基于人臉識別的智能閱讀器
2020-08-31 06:14:02秦益輝李瑋峰王力強李文昊
智能計算機與應用 2020年4期
關鍵詞:人臉識別
秦益輝, 周 華, 李瑋峰, 王力強, 李文昊
(上海工程技術大學 電子電氣工程學院, 上海 松江201600)
0 引 言
人臉識別技術現如今已廣泛應用于金融行業和安保行業[1]。 在金融行業,通過刷臉進行支付已經進入了人們的日常生活;在安保行業,刷臉開門、掃臉簽到逐漸取代了以往的打卡機。 目前,商用人臉識別系統已達到十萬分之一的錯誤率,可見人臉識別技術已經相當成熟。 盡管人臉識別技術已經在諸多領域嶄露頭角,但在隱私保護方面卻少有相關的應用。
本文提出一種基于人臉識別的智能閱讀器,利用人臉特征的普遍性、唯一性和不可復制性,將其作為密碼來防止閱讀筆記、書簽的泄露。 同時應用語音播報技術直觀地向用戶呈現人臉識別地結果,并在閱讀器基礎上開發了臉部表情翻頁功能,在很大程度上提升了用戶的閱讀體驗。
1 原理分析
閱讀器主要由樹莓派、攝像頭模塊、外部儲存、語音模塊、按鍵以及顯示屏6 個部分組成,如圖1 所示。 樹莓派作為主控單元;圖像采集使用Camera V2 攝像頭模塊,用于拍攝人臉圖像,作為檢測采集數據的輸入;語音模塊用于信息播報;按鍵用于指令輸入;外部儲存用于保存人臉模型以及書簽信息;顯示部分為LCD 液晶屏,用于顯示書籍文字,以及測試結果。
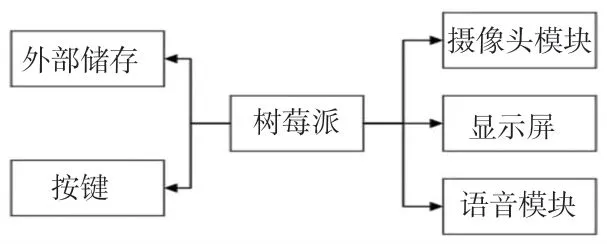
圖1 系統整體結構框架Fig.1 The overall structure of the system
將樹莓派作為智能閱讀器的載體,在40 個引腳上接入對應的攝像頭模塊、顯示屏和簡易鍵盤,并在耳機孔上接入耳機或音響。 閱讀器采用Camera V2攝像頭模塊采集用戶清晰正臉的照片,輸入至樹莓派搭載的OpenCV 軟件中進行圖像處理。 在對圖像整體進行降噪處理和特征向量的提取后,把特征向量與數據庫中樣本進行比對,比對結果反饋至樹莓派。 根據上述結論播報對應的內容,使用eSpeak 軟件將文字轉化為語音。 語音內容包括閱讀者上次閱讀位置及書目名稱等等。 本系統還將人臉作為書本書簽,通過人臉識別后,書本將自動跳轉至上次閱讀位置。 為了便于用戶進行表情翻頁,可預先在系統中導入臉部旋轉的圖像。 使用閱讀器時,系統將實時檢測人臉特征向量變化,實現表情翻頁功能。
2 圖像識別
攝像頭采集得到的圖片利用中值濾波算法進行降噪;Haar 算法提取得到圖像中的人臉特征;AdaBoost 算法用來訓練分類器。
2.1 圖像預處理算法
在采集圖像時,不可避免的會伴有一定的噪聲,它使得圖像質量受到影響。 因此,為了得到較優質的圖像,在使用圖像前須對所采集到的圖像實行降噪處理。 降噪的方式有很多,其中中值濾波是目前應用較多的一種非線性濾波器。 中值濾波主要是將像素四周點的像素值按從大到小的順序進行排列,取出中間值。 加入中值濾波后,能明顯感受到人臉識別成功率顯著提升。
2.2 Haar 特征提取算法
Haar 特征算法最先由Paul Viola 等人提出,后經過Rainer Lienhart 等擴展引入45°傾斜特征。OpenCV 所使用的Haar 特征共計14 種,其中包括:5種Basic 特征、3 種Core 特征和6 種Titled(即45°旋轉)特征。 Haar 特征值反映了圖像的灰度變化情況。 臉部特征能由矩形特征簡單的描述,如:眼睛比臉頰顏色深,鼻梁兩側比鼻梁顏色要深,嘴巴比周圍顏色要深等。 但矩形特征只對一些簡單的圖形結構,如邊緣、線段較敏感,所以只能描述特定走向(水平、垂直、對角)的結構。 算法表達式如下所示:

Haar 特征值=整個Haar 區域內像素和×權重+黑色區域內像素和×權重。
2.3 分類器訓練算法
本文中選擇AdaBoost 分類器算法,主要考慮同一產品的使用者不會超過10 人,AdaBoost 算法完全可以滿足數據體量小、訓練時間短的項目。
Adaboost 算 法[2](Adaptive Boosting 自 適 應 增強)是一種迭代算法,將多個弱分類器,組合成強分類器。 其自適應性在于:前一個弱分類器分類錯誤的樣本權重會得到加強,在權重更新后的樣本,將再次被用來訓練下一個新的弱分類器。 在每輪訓練中,用樣本總體訓練新的弱分類器,產生新的樣本權重、該弱分類器的話語權,一直迭代直到達到預定的錯誤率或達到指定的最大迭代次數。
若有N 個樣本,則每個訓練的樣本點開始時都被賦予相同的權重——1/N。 訓練過程中,如果某個樣本已經被準確地分類,則下一次訓練中,它的權重就被降低;相反,如果某個樣本點沒有被準確地分類,那么它的權重就得到提高。 同時,得到弱分類器對應的話語權。 然后,更新權值后的樣本集被用于訓練下一個分類器,整個訓練過程如此迭代地進行下去。 各個弱分類器的訓練過程結束后,分類誤差率小的弱分類器的話語權較大,其在最終的分類函數中起著較大的決定作用,而分類誤差率大的弱分類器的話語權較小,其在最終的分類函數中起著較小的決定作用。 換言之,誤差率低的弱分類器在最終分類器中占的比例較大,反之較小。 最后訓練得到的弱分類器將組合成強分類器。
3 設計與實現
本系統在研究中,應用了多個算法提取人臉特征,來判斷是否與庫中人臉相匹配;在硬件設計中,自行設計了樹莓派電路,如圖2 所示。

圖2 樹莓派電路圖Fig.2 Raspberry Pi circuit diagram
除了人臉識別功能外,本系統還包括書簽跳轉、語音播報以及臉部表情翻頁功能,如圖3 所示。
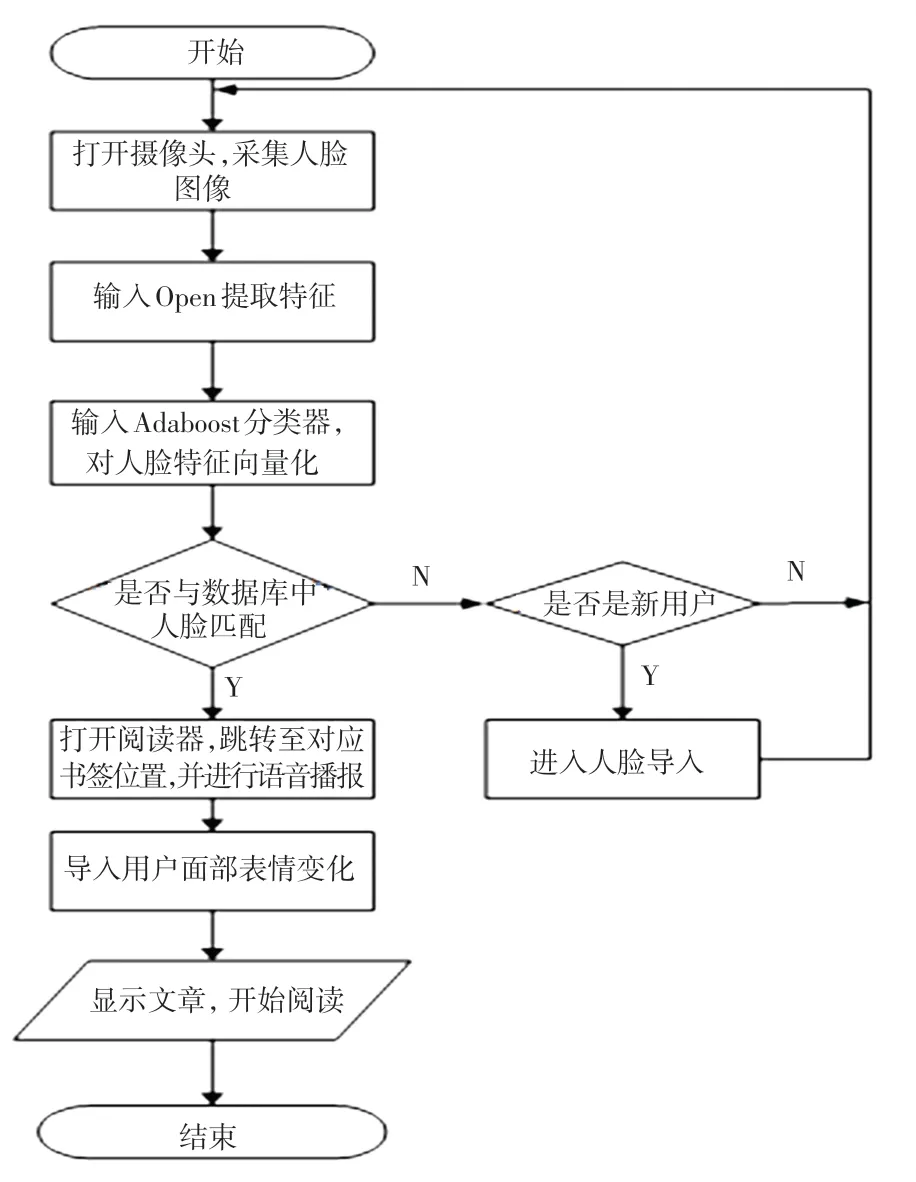
圖3 系統流程圖Fig.3 System flow chart
3.1 攝像頭模塊
攝像頭模塊承擔了本系統最重要的人臉識別功能,是后續所有功能實現的基礎。 本系統采用Camera V2 樹莓派官方原裝的攝像頭,裝載有索尼IMX219 感光芯片,具有800 萬像素,可拍攝出3 280 像素?2 464 像素的靜態圖像,其接口電路如圖4 所示。
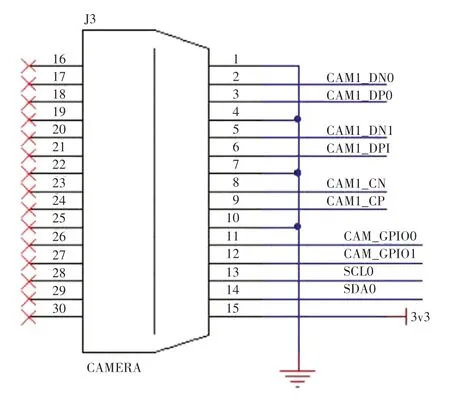
圖4 樹莓派攝像頭接口電路圖Fig.4 Raspberry Pi camera interface circuit diagram
樹莓派與攝像頭的連接線采用了柔性扁平電纜(FFC),一種用PET 絕緣材料和極薄的鍍錫扁平銅線壓合而成的新型數據線纜。 具有柔軟、厚度薄、體積小、連接簡單、拆卸方便、易解決電磁屏蔽等優點。很好的解決了連接線體積大,不易彎折等問題,給用戶使用帶來了極大的便利。
3.2 書簽跳轉實現
書簽跳轉位置的信息以人臉文件名的方式進行儲存。 當人臉配對成功時,書簽將按照文件名上的字節數進行跳轉。 在用戶打開書簽時,系統會先將書簽按照字節長度數進行分頁,并實時記錄當前的字節數。 當需要保存書簽時,儲存當前位置的字節數,并通過命令行進行命名。
3.3 語音播報功能
書簽頁碼以及書目名稱通過語音的方式讀出。為此,本文在樹莓派上安裝eSpeak 開源軟件,便于將文字轉為語音讀出。 其中espeak_txt_chinese 命令是將指定文本中的內容通過eSpeak 軟件語音讀出。 如:使用命令行espeak-vzh"編程",就可以讓樹莓派讀出中文一詞“編程”。
3.4 臉部表情翻頁功能
臉部表情翻頁是本系統最具特色的功能。 由于Haar 特征值算法將人臉輪廓、眼睛、嘴作為人臉特征的主要依據,當人臉發生一定角度轉動時,系統將無法識別其側臉,并將其作為一張全新的人臉來處理。 本系統正是利用了側臉和正臉人臉識別結果的不同,實現了搖頭翻頁的功能。 但當人臉轉動角度過大時,系統將徹底無法識別人臉,即超出了測量范圍,也就不存在翻頁了。 當用戶閱讀時,系統攝像頭將處于實時檢測的模式中,當側臉被檢測到時,就意味著翻頁指令運行。 以此來實現搖頭翻頁功能。
4 結果驗證
(1)驗證環境: 樹莓派3B+為核心控制器,并在SD 卡預先儲存人臉識別數據庫(真人模型數據)及電子書籍。
(2)驗證過程:
①使用樹莓派上攝像頭的拍攝,用以捕捉人臉信息。
②對照片信息進行數字化處理,再將其與數據庫信息進行對比。
③對比信息正確時,在樹莓派的LCD 屏上顯示該用戶信息(已閱讀書目、書簽位置等),同時跳轉到該頁面。 對比無此人時,新建人臉信息。
④對比完成后,使用語音模塊對結果經行播報。正確時樹莓派控制語音模塊說出書名與頁碼。
⑤使用樹莓派攝像頭,儲存側臉照片。 拍攝多組,多角度側臉照片以提高成功率。
⑥轉頭并還原至正臉位置,觀察是否翻頁成功。翻頁效果如圖5 所示。
(3)驗證結果:經過反復測試,正臉正確識別率高達95%以上,語音播報功能運行良好,書簽功能正常進行。 由于受樹莓派本身性能限制,人臉識別實時檢測時有較大延遲,搖頭翻頁功能實現效果一般。 當兩張人臉在同一攝像頭畫面中出現時,系統發生錯誤識別等情況。

圖5 書本翻頁效果圖Fig.5 Book turning page renderings
5 結束語
本項目的靈感來源于人臉識別的興起,從視覺感知層面,對日常生活中的設備進行智能化的設計,很好地滿足了現代人對于快捷、保密性良好的電子閱讀設備的需求。 目前系統還有較大的提升空間,如當儲存大量人臉模型時,整個嵌入式的系統識別率還有待提高,與其他設備如何兼容等等問題。
猜你喜歡
作文中學版(2022年1期)2022-04-14 08:00:34
學生天地(2020年31期)2020-06-01 02:32:06
電子制作(2019年14期)2019-08-20 05:43:34
中國交通信息化(2018年1期)2018-06-06 07:29:55
電子制作(2017年17期)2017-12-18 06:40:55
中國公共安全(2017年7期)2017-10-13 08:18:26
電子制作(2017年1期)2017-05-17 03:54:46
中國公共安全(2017年9期)2017-02-06 03:05:32
現代工業經濟和信息化(2016年6期)2016-05-17 05:36:23
華東理工大學學報(自然科學版)(2015年2期)2015-11-07 09:16:51
