一種噪聲環境下的雷達目標高分辨率距離像魯棒識別方法
2020-09-05 14:35:30李瑋杰劉永祥
雷達學報 2020年4期
關鍵詞:模型
李瑋杰 楊 威 黎 湘 劉永祥
(國防科技大學電子科學學院 長沙 410073)
1 引言
傳統雷達目標識別技術依賴于人工設計的特征,而這些特征的完整性和有效性往往缺乏有力保證,并且復雜電磁環境會干擾識別結果,導致傳統雷達目標識別技術的精確性和魯棒性面臨極大挑戰。而深度學習技術可以自動提取目標本質特征,這種端到端的學習方式大大提升目標識別的精確性和魯棒性。
有學者通過不同的深度學習方法對高分辨率距離像(High Resolution Range Profile, HRRP)進行目標識別,主流算法包括卷積神經網絡(Convolutional Neural Networks, CNN)、棧式自編碼器(Stacked AutoEncoder, SAE)、深度置信網絡(Deep Belief Networks, DBN)以及循環神經網絡(Recurrent Neural Network, RNN)等[1]。其中,文獻[2]將CNN應用于HRRP識別,在–20~40 dB的高斯白噪聲環境情況下擴展訓練集樣本,對3類目標進行識別,平均識別率達到91.4%。文獻[3]使用直接基于極化距離矩陣、Pauli分解和Freeman分解3種方式提取極化距離矩陣中的信息,并將提取得到的目標特征向量送入CNN進行訓練,最終識別率達到100%。文獻[4]提出利用RNN中的長短時記憶循環神經網絡(Long-Short Term Memory recurrent neural network, LSTM)對HRRP進行識別,使用175個數據進行訓練,測試100個樣本,全部識別成功。文獻[5]提出一種基于RNN的注意模型,使得模型自適應衡量每一個數據段在識別中起到的作用,訓練樣本個數為 7375,測試數據的樣本個數為16655,測試樣本識別率達到88.3%。文獻[6]將雙向LSTM的模型應用于HRRP數據識別,訓練樣本個數為 7800,測試數據的樣本個數為5124,識別率達到了90.1%。文獻[7]提出了一種基于雙向GRU的注意力機制模型,訓練樣本個數為 7800,測試數據的樣本個數為5124,識別率達到了90.7%。文獻[8]中將棧式降噪稀疏自編碼器(stacked Denoising Sparse AutoEncoder, sDSAE)用于雷達目標識別,由于深度的增加,該方案的識別效果比K近鄰分類方法和棧式自編碼器好。文獻[9]使用支持向量機、深度神經網絡、SAE對Su27, J6, M2K 3種仿真戰斗機的HRRP數據進行識別,識別率分別為74.26%, 79.63%和85.00%。
對基于深度學習的雷達目標HRRP識別模型,研究尚在起步階段,上述研究將深度學習應用于雷達目標識別領域取得了較好的成果,但較少考慮到低信噪比情況下如何提高模型的抗噪聲性能。本文提出了一種噪聲環境下的雷達目標HRRP魯棒識別方法,在訓練集中插入不同信噪比值的噪聲,并使用結合殘差塊、inception結構和降噪自編碼層的卷積神經網絡進行識別,在高斯白噪聲和瑞利噪聲的條件下可以實現在較寬范圍信噪比條件下的較高識別率。
2 一種噪聲環境下的雷達目標HRRP魯棒識別方法
2.1 卷積神經網絡
卷積神經網絡是深度學習的代表算法之一,大量應用于計算機視覺、自然語言處理等領域,使用了稀疏交互(sparse interactions)、參數共享(parameter sharing)、等變表示(equivariant representations)來降低網絡復雜度,使得存儲需求降低、運算效率提高、具有對平移等變性質[10]。CNN具有分層學習特征的能力,可以訓練CNN自動地從HRRP數據集中學習有用特征并分類。
CNN結構分為輸入層、隱藏層、輸出層,如圖1所示。
輸入層接收多維數據,一維CNN的輸入層接收一維或二維數組,其中一維數組通常為時間或頻譜采樣,二維數組可能包含多個通道;二維CNN的輸入層接收二維或三維數組。
隱藏層通常是由一連串的卷積層、池化層和全連接層組成的。卷積層模仿人眼對環境的識別,參數比全連接層相比大大減少,其功能是對輸入數據進行特征提取,通常會有多個卷積核對輸入進行處理。經過卷積層后的輸出會被傳遞至池化層進行特征選擇和信息過濾,在池化層進行下采樣,對特征進行降維,并且使得網絡對數據平移保持近似不變。經過多層卷積層和池化層,在全連接層把學習得到的特征聚合起來。
輸出層在分類問題中,通常使用softmax層來輸出分類標簽。
為了防止過擬合,Hinton等人[11]提出Dropout機制,如圖2所示,在每次訓練時,讓神經元依概率(如50%)隨機失活,阻止某些特征的協同作用來緩解過擬合,也可以將Dropout作為一種多模型效果平均的方式,每次訓練時,模型的結構都會因為Dropout隨機性發生變化,多次訓練后相當于多個不同模型結合起來得到最終模型,能很好地緩解過擬合。
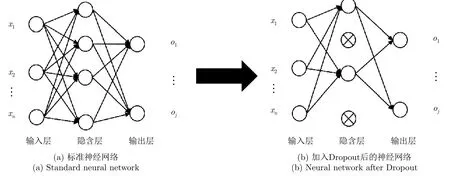
圖 2 Dropout示意圖Fig. 2 The schematic diagram of Dropout
網絡在訓練階段,文獻[12]證明了交叉熵代價函數要優于平方差代價函數,因此本文采用交叉熵函數損失函數,假如給定一個帶標簽的數據集i 個訓練數據 x(i)經過網絡后得到輸出層標簽向量o(i),則交叉熵損失函數表達式為。

其中, D 為樣本維數, mb為批訓練樣本個數,第i個 訓練數據 x(i)對 應的標簽數據集的第 j維對應值,第i個 輸入數據 x(i)對應的輸出層標簽向量的第j維對應值。
2.2 殘差塊、inception結構和降噪自編碼層
本文受文獻[13]啟發,為了進一步提高網絡深度,降低噪聲影響,提高網絡性能,使用了圖3所示的殘差塊,其中數據流向有兩條,一條經過卷積層,另一條不經過卷積層。殘差塊包含的卷積層個數和卷積層的核參數都是可以調節的。殘差塊可以有效提高網絡深度,而網絡深度的提高可以提取更深層次的特征,這種特征具備更好的魯棒性。
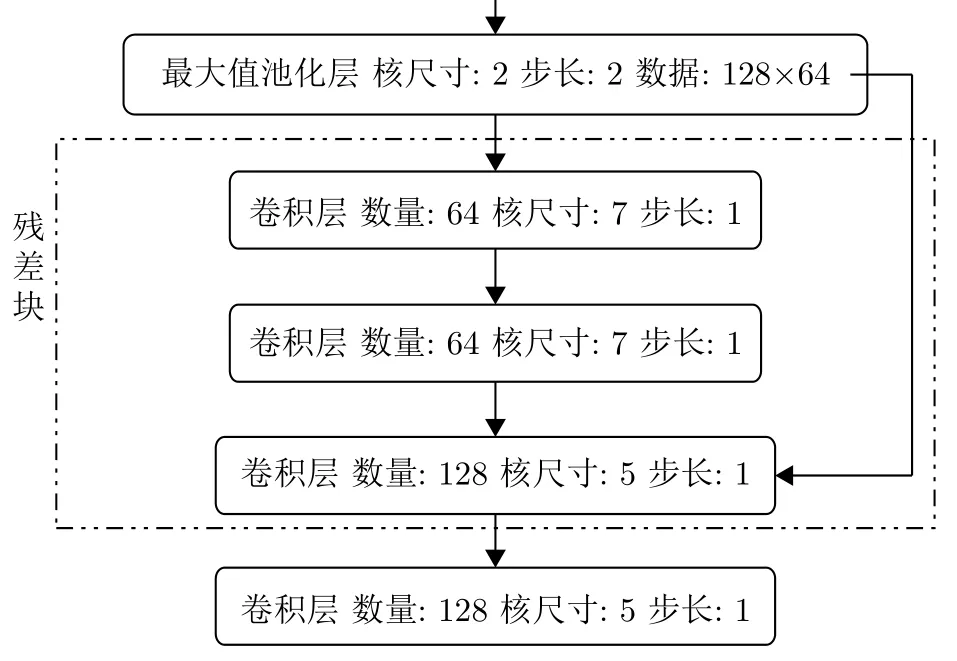
圖 3 殘差塊結構圖Fig. 3 The structure of residual block
在使用殘差塊來提高網絡深度的同時,借鑒inception結構[14]來增加網絡寬度來更好學習特征,提升網絡性能。利用稀疏網絡結構產生稠密的數據,這樣將稀疏矩陣聚類為較為密集的子矩陣來提高計算性能,在提高神經網絡性能的同時,又能保證計算資源的使用效率。GoogLeNet團隊提出了inception網絡結構,通過這種結構來搭建一個稀疏性、高計算性能的網絡結構。卷積核的核尺寸影響感受野的大小,因此選擇不同的核尺寸會影響學習結果,該結構使用了不同核尺寸模塊,由網絡自行選擇參數,從而將選擇不同核尺寸的權重這一步驟交由模型自行學習,這樣就通過稀疏的卷積連接產生了不同感受野范圍下的稠密數據。如圖4所示,inception結構使用了多個子模塊,將核尺寸1, 3和5的卷積層和池化層并聯在一塊,并在在核尺寸為3, 5的卷積層前面和池化層后面分別加上了核尺寸為1的卷積核,來降低數據維度,增加了網絡對尺度的適應性和網絡寬度來更好地學習特征。
降噪自編碼器通過對輸入數據加噪,使得模型學習如何去除噪聲,還原本來的數據,從而提高模型魯棒性[15]。增加了如圖5所示降噪自編碼器層來進一步降低噪聲影響,在訓練時通過隨機丟棄輸入來實現對輸入的損失,近似模擬噪聲對數據影響,而輸出通過訓練來還原為原始輸入。其中隱含層的數量和節點數可以調節,對網絡的損失函數重新定義,加入了對降噪自編碼器層輸入和輸出之間的均方誤差函數,進行整體網絡的訓練。降噪自編碼器層的均方誤差對于降噪自編碼器層之后的層沒有影響,但會影響之前層的訓練。

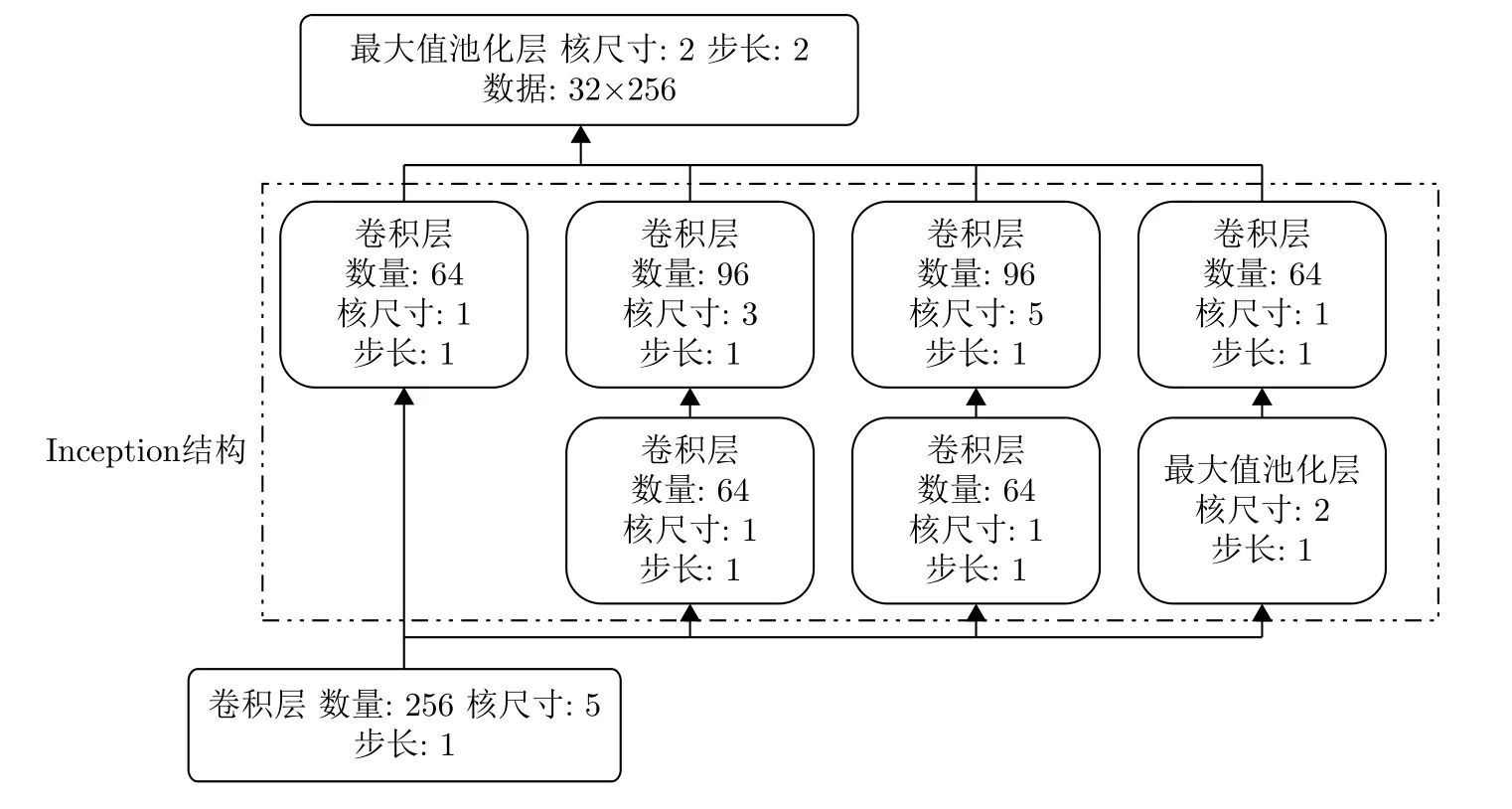
圖 4 Inception結構圖Fig. 4 The structure of inception
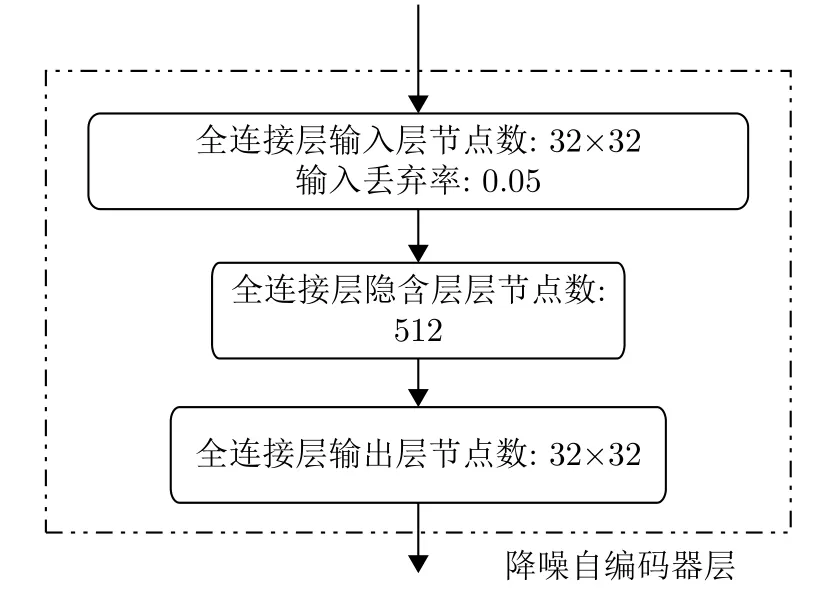
圖 5 降噪自編碼器層結構圖Fig. 5 The structure of residual DAE
其中, J2為 新的損失函數, J1為網絡交叉熵損失函數,降噪自編碼器層輸入,降噪自編碼器層輸出, mb為 批訓練樣本個數, α為超參數控制降噪自編碼器層損失函數占總體的權重,本文取1。
2.3 結合殘差塊、inception結構和降噪自編碼層的卷積神經網絡
將以上模塊結合起來,本文所設計的網絡結構如圖6所示。
網絡使用了兩個殘差塊,之后鏈接了一個inception結構以更好學習通過殘差塊得到的特征,最后一個卷積層是為了降低數據維數,并且在最后一個卷積層后鏈接一層降噪自編碼器降低噪聲影響。其中殘差塊和inception結構的數量和位置可以調節,而降噪自編碼器層使用的是全連接層,放在網絡的較高隱藏層,通常是最后全連接層部分。網絡各部分功能框圖如圖7所示。
3 實驗結果與分析
實驗平臺為64位Window10系統,CPU2.8 GHz,內存8 GB,采用Tensorflow框架CPU版本實現。采用3類實測飛機目標雷達HRRP實測數據,其中雷達的中心頻率為5520 MHz,信號帶寬為400 MHz,飛機的參數如表1所示,其時域特征示意圖如圖8所示。其中“安26”為中型螺旋槳飛機,“獎狀”為小型噴氣式飛機,“雅克42”為中型噴氣式飛機。

表 1 飛機參數(m)Tab. 1 Parameters of planes (m)
每類有26000個樣本,隨機抽取不放回得到訓練集每類23000個樣本,測試集每類3000個樣本,每一個樣本為256維,學習率為0.001,優化算法使用Adam算法,批訓練大小mb為100。值得指出的是訓練集樣本的增多會提高識別率,當每類7000個時,在高斯白噪聲條件下,圖6和圖9所示模型在0 dB下相差較大,約15%左右,但增加訓練集數量后,差距會減小。這說明當擁有足夠數據時,模型的復雜度對于結果的影響會降低。

圖 6 網絡結構Fig. 6 The structure of network
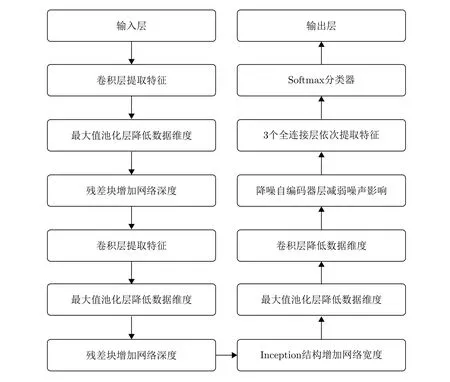
圖 7 網絡功能框圖Fig. 7 The block diagram of network function
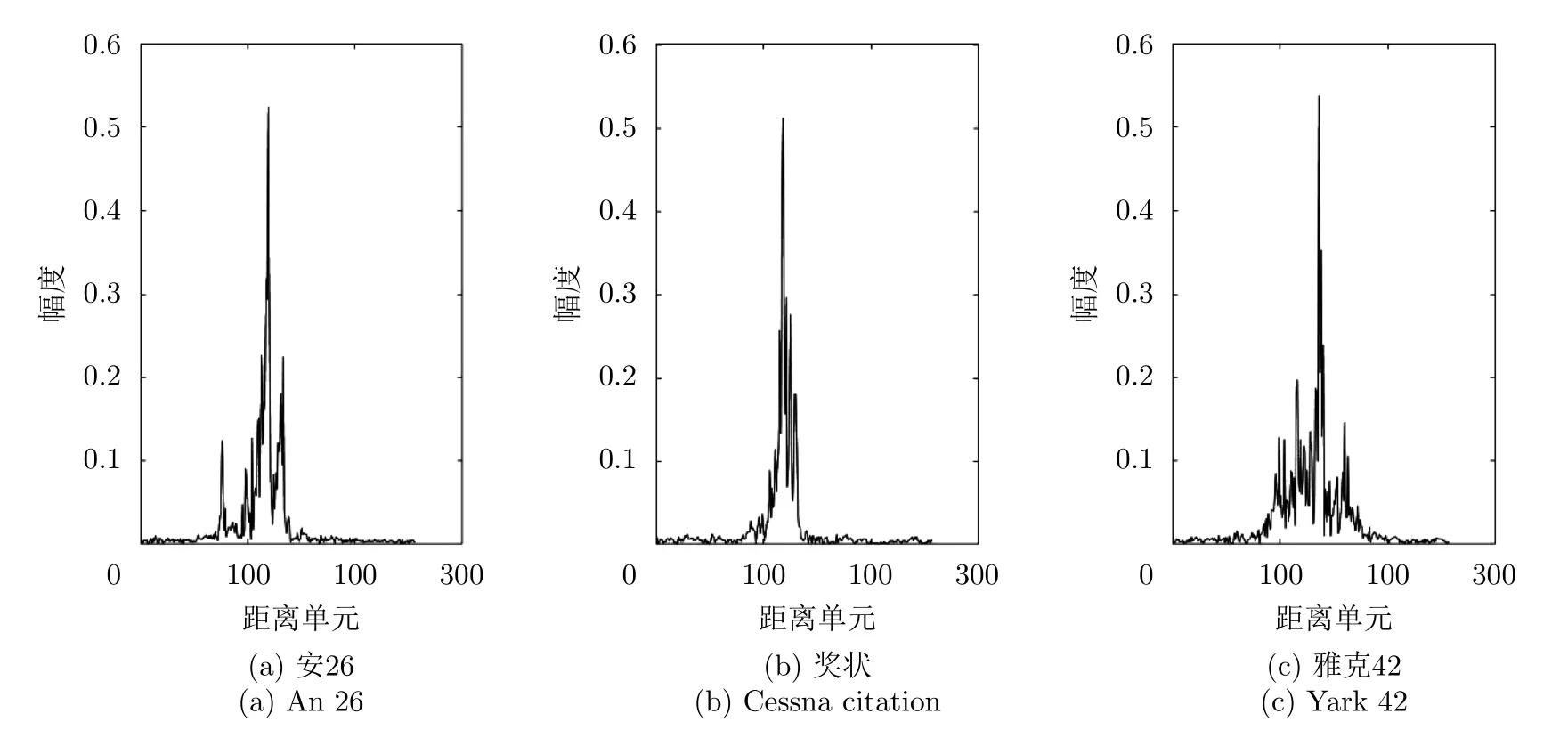
圖 8 HRRP數據示意圖Fig. 8 Schematic diagram of HRRP
文獻[16]指出信號的正交分量和同向分量中噪聲類型可以假設為高斯白噪聲。文獻[17]指出復信號的噪聲幅度服從瑞利分布,因此本文在瑞利噪聲的環境下進行實驗,根據信噪比對樣本添加瑞利噪聲,訓練集的每類樣本中的4000個樣本加入SNR=0 dB的瑞利噪聲,每類樣本中的2000個樣本加入SNR=15 dB的瑞利噪聲,其余訓練樣本不進行加噪處理,再進行歸一化處理。需要指出的是,加入不同信噪比的樣本的數量對結果會有一定影響,加入某信噪比下的樣本越多,會提高該信噪比樣本的識別率,同時降低其他信噪比樣本識別率,使用不同比例的樣本,會導致識別率發生變化,因此如果加入過多低信噪比樣本會導致對于高信噪比樣本識別率下降。測試集樣本加入不同信噪比的瑞利噪聲,使用訓練集樣本的歸一化參數進行歸一化處理。為了對照觀察網絡深度和寬度對結果影響,參考文獻[2]和文獻[3]使用了如圖9所示的卷積神經網絡,含有2個卷積層和2個池化層。識別結果如表2所示。
其中信噪比公式為


圖 9 卷積神經網絡結構圖Fig. 9 The structure of CNN
其中, Ps為 信號的平均功率, D為樣本維數,即距離單元個數,為256, Pd為第d個距離單元上信號功率, n0為噪聲功率。
考慮到不同噪聲類型對結果的影響,本文還在高斯白噪聲下進行了實驗,訓練集的每類樣本中的4000個樣本加入SNR=0 dB的高斯白噪聲,每類樣本中的2000個樣本加入SNR=15 dB的高斯白噪聲,其余訓練樣本不進行加噪處理,再進行歸一化處理。測試集樣本則加入不同信噪比下的高斯白噪聲來測試模型性能,使用訓練集樣本的歸一化參數進行歸一化處理。結果如表3所示。
通過對比結果可以發現,隨著網絡深度和寬度的增加,提取得到的特征受噪聲影響會越來越小。模型在低信噪比情況下的識別能力進一步得到提高,各個信噪比之間的識別率差別進一步縮小。這是由于隨著網絡復雜度的提升,提高了對于樣本的學習能力,增強了網絡性能,因此對于包含了噪聲樣本和正常樣本的訓練集,改進后的網絡可以更好地學習兩者特性,只需通過幾個點的信噪比就可推廣到較寬信噪比范圍下的樣本分類。但要想得到更好結果,可能需要對樣本和模型兩個方面進行調整。調整樣本信噪比分布,增加網絡深度和寬度,在多處隱藏層中插入自編碼器,可以進一步提高識別率,縮小各個信噪比之間的識別率差距,達到在各種信噪比情況下識別率的一個平衡。
同時可以發現,如果在訓練集中未加入噪聲,所得到的模型其實對于低信噪比的測試樣本是沒有識別能力的,因此出現了過擬合現象,訓練集喪失了泛化能力,識別率急劇下降甚至到0。但加入0 dB和15 dB的噪聲后,模型具備了在較寬范圍下的識別能力。說明模型需要一定的先驗信息進行學習并泛化到其他條件下的識別。并且模型在兩種噪聲類型下的表現均不錯,這是由于深度學習模型是由數據驅動的,對于數據噪聲類型沒有過多要求,因此在實際應用中模型訓練時加入低信噪比樣本可以提高模型的抗噪性能。

表 2 訓練集加入瑞利噪聲結果Tab. 2 Recognition results based on Rayleigh noise training set

表 3 訓練集加入高斯白噪聲結果Tab. 3 Recognition results based on White Gaussian noise training set
為了進一步探究訓練集和測試集中噪聲類型對結果的影響,本文在訓練集和測試集中使用了不同類型的噪聲進行實驗,得到的結果如表4所示,方案1為訓練集使用瑞利噪聲測試集使用高斯噪聲,方案2為訓練集使用高斯噪聲測試集使用瑞利噪聲。通過結果可以發現識別率有所降低,但對比訓練集未加噪來說仍有較高的識別率,說明模型在這兩種類型的噪聲之間具有泛化性,這可能是因為這兩種噪聲類型的差異不大,識別率不會下降過多,但模型是否可以泛化到更多的情況下還需要進一步研究。
為了更好地理解各個結構對識別率的影響,本文刪除了網絡中部分結構來觀察對結果的影響。在高斯白噪聲環境下,并且降低訓練集樣本數到每類6000個,訓練集的每類樣本中的1000個樣本加入SNR=0 dB的高斯白噪聲,每類樣本中的500個樣本加入SNR=15 dB的高斯白噪聲,其余訓練樣本不進行加噪處理。通過表5可以發現,改變網絡的寬度和深度都能影響網絡的性能。降噪自編碼器層在某種程度上消除噪聲,也是提高網絡性能的一種方案。
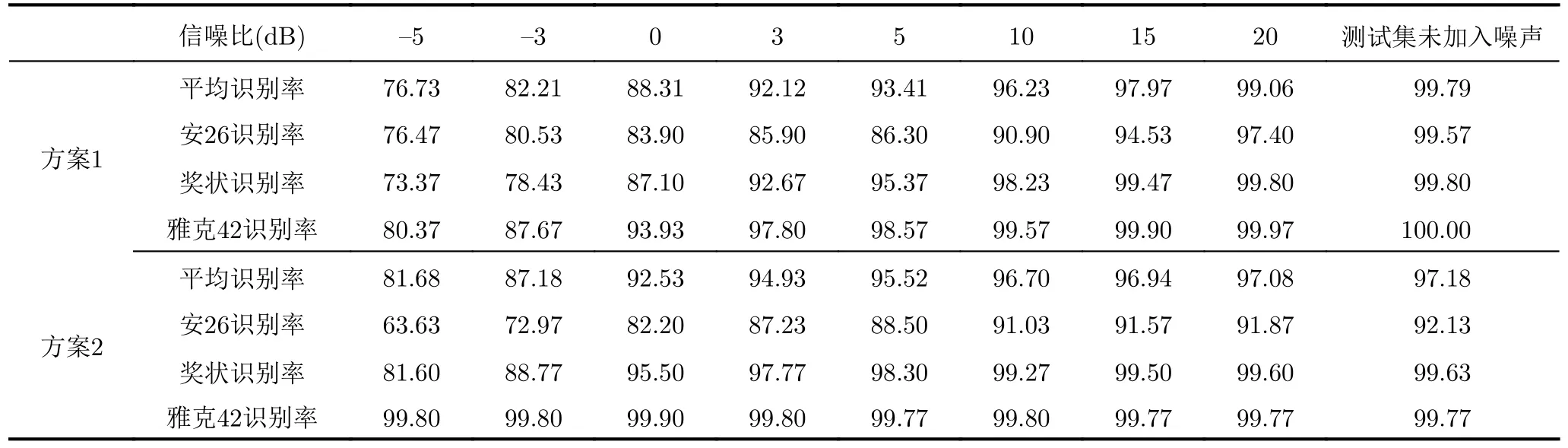
表 4 不同噪聲類型識別結果Tab. 4 Recognition results based on different noise types
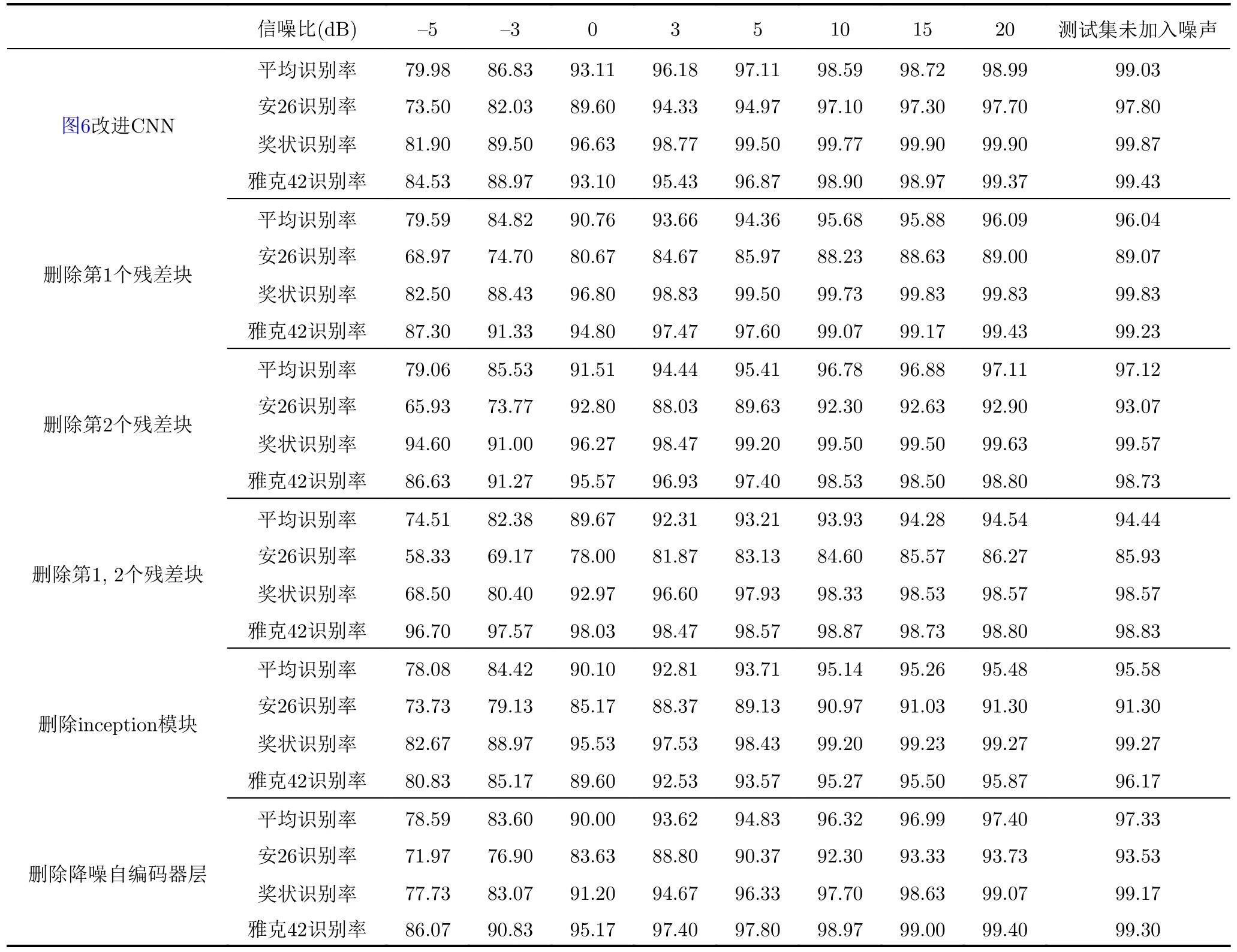
表 5 刪除結構加入噪聲結果Tab. 5 Recognition results based on deleted structure
4 結束語
本文提出一種噪聲環境下的雷達目標HRRP魯棒識別方法,通過增強訓練集和使用結合殘差塊、inception結構和降噪自編碼層的卷積神經網絡。實驗結果表明,本方法能保證較寬信噪比范圍內的識別性能。同時本文在對訓練集中加入噪聲時,無需像文獻[2]中加入從–20到40 dB的噪聲樣本,而是插入幾個點的噪聲即可,模型可以根據所加入的幾個信噪比學習到其他信噪比下的樣本識別能力。此外,對于模型深度和寬度提高對于噪聲環境下識別性能提升的機理有待進一步研究。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19