基于U-net的直腸癌智能分割
2020-09-15 16:30:34譚俊杰鐘妤黃澤斌
計算機時代 2020年8期
譚俊杰 鐘妤 黃澤斌
摘要:近年來,隨著醫學影像與大數據的發展,通過人工智能來處理圖像,從而給醫生帶來輔助性的診斷參考成為廣大學者的研究熱點。文章利用U-net網絡對直腸癌CT影像進行智能分割,加入了圖像增強、批歸一化等技巧緩解過擬合現象,并通過多次實驗確定最佳初始學習速率和卷積核數目,在驗證集上的Dice系數達到0.9329。實驗表明,U-Net對小數據集的醫學圖像分割有很好效果,對正負樣本極度偏斜的數據集,使用Dice系數可以準確地衡量分割的相似程度。
關鍵詞:直腸癌;圖像分割:U-net:Dice系數
中圖分類號:TP301.6 文獻標識碼:A 文章編號:1006-8228(2020)08-18-03
0 引言
近年來,我國直腸癌發病率呈顯著上升趨勢,特別是在大城市,已躍居惡性腫瘤發病率排行榜前三位。研究顯示,有65%的患者的發病時間是在40歲之后,其中男女比例為23:1,并且發病率最高的人群年齡分布在40歲-50歲。
醫學圖像分割是臨床診斷和治療的關鍵技術,能夠提供準確可靠的診斷依據。隨著深度學習中圖像翻譯算法的普遍應用,醫學圖像分割技術也獲得了巨大的進展。尤其在U-Net網絡結構被提出后,該網絡一直在醫學圖像分割領域表現優秀,眾多研究者利用此模型進行醫學圖像分割[1],并在此基礎上提出改進。本文研究來自于第七屆“泰迪杯”數據挖掘挑戰賽B題,對直腸CT影像中的腫瘤分割問題提出一種基于深度學習U-Net網絡結構的分割方法。
1 數據預處理
1.1 數據清洗與劃分
本數據集共有107個病例,3029張CT影像及對應的掩模圖,數據樣本為512×512像素。而且每個病例有1745張CT影像序列。其中,有腫瘤區域的CT影像僅有860張且腫瘤區域在CT影像中占比較小,屬于正負樣本不平衡的數據集。因此,在劃分數據集時,為使訓練集、驗證集和測試集的正負樣本分布盡可能地相近,將病例數作為劃分對象,訓練集、驗證集、測試集的個數分別設置為65個(即0.6)、16個和26個。
通過掩模圖,可觀察出腫瘤位置均在圖像的一定區域內,因此,本文運用OpenCV庫計算出腫瘤區域的最大最小像素值。經統計,長為126-382,寬為202-458的像素范圍能包含所有腫瘤特征。因此,最終將數據集裁剪成256x256大小的影像,即過濾了無關特征,同時節省資源,減少計算量。
1.2 圖像增強
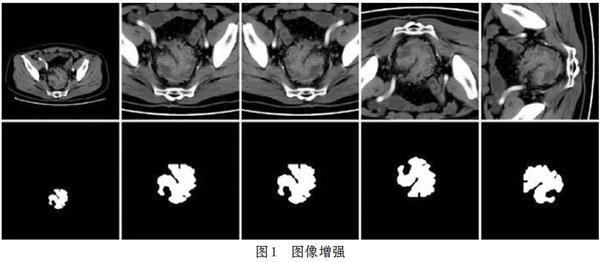
由于劃分后的訓練集只有1820張CT影像,對深度學習而言遠遠不足。因此,需要通過圖像增強[2]技術擴充訓練集樣本量,本文使用水平翻轉、垂直翻轉、90度旋轉以及翻轉和旋轉的組合將訓練集樣本量擴充至原來的6倍。圖像增強對模型性能的訓練有很大的提升,既可以減少過擬合現象的發生,又能提升模型的泛化能力。效果如圖l所示。
2 U-Net模型訓練
2.1 窗寬和窗位
由于CT影像的格式為DICOM,首先利用RadiAntDICOM Viewer軟件得出每個病例CT序列的最佳窗寬和窗位,其次利用SimpleITK庫讀取CT影像的HU值,將HU值儲存為數組后設置其最佳窗寬和窗位,使用灰度直方圖均衡化技術提高具體器官的對比度。最后在模型訓練前,對樣本數據做均值方差歸一化,大幅度減少計算量。
2.2 U-Net結構
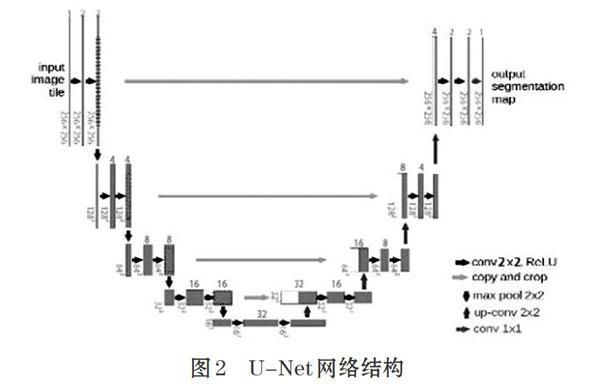
U-Net網絡結構是全卷積神經網絡[3](FCN)基礎的改進,主要包括卷積、池化和反卷積三大步驟。其中,卷積操作中每一個卷積塊包括兩次卷積,然后是最大值池化操作,通過10次卷積操作后先結合對應大小的特征圖進行反卷積操作使圖像大小翻倍而通道數縮減一倍,再進行兩次卷積操作,激活函數為ReLU。
本文針對醫學圖像數據集對U-Net網絡結構進行超參數調整,由于腫瘤占圖像范圍區域小,提取的特征數太多易導致過擬合。經過多次實驗,本文對256×256大小的輸入圖像初始提取兩個特征,每經過一次最大值池化,提取的特征數翻倍。每個卷積核的大小設置為3x3,其中步長為l,Padding設置為same,這樣即可保證卷積后的圖像與原來圖像大小一致。反卷積操作后再經過一層卷積層,卷積核大小為1x1,利用Sigmoid函數進行二分類。U-net網絡結構如圖2所示。
本文在卷積和反卷積操作后加入批歸一化( Batch_Normalization)的操作,使上一層傳遞到下一層的參數分布保持一致,這既能加快訓練速度,防止低層次神經網絡的梯度在反向傳播中消失,又能減少參數初始化的影響。
2.3 衡量指標
考慮到這個數據集中陽性和陰性樣本的極端不平衡,因此本文模型的衡量指標選擇使用Dice系數Ⅲ,模型的損失函數是1-Dice系數。兩個輪廓區域所包含的點集分別用A、B來表示,通過計算公式可知,它可以衡量A、B的相似程度。
2.4 超參數
本文使用Adam算法優化損失函數,它結合了AdaGrad和RMSProp兩種優化算法的特點,能對每次梯度的學習速率進行調整,同時后期不會使學習速率衰減至很小而導致模型無法學習。
經過多次實驗,本文設置的初始學習速率為1x10-5,雖然小的學習速率需要更多的訓練次數,但模型結果會比較好;而較大的學習速率使學習曲線大幅震蕩,甚至還可能導致梯度朝著錯誤的方向更新。
每次迭代傳入8張CT圖和對應的掩模圖進模型中訓練,若批量( Batch)設置過小,模型需要消耗更多時間訓練,且會使批歸一化的效果不明顯;若批量設置過大,雖然加快訓練速度,但更容易出現過擬合。
3 實驗結果
3.1 模型結果
本文使用Tensorflow為后端的Keras框架結構搭建U-Net網絡[5],并在服務器上使用GPU對加速模型訓練。模型參數共有31507個,訓練一次所花費的時間為44秒,最終在第45次訓練結束后,訓練集上的Dice系數達到0.9803,驗證集上的Dice系數達到0.9329,訓練曲線如圖3所示。
3.2 結果分析
通過觀察訓練曲線,模型沒有明顯過擬合,且梯度更新較大,在前10次訓練中,訓練集和驗證集上的Dice相似,甚至出現欠擬合,原因在于使用圖像增強技巧加大了模型的訓練難度。訓練10次后,學習速率出現緩和,但后來又比之前更加陡峭地上升,并且在第40次訓練結束后過擬合越來越明顯。
學習率越來越陡峭,這說明過擬合程度已經逐漸增大。并且當Dice值大于1后,模型會學習更多其他區域的特征而導致嚴重過擬合。因此當前訓練集上的Dice系數大于1時,應停止訓練。
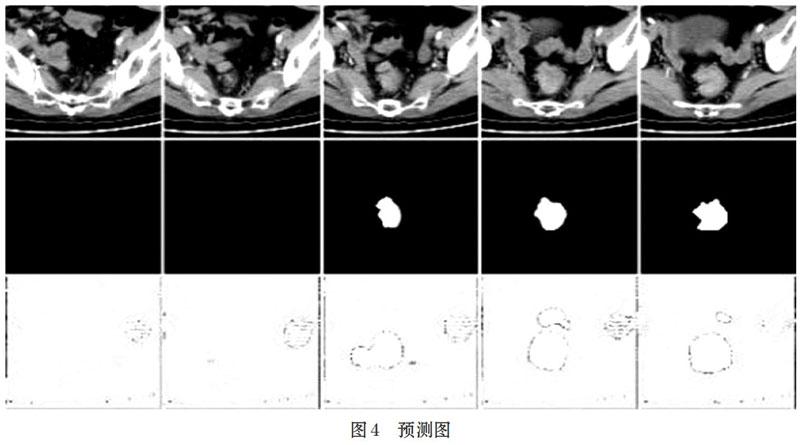
在圖4中,第一行為測試集中隨機一個病例的5張CT影像,第二行是對應的掩模圖,第三行是模型的預測結果。通過觀察得出U-Net模型能準確分類出有無腫瘤的CT影像,但預測的腫瘤邊緣不夠細致,而且存在一定的過擬合。同時,預測圖中非腫瘤區域是灰白色,說明CT圖像與輪廓濾波器進行卷積運算時,還不能把腫瘤區域和非腫瘤區域的輪廓區分得很明顯,模型還需要進一步改進。
4 總結
本文基于深度學習中U-Net網絡對直腸癌腫瘤區域進行圖像智能分割。經過超參數調整后,驗證集上的Dice系數達到0.9329,可以準確區分有無腫瘤的CT影像,一定程度上能夠給予醫生輔助性的診斷參考意見,減輕醫生的工作負擔。但預測的腫瘤區域輪廓不夠細致,且模型容易出現過擬合,主要原因在于模型的訓練樣本還不夠充足和豐富,相信在樣本量增大后,模型一定有顯著提升。
參考文獻(References):
[1]吳銳帆,代海洋,楊坦,江穎,蔡志杰.直腸癌淋巴結轉移的智能診斷研究[J].數學建模及其應用,2019.8(4):30-37
[2]李雯.基于深度卷積神經網絡的CT圖像肝臟腫瘤分割方法研究[D].中國科學院深圳先進技術研究院,2016.
[3]周魯科,朱信忠.基于U-net網絡的肺部腫瘤圖像分割算法研究[J].信息與電腦(理論版),2018.5:41-44
[4]袁甜,程紅陽,陳云虹,張海榮,王文軍.基于U-Net網絡的肺部CT圖像分割算法[J].自動化與儀器儀表,2017.6:59-61
[5]張凱文.基于U-Net的肝臟CT圖像分割研究[D].華南理工大學,2019.
作者簡介:譚俊杰(1997-),男,廣東佛山人,本科,主要研究方向:深度學習、數據挖掘
通訊作者:黃澤斌(2000-),男,廣東普寧人,本科,主要研究方向:數據科學,數據挖掘
