單機器人SLAM技術的發展及相關主流技術綜述
2020-09-15 04:47:28劉明芹張曉光徐桂云李宗周
計算機工程與應用 2020年18期
劉明芹,張曉光 ,徐桂云,李宗周
1.中國礦業大學 機電學院,江蘇 徐州 221116
2.江蘇海洋大學 機械與海洋工程學院,江蘇 連云港 222001
1 引言
SLAM(Simultaneous Localization And Mapping)技術首次提出是用來估算對象之間位置和方向關系,以及估算與關系相關的不確定性。經過國內外眾多學者多年的研究,目前該技術被廣泛應用于自主移動(無人機、機器人、無人駕駛汽車等)及AR 等領域[1-3]。SLAM技術在機器人領域應用較廣泛,本文主要綜述其在機器人領域的應用。
SLAM在機器人領域主要用來解決我在哪、我要去哪的問題。也就是解決機器人自身定位和對環境的認知問題,進而解決路徑規劃問題。
2 SLAM算法的主要發展歷程
2.1 基于距離傳感器的主流SLAM技術
早期SLAM 技術從提出開始,學者們在應用中逐漸針對存在的缺點進行改進,使SLAM 技術在不斷地修正中持續發展。基于概率統計的擴展卡爾曼濾波器最早應用于SLAM 上,由于EKF 擴展卡爾曼濾波器計算量大,計算速度慢,后續學者對EKF-SLAM提出改進,Castellanos等[4]對一致性進行改進,2002年Montemerlo等針對EKF計算量大的缺點進行改進,提出Fast SLAM1.0[5]和 Fast SLAM2.0[6],該 方 法 使 用 EKF 和 RBPF(Rao-Blackwellized Particle Filtering)聯合起來,估計位置和軌跡,使計算量大大減小,運算速度提升。
2.2 基于視覺傳感器的主流SLAM技術
隨著視覺傳感器和圖像傳輸、處理技術的提高,2010年以后,越來越多的SLAM系統采用視覺傳感器為主要輸入信號,從此SLAM 的研究主要集中在視覺SLAM技術上,即VSLAM(Visual SLAM)。VSLAM在計算機視覺、機器人和AR 領域被廣泛使用。在視覺SLAM技術上,國內外眾多學者進行研究。從現有研究成果中看,所使用的視覺傳感器主要有單目、雙目(雙目有普通雙目視覺和Kinect RGB-D 深度視覺兩種)和全景視覺傳感器三種。不同結構的傳感器其相應的后續處理方法也不同:如單目相機無法得到環境深度信息,所以研究的算法中要包含深度預測環節;而雙目視覺(普通雙目視覺和Kinect 深度視覺)可以由傳感器獲得深度信息,算法中就不需要包含深度預測環節。
本文將現有研究視覺SLAM 的技術按是否提取特征點然后通過匹配進行運算,分為特征法和直接法。由于RGB-D 相機獲取環境的信息與普通視覺傳感器不同,所以它后續處理技術也不同,本文將基于RGB-D傳感器的SLAM單獨列出。
2.2.1 基于特征法的SLAM
早期VSLAM的研究主要基于單目相機視覺輸入,使用基于跟蹤和特征點建圖,這被稱為“基于特征的方法”。Harris 最早提出以角點為特征點,稱為Harris 角點,由于Harris 角點對亮度和對比度的變化魯棒性弱,且不具備尺度不變性,在角點檢測時清晰度不高。
利用特征點檢測器及描述符比較流行的方法主要有FAST、SIFT[7]、SURF[8]和ORB[9-10]。其中SIFT和SURF檢測器包含特征點方向,涉及梯度計算的直方圖,ORB特征點由FAST角點檢測器檢測,加入了方向和旋轉不變性特征描述,使特征檢測實時性和描述的魯棒性更強。
點特征是VSLAM算法的主流特征,也有基于線特征,但沒有被廣泛應用。
基于特征點法一直是VSLAM的主流方法,解決方案比較成熟。但從眾多研究者的研究中發現,特征點法存在以下幾個缺點:
(1)關鍵點的提取與描述子的計算非常耗時。實踐中發現,SIFT在CPU上是無法實時計算的,ORB也需要近20 ms的計算。如果整個SLAM以每幀30 ms的速度運行,那么一大半時間都將花在計算特征點上。
(2)使用特征點時,忽略了除特征點以外的所有信息。一幅圖像有幾十萬個像素,而特征點只有幾百個。只使用特征點丟棄了大部分可能有用的圖像信息。
(3)相機有時會運動到特征缺失的地方,這些地方往往沒有明顯的紋理信息。例如有時會面對一堵白墻,或者一個空蕩蕩的走廊。這些場景下特征點數量會明顯減少,可能找不到足夠的匹配點來計算相機運動。
2.2.2 基于直接法的SLAM
為克服特征點法的上述缺點,提出既不計算關鍵點也不計算描述子,而是根據像素灰度的差異,直接計算相機運動的方法,稱為直接法(Direct Method)。Silveira[11]在2008 年最早提出了直接法的概念。在直接法中,并不需要知道點與點之間的對應關系,而是通過最小化光度誤差(Photometric error)來計算。
在直接法中,完成相機位姿估計的視覺里程計,是保證算法準確性和快速性的關鍵、是準確建圖的基礎,也是算法的主要核心部分。眾多學者在視覺里程計上進行研究,Forster 在 2014 年提出SVO(Fast Semi-direct monocular Visual Odometry)[12],通過特征點匹配完成跟蹤,通過直接方法完成建圖。通過特征描述子和LK光流(Lucas-Kanade tracker)用于查找匹配點,通過最小化特征點周圍的光度誤差來估計相機運動。SVO 系統對稀疏的特征塊使用直接法配準,獲取相機位姿,隨后根據灰度不變假設構造優化方程,對預測的特征位置進行優化,最后對位姿和結構進行優化,由于SVO是開源的,被該領域學者廣泛采用。2016年Engel等提出DSO(Direct Sparse Odometry)直接稀疏里程計[13],DSO 是一種完全直接的方法,它擬合了完全直接的概率模型(最小光度誤差)一致性,聯合優化所有模型參數,包括幾何參數(作為參考幀中的逆深度)和攝像機運動。省略了其他直接方法中使用的前期平滑濾波,取而代之的是在整個圖像中均勻地采樣像素,因此其在實時性上非常成功。不依賴于關鍵點探測器或描述符,它可以自然地從所有區域采集像素,包括光度梯度變化的圖像區、邊緣,或是類似白色墻壁等那些光度平滑變化的區域。該算法模型集成了一個完整的光度校準、計算曝光時間、鏡頭漸暈和非線性響應函數。實驗表明,無論是在跟蹤精度上還是在魯棒性方面,該方法在各種現實環境中都優于目前最先進其他視覺里程計方法。
在2011 年,Newcombe[14]提出了基于密度追蹤的實時地圖創建算法(Dense Tracking And Mapping,DTAM),開啟了直接法在SLAM 中的嘗試。DTAM 采用逆深度方式表達深度,為每個像素都恢復稠密的深度圖,并且采用全局優化,計算量大但能保證在特征缺失、圖像模糊等情況下穩定地直接跟蹤和創建地圖,取得較好的效果。2014 年Engel 等人[15]提出了同樣基于直接法的LSD-SLAM,并于2015年擴展為支持雙目相機[16]和全景相機的版本[17]。該算法允許構建大規模、一致的環境圖。除了基于直接圖像對齊的高精度姿勢估計之外,還可以實時重建3D環境為具有相關的半稠密深度圖的關鍵幀的姿勢圖。在sim(3)上運行具有尺度漂移意識的直接跟蹤方法,并可將深度值的噪聲影響納入跟蹤。與DTAM相比,LSD-SLAM僅恢復半稠密深度圖且每個像素深度獨立計算,因此能達到很高的計算效率。
2.2.3 基于RGB-D的SLAM
在2011 年Newcombe 等人最早提出基于深度的VSLAM Kinect Fution[18]。Kinect Fusion在GPU上運行以實現實時處理。Kahler 等人[19]在建圖過程中使用體素塊散列在移動設備上實現Kinect Fusion的實時處理。
為了獲得幾何一致的映射,在RGB-D VSLAM 算法中也使用位姿圖優化和形變圖優化。Kerl 等人[20]使用位姿圖優化來減少累積誤差,這種位姿圖優化幾乎與單目VSLAM 算法中的回環相同。Whelan 等人[21]分別使用位姿圖優化來改進相機運動估計和形變圖優化來改進地圖,估計的地圖得到了改進。形變圖優化通過RGB-D圖像和重建模型之間的匹配來估計相機運動。
基于結構光的RGB-D相機,如Microsoft Kinect,變得便宜且小巧。由于這些相機能實時提供3D 信息,因此這些相機也用于VSLAM算法。應該注意的是,大多數面向消費者的深度相機是為室內使用而開發的。他們將紅外光(IR)投射到環境中以測量深度信息,在室外環境中難以檢測發射的紅外光。此外,深度測量范圍存在限制,使得RGB-D 傳感器只可以捕獲從1~4 m 的環境。RGB-D SLAM API 會提供給消費者成套設備,例如 Google Tango 和 Structure Sensor。特別是,Google Tango通過整合內部傳感器信息給消費者提供穩定的估算結果,使后續使用變得簡單方便。
3 基于距離傳感器的SLAM算法及研究內容
3.1 基于距離傳感器的SLAM研究框架
根據國內外學者的研究文獻可見,基于距離傳感器進行SLAM的機器人,攜帶感知外部環境的距離傳感器常見的有激光雷達和聲吶測距、激光測距傳感器,另外少數用紅外、微波、Kinect等,用外部傳感器獲得環境中障礙物距離機器人的距離,根據距離信息對周圍環境特征進行抽象描述。這些機器人同時也會攜帶如里程計、速度傳感器、加速度傳感器、陀螺儀等可以檢測機器人自身狀態的內部傳感器。將內部傳感器和外部傳感器的信息融合,基于SLAM 框架對機器人定位,并構建增量式環境地圖,同時消除航跡誤差和位姿偏差。
基于概率的方法仍然是解決基于距離傳感器SLAM 問題的主要方法。其基本思想是將SLAM 過程視為一個Bayesian評估問題。

Xt表示0到t時刻機器人的狀態,Zt表示0到t時刻傳感器的觀測值,ut是0到t時刻給定機器人的控制量(或叫里程計數值)。
在SLAM 算法中,機器人的狀態Xt采用創建的地圖Xn(t)和機器人當前的位姿Xr(t)聯合概率分布來表示,即p(Xr(t),Xn(t)|Zt,ut),Xn(t)是環境地圖,Zt,ut為機器人序列的觀測值和運動值。
由此,可以將 SLAM 問題分解成兩個相對獨立的問題:機器人定位問題和環境特征估計問題,或者是基于觀測確定位姿和基于機器人位姿對地圖更新問題。
3.2 SLAM算法及研究的具體內容
基于距離傳感器SLAM在機器人定位問題上,主要采用濾波器EKF 和PF,在環境特征估計上,主要采用EKF等方法。
3.2.1 EKF-SLAM
在EKF-SLAM 中,系統的狀態變量包括機器人位姿和環境特征的位置,假設所有狀態變量均服從正態分布,狀態變量之間的不確定關系由狀態的協方差矩陣表示,而整個EKF-SLAM 的核心問題就是計算和更新協方差矩陣。圖1給出了EKF-SLAM的過程。

圖1 EKF-SLAM過程
EKF 算法的本質就是在“最佳點”處對非線性模型進行線性化。非線性模型的線性化是通過Taylor 展開完成的。通過對運動模型和觀測模型的線性化處理,得到 EKF的預測和更新的狀態估計過程:
在第K步預測下一步的狀態、協方差以及觀測值如下:

第k+1 步獲得觀測值Z(k+1),利用觀測值進行如下更新:

EKF-SLAM 的主要過程就是利用式(2)~(6)遞推估計由機器人位姿和路標位置組成的狀態及相應的協方差矩陣。
EKF-SLAM 的優點是,小環境預測時計算量小,易于實現。缺點是概率密度函數滿足高斯分布,線性化處理誤差大,對錯誤數據關聯敏感,對大環境預測時計算量大。
3.2.2 PF-SLAM
基于RB粒子濾波器的PF-SLAM,在條件概率的基礎上,因式分解:

nt為地圖上路標標記集合,nt={n(1),n(2),…,n(k)}。
將機器人狀態估計分為運動軌跡估計和地圖估計兩部分。粒子濾波幾乎能夠適用于任意傳感器特性、動力學、噪音分布等,可以用于描述非線性、非高斯分布模型。采用通用的概率近似法,和以前的參數方法相比較,減小了在后驗概率密度形狀上的假設限制。通過控制采樣點的數目,粒子濾波能夠隨計算資源進行調節。相同的代碼可以在計算機上按照不同的速度執行不需要修改,能用于解決機器人“綁架”(Robot Kidnapping)問題。與EKF-SLAM 比降低了計算的復雜度,又具有較好的魯棒性。但其局限性是假定環境特征的觀測只與機器人當前位置有關。
3.2.3 Fast SLAM
Fast SLAM中機器人的運動軌跡p(|Zt,ut,nt)的后驗概率用一個粒子濾波器來計算,每個粒子采用N個EKF 濾波器,來估計地圖中N個路標位置p(Xn(t)|,Zt,ut,nt)的后驗概率分布。如果有M個粒子的話,將需要NM個EKF 濾波器,計算量比EKF-SLAM 方法少很多,且在每次采樣中估算機器人的運動軌跡時間是恒定的,這給機器人控制提供了方便。
基于粒子濾波的Fast SLAM 算法采用加權采樣的思想,算法框架如圖2 所示,主要由以下四個迭代步驟組成:首先,針對每個粒子,利用運動學模型預測p(Xr(t)|u(t),Xr(t-1))機器人新的位姿;然后,在每個粒子中,利用觀測信息基于 EKF 更新地圖;其次,利用前面假定的機器人運動軌跡和估計的概率分布,計算每個粒子的權重;最后,利用上一步的權重進行加權采樣,得到無權重的新粒子集。

圖2 Fast SLAM框架
Fast SLAM 算法優點:采用非線性模型,將高維運算降為低維運算,在計算復雜度、數據關聯等方面具有優勢;缺點是樣本退化、樣本貧化嚴重。
另外,在基于距離傳感器的SLAM 中,還有應用SVD(矩陣奇異值分解)的SLAM 方法。通過激光雷達獲得機器人與障礙物的方向、距離信息,利用SVD獲得路標在全局坐標系和局部坐標系下的關系,完成地圖的更新。將SLAM 問題看成距離信息矩陣SVD 的過程,通過把距離矩陣SVD得到包含有路標信息和機器人位姿的2 個矩陣[22]。該方法優點是不需要線性化模型,能降維處理,具有計算量小、跟蹤性能好,避免了運動模型的偏差和“綁架”問題;缺點是依據實際情況不同會出現病態矩陣。
3.3 地圖的表達方式
基于距離傳感器的SLAM地圖表達方式,典型模式有基于特征的地圖和基于網格的地圖。
基于特征的地圖,表示機器人移動時觀測到的路標和應用路標定位的概率,一般基于路標定位的EKFSLAM建立該特征的地圖比較多。圖3是特征地圖。

圖3 特征地圖
網格地圖表示地圖是否被占用,或者反應的被占用的相關概率。網格地圖比特征地圖更清楚反應環境的實際特征,圖4是2D網格地圖。

圖4 2D網格地圖
3.4 基于距離傳感器SLAM方法性能比較分析
幾種比較典型的基于距離傳感器的SLAM 方法性能比較分析如表1所示。
基于距離傳感器的SLAM方法,是在建立模型的前提下使用概率估計和濾波的方法對機器人位置和運行軌跡估計,這個過程存在事先假定條件,如果假定條件出現偏差或不滿足,將會導致后續估計出現誤差。所以,基于距離傳感器的方法大多計算量大,使用過程中存在局限性,因此導致誤差較大。基于距離傳感器建立的地圖是特征圖或網格圖,對環境表達不直觀,與人類對環境的理解有差距。

表1 基于距離傳感器SLAM方法性能比較
4 基于視覺的SLAM方法
視覺SLAM的處理過程由傳感器信息讀取、視覺里程計(也叫前端)、后端優化(非線性優化)、回環檢測和建圖五個過程組成。圖5是視覺SLAM的流程圖。

圖5 視覺SLAM流程圖
(1)傳感器信息讀取。在視覺SLAM中主要為相機圖像信息的讀取和預處理。如果是在機器人中,還可能有碼盤、慣性傳感器等信息的讀取和同步。
(2)視覺里程計(Visual Odometry,VO)。視覺里程計的任務是估算相鄰圖像間相機的運動,以及局部地圖的樣子,VO又稱為前端(Front End)。
(3)回環檢測(Loop Closing)。回環檢測判斷機器人是否到達過先前的位置。如果檢測到回環,它會把信息提供給后端進行處理。
(4)后端優化(Back End Optimization)。后端接受不同時刻視覺里程計測量的相機位姿,以及回環檢測的信息,對它們進行優化,得到全局一致的軌跡和地圖。由于接在VO之后,所以稱為后端(Back End)。
(5)建圖(Mapping)。它根據估計的軌跡,建立與任務要求對應的地圖。
視覺SLAM在執行上述五個過程中,主要依據關鍵幀技術,采用與關鍵幀的誤差最小的優化方法尋找系統最優的參數值。把目前文獻按在此過程中采用技術的特點,分為三大類:特征點SLAM(或間接法)、直接SLAM 和基于深度學習的SLAM。下面對以上三類中比較典型的幾種方法進行分析。
4.1 特征點SLAM
基于特征點的視覺SLAM利用關鍵幀圖像,每當系統獲取到一幀圖像,首先提取圖像中的特征點,計算每個特征點的描述子,然后通過與前一幀圖像中的特征點進行特征匹配建立起特征點之間的一一對應關系,最后利用匹配的特征點在不同的圖像中的投影結果最小化重投影誤差(Reprojection error)來估計相機的運動。特征點計算幀間相機位姿的原理如圖6 所示,Tk,k-1是k和k-1 時刻兩幀之間的位姿變換。

圖6 特征點計算幀間相機位姿的原理
2015 年,Mur-Artal 等提出了開源的單目ORBSLAM,并于2016年拓展為支持雙目和RGBD傳感器的ORB-SLAM2,它是目前支持傳感器最全且性能最好的視覺SLAM系統之一,也是所有在KITTI數據集上運行結果排名最靠前的一個。ORB-SLAM 延續了PTAM(Parallel Tracking And Mapping)的算法框架[23],增加了單獨的回環檢測線程,采用詞袋(Bag of Words)法進行回環檢測和重定位。
基于詞袋的閉環檢測由四個步驟組成,如圖7所示。

圖7 基于詞袋的閉環檢測流程
(1)數據庫查詢
當獲取一個圖像It時,它將轉換為詞袋矢量vt。在數據庫中搜索vt,生成匹配候選對象<vt,vt1>,<vt,vt2>,…,<vt,vtj> 及與其相關的s(vt,vtj)列表。
然后,用在向量vt的序列中期望獲得的最佳分數對每次獲得的分數進行歸一化,從而獲得一個歸一化的相似性度η:

選擇一個較小的閾值α,對η(vt,vtj)<α的匹配圖像不予選擇。
(2)匹配分組
為了防止在查詢數據庫時時間比較近的圖像之間發生競爭,將這樣的圖像分為一組,并將它們視為一個匹配項。使用符號Ti表示有一定間隔的連續時間組tn1,tn2,…,tnm和用VTi表示一個匹配組,其包含匹配項vn1,vn2,…,vnm。因此,如果tn1,tn2,…,tnm中連續時間之間的間隔很小,則將一組匹配項轉換為單個匹配項計算分值H:

選擇得分最高的組作為匹配項,然后進行后續時間一致性檢測。
(3)時間一致性檢測
在獲得最佳匹配VT′之后,檢查它與前序查詢的時間一致性。
匹配<vt,VT′>必須與K個先前的匹配<vt-Δt,VT1>,<vt-2Δt,VT2>,…,<vt-kΔt,VTk> 保持一致,使得Tj和Tj+1間隔接近交疊。如果通過了時間約束,只保留使得分η最大的匹配 <vt,vt′>(t′∈T′),認為它是一個閉環候選,然后由幾何一致性檢查決定是否最終接受。
(4)幾何一致性檢查
在閉環候選的任何一對圖像之間應用幾何檢查,用RANSAC查找It和It′之間的基本矩陣進行驗證。
ORB SLAM建立了關鍵幀圖以及關鍵幀之間的可見關系圖。如果兩個關鍵幀之間共享相同地圖點(至少15個),則兩個關鍵幀之間存在一條邊,該邊的權重θ為公共地圖點數。每個節點都是一個關鍵幀,關鍵幀之間的可見性信息,表示為無方向的加權圖。關鍵幀、地圖點和可見性圖的表示見圖8[9]。

圖8 地圖表示形式(關鍵幀、地圖點、可見性圖和基礎圖)
在支持雙目和RGBD 傳感器的ORB-SLAM2[10]中,使用g2o 里的 LM(Levenberg-Marquardt)算法,優化相機的運動參數R和t,從而使世界坐標系中已匹配的3D點Xi∈R3和關鍵點之間的重投影誤差最小。
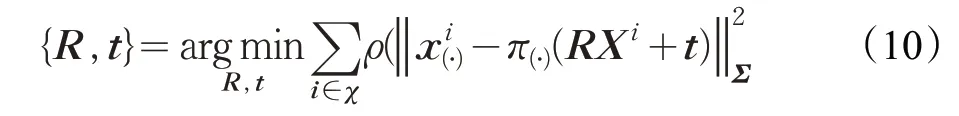
其中ρ是Huber代價函數,而Σ是與關鍵點規模(scale)相關的協方差矩陣。π(?)是投影函數。
BA(Bundle Adjustment,光束法平差)也是應用比較廣泛的圖優化方法,在ORB SLAM 中采用BA 結合g2o,在圖優化中有效地閉合回路,執行位姿圖優化,該位姿圖沿圖分配了閉合誤差。在優化之后,根據能觀察到該點的其中一個關鍵幀的校正來變換每個地圖點。
基于最小二乘的圖優化法g2o,是機器人視覺SLAM 中較常用的圖優化方法。它較其他圖優化方法如性能全面,并且還可以輕松擴展解決其他新問題。
ORB-SLAM 對PTAM 框架中的大部分組件都做了改進,歸納起來主要有以下幾點:(1)ORB-SLAM追蹤、建圖、重定位和回環檢測各個環節都使用了統一的ORB 特征,使得建立的地圖可以保存載入重復利用;(2)得益于可見圖(convisibility graph)的使用,將跟蹤和建圖操作集中在一個局部互見區域中,使其能夠不依賴于整體地圖的大小,能夠實現大范圍場景的實時操作;(3)采用統一的BoW詞袋模型進行重定位和閉環檢測,并且建立索引來提高檢測速度;(4)改進了PTAM只能手工選擇從平面場景初始化的不足,提出基于模型選擇的新的自動魯棒的系統初始化策略,允許從平面或非平面場景可靠地自動初始化。
4.2 直接SLAM
在2011 年,Newcombe[14]提出了基于密度追蹤的實時地圖創建算法DTAM(Dense Tracking And Mapping),開啟了直接法在SLAM中的嘗試。
直接法與特征法不同,直接法不需要進行特征的提取,而是通過最小化兩幀圖像之間的光度誤差(Photometric Error)來估計圖像之間的運動,如圖9 所示。直接法的思路源自圖像光流(Optical Flow)的計算,基本假設是圖像灰度一致性,即同一個空間點在各個圖像中的像素灰度值不變。因此,通過估計得到的位姿變換和深度值可以將圖像投影(Warp)到另一幀圖像的坐標系下,計算此時投影的圖像與原圖差值即為兩幀圖像的光度誤差,通過最小化兩幀圖像之間的光度誤差來估計圖像之間的運動。

其中,D為當前幀對應的深度圖,T2,1為當前幀和相鄰幀之間的位姿變換估計。
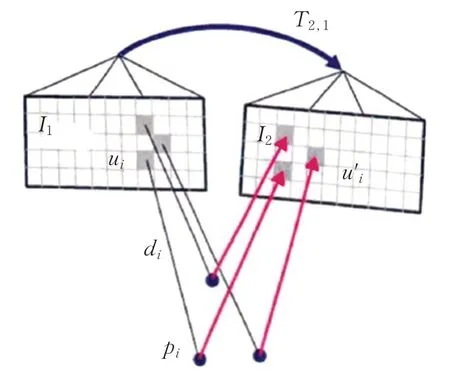
圖9 直接法計算幀間位姿示意圖
DTAM 對特征缺失、圖像模糊有很好的魯棒性,但由于DTAM為每個像素都恢復稠密的深度圖,并且采用全局優化,因此計算量很大,即使采用GPU 加速,模型的擴展效率仍然較低。DTAM 為每個像素都恢復稠密的深度圖,如圖10所示。
2013年,TUM機器視覺組的Engel等人提出了一套同樣也是基于直接法的視覺里程計(Visual Odometry,VO)系統,該系統2014年擴展為視覺SLAM系統LSD-SLAM[15]。
Engel 等在文獻[15]中采用基于深度估計的半密集視覺里程計,通過高斯-牛頓最小化光度誤差來對齊兩個圖像:給出對ξ的最大似然估計量。


圖10 稠密的深度圖
從現有關鍵幀Ki=(Ii,Di,Vi)開始,通過最小化光度誤差的歸一化方差來計算新圖像Ij的相對3D 姿態ξij∈se(3),即

其中:
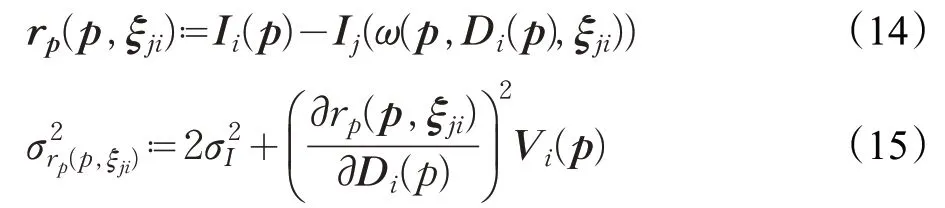
其中,‖ ‖δ是Huber范數

用于歸一化殘差。
LSD SLAM 中采用sim(3)上直接圖像對齊,使用場景深度和跟蹤精度之間的固有相關性來解決在長距離跟蹤上,導致尺度漂移產生的誤差。縮放每個創建的關鍵幀的深度圖,以使其平均逆深度為1,建立最小化總誤差函數為:

在將新的關鍵幀Ki添加到地圖后,將收集許多可能的循環閉合關鍵幀Kj1,Kj2,…,Kjn,使用最接近的十個關鍵幀,檢測大規模的循環閉合。為了避免錯誤插入或錯誤跟蹤閉環,采用相互跟蹤檢查,即對于每個候選幀Kjk,獨立估計相對于關鍵幀Ki的攝像機位姿ξjki和ξijk,僅當兩個估算值在統計上相似時,即如果

足夠小時,才將它們添加到全局地圖中,作為閉環候選。
LSD SLAM 中由位姿圖描述相機位置及移動軌跡。可通過位姿圖優化(pose graph optimization)來對閉環進行優化。如圖11 所示[15]藍色標記是一個個相機位姿,一般由錐形四面體表示,頂點是所采集圖像時相機在世界坐標系中位置,四邊形底面表示此時相機的視平面,相機位姿之間連線用綠色表示。

圖11 描述相機的位姿圖
LSD-SLAM 中是由一組關鍵幀和跟蹤的sim(3)約束組成的地圖,使用最小化的誤差函數對其進行圖優化,最小化的誤差函數為(W定義為世界坐標):

ξji是關鍵幀i和j的相對位姿。
LSD-SLAM 隨機從位姿圖中選擇一個具有兩個以上相鄰關鍵幀的關鍵幀,并試圖將當前幀與它進行匹配,如果外點/內點比率較大,那么丟棄該關鍵幀,重新隨機選擇;否則接著測試所有與它相鄰的關鍵幀,如果相鄰的關鍵幀中內點/外點比率較大的關鍵幀數多于外點/內點比率較大的關鍵幀數,或者存在多于五個的內點/外點比率較大的關鍵幀,那么選擇內點/外點比率最大的關鍵幀進行跟蹤,重定位成功。
該算法允許構建大規模、一致的環境圖。除了基于直接圖像對齊的高精度姿勢估計之外,還可以實時重建3D 環境為具有相關的半稠密深度圖的關鍵幀的位姿圖。在sim(3)上運行具有尺度漂移意識的直接跟蹤方法,并可將深度值的噪聲影響納入跟蹤。與DTAM 相比,LSD-SLAM僅恢復半稠密深度圖且每個像素深度獨立計算,因此能達到很高的計算效率。
4.3 典型視覺SLAM方法性能比較分析
基于視覺SLAM的幾種典型方法工作機制、優缺點和適用場合等比較,如表2所示。隨著計算機處理速度的提升,基于視覺傳感器的SLAM實時性和準確性大大提高,目前已達到無人車城市道路實時應用的水平。由于視覺傳感器采集信息豐富、使用方便、價格便宜,構建的環境地圖接近人眼所見的真實環境,所以視覺SLAM將是未來的主流應用技術。
4.4 基于深度學習的視覺SLAM
隨著計算機數據處理量的提升以及深度學習技術的發展,國內外學者發現將深度學習技術應用到SLAM中,將會給SLAM技術帶來巨大革命。目前在SLAM中可以利用深度學習技術閉環檢測、實時估計相機位姿、特征點檢測和描述、構建語義地圖等。
4.4.1 深度學習在閉環檢測上的應用
目前深度學習在閉環檢測上的應用可分為兩大類,一類是利用深度學習模型提取圖像特征進行閉環檢測;另一類是提取環境語義信息,利用語義節點匹配。
(1)利用深度學習模型提取圖像特征進行閉環檢測
深度學習在閉環檢測上的應用,主要是通過使用深度學習模型提取圖像特征,并使用相似度矩陣檢測閉環。經過特征提取后得到的特征向量在經過相似度計算后可以判定為擁有相同的圖像特征,來證明兩幅圖像擁有相似的內容。
Chen等人[24]首次提出在閉環檢測上基于CNN的位置識別技術。Hou 等人[25]利用Caffe 框架下的AlexNet模型提取特征,Sunderhauf 等人[26]利用 Image Net 數據庫對基于Caffe框架的AlexNet模型進行預訓練,提高其在閉環檢測方面的優勢,Li等人[27]提出了基于雅可比神經網絡(fast Neural Network,NN)的Fast SLAM 算法來處理觀測誤差和SLAM線性化誤差,都取得了較好的效果。

表2 典型視覺SLAM方法性能比較
文獻[28]提出基于無監督棧式卷積自編碼(CAEs)模型的特征提取方法,運用訓練好的CAEs 卷積神經網絡對輸入圖像進行學習,將輸出的特征應用于閉環檢測。與傳統的BoW 方法相比,能夠有效降低圖像特征的維數并改善特征描述的效果,可以在機器人SLAM閉環檢測環節獲得更好的精確性和魯棒性。
(2)構建語義節點特征匹配
文獻[29]利用YOLOv3 目標檢測算法獲取場景中的語義信息,以基于密度的帶有噪聲的稀疏聚類DBSCAN(Density-Based Spatial Clustering of Application with Noise)算法修正錯誤檢測和遺漏檢測,構建語義節點,對關鍵幀形成局部語義拓撲圖。利用圖像特征和目標類別信息進行語義節點匹配,計算不同語義拓撲圖中對應邊的變換關系,得到關鍵幀之間的相似度,并根據連續關鍵幀的相似度變化情況進行閉環的判斷。目標聚類有效地提高了室內場景下的閉環檢測準確性,與單純利用傳統視覺特征的算法相比,能夠獲得更加準確的閉環檢測結果。
4.4.2 深度學習估計相機位姿
文獻[30]根據單目視覺傳感器采集的圖像,實時估計相機位姿,實現了單目相機實時六自由度重新定位。系統訓練一個卷積神經網絡,以端到端的方式從單個RGB 圖像中回歸六自由度相機的姿態,而無需其他工程或圖形優化,該算法可以在室內和室外實時運行。
4.4.3 深度學習應用于特征點檢測全過程
文獻[31]采用深度網絡實現了完整的特征點檢測、方向估計和特征描述全部處理過程。以往的研究工作只能成功地單獨解決一個問題,該文獻展示了如何在保持端到端的差異性的同時以統一的方式完成這三個問題,與傳統方法比較取得了較好的效果。
隨著深度學習[32]、語義理解[33]和SLAM 技術的發展[34],未來三者結合基于語義地圖指導機器人進行定位和自主運行將是視覺SLAM的發展方向。
5 SLAM技術實現的難點和未來發展的方向
5.1 SLAM技術實現的難點
SLAM 是多學科多算法組合,它包含圖像處理技術、幾何學、圖理論、優化和概率估計等學科的知識,需要扎實的矩陣、微積分、數值計算知識,SLAM與使用的傳感器和硬件平臺也有關系,研究者需要具備一定的硬件知識,了解所使用的傳感器的硬件特性。所以,根據不同的應用場景,SLAM研究者和工程師必須處理從傳感器模型構建到系統集成的各種實踐問題[35]。從前面章節的分析可以看出,SLAM的各個環節用到的技術是偏傳統的。與當前大熱的深度學習“黑箱模型”不同,SLAM 的各個環節基本都是白箱,能夠解釋得非常清楚。但SLAM卻并不是上述各種算法的簡單疊加,而是一個系統工程。
比如SLAM需要平衡實時性和準確性,SLAM一般是多線程并發執行,資源的分配、讀寫的協調、地圖數據的管理、優化和準確性、關鍵參數和變量的不確定性以及高速高精度的姿態跟蹤等,都是需要解決的問題。
SLAM還需要考慮硬件的適配,SLAM的數據來源于傳感器,有時是多個傳感器融合,傳感器的質量對SLAM的效果影響很大。例如,如果SLAM使用的相機圖像噪點非常多,那么就會對姿態跟蹤產生不好的影響,因為特征點提取會很不一致;再比如在VIO系統中,如果相機和IMU 的時間戳不一致(至少毫秒級),也會影響算法精度甚至算法失敗。多個傳感器的分別校準和互相校準,乃至整個系統眾多參數的調整,都是非常耗費時間的工程問題。
由于產品和硬件高度差異化,而SLAM相關技術的整合和優化又很復雜,導致算法和軟件高度碎片化,所以市場上目前還沒有一套通用普適的解決方案。
5.2 視覺SLAM主要發展趨勢
SLAM 未來的發展趨勢有兩大類:一是朝輕量級、小型化方向發展,讓SLAM能夠在嵌入式或手機等小型設備上良好運行,然后考慮以它為底層功能的應用,比如手機端的AR和無人機SLAM等。在這些應用中,不希望SLAM占用所有計算資源,所以對SLAM的小型化和輕量化有非常強烈的需求。另一方面則是利用高性能計算設備,實現精密的三維重建、場景理解等功能。在這些應用中,本文目的是完美地重建場景,而對于計算資源和設備的便攜性則沒有多大限制,由于可以利用GPU,這個方向和深度學習也有結合點。
5.3 SLAM技術未來的研究熱點
(1)多傳感器融合SLAM
相機能夠捕捉場景的豐富細節,而慣性測量單元(Inertial Measurement Unit,IMU)有高的幀率且相對小地能夠獲得準確的短時間估計,這兩個傳感器能夠相互互補,從而一起使用能夠獲得更好的結果。
最初的視覺與IMU結合的位姿估計是用濾波方法解決的,用IMU的測量值作為預測值,視覺的測量值用于更新。
上述文獻分析已證明在準確性上基于優化的視覺SLAM優于基于濾波的SLAM方法。
實際的機器人和硬件設備,通常都不會只攜帶一種傳感器,往往是多種傳感器的融合。比如機器人除了視覺傳感器,還通常具有激光雷達、里程計、IMU 等,手機除了攝像頭,也帶有IMU、磁力計等傳感器。融合多種傳感器的信息對于提高SLAM 系統的精度和魯棒性有著重要的意義。比如目前手機上的VIO的研究,它將視覺信息和IMU 信息融合,實現了兩種傳感器的優勢互補,為SLAM的小型化與低成本化提供了非常有效解決方案,取得了良好的效果。
(2)語義SLAM
SLAM的另一個方向就是和深度學習技術結合[36-37]。到目前為止,SLAM的方案都處于特征點或者像素的層級。人們對于這些特征點或像素到底來自于什么東西一無所知。這使得計算機視覺中的SLAM 與人類的做法不怎么相似,至少人類自己從來看不到特征點,也不會去根據特征點判斷自身的運動方向。看到的是一個個物體,通過左右眼判斷它們的遠近,然后基于它們在圖像當中的運動推測相機的移動。SLAM 和語義的結合點主要有兩個方面:
一是語義幫助SLAM。如果有了物體識別的語義信息,就能得到一個帶有標簽的地圖,物體信息可為回環檢測、BA優化帶來更多的條件。
二是SLAM 幫助語義。物體識別和分割都需要大量的訓練數據。要讓分類器識別各個角度的物體,需要從不同視角采集該物體的數據,然后進行人工標定,非常辛苦。而SLAM 中,由于可以估計相機的運動,可以自動地計算物體在圖像中的位置,節省人工標定的成本。如果有自動生成的帶高質量標注的樣本數據,能夠很大程度上加速分類器的訓練過程。
(3)SLAM算法與硬件的結合
此外,未來的SLAM技術將會越來越注重算法和硬件的深度結合,專用處理器(如HoloLens HPU)和一體化功能模組(如Tango模組)也是未來的發展方向,這將會大大降低現有硬件平臺的計算能力瓶頸和算法調試門檻,帶給用戶更流暢的體驗。
(4)SLAM算法與深度學習的結合
隨著深度學習在計算機視覺領域的大成功,大家對深度學習在機器人領域的應用有很大的興趣。SLAM是一個大系統,里面有很多子模塊,例如閉環檢測、立體匹配等,都可通過深度學習的使用來獲得更優的結果。
6 結論
本文從SLAM產生到目前最新的前沿主流技術,按機器人SLAM 技術常用的距離傳感器和視覺傳感器兩大類進行綜述。分別對這兩類輸入信號對應的SLAM主流技術,從技術框架、主要研究內容、優缺點及適應的場景等性能做了分析,并對目前最新技術、未來的研究熱點做了介紹,預示了SLAM與深度學習和語義結合的未來發展方向。
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
河南科技(2014年23期)2014-02-27 14:19:15
