模型關系有向圖輔助下的KL-VSIMM目標跟蹤算法
2020-09-02 01:34:58崔麗珍李丹陽王巧利赫佳星史明泉
計算機應用與軟件 2020年8期
關鍵詞:模型
崔麗珍 李丹陽 王巧利 赫佳星 史明泉
(內蒙古科技大學信息工程學院 內蒙古 包頭 014010)
0 引 言
隨著卡爾曼濾波在目標跟蹤算法領域的廣泛應用,基于動態系統模型的狀態估計算法成為目標跟蹤的主要算法之一[1]。在實際的跟蹤過程中,目標的運動狀態模式隨機變化,采用單個模型不能達到很好的跟蹤效果,因此采用多個模型對目標的真實運動模式進行逼近,在同一時刻各模型分別進行濾波估計,最后融合估計數據形成多模型估計算法。多模型估計算法中,IMM算法[2]融入了模型信息交互的思想,是目前應用較為廣泛的跟蹤算法,然而因其實際采用的模型集合為目標真實模式集合的取樣,為提高跟蹤精度,往往加入更多的模型,這導致了更多的模型競爭和計算量增加。為降低模型集固定對跟蹤性能造成的影響,VSIMM算法假設模型集隨著外界條件和實時信息的變化而變化,以該算法為基礎的模型集自適應估計算法得到了廣泛的研究[3]。可能模型集(Likely-Model Set,LMS)算法[4]基于模型的預測概率,通過分設高低兩個閾值對模型好壞進行區分,刪除不可能模型,保留一般模型,激活可能模型以達到模型集的自適應。文獻[5]提出了一種基于多速率模型的變結構多模型方法,同時改善原始量測數據和自適應調整模型集。文獻[6]考慮到目標的類型和環境因素,并利用相關知識對模型集進行了自適應的調整。文獻[7]利用KL(Kullback-Leiber)信息評定模型優劣,去除最差的模型后再利用期望模型擴展算法增加一個新的模型,在此且稱之為KL-EMA算法。
本文利用加速度向量描述目標模式和系統模型,并借助模型間的有向關系圖簡化加速度空間,明確模型轉換關系,在此基礎上利用KL信息制定模型集自適應規則,剔除匹配程度最低的模型,同時計算出與目標運動模式相似度較高的模型,激活其在加速度空間上的鄰近模型以實現模型集的自適應切換。
1 問題描述
1.1 系統模型
實際情況中,目標的運動模式具有隨機性,無法直接獲得目標的真實模式,跟蹤系統無法精準預判其模式變化。多模型估計算法以一個運動模型描述一種目標運動模式,以一個模型集合逼近目標整個模式空間,而且每個模型都可能與未知的目標模式匹配,各個模型通過濾波器進行狀態估計,最終結果由各個模型的狀態估計融合完成。目標動態模型描述了相鄰兩個時刻目標的狀態變化規律,觀測模型則表示了觀測信息與目標狀態之間的關系。多模型估計的系統模型[8]可描述為:
(1)
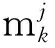
1.2 模型關系有向圖設計
對于多模型跟蹤算法,基礎模型集的設計決定了算法的跟蹤性能。本文將利用加速度向量描述目標的運動模式,這些加速度向量組成的集合構成加速度空間并用來模擬目標模式空間。從中取樣n個加速度向量作為固定加速度,輸入到運動模型組成基礎模型集,最后由加速度向量間的關系確定基礎模型集的模型關系有向圖[4]。
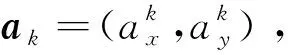
ac={(ax,ay):|ax|+|ay|≤r}
(2)
基于以加速度向量表示的目標模式空間ac,從中采樣n個加速度向量,將這n個向量作為固定加速度分別代入式(1),得到n個時不變的加速度模型,組成模型集M。
假設目標最大加速度為r=0.8 m/s2來保證對目標實際模式集合的有效覆蓋,從加速度空間等距離采樣n=13個加速度向量,用來構成基礎模型集M={m1,m2,…,m13}。不同的模型區別于固定輸入的加速度向量。
m1:[0,0]T,m2:[0.4,0]T,m3:[0,0.4]T
m4:[-0.4,0]T,m5:[0,-0.4]T,m6:[0.4,0.4]T
m7:[-0.4,0.4]T,m8:[-0.4,-0.4]T
m9:[0.4,-0.4]T,m10:[0.8,0]T,m11:[0,0.8]T
m12:[-0.8,0]T,m13:[0,-0.8]T
(3)
將這些加速度向量以坐標的形式簡化成有向圖,如圖1所示。

圖1 模型集M模型關系有向圖
圖中的每個點代表一個模型,且任意兩個點之間的距離與它們代表的兩個模型間的加速度距離成正比;箭頭指向表示當前模型匹配的系統模式在下一時刻有可能轉向的模式,且每個模型都有很大概率不切向其他模型,而繼續保持本模型匹配目標當前加速度。由于目標狀態變化的連續性,假設在一個采樣間隔內,模型僅可能切向臨近模型和自己,轉向其余模型的概率為零。本文將根據加速度模型空間結合實驗情景設計基本模型集,并根據圖1所示的模型關系有向圖輔助設計模型集自適應策略。
2 KL算法
為實現模型集的自適應,根據實時信息對模型集進行縮減和擴展,以更好地描述目標模式,需要通過一個共有的參量來比較模型與目標實際模式的差異,即使模型與模式可能在結構和參數上均不相同。KL準則為測量模型與模式的匹配程度提供了方法,具體實現為[9]:
(4)

(5)
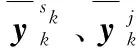
(6)
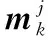
(7)
(8)
式中:
(9)

(10)
(11)
3 算法設計
3.1 VSIMM算法

1) 交互輸入。
各模型的預測概率:
(12)
交互的權值:
(13)
信息的交互估計:
(14)
交互方差:
(15)
2) 卡爾曼濾波器濾波估計。
狀態估計:
(16)
狀態方差估計:
(17)
3) 模型概率更新。
各模型似然函數:
(18)

更新后的模型概率:
(19)
4) 結果融合。
總體狀態估計:
(20)
總體估計協方差矩陣:
(21)
3.2 KL-VSIMM算法
實現模型集自適應的原則為:刪除不能較好匹配目標運動模式的模型集;激活能更好反映目標模式的模型集合[8]。好的模型集自適應策略應基于某個度量標準來比較目標模式與待選模型之間的差異,即便這些模型與目標運動模式的參數和結構并不相同[9-11]。本文利用KL準則衡量模型能夠正確描述目標模式的程度。KL準則也叫作相對熵,本文采用量測向量zk作為共有參量,利用相對熵顯示量測值在模型與模式條件下的概率分布差異,亦稱作KL距離,KL值越小,表示模型越接近實際模式。用于模型選擇的自適應基本準則為:根據各模型的KL 值,先刪除KL值最大的模型,然后以ε為界限,找到KL值小于ε的模型,根據圖1,找到與這些模型由雙向箭頭連接的模型并激活,剩下的模型繼續參與下一步狀態估計[4]。算法具體步驟如下:
定義:
M:基本模型集合。
Mk:k時刻用于估計的模型集合。
Mo:KL值小于ε的模型組成的結合。
Ma:Mo中各模型的鄰居模型組成的集合。
Mn:用于激活的模型組成的集合。
mt:被剔除的模型。
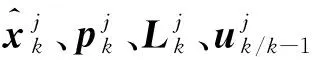
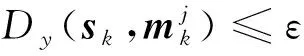
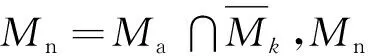
(22)
(23)
(24)
同時更新Mk=Mn∪Mk。
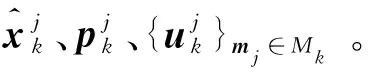
Step5判斷算法是否達到預定跟蹤時間,若達到則結束跟蹤;否則執行Step 6。
Step6將模型mt從Mk中刪除,得到新的模型集Mk+1=Mk-mt。最后跳到Step1。
算法流程如圖2所示。
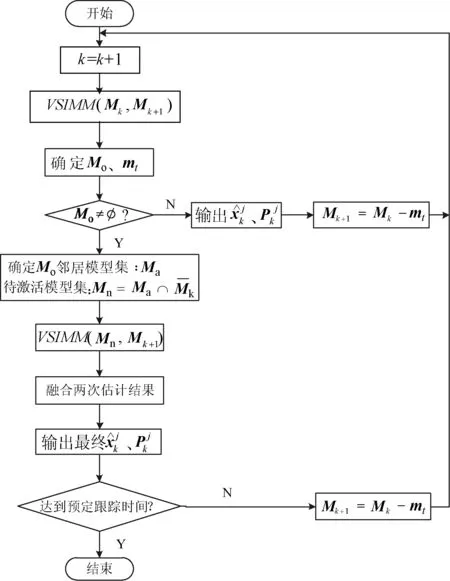
圖2 KL-VSIMM算法流程圖
4 仿真實驗與分析
4.1 實驗設計
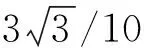
根據目標運動場景,采用式(3)中的13個加速度向量作為固定加速度輸入的二維運動CV模型。設采樣時間T=1 s,觀測噪聲方差R=400Im2,系統噪聲方差Q=0.001Im2/s4。
式中各參數為:

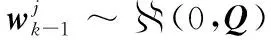
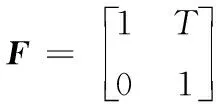
基本的狀態轉移概率矩陣A13×13依照模型拓撲圖中模型之間的轉移關系,采用文獻[3]提供的方法設計。在運行VSIMM(Mk,Mk-1)時,由于模型集的自適應調整,Mk與Mk-1模型個數不一定相同,設它們的模型總數分別為n1、n2。從A13×13中提取對應的轉移概率就組成了新的轉移概率矩陣Ak=(ωij)n2×n1,其中ωij為A13×13中元素,i對應Mk-1中模型序號,j為Mk中模型序號(按基本模型集中模型序號排列)。最后將Ak=(ωij)n2×n1各行元素歸一化,得到最終矩陣Ak=(aij)n2×n1。
模式估計均方根誤差[3]實際上是模型中假設的加速度與加速度之和的均方根誤差,定義為:
(25)
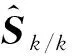
(26)
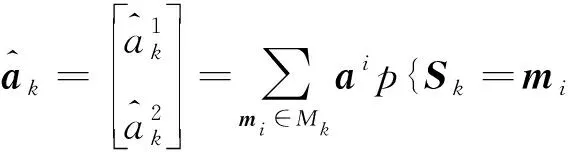
(27)
式中:ai為模型mi中設定的加速度向量。
4.2 仿真結果分析
分別使用IMM(13)算法、LMS算法、KL-EMA算法、KL-VSIMM算法對13個模型各運行50次Monte-carlo仿真實驗,進行了狀態估計質量和模式識別方面的對比。經多次實驗分析后,取KL-VSIMM算法中ε為0.01。圖3為跟蹤軌跡;圖4和圖5分別為4種算法在位置和速度上的均方根誤差對比圖;圖6為模型匹配真實模式的平均概率對比圖;圖7為模式估計均方根誤差對比圖,計算方法見式(26)。表1給出了關于4種算法的位置和速度的平均誤差、最大誤差(忽略不計初始時刻由初始狀態造成的誤差)以及參與估計的平均模型個數的數據。
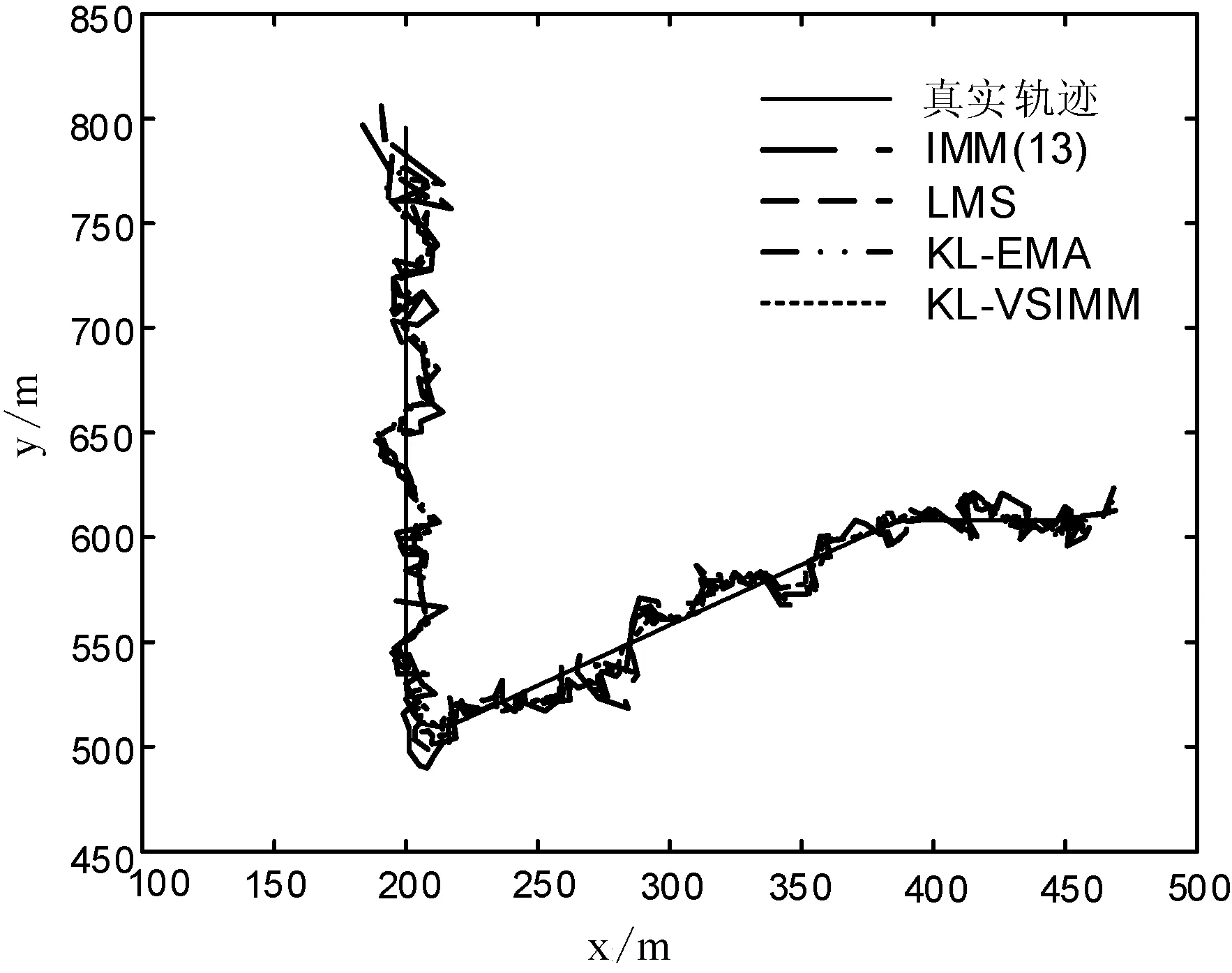
圖3 跟蹤軌跡圖

圖4 位置估計均方誤差對比圖

圖5 速度估計均方誤差對比圖
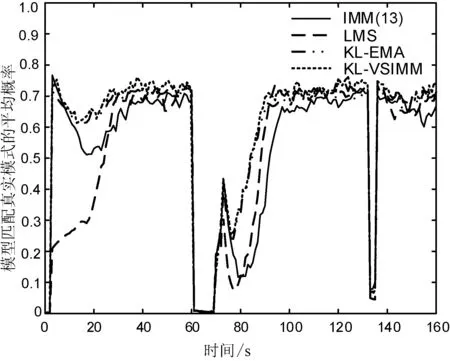
圖6 模型匹配真實模式的平均概率

圖7 模式估計均方根誤差對比圖
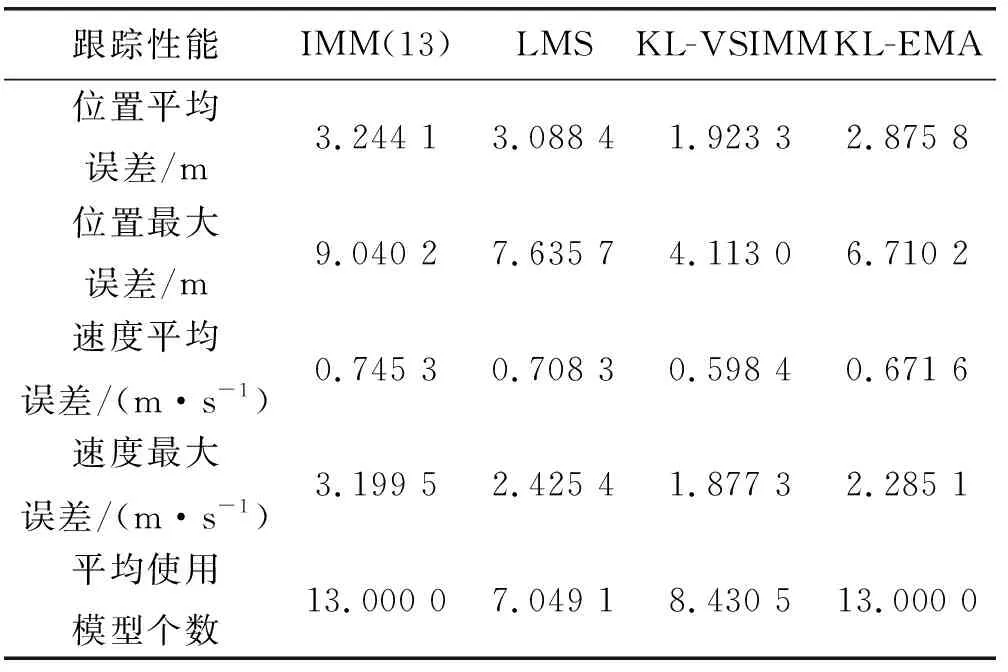
表1 4種算法跟蹤性能數據比較
由圖3可知,總體上4種算法都達到了跟蹤的目的,但是從IMM(13)、LMS、KL-EMA、KL-VSIMM分別對應的跟蹤軌跡曲線可以發現4條曲線依次逐步逼近真實軌跡。由圖4和圖5可知,在目標加速度發生改變的3個時刻附近,位置和速度的均方根誤差曲線都發生了較大的波動,并且出現了3個誤差的峰值。LMS算法與IMM(13)算法的位置與速度均方根誤差曲線基本一致,精度幾乎沒有提高,KL-EMA算法和KL-VSIMM算法相對于IMM(13)算法在精度上均有所提高,并且KL-VSIMM算法的誤差峰值小于KL-EMA算法,精度更好,表明本文算法的狀態估計質量較好。圖6和圖7則反映了算法的模式識別能力,與IMM(13)算法相比,在模式的識別能力上,KL-VSIMM算法最好,KL-EMA算法次之,LMS算法較弱。由表1可得,在模型集自適應過程中, KL-VSIMM算法在4種算法中估計性能最優,誤差最小,LMS算法雖然比KL-VSIMM算法使用了較少的模型個數,但跟蹤精度并沒有顯著提高,而KL-EMA算法雖然提高了精度但模型選擇策略相對本文算法較復雜,參與估計的模型數量沒有變化,模型集的自適應程度還有待提高。
5 結 語
本文算法結構簡明,可執行性好,既提高了目標的狀態估計精度,又減少了參與估計的模型個數,降低了模型間競爭。同時保留了交互多模算法的穩健性,很好地實現了模型集的自適應,與自適應策略較為接近的LMS算法和KL-EMA算法相比,跟蹤效果更佳。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
