數據挖掘在全國計算機等級考試(NCRE)成績分析中的研究及應用
2020-09-02 01:36:08徐承俊朱國賓
計算機應用與軟件 2020年8期
關鍵詞:關聯
徐承俊 朱國賓
(武漢大學遙感信息工程學院 湖北 武漢 430079)
0 引 言
信息化的發展使得計算機的作用越發凸顯,也改變著我們的生活方式。在我國,絕大部分企業、高校等,尤其是大專類院校,把計算機等級證書作為學生是否真正掌握計算機實際操作的衡量標準,要求學生畢業前盡可能獲得全國計算機一、二級證書。但從考試實際情況看仍存在優秀率低、高級別通過率低等問題。這些問題引起了學校、學院的高度重視,同時也令老師和學生感到很困惑。老師無法從考生成績中找到規律性的原因,學生則很難進行針對性復習和應考。事實上,從一個龐大且復雜的數據中挖掘隱藏的數據信息,需要采用新的方法和技術,而數據挖掘技術無疑是目前最為有效的方法。
國外對數據挖掘的研究起步早,發展快。近些年主要研究集中在:(1) 天文系統,如加州理工學院計算機專家與天文學家共同開發的天文SKICAT系統[1];(2) 金融行業,如金融系統中甄別洗錢FAIS系統[2];(3) 零售行業,如超市銷售異常情況分析OPPORTUNITYEXPLORER系統[3]等。但這些研究幾乎不涉及對影響考試成績因素的挖掘。
國內高校主要將數據挖掘應用于高校教學與管理,如北京市科學技術委員會重點課題《教育考試數據挖掘的研究與實現》[4],挖掘教育考試數據內在關聯;將教育數據挖掘應用于招生、就業、后勤服務等各方面[5]。
以上研究主要涉及行業研究,很少有學者對某一具體考試中影響成績合格、優秀等因素展開研究。本文提出基于數據挖掘關聯規則Apriori算法和C4.5算法相結合建立考試成績分析模型,建立學生對課程的熱愛程度、課前預習、課后復習和各種題型與成績的關聯,以2016年考試數據為訓練集,2017年考試數據為測試集,根據實際成績進行對比論證。挖掘導致優秀率低、高級別通過率低的原因,并將得到的信息反饋給教師,以提高教學效率,查漏補缺,提高考試優秀率和高級別類通過率。
1 技術路線
1.1 Apriori
本文針對不同專業的考生成績和各種題型,如單選題、基本操作題、OFFICE操作題(Word,Excel,PPT)、上網操作題得分為目標,分析其內在的關聯,挖掘出各類題型得分對成績不合格、合格和優秀的影響。基于這些關聯,本文采用關聯規則Apriori算法[6],偽代碼如下:
L1 =fINd_frequent_1-itemsets(D);
//找出頻繁1項集
FOR(k=2;Lk-1 !=null;k++){
//產生候選,并剪枝
Ck =apriori_gen(Lk-1 );
//掃描D進行候選計數
FOR each 事務t IN D{
Ct =subset(Ck,t);
//得到t的子集FOR each 候選c屬于Ct
c.count++;}
//返回候選項集中不小于最小支持度的項集
Lk ={c 屬于 Ck | c.count>=mIN_sup}}
RETURN L= 所有的頻繁集;
第一步:連接(joIN)
Procedure apriori_gen(Lk-1 :frequent(k-1)-itemsets)
FOR each 項集 l1 屬于 Lk-1
FOR each 項集 l2 屬于 Lk-1
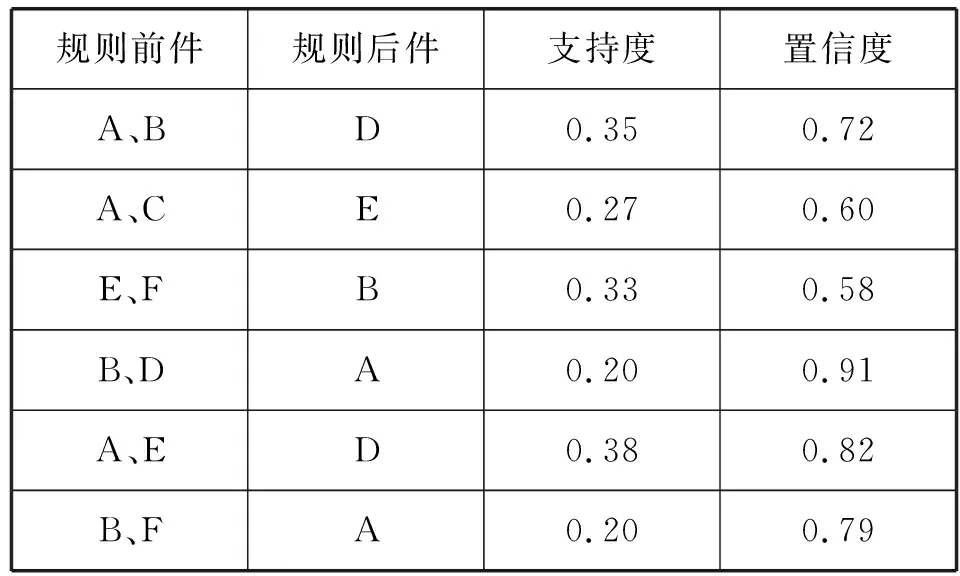
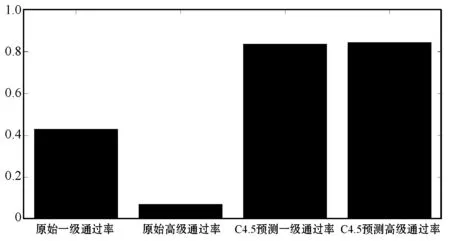
IF( (l1 [1]=l2 [1])&&( l1 [2]=l2 [2])&& ……&& (l1 [k-2]=l2 [k-2])&&(l1 [k-1] THEN{ c = l1 連接 l2 //連接步:產生候選 //若k-1項集中已經存在子集c則進行剪枝 IF has_INfrequent_subset(c, Lk-1 ) THEN delete c; //剪枝步:刪除非頻繁候選 else add c to C} RETURN Ck; 第二步:剪枝(prune) Procedure has_INfrequent_sub(c:candidate k-itemset;Lk-1: frequent(k-1)-itemsets) FOR each (k-1)-subset s of c IF s 不屬于 Lk-1 THEN RETURN true; RETURN false; Apriori算法每輪迭代都要掃描數據集,因此在數據集很大、數據種類很多的情況下,算法效率很低。本文引入C4.5算法,其具有如下優點:(1) 效率高。數據計算量小,減少因計算而花費的時間和精力,提高效率。(2) 便于客戶理解。研究結果既反饋給教師,又反饋給學生,對其理解和解析所需的專業背景知識要求低。樹形結構簡單易懂,簡單的IF語句即可實現。(3) 數據類型靈活。既能對離散數據,又能對連續數據進行處理。(4) 結構清晰。 從“學生對該課程的熱愛程度”、“課前預習、課后復習”、“課堂上機實踐完成程度”和“學前原有知識儲備”等多個方面來分析構造決策樹。將兩種算法有機結合,更具有普遍性,使得數據分析結果更具有說服力。 C4.5算法偽代碼如下[7]: 訓練樣本集D={(x1,y1),(x2,y2),…,(xn,yn)} 屬性集A={a1,a2,…,an} TreeGenerate(D,A): //生成節點node IF D中樣本全屬于同一類別C: 將node標記為C類葉節點 RETURN END IF IF 屬性集A為空或者D的所有屬性值均一樣: 將node標記為最多類 RETURN END IF 從A中選取最佳劃分屬性a* FOR a IN a*: 為node生成一個分支,令Dv表示D中在a*屬性值為a的樣本子集 IF Dv為空: contINue; else:TreeGenerate(Dv,A{a*})遞歸繼續 END IF END FOR 關聯規則的支持度(support)為: support(A?B)=P(A∪B) 關聯規則的置信度(confidence)為: confidence(A?B)= P(B|A)=support(A∪B)/supportA= support_count(A∪B)/support_count(A) 項集的出現頻度(support_count):包含項集的事務數,即為項集的計數。 根據上述公式,找出所有的頻繁項集以及由頻繁項集產生強關聯規則。 關聯規則如表1所示。其中:A代表單選,B代表基本操作,C代表Word操作,D代表Excel操作,E代表PPT操作,F代表上網操作,G代表總成績。 表1 關聯規則表 結果分析: ① 單選和基本操作同時為優秀,總成績有72%優秀可能。 ② 單選和Word操作同時為優秀,總成績有60%優秀可能。 ③ PPT和上網同時為優秀,總成績有58%優秀可能。 ④ 基本操作和Excel同時為優秀,總成績有91%優秀可能。 ⑤ 單選和PPT同時為優秀,總成績有82%優秀可能。 ⑥ 基本操作和PPT同時為優秀,總成績有79%優秀可能。 可以發現,考生在Word、Excel和PPT三種題型上的表現對考試總分的影響較大。 信息增益公式: 式中:D表示訓練集;k表示類的不同屬性的取值數;pi是訓練集D中任意元素在k個類的不同屬性所占的比率。Info(D)也稱為D的熵。 信息增益率公式為: splitRatio(A,D)=[Split(A,D)-Info(A,D)]/ Split(A,D) 式中:Split(A,D)表示屬性A對D的分裂信息量;splitRatio(A,D)表示屬性A對D的分裂信息量的變化率。用信息增益率最大的作為決策樹根,因“平時成績”有最大信息增益率,故將其作為根節點,對每個屬性建立分支并生產決策樹,得到如圖1所示決策樹。 圖1 部分數據的決策樹 結果分析: ① IF(“原有知識儲備”=“無”)&&(“課前預習”=“無”)&&(“課后復習”=“無”)&&(“感興趣程度”=“喜歡”)then “是否通過”=“否”。 ② IF(“原有知識儲備”=“有”)&&(“課前預習”=“無”)&&(“課后復習”=“無”)&&(“感興趣程度”=“喜歡”)then “是否通過”=“否”。 ③ IF(“原有知識儲備”=“有”)&&(“課前預習”=“無”)&&(“課后復習”=“無”)&&(“感興趣程度”=“厭惡”)then “是否通過”=“否”。 ④ IF(“原有知識儲備”=“無”)&&(“課前預習”=“無”)&&(“課后復習”=“無”)&&(“感興趣程度”=“厭惡”)then “是否通過”=“否”。 可以發現,“平時成績”對考試是否通過影響比較大,“課后鞏固”也很重要。 本文以2016年考試數據為訓練集,對2017年考試數據預測,結果如圖2、圖3所示。 圖2 實際成績與Apriori預測對照圖 圖3 實際成績與C4.5決策樹預測對照圖 如圖2所示,應用Apriori對1 200名考生的考試成績進行預測,發現1 002名考生數據正確,198名考試數據錯誤,實際考試通過率為83.5%。 如圖3所示,應用決策樹對1 200名考生的考試成績進行預測,發現1 013名考生數據正確,187名考試數據錯誤,實際考試通過率為84.4%。 Apriori算法與C4.5算法預測對比如圖4所示。可以看出,C4.5算法準確度要比Apriori算法略高一些,因為在實際考試中,基于Apriori算法中各個題型得分由考生掌握知識點程度決定,得分相對穩定,但是考試過程中的狀態,例如預習、復習時間長短、復習效率都易受到情緒波動影響,C4.5算法預測會有一些波動,但只影響其預測值。兩個算法預測值基本相同,由此可見,兩個算法總體上的可信度是可取的。 圖4 Apriori算法與C4.5算法預測對比圖 基于上述模型分析,挖掘出導致考試一級優秀率低和高級別通過率低原因:(1) 各類題型作答優秀直接影響考試優秀率;(2) 自身主觀原因,如“課前預習”“課后復習”“感興趣程度”等都是導致通過率、優秀率低的原因。將這些信息反饋給教師和學生。在教師層面,教師對學生因材施教,培養學生自主學習的良好習慣,保持良好的學習態度和方法。在學生層面,學生可以通過決策樹分析自己在學習過程中的問題,并結合關聯規則的相關結論,把握各題型的作答重點,有針對性地進行訓練操作。 將本文方法應用于2018年全國計算機等級考試,優秀率、通過率對比如圖5所示。可以看出,該方法使得一級優秀率平均提升25%,高級通過率平均提升50%。 圖5 2018年全國計算機等級考試優秀率、通過率對比圖 本文主要以2016年、2017年考生成績庫為研究基礎,從以下兩個方面分析:(1) 從題型入手,采用基于Apriori算法針對不同的題型,找出它們之間的關聯規則,發現題型本身的關聯及影響;(2) 基于C4.5決策樹,以學生“原有知識儲備”、“課前預習”“課后復習”“感興趣程度”等為切入點,構建決策樹模型,找到考生不合格的原因。通過兩種算法的研究和分析,挖掘出隱含在考試數據庫信息,并將研究結果反饋給授課教師及學生。實驗結果表明,本文方法能夠有效提高全國計算機等級考試通過率及優秀率。1.2 C4.5
2 算法實現
2.1 Apriori關鍵計算
2.2 C4.5關鍵計算

3 討論及分析



4 結 語
猜你喜歡
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:30
當代陜西(2021年17期)2021-11-06 03:21:36
原道(2020年2期)2020-12-21 05:47:06
當代陜西(2019年15期)2019-09-02 01:52:00
中國非營利評論(2018年2期)2018-06-18 10:48:50
學苑創造·A版(2018年11期)2018-02-01 06:29:20
自動化學報(2017年1期)2017-03-11 17:31:17
讀者(2017年5期)2017-02-15 18:04:18
西藏科技(2016年5期)2016-09-26 12:16:39
振動工程學報(2015年1期)2015-03-01 01:15:42
