基于時空雙流融合網絡與Attention模型的行為識別
2020-09-02 01:22:36馬翠紅毛志強
計算機應用與軟件 2020年8期
王 毅 馬翠紅 毛志強
(華北理工大學電氣工程學院 河北 唐山 063210)
0 引 言
人體行為識別是基于收集的視頻序列來分析人體的運動,并廣泛應用于智能視頻監控、健身評估、人機交互、虛擬現實等領域,成為人工智能領域研究的熱點問題[1-2]。
傳統的人體行為識別主要是基于手工特征的方法,然而傳統方法進行特征提取的步驟繁瑣且難以提取到深層特征,使得行為識別準確率難以提升。近年來,隨著深度學習被廣泛應用于圖片分類、人臉識別和目標檢測等識別領域,其在人體行為特征提取上也表現出了很好的效果。2014年,Karpathy等[3]首次利用深度卷積網絡以連續的RGB視頻幀為輸入,實現人體行為識別,但并沒有很好地利用時間域特征;Simonyan等[4]利用雙流卷積網絡分別提取視頻序列中的時間和空間特征,識別精度雖然有了明顯提升,但由于該網絡結構使用的是傳統Softmax和SVM進行人體識別,其識別準確率并不高。
在文獻[4]的基礎上,本文對其網絡結構進行改進,在雙流卷積網絡基礎上構建雙向長短時記憶網絡(Bi-LSTM)提取時序特征;輸入Attention層自適應地對相關的特征向量分配較大的權重,利用Softmax分類器對視頻進行分類,從而實現人體行為識別。
1 模型架構
卷積神經網絡(CNN)主要用于單一靜態圖片特征的提取,很難提取視頻的時間信息。文獻[4]提出了雙流卷積識別網絡,與以往的視頻中人體行為識別方法相比,有效地利用了視頻中的時間信息,但仍存在一些問題:雙流結構提取的時空特征僅在最后的Softmax層進行融合,沒有考慮到時空特征在卷積層和全連接層之間的關聯性;該模型采用的是傳統的Softmax-loss函數[7],對類內距離小、類間距離大的相似行為識別效果并不好。
本文提出的基于時空雙流融合網絡與Attention模型的架構如圖1所示。該網絡模型主要以時空雙流融合網絡、Bi-LSTM層、Attention機制、Softmax來實現行為分類識別。

圖1 總體架構設計
1.1 時空雙流融合網絡
為了更好地提取利用視頻中的時空信息,加強時空特征之間的相關性,提出了一種時空雙流融合網絡結構,具體參數設置如圖2所示。本文選擇的雙流卷積網絡模型是VGG-M-2048模型。

圖2 雙流融合卷積網絡結構
空間流卷積神經網絡本質上是一個圖片分類網絡結構,以單個多尺度RGB視頻幀作為輸入,提取圖片中人類動作的表觀運動特征。時間流卷積神經網絡以連續的光流圖作為輸入,提取光流圖中的人體運動的時間信息。本文采用OpenCV中的稠密光流幀提取方法[5],分別提取視頻中水平和垂直方向的光流幀,將20幅光流圖構成一個光流組(flow_x,flow_y)作為時間流卷積神經網絡的輸入。
時空雙流融合網絡是利用空間流網絡來提取表觀運動信息,利用時間流網絡來提取長時運動信息,利用其特征的相關性來識別人體的行為。在時空雙流融合網絡內部,采用一種時間流到空間流的單向連接,將時間流提取到的運動特征輸入到空間流,將其與表觀信息相關聯以提取更深層次的人體行為特征。
將雙流網絡結構提取的時空特征嘗試在不同的網絡層進行融合,找到表征能力最強的層數,然后作為Bi-LSTM層的輸入。雖然在雙流卷積網絡內部各層進行了單向連接,各層也進行了關聯性學習,但是由于運動特征是重要的人體行為信息,仍會將時間流的全連接層輸出與空間流的輸出特征進行融合,視頻序列中的運動特征會作為網絡模型的主導特征進行人體行為識別。
1.2 Bi-LSTM
Bi-LSTM由一個前向傳播和一個后向傳播的LSTM組成。LSTM的內部結構如圖3所示。
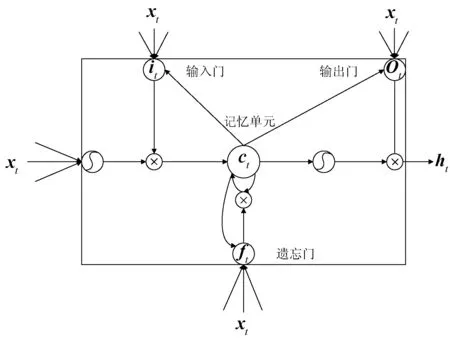
圖3 LSTM內部結構
LSTM的核心部分就是記憶單元ct,其作用是選擇有用的信息,去除多余的信息。同時LSTM通過其特殊的門結構來控制信息與記憶單元之間的傳播能力[6],LSTM門的結構是一個Sigmoid函數,這里用σ(x)=(1+e-x)-1表示,Sigmoid函數的輸出在(0,1)范圍內,反映了信息保存情況。具體如下:
it=σ(Wxixt+Whiht-1+bi)
(1)
ft=σ(Wxfxt+Whfht-1+bf)
(2)
Ot=σ(Wxoxt+Whoht-1+bo)
(3)
gt=tanh(Wxcxt+Whcht-1+bc)
(4)
ct=ft×ct-1+it×gt
(5)
ht=Ot×tanh(ct)
(6)
式中:xt代表當前記憶單元的輸入;ht-1表示上一時刻細胞的輸出;it決定存留的信息;ft決定刪除的信息;Ot確定記憶單元ct的輸出;gt為候選值向量。如式(6)所示,LSTM的輸出ht是由輸出門Ot控制是否激活記憶單元ct。
傳統的LSTM僅能單向學習而忽略了視頻前后的關聯信息。Bi-LSTM中,當前時刻的輸入同時依賴于前后的視頻幀,充分考慮了視頻幀的時序信息,其模型結構如圖4所示。
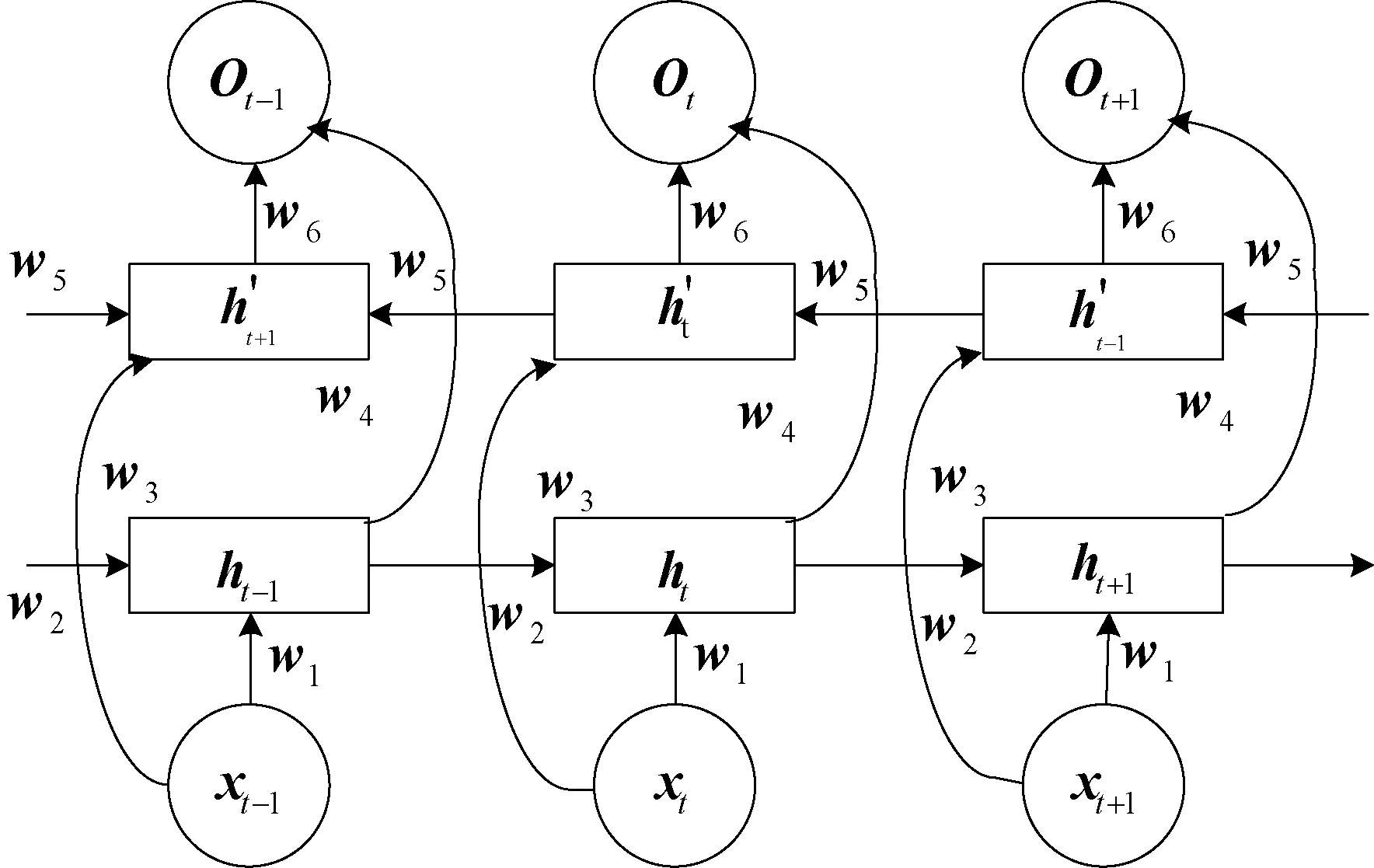
圖4 Bi-LSTM網絡模型
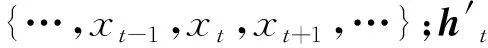
h1=f(w1x1+w2ht+1+b1)
(7)
(8)
(9)
(10)
(11)
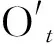
1.3 Attention層
Attention機制是根據人類視覺特性研究的一種類似大腦的信息處理機制,它能夠根據不同時刻Bi-LSTM網絡的輸出為視頻幀序列動態分配不同的權重,突出某些幀的重要性,提高識別性能。模型加入Attention機制有利于區分視頻的重要信息和無關信息,例如常見的籃球運動中與彈跳、投籃、籃球有關的視頻幀能提供更多信息,Attention機制會分配更大的權重,有利于特征提取,提高識別準確率。Attention機制模型如圖5所示。
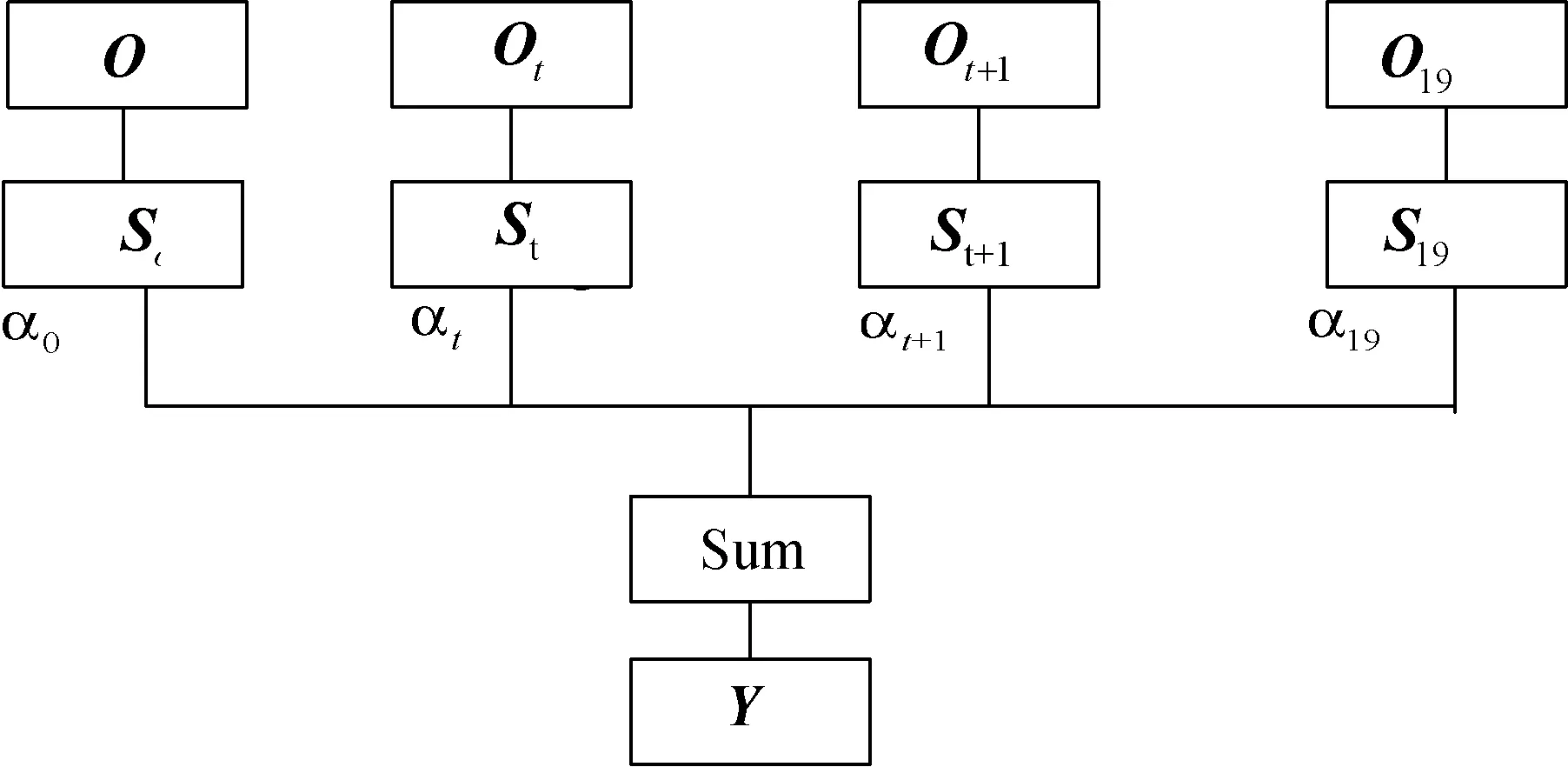
圖5 注意力機制模型
圖5中:Ot為Bi-LSTM網絡輸出的第t個特征向量;經過Atention中的隱層后得到初始向量St;αt為權重系數。計算公式如下:
et=tanh(wtst+bt)
(12)
(13)
(14)
式中:wt和bt分別為權重和偏置。通過式(13)可以得到權重系數,達到初始狀態向注意力狀態轉換的目的,通過式(14)得到輸出狀態向量Y,最后全連接層整合作為輸出值,減少特征位置對分類造成的干擾,經Softmax分類器將輸出映射到(0,1)內。
2 實 驗
2.1 實驗設置
實驗選擇Python語言在GPU下用深度學習框架TensorFlow進行實驗,電腦配置為Ubuntu 16.04、32 GB運行內存、GTX 1080TI(11 GB)顯存。具體參數設置如表1所示。
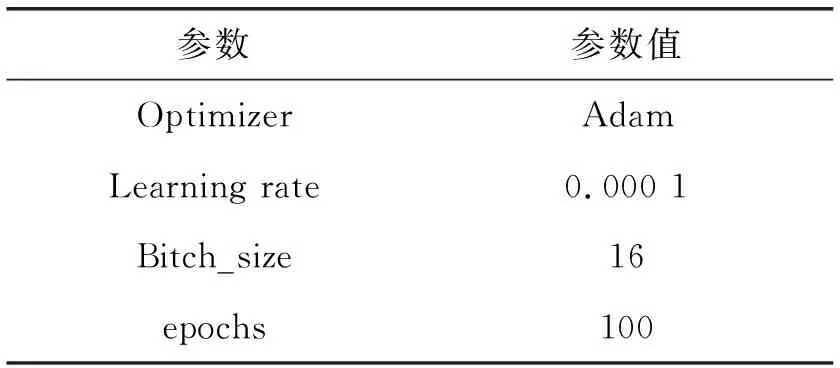
表1 實驗參數
實驗數據集采用KTH數據集,其包含4個不同場景下25個人的6類動作視頻:走(Walk)、慢跑(Jog)、跑(Run)、打拳(Box)、揮手(Wave)和拍手(Clap),如圖6所示。

圖6 KTH樣本數據集
2.2 實驗結果與分析
為了保證實驗的準確性,將KTH數據集隨機分為3組,每次選取80%作為訓練集,20%作為測試集。最后取3組測試的平均準確率作為評估指標。
通過時空雙流融合網絡提取時空特征,在模型內部時間網絡到空間網絡的采用單向連接方式,進行長時運動與表觀特征的關聯性學習。實驗中,分別在雙流結構全連接層的不同位置進行時空特征融合,識別精度如表2所示。

表2 不同全連接層輸出特征識別準確率的比較
可以看出,隨著時空特征融合層數的加深,其識別精度不斷提高,尤其在空間流的fc6層與時間流的fc7層進行融合時,識別效果最好,說明更深層次的語義信息,對行為的表征能力更強,而且當視頻序列中的運動特征主導模型訓練時,有利于識別準確率的提升。
采用LSTM、Bi-LSTM、Bi-LSTM-Attention三種方法,結合時空雙流融合網絡在KTH數據集上進行測試。選取100個視頻樣本作為測試集,其余作為訓練集,作為第一次交叉驗證記作Dataset1,共進行3次,取平均值作為結果,如表3所示。
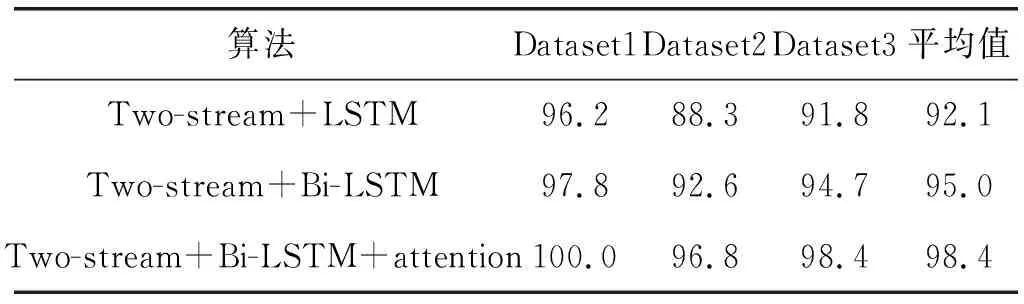
表3 KTH數據集交叉驗證精度比較 %
可以看出,本文算法在KTH數據集上識別率達98.4%。
為了便于觀察識別準確率,制作了各種行為的混淆矩陣,如表4所示。

表4 各種行為的混淆矩陣
可以看出,本文算法識別率較高,對于Jog、Walk、Run相似度較高的行為,誤識別率只為0.01~0.05,因此,本文算法具備很好的識別效果。
將本文方法與當前精度較高的行為識別算法在KTH數據集上測試進行比較,結果如表5所示。

表5 不同算法在KTH上的比較結果
可以看出,本文提出的基于時空雙流融合網絡與Attention算法優于其他算法,在KTH數據集上有良好的表現,降低了內存占有率,并且算法精度損失小于其他算法,行為識別準確率明顯提高。
3 結 語
本文從人體行為類內與類間的差異的角度出發,提出了基于時空雙流融合網絡與Attention模型的行為識別方法。通過時空雙流卷積網絡分別提取視頻幀中的表觀短時特征和長時運動流特征,且在卷積層內部采用時空單向連接將時空特征進行關聯性學習;構建Bi-LSTM層學習時序信息;再通過Attention機制自適應分配權重,最后利用Softmax實現分類。在KTH數據集上的測試結果表明,本文方法提高了識別精度,可以有效解決LSTM無法提取視頻幀時序信息的缺點,能夠最大化類間距離、最小化類內距離,有利于人體行為分類。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
