(shù)量,再將得到的結(jié)果取對數(shù),關(guān)鍵詞的IDF 值越大,意味著文檔集合中包含該關(guān)鍵詞的文檔數(shù)量越少,該關(guān)鍵詞就越具有區(qū)分性。
聯(lián)合使用TF 與IDF,可以避免單獨(dú)使用TF 導(dǎo)致一些不具有區(qū)分性的常用詞被賦予過高的權(quán)重,又可以避免單獨(dú)使用IDF 造成生僻詞或者噪聲詞被賦予過高的權(quán)重問題。
本文采用被廣泛應(yīng)用的歸一化的TF×IDF方法為每個文檔中的關(guān)鍵詞進(jìn)行評分,計算式為
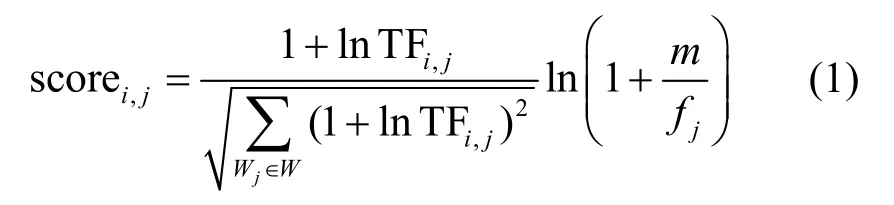
其中,scorei,j和TFi,j分別表示關(guān)鍵詞Wj在文檔Fi中的相關(guān)性得分和詞頻,fj表示包含關(guān)鍵詞Wj的文檔數(shù)量。
4.2 向量空間模型
向量空間模型(VSM,vector space model)由Salton 等[30]于20 世紀(jì)70 年代提出。VSM 利用向量表示文本,把對文本的處理轉(zhuǎn)化為向量空間中的內(nèi)積運(yùn)算。VSM 中向量的維度大小等于關(guān)鍵詞的長度,每一維度表示一個關(guān)鍵詞。VSM 中每個項的值表示關(guān)鍵詞在文檔中的權(quán)重。
通過VSM,2 個文件的相似度可以利用這3 個文件的向量夾角來衡量,夾角越小,相似度越高。查詢請求可以看作一個文檔,根據(jù)查詢的關(guān)鍵詞生成一個與向量空間維數(shù)相同的向量,通過比較查詢請求與所有文檔的相似度得到文檔與查詢的相似性得分,從而按照需求得到與查詢最相關(guān)的若干個文檔。對于查詢來說,除了通過比較向量的夾角偏差程度來計算相關(guān)程度外,還可以通過計算向量內(nèi)積來計算每個文檔與關(guān)鍵詞的相似性得分。有了上述的向量空間模型,文本數(shù)據(jù)就轉(zhuǎn)換成了計算機(jī)可以處理的結(jié)構(gòu)化數(shù)據(jù),文檔與查詢關(guān)鍵詞之間的相關(guān)性得分就轉(zhuǎn)換成了2 個向量的內(nèi)積結(jié)果。
本文使用了文獻(xiàn)[17]中的應(yīng)用于向量空間模型的基于安全kNN 技術(shù)[18]的安全內(nèi)積計算方案。這個技術(shù)可以使邊緣服務(wù)器通過加密的索引和加密的查詢陷門計算出陷門與每個文檔的明文相關(guān)性分?jǐn)?shù),有效地保護(hù)了服務(wù)器上索引和查詢的隱私。
5 本文方案
5.1 初始化
數(shù)據(jù)擁有者遍歷明文文檔集合F中的所有文檔,提取所有關(guān)鍵詞,去掉停用詞后得到關(guān)鍵詞字典W,長度為n。數(shù)據(jù)擁有者隨機(jī)生成一個長度為n+2、由0 和1 組成的向量S作為分裂指示器,再生成兩組可逆矩陣,每組前vh-1個矩陣大小為第vh個矩陣大小為,最終生成的密鑰為
5.2 構(gòu)建索引
數(shù)據(jù)擁有者為每個文檔Fi構(gòu)建一個長度為n的向量Di,向量的第j位是關(guān)鍵詞Wj在這個文檔中的TF×IDF 值,然后將向量Di擴(kuò)展至n+2維得到,其中第n+1位為隨機(jī)數(shù)ε,第n+2位為1,即。接下來,對根據(jù)分裂指示器S進(jìn)行隨機(jī)分裂得到2 個長度為n+2 的向量和,如果S[j]=0,則使???,否則使,然后將按照與密鑰相同的方式分割,得到和,并計算其與的乘積,最終得到加密后的索引
圖2 展示了構(gòu)建索引的過程,首先數(shù)據(jù)擁有者為每個文檔生成文檔-單詞矩陣,然后進(jìn)行分塊操作,得到分塊后的文檔-單詞矩陣,將分塊后的矩陣作為索引上傳給云服務(wù)器,云服務(wù)器將收到的索引分發(fā)給邊緣服務(wù)器。

圖2 構(gòu)建索引
5.3 生成查詢陷門

圖3 是生成查詢陷門的過程。數(shù)據(jù)擁有者首先根據(jù)查詢關(guān)鍵詞生成查詢向量,然后對查詢向量進(jìn)行分塊,同時生成列表L,將與查詢相關(guān)的塊號加入列表L中。接下來,將分塊后的向量加密并連同列表L一起上傳到邊緣服務(wù)器。

圖3 生成查詢陷門的過程
5.4 查詢
數(shù)據(jù)使用者將陷門上傳給邊緣服務(wù)器,邊緣服務(wù)器首先根據(jù)陷門中的L,找出對應(yīng)位置的索引塊,然后按照式(2)計算所有文檔的得分

圖4 是邊緣服務(wù)器上的文檔相關(guān)性分?jǐn)?shù)計算過程。數(shù)據(jù)使用者傳來的查詢請求包括了一組查詢向量塊和一個列表L,其中L=[1,3]表示本次計算文檔相關(guān)性分?jǐn)?shù)需要對塊1 和塊3 進(jìn)行計算,邊緣服務(wù)器收到查詢請求后,對索引的塊1和塊3 及對應(yīng)的查詢向量分別計算內(nèi)積,得到2 個內(nèi)積結(jié)果,再對內(nèi)積結(jié)果求和得到文檔的相關(guān)性分?jǐn)?shù)。
6 安全性分析
6.1 索引安全
索引安全指的是服務(wù)器無法根據(jù)加密后的索引推斷出文檔與關(guān)鍵詞之間的關(guān)聯(lián)關(guān)系。如果服務(wù)器能夠獲得文檔與關(guān)鍵詞之間的關(guān)系,那么服務(wù)器就能夠得知文檔中的一些信息,如果是短文本,甚至能夠推斷出整個文本內(nèi)容[31]。
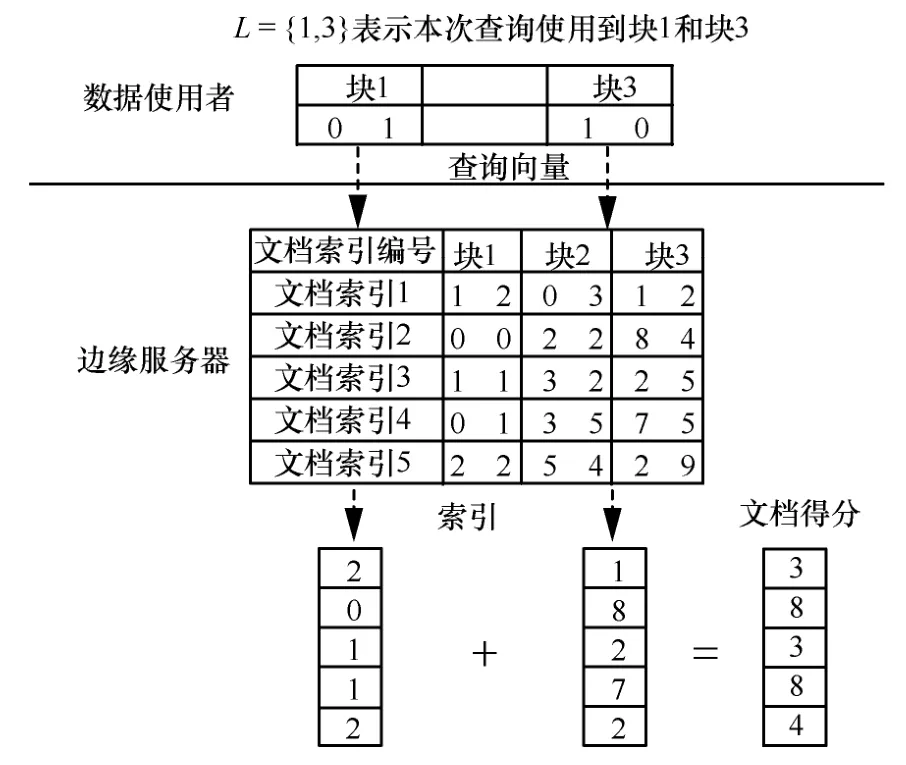
圖4 計算文檔相關(guān)性分?jǐn)?shù)
本文方法中存儲在邊緣服務(wù)器上的索引是2h個加密的矩陣,其密鑰是一個長度為n+2 的向量S和2h個矩陣。云服務(wù)器在不知道密鑰的情況下只能進(jìn)行窮舉攻擊,文獻(xiàn)[18]中已證明,在對稱加密中對稱密鑰長度超過80 bit 可以認(rèn)為是安全的。在本文方法中,如果使每個矩陣塊的維數(shù)為80,則對于每個矩陣塊來說都有一個長度為80 的向量和2 個80 ×80 的矩陣作為密鑰,由于2 個轉(zhuǎn)換矩陣的存在使維數(shù)為80 的矩陣塊的破解難度超過了普通的80 bit對稱密鑰的對稱加密。在這種情況下可以認(rèn)為本文方案能夠保證索引的安全性。
此外,由于本文的分割方法使最后一個分塊的維數(shù)可能很小,為了保證索引的安全性,可以人為地將最后一個分塊通過填充0 擴(kuò)充維度來滿足安全要求,這樣就可以在不影響查詢結(jié)果的同時保證整個索引的安全。
6.2 陷門的不可鏈接性
如果相同的查詢生成的陷門也是相同的,那么云服務(wù)器就能夠統(tǒng)計不同查詢請求出現(xiàn)的頻率,從而結(jié)合背景知識推斷出一些關(guān)鍵字。
綜上所述,云服務(wù)器不能推斷出兩次查詢的關(guān)系,從而保證了陷門的不可鏈接性。
7 效率分析及仿真實驗
本節(jié)分別對構(gòu)建查詢陷門效率和查詢效率進(jìn)行了理論分析和實驗驗證。實驗使用從網(wǎng)絡(luò)上爬取的中文語料作為數(shù)據(jù)集,使用Python 3 語言進(jìn)行仿真實驗。仿真實驗的硬件環(huán)境為 AMD Ryzen 5 3550H CPU,16 GB 內(nèi)存,Microsoft Windows 10 操作系統(tǒng)。
將本文方案與文獻(xiàn)[17,19,21]方案進(jìn)行比較,分別是MRSE 方案、基于多維B 樹的檢索方案和基于平衡二叉樹的檢索方案。實驗中將查詢的關(guān)鍵詞固定為10 個;文獻(xiàn)[19]方案中每層的索引向量固定為100 維,每層按照歐氏距離Ed ≤0.02進(jìn)行聚類;文獻(xiàn)[21]方法采用單線程實現(xiàn)。
7.1 構(gòu)建查詢陷門
由式(3)可知,構(gòu)建陷門是查詢的重要一環(huán),構(gòu)建陷門需要在用戶的本地進(jìn)行,會給用戶帶來一定的計算負(fù)擔(dān),通常來說性能較差的設(shè)備會對陷門構(gòu)建的時延更敏感,為讓盡可能多的用戶有良好的體驗,高效的構(gòu)建陷門是有必要的。

圖5 是本文方案與現(xiàn)有方案關(guān)于構(gòu)建陷門時間的比較。從圖5 可以看出,本文方案在構(gòu)建查詢陷門的效率上優(yōu)于其他方案,雖然文獻(xiàn)[19]中的分層操作與本文方案中的分塊方法類似,但其對所有層都進(jìn)行了加密,而本文方案只加密與查詢有關(guān)的塊,因此本文方案構(gòu)建陷門的效率更高。

圖5 構(gòu)建陷門時間隨字典內(nèi)關(guān)鍵詞數(shù)量的變化
此外,由于本文方案中數(shù)據(jù)使用者只需要上傳相關(guān)的分塊,比其他方法擁有更小的通信開銷。
7.2 計算文檔相似性得分
本文方案的查詢效率主要由計算文檔相似性得分決定。每個索引分塊的大小是ml,對應(yīng)的查詢向量是長度為l的向量,共有對這樣的分塊,所以查詢的時間復(fù)雜度為
首先對本文方案的查詢時間與索引塊數(shù)vh的關(guān)系在固定的文檔數(shù)量、字典長度和返回文檔數(shù)量下進(jìn)行實驗。從圖6 可以看出,本文方案的查詢時間隨著索引塊數(shù)的增加而減少。分塊數(shù)量越多,每個塊的長度就越小,云服務(wù)器計算文檔相似性得分時需要計算的次數(shù)越少,因此提升了查詢的效率。由此可知,分塊數(shù)越多查詢效率越高,而隨著分塊數(shù)量的增加,系統(tǒng)的安全性也會減弱,所以在實際應(yīng)用中,可以根據(jù)對查詢效率與安全性的不同需求來確定適宜的分塊數(shù)量。

圖6 本文方案計算文檔相似性得分時間隨索引塊數(shù)vh 的變化(m=3 000,n=5 000,K=100)
從圖7 可以看出,隨著文檔集合的增大,各種方法的查詢耗時都隨之增加。文獻(xiàn)[19]方案在文檔數(shù)量較大時表現(xiàn)較好,但該方案在構(gòu)建索引的過程中用到了聚類,對于給定的聚類閾值來說,文檔越多,聚類導(dǎo)致的效果提升越顯著,這樣做提升了效率但犧牲了一定準(zhǔn)確性。本文方案的計算文檔相似性得分的時間隨著文檔數(shù)的增加而線性增加,與分析結(jié)果一致。

圖7 計算時間隨文檔數(shù)m 的變化(n=5 000,vh=50,K=100)
圖8 是各種方案的查詢時間隨著字典內(nèi)關(guān)鍵詞數(shù)量的變化情況。實驗中將本文方案塊的維數(shù)始終保持為100,所以塊的數(shù)量隨著字典長度的增加而增加。從圖8 可以看出,隨著字典的增大,本文方案在保持塊大小不變、查詢關(guān)鍵詞數(shù)量不變的情況下查詢效率與字典長度無關(guān),而其他現(xiàn)有方案都是隨著字典的大小線性變化。這表明了本文方案的查詢效率與包含查詢關(guān)鍵詞的塊數(shù)和每個塊的塊長有關(guān),與字典長度無關(guān)。由此可以得出結(jié)論,本文方案比較適于字典維數(shù)很大的場景。

圖8 計算時間隨字典內(nèi)關(guān)鍵詞數(shù)量n 的變化(m=2 000,,K=100)
如圖9 所示,文獻(xiàn)[19]方案和文獻(xiàn)[21]方案受返回文檔數(shù)量的影響比較大,因為這2 個方案是樹形索引,采用基于貪婪的深度優(yōu)先搜索,K值越大,算法在搜索中剪枝的閾值就越小,排除的子樹越少,導(dǎo)致需要遍歷的樹范圍就越大;而文獻(xiàn)[17]方案和本文方案是先計算出所有文檔的相似性得分,然后再選出相似性得分最大的K個文檔索引。對于文獻(xiàn)[17]方案和本文方案而言,K值影響的是選出前K個文檔這一過程,實驗中采用的是利用快速排序的思想劃分出前K個文檔,這一步的時間復(fù)雜度是O(m),然后對這K個文檔進(jìn)行排序,所以總的時間復(fù)雜度是O(m+KlogK)。隨著K的增大,僅在排序前K個文檔的過程中增大了一些計算,因此本文方案的查詢時間受返回文檔數(shù)量的影響較小。

圖9 計算時間隨返回的文檔數(shù)量K 變化(n=5 000,vh=50,m=3 000)
8 結(jié)束語
針對傳統(tǒng)的云計算密文檢索方案難以滿足當(dāng)今用戶需求的問題,本文提出了一種基于分塊的移動邊緣計算密文檢索方案。引入了邊緣服務(wù)器來分擔(dān)云服務(wù)器的計算壓力。在改進(jìn)搜索效率上,不同于現(xiàn)有的方案從過濾低相關(guān)性文檔的角度進(jìn)行改進(jìn),本文從過濾無關(guān)關(guān)鍵詞的角度進(jìn)行了改進(jìn),為提高密文檢索的效率研究提供了新思路。理論分析表明,本文方案具有索引安全性和陷門不可鏈接性。通過實驗對本文方案與現(xiàn)有經(jīng)典方案的查詢效率進(jìn)行了多個方面的比較,結(jié)果表明本文方案相對于現(xiàn)有經(jīng)典方案有效地提高了查詢效率,并且字典維數(shù)越大提高效果越顯著。
