訊飛語音輸入法方言識別在新冠疫情防控中的應(yīng)用評估*
2020-09-04 02:09:36汪高武李晨光楊豆豆
語言戰(zhàn)略研究 2020年5期
關(guān)鍵詞:智能
汪高武,龐 博,李晨光,楊豆豆
(北京師范大學(xué) 文學(xué)院 北京 100875)
提 要 在各種社會重大突發(fā)事件的應(yīng)急處理中,智能語音技術(shù)能起到彌補(bǔ)人力資源嚴(yán)重不足、緊急處理海量信息、有效應(yīng)對風(fēng)險、降低損失的作用,具有獨(dú)特的優(yōu)勢。在2020年新冠肺炎疫情中,全國各地支援湖北,不同方言人群之間的溝通也成為一個問題,這對語音識別技術(shù)提出了要求和挑戰(zhàn)。本文以科大訊飛智能語音輸入法為例,根據(jù)全國多種方言(139個方言點(diǎn),共283位發(fā)音人)在疫情防控模擬場景下的語音識別材料,對其成效進(jìn)行了評估和分析,并探討了智能語音技術(shù)的應(yīng)用和發(fā)展。
一、引 言
智能語音技術(shù)是人機(jī)交互中最為重要的一種,計算機(jī)通過語音的交互方式理解、輔助人類(陳鵬2017;王海坤,等2018)。智能語音技術(shù)具有永不疲倦、降低人力成本、智能可擴(kuò)展等特點(diǎn),已廣泛應(yīng)用在各種領(lǐng)域,包括醫(yī)療健康(張海波,等2017)、出版?zhèn)髅剑ê簦?016;朱晶晶2016)、教育教學(xué)(張筱蘭,王保論2011)、公安警務(wù)(肖益茂,等2018)、呼叫中心(李楓,徐韜2016)、客服質(zhì)檢(林可希2013)等等。其中語音轉(zhuǎn)為文字的技術(shù),幫助人們免于手寫或打字的限制與勞累,為社會做出了很大的貢獻(xiàn)。以科大訊飛智能語音輸入法為例,2019年全國訊飛輸入法用戶語音錄入共計35 560億字,可為用戶節(jié)省8.38億分鐘,接近9.6萬年(中關(guān)村在線2020)。
隨著社會發(fā)展、人口集中、人力成本越來越高,對智能語音技術(shù)的需求也日益增長。特別是在各種社會重大突發(fā)事件中,智能語音技術(shù)能起到彌補(bǔ)人力資源嚴(yán)重不足、緊急處理海量信息、有效應(yīng)對風(fēng)險、降低損失的作用,具有獨(dú)特的優(yōu)勢。重大突發(fā)事件的特點(diǎn)主要有:(1)突破生活常態(tài),意味著新的場景、任務(wù)和交流,以及龐雜的人員聚集重組。人類對某些場景的適應(yīng)性很強(qiáng),但有些情況,例如不同方言和不同語言之間的障礙,卻不是短時間內(nèi)能適應(yīng)解決的。等適應(yīng)了、學(xué)會了,應(yīng)急處理可能又過去了,語言學(xué)習(xí)就顯得不太劃算。(2)重大突發(fā)事件,特別是重大自然災(zāi)害,往往是人員大量受損、人力資源緊張甚至枯竭的時候,為避免諸如醫(yī)療資源被擠兌甚至“擊穿”的風(fēng)險,正需要語音智能去幫助溝通、輔助篩查、緩解人力、安撫情緒,減輕醫(yī)療、救援及工作人員的負(fù)擔(dān)。例如本次疫情中,有智能語音呼梯系統(tǒng)幫助避免電梯按鍵接觸式感染、人工智能輔助醫(yī)療協(xié)助基層醫(yī)生進(jìn)行疫情篩查防控和防疫知識宣教、智能醫(yī)療助理為一線提供最迫切需求的醫(yī)療服務(wù)和國家基層醫(yī)療培訓(xùn)等各種應(yīng)用(任曉寧2020)。
在本次疫情中,全國各地支援湖北,方言溝通成為一個問題。為幫助外地援鄂醫(yī)療隊(duì)解決醫(yī)患溝通的方言障礙問題,教育部語言文字信息管理司指導(dǎo)組成了“戰(zhàn)疫語言服務(wù)團(tuán)”,迅速研制了涵蓋湖北九大方言片區(qū)的《抗擊疫情湖北方言通》,為抗擊疫情的醫(yī)護(hù)人員及相關(guān)群體提供多維度語言服務(wù)(李宇明2020)。可以預(yù)期,將來智能語音技術(shù)會在防疫等重大緊急事件中起到相當(dāng)?shù)淖饔谩榇耍覀円残枰獙χ悄苷Z音技術(shù)在這些實(shí)際應(yīng)用場景下的性能進(jìn)行第三方獨(dú)立的、非商業(yè)的、科學(xué)的評估,為將來國家制定行業(yè)標(biāo)準(zhǔn)、政府采購智能語音技術(shù)產(chǎn)品提供科學(xué)依據(jù)和參考,以更好地為社會民生服務(wù)。
由于歐美國家醫(yī)療健康產(chǎn)業(yè)更為發(fā)達(dá),人力成本也更昂貴,所以對人工智能技術(shù)在健康衛(wèi)生行業(yè)的應(yīng)用和評估也比較多(Johnson et al. 2014),但國內(nèi)對智能語音識別技術(shù)的測試評估比較少(蔣平,吳振國2003)。因此本研究將以語音輸入法對疫情防控場景相關(guān)語料的識別為例,討論智能語音技術(shù)的應(yīng)用情況和表現(xiàn)。智能語音目前有很多家的技術(shù)和產(chǎn)品,選擇以訊飛輸入法為例是因?yàn)椋菏紫龋嶏w輸入法識別語言種類最多,提供了全國23種漢語方言的識別(其硬件產(chǎn)品“訊飛翻譯機(jī)”可提供59種語言翻譯)。其次,訊飛技術(shù)相對較成熟。有醫(yī)療團(tuán)隊(duì)在對兒童發(fā)音評估的研究中,對比了兩種語音識別軟件,發(fā)現(xiàn)其識別率更優(yōu),性能更穩(wěn)定(韓源,等2017)。最后,訊飛輸入法應(yīng)用最為廣泛。在移動互聯(lián)領(lǐng)域,訊飛輸入法用戶達(dá)4億,活躍用戶數(shù)1.1億(中國網(wǎng)2016)。同時,科大訊飛被國家科技部列入新一代人工智能開放創(chuàng)新平臺名單,為同行業(yè)唯一(科技部2017)。
二、研究方法
(一)語料設(shè)計
要評估智能語音技術(shù)的應(yīng)用狀況,最佳方案是在防疫工作醫(yī)療實(shí)際場景中進(jìn)行調(diào)查。但為了避免影響防疫工作、增加醫(yī)療人員或患者的負(fù)擔(dān),以及避免調(diào)查志愿者感染風(fēng)險,我們采取部分模擬真實(shí)場景的一種體驗(yàn)方式,讓發(fā)音人(被試)用方言念相關(guān)的語料。語料應(yīng)該涵蓋可能癥狀的描述(例如咳嗽、發(fā)燒、呼吸困難)和相關(guān)的醫(yī)療用語(例如打針、口罩)等。在教育部語言文字信息管理司指導(dǎo)下成立的“戰(zhàn)疫語言服務(wù)團(tuán)”,根據(jù)語料庫統(tǒng)計和醫(yī)用場景調(diào)研,遴選了156個詞和76個短句(北京日報客戶端2020),應(yīng)用廣泛,較為典型。但根據(jù)我們預(yù)調(diào)查的反饋,其篇幅對于本次的調(diào)查任務(wù)來說還是比較重。經(jīng)過多次反饋和調(diào)整,盡量用較少的文本包含更多的信息,本次調(diào)查研究從中選取了21個跟疫情最為相關(guān)的詞匯(包括癥狀、醫(yī)療、程度副詞、否定副詞),以及20個短句,并對短句加以擴(kuò)充(加入不同的親屬稱謂、醫(yī)療用語等)和調(diào)整,作為本次調(diào)查研究的語料,具體內(nèi)容請見下文和附錄。
(二)發(fā)音人情況
本次調(diào)查研究共有100位志愿者參與,均為學(xué)習(xí)語言學(xué)課程的學(xué)生。調(diào)查對象為志愿者自己與其居家隔離親友,共計283位發(fā)音人。年齡從9歲~84歲,平均年齡35.7歲,標(biāo)準(zhǔn)差17.97歲。其中96位男性,187位女性,女性比男性多主要是因?yàn)榘嗉墝W(xué)生的性別比例女性占多。有鼻炎、鼻塞現(xiàn)象的3例,牙齒缺失的7例,經(jīng)人耳聽辨錄音,對于發(fā)音沒有太大影響。除了極個別情況(例如帶鼻炎的“發(fā)燒”人耳聽辨無問題,但輸入法識別為“放手”),語音識別也沒有太大問題,屬于可接受范圍。
(三)實(shí)驗(yàn)步驟
調(diào)查方法是讓發(fā)音人在自己的手機(jī)上下載并安裝訊飛語音輸入法,根據(jù)自己的方言情況,從訊飛輸入法提供的23種方言中選取跟自己最接近的方言。然后讓發(fā)音人用自己的方言,以對應(yīng)普通話詞句的當(dāng)?shù)乇磉_(dá)方式,對著手機(jī)說話,由志愿者記錄下方言的文本和訊飛輸入法識別出的文本。然后由志愿者標(biāo)記語音識別的錯誤之處,并加以分析,填寫到調(diào)查表中。同時保留錄音,以做后期的校對和分析。調(diào)查表收取后,經(jīng)過研究小組的校對和核查,用Python和Matlab編程進(jìn)行數(shù)據(jù)文件的處理和統(tǒng)計分析。
三、結(jié)果分析
(一)基本情況
本次調(diào)查的發(fā)音人地點(diǎn)有139個,詳細(xì)到城區(qū)或鄉(xiāng)鎮(zhèn)。除青海和臺灣外,全國各省市自治區(qū)均有分布,地址為“鄉(xiāng)/鎮(zhèn)”的57個,“市/區(qū)/縣”的82個,城區(qū)略占優(yōu)勢。訊飛輸入法提供的23種“方言”,是一種籠統(tǒng)的、并非學(xué)術(shù)意義上的說法,大體相當(dāng)于23種“地方話”。本次調(diào)查沒有發(fā)音人選擇天津話、蘇州話和合肥話作為識別方言,另外有些發(fā)音人沒有母語方言只會說普通話,所以最終在圖1中列出了20種“方言”和普通話的人數(shù)分布。
本次研究,是讓發(fā)音人自行從訊飛輸入法提供的23種方言中選取,所以會遇到選擇錯誤的情況。一般人對自己方言的認(rèn)識,往往是以距離、行政歸屬來判斷,對于語言學(xué)里劃分的方言、次方言、片區(qū)等并無太大概念。本次調(diào)查中,有6人選擇了錯誤的方言,占總?cè)藬?shù)的2.1%。例如:104號發(fā)音人是講河南省安陽市內(nèi)黃縣井店鎮(zhèn)的方言,初期選擇了輸入法提供的河南話,實(shí)際上安陽話屬晉語邯新片獲濟(jì)小片,不屬于中原官話,保留了入聲,跟通常所說到的河南話區(qū)別很大,相比較而言更應(yīng)該選取輸入法提供的山西話(太原)來識別。143號發(fā)音人是講江西省贛州市蓉江新區(qū)潭東鄉(xiāng)的方言,根據(jù)行政歸屬選擇了訊飛提供的江西話(南昌)。實(shí)際上,贛州話是一個方言島,市區(qū)是西南官話,周邊都是客家話。這個地點(diǎn)在贛南師范大學(xué)黃金校區(qū)附近,經(jīng)錄音聽辨,有入聲,基本上還是客家話。以上都在訊飛提供的23種方言中有更好的選擇,但還有很多方言,只能相對擇優(yōu),選擇其中一種最為靠近的方言,這會嚴(yán)重影響識別錯誤率,這些將在下文討論。
另外,為了解社會大眾對智能語音技術(shù)特別是語音輸入法的認(rèn)知狀況,本次研究在調(diào)查問卷中設(shè)置了9個相關(guān)的問題,具體情況將另文介紹。總體上看,語音識別技術(shù)還是廣泛進(jìn)入社會生活、被大眾認(rèn)知的,但只有很少一部分人(占比16.4%)使用過方言識別的功能。
(二)識別錯誤分析
1.錯誤率的判斷標(biāo)準(zhǔn)
對于智能語音識別(語音輸入法),最重要的衡量指標(biāo)就是把語音識別成文字的正確率或錯誤率。英語的錯誤率一般用錯詞率,漢語一般用錯字率。通常設(shè)定普通人類錯詞率為5.9%,受過嚴(yán)格訓(xùn)練的專業(yè)速記員錯詞率在3%左右。2018年的Pyramidal-FSMN語音識別模型,錯詞率低至2.97%,將全球語音識別準(zhǔn)確率紀(jì)錄提高到97.03%,超過了受過嚴(yán)格訓(xùn)練的專業(yè)人類速記員(Yang et al. 2018)。但無論算法如何改進(jìn),只要是基于統(tǒng)計模型,識別正確率都只會無限趨近而不會達(dá)到100%。而且這些正確率都是基于特定的數(shù)據(jù)庫,真實(shí)場景的正確率實(shí)際上會降低,這也是語音識別沒有更為普及的原因。當(dāng)然相比于自動駕駛、機(jī)床操作等對安全有極高要求的領(lǐng)域,語音的識別錯誤相對來講更容易被用戶接受,達(dá)到“可信任”水平。
本次主要研究漢語方言,錯誤率的判斷標(biāo)準(zhǔn)說明如下:(1)因?yàn)闈h語基本上是一個漢字對應(yīng)一個音節(jié),所以計算錯誤率的時候可以用字符數(shù)或音節(jié)數(shù)計算均可。但日常使用語言當(dāng)中常常會有英文和數(shù)字,例如這次的語料里就含有英文“CT”和數(shù)字“38”,以及常見的“WC、18、花兒”等,我們這里統(tǒng)一標(biāo)準(zhǔn),都按字符算成兩個字。(2)“的、地、得”之類的混淆不算錯誤。這3個字的發(fā)音一樣,在短句正文中即使輸入法識別錯誤,對正確意思的理解也幾乎沒有影響,就不計入錯誤。(3)標(biāo)點(diǎn)符號。一般的情況(例如逗號、句號等)對正確理解影響極小。除了極個別情況,例如問號和句號弄錯。但在本次調(diào)查的語料中,所有的問句都含有疑問詞,例如“要不要緊?”“治得好不?”“在哪兒?”“哪個醫(yī)院?”等,所以對于普通話以及北方方言一般都能識別為問號。但對于有些方言,其疑問方式未必帶有疑問詞,例如云南曲靖方言,“我外婆的病要不要緊?”對應(yīng)的方言表達(dá)為“我外婆的病可嚴(yán)重?”,就會被輸入法識別為陳述句。所以標(biāo)點(diǎn)符號的識別錯誤會跟正文字符分開單獨(dú)處理。
2.各方言點(diǎn)的識別錯誤率
表1是各方言點(diǎn)的識別錯誤率,包括21個孤立詞和20個短句的錯誤率。從表中可以看出,普通話短句的錯誤率為2.5%,達(dá)到了宣稱的97%正確率水平。孤立詞的錯誤率稍高,這是正常的,因?yàn)槿鄙偕舷挛沫h(huán)境,難以區(qū)分同音詞。選擇普通話識別的,大部分是北京人或新疆、黑龍江、內(nèi)蒙古等地的移民家庭成員(特別是已經(jīng)不說方言而以普通話為母語的年輕人)。東北話的識別錯誤率3.1%也比較低,這是因?yàn)橄鄬τ谄渌窖裕瑬|北方言內(nèi)部一致性更高,差別較小。表1中各方言的排序大致有幾個規(guī)律:
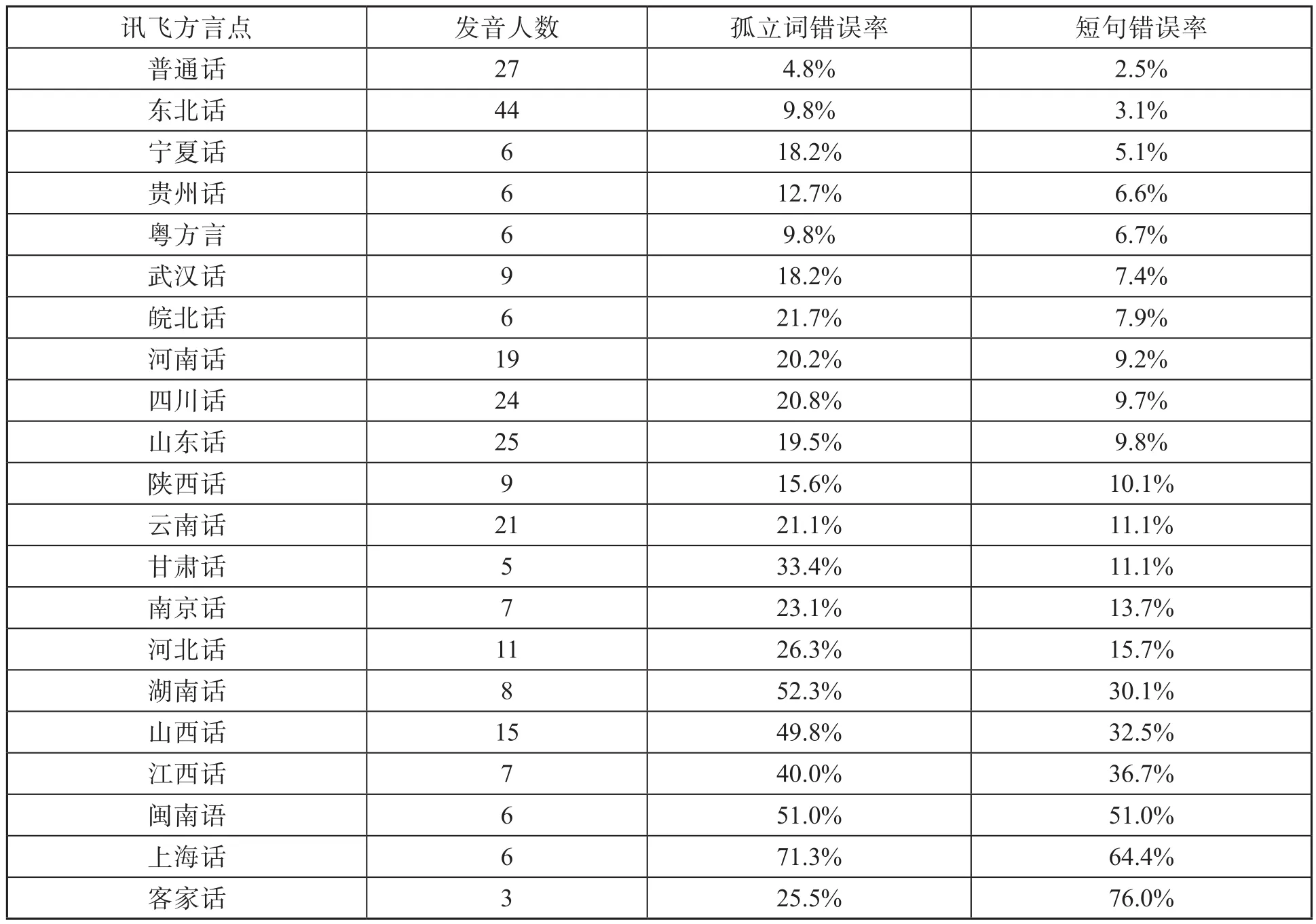
表1 各方言點(diǎn)識別錯誤率
(1)北方方言(或者說官話)內(nèi)部一致性相對較高,所以即使我們的發(fā)音人不是恰好在訊飛方言所提供的方言點(diǎn),區(qū)別也不會很大,其識別錯誤率會相對較低,除了山西話(晉語),絕大部分的短句錯誤率在15%以下。
(2)南方方言(或者說東南方言)內(nèi)部區(qū)別較大,有的鄰近地區(qū)甚至無法溝通,發(fā)音人所說方言若跟訊飛方言選點(diǎn)不在一處,其識別錯誤率極高,幾乎無法識別。例如,125號發(fā)音人說的是海南省海口的方言,選擇的訊飛方言是閩南語,識別錯誤率高達(dá)80%。這可能是因?yàn)楹?诜窖詫儆陂}語瓊文片府城小片,與閩南片差距較大。發(fā)音人還嘗試了選擇粵方言和客家話,準(zhǔn)確率都很低。
(3)南方方言內(nèi)部一致性相對較低,發(fā)音人的分布對錯誤率影響較大。例如選擇貴州話的6位發(fā)音人都是貴陽市區(qū)的,與訊飛輸入法選點(diǎn)(大概率為貴陽市)一致,錯誤率較低。而同為西南官話的武漢話、四川話和云南話錯誤率卻相對較高,這是因?yàn)榘l(fā)音人分布較廣,例如選擇云南話的21位發(fā)音人分屬昆明市、曲靖市、玉溪市和昭通市,與訊飛輸入法的選點(diǎn)“云南話(昆明)”有一定差異,所以錯誤率較高。粵方言的內(nèi)部差異也不小,但在本次調(diào)查中,由于其使用人數(shù)少、分布又集中,所以作為南方方言錯誤率反而較低。
(4)方言交界地區(qū)的方言點(diǎn),往往受到臨近多個方言的影響,同時帶有不同方言的特點(diǎn),按方言歸屬來選擇訊飛輸入法的方言點(diǎn),錯誤率就會很高。例如,40號發(fā)音人是湖南省株洲市茶陵縣的方言,根據(jù)行政歸屬選擇了訊飛提供的湖南話(長沙),方言劃分上也同是湘語長益片長株潭小片,但錯誤率依舊接近40%。實(shí)際上湖南省株洲市茶陵縣處于湖南江西交界地帶,緊鄰江西井岡山,受贛客方言影響較大。同樣的錄音,選擇客家話和江西話,也基本無法識別。所以對于交界地帶受各種方言影響的方言點(diǎn)來說,語音識別很是困難。以上規(guī)律說明,智能語音輸入法如要提高方言特別是南方方言的識別正確率,需要更加細(xì)分的方言選點(diǎn)。
3.具體語句的識別錯誤分析
本次調(diào)查的語料包括疫情相關(guān)的21個孤立詞和20個短句。雖然在實(shí)際生活場景中,也會有單獨(dú)詞成句的,但孤立詞因?yàn)闆]有上下語境,語音識別的難度會高很多。本次調(diào)研選取的21個疫情相關(guān)用語,其平均識別錯誤率如表2所示。錯誤率最高的是“發(fā)麻”,識別出的錯誤結(jié)果有“發(fā)嗎、發(fā)嘛、煩嗎、壞嗎、花馬、喝嘛、號碼、干嘛、干嗎、嘎瑪、福馬、服務(wù)忙、放忙、番麥、砝碼、伐麻、發(fā)息、發(fā)墨、發(fā)膜、發(fā)毛、發(fā)忙、發(fā)碼、發(fā)馬、幫忙、白馬、霸蠻、爸媽、發(fā)墨、丈母娘啊、Fame”等。錯誤率第二的“嘔吐”,在很多方言里的說法為“噦”,這樣的一個單音節(jié)詞是很難被識別出來的,識別錯誤有“哦、敢約、約、干約、干悅、與、原、月、我、暈、約”等等。由于篇幅限制,關(guān)于孤立詞和短句更為具體的錯誤分析將另文討論。
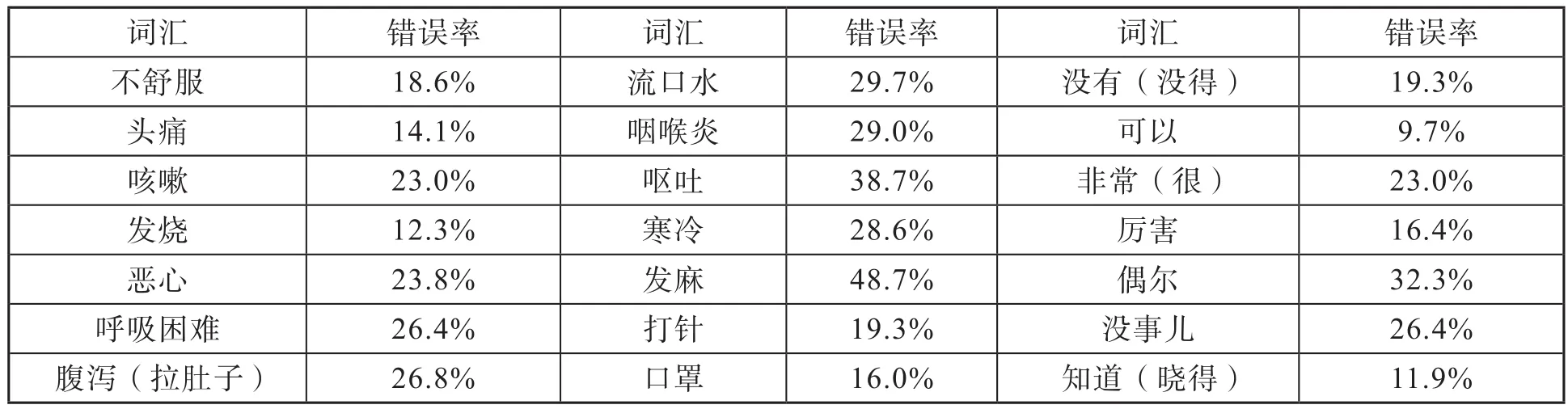
表2 調(diào)查表中21個孤立詞語的識別錯誤率
四、討 論
本研究是以訊飛語音輸入法在疫情防控場景下的識別情況為例,對智能語音技術(shù)在重大突發(fā)事件中應(yīng)用評估的初步探索。可以看到,社會大眾對智能語音輸入法已經(jīng)有了相當(dāng)?shù)牧私夂推诖嶏w輸入法對于疫情語料的識別,在官話地區(qū)的方言表現(xiàn)較好,可以達(dá)到實(shí)用水平,而在東南地區(qū)的方言表現(xiàn)較差,需要更加細(xì)分的方言選點(diǎn)。由于現(xiàn)實(shí)條件的多種限制,本次調(diào)查語料樣本的數(shù)量和部分方言點(diǎn)的發(fā)音人數(shù)量(少于10人)還不太夠,這也使得調(diào)查數(shù)據(jù)有一定的隨機(jī)性,導(dǎo)致最終結(jié)果受手機(jī)狀況、背景噪音、發(fā)音人狀況、分布等各種因素的影響,這些我們將在下一步的工作中加以改進(jìn)。其中有兩個問題需要在這里討論一下。
(一)言語表達(dá)方式的問題
本次實(shí)驗(yàn)的語料是固定的,調(diào)查表里的21個詞語和20個短句,都是普通話的表達(dá)方式,但在各個方言里往往會有不同的說法,甚至具體到某個發(fā)音人,表述的方式都可能有所不同。這也跟發(fā)音人的言語轉(zhuǎn)換能力和風(fēng)格有關(guān),其中老中青不同年齡段發(fā)音人的說法往往就不一樣。例如贛方言某方言點(diǎn),其老中青三代對“雞蛋”的說法分別是“嘎=子”①此處在字后右上角加等號“=”表示同音字。“雞子”“雞蛋”。一般來說,越年輕的人受普通話影響越多,會用方言的讀音來念普通話的句子(例如有些方言里年輕人不再說“噦”,而只是用方言的讀音來念“嘔吐”),而中老年人會用更為本地方言甚至瀕臨消失的表達(dá)方式(常常被認(rèn)為是特別“土”的表達(dá)方式),這對識別錯誤影響會很大。從實(shí)際需求來看,在語言應(yīng)急服務(wù)中,以解決方言障礙為目標(biāo)的主要人群是中老年人,所以我們在調(diào)查和實(shí)驗(yàn)的時候,需要考慮周到,把各年齡階段的老中新派方言表達(dá)方式都要涵蓋進(jìn)來,以更好地應(yīng)社會所需。
(二)方言的選擇和劃分問題
漢語方言差異較大,劃分復(fù)雜,給語音識別提出了很大的挑戰(zhàn)。從本次調(diào)查研究可以看出,方言的選擇和劃分對識別結(jié)果影響很大,需要認(rèn)真對待。(1)從使用者角度來看,需要恰當(dāng)選擇方言,不僅僅是根據(jù)距離和行政區(qū)劃,還要根據(jù)方言學(xué)上的劃分。但普通人一般都不會具備這樣的語言學(xué)知識,所以還需要語音技術(shù)(結(jié)合地理定位功能)能夠更加智能地識別方言,這就需要知道并能提取各方言的特征因素(戴慶廈,等2018)。另外,語音識別的錯誤率跟方言間的可懂度、互通度等因素有關(guān),但可懂度不是劃分方言區(qū)屬的唯一依據(jù),也不是最為重要的依據(jù),所以方言區(qū)屬劃分跟語音識別的效果偶爾會出現(xiàn)矛盾,在實(shí)際應(yīng)用中應(yīng)當(dāng)以識別效果為準(zhǔn)。(2)從技術(shù)研發(fā)者角度看,需要給出更多的方言點(diǎn)。但方言猶如顏色一樣,界限模糊,可以無限細(xì)分。另外,普通話長期形成了規(guī)范的文語對應(yīng),而方言很多時候“考本字”都很困難,分得太細(xì),則語料庫的訓(xùn)練成本會很高。那方言到底要細(xì)分到什么地步?好在到了智能信息時代,可以有新的思路。首先是數(shù)據(jù)獲取更為容易,在需求驅(qū)動下,哪個方言點(diǎn)的用戶多、使用頻率高,軟件搜集的數(shù)據(jù)越多,對該地區(qū)方言的劃分就可以更細(xì)。所以不一定以方言劃分為唯一標(biāo)準(zhǔn),而是以識別效果為標(biāo)準(zhǔn),不降到一定的錯誤率標(biāo)準(zhǔn),就繼續(xù)細(xì)分,達(dá)到實(shí)用程度為止。其次是用戶參與,現(xiàn)在智能終端普及,人手一機(jī),均可對本家鄉(xiāng)方言的識別結(jié)果加以校正,這種方式可以大大降低成本,使得技術(shù)能更快地進(jìn)入社會使用。值得注意的是,對于商業(yè)應(yīng)用來講,需要考慮到市場和成本因素,但從社會民生角度來講,需要適當(dāng)?shù)乇U险Z言“少數(shù)、弱勢”群體的權(quán)益。
五、展 望
本次疫情中,語音智能技術(shù)并沒有得到如我們所期望的大規(guī)模應(yīng)用。原因之一是對新生事物要求往往會更高更挑剔。好比自動駕駛技術(shù)已經(jīng)可以比人類司機(jī)事故率更低,但只有其安全系數(shù)高出很多倍,才有可能被認(rèn)可進(jìn)入大眾生活。語音技術(shù)也是如此,雖然本次調(diào)查表明大眾對語音技術(shù)是期望的,但根據(jù)我們另外一項(xiàng)對159人的調(diào)查,大眾對語音識別技術(shù)依然不滿意,認(rèn)為需要改進(jìn)的地方有:準(zhǔn)確率低(占比54.09%)、轉(zhuǎn)換速度慢(31.45%)、缺少方言識別(64.15%)、缺少外語識別(29.56%)、無法感知話語中的情感態(tài)度(45.28%)等。語音識別技術(shù)要真正達(dá)到實(shí)用,進(jìn)入日常生活,還需要繼續(xù)降低識別錯誤率。目前語音智能技術(shù)(采用深度神經(jīng)網(wǎng)絡(luò))有兩個缺陷:(1)計算量龐大,大量參數(shù)迭代收斂、訓(xùn)練封裝后如果有新的數(shù)據(jù)需要學(xué)習(xí),用戶端的簡單設(shè)備就做不到了;(2)模型不可解釋,難以保證下一次不犯同樣的錯誤。有學(xué)者提出了深度模糊系統(tǒng)及其快速學(xué)習(xí)算法可以克服這兩大缺陷,是一個很好的發(fā)展方向(Wang 2003)。另外,人的大腦適應(yīng)性極強(qiáng),具有很強(qiáng)的泛化能力,但神經(jīng)網(wǎng)絡(luò)無法把學(xué)到的東西泛化到和訓(xùn)練集統(tǒng)計規(guī)律稍有區(qū)別的地方。長期以來,語音智能技術(shù)依靠統(tǒng)計模型,很多試圖從規(guī)則知識出發(fā)或者采用兩者結(jié)合的方法都不是很成功。最近的符號主義人工智能提出了一個切實(shí)可行的道路,就是利用符號和它的一套操作系統(tǒng),重新把知識和模型教給神經(jīng)網(wǎng)絡(luò)(Marcus 2020)。這些新方法都為降低錯誤率提供了新的發(fā)展方向。
目前很多語音智能識別技術(shù)的高正確率是基于特定語料庫的,從本次調(diào)查和研究可以看到,智能語音技術(shù)在疫情防控場景下,特別是對方言的識別效果,還是有很大的改進(jìn)空間。我們期待語言學(xué)和計算機(jī)領(lǐng)域的學(xué)者,不斷探索新思路、新技術(shù),提升智能語音技術(shù),在重大突發(fā)事件中能更好地為社會民生服務(wù)。
(感謝參與調(diào)查工作的諸位志愿者:白薦楠、陳麗琳、陳璐、陳雯茜、程婭惠、從恩竹、崔澤馨、樊星辰、范婧婕、馮星云、馮驛雯、付羿雨、高凡舒、高山倩、高子庭、關(guān)喬之、郝雨潔、胡硯才、黃悅、賈紫琳、姜啟寧、姜玉郎、金靈、拉姆、李晨光、李吉霞、李康敏、李樂樂、李祺溦、李宛婷、李正、梁霄云、劉晨筱、劉會珠、劉麓基、劉瑞秋、劉一新、劉玉萍、羅會露、羅家淇、馬悅霞、毛翎、歐陽瑞美、潘新宇、龐博、彭曉鈺、彭彥涵、蒲素素、蒲璇妃、陜月、尚鑫欣、邵芊涵、孫建亞、孫銘澤、孫千千、唐銳奇、汪子涵、王春醒、王家琪、王京欣、王曉宇、王雪瑩、王祎琳、王瑜琦、尉然、鮮欣儀、肖開捷、熊莉萍、徐立恒、鄢冉、楊豆豆、楊渙渙、楊子謙、姚安甫、殷王會、尹雪力、袁詩夢、張競兮、張沁萌、張瑞穎、張婷婷、張鈺琪、張鈺揚(yáng)、張蕓鷺、趙姝忞、趙怡昕、趙玥、周博聞、周婧妍、朱思恒、朱芷妍、曾心怡、鄒雨桐等。并向身體不便特別是手指受傷無法寫字、打字的文字工作者致敬!本調(diào)查為獨(dú)立進(jìn)行,跟任何語音公司,包括科大訊飛,均無利益關(guān)聯(lián)。)
附錄(調(diào)查表中的20個短句):
(1)我頭疼,我頭暈。
(2)我咳嗽,干咳,我咳得出不了氣了。
(3)我女兒拉肚子,肚子痛。
(4)我全身酸痛,我沒有力氣。
(5)我奶奶平時身體還好,沒有什么別的病。
(6)我外婆的病要不要緊?
(7)醫(yī)生,我媽媽的病治得好不?
(8)我爸爸輸液輸完了,要拔針頭。
(9)我家里有人好像不舒服,還沒確診。
(10)我想上廁所,廁所在哪兒?
(11)我老婆吃了飯,還沒有吃藥。
(12)我爺爺發(fā)燒,燒得很厲害,燒了幾天了。
(13)我量了體溫,我老公的體溫是38度多。
(14)我外公做過CT、做過核酸檢測、做過采樣了。
(15)我昨天到湖北去過一趟,沒有去過武漢。
(16)我今天應(yīng)該到哪個醫(yī)院、哪個科室去看病?
(17)護(hù)士,我對青霉素和其他抗生素都不過敏。
(18)我喉嚨疼、我腰疼、我胸口疼。
(19)我自己沒事,就是我兒子有點(diǎn)流鼻涕。
(20)我的頭很疼,都快要炸了。
猜你喜歡
開放教育研究(2021年3期)2021-05-25 02:41:06
小學(xué)科學(xué)(學(xué)生版)(2020年12期)2021-01-08 09:28:04
裝備制造技術(shù)(2020年4期)2020-12-25 05:26:24
表面工程與再制造(2019年6期)2019-08-24 06:40:04
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
商周刊(2018年18期)2018-09-21 09:14:46
能源(2018年4期)2018-05-19 01:53:44
