基于分階段深度神經網絡的施工違章識別
2020-09-22 20:37:16劉思雨薛勁松景棟盛
軟件工程 2020年9期
關鍵詞:深度學習
劉思雨 薛勁松 景棟盛


摘 ?要:目前很多施工場地仍然使用人工方式檢測施工人員是否佩戴安全帽。針對此,設計并實現了一個基于分階段深度神經網的施工違章識別系統,用以檢測施工人員是否佩戴安全帽。系統利用深度神經網,通過在視頻中采樣獲得圖片,然后將其分割成若干子區域,接著利用預處理后的數據訓練模型,不斷優化提升識別精度,然后將訓練好的模型應用到系統中。在室內、室外和紅外線三個場景中進行測試。實驗結果表明,系統具有良好的實時檢測能力,總體平均正確檢出率達86.79%。
關鍵詞:違章識別;深度學習;神經網絡;物體識別;視頻監控
中圖分類號:TP18 ? ? 文獻標識碼:A
Construction Safety Violation Recognition based on Staged Deep Neural Network
LIU Siyu, XUE Jingsong, JING Dongsheng
(Suzhou Power Supply Branch, State Grid Jiangsu Electric Power Limited Company, Suzhou 215004, China)
lsy2801@163.com; 6802569@qq.com; jds19810119@163.com
Abstract: In many building sites, people still manually monitor whether the construction crew wear safety helmets or not. To solve this problem, this paper designs a safety-violation identification system based on phased deep neural network in order to locate the construction crews who appear without safety helmets. By using deep neural network, this proposed system samples pictures from videos, divides them into sub-sections, and then uses processed data to train the model. When the identification accuracy is high enough, the model is then applied to practical use. The model is tested respectively in indoor scene, outdoor scene and infrared scene. The experiment results show that this system can achieve good real-time monitoring, with an average correct detection rate of 86.79%.
Keywords: violation recognition; deep learning; neural network; object recognition; video surveillance
1 ? 引言(Introduction)
計算機在眾多領域得到了迅速的發展,其中包括計算機視覺技術、圖像技術等。不少工作研究如何將計算智能應用于各種領域[1,2]。通過視頻監控設備實時監控檢測施工場地中人員是否有違章操作就是很重要的一類應用場景。然而,目前大部分還是通過人工方式來查看施工人員是否違章,這種方法比較耗時耗力,而且由于人的工作時間也有限,無法實現全天候實時監控。隨著工作時間的增加,效率也會降低。因此,人工方式來檢測違章的情況存在一定的局限性。
針對此,本文設計通過深度學習來自動地檢測是否存在施工違章情況,生成并保存相應的違章。這種方法和人工方法相比,在識別準確率方面可能會下降,但是這種方式更加高效,并且大大節省了人工的成本。
2 ? 相關研究(Related studies)
2.1 ? 圖像處理技術
通過計算機來對圖像進行一些操作包括對圖像進行去噪,提取特征等類似方法的技術就是圖像處理技術。計算機軟硬件的發展、離散數學的發展,以及各種需求推動了圖像技術的發展。數學的對圖像處理技術的貢獻主要是在圖像處理的過程中需要將圖像信號轉換成數字信號,轉化成數字信號后,計算機就可以處理這種信號。圖像處理技術在農林、氣象和水利等眾多領域得到廣泛的應用。
圖像處理有幾個目的。第一個目的是提高圖像的視感質量,主要是讓圖像的質量變得更好;第二個目的是提取圖像中特征,在計算機分析圖像時這些特征至關重要;第三個目的是對圖像中數據進行處理,處理的方法主要是變換、編碼和壓縮,從而讓圖像的存儲和傳輸更為快捷。圖像處理技術有很多,而圖像分類是其中的一種,其主要內容是將圖像預處理,然后提取特征,根據特征來進行分類。圖像分類的方法有很多種,而人工神經網絡模式分類在圖像技術中的表現和以前的方法相比,更為準確,因此這種方法就越來越受到重視。
2.2 ? 人臉識別技術
人臉識別技術是近幾年興起的一種識別技術。這種識別技術是基于輸入的圖片的特征來識別,對于輸入的一張圖像,首先要做的就是判斷輸入的圖像中是否存在人臉。如果存在的話,則需要進一步給出臉的具體信息。這些信息中提取這張臉所對應的身份特征。然后將這個身份特征與已知的情況,即可知道這張臉的身份情況。廣義的說法是構建一個人臉識別系統,這個系統比較廣泛,包括人臉的定位,人臉的預處理等等;而只通過人臉來進行身份上的確認和廣義的人臉識別相比就是狹義上的人臉識別。
人臉識別技術主要采用的是特征分析算法,這個算法用到了兩個方面的技術,一個是計算機圖像技術,需要用圖像技術來提取圖像中的特征點,第二個是生物統計學原理,利用這個來分析特征點來建立對應數學模型,這個模型就是人臉特征模板。這個模板需要與被測的人的圖像來進行特征分析,特征分析會得到一個相似值。判斷是否為同一個人就是根據這個值推理出來的。
2.3 ? 分類問題
機器學習是一門交叉學科,主要研究怎樣讓機器更加智能化,是目前人工智能領域的一個重要方向,從誕生到現在經歷了若干個階段。機器學習的一些方法的應用逐漸從一些理論轉化為落地的產品,應用范圍更為逐漸變廣。
分類問題是機器學習中的基礎問題。目前很多落地的產品當中好很多就是分類問題的應用。現階段機器的計算能力很強,使得機器學習可以對海量的數據進行處理,由于數據的規模比較大,因此數據內部存在著有用的信息,因此機器學習可以通過這些數據可以挖掘出很多有用的信息。監督學習和無監督學習是機器學習中的兩種數據處理方式[3]。機器學習中的分類算法有很多,其中具有代表性方法包括決策樹[4]、支持向量機[5]、關聯規則[6]和AdaBoost算法[7]等。這些算法的步驟大致一致:首先,建立一個訓練模型,根據模型所需要的訓練數據和標簽,然后構建相應的模型;然后,驗證數據的輸入,模型建立好之后有對應的輸入和輸出,將裝備好的數據放入模型之中,模型會輸出結果;最后,將結果與數據對應的正確標簽進行比對,從而評價算法的效果。數據的驗證是算法準確率的體現,評價一個算法好壞最直接的標準就是準確率,因此需要測試數據來進行驗證數據。隨著精確率的不斷提高,模型就變得越來越好,模型就可以運用到現實之中。自深度學習提出以后,深度學習也可以運用到分類問題中,并取得了很好的效果。
2.4 ? 深度學習
深度學習與機器學習領域中的神經網絡有著特別大的關聯。深度學習也是學習海量數據中的潛在的信息,學到的信息對于對應的數據的解釋有著很大的幫助。深度學習的目的是使計算機更智能,可以識別各種問題,看懂各種圖像,聽懂各種語音。深度學習近兩年在各種方面的取得較好的成就,其中在文本、圖像、語音和生成式對抗網(Generative Adversarial Network, GAN)等方面取得了很好的效果。
深度學習與神經網絡有著很強的關聯主要是因為深度學習來源于人工神經網絡的研究。深度學習可以通過組合底層特征來發現數據的特征表示,形成更高級的特征。神經網絡是模擬人腦而建立的。深度學習就是通過這種方式來分析數據。深度學習中有很多網絡結構,其中包括卷積神經網(Convolutional Neural Networks, CNN)、循環神經網(Recurrent Neural Network, RNN)和長短期記憶網(Long Short-Term Memory, LSTM)等。卷積神經網是比較常見的一種網絡,第一個卷積神經網[8]計算模型是在Fukushima D的神經認知機中提出的,基于神經元之間的局部連接得到一種平移不變神經網絡結構形式。之后,有研究人員在此基礎上,用誤差梯度設計并訓練卷積神經網,在一些任務上得到優越的性能[9]。
3 ? 方法設計(Method design)
3.1 ? 訓練模型
訓練模型采用的卷積神經網所訓練的模型。輸入層、隱藏層和全連接層構成了卷積神經網絡[10]。神經網絡的輸是輸入層,本文中所使用的神經網結構中的卷積神經網,該網絡的輸入是一個像素矩陣,這個像素矩陣是圖片所對應的。卷積神經網絡示意圖,如圖1所示。
在圖1中,最左側的輸入是一個三維矩陣,矩陣長寬代表圖像大小,深度代表色彩通道。卷積神經網絡從輸入層通過不同的神經網絡結構將上層的三維矩陣轉化為下一層的三維矩陣,生成的三維矩陣作為下一層的輸入,直到最后一個全連接層。圖中的隱藏層中包括卷積層和池化層。而卷積網絡結構中最重要的部分就是卷積層。卷積層的輸入是上一層神經網絡的輸出,卷積層再次進行卷積操作從而獲得更抽象的特征。池化層的功能是縮小矩陣的大小,將高分辨率的圖像轉化為低分辨率的圖像。通過池化操作,最后一個全連接層的節點數就會減少。在經歷多隱藏層的操作后,最后通過全連接層來輸出結果。隱藏層的操作是圖像抽象提出的過程,在完成了特征提取后,通過最后的全連接層就完成分類。
在此基礎上,本文把一些符合安全條件的施工圖片和不符合安全的施工圖片放入此神經網絡中進行訓練,最后準確度高于90%的情況下,將此時的參數進行保存,得到了訓練后的模型。只要將施工中得到的圖片放入此模型中便可以得到施工中的人是否符合安全施工的條件。
3.2 ? 視頻處理
由于攝像頭獲取到數據是以視頻的方式呈現的,因此系統的輸入是視頻。然而視頻數據量很大,因此需要將視頻處理一下,以便做之后的處理。將視頻處理成需要的圖片是必不可少的。
目前的圖像處理技術很容易做到將視頻分割成圖片[11,12]。視頻中有幀率屬性,本文就是在幀率的基礎之上對視頻進行,按照15幀獲取一次圖片,在所使用的視頻中,每15幀為視頻中的1秒,如果間隔幀率比15小的話,獲取到的圖片就會更多,反正,獲得的圖片就會更少,本文采用1秒鐘截圖一次,盡量保存必要的信息。采用OpenCV技術來講視頻處理為若干圖片,第一步就是獲取視頻,這一步相當于輸入,獲取到對應的視頻后,然后獲取視頻的總幀數,然后設置一個標記,并且標記此標記為真,在標記為真的情況下,持續讀取視頻,按照每15幀的情況截圖視頻中當前的畫面,并保存在對應的文件下,直至視頻結束,在視頻結束后,讓標記變為假。獲取視頻總幀數的情況是保證獲取到的圖片數量不會太多,由于系統使用視頻幀率是已知的,因此規定每15幀取一張圖,在未知的情況下,可以通過總幀數和規劃獲取的圖片總量來決定多少幀獲取一張圖片。
3.3 ? 人臉識別
在圖片中,有一部分圖片中是包含人臉的,有一部分是不包含人臉的,因此需要將包含人臉的圖片挑選出來。本系統主要是來識別施工人員中是否穿戴安全帽的情況,因此需要將人臉和戴安全帽一起進行檢測。因此,本文中做工作首先就是先將每個圖中的人臉部分獲取到,然后將獲取到的人臉進行檢測,檢測人臉是否穿戴安全帽,穿戴安全帽的標記為真,反之,標記為假。
本文中采用的人臉識別技術主要是采用深度學習的方法,根據圖像中的內容,來檢測圖像中是否存在人臉,通過已經訓練好的檢測人臉的模型就可以做到,這種模型和其他的神經網絡模型一致,其中最重要的部分是數據。本文采用的模型是谷歌訓練好的模型。只要將一張圖片放入模型的輸入之中,就可以得到該圖所對應的人臉,根據輸入的圖片的名稱來以此命名對應輸出的圖片的名稱,這是因為一張圖中對應的人臉可能不止一個,因此需要這個操作。在得到這些人臉之后,我們可以把這些圖片放入檢測是否佩戴安全帽的模型之中,并根絕對應的情況來輸出未佩戴安全帽的圖片對應的原始圖片。
3.4 ? 分階段處理
由于系統比較復雜,因此需要采取分階段處理的方法去將復雜的問題轉化為若干個簡單的問題并分別處理,直至系統的完成。
第一個階段就是從視頻處理為圖片的階段,需要將視頻轉化為圖片,根據視頻中的幀率情況將視頻轉化為若干圖片,用以保證產生的圖片不會太多也不會太少,更加保證產生的圖片中包含臉的圖片不會被遺漏。第二個階段主要是針對產生的圖片的處理,由于視頻清晰度的原因,產生的圖片可能會由于視頻的原因而大小不一。對圖片處理的速度受到了圖片清晰度的影響,圖片越清晰,對圖片的處理的速度就越快。基于此,需要先對圖片進行處理,無關圖片的清晰度,都需要對其進行處理,從而保證后續的處理更加快捷。第三個階段就是將處理后的圖片進行人臉的識別,由于有圖片的預處理過程,人臉識別的部分的效果會更好,減小了識別過程中的誤差。第四個階段就是識別當前的人臉的圖片中是否佩戴了安全帽,如果沒有帶的話,此圖片就保留下來用以輸出。經過這種分階段的處理過,保證了實施性更高,速度更快,效果更好,準確率更高。
3.5 ? 算法描述
根據方法設計中所提到的各種技術,在提前訓練好兩個模型的基礎之上提出一個算法用以開發這個系統,其中第一個模型用以識別該張圖片中是否存在人臉,而第二個模型用以識別該張圖片中是否存在安全帽,圖片符合第一個模型識別下在第二個模型中得到了一個否的情況就是我們最后得到的情況,即該張圖片中存在人臉,但是并不存在安全帽。
算法1基于分階段深度神經網的安全違章識別
輸入:實時視頻
輸出:帶有安全帽的人員圖片
讀取輸入的視頻
根據幀率情況將視頻分解為合適的圖片集
For ?i←1 to 圖片集末尾 do:
調整當前圖片的大小
將圖片進行灰度化處理
If 當前圖片包含人臉:
圈出人臉并生成人臉圖片并放入一個新的圖片集
標記生成人臉的原始圖片
End For
根據人臉圖片集的標記情況去除原始圖片集中不包含人臉的圖片
For ?j←1 to 人臉圖片集末尾 do:
If 當前圖片包含安全帽:
根據當前圖片的標記,去除原始圖片集中對應的圖片
End For
返回處理后的原始圖片集
4 ? 系統效果展示(System effect display)
本文系統主要是通過對視頻進行處理,得到最后的不戴安全帽的人員的圖片并進行展示。系統監控的展示效果如圖2所示。其中,圖2(a)是室內場景效果圖,圖2(b)是室外場景效果圖,圖2(c)是紅外線場景效果圖。在本文中,對效果圖的涉及敏感的隱私信息部分進行了處理。
(a)室內場景效果圖 ? ?(b)室外場景效果圖 ? ?(c)紅外線場景效果圖
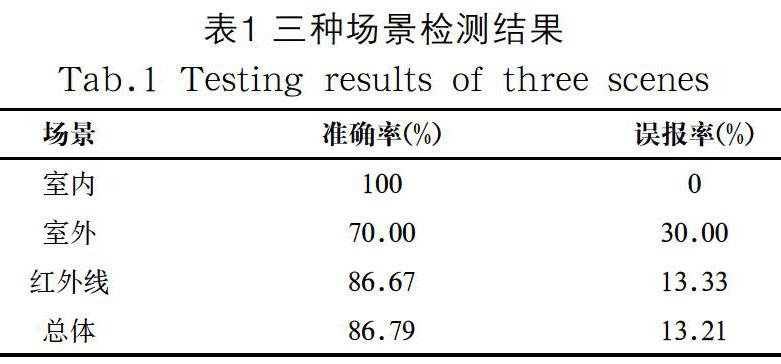
本文使用三種場景的視頻文件中所獲取的圖像作為訓練數據。在完成了訓練之后,本文分別在室內、室外和紅外線三個場景中對模型進行測試,統計分析正確率和誤報率,其中室內場景下得到圖像13張,檢測出未戴安全帽的圖像13張,正確率100%,誤報率0%,室外場景下得到圖像10張,檢測出未戴安全帽的圖像7張,正確率70%,誤報率30%,紅外場景下得到圖像30張,檢測到未戴安全帽的圖像26張,正確率86.67%,誤報率13.33%。通過分析可以發現,由于室外場景相對較為復雜,因此正確率較低。在三種場景中,總體正確率為86.79%,誤報率達13.21%,可以滿足識別需求。三種場景檢測結果統計如表1所示。
5 ? 結論(Conclusion)
本文提出了一個基于分階段深度神經網的施工違章識別系統,該系統可以面向視頻實現實時監控,識別出未按要求佩戴安全帽的人員。本系統提供了模型學習的功能,能利用監控視頻數據自動學習獲得檢測模型。用戶只要輸入所需要的視頻文件,就可以得到檢測模型。學習完成后,系統即可在此基礎上進行檢測。在本文實驗中,學習了兩個模型,并將其運用到系統中,實現了從視頻當中檢測出未佩戴安全帽的情況,獲得了較高的正確識別率。
參考文獻(References)
[1] 孫卓晟,彭來湖,倪利明,等.基于虛擬現實技術的機房動力環境監控系統設計[J].軟件工程,2020,23(3):28-31.
[2] 王昌海,申紅雪,張王衛,等.一種基于人臉識別的課堂教學監控系統[J].軟件工程,2020,23(1):48-50.
[3] 呂永標,趙建偉,曹飛龍.基于復合卷積神經網絡的圖像去噪算法[J].模式識別與人工智能,2017,30(2):97-105.
[4] 湯鯤,蔣炳南,彭艷兵,等.基于決策樹的多維屬性自動推理識別[J].計算機與現代化,2017(2):83-87.
[5] 游清順,王建新,張秀宇,等.基于支持向量機的食品安全抽檢數據分析方法[J].軟件工程,2019,22(2):29-31.
[6] 李昌盛,伍之昂,張璐,等.關聯規則推薦的高效分布式計算框架[J].計算機學報,2019(6):1218-1231.
[7] 黃健.基于深度學習與二維離散小波分解特征相融合的adaboost人臉識別模型[J].軟件工程,2020,23(2):43-46.
[8] 周飛燕,金林鵬,董軍.卷積神經網絡研究綜述[J].計算機學報,2017,40(6):1229-1251.
[9] 萬曉琪,宋輝,羅林根,等.卷積神經網絡在局部放電圖像模式識別中的應用[J].電網技術,2019(6):2219-2226.
[10] Jin K H, McCann M T, Froustey E, et al. Deep convolutional neural network for inverse problems in imaging[J]. IEEE Transactions on Image Processing, 2017, 26(9): 4509-4522.
[11] 周力,閔海.基于局部連接度和差異度算子的水平集紋理圖像分割[J].中國圖像圖形學報,2018,24(1):39-49.
[12] Ding, Changxing, Dacheng Tao. Robust face recognition via multimodal deep face representation[J]. IEEE Transactions on Multimedia, 2015, 17(11): 2049-2058.
作者簡介:
劉思雨(1994-),女,碩士,助理工程師.研究領域:智能信息系統,計算機應用.
薛勁松(1977-),男,本科,高級工程師.研究領域:網絡安全,智能化信息系統.
景棟盛(1981-),男,碩士,高級工程師.研究領域:軟件智能化,信息安全.
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
