基于循環神經網絡的花兒信息模型建模方法
2020-08-13 07:17:51趙吉山王青海
軟件 2020年6期
趙吉山 王青海
摘 ?要: “花兒”是一種流傳在青海、甘肅兩省、寧夏回族自治區以及新疆個別地區的山歌,被譽為大西北之魂,是國家級人類非物質文化遺產,2009年9月被聯合國列為人類非物質文化遺產。隨著網絡技術及機器學習的迅猛發展,對“花兒”信息的網絡傳播和深度挖掘至關重要。對此,筆者提出利用機器學習自然語言處理(Machine Learning-Natural Language Processing)來進行花兒唱詞信息挖掘。通過構建循環神經網絡(Recurrent Neural Network,RNN)青海花兒模型,展開對花兒唱詞的數據挖掘,并且實現Python內置語言模塊與動態網頁互聯,能為花兒藝術研究者及民間花兒藝術愛好者提供有效且高質量的花兒信息。利用RNN進行花兒唱詞挖掘是一個非常有意義的研究課題,對未來花兒藝術的發展和傳承具有重大的作用。
關鍵詞: 循環神經網絡;青海花兒;信息挖掘;動態網頁
中圖分類號: TP389.1 ? ?文獻標識碼: A ? ?DOI:10.3969/j.issn.1003-6970.2020.06.004
本文著錄格式:趙吉山,王青海. 基于循環神經網絡的花兒信息模型建模方法[J]. 軟件,2020,41(06):1923
【Abstract】: “Huaer” is a folk song spread in Qinghai、Gansu Province、Ningxia and some areas in Xinjiang. It is known as the soul of the Northwest and is a national intangible cultural heritage. Human intangible cultural heritage. With the rapid development of network technology and machine learning, it is very important for the network dissemination and deep mining of Huaer information. In this regard, the author proposes to use Machine Learning- Natural Language Processing to perform flower singing information mining. By constructing a Recurrent Neural Network (RNN) Qinghai Huaer model, the data mining of Huaer chanting is carried out, and the built-in language module of Python is interconnected with dynamic web pages, which can be a flower art researcher and folk flower art hobby Provide effective and high-quality Huaer information. The use of RNN for the mining of Huaer lyrics is a very significant research topic, and it will have a significant effect on the development and inheritance of Huaer art in the future.
【Key words】: Recurrent neural network; Qinghai huaer; Information mining; Dynamic webpage
0 ?引言
伴隨著計算機技術的不斷發展,國外及國內的網民獲取信息的速度更加迅速,人們日益增長的精神文化需求越來越高,青海花兒民間愛好者及花兒研究者急需獲取有效、全面、及數據規模較大的花兒信息。目前世界文化正處在大發展時期,各種思想文化交流交融更加頻繁,文化在綜合國力競爭中的作用及地位更加凸顯,作為中華民族傳統文化中的一部分,青海花兒的發展與傳播在當下也是不可或缺的。對此,筆者利用計算機技術的優勢,分析本地區特色文化——青海花兒,通過研究青海花兒的發展狀況得出:互聯網上對于花兒信息的收錄量很少,內容不完整、不全面、且收集困難。花兒作為本地區特有的藝術,其有很大的發展空間,并且在傳承及發揚的過程中收到資源限制,因此,青海花兒信息的研究在當下更顯必要性和緊迫性。
1 ?RNN與PHP概述
1.1 ?RNN
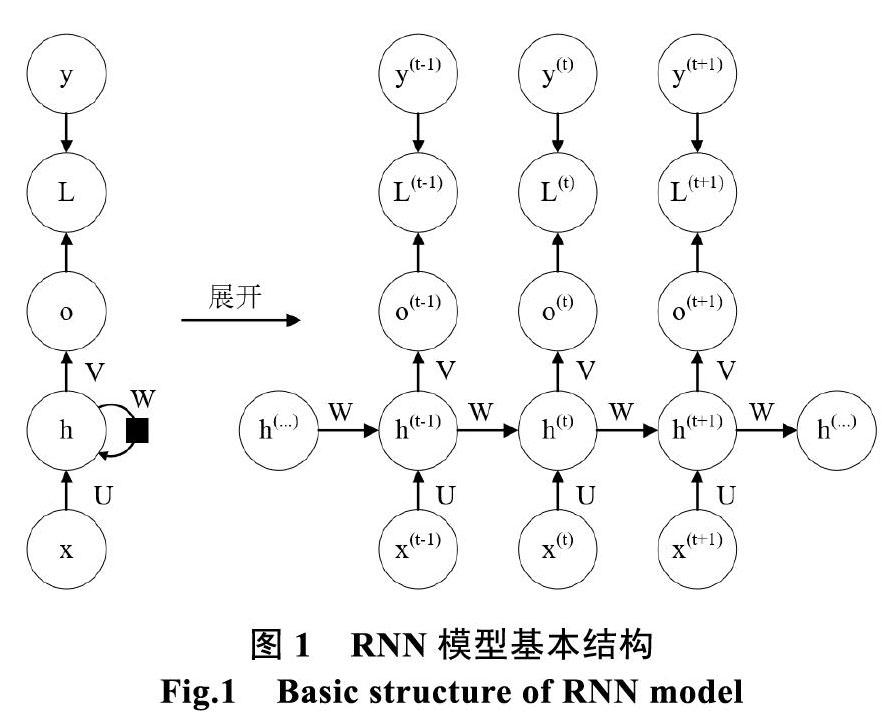
RNN是一類專門用于處理序列x(1)、x(2)、...x(t)的神經網絡。RNN可以擴展到更長的序列,大多數的RNN也能處理可變長度的序列。它以不同的方式共享參數,輸出的每一項是前一項的函數,輸出的每一項對先前的輸出應用相同的更新規則產生[1]。RNN可應用于跨越兩個維度的空間數據,當某個應用涉及時間的數據,并且將整個序列數據提供給網絡之前就能觀察到整個序列時,RNN可具有關于時間向后的連接[2]。主流的循環神經網絡模型的基本結構如圖1所示。
圖1.1左半部為沒有按時間展開的RNN模型基本結構圖(圖中黑色方塊表示單個時間步的延遲),右半部為按時間展開的圖。在結構圖中,對于每個時間步t,一般的作如下表示:
(1)x(t)表示在時間步t時訓練樣本的輸入。而x(t–1)、x(t+1)分別表示在時間步t–1、t+1時訓練樣本的輸入。
(2)h(t)表示在時間步t時隱藏層的激活函數。h(t)由x(t)、h(t–1)共同決定,一般二分問題采用sigmoid函數,K類別分類問題采用softmax函數。
(3)o(t)表示在時間步t時模型的輸出。o(t)只由模型當前的隱藏狀態h(t)決定。
(4)L(t)表示在時間步t時模型的損失函數,損失函數L(t)表示輸出值o(t)與相應訓練目標y(t)的長度[3]。
(5)y(t)代表在時間步t時訓練樣本序列的目標輸出。輸入層到隱藏層、隱藏層到輸出層、隱藏層到隱藏層的連接分別由權重矩陣U、V、W參數化。
1.2 ?PHP
PHP:Hypertext Preprocessor(簡稱PHP)是一種通用編程語言,最初為動態網頁開發而設計。語法吸收了C、Java和Perl語言的特性,語法簡單利于學習,在互聯網動態網頁開發技術當中應用廣泛,主要適用于網頁開發領域。PHP獨特的語法混合了C、Java、Perl以及PHP自創的語法。它可以比CGI或者Perl更快速地執行動態網頁。用PHP做動態頁面和其他的編程語言相比,PHP是將程序嵌入到HTML中去執行,執行效率比完全生成HTML標記的CGI要高許多[4]。PHP還可以執行編譯后代碼,編譯可以達到加密和優化代碼運行,使代碼運行更快。
2 ?python內置模塊與動態網頁互聯
Python是一門解釋型的編程語言,因此它具有解釋型語言的運行機制[5]。迄今為止Python由于其可擴展性、跨平臺等特性相較于其他語言擁有諸多的優勢,python的可擴展性體現為它的模塊,其強大的類庫為機器學習等計算機前沿學科提供了有效的幫助。本次實驗涉及的Python模塊包括應用于文本中自動提取語義主題的Gensim模塊和Python標準庫中的sys、os、time、json、process、和網絡模塊socket等等。
Gensim是一款開源的第三方Python模塊,用于從原始的非結構化的文本中,無監督地學習到文本隱層的主題向量表達[6]。它支持包括TF-IDF、LSA、LDA、和word2vec在內的多種主題模型算法,支持流式訓練,并提供了諸如相似度計算,信息檢索等一些常用任務的API接口。在本實驗中我們采用Word2vec,Word2Vec是Google公司推出的用于獲取詞向量的工具,該工具內部算法通過深度學習實現詞到向量的轉化。Word2vec模型輸出的詞向量可以被用來做很多自然語言處理的相關工作,比如聚類、找同義詞、詞性分析,預測等[7]。
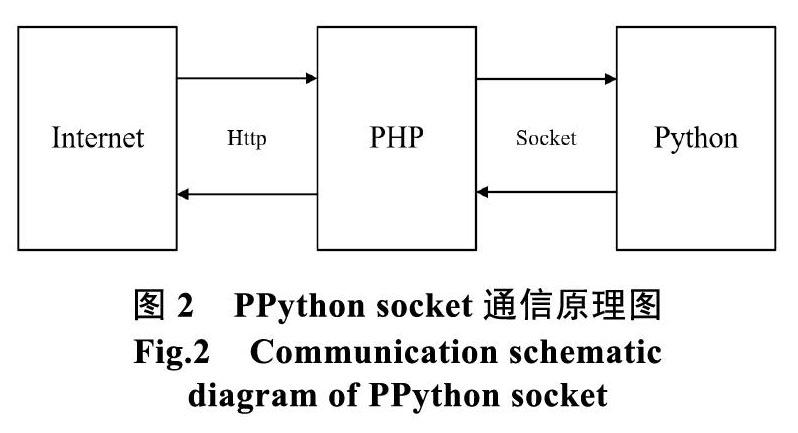
本實驗采用Google公司開源項目PPython實現Python與動態網頁互聯,其實現對兩種語言的優勢互補,結合使用Python程序和PHP程序,可理解為Python語言和PHP語言相結合的技術,通俗的可以理解為Python語言和PHP語言混編技術。Python和PHP語言各有其內部定義的數據類型,當PHP端數據發送到Python端或者Python端數據發送到PHP端時在傳統技術上需要轉碼處理,而PPython技術通過將Python和PHP不同數據類型序列化就可以直接發送數據,不用進行轉碼處理,大大提高開發速度。Python語言因其GIL(Global Interpreter Lock)特性,多線程效率不高,在基于由Python程序和PHP程序的混編機制實現的PPython中,Python端可進行多進程方式部署,從而提高Python程序的整體工作效率,此技術提高了Python的多線程效率。PPython技術實現基本原理為socket通信,因此需要網絡模塊socket支持。socket(套接字)是網絡編程中的一個基本組件,套接字基本上是一個信息通道,兩端各有一個程序[8]。這些程序可能都位于(通過網絡相連的)不同的計算機上,通過套接字向對方發送信息。PPython中網絡通信的主要原理如圖2所示。
3 ?基于RNN的青海花兒模型構建
3.1 ?Python爬蟲構建
循環神經網絡模型的構建對數據量有較高的要求,因此本實驗所用的花兒唱詞信息采用Python網絡爬蟲技術獲取。利用爬蟲技術可以快速、準確的從WEB應用中獲取花兒唱詞信息,為后續實驗的進行提供數據支持。Python網絡爬蟲的構建是模擬計算機網絡連接,即計算機對服務器進行一次Request請求(帶著請求頭和消息體),相應地服務器對于計算機的Request請求進行Response回應(帶著HTML文件)。爬蟲程序模擬計算機對服務器發起Request請求,并且接受服務器端的Response內容并解析、提取所需的信息。
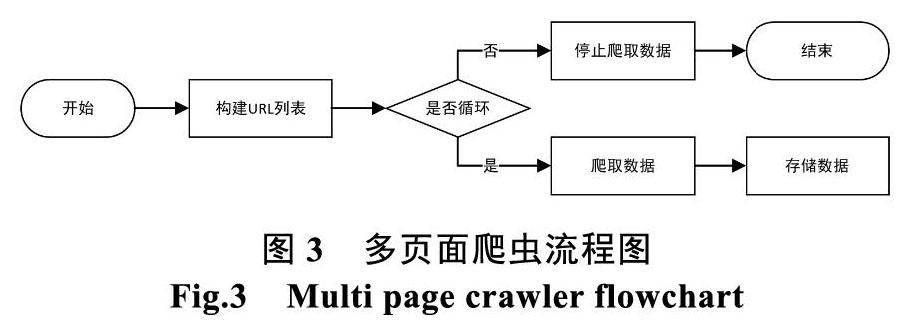
筆者通過分析花兒信息源,發現現有的花兒信息主要分布在WEB應用網易云音樂、QQ音樂上。對此根據不同平臺WEB頁面的結構,相應的進行爬蟲程序的設計。通過分析,網易云音樂WEB頁面結構為多頁面網頁結構,這種類型的網頁爬蟲流程為。
(1)手動翻頁觀察個網頁的URL構成特點,構造出所有頁面的URL存入列表中。
(2)根據URL列表依次循環取出URL。
(3)定義爬蟲函數。
(4)循環調用爬蟲函數,存儲數據。
(5)循環完畢,結束爬蟲程序。
多頁面爬蟲流程圖如圖3所示。
而QQ音樂WEB頁面結構為跨頁面網頁結構,跨頁面的爬蟲流程為。
(1)定義爬取函數爬取列表頁的所有專輯的URL。
(2)將專輯URL存入列表中。
(3)定義爬取詳細頁數據函數。
(4)進入專輯詳細頁面爬取詳細頁數據。
(5)存儲數據,循環結束,結束爬蟲程序。
跨頁面爬蟲流程圖如圖4所示。
本實驗獲取到的所有花兒唱詞數據保存在文本文件中,以便后續處理。
3.2 ?唱詞分詞
中文與英文相比,英文以空格作為非常明顯的分隔符,而且一個英文單詞橫向可按字母拆分,但是中文由于繼承自古代漢語的傳統,詞語之間沒有分隔符,并且按“永字八法”分為點、橫、豎、撇、捺、折、彎、鉤8種。古代漢語中除了人名、地名和連綿詞等,詞通常就是單個漢字,所以當時沒有分詞書寫的必要。而現代漢語中雙字或多字詞居多,一個字不再等同于一個詞[9]。因此給中文分詞帶來難度。為了得到更加有效的實驗數據及更為嚴謹的實驗結果分析,對于花兒唱詞采用目前主流的分詞工具jieba分詞。通過分詞工具jieba將爬取到的花兒唱詞進行去噪處理,并且剔除唱詞中含有的“,”、“。”、“_”、“《”、“》”、“[”、“]”、“(”、“)”、等特殊字符。分詞結束后即可得到可以用于訓練的預料庫,此后進行RNN模型的訓練。
3.3 ?系統建模
語料庫規模越大,模型的訓練結果就越好,而對于規模較小的語料則相反。模型訓練需要Python NLP gensim包,首先需要安裝gensim,但是gensim對科學技術庫NumPy和SciPy的版本有要求,需要注意NumPy和SciPy版本,當導入時算法程序不出錯則成功。在genism中,與訓練算法相關的參數都在gensim.models.word2vec.Word2Vec中。需要注意的參數有。
(1)sentences:此參數設置當前需要分析的語料庫,可以是序列、字符文件。在本實驗中,采用文件遍歷讀取。
(2)size:此參數設置詞向量的維度,默認值是100。這個維度的取值一般與當前所使用的語料的規模相關,如果語料庫很小,比如小于100M的文本語料,則使用默認值。如果語料庫規模較大,則增大維度。
(3)window:此參數為詞向量上下文最大距離,window越大,則和某一詞較遠的詞也會產生上下文關系。默認值為5。在實際使用中,可以根據實際的需求來動態調整這個參數的大小。如果是小語料則這個值可以設的更小。
(4)sg:此參數為word2vec兩個模型的選擇。如果是1,則是Skip-Gram模型,是0則是CBOW(Continuous Bag-of-Words)模型,默認參數值為0。
(5)hs:此參數為word2vec兩個解法的選擇,如果參數值是1,并且負采樣個數negative大于0,則是Hierarchical Softmax。參數值為0,則是Negative Sampling。默認參數值為0。
(6)negative:此參數為使用Negative Sampling時負采樣的個數,默認是5。推薦在[3,10]之間。
(7)cbow_mean:此參數為用于CBOW在做投影的時候,為1則為上下文的詞向量的平均值。為0,則算法中的xw為上下文的詞向量之和。在本文中采用平均值來表示xw,默認值也是1,不推薦修改默認值。
(8)min_count:此參數為需要計算詞向量的最小詞頻。添加此參數,可去掉生僻的低頻詞,默認是5。語料庫太小,則調低這個值。
(9)iter:此參數為隨機梯度下降法中迭代的最大次數,默認是5。對于規模較小的語料庫,可以調小這個參數值,相應的規模較大的語料庫,可以增大這個參數值。
(10)alpha:此參數為在隨機梯度下降法中迭代的初始步長,默認是0.025。
(11)min_alpha:由于算法支持在迭代的過程中逐漸減小步長,min_alpha給出了最小的迭代步長值。
模型的訓練調用word2vec.Word2Vec()算法即可,對于不同規模的語料庫,需要對算法參數進行調整,才能達到更好的訓練結果。當模型訓練完成以后,需要保存模型以便重用。在word2vec中模型的保存有兩種方式可供選擇,一種是直接保存模型,另一種是以C語言可以解析的形式存儲,對此根據需求保存。
此外,模型訓練的速度受到訓練程序運行環境和語料庫規模的影響。當語料庫特別龐大時,性能更為優良的計算機能更快的進行模型的訓練。
4 ?RNN花兒唱詞挖掘
4.1 ?挖掘結果
本實驗模型的訓練屬于無監督學習,并沒有太多的類似于監督學習里面客觀的評判方式,更多的依賴于端應用。利用RNN對青海花兒信息處理,實現對花兒唱詞信息進行聚類、找同義詞、詞性分析、預測。word2vec語言模型性能較高,但由于其對數據量有很高的要求。由于花兒信息搜集困難,預測的準確度不夠高。實驗部分結果如下:
4.2 ?挖掘分析
本實驗采用循環神經網絡,這是為了綜合運用歷史信息中的正向信息和反向信息所設計的優秀的神經網絡,在數據采集上,由于青海花兒的歷史屬性及文化背景限制,筆者所搜集的花兒信息有限,加之神經網絡對語料庫規模的要求較高,訓練結果的正確性有待提高,需要將語音識別技術把現有的花兒視頻、音頻的語音信號轉化為相應文本或命令來獲取大量花兒數據更為理想。
4.3 ?詞云生成
作為青海傳統文化——青海花兒,提取花兒唱詞關鍵內容形成詞云,詞云的生成對詞進行排序后,由于詞語過多,僅截取了前300個高頻詞,詞云如圖5所示,觀察詞云圖可知:“花兒”(圖5的中心位置)這個詞的詞頻最高,其他詞根據詞頻依次從原點展開分布在各點。
5 ?結論
本文通過循環神經網絡序列建模,將深度學習自然語言處理應用于青海花兒信息挖掘當中。在實驗中發現許多有趣的特性,分析挖掘青海花兒文本信息的原理同樣的可以應用到很多方面,人工智能的發展會給我們帶來更多的機遇,我們也會面臨著更多的挑戰。合理有效的利用好計算機技術能為我們人類的方方面面帶來便利,例如語音識別、DNA序列分析、情感分類、機器翻譯、命名體識別等。實驗中在青海花兒信息搜集過程中出現了些許困難,更大規模的語料庫及優化RNN內部網絡架構能更加有效地分析花兒信息。如何通過語音識別、視頻行為識別技術的輔助來獲取數據規模更大的語料庫,及優化網絡內部架構是下一部研究的問題。
參考文獻
[1] The Unreasonable Effectiveness of Recurrent Neural Networks. http://karpathy.github.io/2015/05/21/rnn-effectiveness/.
[2] 邵偉明, 葛志強, 李浩, 等. 基于循環神經網絡的半監督動態軟測量建模方法[J]. 電子測量與儀器學報, 2019, 33(11): 7-13.
[3] 余萍, 曹潔. 深度學習在故障診斷與預測中的應用[J/OL]. 計算機工程與應用: 1-25 [2020-02-17].
[4] [美] Luke Welling, Laura Thomson. PHP and MySQL Web Development[M]. 慧珍, 武欣, 羅云峰, 等譯. 北京: 機械工業出版社, 2018: X—XIV.
[5] 林信良. Python程序設計教程[M]. 北京: 清華大學出版社, 2017: 2—6.
[6] 唐曉麗, 白宇, 張桂平, 等. 一種面向聚類的文本建模方法[J]. 山西大學學報(自然科學版), 2014, 37(04): 595-600.
[7] 丁璐璐. 基于信息覓食理論的智庫情報分析質量及其提升策略研究[D]. 吉林大學, 2019.
[8] 董彧先. 基于Python的網絡編程研究與分析[J]. 科學技術創新, 2019(20): 85-86.
[9] 成銳. 基于Lucene面向主題的手機搜索引擎的研究與實現[D]. 電子科技大學, 2012.
