C 語言程序的理解與編譯優化
2020-08-07 14:44:38吳元斌
現代計算機 2020年18期
吳元斌
(重慶三峽學院計算機科學與工程學院,重慶404000)
0 引言
在多年的C 語言教學實踐中發現,不少初學者對C 語言中運算求值存在一些模糊認識。很多人認為C語言的算術表達式求值順序與數學中算術表達式的求值順序相同,即先乘除、后加減。C 語言標準規定了運算符間的優先級及同級運算的結合性[1],也是乘除運算的優先級高于加減運算,因此對于表達式a+b-c*d,其運算順序看起來是:*、+、-,但事實上并非如此。
一些習題包括一個變量多次自增(或自減)求和的表達式,如:(a++)+(a++)。C 語言并沒有規定這兩個自增運算與相加的求值順序。通常的理解是:先求左邊自增的值,再求另右邊自增的值,最后將兩個值相加,但實際上,有些編譯器進行了優化:先進行兩次自增,然后再將兩個a 相加。還有其它依賴于編譯器的問題,出現在習題或思考題甚至考試題中。這種情況是應該避免的,因此程序的運行結果是依賴于編譯器的,在不同的編譯器下運行結果可能不同。
為了清楚的理解C 語言教學中存在的一些編譯相關的問題,使初學者編寫與不依賴于編譯器的C 語言程序,本文將列舉一些典型的C 語言示例程序,給出了它們在集成開發環境Eclipse + MinGW GCC、LCCWin32 以及在Visual Studio 2019 下的運行結果對比。由于多數示例程序的運行結果存在一些差異,進一步展示、對照和分析了源程序在開源編譯器MinGW GCC和LCC 下目標程序的反匯編程序,目標程序的反匯編程序是利用Eclipse+MinGW GCC、LCC-Win32 兩種集成開發環境調試程序環境下得到的。本文還對編譯器翻譯算術表達式的基本思想進行說明,并分析編譯器在表達式運算求值順序實現中的具體差異。
1 示例源程序及其目標程序反匯編分析
1.1 算術表達式中運算的次序
算術表達式是用二元運算符+、-、*、/和圓括號連接起來的滿足語法和語義規則的式子,C 語言規定了其中運算符的優先級和結合性,如圓括號的優先級最高,之后是乘除,加減最低,同一優先級的兩個算術運算符的結合性是從左到右,但C 語言算術表達式中運算的次序不等同于數學中運算的次序。通過分析一些C 語言教材[2-4]中給出的容易引起模糊認識的示例,用下列典型程序段進行說明:
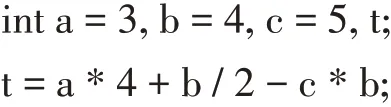
照數學運算規則,賦值語句右邊的表達式運算順序依次是:*、/、*、+、-,運算過程和結果可以表示為:a* 4 + b/ 2- c * b →12 + b/ 2- c * b →12 + 2 - c *b →12+2-20 →14-20 →-6。雖然C 語言程序中表達式的運行結果值也是-6,但運算次序與上述數學運算次序是不同的。編譯程序是用下面的文法對算術表達式進行了嚴格的定義,文法指明了運算符的結合性和優先級,算術表達式的文法為[5-6]:

其中非終結符E 表示一組以+號或-號分隔的項所組成的表達式;T 表示由一組以*號或/號分隔的因子所組成的項,F 表示因子,它是用括號括起來的表達式或標識符id。變量和常數被詞法分析程序歸類為標識符id。利用該文法生成上面表達式的語法樹是唯一的,如圖1 所示。

圖1 生成示例表達式的語法樹
其中,圖中的id 對應的變量或常量從左到右依次是a、4、b、2、c、b。通過語法制導翻譯(類似于語法樹自下而上或遞歸下降分析),上述表達式被翻譯成為每條指令最多一個運算符的指令序列[5]。將上述表達式計算的同一示例程序在兩種集成環境中調試視圖截圖(源程序及反匯編)如圖2 所示,左圖是Eclipse+Min-GW GCC,右圖LCC-Win32,兩個子圖的上面部分都是源程序,下面都是目標程序的反匯編程序。左、右兩圖放在一起是便于對比分析(下面示例都采用這種方式)。
其中左圖中最后用紅色邊框包括的列為手工添加的代碼說明,右圖的反匯編用圓括號包含了變量名。兩種編譯器采用的指令不完全相同,左圖中除法比右圖的實現復雜,詳細分析可見文獻[7]。可以看出,兩個編譯器處理表達式的運算次序相同的,它們的次序都是:*、/、+、*、-,顯然與數學運算規則不同。這個運算次序也就是圖1 中的語法樹按運算符從下到上、從左到右得到的運算次序。
實際上,C 語言算術表達式求值中在處理當前運算符時,要與其右邊相鄰的運算符進行比較,若當前運算符高于其相鄰右邊的運算符,或者它們的優先級相同,且結合性是從左到右,則完成當前運算,否則先處理其右邊相鄰的運算,其右邊相鄰的運算也要處理方法也是相同的,如此等等,直到所有運算完成。編譯器自下而上的翻譯法在表達式最后添加了一個運算符$(優先級最低)運算符[5-6],它就沒有右邊相鄰的運算符了。
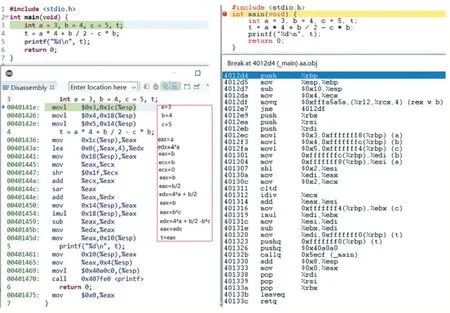
圖2 兩種編譯器表達式運算次序相同
1.2 表達式運算次序的副作用
很多時候無論是按數學運算次序還是按編譯程序指定的次序運算,算術表達式的值是相同的,看起來不用區分C 語言表達式的運算次序,但并不總是這樣。當表達式中存在項與項之間的值存在依賴關系時,結果就可能不同,如將上面的程序段修改為:

所作的修改只是將上例的表達式最后一項改為(b=2),由于第2 項中的b 與最后一項的b 存在依賴關系,編譯器MinGW GCC 與LCC 對表達式的優化處理不同,程序在兩種環境下的運行結果不同,分別為4和3,在Visual Studio 2019 下運行的結果也為3。
該程序在MinGW GCC 與LCC 編譯反匯編對比如圖3 所示,分析發現LCC 編譯器中b 賦值為2 的指令被提前,MinGW GCC 則沒有,兩條指令分別用紅色方框標出,表達式中其它的運算次序還是與上例相同。可見,兩種編譯器只是對“(b=2)”的處理不同,在LCC環境下表達式中所有b 的值都是2,而在MinGW GCC環境下只是最后的b 的值為2,因此導致了程序的運行結果不同,所以該程序的運行結果完全依賴于編譯環境。

圖3 兩種編譯器對運算次序優化存在差異
1.3 函數實參的求值順序處理
C 語言也沒有指定函數各參數的求值順序[1]。在函數調用時,有的編譯器是從左到右,有的則是從右到左。參考文獻[3]有一個類似于下面的程序段:
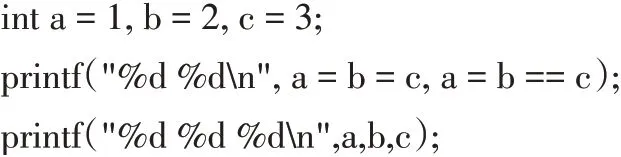
通過在MinGW GCC 與LCC 下運行程序后發現,第1 個輸出語句的運行結果不同,分別為“3 3”和“3 0”,而第1 個輸出語句在Visual Studio 2019 下運行的結果為“3 3”。三種環境下第2 個輸出語句的結果為“3 3 3”,即變量a、b、c 的值最后都是3,這說明在三種環境下編譯器的求值順序都是從右到左。由于第1 個輸出存在差異,為了找出問題的原因,將該程序在Min-GW GCC 與LCC 編譯反匯編進行對比,如圖4 所示。
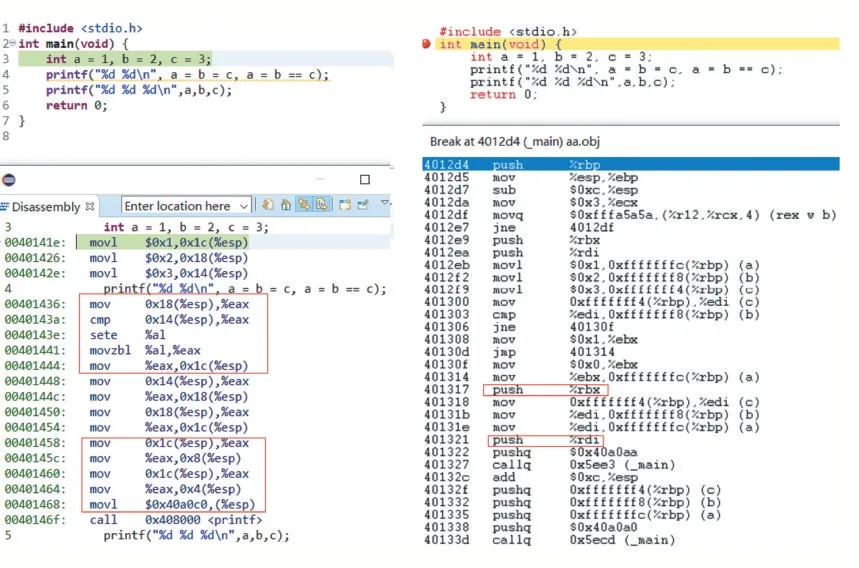
圖4 兩種編譯器對實參求值的處理不同
分析圖4 發現,兩種編譯器都是先計算右邊的參數(左圖中第1 個加框的部分為第1 個參數的求值,右圖中為第1 個加框指令的前6 條指令),然后計算左邊的參數。但是它們處理值的方式不同,對MinGW GCC環境中,printf 輸出的是變量a 的最終值(左圖第2 個加框部分)。但在LCC 環境中是將兩個實參的值分別保存在寄存器rbx、rdi 中,計算一個保存一個(右圖中兩個加框指令),rbx 的值為0,rdi 的值為3。可見盡管都是從右到左計算函數實參,但形參的值卻不同,程序的執行結果也依賴于編譯程序,只有仔細分析它們的反匯編程序,才能搞清楚其中的原因。
1.4 自增自減運算的副作用
函數調用、嵌套賦值語句、自增與自減運算符都有可能產生“副作用”—在對表達式求值的同時,修改了某些變量的值[1]。一些C 語言教材的練習中常常包含類似于下面的程序段:
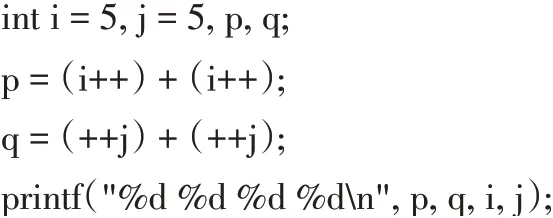
上述程序在MinGW GCC 和LCC 下下的運行結果分別為“11 14 7 7”和“11 13 7 7”,在Visual Studio 2019下的運行結果為“11 14 7 7”。可見輸出結果存在差異,為了找出問題的原因,將該程序在MinGW GCC 與LCC編譯反匯編進行對比,如圖5 所示。

圖5 兩種編譯器對自增運算處理不同
在圖5 中,分別對兩種環境下相關指令功能進行了說明(紅色框線中)。可以看出,兩種環境下對后綴的自增運算處理相同,即先累加,再自增,再累加,再自增,累加的結果都是11。但對于前綴的自增運算處理則不同,在MinGW GCC 下前綴的自增運算被優化(在加法運算前進行),而在LCC 下前綴的自增運算則不同,并沒有優化,所以前綴的自增運算相加的結果不同,分別為14 和13。因此一個變量多次自增(或自減)求和表達式的值也依賴于編譯器。
2 結語
本文討論了C 語言教學中一些容易引起初學者產生模糊認識的典型問題,通過不同編譯環境對目標程序的反匯編對照與分析,能夠清楚地看到這些程序的運行結果依賴于編譯器,不同編譯器可能產生不同的結果。這樣的問題還很多,雖然初學者也不一定能夠理解這些分析及編譯原理的具體細節,但教學中應該讓他們知道編寫依賴于編譯器的程序是不好的習慣。在任何一種編程語言中,如果代碼的執行結果與求值順序有關,則都是不好的程序設計風格。很自然,有必要了解哪些問題需要避免,但是,如果不知道這些問題在各種機器上是如何解決的,就最好不要嘗試運用某種特殊的實現方式[1]。因此,C 語言教學一個很重要的工作是讓學生學會正確的編程方法,培養良好的編程習慣[2],避免編寫執行結果依賴于編譯器的C 語言程序。
猜你喜歡
文苑(2020年4期)2020-05-30 12:35:30
人大建設(2019年12期)2019-05-21 02:55:44
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
中山大學法律評論(2018年1期)2018-03-30 01:21:00
瞭望東方周刊(2017年42期)2017-12-05 18:49:38
瘋狂英語·新策略(2017年8期)2017-05-31 08:13:46
環球時報(2017-03-30)2017-03-30 06:44:45
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
中國衛生(2015年3期)2015-11-19 02:53:32
少兒科學周刊·少年版(2015年4期)2015-07-07 21:11:17
