融合語義激光與地標信息的SLAM技術研究
2020-09-15 04:48:18何煒婷
計算機工程與應用 2020年18期
楊 爽,曾 碧,何煒婷
廣東工業大學 計算機學院,廣州 510006
1 引言
重定位是指由于外界因素的影響,移動機器人會丟失其實際位置,需要重新定位以修正其錯誤位姿,依賴即時定位與地圖構建(SLAM)技術中定位算法的自適應能力。目前在SLAM 的實際應用中包含多種定位算法。比如Hanten[1]和Wang 等人[2]提出的自適應蒙特卡羅定位算法,對傳統基于粒子濾波原理的蒙特卡羅定位算法[3]耗時較長、應用環境單一等缺陷進行改進,提高了它們在定位過程中的自適應能力。但其對里程計(記錄速度、位移等運動量的相關方法)信息依賴程度過高,觀測靈敏度也不夠。在變化頻繁的動態環境中,碰到位置漂移,機器人定位被劫持這些意外情況時,該類算法的容錯性并不高,定位仍存在問題。文獻[4-5]則是針對SLAM中的掃描匹配過程進行了改進,不僅減少了觀測匹配和位姿估計的時間,還降低了算法對環境特征的依賴,但由于其基礎算法本身易受環境因素的影響,在特征稀少的動態場景中,重定位效果依然不好。
目前基于深度圖像信息的視覺SLAM 方法發展迅速,見文獻[6]。本文依賴地標物體準確的位置信息來進行重定位,而在視覺SLAM算法[7]的研究應用中,已經有很多學者提出了把地標作為參照物,用來修正機器人位姿的算法,如主流的ORB-SLAM[8]和LSD-SLAM[9]算法。除此之外,Frintrop等人在文獻[10]中提出的位姿圖優化算法,以及地標的自動識別與配準方法[11],都是在區域內人為使用(設定)少量的地標,豐富該區域的特征信息進行圖優化,提高匹配對比的準確性,達到優化定位精度的目的。因為對于這類算法,觀測信息越可靠,位姿估計也就更加準確。
這些利用地標信息的視覺SLAM 算法均能通過后端優化來重新修正錯誤位姿。一些方法[12-14]在此基礎上引入了IMU傳感器,進行數據融合,把視覺和慣性測量信息緊密耦合在一起,就能進一步提高定位精度,縮小偏差。但從長遠的趨勢上來看,機器人的位姿漂移現象仍然存在。所以張玉龍等人基于此在文獻[15]中提出了一種閉環檢測算法,用于修正位姿漂移,重新找回初始定位。Kasyanov等人也提出了一種KBV(IKey frame Based on Visual Inertia)算法[16],在整個SLAM過程中,采用閉環檢測方法,在過去的關鍵幀中找到與當前關鍵幀的最佳匹配,以此來優化機器人的運動軌跡,不僅如此,在機器人丟失位置之后,也能通過這種關鍵幀匹配方法重新定位。該算法的重定位性能良好,但由于使用的視覺傳感器在獲取深度和角度信息時,易受光線、觀測方位等多方面因素影響,位姿修正結果往往不如人意。
2018 年,Zhang 等人[17]專門為環境信息中的地標提出了一種概念——設立及識別自然地標,并建立自然地標庫。通過對地標圖像進行特征檢測與匹配,完成對自然地標的準確識別,從而達到提高機器人定位精度的目的。
機器人在室內環境中導航,基于多傳感器數據融合的SLAM 技術[18]是目前較為熱門的研究方向。激光信息測距十分準確,而視覺傳感器獲取的圖像信息則更為豐富,為了結合兩種數據的特性,本實驗室曹軍等人在文獻[19]提出了一種將離散的激光點聚類成激光簇的方法(本文將該算法簡稱為C-Clustering),用于加強環境特征,縮小了重定位的檢測范圍,在文獻[20]中提出了一種視覺信息與激光數據融合的方法(本文將該算法簡稱為C-Fusion)。通過這兩種方法可以給激光數據賦予語義標簽,因而本文利用此研究基礎,在SLAM 過程中,基于語義激光數據和地標物體提出了一種重定位方法(Relocation based Semantic Laser and Landmark Information,RLSLALI),該方法借助激光感知與視覺識別融合后的語義激光信息,結合地圖環境中的地標物體搭建地標數據庫,建立位姿轉化模型,修正機器人錯誤定位。在室內動態場景中,其定位健壯性高,可在標準硬件設備上正常運行且不易受環境等因素影響。
2 一種基于語義激光與地標信息的機器人重定位算法
人類在日常行車過程中,即使有全球定位工具,在經過一些復雜、偏僻的路段時,依然容易迷失,往往需要借助路邊的指示牌或者標志性建筑物來確認自身所處位置。由此,本文提出一種利用語義激光及地標信息進行重定位的方法,用激光傳感器獲取距離、位置等定量信息,而分類、名稱等語義信息則使用視覺傳感器得到。這樣既避免了由于激光數據太相似導致的誤識別與誤匹配,又能減少光線、角度等影響視覺檢測的因素所帶來的數據誤差,適合室內動態環境。算法整體結構見圖1。
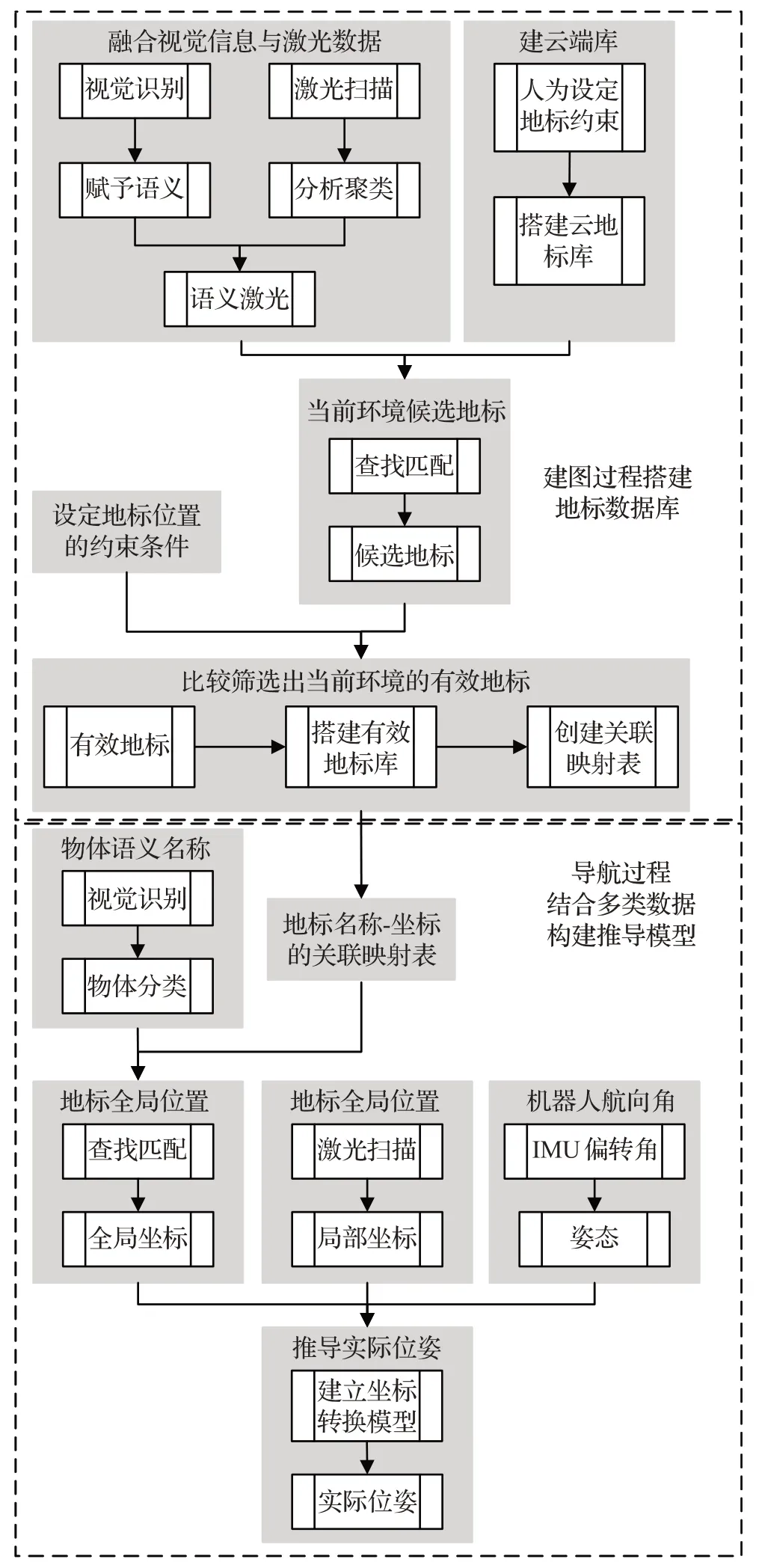
圖1 重定位算法結構圖
2.1 搭建地標數據庫系統
2.1.1 云地標庫的建立
本文之所以提出建立地標數據庫,是因為并不是所有的物體都能設為地標,要依賴相關權限進行授權。而云地標庫就相當于授權者、各機器人在不同的環境中,均可通過查找匹配云地標庫中的數據內容,初定當前環境中的候選地標,所以也可將云地標庫稱作候選地標庫。在構建云地標庫的過程中,最為關鍵的部分就是篩選條件的設定,用于判斷物體是否有成為地標的資格,設定原則如下:
(1)物體的圖像特征要明顯,如色彩鮮艷、樣式豐富等,或自身就具有可辨識的標志。
(2)物體形狀盡量扁平化,就能保證在多個角度識別到地標時,也不會存在明顯的位置偏差;如果是形狀或位置會變化的物體,則拒絕,以此保證基礎數據的準確性。
基于此,在本文的實驗測試中,在云地標庫中錄入了兩大類物體,一種是類似于高速公路上指示牌,一種是貼在墻壁上的壁畫。可將本文地標數據庫系統表示為圖2。
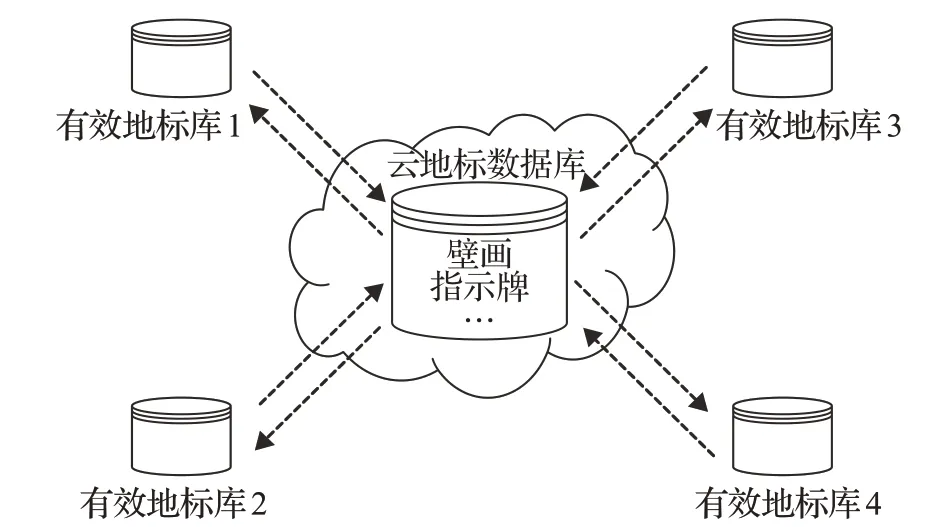
圖2 地標數據庫系統
2.1.2 有效地標庫的建立
在建圖過程中,通過查找云地標庫中的數據內容,可在識別出的物體中篩選出候選地標。但這樣還不夠,除云地標庫外,還需建立多個有效地標庫,見圖2。那是因為通過云地標庫篩選出的候選地標,很難達到算法的實際要求,需要針對每個運行場景,單獨成庫,利用各候選地標的相對位置關系進行判斷,篩選出在當前環境下可用的地標物體。
相對位置關系的約束條件設置為:
(1)地標的位置盡量挑選在不常訪問的地方(靠墻或者角落等)。
(2)如果一個地圖環境中存在多個地標,則各個地標的位置不能太過稠密,要分散選擇,盡量做到地圖環境的全覆蓋。
這樣便可初步建立有效地標庫,再結合2.2.1 小節融合視覺信息與激光數據的方法,獲取每個地標物體在地圖上的位置坐標,就能順利完成有效地標庫的搭建,詳見2.2.2小節。
2.2 創建地標名稱與位置坐標的關聯映射表
建圖過程中,本文算法在融合激光感知與視覺識別的基礎上,根據地標庫系統的約束條件,篩選并確定當前環境中的可用地標;在有效地標庫中創建地標名稱與全局位置坐標的關聯映射表。對應流程見圖3。
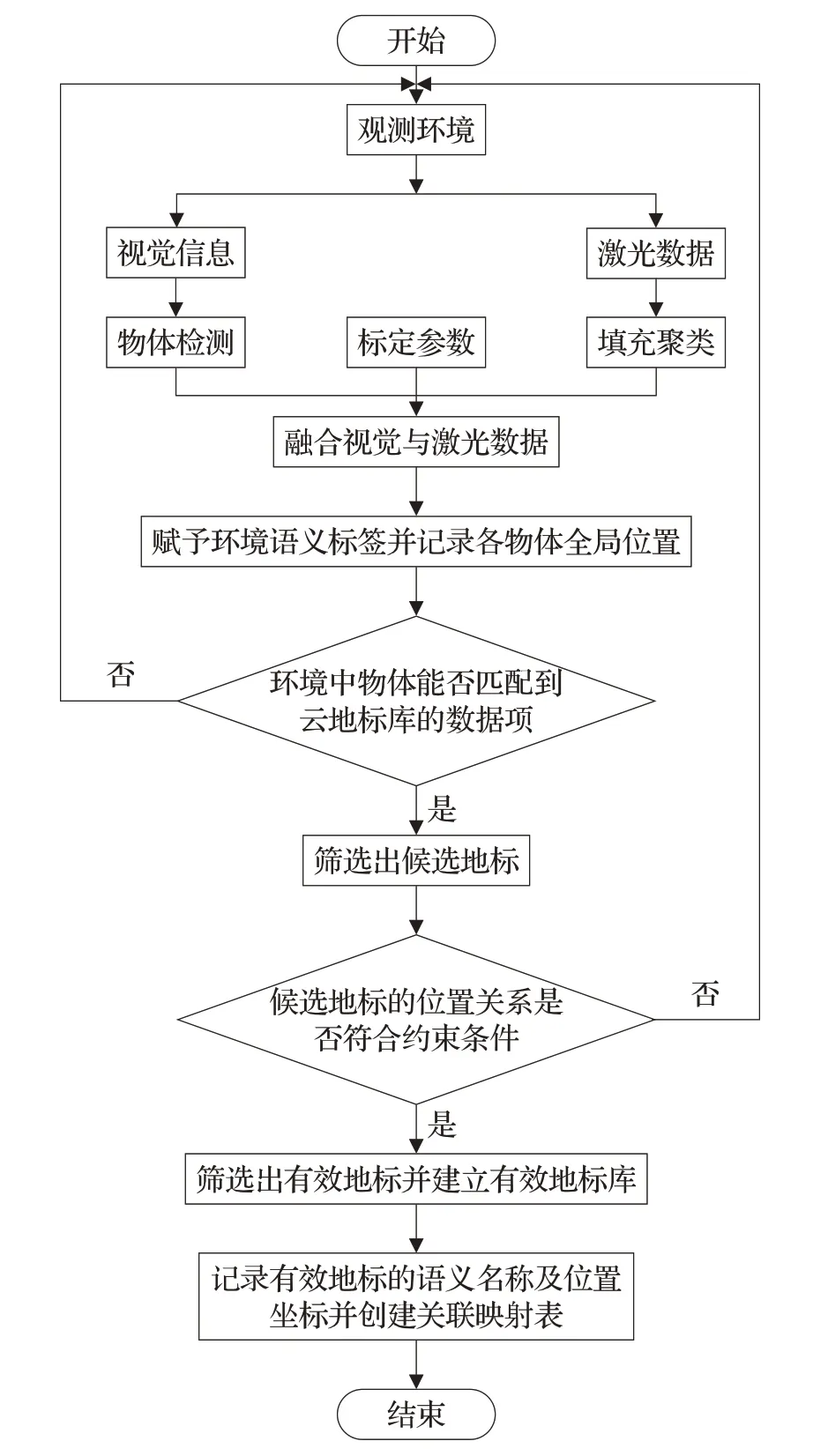
圖3 創建映射表流程
2.2.1 融合視覺信息與激光數據
首先通過C-Clustering 算法對激光數據進行聚類,可得到每個激光掃描點的聚類標簽,對應每個掃描點的類別信息為{c1,c2,…,cn} ,由于激光雷達的工作原理是在極坐標系下每隔一定角度(角度分辨率)θ發射和接收激光信息,獲得測量距離d,假設所使用的激光傳感器每幀測量數據包括了n個掃描點,則激光雷達數據可用公式(1)表示,L中每個元素 (θi,di)表示第i個激光掃描點在激光雷達極坐標系下的角度和距離。
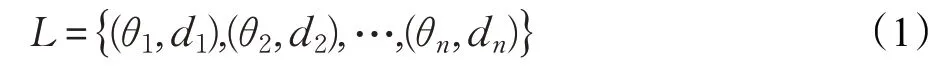
通常激光掃描點的信息可以轉換到直角坐標系(2)下表示,D中每個元素表示第i個激光掃描點的笛卡爾坐標,其中l 代表local,是指以激光雷達中心為原點構建的局部坐標系。

接著根據C-Fusion 算法給聚類激光與物體語義進行融合,賦予每個激光掃描點語義標簽。同一類的激光數據可聚類成一個激光簇,對于每個激光簇j,將對應物體的標簽及標簽概率賦予激光簇內每個激光掃描點,所以激光掃描點可能存在多個標簽及標簽概率。最終聯合可得式(3):
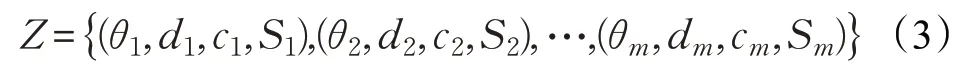
其中,Sj={(li,p′ij):p′ij >0}。li表示第i個物體的標簽,p′ij表示第j個激光簇屬于視覺檢測結果中第i個物體的概率。
在此過程中,利用YOLOv3算法獲取地標等物體的語義信息。通常情況下,當運行環境中存在較多符合云地標庫約束的物體時,僅通過coco公開數據集預訓練好的模型便可完成物體的識別分類,實現成本相對較低。但是當環境中的物體較少且具有特殊性,或者重復物體過多時,信息的獲取難度加大,此時視覺檢測模型的性能并不能滿足本文算法的需求。為了保證機器人在運行過程中,能夠穩定獲取準確的基礎數據,首先要確保視覺識別的有效性。所以就需要針對當前運行環境,進一步訓練調優視覺檢測模型。該部分的前期工作大致可分為三步。第一步是要添加當前環境對應的目標檢測數據集,并對它們進行數據增強。這一步尤其重要,首先在距離遠近、背景簡單與復雜、亮度高低這幾種條件下對環境中的物體實拍400(50×2×2×2)樣張圖片。緊接著使用工具程序對這400張圖片進行隨機類型(增強類型有調節飽和度、亮度、對比度、左右翻轉、旋轉0~30°等)的數據增強。對整個樣張集反復增強5次,得到包含2 000張圖片(400×5)的有效數據集,通過這些數據的訓練,就能降低識別過程中隨機性的影響;第二步是結合實際環境中的物體,在視覺檢測模型中重新設定分類(以本文實驗為例,雖然有多個指示牌,但是本文將其分為指示牌1 類、指示牌2 類等);第三步則是要利用k-means函數根據第一步得到的數據集計算出9種類型的初始候選框尺寸,以此提高識別準確率。然后自行確定檢測模型中幾個基本參數的初始值(學習率、衰退率等)。基于此,便可利用該有效數據集,繼續訓練模型,達到算法適應特殊環境的目的。而激光數據的獲取相對簡單,通過激光雷達掃描周圍環境,并獲取環境中各物體的位置信息。基于此,經過以上方法,即可完成視覺檢測結果與激光雷達信息的融合,產生語義激光數據。語義激光數據Z中每個元素不僅包含原始激光掃描點位置信息,還包含聚類標簽和物體標簽及其對應的標簽概率,模擬運行過程見圖4。
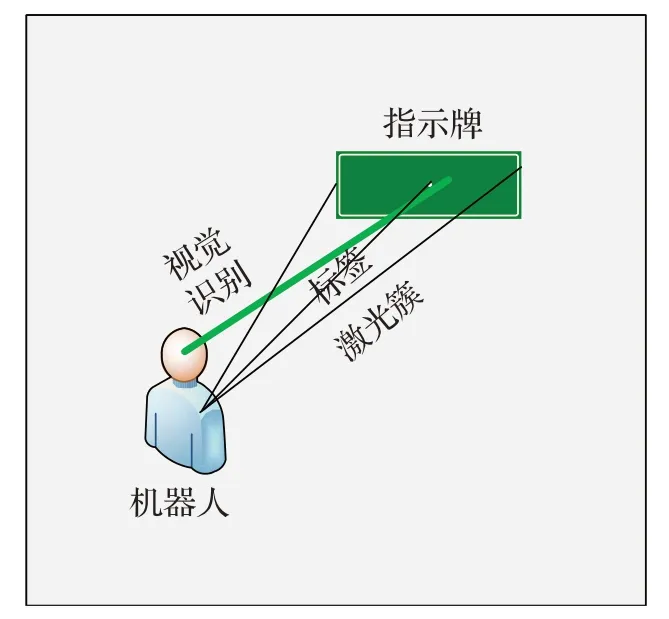
圖4 賦予地標語義標簽示意圖
2.2.2 設置有效地標
采用以上融合方法可得到場景中物體的語義激光數據,因此本文利用該方法設置有效地標(既能識別出地標的分類,又能記錄其對應的位置信息)。這樣機器人在后續的導航過程中,就可依賴準確的地標信息來修正自身位姿偏差。在2.2.1 小節的融合過程中,通過標定參數使相機和激光雷達的探測范圍一致。激光聚類,可使識別出的每一個物體都對應一束激光簇,一束激光簇中又包含多個激光數據點,對應多個位置坐標,而同一個物體又無法用多個坐標定位,所以C-Fusion算法中有個特定的約束,選取激光簇中心激光點記錄的坐標代表對應物體的位置,視覺識別出的物體分類信息也就可以看做是其中心激光點的語義標簽。所以利用式(3)和SLAM 技術中gmapping 建圖算法將各物體相對激光雷達的局部坐標轉換成當前地圖的全局坐標。同時獲取物體的語義標簽及標簽概率,將每個物體的標簽結合它的標簽概率與2.1節建立的云地標數據庫中的數據內容匹配對比出候選地標,再根據各候選地標在運行場景中的位置約束,自適應地確定當前環境中最終可使用的地標物體,并存入有效地標庫,作為用于修正錯誤定位的有效地標。所以在位姿轉換模型中,可將每個地標物體看作一個點,一個語義名稱對應一個坐標點,聯合可推得下式:
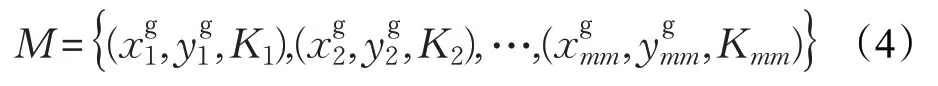
其中,g 代表global,是指以世界地圖中心為原點構建的全局坐標系;mm表示當前環境包含有效地標的數量,表示第mm個地標在全局笛卡爾坐標系下的橫坐標,表示其縱坐標,Kmm表示第mm個地標的語義名稱。
由此,可在有效地標數據庫中通過式(4)創建地標名稱和地標全局位置坐標的關聯映射表,見表1。

表1 地標名稱與位置坐標的關聯映射表
在后續修正定位的過程中,與此部分一致,機器人可能會從不同視角、方位觀測到地標物體,但不論哪種情況,只要能識別出地標的語音名稱即可,具體進行位姿推導時,是將每個地標物體當作地圖上的一個點,獲取其全局位置和局部位置,不受機器人觀測位置和觀測角度的影響,滿足實際情形中可能會遇到的各類情況,詳見2.4節。
這部分的研究工作是為了在當前構建的地圖上設置地標物體,搭建有效地標庫,并給這些地標賦予語義名稱,同時記錄其(其中心激光點)在地圖上的全局坐標,創建地標名稱-位置坐標的關聯映射表,為位姿推導模型提供數據支持。傳統方法中,通常是人為設定地標物體,不僅需要花費大量的人力、時間成本去完成設置,還需要在算法中預先輸入地標位置的定值、可變性差,前期準備工作繁瑣。而通過本文方法搭建地標庫,僅需要針對運行環境,完成視覺檢測模型訓練調優的前期工作,機器人便可根據各類條件自主設定地標,并將相關信息在算法中動態更新,即使地標發生改變,也能通過重新建圖自主更新地標庫。不僅如此,所有使用者還能為云地標庫提供負反饋,提交庫中缺少的地標種類,讓本文算法自適應各類實際運行環境。
2.3 獲取各類數據
2.3.1 獲取地標物體的全局坐標
由上可知,完成地圖與有效地標庫的建立工作后,利用式(4)創建的映射表可以直接得到地標物體在地圖上的全局坐標,但是在映射表中可能存在多個地標物體,不能盲目地選擇一個用于求解,必須要讓機器人認清周圍是哪個地標,所以必須通過地標名稱來篩選查找。
模擬人類用眼睛分辨物體信息,本文基于視覺傳感器,采用目前主流的深度學習方法進行視覺識別,得到被識別物體的語義信息。比較各種物體檢測算法,發現它們在實時性和準確率這兩方面不能同時滿足本文需求。由于機器人在導航時處于運動狀態,對運算實時性要求較高,所以在此優先考慮了YOLOv3-Tiny 檢測模型,經過實驗驗證,在運動過程中,YOLOv3-Tiny雖然識別物體速度能達到本文需求,但正確率較低,特別是在復雜環境下識別較遠位置的地標時,檢測效果很不理想。
針對以上問題,本文在YOLOv3-Tiny物體檢測模型研究的基礎上提出了Acc-YOLOv3(Accurate YOLOv3)算法。首先,由于YOLOv3-Tiny只有13×13特征尺寸圖(對應候選框為(116×90),(156×198),(373×326))和26×26 特征尺寸圖(對應候選框為(30×61),(62×45),(59×119))兩種特征圖尺寸。所以在其基礎上加上52×52特征尺寸圖(對應候選框為(10,13),(16,30),(33,23)),來增加遠距離小物體識別的正確率。原理見圖5,特征圖尺寸越小,對應候選框越大,識別的是較大目標;特征尺寸圖越大,對應候選框越小,識別的是較小目標。例如:圖5(a)與(b)是較小的特征尺寸3×3 和對應較大的候選框;圖5(c)與(d)是較大的特征尺寸6×6 和對應較小的候選框。所以,加上52×52 特征尺寸圖(對應候選框為(10,13),(16,30),(33,23)),可以提高小目標物體的識別正確率。

圖5 候選框選擇原理示意圖
加入了52×52 特征尺寸圖后,檢測速度基本不變,但準確率并沒有達到期望效果,反而還有些許下降。分析整體架構可知,其提取特征的基礎網絡層數太少太淺(一共15層),導致用來提取52×52特征尺寸圖候選框的網絡層太靠近輸入端,即候選框中采用的52×52特征尺寸圖所在的網絡層太淺(第7 層),提取的細粒度還不夠,特征還未被提取完就進行識別,導致準確率下降。
所以,參考Darknet19,進一步把YOLO3-Tiny 的基礎網絡在其基礎上分別增加一層52×52和兩層26×26尺寸的卷積層,見圖6,加強特征提取。
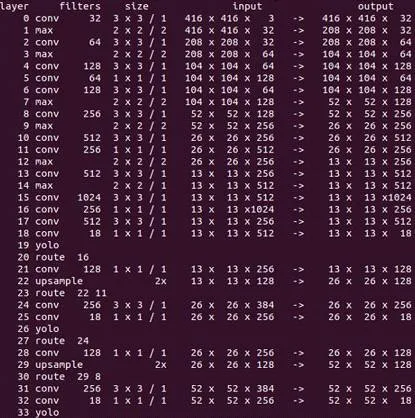
圖6 增加卷積層示例
經過實驗測試,識別準確率提升到85%以上,識別響應時間基本沒受影響,只增加了0.01 s左右,效果可達到本文需求。
基于此,可獲取當前運行環境的各物體語義,再通過語義信息查找匹配有效地標庫,則可得到地標物體在世界地圖上的全局坐標。
2.3.2 獲取地標物體的局部坐標
為保證數據來源的準確性,本文RLSLALI 算法使用激光雷達獲取地標的局部坐標,避免視覺傳感器受光線等環境因素的影響產生偏差。將激光雷達與機器人的安裝位置統一,并且在算法中確定了它們的相對關系之后,激光雷達所建立的局部坐標系就與機器人的基坐標系保持一致。
以本文實驗所用的rplidar-a2 激光雷達為例,雷達掃描激光數據點間隔設置為0.5°(分辨率),掃描范圍設置為正前方的180°,可掃描361個數據點。而雷達的測量數據點是按角度順序排列的,可知第i個地標物體激光簇中心點對應的第j個數據點在以雷達為中心的極坐標系中的角度θj為:

見圖7,假定Ri是機器人附近的第i個地標,對應的第j個激光點,根據激光雷達測距及式(1)可知第i個地標物體在局部坐標系下的笛卡爾坐標為:

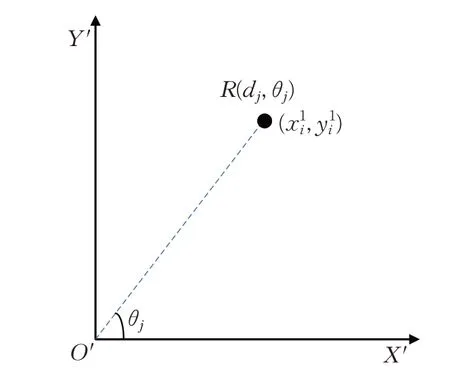
圖7 以機器人為原點的局部坐標系及其位置關系
2.3.3 獲取機器人的偏轉角
IMU(慣性測量單元)是一種記錄加速度、角速度等運動量信息的工具,其中包含的陀螺儀可以記錄機器人運動的轉動速度及航向角,但是其值很容易受其他因素的影響,不同環境下的同一個陀螺儀測量值都相差甚大,所以必須針對當前使用場景,對所使用的IMU進行校正標定,使其適配環境。標定完成后,IMU 計算出來機器人偏轉角精度高,且健壯性好,因此本文采用IMU作為一種數據源來獲取機器人的偏轉角α。
2.4 創建位姿推導模型
2.4.1 構建全局坐標與局部坐標的轉換關系
導航過程中,當機器人位姿估計產生偏差時,本文RLSLALI算法的理念是以準確的地標信息推算機器人的實時位置,所以必須要在世界坐標系中,建立地標全局位置、地標局部位置及機器人實時位置相互轉換的數學模型,圖8給出了全局坐標系與局部坐標系的相對關系以及其中的位置坐標轉換。圖8 中O為世界地圖(全局坐標系)的原點。O′為機器人的實時位置,以其為原點構建一個局部坐標系。其中位置關系轉換的計算信息如圖8中標注,α為機器人相對全局坐標系的偏轉角,機器人的實時位置坐標設為(x0,y0),通過轉換關系可推得:

其中,lx1,lx2,ly1,ly2可根據地標R的局部坐標以及角度α推導而得,可將轉換關系式整理為:
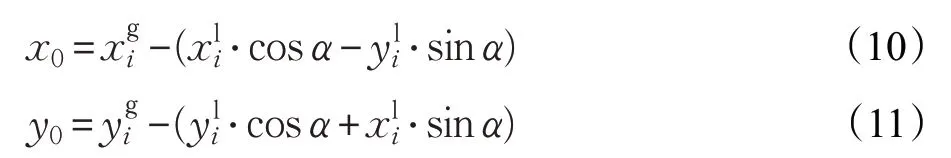
其中,地標相對于全局坐標系的位置坐標,可根據視覺識別結果查找地標名稱-位置坐標映射表得到,地標相對于局部坐標系的位置坐標,可根據式(6)、(7)推得。
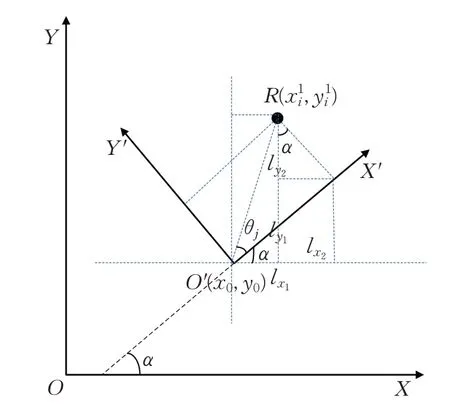
圖8 相對坐標系及各位置坐標轉換模型
2.4.2 修正位姿偏差完成重定位
由2.4.1 小節中的式(10)及式(11)理論上可推算機器人當前位姿,圖8 給出的是第一象限的坐標轉換關系。但是由于實際情況的多樣性,比如考慮到機器人及地標物體不可能只處于坐標系的第一象限,機器人有可能運動到全局坐標系的其他象限,地標物體也有可能在機器人局部坐標系的其他象限,所以分析各類場景中的不同情況,可排列組合出64種情況,對每種情況進行推導驗算,并完成多組實驗測試與分析,可將機器人實際位置的推導式總結為:
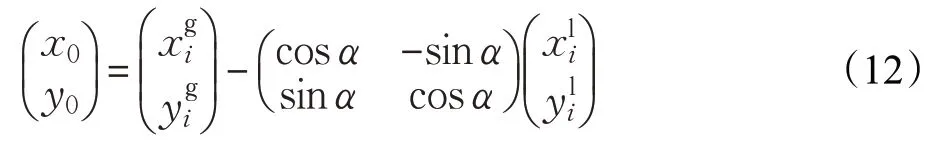
通過本文提出的算法,根據多類傳感器數據及地標物體信息,可以快速準確地推算出機器人的實時位置坐標(x0,y0)及它的航向角α,從而修正其位姿偏差,完成重定位。機器人修正其錯誤定位的過程可見示意圖9。
綜上,本文算法只需要輸入視覺信息與激光數據,就能借助地標物體,完成正確位姿的推導,修正其錯誤定位。偽代碼如下:
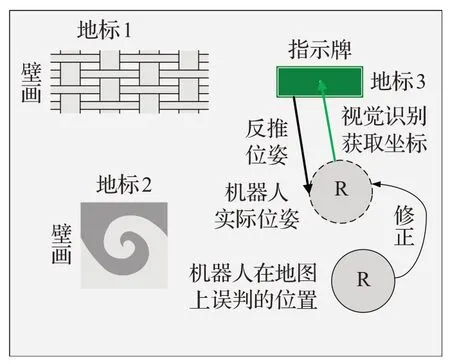
圖9 機器人利用地標修正位姿示意圖

3 實驗分析
3.1 實驗平臺及實驗環境的搭建
為了驗證本文RLSLALI 算法的有效性及創新性,搭建了相應的實驗平臺及實驗環境,見圖10。本文的實驗平臺是由PC、相機、激光雷達、IMU 和移動底座這幾部分組成。采用ROS 機制下的通信方式進行數據傳輸,主要算法由PC決策運行。

圖10 實驗平臺及實驗環境
其中相機為kinect v1,分辨率:640×480;PC的CPU為i7-8750H,顯卡為GeForce GTX 1060;移動底座為Kobuki;IMU為L3G4200D型號的3軸數字陀螺儀;激光雷達為RPLIDAR A2,測距分辨率可達0.5 mm。
為了更好地證明RLSLALI 算法的先進性,驗證其更好的定位效果,本文設置了一個室內動態場景作為實驗環境:8×7 m2大小,多種障礙物隨機擺放,并且在運行過程中有動態人流變化;同時也會人為改變室內光照強度和環境物體擺放的位置等等。
3.2 驗證算法的定位性能
本文首先要對比文獻[2]、文獻[8]與文獻[16]中算法的定位性能,驗證RLSLALI 算法是否具有有效性與先進性,所以設計機器人在當前環境自主導航6 h,重復航行軌跡12 次,測量72 個誤差值(每5 min 記錄一次誤差值),利用機器人在地圖上顯示的位置(x,y)與其實際位置 (x′,y′) 的歐式距離表示其誤差,在6 h的運行過程中,各算法的定位誤差隨時間的變化情況見圖11。計算誤差值的均值,用來說明算法修正定位的精度;計算誤差值的方差,用來說明算法在場景中各個位置和各時間段修正定位的穩定性,得到表2的對比數據。圖12為各類算法定位性能對比。
3.3 “綁架機器人”后的算法重定位效果對比
為了進一步評估本文算法在3.2節中的實驗結果是否準確可靠,本節將通過算法的重定位效果對其分析驗證。在當前已知的地圖環境中,人為“劫持”機器人一段距離,觀察機器人在地圖中能否定位到新的位置,及時更新自己的實時位姿。所以本文就人為模擬了“機器人綁架”情況,在SLAM 過程中,把機器人騰空提起,直接搬離至另一個位置,對比RLSLALI 算法與其他算法的重定位效果。
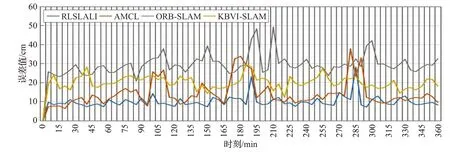
圖11 運行過程中各算法的定位誤差變化

表2 各類算法定位性能對比表
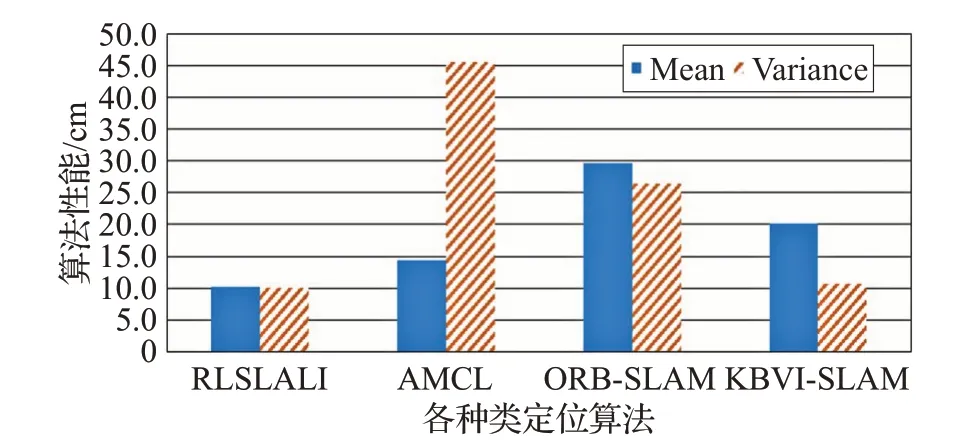
圖12 各類算法定位性能對比
圖13 及圖14 是環境特征較為明顯時文獻[2]中AMCL定位算法與本文RLSLALI算法的重定位效果對比,其中黑色和灰色所圍成的部分是當前環境的地圖表示,黑色圓圈O表示的是當前時刻機器人在地圖上顯示的位姿,也就是誤判位姿,而綠邊白色圓圈N 表示的是機器人在當前環境的實際位姿。圖13是文獻[2]中AMCL算法的重定位效果,其中的圖13(a)代表t時刻人為把機器人從黑圓O 位置搬離到白圓位置,圖13(b)代表t+1 時刻機器人的位姿更新狀態,在地圖上觀察到機器人還是在原來位置的周圍,并未進行明顯的位姿更新,而圖13(c)則是t+2 時刻機器人左右各旋轉一圈后的位姿狀態,機器人在地圖上重定位到白圓位置N 周圍,也就是其實際位姿。而圖14是本文RLSLALI算法的重定位效果,其中的圖14(a)表示的是t時刻將機器人從當前位置O 強行搬離到一個新的位置N,圖14(b)則代表在t+1 時刻時,機器人已經在地圖上重定位到白圓N(實際位置)的附近。
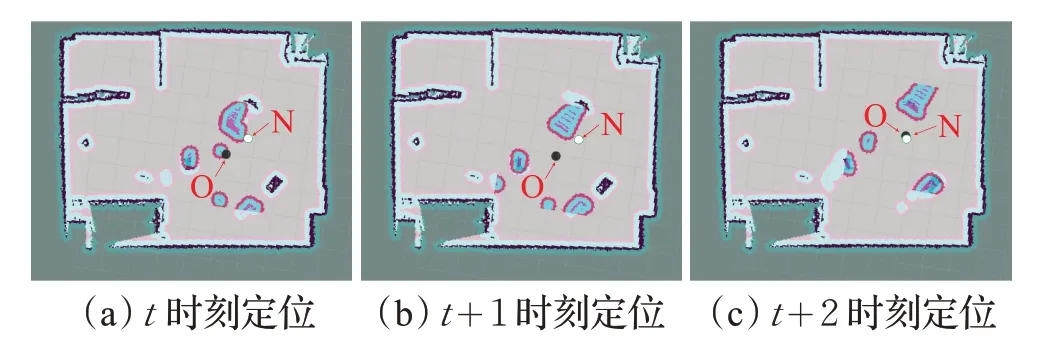
圖13 環境多特征情況下AMCL算法的重定位效果
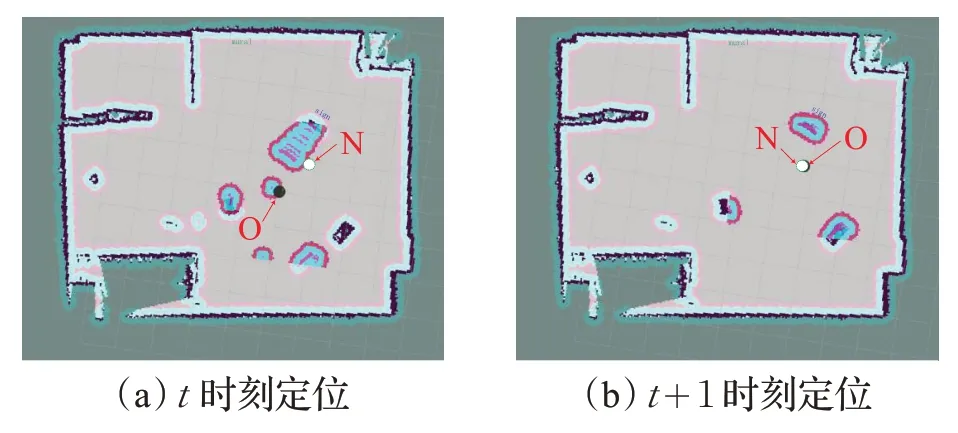
圖14 環境多特征情況下RLSLALI算法的重定位效果
進行多組實驗,結果表明,對比本文RLSLALI 算法,傳統的AMCL定位算法不僅耗時較長,要求較高(需要機器人的其他觀測行為),成功率也不理想,在本文實驗測試中僅為72%,而這還是在搬離到特征較為明顯的位置時所產生的結果,如果是將機器人搬離到一個環境特征低的位置(比如墻角,周圍墻壁環境類似等),傳統的AMCL定位算法就會幾乎無法完成重定位,而本文算法依然可以利用地標物體實時修正位姿,不受其影響,實驗測試效果見圖15 及圖16,AMCL 算法無法將機器人從黑圓位置O更新到白圓位置N,而使用本文RLSLALI算法卻能有效重定位。
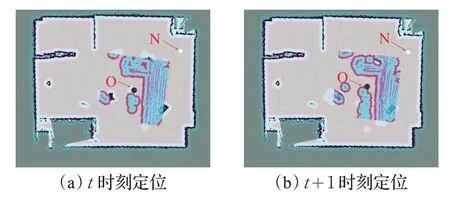
圖15 環境低特征情況下AMCL算法的重定位效果
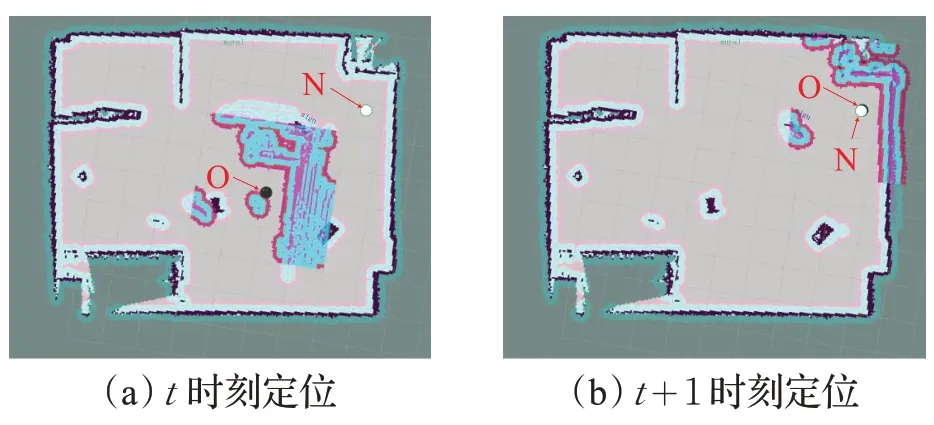
圖16 環境低特征情況下RLSLALI算法的重定位效果
不僅如此,還要將本文RLSLALI算法與視覺SLAM算法[8]的重定位效果進行對比,見圖17及圖18。

圖17 ORB-SLAM算法的重定位效果
其中圖17表示視覺SLAM算法的重定位效果,圖17(a)代表SLAM過程中算法正在獲取當前環境地圖特征點,圖17(b)是將機器人從藍邊倒三角位置O搬離到了綠邊倒三角N 的位置,而圖17(c)則是下一個時刻機器人在地圖上的進行位置更新,重新定位到綠邊倒三角N位置的附近,并形成一定的位姿軌跡,準確性較高。圖18則與之前的幾組實驗相似,表示的是本文RLSLALI 算法將機器人在地圖上黑圓O 的位置順利更新到綠邊白圓N位置(實際位置)的周圍。
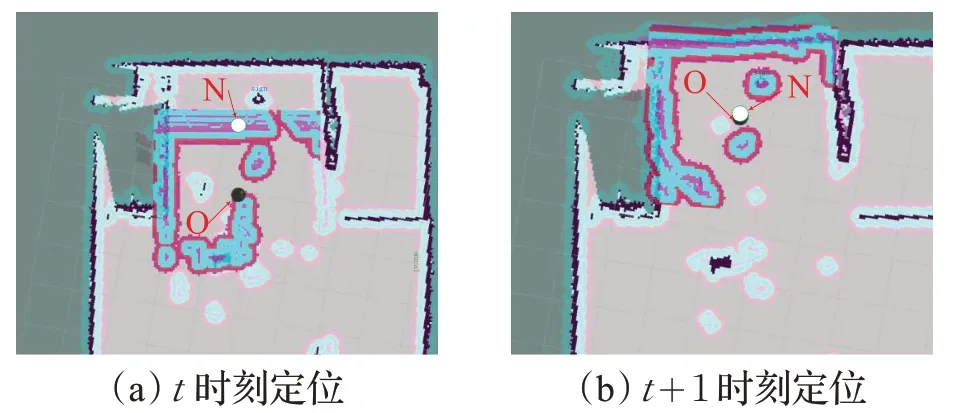
圖18 RLSLALI算法的重定位效果
3.4 物體檢測模型的識別效果
由于本文算法中所用的地標全局坐標是通過視覺識別地標,查找匹配關聯映射表來獲取的,所以為了適配本文重定位算法對實時性和準確率的需求,提出了Acc-YOLOv3 算法。為了驗證本文Acc-YOLOv3 識別算法的可行性,分別在亮光條件(300以上lux)和暗光條件(200 以下lux)對應的遠近距離(1.5 m 與3.5 m)進行實驗驗證,識別效果見圖19與圖20。

圖19 近距離物體檢測效果圖

圖20 遠距離物體檢測效果圖
圖19 中的(a)是模擬暗光條件下(200 lux 以下)近距離對地標物體(模擬指示牌)的識別結果;(b)是模擬亮光條件下(300 lux以上)近距離對地標物體(模擬指示牌)的識別結果。將其框住并賦予語義標簽。
圖20 中的(a)是模擬暗光條件下(200 lux 以下)遠距離對地標物體(模擬指示牌)的識別結果;(b)是模擬亮光條件下(300 lux以上)遠距離對地標物體(模擬指示牌)的識別結果。將其框住并賦予語義標簽。
通過與其他識別算法在當前實驗場景中實驗效果對比,可以得到表3的實驗數據,性能對比見圖21。

表3 各類物體檢測算法實驗結果對比表
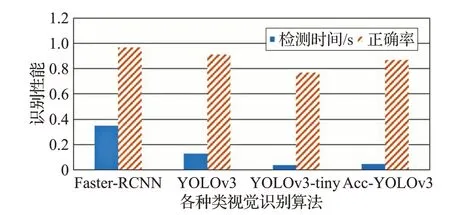
圖21 各識別算法的性能對比
對比實驗結果可知,雖然本文Acc-YOLOv3算法不能在檢測速度和準確率上同時做到最佳,但卻可以在只多消耗一點時間的情況下大幅度提升檢測的準確率,從而適配本文RLSLALI算法的運行需求。
4 結論和展望
本文提出的重定位算法是在當前主流SLAM 算法的基礎上,對它們的定位效果加以優化和改進。本文RLSLALI 算法利用視覺傳感器模擬人的眼睛,用來識別機器人周圍物體及地標;利用激光和IMU 來獲取位置、距離、角度等準確度要求較高的信息。巧妙地結合激光測距的準確性與視覺信息的豐富性,用來構建本文創新的地標數據庫與位姿推導模型。使機器人能夠根據環境中的地標信息,自主地完成重定位。從實驗結果對比來看,本文算法取得了較好的重定位效果,算法修正每一次的錯誤定位之后,總的定位偏差均值約為10.2 cm,方差約為10.1 cm,可見本文提出的基于語義激光與地標信息的機器人重定位算法具有先進性、有效性以及健壯性。
本文算法不僅是對目前SLAM 技術中定位方法的改進與補充,也是對某些人為設置地標優化定位精度算法的加強與優化。一般情況下,通過本文算法搭建的地標數據庫系統,能夠讓機器人在運行環境中自主篩選和設置有效地標,無需為設置地標做大量的前期繁雜工作,減少了人為干預步驟。當然,本文算法也存在待改進的地方,就是過于依賴自然地標,如果環境中符合地標條件的物體太少甚至沒有的話,就必須通過增加數據集對模型繼續訓練調優和設置人為地標來實現算法,這也是本文作者以后繼續研究的一大重點。
致謝 感謝本實驗室曹軍的前期研究工作,給本文RLSLALI算法研究提供了前期數據支持,在他的研究基礎上,本文順利地將地標概念引入后端重定位算法中。
猜你喜歡
中老年保健(2021年12期)2021-08-24 03:30:40
中國傳媒大學學報(自然科學版)(2021年1期)2021-06-09 08:43:00
開放教育研究(2020年2期)2020-03-31 01:54:14
中國生殖健康(2020年6期)2020-02-01 06:28:50
新世紀智能(英語備考)(2019年12期)2020-01-13 06:07:18
中國生殖健康(2019年11期)2019-01-07 01:28:02
中國生殖健康(2018年6期)2018-11-06 07:09:28
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
當代修辭學(2011年6期)2011-01-29 02:49:50
