基于Spring Batch+Gemfire+CXF的金融大數(shù)據(jù)集成和整合
2020-09-02 01:22:04朱錚雄黃宇青
計(jì)算機(jī)應(yīng)用與軟件 2020年8期
朱錚雄 黃宇青
1(海際金控有限公司 上海 200120)2(上海市計(jì)算技術(shù)研究所 上海 200040)
0 引 言
巴塞爾協(xié)議Ⅲ[1]根據(jù)銀行交易數(shù)據(jù)與風(fēng)險(xiǎn)資產(chǎn)計(jì)算一級(jí)資本的充足率。銀行的各種交易數(shù)據(jù)的集成和整合是整個(gè)巴塞爾系統(tǒng)的核心。傳統(tǒng)方式采用腳本和數(shù)據(jù)庫(kù)存儲(chǔ)過(guò)程[2]進(jìn)行數(shù)據(jù)整合,串聯(lián)起上游數(shù)據(jù)源系統(tǒng)和下游商業(yè)報(bào)告系統(tǒng)。隨著金融全球化的步伐加快,數(shù)據(jù)量呈幾何級(jí)增長(zhǎng),從原先面臨億級(jí)數(shù)據(jù)處理到面對(duì)每天萬(wàn)億級(jí)以上的處理數(shù)據(jù),系統(tǒng)面臨極大的瓶頸。原先采用的全部是存儲(chǔ)過(guò)程,導(dǎo)致數(shù)據(jù)庫(kù)瓶頸大,單個(gè)節(jié)點(diǎn)擴(kuò)展性能難,數(shù)據(jù)處理速度慢,存儲(chǔ)過(guò)程難以維護(hù)。同時(shí)下游報(bào)表系統(tǒng)也嚴(yán)重依賴(lài)上游數(shù)據(jù)庫(kù)[2],數(shù)據(jù)庫(kù)經(jīng)常卡頓,嚴(yán)重制約整個(gè)巴塞爾系統(tǒng)運(yùn)行的準(zhǔn)確性、時(shí)效性。提升數(shù)據(jù)處理性能,提高自動(dòng)化程度,降低系統(tǒng)之間耦合度是擺在整個(gè)銀行運(yùn)維和開(kāi)發(fā)面前的重要問(wèn)題。
本文采用Spring Batch的系統(tǒng)構(gòu)架方式,重新架構(gòu)整個(gè)數(shù)據(jù)整合系統(tǒng),并結(jié)合目前業(yè)界最為流行的Web Service對(duì)數(shù)據(jù)采集、數(shù)據(jù)處理、數(shù)據(jù)發(fā)布、數(shù)據(jù)持久化等各個(gè)應(yīng)用模塊按照面向服務(wù)模式進(jìn)行解耦合。本文將這些應(yīng)用模塊按照面向服務(wù)的設(shè)計(jì)理念重新定義接口,使整個(gè)模塊有機(jī)地聯(lián)系起來(lái),每個(gè)服務(wù)相互獨(dú)立并且可以以一種統(tǒng)一和通用的方式進(jìn)行交互。當(dāng)某個(gè)服務(wù)無(wú)法適應(yīng)數(shù)據(jù)壓力時(shí),可以進(jìn)行水平擴(kuò)展,在保持各個(gè)模塊獨(dú)立的擴(kuò)展性的同時(shí)進(jìn)行創(chuàng)新,確保了數(shù)據(jù)整合的可靠、穩(wěn)定、高效,且滿(mǎn)足巴塞爾系統(tǒng)的運(yùn)行要求,成為海量數(shù)據(jù)整合的核心樞紐。采用這種整合方式,數(shù)據(jù)處理效率高,系統(tǒng)易于擴(kuò)展以及被下游系統(tǒng)接入。
1 相關(guān)技術(shù)
1.1 Spring Batch
Spring Batch[3]是一款優(yōu)秀的、開(kāi)源的大數(shù)據(jù)并行處理框架。通過(guò)Spring Batch可以構(gòu)建出輕量級(jí)的健壯的并行處理應(yīng)用,支持事務(wù)、并發(fā)、流程、監(jiān)控、縱向和橫向擴(kuò)展,提供統(tǒng)一的接口管理和任務(wù)管理。它是一款基于 Spring 的企業(yè)批處理框架,通過(guò)它可以完成大數(shù)據(jù)并發(fā)批量處理。使用Spring Batch可以實(shí)現(xiàn)下列目標(biāo)[4]:
(1) Batch Data:能夠處理大批量數(shù)據(jù)的導(dǎo)入、導(dǎo)出和業(yè)務(wù)邏輯計(jì)算;
(2) Automation:無(wú)須人工干預(yù),能夠自動(dòng)化執(zhí)行批量任務(wù);
(3) Robustness:不會(huì)因?yàn)闊o(wú)效數(shù)據(jù)或錯(cuò)誤數(shù)據(jù)導(dǎo)致程序崩潰;
(4) Reliability:通過(guò)跟蹤、監(jiān)控、日志及相關(guān)的處理策略(retry,skip,restart);
(5) Scaling:通過(guò)并發(fā)和并行技術(shù)實(shí)現(xiàn)應(yīng)用的縱向和橫向擴(kuò)展,滿(mǎn)足數(shù)據(jù)處理的性能需求。
Spring Batch良好的大數(shù)據(jù)批處理的性能和高可擴(kuò)展性,使其被廣泛應(yīng)用于各類(lèi)自動(dòng)化的數(shù)據(jù)遷徙系統(tǒng)中,包括超大數(shù)據(jù)的氣象系統(tǒng)[3]。
1.2 Gemfire
VMware vFabric Gemfire[5]是一個(gè)彈性可擴(kuò)展分布式內(nèi)存數(shù)據(jù)管理平臺(tái),可用于構(gòu)建需要超高速數(shù)據(jù)交互的、具有高度可擴(kuò)展能力的應(yīng)用系統(tǒng)。它能夠跨越多臺(tái)虛擬機(jī)、多個(gè) JVM 和多個(gè)Gemfire服務(wù)器來(lái)管理應(yīng)用對(duì)象。使用動(dòng)態(tài)備份和分區(qū),使它能提供多種平臺(tái)特性,例如:數(shù)據(jù)持久性、可靠的事件通報(bào)、連續(xù)查詢(xún)、通用的并行處理、高吞吐、低延遲、高擴(kuò)展性、持續(xù)有效性和WAN分布。
基于以上特性,可以看出VMware vFabric Gemfire非常適合于巴塞爾風(fēng)險(xiǎn)業(yè)務(wù)管理系統(tǒng)的數(shù)據(jù)緩存層,它可以滿(mǎn)足本文對(duì)整合交易數(shù)據(jù)進(jìn)行實(shí)時(shí)訪(fǎng)問(wèn)的需求,其性能可以隨著需要彈性擴(kuò)展,并且可以在多臺(tái)服務(wù)器上實(shí)現(xiàn)部署,實(shí)現(xiàn)海量?jī)?nèi)存緩存池的要求。
1.3 Apache CXF
Apache CXF[6]是一個(gè)開(kāi)源的Services框架,CXF支持使用Frontend編程API來(lái)構(gòu)建和開(kāi)發(fā)Services,如JAX-WS。這些Services可以支持多種協(xié)議,例如:SOAP、XML/HTTP、RESTful HTTP、CORBA,并且可以在多種傳輸協(xié)議上運(yùn)行,例如:HTTP、JMS、JBI。CXF大大簡(jiǎn)化了Services的創(chuàng)建,同時(shí)繼承了XFire傳統(tǒng),可以天然地與Spring進(jìn)行無(wú)縫集成。
2 數(shù)據(jù)整合整體設(shè)計(jì)
2.1 功能需求分析
系統(tǒng)按照功能大致可以分成三個(gè)主要階段:大數(shù)據(jù)讀取,數(shù)據(jù)整合與映射以及數(shù)據(jù)計(jì)算與存儲(chǔ)。
(1) 大數(shù)據(jù)讀取:批量高速讀取交易流程上所有的數(shù)據(jù),包括交易對(duì)手的合同、實(shí)際交易、賬戶(hù)信息、證券產(chǎn)品信息以及價(jià)格,存入中間高速緩存中。
(2) 數(shù)據(jù)整合與映射:將高速緩存中的交易對(duì)手信息、交易系統(tǒng)、合約信息做一一映射,存入數(shù)據(jù)庫(kù)系統(tǒng)中,同時(shí)將證券產(chǎn)品中的固收產(chǎn)品單獨(dú)提取并寫(xiě)入數(shù)據(jù)庫(kù),根據(jù)緩存中的合約信息計(jì)算凈合約,將凈合約信息更新進(jìn)系統(tǒng)中。
(3) 數(shù)據(jù)計(jì)算與存儲(chǔ):先根據(jù)已經(jīng)映射好的數(shù)據(jù)做風(fēng)險(xiǎn)敞口計(jì)算,再根據(jù)抵押品現(xiàn)狀抵減風(fēng)險(xiǎn)敞口值,最后計(jì)算VaR、預(yù)期信用風(fēng)險(xiǎn)、客戶(hù)的風(fēng)險(xiǎn)評(píng)級(jí)和產(chǎn)品的敏感度值。
圖1為系統(tǒng)主要功能模塊。

圖1 系統(tǒng)功能模塊圖
各個(gè)模塊的功能如下:
協(xié)議/交易/賬戶(hù)(Agreement/Trade/Account)的BCP Loading:使用Sybase的BCP導(dǎo)入數(shù)據(jù)。BCP[7]基于DB-Library以并行的方式導(dǎo)入批量的數(shù)據(jù),目的是快速導(dǎo)入Agreement/Trades/Account等基礎(chǔ)信息進(jìn)入數(shù)據(jù)庫(kù)中待用。
協(xié)議數(shù)據(jù)(Agreement):與交易對(duì)手簽訂的結(jié)算合約。
交易數(shù)據(jù)(Trades):實(shí)際交易數(shù)據(jù)。
賬戶(hù)數(shù)據(jù)(Account):交易對(duì)手等賬戶(hù)信息。
證券數(shù)據(jù)(Security):證券化的產(chǎn)品信息。
價(jià)格數(shù)據(jù)(Pricing):標(biāo)價(jià)信息。
交易對(duì)手/機(jī)構(gòu)映射(Counterparty/Legal Mapping):使用存儲(chǔ)過(guò)程處理,將交易對(duì)手信息(Legal指公司交易機(jī)構(gòu))與交易信息對(duì)應(yīng),存入系統(tǒng)表中。
主要數(shù)據(jù)映射(Master Data Mapping):使用存儲(chǔ)過(guò)程處理,將交易對(duì)手、交易信息以及合約信息數(shù)據(jù)一一匹配映射,存入系統(tǒng)表中。
固收數(shù)據(jù)處理(Fix Income Process):將固定收益證券(包括中長(zhǎng)期國(guó)債、公司債券、市政債券和抵押債券等債務(wù)類(lèi)證券)提取出來(lái),存入數(shù)據(jù)庫(kù)中。
價(jià)格和數(shù)據(jù)處理(Pricing & Mapping Process):將標(biāo)價(jià)信息與固定收益證券映射,對(duì)固定收益?zhèn)M(jìn)行標(biāo)價(jià),用于計(jì)算市場(chǎng)風(fēng)險(xiǎn),結(jié)果存入數(shù)據(jù)庫(kù)中。
凈合約映射(Netting Data Mapping):使用存儲(chǔ)過(guò)程對(duì)雙邊凈合約(Netting Agreement)的信用風(fēng)險(xiǎn)抵減計(jì)算,并且將得出的數(shù)據(jù)全部存儲(chǔ)更新在系統(tǒng)表中。
風(fēng)險(xiǎn)敞口計(jì)算(Analytical Calculation Processor):使用存儲(chǔ)過(guò)程對(duì)數(shù)據(jù)進(jìn)行風(fēng)險(xiǎn)敞口的初步計(jì)算,并且將得出的數(shù)據(jù)全部存儲(chǔ)更新在系統(tǒng)表中。
抵押品計(jì)算(Collateral Mapping):使用存儲(chǔ)過(guò)程對(duì)抵押品進(jìn)行的計(jì)算,并且抵減對(duì)應(yīng)的風(fēng)險(xiǎn)敞口值,將得出的數(shù)據(jù)全部存儲(chǔ)更新在系統(tǒng)表中。
VaR計(jì)算(VaR Calculation):使用存儲(chǔ)過(guò)程計(jì)算在一定概率水平(置信度)下,交易數(shù)據(jù)價(jià)值在未來(lái)特定時(shí)期內(nèi)的最大可能損失,并將結(jié)果存入數(shù)據(jù)庫(kù)中。
CEF計(jì)算(CEF Calculate):使用存儲(chǔ)過(guò)程計(jì)算信用風(fēng)險(xiǎn)敞口預(yù)期值。
機(jī)構(gòu)PDLC計(jì)算(Facility PDLC Calculation):根據(jù)交易數(shù)據(jù)更新調(diào)整機(jī)構(gòu)客戶(hù)信用值,同時(shí)可以授予信用值。
敏感度映射(Sensitivity):使用存儲(chǔ)過(guò)程針對(duì)固定收益證券按照利率、利差和在投資收益率等數(shù)據(jù)敏感度對(duì)標(biāo)的資產(chǎn)做數(shù)據(jù)映射,完成數(shù)據(jù)的敏感性值預(yù)設(shè)。
2.2 系統(tǒng)設(shè)計(jì)
按照上述的系統(tǒng)主要功能需求,數(shù)據(jù)整合核心服務(wù)層主要分為Spring Batch大數(shù)據(jù)加載和通用服務(wù)數(shù)據(jù)處理兩大部分。Spring Batch+Gemfire+CXF 輕量級(jí)架構(gòu)系統(tǒng)結(jié)構(gòu)如圖2所示。
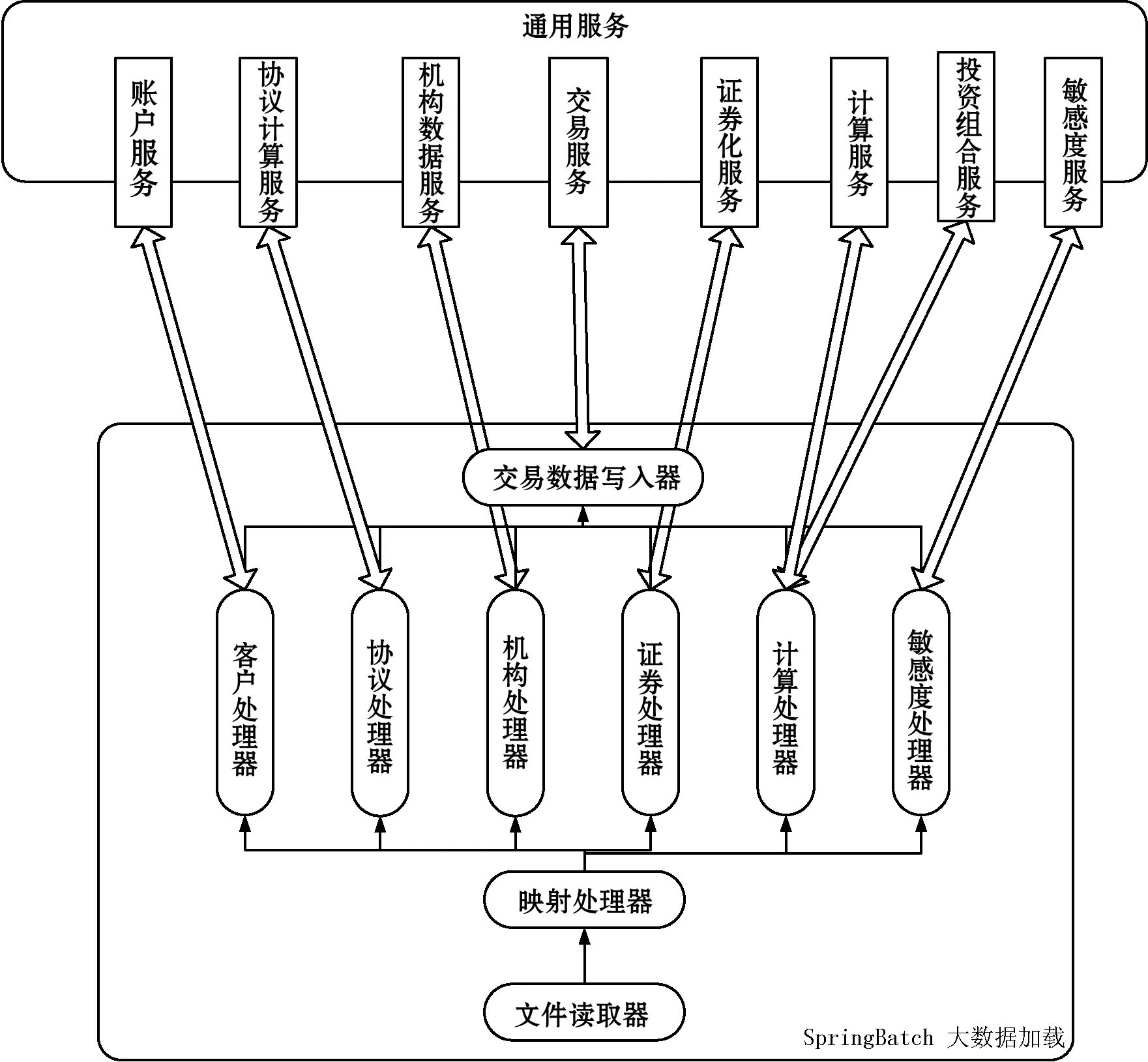
圖2 核心服務(wù)層系統(tǒng)結(jié)構(gòu)圖
本文利用Spring Batch批量讀入大文件,使用Mapper將文件數(shù)據(jù)映射成對(duì)象數(shù)據(jù),根據(jù)數(shù)據(jù)類(lèi)型適配不同的數(shù)據(jù)處理器(Processor),并調(diào)用通用服務(wù)中與之對(duì)應(yīng)的服務(wù)進(jìn)行數(shù)據(jù)處理,將處理完成的數(shù)據(jù)存儲(chǔ)進(jìn)數(shù)據(jù)庫(kù),并發(fā)布在Gemfire cache中。
根據(jù)系統(tǒng)功能劃分,有如下處理器:
(1) 客戶(hù)處理器(Customer Processor):使用Spring Batch導(dǎo)入客戶(hù)及交易對(duì)手信息,并調(diào)用客戶(hù)服務(wù)獲取匹配交易對(duì)手信息。
(2) 協(xié)議處理器(Agreement Processor):使用Spring Batch導(dǎo)入合同信息,并調(diào)用協(xié)議計(jì)算服務(wù)獲取匹配合同以及凈值優(yōu)惠計(jì)算的信息。
(3) 機(jī)構(gòu)處理器(Facility Processor):使用Spring Batch導(dǎo)入客戶(hù)信用信息,并且調(diào)用機(jī)構(gòu)數(shù)據(jù)服務(wù)獲取客戶(hù)信用的信息。
(4) 證券處理器(Securities Processor):使用Spring Batch導(dǎo)入證券信息,并且調(diào)用證券化服務(wù)獲取證券的信息。
(5) 計(jì)算處理器(Calculate Processor):使用Spring Batch導(dǎo)入計(jì)算信息,并且調(diào)用計(jì)算服務(wù)和投資組合服務(wù)來(lái)計(jì)算整個(gè)信息。
(6) 敏感度處理器(Sensitivity Processor):使用Spring Batch導(dǎo)入敏感度信息,并且調(diào)用敏感度服務(wù)來(lái)比較和計(jì)算敏感度。
2.2.1 Spring Batch大數(shù)據(jù)加載
數(shù)據(jù)處理流程如圖3所示。
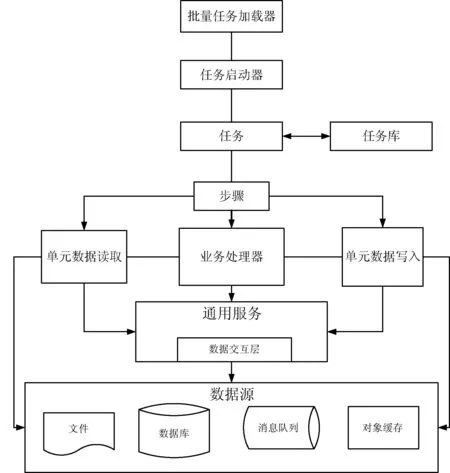
圖3 數(shù)據(jù)處理流程圖
本文將處理的數(shù)據(jù)分解為Job,并且為其定義屬性和基礎(chǔ)設(shè)施,通過(guò)Reader、Processor和Writer來(lái)實(shí)現(xiàn)數(shù)據(jù)業(yè)務(wù)處理、基于Pojo的開(kāi)發(fā)以及領(lǐng)域?qū)ο竺枋觥1疚姆謩e使用了如下組件:
(1) 批量任務(wù)加載器(Batch Loader):使用Autosys定時(shí)啟動(dòng)Spring Batch開(kāi)始處理文件。
(2) 任務(wù)庫(kù)(Job repository):用來(lái)持久化Job的元數(shù)據(jù),是所有Job的中心倉(cāng)庫(kù)。
(3) 任務(wù)啟動(dòng)器(Job launcher):從Job的中心倉(cāng)庫(kù)取出一個(gè)Job,并且啟動(dòng)。
(4) 任務(wù)(Job):Batch操作的基礎(chǔ)執(zhí)行單元。
(5) 步驟(Step):Job的一個(gè)階段,一個(gè)Job由一組Step構(gòu)成,其中Tasklet Step包含一個(gè)事務(wù)過(guò)程,包含重復(fù)執(zhí)行、同步、異步等策略。
(6) 單元數(shù)據(jù)(Item):從數(shù)據(jù)源讀出或?qū)懭氲囊粭l數(shù)據(jù)記錄。
(7) 單元數(shù)據(jù)讀取(Item Reader):從給定的數(shù)據(jù)源讀取Item集合。
(8) 單元數(shù)據(jù)業(yè)務(wù)處理(Item Processor):調(diào)用通用服務(wù)中對(duì)應(yīng)的服務(wù)組件,對(duì)Item進(jìn)行邏輯業(yè)務(wù)處理(包括數(shù)據(jù)映射和數(shù)值計(jì)算等。
(9) 單元數(shù)據(jù)寫(xiě)入(Item Writer):把Item寫(xiě)入數(shù)據(jù)源。
針對(duì)超級(jí)大數(shù)據(jù),我們還可以對(duì)Spring Batch進(jìn)行橫向和縱向的擴(kuò)展,確保整個(gè)系統(tǒng)能夠應(yīng)付超大的數(shù)據(jù)集合壓力。對(duì)任務(wù)進(jìn)行擴(kuò)展的幾種方式如表1所示。

表1 擴(kuò)展方式描述
每個(gè)Step都可以并行處理,Step并行處理模式使用了在一個(gè)節(jié)點(diǎn)上橫向處理,但隨著作業(yè)處理量的增加,如果一臺(tái)節(jié)點(diǎn)服務(wù)器無(wú)法滿(mǎn)足Job的處理,可以采用Partitioning Step的方式將多個(gè)機(jī)器節(jié)點(diǎn)組合起來(lái)完成一個(gè)Job的處理。如圖4所示,主服務(wù)器對(duì)Item讀、寫(xiě)的處理邏輯進(jìn)行分離,通常情況下將讀操作放在一個(gè)節(jié)點(diǎn)進(jìn)行,將寫(xiě)操作分發(fā)到另外的節(jié)點(diǎn)執(zhí)行。這樣做到了負(fù)載均衡和主從復(fù)制,理論上只要增加處理服務(wù)器,就幾乎可以無(wú)限提升Step的處理業(yè)務(wù)能力。

圖4 集群處理結(jié)構(gòu)圖
定義任務(wù)舉例:
……
processor=″compositeItemProcessor″ writer=″cacheWriter″ commit-interval=″1000″ /> …… 上述任務(wù)中,定義了一個(gè)交易數(shù)據(jù)的加載,定義使用fileReader批量文件讀取組件和使用Gemfire的緩存寫(xiě)入cacheWrite,同時(shí)也定義了數(shù)據(jù)處理器Composite Item Processor映射。 核心處理器Spring配置舉例: 在此配置中,使用了數(shù)據(jù)組合類(lèi)Composite Item Processor處理Transaction Item對(duì)象,把Mapping Processor、Customer Processor、Securities Processor、Agreement Processor和Facility Processor、Trade Level Calculation Processor和Remove Obj Reference Processor等單個(gè)處理器“串聯(lián)”在一起生成 Transaction 對(duì)象,這樣就可以通過(guò)調(diào)整配置文件,達(dá)到各個(gè)組件復(fù)用和靈活配置的目的。 以配置中的客戶(hù)處理Customer Processor為例子,在Spring中定義bean: 實(shí)現(xiàn)customerProcessor類(lèi): public class CustomerProcessor implements ItemProcessor public BaseTransaction process(BaseTransaction txn) throws Exception { setAccountDetail(txn); return txn; } protected void setAccountDetail(BaseTransaction txn) { this.accountDataService.matchAccounts(txn); this.transactionService.processHouseAccounts(txn); } } 處理客戶(hù)數(shù)據(jù)需要進(jìn)行兩個(gè)步驟:(1) 將客戶(hù)賬戶(hù)信息進(jìn)行映射;(2) 將集團(tuán)客戶(hù)內(nèi)部掛消帳內(nèi)部處理掉。 2.2.2 Gemfire做數(shù)據(jù)通用服務(wù)的DAO 通用服務(wù)主要提供核心業(yè)務(wù)邏輯處理,并以Web Service方式將數(shù)據(jù)發(fā)布在網(wǎng)絡(luò)上。其主要體系結(jié)構(gòu)如圖5所示。 圖5 通用服務(wù)系統(tǒng)結(jié)構(gòu)圖 本文主要采用面向接口的方式對(duì)通用服務(wù)進(jìn)行設(shè)計(jì)。通過(guò)Java Interface。接口中對(duì)服務(wù)實(shí)現(xiàn)方法進(jìn)行抽象定義,并對(duì)方法進(jìn)行具體實(shí)現(xiàn)。通過(guò)面向接口編程,可以完成統(tǒng)一調(diào)用,應(yīng)用在不同數(shù)據(jù)源上,比如對(duì)于同一個(gè)DAO接口,分別有Gemfire、jdbc、hibernate以及jms的實(shí)現(xiàn),當(dāng)Service調(diào)用DAO的save功能時(shí),可以同步完成對(duì)Gemfire、數(shù)據(jù)庫(kù)以及jms的數(shù)據(jù)存儲(chǔ)(發(fā)布)。 本文以交易服務(wù)為例,定義了Transaction Data Service的創(chuàng)建交易數(shù)據(jù)(create)接口: public interface TransactionDataService { public void create(BaseTransaction tx); } GemfireDAO通過(guò)對(duì)緩存節(jié)點(diǎn)Region塊的存儲(chǔ)傳入交易數(shù)據(jù),實(shí)現(xiàn)了創(chuàng)建交易數(shù)據(jù)(create)接口,在實(shí)現(xiàn)過(guò)程中,注意使用同步來(lái)確保數(shù)據(jù)的原子性: public class TransactionGemfireDAOImpl implements TransactionDAO { public BaseTransaction create(BaseTransaction tx) { if(tx != null){ this.getTransactionRegion().put(tx.getId(),tx); } return tx; } public Region String regionName = ″/transactionRegion″; if(this.transactionRegion == null){ synchronized(this){ this.transactionRegion = RegionUtils.getRegionByName(regionName); } } return transactionRegion; } … } 2.2.3 CXF完成通用服務(wù)數(shù)據(jù)接口發(fā)布 通用服務(wù)通過(guò)CXF發(fā)布標(biāo)準(zhǔn)的Web Service,不僅可以做到水平橫向擴(kuò)展,同時(shí)也方便與下游系統(tǒng)主要系統(tǒng)對(duì)接,按照其要求定義對(duì)應(yīng)的接口,本文以敏感性分析為例,在保持其他條件不變的前提下,研究單個(gè)市場(chǎng)風(fēng)險(xiǎn)要素(利率、匯率、股票價(jià)格和商品價(jià)格)的變化可能會(huì)對(duì)金融工具或資產(chǎn)組合的收益或經(jīng)濟(jì)價(jià)值產(chǎn)生的影響。 在Web.xml中除了傳統(tǒng)加載Spring配置文件外,還需要加載CXF的Servlet,完成Web Service的映射: 在Spring中定義bean: 本文還定義了Sensitivity接口: @WebService public class SensitivityWebSerivce implements SensitivityService { @WebMethod public String getTransactionss(@Webparam(name=″asOfDate″)String asOfDate, @WebParam(name=″tradeType″)){ Criteria criteria = new Criteria(asOfDate, tradeType); return transactionDataService.getTransactions(criteria); } … } 本文通過(guò)定義一個(gè)敏感度的查詢(xún)數(shù)據(jù)接口,直接調(diào)用內(nèi)部的Transaction Service查詢(xún)接口,間接地把內(nèi)部交易服務(wù)標(biāo)準(zhǔn)的Web Service的方式提供給下游系統(tǒng)使用。同時(shí)因?yàn)椴捎玫氖欠植际讲渴穑到y(tǒng)擴(kuò)展很方便,下游運(yùn)行報(bào)表期間,直接增加CXF的節(jié)點(diǎn)就輕松應(yīng)對(duì)了高訪(fǎng)問(wèn)需求,同時(shí)隔離了對(duì)數(shù)據(jù)庫(kù)的壓力。 本文在使用Spring Batch+Gemfire+CXF框架重構(gòu)了整個(gè)整合系統(tǒng)后,在銀行內(nèi)部管理系統(tǒng)中的3臺(tái)8核CPU的虛擬機(jī)(SpringBatch 80 GB內(nèi)存,Gemfire 120 GB內(nèi)存,CXF80 GB內(nèi)存)上進(jìn)行了UAT環(huán)境測(cè)試實(shí)驗(yàn)。計(jì)算處理1.4 TB數(shù)據(jù)所需時(shí)間從2小時(shí)變?yōu)?0分鐘。此外,通過(guò)提升部分風(fēng)險(xiǎn)計(jì)算服務(wù)器CPU性能,進(jìn)一步提升了空間。下游系統(tǒng)讀取系統(tǒng)穩(wěn)定性大大增強(qiáng),沒(méi)有再發(fā)生因?yàn)橄掠蜗到y(tǒng)查詢(xún)導(dǎo)致核心數(shù)據(jù)庫(kù)宕機(jī)的情況,極大地節(jié)省了人力維護(hù)成本和機(jī)器運(yùn)行成本。 傳統(tǒng)巴塞爾數(shù)據(jù)整合系統(tǒng)依賴(lài)存儲(chǔ)過(guò)程和ETL工具,系統(tǒng)復(fù)雜,性能較差,而Spring Batch 和Gemfire的整合應(yīng)用在業(yè)界整合使用案例較少。本文提出一套全新的基于Spring Batch+Gemfire+CXF輕量級(jí)應(yīng)用架構(gòu)來(lái)處理海量的巴塞爾整合數(shù)據(jù),用于替代之前大量的存儲(chǔ)過(guò)程的設(shè)計(jì)。整個(gè)系統(tǒng)通過(guò)實(shí)際測(cè)試、運(yùn)行,表現(xiàn)良好,具有各層間低耦合、高擴(kuò)展性、高可靠性的特點(diǎn),性能遠(yuǎn)超傳統(tǒng)依賴(lài)存儲(chǔ)過(guò)程的數(shù)據(jù)整合系統(tǒng)。基于Spring Batch+Gemfire+CXF架構(gòu)是一個(gè)行之有效的輕量級(jí)、大數(shù)據(jù)、低成本應(yīng)用整合解決方案,可以推廣到大數(shù)據(jù)、高可用、企業(yè)級(jí)、可伸縮的企業(yè)、銀行等應(yīng)用開(kāi)發(fā)中。
3 應(yīng)用效果
4 結(jié) 語(yǔ)
猜你喜歡
心理學(xué)報(bào)(2022年4期)2022-04-12 07:38:02
水泵技術(shù)(2021年3期)2021-08-14 02:09:20
財(cái)經(jīng)(2017年2期)2017-03-10 14:35:35
財(cái)經(jīng)(2016年15期)2016-06-03 07:38:02
財(cái)經(jīng)(2016年3期)2016-03-07 07:44:46
山東青年(2016年1期)2016-02-28 14:25:25
財(cái)經(jīng)(2016年6期)2016-02-24 07:41:51
中國(guó)慣性技術(shù)學(xué)報(bào)(2015年1期)2015-12-19 13:12:17
當(dāng)代修辭學(xué)(2014年3期)2014-01-21 02:30:44
公務(wù)員文萃(2013年5期)2013-03-11 16:08:37
