點云數據在深度學習中表示方法的研究
2020-09-15 04:47:58周明全耿國華
計算機工程與應用 2020年18期
張 婧,周明全,耿國華
西北大學 文化遺產數字化國家地方聯合工程研究中心,西安 710127
1 引言
隨著深度學習的發展,在計算機視覺領域中如何將具有無序性的點云數據表示成深度學習網絡可以接收的有序數據結構,用于深度學習的訓練是亟待解決的問題。現階段深度學習被廣泛地用于2D 圖像特征提取,并且在大多數圖像分析和理解任務中,已經證明它們優于傳統算法的解決方案。在點云的深度學習中,主要的解決方法是將3D模型轉換為規則的2D圖像表示,將用于2D 圖像的深度學習方法應用于不規則3D 模型。如何表達三維模型能夠實現點云在深度學習中的端到端的輸入而不需要把三維3D數據轉換為2D圖像,是本文要解決的問題。點云數據的另一個特點是海量性,如何對大規模的無序的點云模型進行有效的三維表示與管理,為后期模型數據的分析提供基礎,是另一個亟待解決的問題。
為解決以上問題,本章提出基于八叉樹和三維K-D樹的集成索引(OctKD)的點云數據表示方法。本文的主要貢獻是:
(1)提出一種深度學習卷積神經網絡可以接受的,能夠端到端表示點云模型的OctK數據結構。
(2)OctKD 的點云模型表示方法,能夠真實反映模型本身的細節特征。
(3)提出一種新穎的完全在GPU 端以并行方式構造八叉樹的算法,降低了點云模型的構造時間。
(4)針對點云模型的散亂性,采用三維K-D 樹索引單個三維空間點,提高點云檢索效率。
2 相關研究
點云模型目前常用的表示方法有多視圖、體素和點云結構。基于視圖的表示方法[1-5]首先從具有固定視點的原始對象獲取2D 視圖,然后將這些視圖作為對象信息,利用圖像處理中的一些成熟的方法來處理這些圖像,并從中提取特征。基于視圖的方法由于其靈活性和良好的性能而引起人們的極大關注。多視圖卷積神經網絡把三維模型轉換為二維圖像,然后應用二維卷積網絡處理,但3D數據的計算量將會極大的增加,就是所謂的“維數災難”。目前比較常用的是基于體素的表示,Wu 等人[6]提出ShapeNets,是第一個將卷積神經網絡應用于三維表示,將對象的3D數據表示為30×30×30大小的“立體柵格”。Daniel 等人[7]提出 VoxNet,將點云劃分為等間距的3D 體素,并通過新引入的體素特征編碼層將每個體素內的一組點轉換為統一的特征表示,然而這種表示由于數據稀疏性和卷積計算成本的約束,要求其分辨率不能高。Li等人[8]提出一種處理點云數據稀疏問題的方法,但是這種方法是在稀疏模型上進行的,因此還是無法處理大量點云數據。Fang等人[9]和Guo等人[10]提出將三維數據轉換為向量矩陣,通過提取特征向量達到特征提取的目的。Wang等人[11]提出將點云模型八叉樹表示,該方法將所有三維模型用深度為8的八叉樹表示,最后葉節點中的點云用平均法向量表示,這種將點云模型法向量表示的方法,模型表示的精確度不夠。在基于點云的表示方法中,Qi等人[12]設計了一種直接消耗點云的新型神經網絡,它保證輸入點的置換不變性,將網絡命名為PointNet,但是PointNet 網絡不會捕獲由度量空間點所引發的局部結構,從而限制了識別細粒度模式的能力以及對復雜場景的普遍性,之后Qi等人[13]提出了新的集合學習層,以自適應地組合來自多個尺度的特征,該網絡命名為PointNet++。山東大學的Li等人[14]為了讓卷積神經網絡(CNN)更好地處理不規則和無序的點云數據,提出了PointCNN網絡。
3 GPU并行生成八叉樹算法
3.1 算法步驟概述
采用自頂向下的方式逐層并行構建八叉樹,規定根節點層為第0層,一棵深度為L的八叉樹其層號最大取值為L-1,算法流程圖如圖1所示。
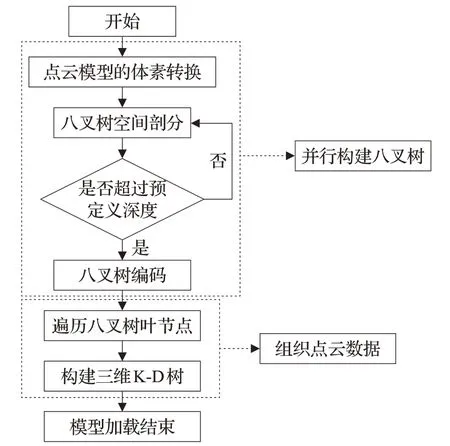
圖1 算法流程圖
步驟1將無組織的點云轉換成體素空間。
步驟2在體素空間中對點云模型進行八叉樹空間剖分,區分并標記空節點和非空節點,統計非空節點的總數。
步驟3根據八叉樹葉節點的數量,為每個葉節點開辟存儲空間,對八叉樹編碼。
步驟4從第0層起,自頂向下逐層構建節點間的關系,每次只處理一層,對每層節點并行處理。
3.2 點云轉換成體素空間
初始時求出點云模型中頂點的最大、最小值頂點(xmax,ymax,zmax)和(xmin,ymin,zmin)。以這兩點為對角頂點構成空間包圍盒,并將其作為數據點云拓撲關系的根模型。包圍盒沿x、y、z軸的長度分別為:Lx=|xmax-xmin|、W y=|ymax-ymin|、H z=|zmax-zmin|。在頂點(xmin,ymin,zmin)上固定一坐標系,方向與歐氏空間的x、y、z方向相同,坐標為整數坐標,構成一空間,稱為空間Z3。該空間是3D離散空間,是三維歐氏空間的子空間(Z?R3),在邏輯上該空間為根節點。
3.3 八叉樹空間剖分
在Z3空間中,以深度優先的方式遞歸細分包圍模型的立方體,將外部立方體劃分為相同大小的8 個子類,每個子立方體被視為根節點的8個葉節點。當立方體被剖分成8個小的立方體時,空間物體分別位于這些子立方體的不同部分。若模型的點云在該節點或者立方體上,則該節點標記為FULL,否則該節點標記為NULL,同時該節點無需進行剖分,如公式(1)所示:

在每個步驟中,對于當前深度l遍歷被三維模型曲面占據的非空的節點,并在下一個l+1 深度將它們分別細分為8 個孩子節點。重復這個過程直到達到終止條件,終止條件為預定義深度或者葉子節點的大小。圖2(a)所示為點云模型的八叉樹空間剖分,圖2(b)為其對應的八叉樹表示。分割的每個單元格的大小為Δx=Lx/l、Δy=Wy/l、Δz=HZ/l,其中l為分割的層數。
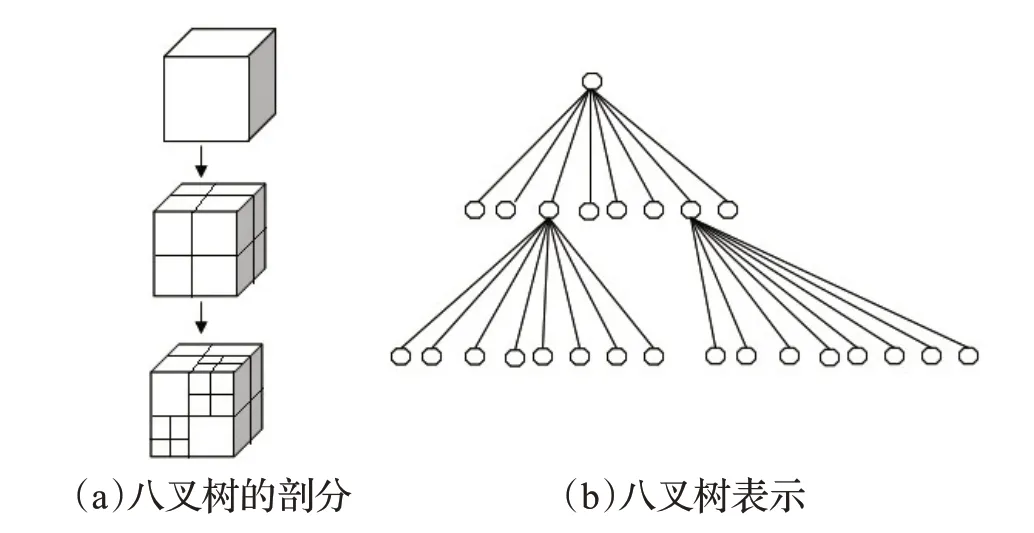
圖2 八叉樹剖分與表示
3.4 改進的八叉樹編碼方式
在本節中,描述如何從給定的一組點云數據集Q={qi|i=0,1,…,N} 構建具有最大深度D的八叉樹O。(1)按照3.2節中的方式先把點云模型轉化為體素空間,并對體素空間進行八叉樹剖分。(2)按照文獻[11]的思想設計八叉樹的存儲方式,引入一個索引數組和哈希函數用于尋找不同深度的節點對應關系以進行下采樣,同時為父節點的8 個子節點構造鄰域,用于鄰域快速計算。
八叉樹節點的表示。記錄八叉樹節點較復雜,主要包含三條信息:
(1)向量sl:記錄八叉樹葉節點的三維空間坐標。
(2)點集t:記錄每個節點所封閉的點。
(3)索引p:標記父節點與子節點,及子節點之間的鄰域關系。
向量sl:為了記錄八叉樹l層的n個節點,用一個維一的 3n長的字符串key(Ο)=i1j1k1i2j2k2…in jnkn表示。in jnkn可以由任意一點坐標計算所得到,具體計算方法是已知任意一點P的坐標為(x,y,z),則點P所在的單元格坐標為:
in=(x-xmin)/Δx,jn=(y-ymin)/Δy,kn=(z-zmin)/Δz in jnkn即八叉樹分割中每個點所在單元格的三維空間坐標(i,j,k),是3D立方體中的單元格的相對位置。
按照in jnkn升序的方式對八叉樹空間的位置排序并將八叉樹第l層排序好的空間位置存儲在sl向量中。sl之后用于構建三維卷積的八叉樹的鄰域。在實現中,每個空間位置存儲在32位整數中。圖3列舉八叉樹節點的二維空間位置,圖4顯示每層對應的排序。
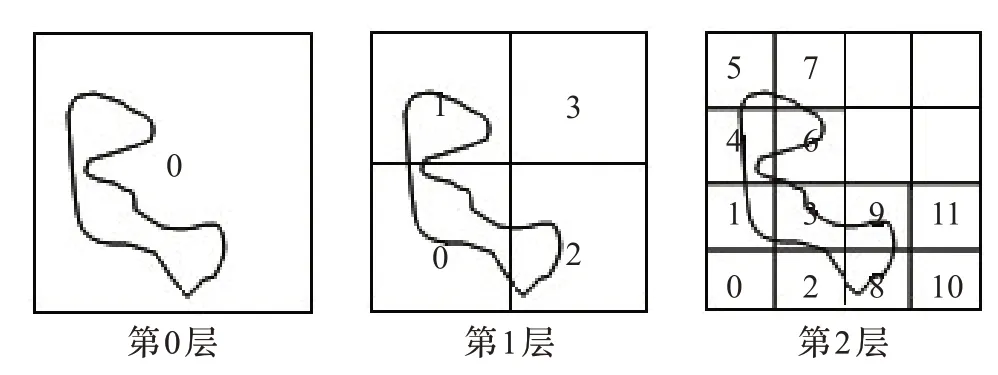
圖3 二維空間中圖像的四叉樹構造
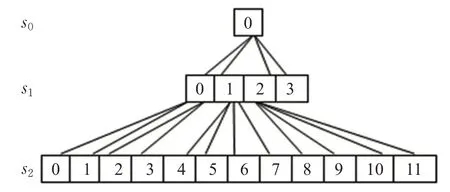
圖4 每層節點對應的排序
4 構建八叉樹
4.1 構建節點間的鄰接關系
對于每個節點,需要記錄其父節點、8個子節點,相鄰節點。在一般的八叉樹數據結構中使用指針來表示節點間的相互關系,但本文中,為了節省內存空間,加速計算,丟棄從父節點到子節點的指針,并引入一個哈希函數,用于尋找不同深度的父子節點間的對應關系。
在計算中,需要快速找到相鄰層上八叉樹上的父子的相鄰關系。為l層的非空節點指定一個索引p,表示它是第l層排序節點中第p個非空節點。對于空節點,把它的索引設置為零。l層的所有索引存儲在索引向量Ll中。圖5 表示二維空間中每個深度的索引向量。對于非空節點,在圖5 中被標記成藍色的節點,其索引為3(L1[2]=3),因為它是第一層的第三個非空的節點。
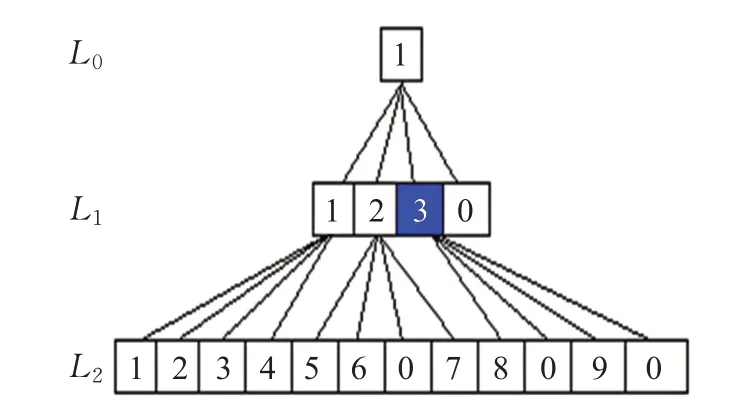
圖5 索引向量
4.2 逐層并行構造八叉樹
在確定一個節點是非空節點后,用原子計數器為其分配一個索引,作為節點在索引向量中的存儲位置。從根節點開始,每次只處理一層,每層節點并行處理。再處理第l層時(i>0),需要獲取第l-1 層即其父節點的索引位置,以構建父子關系。
(1)只有第l深度的非空節點被細分。
(2)根據屬性的升序排序節點。一個節點的8個孩子被順序存儲。
(3)父節點和孩子節點的屬性向量都遵循相同的順序。如圖5所示,第2層的最后4個節點是第1層的第3個非空節點創建。
5 點云數據組織
文獻[11]提出了既節省內存空間,又可以快速進行鄰域搜索的八叉樹存儲方式,但該方法對八叉樹葉子節點內的點云僅做了平均法向量處理,并沒有提出具體每個點云的組織方式。針對該問題本文結合三維K-D 樹的空間索引單個三維空間點云,使大規模點云直接端到端輸入深度學習網絡成為可能。
5.1 基于K-D樹的點云組織
通過八叉樹剖分后的點云數據被分到若干個規則節點中,其二維平面結構如圖6所示。這種方法采用規則格網剖分,易于實現,具有較好的可操作性,在點云數據的空間分布比較均勻的,且數據量不是很大時也可以達到快速檢索的目的,但是當海量數據,且點云數據的空間分布不均勻(如存在局部點云密集)時,這種單一組織方式存在的弊端就會顯現。比如葉子節點中點云數據量的不均衡,在數據密集的葉節點中進行坐標點的二次查詢仍然是很耗時,難以提高點云數據的檢索效率。如果大量增加八叉樹的深度,不僅會給數據結構的實現帶來困難,也會造成大量“無點”空間的浪費,降低檢索效率[15]。
今年云南省局部地區,在授粉階段成片發生高溫熱害,造成缺粒減產,產量可能降低30%-50%。主要原因是開花抽絲期間,當溫度高于32-35℃,空氣濕度低于30%,田間水量低于70%,雄穗開花的時間會顯著縮短。因高溫干旱,花粉粒在1-2 h內失水干枯,喪失發芽能力,花絲延期抽出,造成花期不遇;或花絲過早枯萎,嚴重影響授粉結實,形成禿尖、缺粒,產量降低。如能及時澆水,改善田間小氣候,可減輕高溫干旱的影響。

圖6 點云數據的規則間組織二維結構示意圖
基于此,文中對存儲于葉子節點中的點云數據采用K-D 樹進行二次組織。要求存入的數據能夠按照一定的規則進行排序,并且按照此規則進行的排序結果必須遵循兩個原則:
(1)唯一性。即坐標不同的三維點坐標的排序結果一定不同。
(2)傳遞性。如果Pn1>Pn2,Pn2>Pn3,則Pn1>Pn3(Pn3為三維坐標點)。
在每個八叉樹葉子節點內構建K-D樹的步驟為:
(1)將八叉樹葉子節點作為K-D 樹的根節點,該節點內包含的點{P}作為預分割點集。
(2)將葉節點進行“分維”處理,在一維空間中進行排序操作。首先將坐標點投影到x軸上進行比較,如果相同,再投影到y軸上比較,依次拓展到z軸進行判斷。對于任意兩個點Pn1和Pn2,其對應的坐標點為(x1,y1,z1)和 (x2,y2,z2),那么
if(x1≠x2),以x軸為法向平面將點集{P}分割為2 個集合,設P1為左集合,P2為右集合。
if(x1=x2)and(y1≠y2),以y軸為法向平面將點集{P}分割為2個集合,設P1為左集合,P2為右集合。
if(x1=x2)and(y1=y2)and(z1≠z2),以z軸為法向平面將點集{P}分割為2個集合,設P1為左集合,P2為右集合。
(3)更新點集{P},在P1和P2中分別執行構建K-D樹。
5.2 點云數據組織結構設計
通過上述分析,三維點數據以坐標為關鍵字直接存儲在K-D樹中,而K-D樹作為二級組織結構關聯存儲于空間八叉樹的葉子節點中。這種結構的內存實現比較容易(其數據結構如圖7所示)。
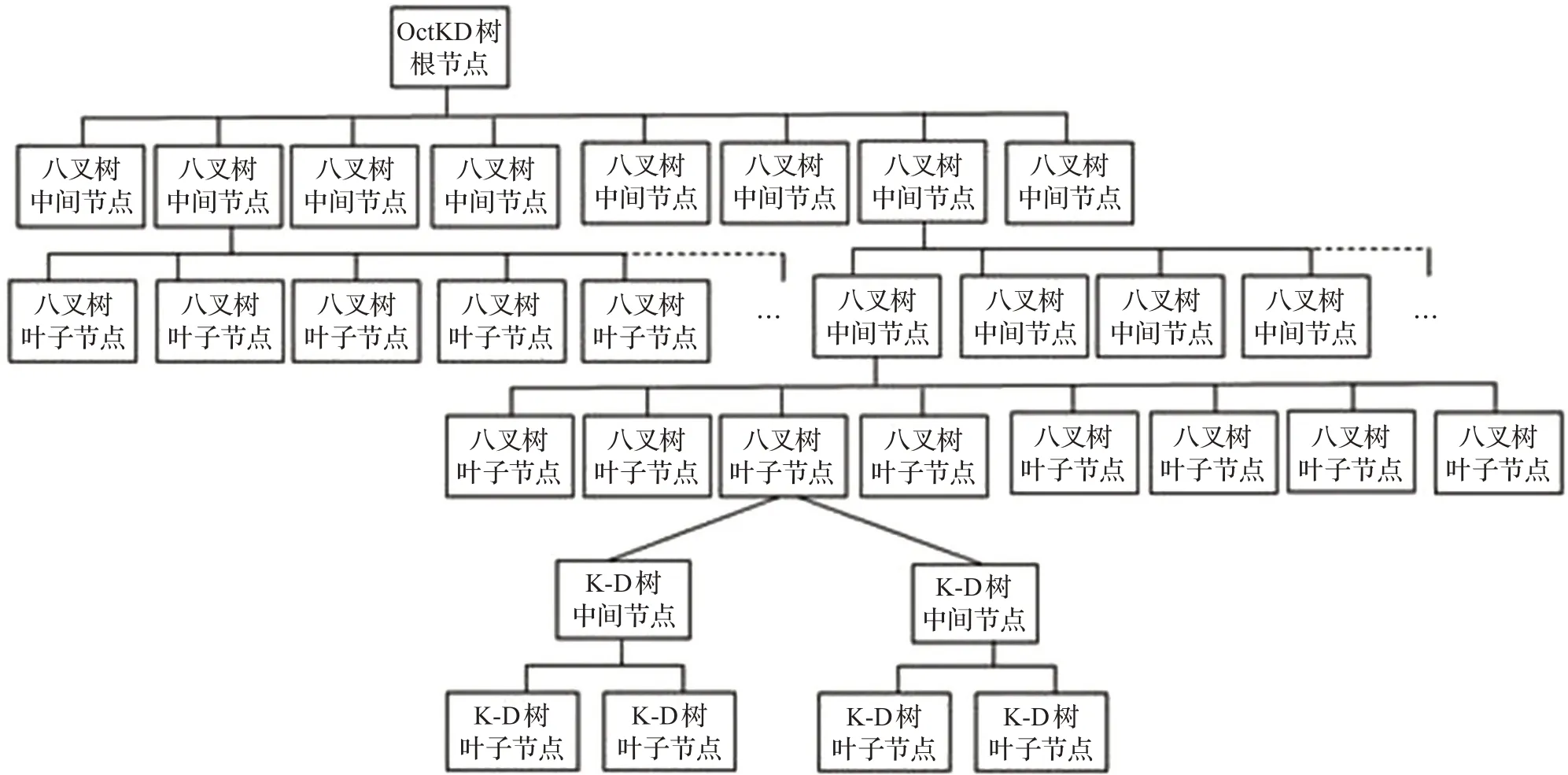
圖7 點云數據組織的結構圖
6 實驗結果與分析
6.1 實驗環境
算 法 在 一 臺 Intel Core i7,3.30 GHz 的 CPU 和GeForce GTX 1080 的GPU(8 GB顯存)的臺式機上完成點云模型的表示。本文使用Visual studio 2013環境下進行CPU 編程,使用OpenGL 進行GPU 編程,并使用OpenGL實現三維模型加載表示。
6.2 實驗數據
實驗數據以在兵馬俑一號坑第三次發掘中掃描的模型數據為例,這些模型經過除噪,孔洞修復后的點云模型如圖8 所示,(a)為 10 號坑 4 號俑(G10-4)的手,(b)為9號坑3號俑(G9-3)的頭,(c)為9號坑7號俑(G9-7)的腿。

圖8 碎片的原始點云模型
6.3 實驗分析
實驗1 實驗結果的可視化
利用本文提出的構造八叉樹的算法對圖8 中的模型分別進行八叉樹剖分,點云模型經過八叉樹剖分(深度分別為5和7)后的可視化圖如圖9至圖11所示。

圖9 G10-4俑手的可視化表達
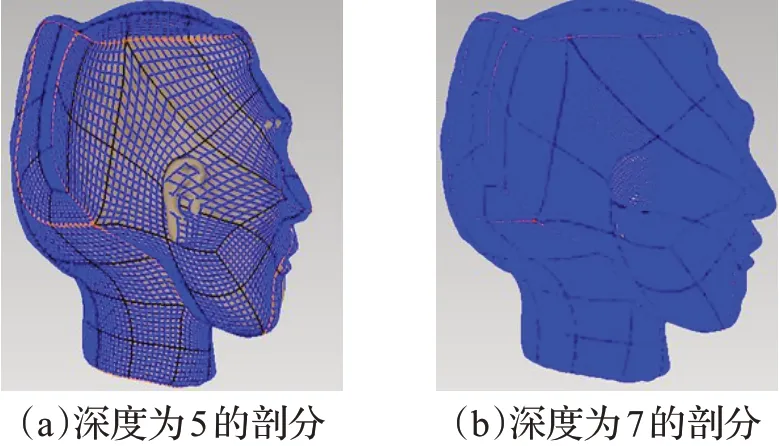
圖10 G9-3俑頭的可視化表達
實驗2 與已有方法比較

圖11 G9-7俑腿的可視化表達
圖12 為將文獻[11]的點云模型八叉樹表示與本文點云模型八叉樹表示方法的比較,其中(a)為G9-3俑頭的原始模型,含有46 919 個點云,(b)為使用文獻[11]將點云模型用八叉樹方法表示,(c)為使用本文提出算法將點云模型用八叉樹方法表示。比較圖(b)和圖(c)可以明顯地看出本文提出的算法將點云模型八叉樹表示后保留了傭頭的眉毛、眼睛、鼻子和嘴巴等細節,而文獻[11]提出的八叉樹體表示方法模型的細節特征表示模糊。這是因為本文的方法在將模型八叉樹化后點云模型使用K-D樹的方法進行了組織,能夠真實表達模型特征,如圖(c)所示,而文獻[11]將葉節點中的點云用平均法向量表示,所以文獻[11]中看到的特征是平均法向量特征,如圖(b)所示。

圖12 文獻[11]與本文點云模型八叉樹表示方法的比較
表1展示了G9-3俑頭的原始模型(含有46 919個點云),分別在CPU 端使用文獻[11]的方法構建八叉樹所耗費的時間與在CPU端使用本文的算法構建八叉樹所耗費的時間。其中CPU端采用傳統的遞歸分割根節點的方法構建八叉樹,八叉樹的深度為5、6 和7。通過比較可知,本文所提出的GPU并行構建八叉樹的方法,較傳統的CPU 算法速度可以提高一個數量級,且構造八叉樹的深度越大加速比越高。
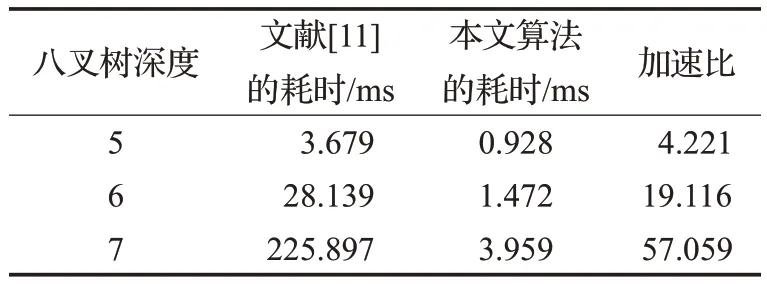
表1 八叉樹生成算法在CPU和GPU上耗時對比
實驗3 點云查找耗時分析
為了驗證八叉樹與K-D樹混合的索引效率,本實驗利用圖8 的點云模型,其中俑手含有16 274 個點云,俑頭含有46 916 個點云,俑腿含有226 792 個點云。分別利用改進八叉樹,K-D樹和改進八叉樹與K-D樹的混合索引對點云進行組織,并對指定的同一個點進行查詢,查詢的時間統計如表2所示,從表中可以看出利用單一的八叉樹進行點云的查找的時消耗時間最多,這是由于隨著八叉樹深度的變大,導致了查詢的效率明顯下降。而K-D樹組織的點云明顯可以改善查詢的效率,但是隨著點云數量的增大其效率降低相對也比較明顯。而利用混合結構的索引方式可以大大地改善查詢點的效率,非常有利于對點云數據的分析、可視化與交互。
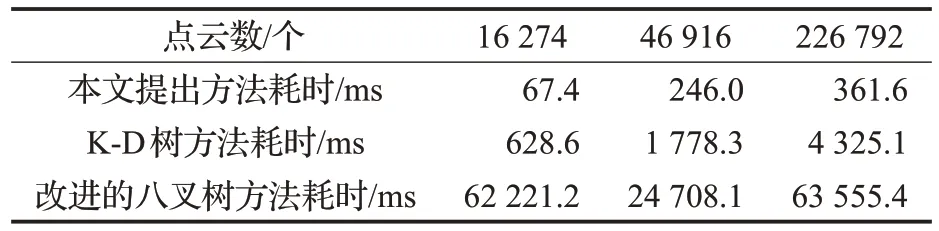
表2 三種不同的算法點云查找耗時對比表
實驗4 OctKD混合索引在深度學習中的應用
將本文提出的OctKD混合索引結構應用于文獻[11]提出的三維模型分割的卷積神經網絡。文獻[11]提出的深度分割網絡為:
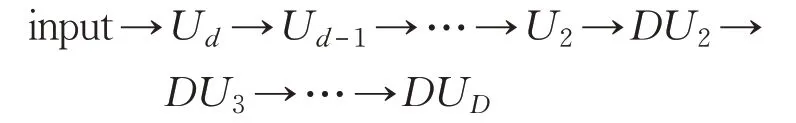
其中Ul表示為convolution+BN+Relu+pooling,DUl表示為unpooling+deconvolution+BN+Relu,d為八叉樹的深度。圖13為將OctKD混合索引結構應用于深度網絡所得到的特征提取圖和模型分割圖。黃色、綠色、紫色來表示該碎塊被分割出的不同面,紅色表示粗分割線,桔黃色表示精細分割結果。
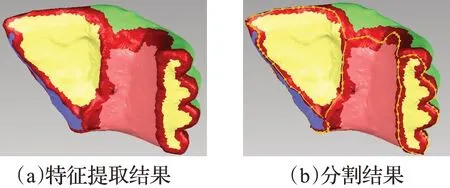
圖13 OctKD在深度學習中的應用
7 結束語
對于機器學習任務,模型表示是至關重要的一步。發現和表達原始數據的能力是決定算法整體性能的重要因素。因此,本章的目標是尋找能夠代表3D 對象而且能夠用于深度學習的表達方式。針對海量散亂點云數據不能直接輸入深度學習網絡進行學習的問題,提出基于八叉樹和三維K-D 樹的集成索引(OctKD)的點云數據的表示方法。該方法即克服傳統八叉樹編碼浪費空間的問題,又實現層與層之間以及八叉樹節點的鄰域信息之間的快速訪問。實驗表明這種新的點云模型的OctKD數據結構優化模型在卷積神經網絡上的訓練,是一種深度學習能夠處理點云數據的數據結構。最后按層構造八叉樹,在同一層上的所有八叉樹節點并行處理的,實現點云數據在GPU上的并行處理。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
