粒子群優(yōu)化神經(jīng)網(wǎng)絡(luò)在船舶輔鍋爐故障診斷中的應(yīng)用
2020-09-02 01:22:30高鶴元甘輝兵楊遠(yuǎn)達(dá)
計算機(jī)應(yīng)用與軟件 2020年8期
高鶴元 甘輝兵 鄭 卓 楊遠(yuǎn)達(dá)
(大連海事大學(xué)輪機(jī)工程學(xué)院 遼寧 大連 116001)
0 引 言
船舶輔鍋爐用來產(chǎn)生飽和水蒸氣,是保證船舶正常航行的重要設(shè)備之一,其主要用于船上油類加熱、主機(jī)預(yù)熱及提供各種生活用汽[1]。對于蒸汽系統(tǒng)而言,船舶輔鍋爐十分重要。一旦該系統(tǒng)在運(yùn)行過程中出現(xiàn)故障或在使用和操作中出現(xiàn)問題,會影響船舶運(yùn)營,甚至有可能降低船舶的收益。而傳統(tǒng)意義上的船舶故障診斷只依靠機(jī)艙輪機(jī)員的經(jīng)驗(yàn)判斷,難免會出現(xiàn)不準(zhǔn)確的判斷和決策上的失誤[2]。目前國內(nèi)外在大型機(jī)械故障診斷中多使用BP神經(jīng)網(wǎng)絡(luò)、支持向量機(jī)和故障樹等方法[3]。這些方法需要對大量已知故障樣本數(shù)據(jù)進(jìn)行學(xué)習(xí),以達(dá)到預(yù)期的準(zhǔn)確率,從而實(shí)現(xiàn)對未知數(shù)據(jù)的診斷。但實(shí)際上,大部分實(shí)驗(yàn)室條件不足,船舶故障特征信號難以獲得,往往只有正常數(shù)據(jù),缺少故障數(shù)據(jù),導(dǎo)致有監(jiān)督學(xué)習(xí)的研究難以有效開展。
無監(jiān)督學(xué)習(xí)分類方法的依據(jù)是樣本特征參數(shù)與統(tǒng)計決策規(guī)則,就是在無任何已知類樣本的前提下,通過分析數(shù)據(jù)內(nèi)在結(jié)構(gòu)、樣本相似度、概率密度函數(shù)估計等方法對樣本數(shù)據(jù)實(shí)現(xiàn)正確分類[4]。這種方法不需要準(zhǔn)確的數(shù)學(xué)模型,具有較好的自組織學(xué)習(xí)性和較強(qiáng)的容錯、泛化能力,能夠較好地實(shí)現(xiàn)待分類數(shù)據(jù)的非線性映射[5]。
自組織特征映射(SOM)神經(jīng)網(wǎng)絡(luò)于1987年提出,屬于無導(dǎo)師學(xué)習(xí)網(wǎng)絡(luò),可以對任意模擬輸入信號進(jìn)行區(qū)域分類[6]。SOM網(wǎng)絡(luò)具有向周圍環(huán)境學(xué)習(xí)并通過自我學(xué)習(xí)改善自身性能的能力,所以無須對大量樣本數(shù)據(jù)進(jìn)行訓(xùn)練,目前在電機(jī)系統(tǒng)、轉(zhuǎn)子系統(tǒng)和污水處理等故障診斷領(lǐng)域均得到了廣泛的運(yùn)用[7-9]。
為了避免SOM網(wǎng)絡(luò)通過“硬競爭”方式選取獲勝神經(jīng)元導(dǎo)致分類錯誤等問題,本文采用粒子群(Particle swarm optimization,PSO)算法優(yōu)化SOM更新權(quán)值過程,并對船舶輔鍋爐某燃燒工況下的運(yùn)行數(shù)據(jù)進(jìn)行對比分析。仿真結(jié)果表明,優(yōu)化后的算法用于聚類計算時,很好地克服了權(quán)值初始化、識別準(zhǔn)確率不高等缺點(diǎn),提高了船舶輔鍋爐燃燒故障診斷的聚類精度,取得了更好的識別效果。
1 PSO優(yōu)化的SOM神經(jīng)網(wǎng)絡(luò)
1.1 SOM神經(jīng)網(wǎng)絡(luò)
SOM網(wǎng)絡(luò)是一種可以進(jìn)行自組織學(xué)習(xí)的競爭型神經(jīng)網(wǎng)絡(luò),自適應(yīng)學(xué)習(xí)能力強(qiáng)、魯棒性好。其學(xué)習(xí)方式與人腦中的生物神經(jīng)網(wǎng)絡(luò)相似,可以自主尋找樣本數(shù)據(jù)中的本質(zhì)屬性和內(nèi)在規(guī)律,從而改變自身網(wǎng)絡(luò)結(jié)構(gòu)和相關(guān)參數(shù)[10]。SOM網(wǎng)絡(luò)結(jié)構(gòu)簡單,具有良好的非線性擬合性、生物神經(jīng)元特性和聚類自動性[11]。SOM網(wǎng)絡(luò)通過輸出層神經(jīng)元互相競爭,與輸入向量進(jìn)行匹配,選擇其中一個最合適的神經(jīng)元獲勝,然后修正獲勝神經(jīng)元領(lǐng)域相關(guān)的權(quán)值向量。SOM網(wǎng)絡(luò)結(jié)構(gòu)如圖1所示,其分為下層輸入層和上層競爭層。輸入層輸入初始向量,輸出層的輸出節(jié)點(diǎn)之間由權(quán)值連接,排成一個節(jié)點(diǎn)矩陣,相互激勵或抑制。
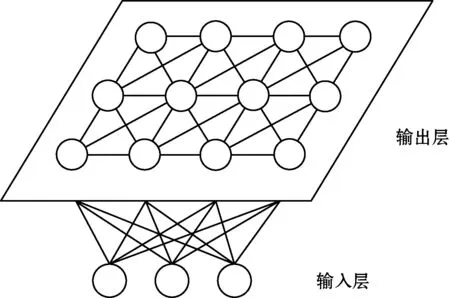
圖1 SOM網(wǎng)絡(luò)結(jié)構(gòu)圖
其學(xué)習(xí)算法步驟如下:
(1) 隨機(jī)數(shù)初始化輸入層與映射層之間的權(quán)值Wij。
(2) 把向量X=(X1,X2,…,Xn)輸入給輸入層。
(3) 計算各神經(jīng)元的權(quán)值向量和輸入向量的歐氏距離。
(1)
(4) 選擇使dj最小的神經(jīng)元作為獲勝神經(jīng)元,記作j*。
(5) 更新獲勝神經(jīng)元及其鄰域權(quán)值:
Δwij=wij(t+1)-wij(t)=η(t)(xi-wij)
(2)
式中:η(t)是(0,1)上的常數(shù)。
(6) 若達(dá)到目標(biāo)要求則算法結(jié)束;否則返回步驟(2)。
SOM網(wǎng)絡(luò)二維平面上的節(jié)點(diǎn)之間依據(jù)Kohonen學(xué)習(xí)規(guī)則,學(xué)習(xí)輸入向量的分布情況和拓?fù)浣Y(jié)構(gòu),對獲勝神經(jīng)元及附近由近及遠(yuǎn)的神經(jīng)元產(chǎn)生由興奮到抑制的影響[12]。若一個神經(jīng)元的權(quán)值與輸入向量模式相差很大,則其可能永遠(yuǎn)不會成為獲勝神經(jīng)元,其權(quán)值無法得到任何有效的學(xué)習(xí)訓(xùn)練,成為“死神經(jīng)元”,進(jìn)而降低網(wǎng)絡(luò)計算時的收斂速度與聚類精度[13]。所以SOM網(wǎng)絡(luò)對初始權(quán)值的設(shè)置有較大的依賴性,會影響網(wǎng)絡(luò)的收斂速度和學(xué)習(xí)效果。
1.2 粒子群優(yōu)化算法
粒子群優(yōu)化算法源于生物群體尋找食物等行為,學(xué)習(xí)“種群”和“進(jìn)化”的思想,無須執(zhí)行選擇、交叉以及變異等算子,通過個體協(xié)作與競爭實(shí)現(xiàn)復(fù)雜空間最優(yōu)解的搜索[14]。PSO無需神經(jīng)導(dǎo)數(shù)等梯度信息,通過全局尋優(yōu),可以簡單實(shí)現(xiàn)全局優(yōu)化[15]。每個粒子的特征用方向、速度和適應(yīng)度值來表示。適應(yīng)度值由適應(yīng)度函數(shù)計算得到,用來表示粒子的優(yōu)劣。假設(shè)在可解空間中初始化一群粒子,每個粒子都存在一個優(yōu)化問題的潛在最優(yōu)解。優(yōu)化過程就是粒子逐代搜索,計算適應(yīng)度值,朝著群體最好的地點(diǎn)和歷史最好的方向移動,尋找最優(yōu)解[16]。每一代粒子通過跟蹤個體極值和全局極值來更新個體位置。個體極值是指粒子本身所經(jīng)過位置中適應(yīng)度值最優(yōu)的位置,群體極值是指整個種群搜索得到的適應(yīng)度最優(yōu)位置。粒子每更新一次位置,就計算一次適應(yīng)度值,通過比較適應(yīng)度值更新Pbest和Gbest的位置。
假設(shè)在D維空間中存在一個由n個粒子組成的種群X=(X1,X2,…,Xn),其中第i個粒子速度用Vi=(Vi1,Vi2,…,ViD)T表示,該粒子個體極值和群體極值分別為Pi=(Pi1,Pi2,…,PiD)T和Pg=(Pg1,Pg2,…,PgD)T。粒子每次迭代更新自身速度和位置的公式為:
(3)
(4)
式中:ω為慣性權(quán)重;k為當(dāng)前迭代次數(shù);c1和c2是非負(fù)常數(shù),稱為加速因子或?qū)W習(xí)因子;r1和r2是[0,1]上均勻分布的隨機(jī)數(shù)。
1.3 PSO優(yōu)化的SOM神經(jīng)網(wǎng)絡(luò)分類方法
SOM神經(jīng)網(wǎng)絡(luò)與其他競爭型神經(jīng)網(wǎng)絡(luò)算法相比精度較高,收斂速度較快,但是權(quán)值的隨機(jī)初始化導(dǎo)致網(wǎng)絡(luò)環(huán)境復(fù)雜,影響收斂速度,且對于數(shù)據(jù)相識度較高的故障類型,識別準(zhǔn)確度下降。為了解決上述問題,本文使用PSO算法優(yōu)化神經(jīng)網(wǎng)絡(luò),稱為P-SOM算法。算法將SOM神經(jīng)網(wǎng)絡(luò)的權(quán)值向量看作一個個粒子,將樣本分類結(jié)果與實(shí)際分類的誤差率作為適應(yīng)度函數(shù),迭代過程就是更新權(quán)值向量使適應(yīng)度函數(shù)達(dá)到最小。通過更新每個粒子的位置來更新每個權(quán)值向量。達(dá)到一定迭代次數(shù)之后,再利用優(yōu)化后的SOM網(wǎng)絡(luò)權(quán)值向量尋找獲勝神經(jīng)元。算法流程見圖2。

圖2 SOM結(jié)合PSO的算法流程
具體步驟如下:
Step1將提取的特征樣本集進(jìn)行數(shù)據(jù)預(yù)處理,對樣本數(shù)據(jù)進(jìn)行歸一化后作為神經(jīng)網(wǎng)絡(luò)的輸入。
Step2初始化SOM網(wǎng)絡(luò),獲取初始權(quán)值向量,確定SOM網(wǎng)絡(luò)結(jié)構(gòu)。
Step3用隨機(jī)數(shù)初始化種群,同時初始化粒子的速度、位置及個體極值和全局極值。
Step4按式(3)和式(4)跟蹤計算每個粒子的速度和位置,得出個體極值和全局極值,并更新粒子的位置和速度。
Step5將更新后的粒子代入SOM網(wǎng)絡(luò)尋找獲勝神經(jīng)元,計算相應(yīng)的適應(yīng)度值。
Step6判斷迭代次數(shù)是否達(dá)到要求,是則算法結(jié)束,否則返回Step4。
2 船舶輔鍋爐燃燒故障診斷
船舶航行時,當(dāng)船舶輔鍋爐出現(xiàn)燃燒故障時,通常是由航行輪機(jī)員依據(jù)經(jīng)驗(yàn)對點(diǎn)火油路、主油路、回油路的燃燒設(shè)備逐一進(jìn)行檢查,清潔更換后分別點(diǎn)火測試,診斷故障。但船舶輔鍋爐的故障種類繁多,引發(fā)這些故障的原因繁雜,需要監(jiān)測的故障點(diǎn)也很多,傳統(tǒng)故障診斷方法很難滿足需求。而且船舶輔鍋爐的工作環(huán)境特殊,會對輪機(jī)員造成一定的影響,判斷故障時可能會出現(xiàn)失誤。因此,應(yīng)用神經(jīng)網(wǎng)絡(luò)對輔鍋爐燃燒運(yùn)行時的數(shù)據(jù)特征進(jìn)行分析,智能診斷故障尤為重要。
本文主要對船舶輔鍋爐點(diǎn)火失敗、燃燒過程中熄火、燃燒不穩(wěn)定等常見燃燒故障進(jìn)行診斷研究。輔鍋爐點(diǎn)火失敗的原因主要有:點(diǎn)火噴油器機(jī)械故障,點(diǎn)火電極積泥或堵塞;主油路供油泵機(jī)械故障,燃油未達(dá)到指定狀態(tài);控制燃燒電路故障,如供油電磁閥和伺服電動機(jī)控制線路短路,線路絕緣層老化、斷路等;供風(fēng)系統(tǒng)故障;安全保護(hù)裝置起作用等。本文以大連海事大學(xué)開發(fā)的DMSVLCC輪機(jī)模擬器的船舶輔鍋爐為研究對象進(jìn)行實(shí)驗(yàn)研究。DMSVLCC輔鍋爐為大型燃油鍋爐,其仿真模型數(shù)據(jù)與設(shè)計值的誤差在允許范圍之內(nèi),滿足精度要求,并已經(jīng)投入教學(xué)使用。其主要技術(shù)參數(shù)如表1所示,DMSVLCC輔鍋爐低負(fù)荷運(yùn)行界面如圖3所示。
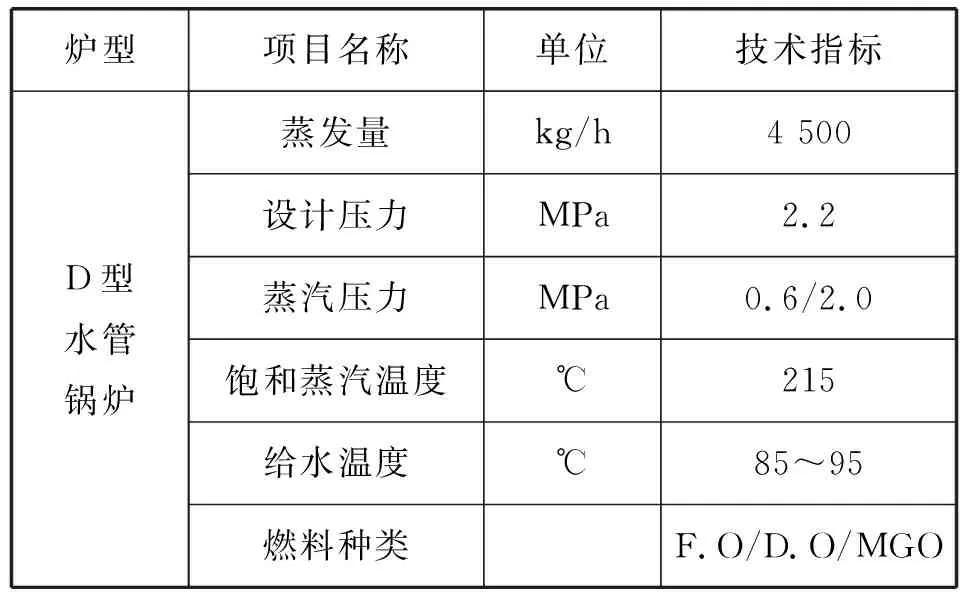
表1 DMSVLCC輔鍋爐主要技術(shù)參數(shù)
3 實(shí)例分析
3.1 測試描述
DMSVLCC輔鍋爐燃油簡化系統(tǒng)管路如圖4所示,針對上述輔鍋爐燃燒系統(tǒng)可能出現(xiàn)的常見故障,在DMSVLSS模擬器上設(shè)置4種故障。在圖中管路上布置監(jiān)測點(diǎn),提取特征參數(shù)。在低負(fù)荷工況5種運(yùn)行狀態(tài)下分別采集輔鍋爐燃燒系統(tǒng)的12個參數(shù),表2為低負(fù)荷工況下DMSVLCC輔鍋爐燃燒系統(tǒng)部分參數(shù)及范圍。
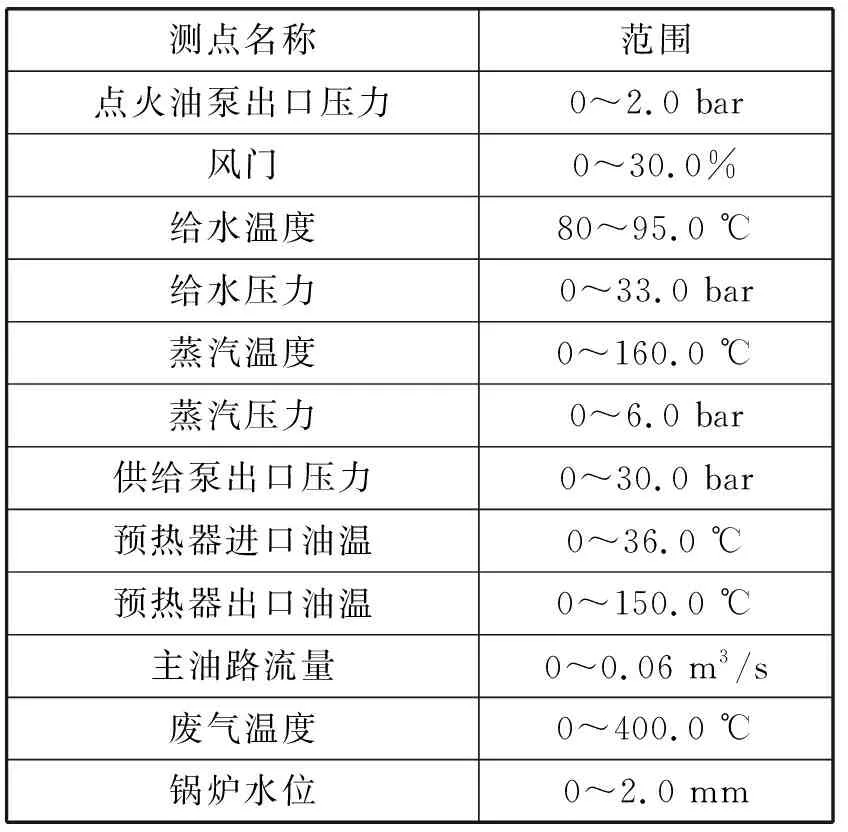
表2 燃油系統(tǒng)部分監(jiān)測點(diǎn)參數(shù)
將采集的樣本數(shù)據(jù)按運(yùn)行狀態(tài)分為5組,每組采集16個樣本數(shù)據(jù),樣本號1-16、17-32、33-48、49-64、65-80各為一組,共獲得80個樣本進(jìn)行聚類試驗(yàn)。類別依次為正常運(yùn)行、燃油供給泵磨損、燃油預(yù)熱器臟堵、點(diǎn)火油泵故障、風(fēng)機(jī)故障。
3.2 數(shù)據(jù)預(yù)處理
考慮到船舶輔鍋爐參數(shù)具有不確定性和復(fù)雜性,12種特征參數(shù)存在較大差異,具有不同的量綱和數(shù)量級等特點(diǎn),所以先對樣本進(jìn)行歸一化處理,統(tǒng)一將樣本數(shù)據(jù)映射到[0,1]區(qū)間上,去除樣本數(shù)據(jù)對單位的限制,避免數(shù)值過大或過小對網(wǎng)絡(luò)計算聚類產(chǎn)生的影響。
樣本數(shù)據(jù)歸一化之后構(gòu)成80×12的樣本特征矩陣。為了在不影響原始輸入向量結(jié)構(gòu)與聚類準(zhǔn)確度的前提下加快神經(jīng)網(wǎng)絡(luò)的收斂速度,本文采用主成分分析法(PCA)降低原始特征矩陣空間的維數(shù),結(jié)果如圖5所示。可以看出,第一主成分對應(yīng)的貢獻(xiàn)率為74.39%,第二主成分對應(yīng)的貢獻(xiàn)率為16.96%,第三主成分對應(yīng)的貢獻(xiàn)率為6.58%,前三個主成分的累積貢獻(xiàn)率可以達(dá)到97.94%。所以將原始16維空間降到3維特征空間對特征矩陣的影響較小。由此刪除了多余變量,提升了故障診斷的工作效率。

圖5 主成分對應(yīng)貢獻(xiàn)率
5組樣本數(shù)據(jù)經(jīng)PCA降維后的空間分布如圖6所示。可以看出,第1、4、5組的樣本空間分布趨勢相似,分布空間較為接近,在神經(jīng)網(wǎng)絡(luò)聚類時容易產(chǎn)生錯誤;第2、3組樣本分布遠(yuǎn)離第1、4、5組,分布比較集中且更明顯。
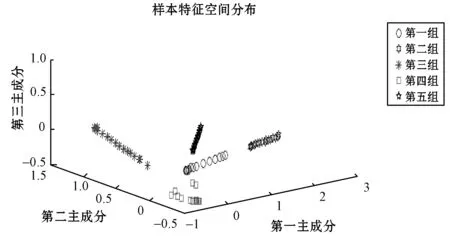
圖6 樣本特征分布
3.3 P-SOM的船舶輔鍋爐燃燒故障診斷
將80個輔鍋爐樣本構(gòu)成未被分類的樣本集合,按上述歸一化和降維后作為SOM神經(jīng)網(wǎng)絡(luò)的輸入進(jìn)行仿真計算,分別使用SOM和P-SOM進(jìn)行分析。首先設(shè)計SOM神經(jīng)網(wǎng)絡(luò),即輸入層的神經(jīng)元為3,隱含層采用二維2×3結(jié)構(gòu),即隱含層神經(jīng)元有6個,輸出層神經(jīng)元個數(shù)為5,即要區(qū)分的類別數(shù)目,神經(jīng)網(wǎng)絡(luò)拓?fù)浜瘮?shù)默認(rèn)為“hextop”,分類階段學(xué)習(xí)速率默認(rèn)為0.9,分類階段學(xué)習(xí)步長為1 000,學(xué)習(xí)速率為0.02。經(jīng)多次測試,當(dāng)神經(jīng)網(wǎng)絡(luò)迭代次數(shù)達(dá)到500次時,樣本劃分結(jié)果較好。每個神經(jīng)元獲勝次數(shù),即含有的樣本數(shù)如圖7所示。6個隱含層神經(jīng)元均有勝出,每組獲勝神經(jīng)元序號如表3所示。結(jié)果表明,第4組獲勝神經(jīng)元與第1組和第5組重復(fù),說明其數(shù)據(jù)特征類似,導(dǎo)致神經(jīng)網(wǎng)絡(luò)分類不精確。綜上,SOM網(wǎng)絡(luò)可以將1、2、3、5組數(shù)據(jù)明顯區(qū)分,但對第4組數(shù)據(jù)分類時獲勝神經(jīng)元重復(fù),導(dǎo)致分類混亂。
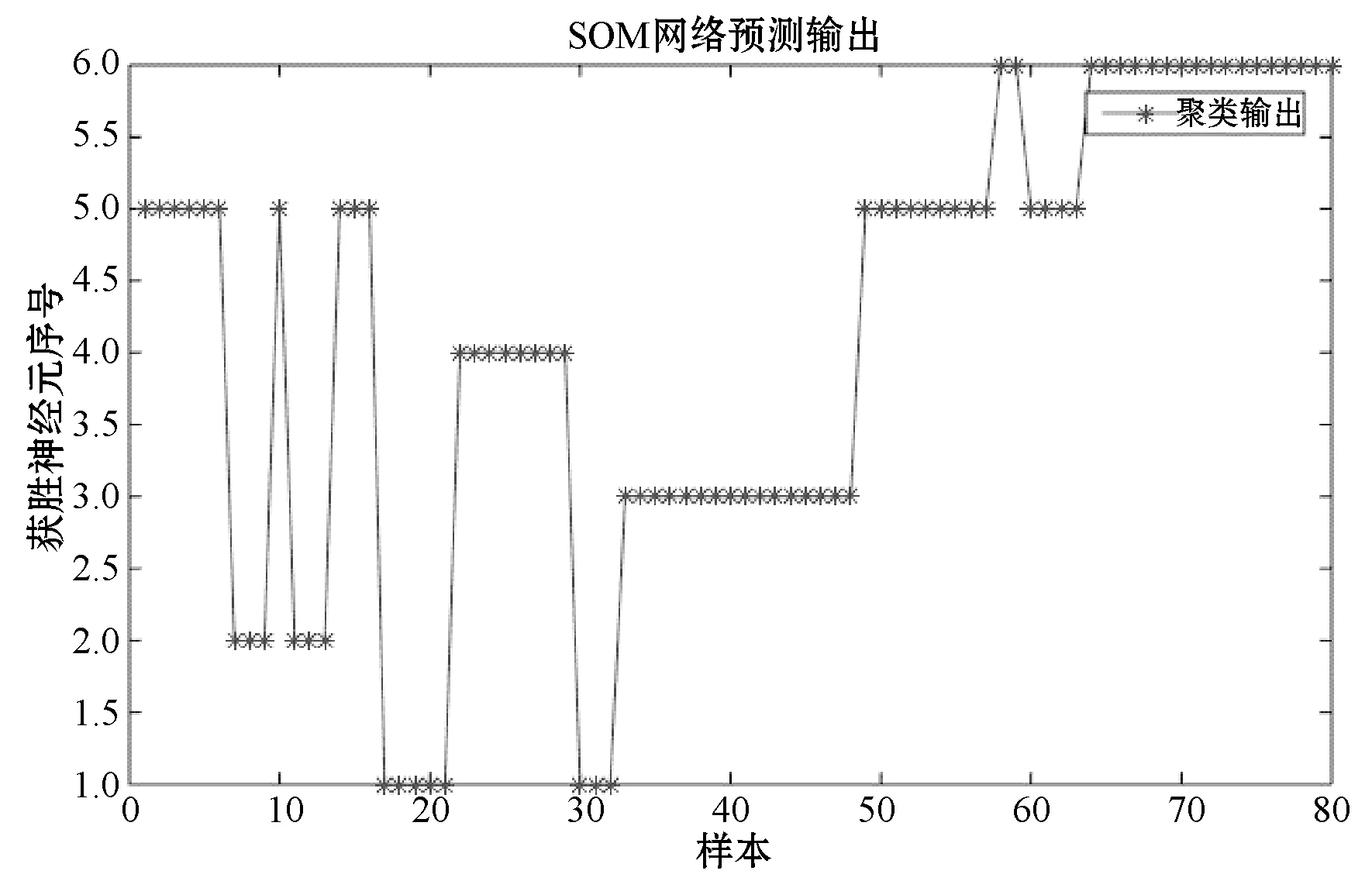
圖7 SOM網(wǎng)絡(luò)聚類結(jié)果

表3 優(yōu)勝節(jié)點(diǎn)序號
采用P-SOM方法對樣本數(shù)據(jù)聚類。PSO算法參數(shù)設(shè)置原則如下:ω初始值為1;種群迭代次數(shù)為200,每代SOM網(wǎng)絡(luò)的迭代次數(shù)設(shè)置為200次,種群規(guī)模為4,加速因子c1為1.5,c2為2.5。計算后5組樣本數(shù)據(jù)的分類結(jié)果如圖8所示,神經(jīng)元獲勝結(jié)果如圖9所示。可見,P-SOM算法使每組樣本數(shù)據(jù)都產(chǎn)生了明顯區(qū)分,第4組數(shù)據(jù)被有效識別,單獨(dú)區(qū)分出來,只存在一個樣本數(shù)據(jù)被錯誤分到第5組,其他神經(jīng)元沒有重復(fù)獲勝,準(zhǔn)確率可以達(dá)到98.75%。與SOM對比,P-SOM較好地解決了SOM網(wǎng)絡(luò)在激活神經(jīng)元的選擇上依賴初始權(quán)值而導(dǎo)致的一部分?jǐn)?shù)據(jù)特征相似的樣本激活相同神經(jīng)使故障診斷分析精確度下降等問題。
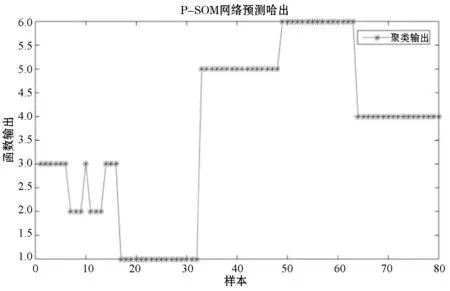
圖8 P-SOM網(wǎng)絡(luò)的聚類結(jié)果

圖9 SOM網(wǎng)絡(luò)優(yōu)勝節(jié)點(diǎn)個數(shù)
綜上所述,經(jīng)過PSO優(yōu)化的SOM 算法的輸出誤差遠(yuǎn)小于未被優(yōu)化SOM的輸出誤差,即本文提出的P-SOM算法在模式識別過程中具有更高的聚類精度和更快的收斂速度。
4 結(jié) 語
本文提出一種基于PSO優(yōu)化SOM神經(jīng)網(wǎng)絡(luò)的無導(dǎo)師式學(xué)習(xí)方法,闡述了SOM神經(jīng)網(wǎng)絡(luò)及PSO算法的結(jié)構(gòu)及特點(diǎn),并利用大連海事大學(xué)研發(fā)的大型油船輪機(jī)模擬器DMSVLCC提取船舶輔鍋爐的數(shù)據(jù)樣本進(jìn)行分析處理,詳細(xì)闡述了P-SOM算法流程及使用方法。P-SOM借助粒子群算法全局迭代尋優(yōu)的特性,學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)權(quán)重,改變了SOM原有的Kohonen學(xué)習(xí)規(guī)則,克服了神經(jīng)網(wǎng)絡(luò)依賴初始化權(quán)值導(dǎo)致類簇?zé)o法有效區(qū)分的問題,從而有效地識別出船舶輔鍋爐的故障類型。通過與單一的SOM神經(jīng)網(wǎng)絡(luò)分類進(jìn)行實(shí)驗(yàn)對比,結(jié)果表明:本文方法分類準(zhǔn)確度較高,合理可靠,為船舶輔鍋爐燃燒故障診斷提供了一種新的思路,擴(kuò)充了船舶輔鍋爐燃燒故障診斷的內(nèi)涵與功能。
猜你喜歡
艦船科學(xué)技術(shù)(2022年14期)2022-09-22 03:07:40
艦船科學(xué)技術(shù)(2022年2期)2022-03-29 01:12:44
小哥白尼(趣味科學(xué))(2019年10期)2020-01-18 09:16:22
汽車維修與保養(yǎng)(2019年7期)2020-01-06 03:30:42
船舶標(biāo)準(zhǔn)化工程師(2019年4期)2019-07-24 07:21:12
中國船檢(2017年3期)2017-05-18 11:33:09
汽車維護(hù)與修理(2016年10期)2016-07-10 08:17:41
汽車維修與保養(yǎng)(2015年12期)2015-04-18 07:51:49
汽車維修與保養(yǎng)(2015年6期)2015-04-17 03:31:50
汽車維修與保養(yǎng)(2015年2期)2015-04-17 01:30:34
