基于語料庫的兼類詞隱性知識挖掘研究
2020-08-14 09:58:31盛玉麒
現代語文 2020年5期
盛玉麒
摘 ?要:運用基于語料庫的知識挖掘方法,采用“二級標注”模式獲得詞類次范疇的類型信息,深入挖掘現代漢語兼類詞的隱性知識,期待為語言教學與研究、語言信息處理、網絡輿情分析等諸多領域的理論與實踐提供積極的參考。
關鍵詞:語料庫;兼類詞;隱性;知識挖掘
一、語言研究的語料庫轉向
(一)網絡時代新趨勢
一個轉向(哲學的語言學轉向)和兩個革命(信息革命和語言學革命)引起了語言學研究范式的語料庫轉向。基于語料庫的知識挖掘幾乎涵蓋了所有基礎科學和應用學科。各種與人類活動相關的行為和心理情感傾向,都可以從語言交際、言語行為、話語方式中發現端倪和深層次的信息。
網絡對人類社會活動的多維度映射,構建出豐富多彩、生機勃勃的認知世界,成為獲取信息、知識的廣域資源庫。語言學的實證主義研究路線獲得了無比充分的海量語料,幾乎可以從任何一個角度、定量分析、探索解決任何復雜性問題。
(二)“約定俗成”的背后
語言是一個音義結合的交際符號系統。“音義結合”是語言的心理認知屬性,“交際”是語言的社會功能屬性,“符號”是語言的編碼屬性,而“系統”則是語言的組織結構屬性。
對于所有使用母語的人來說,都是在幼兒階段(語言習得關鍵期),就毫不費力地“獲得”了母語的“聽說”能力,詞匯句法語義,甚至包括常用的語用規則。3-5歲的兒童所獲得的母語能力,可以終生享用的同時,也在習焉不察中“獲得”了母語“賦予”的認知、思維、邏輯、文化等“模式”或“模態”,并且非常牢固地將這些“內化”為“習慣”。
這一現象可以從心理學的“獲得性無助”假說得到令人信服的解釋。因此,“習慣”了的語言又具有了“制度性”特征——只能服從其規則并受規則的約束,久而久之,不但習慣了這種規則,能“自由”地“享用”這些規則,甚而“自覺”地用這些規則指導和幫助其他人更好地“掌握”和“使用”這些規則。通常在對一些語言現象說不出合理解釋的時候,最后一句擋箭牌就是“習慣”。
(三)“習慣”的背后
具有“下意識”特點的“習慣”往往會成為實施語言內部“監控”的制度性規則①。這里面的機制很耐人尋味。對于每一個咿呀學語階段的兒童來說,無法參與“約定俗成”,只有默默地服從和接受所有的規則。偶爾有自己的創造,也會輕易地被“大人們”給“糾正”過來。
大人們之間的話常常會有自己的創新、創造,有充分自主的選擇性,互相影響交互作用的發生都是建立在自主選擇的基礎上。新詞、新語、新用法說的人多了,就逐漸被“約定俗成”。這個“習慣”的背后,實際上是“統計學”的“大數定律”在起作用。好像選舉制度的“多數決”規則,只不過語言的“多數決”只有無條件服務于社會每個成員,卻沒有任何權利關系,因此也就非常平和自然。貢獻者無名無利,使用者無憂無慮。
(四)“群體無意識”的背后
“群體無意識”是一個社會心理學術語,指的是群體對于涉及每個人的事情或規則表現出無可無不可的態度。雖然與所有人有關,卻認為與己無關,漠不關心。
因為母語的規則系統是所有母語者自幼獲得的能力——毫無例外——所有人都“習慣”地自然而然地遵從。沒有任何勉強和絲毫的不快。感覺不到規則對于個人的言語行為有任何不適應。這種“群體無意識”的規則的存在等于“不存在”。
但是,對于二語習得者和從事二語教學者來說,這種“群體無意識”的規則系統,恰恰是應該發現、提取和研究的“隱性”語言知識的重點。
(五)語言知識的顯性與隱性
1.顯性知識
語言的顯性知識都是有特征標記的。例如構詞語素、搭配關系、上下文等,都是顯而易見的存在。書面上所有的漢字都是“形音義”的統一體。讀者可以根據詞典釋義獲知該字的形音義解釋,從而獲知漢字語素所構成的詞語的“原型”意義。所謂“白紙黑字,鐵證如山”,所有這些都有案可稽,有書為證,查而可知、信而可證。
漢字的構型理性很注重意義,如果某個人名字中有“女”旁的字,就可以推斷主人是位女性。漢語的親屬稱謂能清楚地區別復雜的親屬關系。社會稱謂也有標志性,“張處”“李局”“王總”等等,都是顯性的知識。
但是因為漢語沒有形態,很多語義都依靠語境提示和補充,例如“有關單位”“有關部門”“相關人員”等,都模糊不清但又經常會遇到。這些模糊的表達一旦離開了上下文,可能就不知所云。
而“顯性知識”在具體的語境應用中也往往會“失效”,甚至會誤導讀者理解真實語義。例如:“花”在詞典的解釋中兼有名詞、動詞、形容詞等不同用法。“眼花了不戴花鏡看什么都花里花噠的”,寫出來都是一個“花”字,說出來的語音也沒有什么不同,但在句中不同位置的意義和句法功能卻不一樣。這種差異要由具體的上下文語境提供“區別性特征”①。由此看來,詞典中的“顯性知識”還不是真正的“顯性”。
“上”的顯性知識是表示空間方位的意義,但是,“說不上”“吃不上”“看不上”中的“上”與空間意義無關;“下去”表示動作行為的空間趨向意義,“看不下去”“吃不下去”和“活不下去”中的“下去”都不是空間趨向意義。
這些不能直接從顯性知識推導出真實語義的,都是隱性知識在起作用。
2.隱性知識
幾乎所有非直接使用“原型”語義用法的,都存在著隱性知識。例如:“一臉的無奈”“背一屁股債”中的“一”,不能換成“二”或“三”等其他的數詞,這就隱含了“一”在句中并非等同一般數詞;而在“一看見我扭頭就走”中的“一”,就更明顯不是數詞而是副詞了。
又如回答“你都知道啥?”的問話時,說“我能知道啥?我啥都不知道!”,這三句話中的“啥”都隱含疑問代詞的非疑問用法,都需要結合上下文語境才能正確理解。
因為漢語沒有形態、語法范疇主要依靠虛詞和語序來表達,而句法、語義、語用則要依靠具體的上下文語境獲得解釋。這就使得漢語“隱性知識”的類型和數量遠遠超出顯性知識。
以往的語言學研究,有“例不十法不立”的原則,意思是只有十個以上的例證,才能確立一條規則。這雖然是很基礎的標準,由此也看出傳統的依靠看資料、抄卡片搜集例證的研究方式,委實辛苦不易。相比之下,通過語料庫方法,發現隱性知識的工具和技術手段都不可同日而語。
二、語料庫的資源價值
(一)大規模真實文本
1.大規模
我國第一部《現代漢語頻率詞典》[1]由北京語言學院語言教學研究所專家團隊采用人工和計算機相結合的辦法,從1979年11月到1985年7月完成,歷時將近6年。共統計了200萬字的語料,統計到不同漢字4000余個,不同詞語31000余條[2]。目前研究生畢業論文寫作自建語料庫的規模一般也動輒數千萬字符。由此可見,在信息網絡時代,大規模真實文本語料庫給語言研究提供了多么優渥無比的便捷和資源。
2.多樣化
語言能力的無限性和語言規則的能產性,讓所有使用語言的健全人幾乎可以隨心所欲地自由思考和表達。個性化的話語方式和話語作品成就了語言的多樣化特征。同義、近義、大同小異的話語方式、不同地域、不同領域、不同職業、不同年齡、不同性別等差異,都會產生不同的話語特征。從多樣化中提取語言知識是語言習得、教學與應用研究的重要內容。
3.復雜性
世界上凡是與人有關的幾乎都具有“復雜性系統”的屬性特征。心理、行為、情感、審美、興趣、性格等差異,在語言態度、話語方式、語體風格、語用原則等方面,形成不同的色彩特征。戰狼式的狂懟、醉漢似的豪言;脫口秀的口無遮攔、謙謙君子的溫文爾雅;閨蜜般的私語,鄉愿樣的調侃,冠冕堂皇的高大上,滴水不漏的外交辭令,菜市大媽的斤斤計較,網群之間的連珠吐槽……,隨著網絡的普及發展,網絡語言和網絡文化隨之日新月異。從全息角度看待信息爆炸帶來的網言網語和多元化話語方式,不再簡單作為邊緣化“噪音”雪藏,而是當成客觀性真實話語的自然常態,是知識挖掘的寶貴資源。
4.真實性
從100年前結構主義語言學之父索緒爾提出“語言”和“言語”的區別,并強調通過言語研究語言的主張以來,實證主義一直成為語言學界遵從的不二法則。即使在喬姆斯基唯理主義的“語言學革命”大潮中,基于實證主義的研究路線仍然穩居學界的主流。許多形式句法研究者也大量采用豐富的例證,細致入微地分辨“能說的”和“不能說的”、“合法的”和“不合法的”話語方式。說到底,真實性仍然越來越彰顯出頑強的生命力和有效的解釋力。因此,真實文本語料庫就是語言研究價值的唯一寄托和依靠。
社會語言學創始人拉波夫為了調查到“真實話語”可謂絞盡了腦汁。“人們的話語隨場合的不同而不同(包括風格、社團、家庭、社會、地位等等),這并不稀奇,也不難理解。難就難在如何讓說話人能下意識地說出你讓他說的話。這是一個極其重要的問題,因為如果得不到說話者最自然、最真實的話語,那么一切結果都不可靠。”[3]
(二)充分必要
基于語料庫的隱性知識挖掘必須實現充語料和研究對象的“充分必要”。這不僅是數量規模上要滿足充分和必要性,同時在操作過程中也要體現出來。
當代語言學界對于研究的充分必要主要體現在“充分描寫、充分解釋和充分預測”上。
1.開放資源的可控方式
開放的網絡資源,洶涌如潮的海量信息,要保證研究的“充分必要”,就要給定研究對象一個明確的范疇。好比物理學的“標準溫度”、數學的直線、平行線的定義一樣。通過充分考慮的選材原則和科學設計的抽樣方法,所建立的“抽樣語料庫”就給定了研究對象的可控性范圍。在這個可控性范圍內就可以實現充分的描寫和充分的分析與預測。至于“充分”的程度和效果如何,取決于研究者自身的認真和努力程度。就語料庫本身來說,所提供的具有可控性的真實文本資料,為研究提供了充分必要的保障。
2.定量定性分析
一直以來強調的定量基礎上的定性分析,是借鑒自然科學方法提高語言研究科學性的典型范式,也是學界的共識。
定量分析的基礎在于足夠的樣本量。以往的漢語研究從“例不十法不立”的舉例證明,到百分比,再到基于語料庫的量化分析,逐漸發展出相關性分析、方差分析、曲線分析、透明度分析等。所采用的數據特征、隱顯性類型、呈現方式等,都為定性分析提供了更加科學實用的方法和手段。
3.證明與證偽
學術研究的科學性、結論的可信性要求該研究能夠“證明”和“證偽”,即任何人都可以對整個研究采用的原始樣本數據進行查驗和審核。以往依靠“口耳之學”進行的田野調查結果,常常因為時過境遷,物是人非,無法進行有效的復核和驗證。甚至問卷調查,特別是網絡問卷調查,充滿了隨機性和不確定性,難以進行有效的“證明”和“證偽”。
語料庫則不然。無論任何時候,原始文本語料都會完好如初,所有分詞標注、統計分析的工具軟件和資料數據,也都可以重復n遍。即使有誤差或疏漏,都可以順藤摸瓜,找出原委。這就無形中保證了研究過程的可重現性,從而提升了研究結論的可信度。
三、漢語兼類詞知識挖掘
(一)從“詞無定類”到承認“兼類”
中國第一部語法專著《馬氏文通》的作者馬建忠(1845—1900)曾說過:“字類凡九,舉凡一切或有解,或無解,與夫有形可形、有聲可聲之字胥賅矣。字分九類,足類一切之字。無字無可歸之類,亦類外無不歸之字矣。”[4](P23)“字無定義,故無定類。而欲知其類,當先知上下之文義何如耳。”[4](P24)馬建忠在這里所說的“字”實際指的是“詞”,“字類”就是“詞類”。可見他在承認詞類的基礎上,還是認為漢語“詞無定類”。
著名語言學家王力認為:“我們應該承認一詞多類的事實的存在。一個詞如果有兩個以上的經常職務,就應該承認它是屬于兩個或更多的詞類。”[5](P319)現在的教科書和權威語文工具書《現代漢語詞典》《現代漢語規范詞典》等都增加了詞類標注。由“詞無定類”的模糊狀態演進到詞典中有了明確的詞類標記。身兼多類的“兼類詞”不斷露出水面,蔚為壯觀。例如:“把”的詞典釋義兼有“動詞”“名詞”“量詞”“介詞”四種,有人造出兼類融于一句的例子,如:
(1)一把把車把把住。
在例(1)中,“把”的詞類依次為“量—介—名—動”。
(2)除了校徽別別別的。
在例(2)中,三個“別”的詞類分別是“副—動—形”。
(二)兼類詞的動態分布
詞典工具書并沒有提供兼類詞所兼不同詞類的語用特征和使用頻度分布等信息,而這又恰恰是習得、教學與研究都需要的隱性知識。
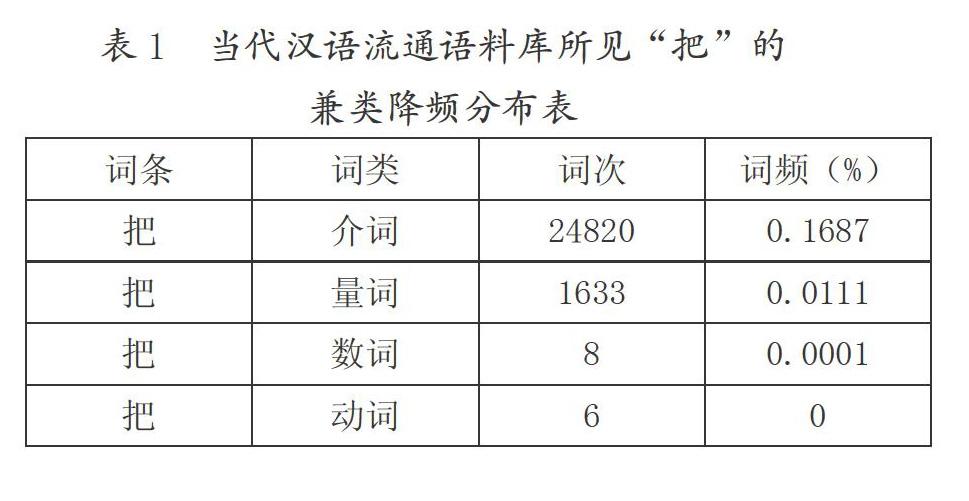
通過對自建的1400萬字符的當代漢語流通語料庫①的統計發現,兼類詞“把”的介詞用法詞次高達24820次,其次是量詞用法1633次,數詞用法8次,動詞用法6次,未見名詞用法。
對于詞典“把”字下未收入的數詞用法,查找原文,發現確有實例。如:
(3)讓/v 我/r 也/d 意興闌珊/i 一/m 把/m 的/b
(4)這個/r 老/a 花花公子/i 為了/p 和/ag 年輕/a 情人/n 作愛/nr 經常/a 大/a 把/m 大/a 把/m 地/j 吃/v 偉哥/nr ,/w
《現代漢語詞典》(第7版)對“把”的釋義順序,前6項都是動詞用法,第7項是方言用法,第8、9項是名詞用法,第10項是量詞用法,第11項才是介詞用法[6](P49)。而實際統計發現:“介詞”用法居首,高達24820詞次;其次為量詞用法,1633詞次;數詞和動詞用法詞次很低,沒有統計數據價值。具體如表1所示:
我們使用中國科學院計算所研發的“ICTCLAS”自動分詞系統進行分詞和詞性標注,在抽樣校對時,發現“把”有一例副詞用法,原句如下:
(5)他們/r 也/c 把/d 煽/vg 情/n 路數/n 發揮/v 到/v 極點/n ,/w
例(5)中的“把”應該是介詞無疑。那么,為什么自動分詞軟件會標錯呢?
實際上計算機自動標注所依據的原則是上下文語境和搭配關系。判斷介詞的規則是后接名詞性成分。這句話后接的“煽/v”是動詞性成分。機器根據規則排除介詞后,就會從動詞的前加詞類中尋找。動詞前面可能出現的詞類主要有“名、形、動、副”等類。機器的智能有限,在名詞主語和動詞謂語中心詞之間,最大可能就是“副詞”了。這個案例提示我們,機器恪守“規則”所遭遇到的例外“陷阱”,恰是值得深入挖掘的問題所在。
(三)自動標注的兼類詞
自動分詞標注詞性工具軟件所執行的是國家標準GB/T 13715-92《信息處理用現代漢語分詞規范》。該規范明確說明:“為敘述方便,本規范沿用了把詞分為名詞、動詞、形容詞、代詞、數詞、量詞、副詞、介詞、連詞、助詞、語氣詞、嘆詞、象聲詞等十三類的方法。”[7](P2)
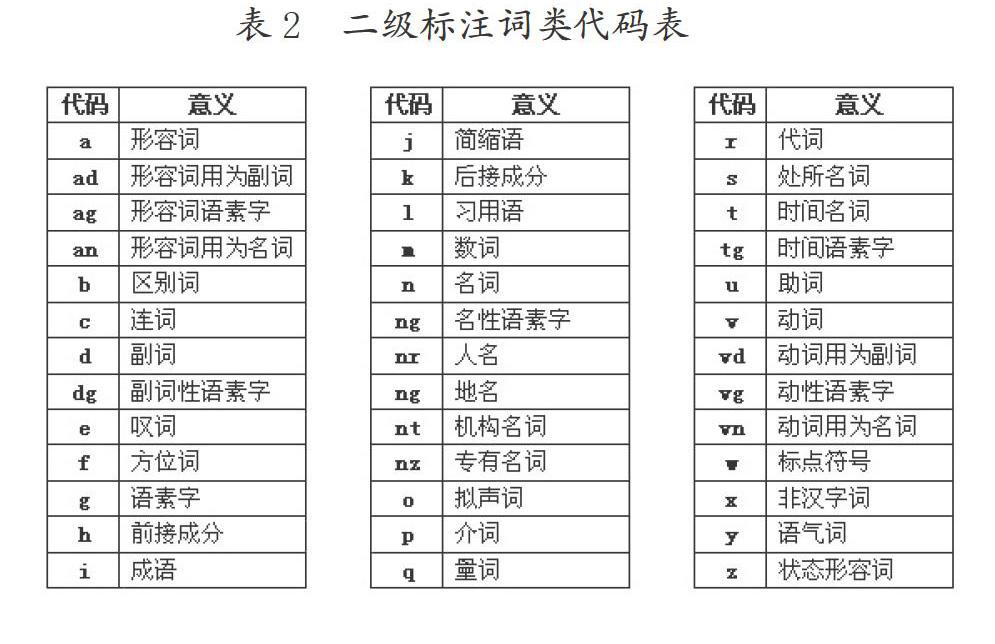
考慮到書面漢語的復雜性和智能化信息處理應用的需要,“ICTCLAS”自動分詞系統設計了“二級標注”模式,增加了多項下位小類,具體如表2所示:
從表2可以看出,形容詞用為副詞、形容詞用為名詞、動詞用為副詞、動詞用為名詞等都是顯性“兼類詞”,至于人名、地名、機構名詞、專有名詞、處所名詞、時間名詞等,都是名詞大類下的小類。
顯然,“二級標注”對兼類詞的隱性知識挖掘提供了極大便利。即使有些標注可能存在偏誤,也已經大大減輕了研究者的工作量,起碼給出了大致范圍和類別,可作為剝繭抽絲、精挑細選的基礎。
1.兼類詞的動態分布
根據當代漢語流通語料庫的統計發現,兼類呈多樣化分布。例如:
人名兼地名,如:阿里(/nr64—/ns55)①;
人名兼產品名,如:大寶(/nr7—/nz64);
名兼地名,如:大巴(/n75—/ns11),燈市(/n4—/ns3);
形兼名,如:典型(/a218—/n199),典雅(/a47—/an9);
形兼名兼地名,如:安康(/a3—/an15—/ns9);
動兼名兼動名,如:登記(/v156—/n7—/vn499);
形兼動兼動名兼形名,如:低迷(/a61—/v8—/vn1/an17);
動兼名兼量,如:兜(/v91—/n7—/q3);
動兼量兼名兼人名,如斗(/v307—/q42—/n23—/nr3)。
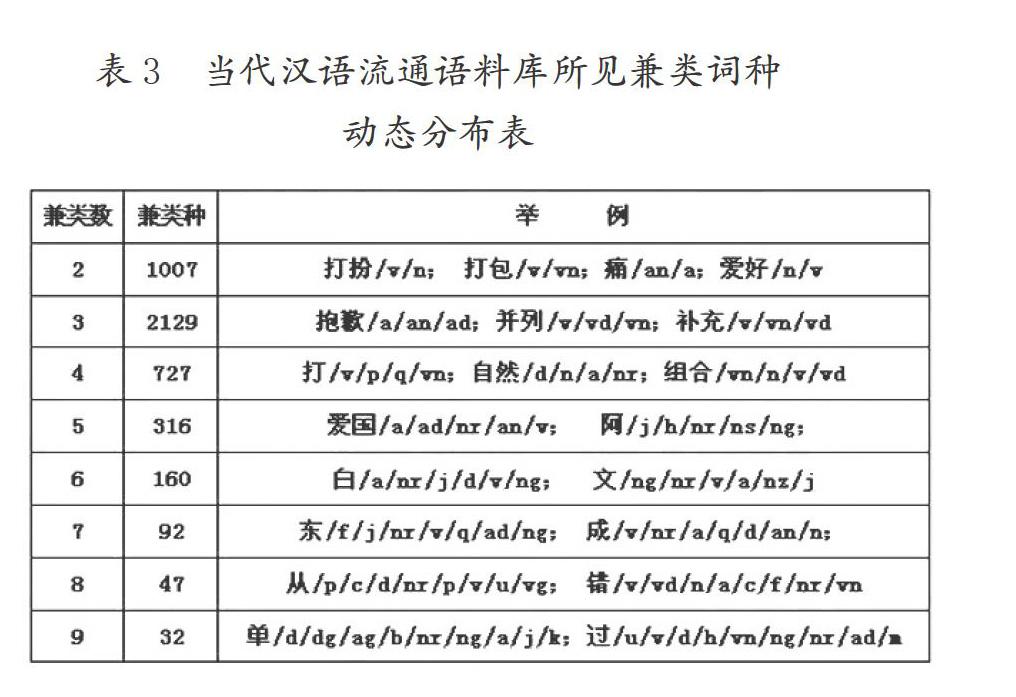
當代漢語流通語料庫兼類詞動態分布情況,具體如表3所示:
表3中的“兼類數”是指兼類詞所兼的詞類數,“兼類種”是指不同的兼類詞個數。不管一個詞兼幾個類,只算是一個“兼類種”。根據自動分詞軟件的二級分詞標準,下位小類也按不同詞類對待。
2.兼類詞動態頻度分布
單純從兼類詞的所兼詞類的多少,還不能真正揭示兼類詞的本質特征。因為重要的參數是在于所兼的詞類在使用頻度方面的分布差異。
分析發現,兼有9個詞類的“單”,副詞(d)類334次、副詞性語素(dg)299次、形容詞性語素(ag)249次、區別詞(b)238次、姓名(nr)211次、名詞性語素(ng)52次、形容詞(a)24次,簡稱(j)5次、后接成分(k)1次。低頻區沒有統計學價值,去掉小類“副素、形素、名素”以及姓名、后接成分等,就只剩副詞、區別詞和形容詞三類了。
下面以列表舉例的方式來展示兼類詞不同兼類的使用頻度的分布情況:
【麒按】表內不同兼類的使用頻次均按降頻排列(下同)。從數據看,兼2類的兼類詞內部分化明顯。“打扮”動詞269詞次,名詞92詞次,名詞用法占動詞用法269次的34.2%;占全部詞次361的25.5%。可見,“打扮”所兼詞類之間的使用頻次差異。表中所列其他四個兼類詞“打包、愛好、打算、打印”的使用頻次差異也十分明顯。
兼類詞頻次分布上的差別化特點,是否可據以推測頻次量差與內部分化存在一定的正相關系,有待全面對比和深入探討。
【麒按】表內所列兼類詞各類頻次之間有比較明顯量差。由于增加了“人名/nr、地名/ns”和“名性語素字/ng、前接成分/h、簡稱/j”等小類,增加了所兼“詞類”數。
【麒按】表6中,“白”的形容詞(/a)用法最多,其次為姓名(/nr)用法和副詞(/d)用法。在現代漢語中,“白”的動詞用法不多,如:“老黃/nr 白/v 了/u 他/r 一/m 眼/q ,/w”“一/m 夜/q 工夫/n 急/ad 白/v 了/u 頭/m 發/q ,/w”。
在現代漢語中,“文”的動詞用法已不多見,不過,在成語中仍有保留,如成語“文過飾非/i”中的“文”就保留了動詞用法。而在句子“虛詞/n 失實/vn 、/w 巧/ad 文/v 亂/v 真/a ,/w”中,“巧文亂真”雖然不是成語,但是,逐詞切分標注時,也可看出“文”的動詞用法。
同時,也不能排除誤標記的情況,如下列例句中的“文”都標錯了:
特色/n融合/v型/k文/v創/vg產業/n、/w
品類/n豐富/a的/b西夏/n文/a佛經/n。/w
兩岸/n同胞/n同宗/v同/c文/a,/w
覺得/v文人/n言/vg商/vg,/w非/h文/a非/h商/n。/w
去掉小類后,“白”只剩下“形容詞、副詞、動詞”3類;“文”只剩下“動詞、形容詞”2類。
【麒按】去掉小類后,“東”只剩“方位詞”1類;“成”只剩“動詞、形容詞、量詞”3類。
【麒按】如上分析,去掉小類,再忽略10次以下用例,“從”只兼“介詞、連詞”2類;“錯”只兼“動詞、副詞、名詞、形容詞”4類。
【麒按】“單”只剩“副、區別、形”3類;“過”只剩“助、動、副”3類。
通過上述分析,我們可以得出以下結論:
第一,“二級分類”可以獲得更細化的分類,增加了兼類詞的選擇范圍;
第二,特殊小類對兼類詞語法功能研究的參考價值不大,但對其他應用如輿情分析、情感分析等具有特殊意義;
第三,10次以下的低頻區用例除非特殊需要(“長尾”挖掘①),可以忽略不計。
3.兼類詞的語域分布
當代漢語流通語料庫的語料來源領域包括經濟、政治、法律、文化、衛生、體育、文學、網絡、博客等九類。因此,可以獲得詞匯使用情況在不同領域的分布信息。例如,兼類詞“把”在不同語域中的使用情況,具體如表10所示:
根據表10信息可以發現,介詞“把”的用法不僅詞次最高,而且在所抽樣的9類語域均有使用。其中,文學類居首,多達8580詞次,其次為網絡8412詞次,第三為博客2274詞次。其他依次為政治861詞次、體育680詞次、經濟442詞次、文化342詞次、衛生311詞次,法律類最少,只有46詞次。這可能與“把”字句構式的語體、語用特征有關,因為突出賓語焦點的變形處置句具有很強的主觀化特征,所以不太適合法律領域強調客觀、公正的話語方式。
四、結論與展望
(一)結論
通過當代漢語流通語料庫的定量分析,挖掘漢語兼類詞的隱性知識,有以下幾點發現:
1.現代漢語詞類具有鮮明的“上下文相關”語法特征。這與前輩提出的“依句辨品”原則具有傳承性,也證明了前賢所論的合理性和獨到之處。
2.沒有形態標記的漢語隱含大量“非顯性”功能屬性,“一成不變”的漢字記錄的書面漢語掩蓋了古今漢語演變的蛛絲馬跡。
3.自動分詞軟件“二級標注”模式增加了兼類詞隱性知識挖掘空間,具有重要參考價值。有些小類如“姓名”“專名”等,在自然語言理解、輿情分析等領域具有重要的參考價值。
4.基于大規模真實文本語料庫知識挖掘,可以透過“不動聲色”的字面表層獲得深藏不露的隱性知識,因而具有廣域的研發空間和應用前景。
(二)展望
1.語料庫加工質量決定挖掘質量
語料庫規模和加工質量直接關系到知識挖掘的水平和質量。因為各方面條件的限制,采用人工抽樣校對的方法,難免存在大量疏漏和偏誤,直接影響到知識挖掘結果的信度。這是本研究的不足和缺憾。
2.兼類詞隱含語法化信息
兼類詞所兼的主要詞類之間,隱含著大量“語法化”的信息,例如“動詞、介詞、副詞、連詞”兼類,數量分布差異實際上反映的是語法化程度的差異。語言共時系統是歷時系統的映射,共時系統中并存的“兼類”現象,在一定程度上反映了不同歷時層面的語法化狀態。這一“假說”有待深入挖掘和大數據求證。
本文在寫作過程中參閱了前輩時賢的大量論著,恕不一一具名,謹此一并致謝。
參考文獻:
[1]北京語言學院語言教學研究所.現代漢語頻率詞典[Z].北京:北京語言學院出版社,1986.
[2]常寶儒.關于《現代漢語頻率詞典》的編纂問題[J].辭書研究,1986,(4).
[3]本刊特約記者.社會語言學創始人拉波夫[J].世界漢語教學,2001,(1).
[4]馬建忠.馬氏文通[M].北京:商務印書館,1998.
[5]王力.關于詞類的劃分[A].王力文集·第十六卷[C].山東教育出版社,1990.
[6]中國社會科學院語言研究所詞典編輯室.現代漢語詞典(第7版)[Z].北京:商務印書館,2016.
[7]國家技術監督局.中華人民共和國國家標準GB/T 13715-92信息處理用現代漢語分詞規范[Z].1992—10—04.
