一種基于單調鏈和Geohash索引的公共邊裂縫處理算法
2020-09-22 02:08:12鄧涵文馮賢菊廖雪花李曉寧
四川師范大學學報(自然科學版) 2020年5期
楊 偉, 鄧涵文, 馮賢菊, 廖雪花, 李曉寧*
(1.四川師范大學計算機科學學院,四川成都610101; 2.河南工業職業技術學院電子信息工程學院,河南南陽473000)
矢量數據壓縮在計算機圖形學、地理信息系統(GIS)和數字制圖等方面的應用非常廣泛,其中較為廣泛使用的壓縮方法為Douglas-Pecucker算法[1]及其一系列的改進算法,其中改進算法大多側重于算法時間效率的優化[2]、距離閾值的計算[3-4]、自相交和相交拓撲異化問題的處理[5-7]等.在壓縮過程中,保持數據的拓撲一致性對數字制圖和GIS都至關重要[8].然而,大多數矢量數據壓縮算法在壓縮數據時并不考慮數據的空間關系,壓縮后出現拓撲關系不一致[9],如在對共享公共邊的無拓撲矢量圖形壓縮時存在公共邊裂縫的拓撲不一致問題.出現這一拓撲異化問題的根本原因是無拓撲矢量圖形的共享邊被存儲多次,當壓縮算法對起止點敏感時,共享公共邊的兩相鄰圖形因起始點和結束點不同,壓縮后導致共享邊在2個圖形中出現不同的化簡結果[10].如圖1(a)所示,多邊形 A 與 B 共享頂點{P6,P7,P8,P9,P1},多邊形 A、B 經壓縮算法化簡后,頂點P7從A中刪除,但沒有從B中刪除,公共邊{P6,P7,P8,P9,P1}在2 個圖形中的壓縮結果不一致,因而出現圖1(b)中的裂縫.
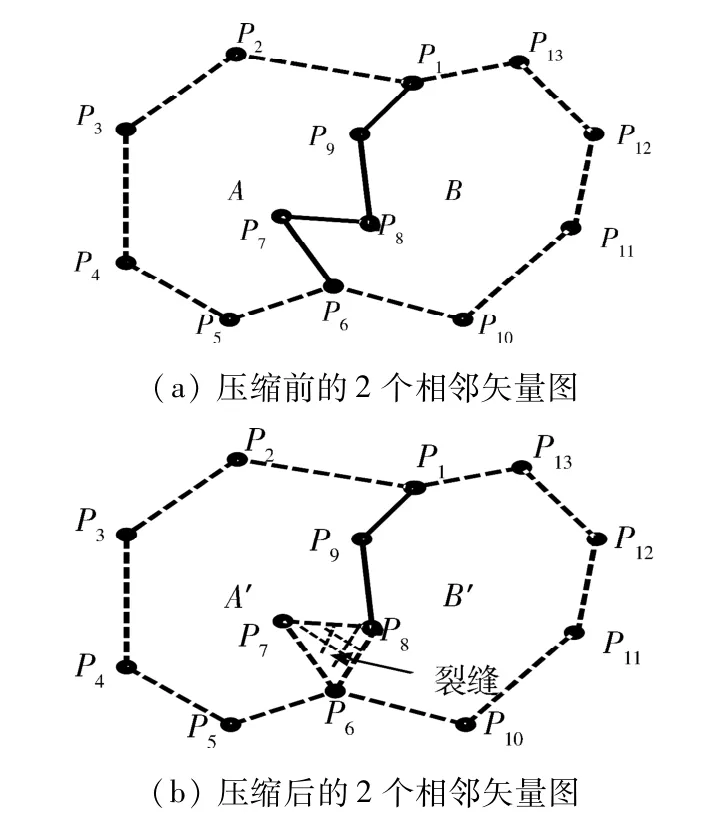
圖1 公共邊裂縫問題Fig.1 Common edge crack problem
針對這一問題,翟戰強等[11]采用窮舉搜索思想查找多邊形的公共邊,對公共邊和非公共邊分別壓縮.王凈等[12]采用深度搜索匹配法在整個矢量數據范圍內查找公共邊,將其從多邊形數據中獨立出來重組數據,然后用DP算法進行壓縮.張勝等[13]采用正向搜索和反向搜索相結合的方法提取公共邊生成等效元數據,對元數據壓縮后再重建數據并按原格式存儲.吳正升等[14]提出一個約束點串建立算法提取公共邊的首尾端點,將多邊形邏輯分段,然后再壓縮各個分段.同文獻[12-13]的方法相比,文獻[14]的算法所需輔助空間較少,但公共邊被多次壓縮,因而時間效率不高.謝亦才等[15]利用字符串的模式匹配算法(KMP算法)提取公共邊,根據公共邊對象的壓縮標記保證公共邊只壓縮1次.金良益等[16]指出了深度搜索匹配法提取公共邊的不足,提出了一種基于共線搜索匹配的公共邊提取算法.此外,金良益[17]將公共邊的提取轉化為找最長公共子串,提出了一種基于動態規劃的無拓撲矢量化多邊形公共邊提取算法.趙真等[18]提出了考慮空間對象拓撲關系的壓縮算法,保留了拓撲關系,解決了公共邊壓縮后出現裂縫的問題.
上述文獻均采取化簡前提取多邊形的公共邊,對公共邊和非公共邊分別壓縮的策略,保證公共邊去除的頂點保持一致.該類算法雖可解決公共邊裂縫問題,但時間效率比較低,主要原因有以下3點:
1)每個矢量圖形均需要同其他矢量圖形進行是否相交判斷,假設矢量圖形數為m,則相交判斷的時間復雜度為O(m2);
2)提取公共頂點的方法大都采用雙向深度搜索匹配法、模式匹配算法或動態規劃算法,這一類算法在搜索多邊形數量較多時效率不高;
3)公共邊在壓縮時可能被壓縮處理多次.
原因2)為制約算法效率的關鍵.為解決上述問題,本文提出了一種基于單調鏈和Geohash索引的公共邊裂縫處理算法.
針對以往模型做了以下3點改進:
針對1),為了避免在整個圖形集中進行相交圖形的判斷,本文采用單調鏈掃描線算法,通過建立矢量圖形單調鏈,提前過濾掉了大量相離圖形,大大減少需要進行相交判斷的矢量圖形數,一定程度上提高了算法效率;
針對2),本文利用Geohash編碼長于快速搜索的特性,構建Geohash索引結構,將空間劃分為一個個矩形區域,實現兩相交圖形的公共頂點快速查找,大大提高了公共點的查找速率;
針對3),設計了一個索引結構存儲公共邊的壓縮信息,當檢索到公共邊已被壓縮過時,則直接根據索引結構提取公共邊的第一次壓縮數據,在保證公共邊只壓縮一次的條件下保證圖形的完整性和一致性.
1 基于單調鏈和Geohash索引的公共邊裂縫處理算法
基于單調鏈的掃描線算法常用于平面線段集合求交中過濾大量候選線段[19].基于此,本文將其應用于矢量圖形集的預處理,用于從眾多的矢量圖形中挑選出可能與當前圖形相交的矢量圖形.其次,對每個矢量圖形,計算每個頂點的Geohash編碼,創建Geohash索引表.然后,利用Geohash索引快速查找的特性,根據圖形的相交圖形,在圖形中找到公共點和非公共點,并據此將矢量圖形劃分為公共邊集合和非公共邊集合.最后,對公共邊和非公共邊分段壓縮時,對壓縮過的公共邊建立索引,保證公共邊只壓縮一次.
算法可粗略分為初始化圖形單調鏈、生成相交圖形集、建立Geohash索引表、提取公共邊和分段壓縮5個步驟.依次詳述如下.
1.1 初始化圖形單調鏈單調鏈掃描線算法的前提就是生成矢量圖形的單調鏈.為此,本文利用堆排序算法,根據每個矢量圖形的最小外接矩形MBR(Minimum Bounding Rectangle)的最小橫坐標 xmin對圖形集進行排序,生成一個xmin值由小到大的單調鏈,記為 MC(Monotonic Chain).MC 中圖形的xmin單增,如果多個圖形的xmin相同,則按其最小縱坐標ymin由小到大排序.如圖2所示的矢量圖形集{A,B,C,D,E,F,G},排序后生成的圖形單調鏈 MC為{A,D,B,E,C,F,G}.
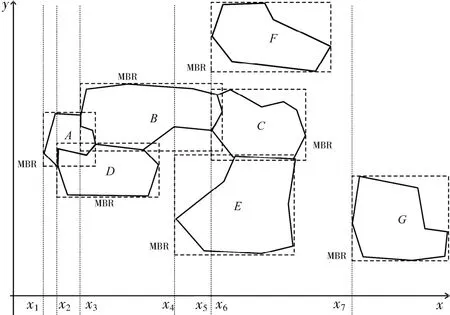
圖2 圖形集示例Fig.2 A graphics set example
1.2 生成相交圖形集基于生成的單調鏈MC,利用掃描線算法掃描單調鏈MC中的矢量圖形,確定每個圖形的相交圖形集.涉及的數據結構有:MC,含義同上;AC(Active Chain)記錄同當前掃描線相交的矢量圖形集合;RS(Related Shapes)為圖形的相交圖形集.
設單調鏈MC中有k個圖形,過每個圖形Si的MBR 的 xmin做縱向掃描線,記為 xi(i=1,2,…,k).初始化AC={},對每一個xi,依次執行如下步驟:
1)如果AC中圖形的MBR的xmax≤xi,從AC中刪除該圖形;
2)將該圖形Si插入AC;
3)將新插入圖形Si,同AC中已有圖形逐一進行最小外接矩形的相交判斷,若AC中已有圖形與新插入圖形Si相交,則將該圖形保存在新插入圖形Si的相交圖形列表RS中.
表1以圖2所示的圖形集為例,說明生成相交圖形集的執行過程.圖形C、F的MBR的xmin相同,所以掃描線x5和掃描線x6相同,分別代表圖形C、F生成相交圖形列表的過程.
通過上述掃描過程,可以過濾掉大量相離圖形,快速確定每個矢量圖形的相交圖形.結束掃描后,每個圖形都生成一個列表RS,記錄了與自己相交的所有矢量圖形,為下一步的公共邊提取處理提供了基礎數據.

表1 相交圖形集的生成過程Tab.1 Generation process of intersecting graphics sets
1.3 建立Geohash索引表Geohash編碼將二維的經緯度坐標編碼成一維的字符串,在實現鄰近點搜索時具有快速查找的顯著優勢[20].Geohash編碼技術廣泛應用于空間數據的檢索,其編碼過程實際上是將區域劃分為一個個規則矩形,并對每個矩形進行base32編碼.Geohash編碼長度越長,區域劃分越細,搜索時的效率越高.例如經緯度坐標為(116.389 550,39.928 167)的空間點,按 Geohash 編碼生成的二進制序列為11100 11101 00100 01111,按base32編碼為wx4g,實際上是表明該點落在wx4g代表的矩形區域.
Geohash索引表的建立的過程如下:
對MC中每一個圖形Si,初始化一個Hash表HTi為空.對圖形Si中的每一個頂點Vk,
1)計算頂點Vk的Geohash編碼Code;
2)若Code在索引表HTi的表項中已存在,則將坐標點插入到Geohash編碼對應的鏈表之后,否則在索引表中新增一項,并保存Geohash編碼和坐標點到該項對應的鏈表.
按上述算法,MC中每一個圖形都會生成一個類似圖3的Geohash表.Geohash索引表中的每一項都由鍵值Geohash編碼及其對應的坐標點鏈表組成,鏈表中存放Geohash編碼相同的坐標點,提供了Geohash編碼和坐標點之間的映射關系.
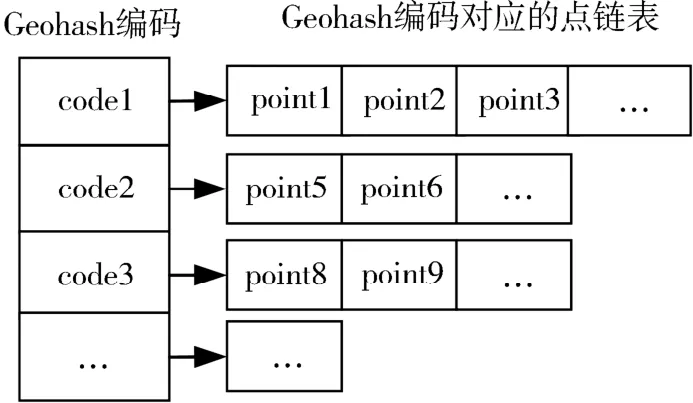
圖3 Geohash索引表示例圖Fig.3 Example diagram of Geohash index table
通過鍵值Geohash編碼來檢索落在某個區域的坐標點,只需搜索Geohash編碼對應的鏈表中的坐標點即可,速度非常快.當編碼長度較大時,鏈表中的坐標點個數接近于1,檢索坐標點的時間復雜度接近于 O(1).
1.4 公共邊提取公共邊提取的前提是公共點的判斷.根據上一節為每個圖形建立的Geohash表,對于相交的2個圖形A和B,判斷A上一點point是否為A和B的公共點的方法如下:
1)計算點point的Geohash編碼,假設為code2;
2)在圖形B的Geohash索引表中查找key值為code2的項.如找到,轉3);如未找到,point為圖形A、B的非公共點;
3)找到該項對應的坐標點鏈表(如圖4中虛線框部分),比較point與鏈表中的點坐標是否相同.若相同,則point為公共點,否則為非公共點.
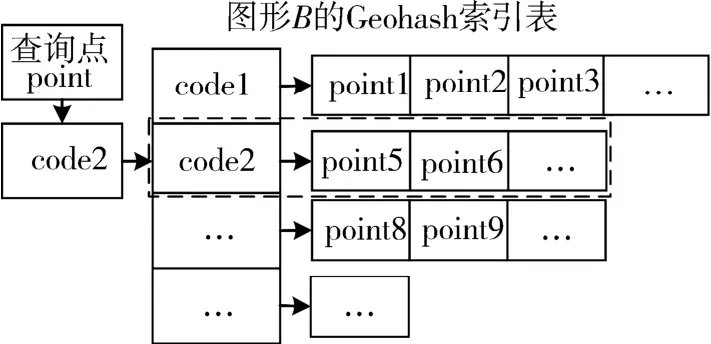
圖4 公共點查找示意圖Fig.4 Example diagram of finding common points
公共邊提取實質上是公共邊端點的查找.假如端點已經確定,以之作為約束點,即可在約束點處將多邊形從邏輯上分段,拆分為公共邊和非公共邊.
假設圖形 A 頂點記為 ai,i=1,2,…,m;圖形 B為 A 的一個相交圖形,其頂點記為 bj,j=1,2,…,n.圖形A中的有2個相鄰頂點ai和ai-1,根據2個相鄰頂點是否是公共點這一特性,可劃分為4種可能:
1)若ai為公共點且ai-1為非公共點,則ai為公共邊的端點.ai和圖形B中與ai坐標相同的頂點bj分別為圖形A和B的拆分點,如圖5(a).
2)若ai為非公共點且ai-1為公共點,則ai-1為公共邊的端點,ai-1和圖形B中與ai-1坐標相同的頂點bk分別為圖形A和B的拆分點,如圖5(b).
3)若ai、ai-1均為公共點,則需進一步判斷圖形B 中ai、ai-1對應的公共點bj、bk是否連續(包括正向連續或反向連續),若不連續,則ai-1、ai為公共邊的端點,ai-1、bk和 ai、bj均為圖形 A、B 的拆分點,如圖5(c);若連續,則 ai不是端點,ai-1是否為端點尚需結合ai-2是否為公共點來判斷.
4)若 ai、ai-1均為非公共點,則 ai、ai-1均不是公共邊的端點.

圖5 公共邊首尾點的3種情況Fig.5 Three kinds of end point cases on common edge
記sorta、sortb為記錄圖形A、B所有公共邊首尾點下標的有序鏈表.假設ai為公共點,bj為B中與ai坐標相同的公共點;ai-1為公共點,bk為B中與ai-1坐標相同的公共點,初始化i=1.根據上面的公共點判斷規則,在2個相交矢量圖形中查找公共邊端點的主要步驟如下:
1)讀取矢量圖形 A(a1,a2,…,ai,…,am)、B(b1,b2,…,bj,…,bn).
2)讀取矢量圖形 A 上點 ai(i=1,2,…,m)的Geohash編碼.
3)根據上面的公共點判斷方法,判斷ai是否為公共點.若ai為公共點,轉4);若ai為非公共點,轉 6).
4)若ai-1為非公共點,則ai為公共邊的端點,ai、bj應為拆分點(如圖6中的的情況),將其下標存儲在各自的排序表sorta、sortb,否則轉5).
5)若 i=m,則 ai為公共邊的端點,ai、bj為拆分點,將其下標存儲在各自的排序表sorta、sortb,轉7);否則進一步判斷bj下標同bk下標是否連續,即|j-k|是否等于 1,若不連續(|j-k|!=1),則 ai、ai-1為公共邊的端點,ai-1、bk和 ai、bj均為拆分點,將其下標存儲在各自的排序表sorta、sortb,轉7).
6)若ai-1為公共點,則ai-1為公共邊界的端點,ai-1、bk為拆分點(如圖6中的的情況),將其下標存儲在各自的排序表sorta、sortb;否則,轉7).
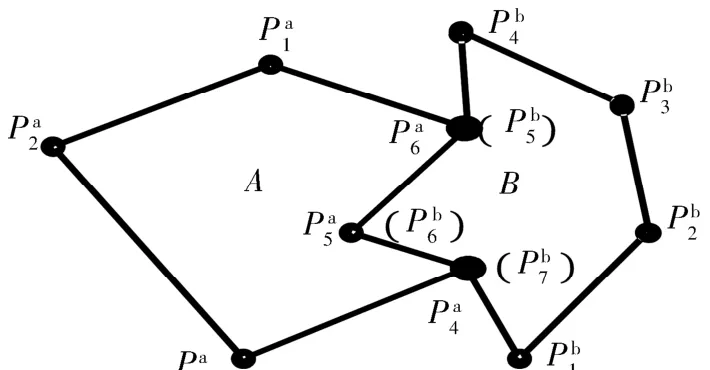
圖6 公共邊首尾端點的標記Fig.6 Mark the ends of common edge
7)i+ +,若 i>m 結束;否則,轉2).
待所有圖形處理完,每個圖形可得到一個記錄圖形拆分點下標的有序鏈表sort.根據這個有序鏈表對圖形進行邏輯分段,就可將圖形分為公共邊和非公共邊.如圖6所示,圖形A得到的有序鏈表為{4,6},可將其拆分成下標為1 ~4、4 ~6、6 ~1 的3個邏輯分段;圖形B的有序鏈表為{5,7},可將其拆分成下標為1~5、5~7、7~1的3個邏輯分段.
1.5 分段壓縮基于上一小節的提取結果,可將每個圖形邏輯分段為公共邊和非公共邊,依次對每個分段進行壓縮,能夠解決公共邊裂縫的問題.但公共邊在共邊圖形中至少出現2次,出于效率考慮的原因,希望其只被壓縮1次.為實現上述目的,并且保證所有共邊圖形的完整性和一致性,本文設計了一個索引結構表,用于為一個圖形保存有關公共邊壓縮的索引信息,如圖7所示.
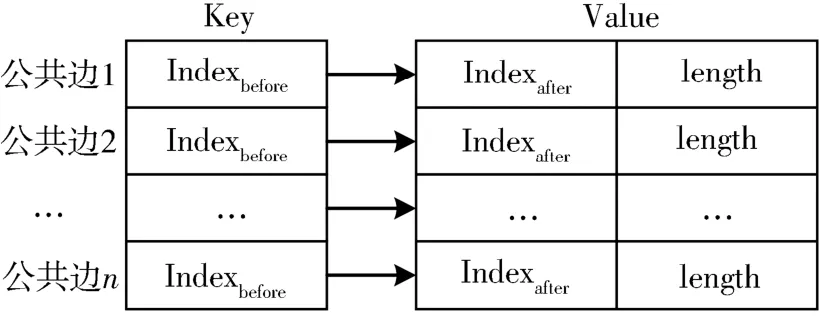
圖7 公共邊壓縮信息索引表Fig.7 Index table of common edge compression information
信息索引結構表中每個元素保存每條公共邊有關壓縮的必要信息,元素由(key,Value)鍵值對構成.其中key為公共邊壓縮前首點在原鏈表中的索引號;Value有2個數據段,一個為該公共邊壓縮后首點在新鏈表中的索引號Indexafter,另一個為公共邊壓縮后頂點的數量length.當圖形未被壓縮時,索引表為空;有公共邊被壓縮后,索引表記錄了圖形中公共邊的壓縮結果.
圖6所示的圖形A,只具有一條公共邊,其首尾點分別為{4,6}.假設該公共邊第一次壓縮,壓縮后非公共邊1~4由4個點約簡為3個點,公共邊4~6由3個點約簡為2個點,則A需要維護圖7所示的壓縮信息索引表,表中只有一個元素,其(key,Value)分別為(4,(3,2)).
分段壓縮時,首先根據有序鏈表數據將原點鏈表分解為多個邏輯分段.對于每一個分段,執行如下步驟:
1)如果該段為非公共邊,直接調用壓縮算法.
2)如果為公共邊,首先根據其首尾點索引號j、k找到其在共邊圖形中的對應索引號l、m.以l、m的最小值min(l,m)作為鍵值,在共邊圖形的壓縮信息索引表中查找該項是否存在.如果不存在,該公共邊未被壓縮,轉3);如果存在,該公共邊已被壓縮,轉4).
3)直接調用壓縮算法,并保存該公共邊的壓縮索引信息到圖形的公共邊壓縮信息索引表.
4)根據該項的Value,從共邊圖形壓縮后的頂點鏈表中,直接拷貝或者反序拷貝從Indexafter開始的length個頂點作為壓縮結果.
根據公共邊首尾點索引號j、k查找其在共邊圖形中的對應索引號l、m時,有可能會出現反序情況,如圖6所示,A中的公共邊頂點序號{4,6}在B中對應為{7,5}.在查找索引信息時,需根據較小值{5}作為查找的鍵值,同時拷貝公共邊壓縮數據時也需要反序.
1.6 算法整體流程綜上所述,從多個圖形對象中提取公共邊和非公共邊的算法流程如下:
1)對矢量圖形集進行堆排序,獲得圖形集的單調鏈MC.
2)通過掃描線算法掃描上述單調鏈MC,確定每個圖形的相交圖形列表RS.
3)構建所有圖形的Geohash索引.
4)相交圖形公共點的查找和標記.遍歷每個圖形,查找圖形和其相交圖形列表RS中所有圖形的公共點,根據公共邊首尾端點的判斷規則,標記公共邊的首尾公共點、邏輯分段公共邊和非公共邊.
5)分段壓縮.
設shapes為所有圖形的集合;MC為根據圖形最小包圍盒構建的單調鏈;AC為活動圖形鏈;RS[i]為第 i個圖形的相交圖形列表;HeapSort(shapes)用于生成圖形的單調鏈,其詳細的處理流程參見本文1.1 小節;CheckCross(e,s)用于判斷圖形 e、s的最小外接矩形是否相交;GeohashTable(s)用于為圖形s建立Geohash索引表,其詳細的處理流程參見本文 1.3 小節;MarkEndPoint(s,e)用于標記圖形s、e的公共邊端點,其詳細的處理流程參見本文1.4小節;Compress(s)用于壓縮圖形 s中的各個分段,其詳細的處理流程參見本文1.5小節.算法偽碼如下:
Input:shapes,vector graphics set and points have no labels
Ouput:shapes,vector graphics set and points have labels
Initializations:
-MC:monotonic chain of shapes,initialized to null;
-AC:active chain of shapes,initialized to null;
For every shape s in shapes{
/*Compute Minimum Bounding Rectangle*/
Compute MBR(s);
}
/*Sort shapes in the increasing order of the minimum x coordinate of its MBR and the minimum y coordinate if minimum x coordinates are equal*/
MC←HeapSort(shapes);
/*Build relative shapes collection for every shape in MC*/
M←count of shapes in MC;
For i←1 to M{
/*initialized related shapes set of the i th element of MC*/
RS[i]=null;
s←MC [i];/*the i th element of MC*/
/*the minimum x coordinate of MBR of shape s;
x←s.MBR.xmin;
For every shape e∈AC{
If e.MBR.xmax≤x then delete e from AC;
}
For every shape e∈AC {
If CheckCross(e,s)then insert(RS[i],e);
}
insert(AC,s);
}
/*Construct Geohash Table for every shape in MC*/
For every shape s in MC{
GeohashTable(s);
}
/*Label all end pointsfor every shape
For every shape s in MC{
For every shape e in RSof shape s{
/*Find and label end points of shape s and e
MarkEndPoint(s,e)
}}
/*Compress every shape sectionally
For every shape s in MC{
/*Compress every shape s
Compress(s)
}
2 實驗結果及分析
本文選取了3個數據集,實現了算法以驗證算法的性能.數據集分別為:中國省級行政界線Data1,世界地圖中的國家行政界線Data2,中國縣級行政界線Data3.3個真實矢量地圖數據集分別代表了不同數量等級和不同分布狀態的地圖數據,其參數如表2所示.
實驗環境如下,處理器:Intel(R)Core(TM)i7-7700HQ CPU @ 2.80 GHz;內存:8.00 GB.

表2 測試數據集參數列表Tab.2 Parameter list of three test data sets
2.1 公共邊提取與否對數據壓縮影響的定性分析針對上述3個數據集,本文采用經典Douglas-Peucker算法作為壓縮算法,對比直接進行壓縮處理的化簡結果和經本文算法做公共邊預處理后再壓縮的結果.總的說來,本文的公共邊提取算法,能夠保證公共邊的化簡結果一致,解決公共邊裂縫問題.
圖8給出了中國省級行政界線數據未做公共邊預處理和做公共邊預處理后壓縮結果的局部放大對比示例.圖8(a)中的粗實線為未做公共邊提取的壓縮結果,圖8(b)中的虛線為采用本文算法做公共邊提取后的壓縮結果.從局部放大圖可以看出,圖8(a)中圓圈部位發生了裂縫,而圖8(b)則保持了2段公共邊的化簡結果一致.
圖9給出了世界地圖國家行政界線數據未做公共邊預處理和做公共邊預處理后壓縮的局部放大對比示例.圖9(a)中粗實線為未做公共邊提取的壓縮結果,圖9(b)中的虛線為采用本文算法做公共邊提取后的壓縮結果.圓圈內國家行政邊界與多國接壤,圈內線段均為公共邊.從圓圈的局部放大圖可以看出,圖9(a)中圓圈部分粗實線線條多為雙線,表明多處公共邊被壓縮成不同的結果,而圖9(b)則保持了多段公共邊的化簡結果一致.

圖8 測試數據集Data1在2種情況下的化簡結果Fig.8 Different simplified results with or without extraction of common edges in Data1 set
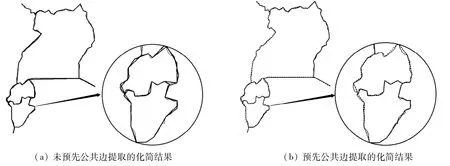
圖9 測試數據集Data2在2種情況下的化簡結果Fig.9 Different simplified results with or without extraction of common edges in Data2 set
從實驗結果來看,采用本文算法預先處理相鄰圖形的公共邊,可以保證公共邊在相鄰圖形中化簡結果的一致,解決常見的公共邊裂縫問題.值得注意的是,雖然都采用DP算法作為壓縮算法,但因為公共邊被拆分后,輸入DP算法處理流程的數據首尾點發生了變化,導致公共邊提取后的壓縮結果與不預先提取公共邊的結果有些細微變化.
2.2 算法的時間效率分析本文算法中涉及公共邊提取和分段壓縮2個部分,其中分段壓縮部分,其時間效率受壓縮算法的選取而不同,所以在時間效率分析上僅對公共邊提取部分的時間效率進行分析.假設M為圖形集中的圖形總數,N為圖形集中總的頂點個數,m為掃描次數(最壞情況下為圖形總數M),k為每次掃描要處理的圖形最大值(k?M),ni為圖形i的頂點總數,ki為圖形i的RS集合中包含的圖形數,L為Geohash編碼長度,S為Geohash編碼對應矩形區域所包含的點數的最大值,則公共邊提取算法的4個環節的時間復雜度分別為:
1)初始化圖形單調鏈,時間復雜度為O(M log2M).
2)生成每個圖形的相交圖形集合RS,時間復雜度為O(k*m).
4)公共邊的提取.需要遍歷每個圖形,查找圖形和相交圖形集合RS中圖形的公共點,標記首尾公共點.對于圖形i,判斷其上所有點是否為公共點共需要ni*ki*S次判斷,那么M個圖形總的時間復雜度為

其中,K=max(ki),K?M.
綜上,算法公共邊提取的時間復雜度為
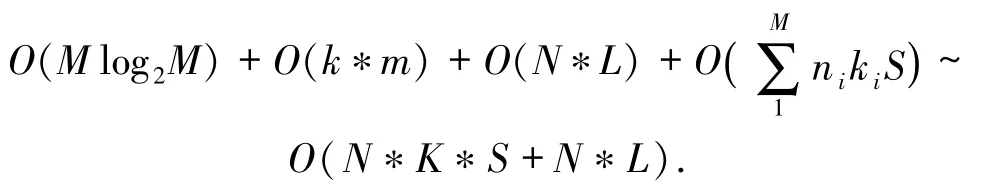
2.2.1 Geohash編碼長度對時間效率的影響 Geo-hash編碼在算法中的作用是減小公共點的搜索范圍.Geohash編碼長度L決定了搜索空間大小,是影響算法時間效率的重要因素.為測試編碼長度L對算法時間效率的影響,本文用1~9的編碼長度對3組數據集進行了公共邊提取實驗,其實驗結果如表3所示.可以看出,隨著編碼長度L的增加,提取公共邊的時間總體上呈先下降后上升的趨勢.這是因為隨著編碼長度L的增加,每個編碼所對應的矩形區域和落入該區域的頂點數越來越小,也就是說Geohash索引表中的頂點鏈表越來越短,查找公共點所花費的時間越來越少.在極限狀態下,每個編碼所對應的矩形區域最多只包含1個數據點,此時公共點的查找時間最短.此后,編碼長度的增加對于公共點查找時間沒有影響,但構建索引的時間一直隨編碼長度單調遞增.因此,提取公共邊的時間總體上呈先下降后上升的趨勢.在實際應用中,由于數據采集精度的限制,無論數據的體量大小、稀疏程度,編碼長度較為合適的取值范圍為4~6.例如,數據集Data1,頂點數在萬級規模,編碼長度為5時,提取公共邊耗時最小,為45.72 ms;數據集Data2,頂點數在十萬級規模,編碼長度為4時,提取公共邊耗時最小,為102.31 ms;數據集Data3,頂點數在百萬級規模,編碼長度為5時,提取公共邊耗時最小,為 1 246.22 ms.
同樣可以看出,提取公共邊所需的時間與數據規模成正向關系.在同一編碼長度下,隨著數據集頂點數、圖形數量的增加,提取公共邊所需時間也總體呈上升趨勢.在編碼長度為2~3時,數據集Data1提取公共邊所需時間明顯大于Data2的處理時間.這主要是因為Data1的圖形比較緊湊,每個圖形的相交圖形個數K較大的緣故.
2.2.2 算法時間效率的對比實驗與分析 為進一步驗證算法的時間效率,本文選用文獻[14,17]算法和本文算法進行對比,其實驗結果如表4所示.
可以看出,當Geohash編碼長度范圍為4~6區間,本文算法的時間效率明顯優于文獻[17]的動態規劃算法和文獻[14]的深度搜索算法.

表3 不同編碼長度、數據量和圖形分布狀態下的公共邊提取時間Tab.3 Common edge extraction time under different encoding lengths,data amounts,and graphics distribution ms

表4 3個不同算法的公共邊提取時間Tab.4 Common edge extraction time using three different algorithms ms
此外,本文還對公共邊壓縮一次和未作公共邊壓縮次數約束的時間效率進行對比,其結果如表5所示.設t0為公共邊壓縮次數未限制的壓縮時間,t1為公共邊壓縮一次的壓縮時間,時間減少率定義為(t1-t0)/t0.
可以看出,限定公共邊壓縮1次時,算法的效率也有一定的提高.但是對不同的數據集,效率提升不同.例如,差不多的壓縮率情況下,對數據集Data3,做了公共邊壓縮次數限定后,時間減少90.02%.而數據集Data2,做了同樣的處理,時間僅減少了19.92%.這可能跟數據集中公共邊的數量有關.
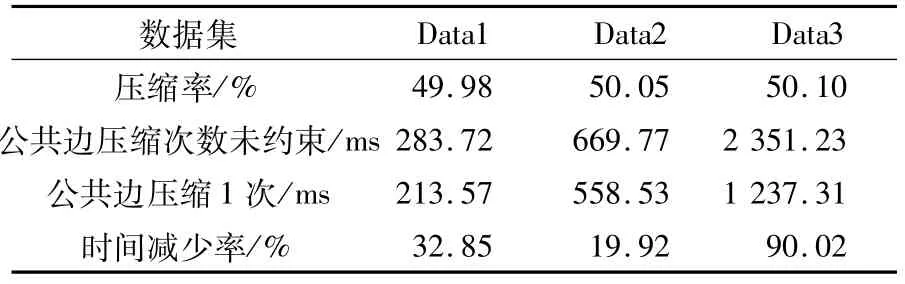
表5 公共邊壓縮次數處理前后的不同壓縮時間Tab.5 Different compression time before and after limiting common edge compression times
綜上,實驗結果說明了本文的公共邊提取算法,不僅能夠有效地解決公共邊裂縫問題,在時間效率上也具有較大的優越性.
3 結論
本文在分析多矢量數據壓縮時產生公共邊裂縫的原因,以及解決該問題的常用方法的優缺點的基礎上,提出了一種基于單調鏈和Geohash的公共邊裂縫處理算法,并通過實驗驗證了本文算法在解決裂縫問題上的有效性,對比分析了本文算法的時間效率.
本文還設計了一個公共邊壓縮信息索引表,用于公共邊多次壓縮時直接從第一次壓縮結果中提取數據,從實驗結果看,經過該環節處理后,壓縮時間也有比較明顯地減少.
本文算法不局限于任何壓縮算法,可作為一個預處理過程,在壓縮前對矢量數據進行邏輯分段,保證公共邊壓縮結果的一致性,從而解決公共邊裂縫問題.從實驗結果可以看出,Geohash編碼長度對于公共邊提取過程的時間效率的影響比較大,而本文僅從數據采集精度的角度給出了編碼長度的一個適當范圍,未涉及如何自適應的確定編碼長度這一問題,未來需進一步研究討論.
此外,本文算法在實現過程中,未過多考慮數據結構與算法的優化,如果進一步優化算法與數據結構,在時間效率上和空間效率上應當有提升的空間.
