基于MOOC的個性化預測和干預研究
2020-09-15 16:30:34蔣翀朱名勛王點
計算機時代 2020年8期
蔣翀 朱名勛 王點
摘要:針對MOOC研究現狀,結合MOOC平臺多樣、規模龐大、種類眾多、學習者背景和目的各異等特點,以個性化預測研究為主要對象,分析和對比了作為研究基礎的點擊流日志、討論區、課后任務、課程信息和學習者基本屬性五類數據源的優劣,歸納了用于預測的基于活動、討論區、社交和認知的模型。以《大學信息技術二(Python程序設計)》為例,構建和應用了個性化預測和干預模型。
關鍵詞:MOOC:個性化:預測模型:復制框架
中圖分類號:G434 文獻標識碼:A 文章編號:1 006-8228(2020)08-10-04
0引言
自2012年以來,MOOC浪潮以美國為起點迅速席卷全球,吸引了全球不同國籍和教育背景的數以千萬計的學習者加入。截止2020年3月,Coursera與來自52個國家207個院校和公司合作,提供4116門課程,學習者超過4500萬人[1];edX與全球140多所頂尖機構合作,學習者數量超過2400萬,提供2600多門課程。國內知名MOOC平臺學堂在線匯集600余所知名院校的近2000門課程,注冊用戶近3000萬[2]。經過近十年的發展,MOOC平臺提供給學習者的選擇更加多樣化,除了免費課程以外,也有一部分付費、學分和學位課程,一些企業也會定向提供付費的培訓。
從MOOC誕生之初,高輟課率就是困擾MOOC發展的絆腳石。2014年,哈佛大學的HarvardX研究委員會和MIT的數字化學習辦公室合作發布的在線課程研究報告顯示:拿到證書的學習者僅占總人數的5.1%[3]。因此,從研究內容來看,大部分MOOC相關的研究工作圍繞學生輟課率展開,對學生行為和活動進行分析,預測可能的學習結果(是否能完成課程,測試是否通過)[4],進行個性化干預;也有部分研究獲取學習者學習行為、興趣和結果,在學習過程中開展個性化學習資源推薦,規劃學習路徑,或者在完成課程后進行相似課程推薦。本文闡述了MOOC個性化預測研究的數據基礎和主要類別、歸納了四種類型的模型構建,總結了復制框架在驗證已有預測研究結論中的應用,最后提出未來研究可能的重點和方向。
1 基礎數據源
在MOOC研究領域,特別是對直接講授MOOC的教師和團隊,可以直接獲取大量用于教學研究的原始數據,這在傳統的高校教育環境中很難實現。在目前MOOC預測研究中,基礎數據有點擊流日志、討論區、測試及課后任務、課程信息和學習者基本屬性五類。
1.1 點擊流日志
點擊流日志又稱為服務器日志,是學習者與課程平臺交互的記錄,由服務器自動記錄,是MOOC研究的主要數據來源。記錄的學習者行為(事件)包括鼠標點擊,頁面瀏覽(當前頁碼,后退或前進),回答問題,視頻播放/瀏覽/略過,問題提交和討論區互動等。一般來說,會開展特征工程,從日志中抽取特征,分析屬性和操作,以及產生的結果,形成規則[5],例如,如果花費在學習資源上的總時間大于所有學生的平均時間,那么更可能完成課程。在很多情況下,特征工程比統計算法更為重要,研究者會采用新的特征工程算法和標準的分類算法[6],提升預測模型的表現。除了服務器日志外,客戶端日志在實時預測中也有使用。Pardos等人在edX平臺客戶端嵌入JavaScript腳本,獲取學習者最近(幾秒前)的操作數據,實現實時的學習預測和干預[7]。
1.2 討論區
在討論區內,主要有學習者發布的基于主題的討論,與課程內容相關的討論和互動,所有學習者都能發表主題和回復,教學團隊也會參與其中。但是,只有部分想要完成課程或對課程興趣較高的學習者會在討論區發言。與點擊流日志相比,這部分數據量相對較小。這部分原始數據都是自然語言構成的文本數據,經過分析處理,可以獲取兩方面的信息,一方面是對與發帖行為相關的數據,例如發帖次數,回復次數,發布的主題貼是否有更多的回復(相比平均數),點贊和反對的操作次數等,另一方面通過自然語言和詞匯復雜度分析,獲取語言和詞法相關信息,例如是否使用更復雜的詞匯和更準確的詞語[8],更多的使用二元/三元語法,使用更多種的詞匯(與平均使用次數相比)。這些數據可用于獲知學習者參與度、掌握和理解學習內容的程度,可用于構建基于課程的社交網絡。
1.3 測試、作業和課后任務
與大學實體面授課程相似,MOOC學習過程中,有各種類型的測試、作業和課后任務,包括視頻中的QUIZ,課后測試,任務,仿真實驗,程序編寫和報告論文等。從中抽取的特征主要包括學習者在課后任務中所花費的時間,嘗試作業次數、
嘗試小測次數和嘗試講座次數等[9]。因為對于大部分課程而言,完成作業的學生較少,數據量和覆蓋的學生比例也比較小。同時,不同學科課程的作業形式有一定差異,數據處理的方法各異,為研究帶來了一定的困難。
1.4 學習者基本屬性和課程信息
課程信息一般與其他信息想結合,進行學習行為和結果的預測,也應用于學習者的持續性和參與度的預測。學習者基本信息一般是通過課前的可選問卷獲取,信息量小,獲取的內容與真實情況有一定偏差,可用性不高。
1.5 數據獲取與應用
在實際研究中,直接使用點擊流數據或結合多項數據的情況較多。華中師范大學張浩等人綜合運用了用戶屬性信息(ID,年齡,性別,教育程度和地區)、用戶行為數據(瀏覽、評論、收藏、是否參與課程、交互次數、播放視頻次數等)和課程屬性信息(ID、名稱和分類)進行課程資源的推薦。國防科技大學的王雪宇等人在研究中擴大使用的數據范圍,不僅使用學習者學習本課程時產生的數據,而且綜合考慮其學習本課程之前在其他課程的行為數據,包括登錄次數,學習其他課程數,通過的課程數和平均成績等,學習本課程期間在其他課程的學習數據,包括同時學習的課程數量,通過的其他課程數和平均成績等[10]。
在絕大部分的MOOC研究中,數據基本源于研究者或團隊所講授的幾門課程。對于其他未講授MOOC的研究者,可以從MORF和DataStage獲取大規模的共享基準數據集,
2 預測模型
預測模型是在根據不同課程源數據提取的特征,構建預測模型,分別進行訓練、測試和應用。常見的預測模型主要有基于活動、討論區、社交和認知的模型。
2.1 基于活動的模型
基于活動的模型使用行為數據,以學習者行為理論為基礎,評估行為結果。因為具有大量可靠穩定的數據源(服務器日志)且具有較好的預測表現,基于活動的模型最為常見。具體來說,有基于早期課程行為的模型,針對學習者在第一周內的學習表現進行早期輟課預測,為風險學生提供早期干預[11];也有包括LSTM神經網絡的序列模型,將每周的活動特征向量序列作為輸入,累積每周的學習數據,逐步提高預測效率[12];另外,SVM、隱馬爾科夫和邏輯回歸等模型也有不同程度的應用。
2.2 基于討論區的模型
基于討論區的模型使用自然語言數據作為基礎。這些自然語言數據來自于學習者或使用語言學理論分析得出。對討論區數據的細節分析包括語言、社交和行為的一些特征,這些只從點擊流數據分析無法獲取。從討論區的自然語言中抽取特征是一項十分耗費時間和人力的工作,但帶來的效果是其他工作無法替代的。通過比較基于點擊流活動特征和自然語言處理特征預測優劣的研究,發現基于點擊流活動的特征是課程完成率最有效的推薦指標。基于討論區模型的局限性主要是數據稀疏性[13],覆蓋的學生比例一般不超過完成課程的學生比例。
2.3 社交模型
社交模型使用觀測或推導出的社交關系,社交互動的理論作為學生模型的基礎。在研究中,以討論區數據為基礎構建社交網絡,學生是節點,不同的回復關系構成邊。Joksimovi等人評估了評論區社交網絡聯系與學習表現之間的關系,相比未完成課程的學生,獲得認證或者優秀的學生更愿意互動和交流,得出了社交網絡中的結構中心與課程完成正相關的結論[14]。與MOOC評論區分析社交網絡相比,外部社交網絡(Facebook、Twitter、微信和微博等)具有數據豐富和網絡關系相對穩定等優點,可作為未來獲取更多社交因素,研究社交聯系與學生成功之間聯系的新方向。
2.4 認知模型
認知模型的基礎是認知理論和學習者的認知狀態。認知數據的獲取主要是通過傳感技術進行生物特征追蹤和同期問卷調查。Dillon等人關注在MOOC模型中情緒這一認知狀態,用自述的情感狀態檢測情緒與學習活動和輟學之間的關系。研究結果顯示,焦慮、困惑、沮喪和希望都與輟學明顯相關。雖然MOOC學習本身就是一個認知的過程,學習結果是認知狀態的直接反映,但是總體來說,對于認知數據的研究和應用相對較少,這與目前傳感設備的普及率不高,認知數據量小有直接關聯。
3 個性化預測和干預模型構建
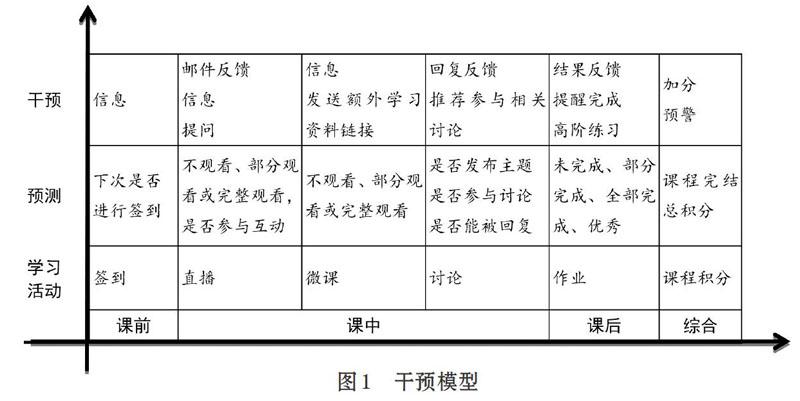
自關注以MOOC為代表的開放在線課程以來,筆者完成了Coursera約翰霍普金斯大學“探索性數據分析”和“R語言程序設計”,學堂在線清華大學“數據挖掘:理論與算法”等課程。在超星學習通先后開設了“數字視頻制作”、“數字媒體技術與應用”和“數字媒體技術專業實訓”等課程。目前正在講授“大學信息技術二(Python程序設計)”課程,本文以該課程為例,結合學習和教學經驗,構建了個性化預測和干預模型,如圖1所示。根據學生學習表現,預測可能的學習行為和狀態,通過系統信息和郵件及時地干預。
具體來說,將學習活動劃分為課前、課中、課后。課前簽到,課中直播、看微課和參與討論,課后完成作業。綜合這三個階段不需要學生額外參與,系統根據所有學生已參與的課堂活動,給出一個分數評價。下面對每個階段的學習活動進行詳細描述。
(1)簽到。根據歷史簽到情況預測下次課程是否會簽到,若結果為不會簽到則發送信息提醒學生。
(2)直播。根據以往觀看直播視頻和是否參與互動的情況,預測學生下次參與直播課程的情況,通過信息進行提醒,郵件反饋歷史情況。若預測參與直播的可能性小,則在下次直播課程中重點關注并進行適當提問。
(3)微課。微課相當于布置的錄播課任務,要求在規定時間內完成觀看,沒有實時互動。根據觀看微課的歷史情況,預測下次將不觀看、部分觀看或完整觀看。對于完整觀看的學生,發送額外學習資料的聯系,鼓勵進行拓展學習。對齊其他學生,發送信息進行反饋和提醒。
(4)討論。根據學生在討論區的表現,預測是否會發布主題、參與討論或主題能被回復,將討論區動態及時通過信息反饋給學生,并為行為活躍的學生推薦相關性高的主題和討論。
(5)作業。預測學生完成課后作業的情況,對全部完成作業和優秀的學生推薦部分高階練習。對其他同學發送提醒信息。
(6)課程積分。課程積分由學習平臺自動生成,為學生各學習階段的表現綜合評價。根據現階段課程積分,來預測課程完結總積分,對積分排名20%的給予不同程度平時成績加分。對于排名后20%的發送預警信息。
目前,在課程《大學信息技術二(Python程序設計)》的簽到、直播、作業和課程積分4項活動中,應用了預測和干預模式,結果表明,學生簽到率明顯提高,直播互動人數增多,作業完成情況有所提升,課程積分有一定程度提高。
4 結束語
本文對目前MOOC研究中的數據源和預測模型研究進行了梳理,結合自身學習和教學經驗提出了個性化預測和干預模型,并將模型應用于所講授的課程中,教學效果和學生在課程中的參與度都有一定程度的提升。對于以MOOC為代表的在線課程的過程管控、個性化施教和輟課率降低具有重要的參考和指導意義。下一步研究工作的開展主要從以下兩個方面入手,一是在微課和討論2項課程活動中應用預測和干預模式,進一步驗證模型效率;二是應用計算機技術和教育學理論,提升預測的準確度,為個性化干預提供更精準的支持。
參考文獻(References):
[1]http://www.rcoe.edu.cn/?p=4 269
[2]https://baijiahao.baidu.com/s?id=1647805030394904836&,A,fr=spider&for=pc
[3]Le C V,Pardos Z A,Meyer S D,et al_Communication atScale in a MOOC Using Predictive EngagementAnalytics. Lecture Notes in Computer Science, 2018:239-252
[4] Gardner, J., & Brooks, C. Student success prediction inMOOCs. User Modeling and User-Adapted Interaction,2018.28(2):127-203
[5] Pardos, Z. A., Tang, S., Davis, D., & Le, C. V. EnablingReal-Time Adaptivity in MOOCs with a PersonalizedNext-Step Recommendation Framework. Proceedingsof the Fourth (2017) ACM Conference on Learning @Scale - L@S '17:23-32
[6] Andres, J. M. L., Baker, R. S., Gasevie, D., Siemens, G.,Crossley, S. A., &Joksimovie, S. Studying MOOCcompletion at scale using the MOOC replicationframework. Proceedings of the 8th (2018)lnternationalConference on Learning Analytics and Knowledge-LAK '18:71-78
[7]盧曉航,王勝清,黃俊杰 . -種基于滑動窗口模型的 MOOCs輟學率預測方法 [J].現代圖書情報技術 ,2017.4:67-75
[8]王雪宇,鄒剛,~驍 .基于 MOOC數據的學習者輟課預測研究[J].現代教育技術,2017.6:95-101
[9] Ho A D, Reich J, Nesterko S O, et aL HarvardX and MITx:The First Year of Open Online Courses, Fall 2012-Summer2013[J]. Social Science Electronic Publishing,2014:1-33
[10] RenZ ,Rangwala H , Johri A . Predicting Performance onMOOC Assessments using Multi-Regression Models,2016.
[11] Xing, W., Chen, X., Stein, J., &Marcinkowski, M.Temporal predication of dropouts in MOOCs:Reaching the low hanging fruit through stackinggeneralization. Computers in Human Behavior,2016.58:119-129
[12] Fei, M., &Yeung, D.-Y. Temporal Models for PredictingStudent Dropout in Massive Open Online Courses.2015 IEEE International Conference on Data MiningWorkshop (ICDMW),2015:256-263
[13] Crossley, S., Paquette, L., Dascalu, M., McNamara, D.S., & Baker, R. S. Combining click-stream datawith NLP tools to better understand MOOC comple-tion. Proceedings of the Sixth (2016)lnternationalConference on Learning Analytics & Knowledge- LAK '16:6-14
[14] Joksimovie, S., Manataki, A., Gasevie, D., Dawson, S.,Kovanovie, V., & de Kereki, I. F. Translatingnetwork position into performance. Proceedings ofthe Sixth(2016) International Conference on LearningAnalytics & Knowledge - LAK '16:314-323
★基金項目:湖南省教育廳科學研究項目“基于移動微課的非結構化教育資源個性化推送算法研究”(16C0804)
作者簡介:蔣翀(1980-),女,湖南黔陽人,碩士,講師/高級工程師,主要研究方向:推薦系統,個性化技術,教育信息化。
