基于分層特征化網絡的三維人臉識別
2020-09-29 06:56:10余元輝
計算機應用 2020年9期
趙 青,余元輝
(1.集美大學理學院,福建廈門 361021;2.集美大學計算機工程學院,福建廈門 361021)
0 引言
隨著人工智能和生物特征識別技術的快速發展,人臉作為重要的生物特征,人臉識別技術在生物特征識別、計算機視覺、圖像處理領域獲得熱門關注和高速發展,在金融、安防、安檢、手機APP 等眾多領域的相關應用也越來越廣泛。二維人臉識別技術已經相當成熟,但識別率仍受光照、姿態、表情等因素的影響,相對而言三維人臉數據受其影響較小,具有更好的魯棒性,同時包含的空間信息更加豐富,具有更高的防偽性,確保信息的安全性更高。因此,越來越多的學者將關注點轉向三維人臉識別技術的研究。
傳統的三維人臉識別技術主要是通過手工設計面部特征或將三維人臉數據投影為二維人臉圖像提取圖像特征[1],進行特征相似性度量實現識別。Drira 等[2]提出了一個幾何框架,從鼻尖點構建徑向曲線表示面部特征,通過彈性黎曼度量標準測量面部形狀差異,該方法在GavabDB 數據庫的仰視數據集取得了100%的識別率,但針對頭部向左、右旋轉的數據集識別率僅有70.49%和86.89%;在此基礎上,Lei 等[3]在三維人臉模型的半剛性區域設計了角徑向特征(Angular Radial Signature,ARS),并通過核主成分分析(Kernel Principal Component Analysis,KPCA)方法將原始ARS 映射為更具區分度的特征,通過支持向量機(Support Vector Machine,SVM)實現人臉識別,該方法開始進行大姿態數據的識別。機器學習算法興起后,將人臉數據進行標簽化處理,人臉識別問題轉換為監督分類任務。Xu等[4]針對表情和姿態數據集進行人臉分類識別,基于深度圖像和強度圖像提取Gabor 小波特征,并獲得深度、強度圖像的融合特征,使用AdaBoost級聯分類器完成人臉分類識別,在CASIA 數據庫上取得了91.2%的識別率,在小姿態(頭部偏轉±20°~±30°)和較大姿態(頭部偏轉±50°~±60°)數據集上分別實現了82.4%和61.5%的識別率。近年來,眾多研究人員進一步專注于利用深度學習框架自動學習數據特征并實現人臉識別[5-7]。Gilani 等[8]提出了第一個深度卷積神經網絡FR3DNet(Deep 3D Face Recognition Network)進行三維人臉識別,基于gridfit算法生成三維人臉模型對應的深度圖,以深度值、法向量的方向角、仰角三通道作為網絡輸入,在CASIA 數據集上的識別率較卷積神經網絡(Convolutional Neural Network,CNN)算法提高5 個百分點以上。Mu 等[9]專注于低質量三維人臉的識別研究,提出了聯合多尺度特征融合(MultiScale Feature Fusion,MSFF)模塊和空間注意力矢量化(Spatial Attention Vectorization,SAV)模塊的輕量級卷積神經網絡Led3D(Lightweight and efficient deep approach to recognizing low-quality 3D faces),以深度圖作為網絡輸入,采用二維人臉識別模式,在Bosphorus 數據庫上獲得91.27%的準確度。
基于深度學習的三維點云分類網絡于2017 年興起,Qi等[10]提出了PointNet 深度網絡用以實現三維點云數據的分類和分割,解決了點云無序性的問題,作為首個直接以三維點云作為輸入的輕量級網絡,其分類網絡提取點云數據的全局特征實現三維點云分類,但存在局部特征缺失的問題;在此基礎上,Qi 等[11]針對PointNet 網絡進行了改進,提出了PointNet++深度網絡,在PointNet++分類網絡結構中,通過采樣、分組、PointNet三層結構實現從局部特征到全局特征的提取,分類精度大幅度提升。Li等[12]在2018年提出了PointCNN 網絡,采用χ-卷積替換了PointNet 網絡中的微網絡T-Net,參數量極大減少,PointCNN 分類網絡準確度較PointNet 分類網絡有較大提升。2019 年,Cai 等[13]在PointNet++網 絡 的 基 礎 上 結 合PointSIFT[14]網絡提出 了空間聚合網絡(Spatial Aggregation Net,SAN)方法,基于多方向卷積提取三維點云空間結構特征,雖然點云分割取得最高精度,點云分類結果卻略低于PointNet++分類網絡。
PointNet 系列的分類網絡主要應用于物體或場景三維點云的分類,三維點云人臉模型不同于物體或場景點云,因此本文探索性地在PointNet 系列的分類網絡上進行三維人臉分類識別,并針對三維人臉模型存在因表情變化產生塑性形變、因姿態變化導致部分數據缺失的問題,提出了一種分層特征化網絡,即HFN(Hierarchical Feature Network)方法,也屬于輕量級網絡。單獨訓練好PointNet++和SAN 的分類網絡,進行特征提取的SA(Set Abstraction)模塊和DSA(Directional Spatial Aggregation)模塊均采用三層結構,將兩種不同的特征進行等維度拼接,HFN 利用拼接特征進行識別時網絡收斂更快,在CASIA數據集實現了96.34%的平均識別準確度,高于已有分類網絡的識別結果。
1 數據預處理
三維點云圖像在采集過程中,由于掃描設備或者外界環境等因素的影響,會出現數據缺損、離群點、數據冗余等問題,對識別結果造成影響;同時CASIA 數據庫中三維人臉的數據類型并不能直接作為分類網絡的輸入,因此,需要進行相關的數據預處理操作,獲取滿足要求的三維點云人臉數據。
CASIA三維人臉數據庫中人臉信息(圖1(a))是以塊方式存儲的,包含點的坐標、顏色、法向量、坐標索引四個部分。為了成功輸入分類網絡,將CASIA 數據庫中的WRL(3D virtual reality World object based on virtual Reality modeling Language)數據轉換為點云數據,包含坐標值[x,y,z]和顏色信息[r,g,b],并生成每個對象的對應標簽。利用統計學濾波器濾除原始點云數據的離群值,基于法向量結合周圍點云的拓撲結構建立同構關系,構建三角網,進而實現點云的孔洞填充。
1.1 反歸一化法確定鼻尖點
CASIA 數據庫中人臉點云模型如圖1(a)所示,可以表示為Fi=[xn,yn,zn,rn,gn,bn],其中,i=1,2,…,M表示點云模型的數量,n=1,2,…,N表示單個人臉模型中點云的數量。針對歸一化后的三維人臉模型采用文獻[15]中方法確定鼻尖點坐標{F1nose′,F2nose′,…,FMnose′}(不能確定側臉的鼻尖點坐標),利用反歸一化方法[16]獲得原始人臉模型中的鼻尖點坐標{F1nose,F2nose,…,FMnose}。為了去除肩膀、脖頸、耳朵等冗余區域,結合文獻[17]中方法裁剪出面部的有效區域(圖1(b)、(c))作為實驗數據。

圖1 CASIA數據庫中的三維人臉數據Fig.1 3D face data in CASIA database
2 分層特征化網絡
受PointNet++、SAN 分類網絡的啟發,為了在CASIA 數據集上取得更好的識別結果,使得分類網絡具有更好的魯棒性,在滿足網絡輸入要求的情況下,提出了分層特征化網絡(HFN)。
2.1 網絡結構
整個網絡結構分為兩層,核心為SA 模塊和DSA 模塊,如圖2 所示。網絡輸入點數為N,坐標維度為d,其他特征維度為C的點云,即點云大小為N×(d+C)。三個SA 模塊進行層次化處理:第一個SA 模塊提取點云局部區域的特征,第二個SA模塊再一次提取點云局部區域的特征,最后一個SA模塊采樣操作后獲得Ns個局部區域質心點,根據需要獲取以坐標為特征的點云全局特征,記為(Ns,C1d);與SA 模塊類似,三個DSA模塊基于多方向卷積的操作更加豐富了點云在三維空間中的結構特征,解決了點云密度不均的問題,前一個DSA 模塊的輸出作為下一個DSA 模塊的輸入,故第三個DSA 模塊基于八鄰域搜索方法采樣Ns個點,其特征記為(Ns,C2d);兩個模塊提取的點云特征拼接為(Ns,C1d+C2d),使得點云的特征較拼接之前的更加豐富,從而進一步解決了人臉表情、姿態導致點云數據缺失的問題。
SA 模塊 包含采樣層、分組層和PointNet 層。采樣層的目的是確定局部區域質心點,以歐氏距離d(?,?)為依據,通過迭代最遠點采樣算法(Farthest Point Strategy,FPS)[18]在人臉點云中{F|p1,p2,…,pN}采樣部分點云{Fs|ps1,ps2,…,psj},目的是在{F-Fs}找到psi滿足式(1):

最遠點采樣算法選擇的點分布均勻,令滿足要求的{Fs|ps1,ps2,…,psj}作為質心點;分組層是為了確定質心點的特定鄰域,以人臉點云N×d和質心點云Ns×d為輸入,通過設置特定半徑和特定點數的球形搜索鄰域,確定各個鄰域的點數B;PointNet 層作為SA 模塊中的微網絡,能夠將分組層確定的鄰域點的特征提取出來,提取多個局部區域特征并編碼成更高維的特征向量。
DSA模塊 包括采樣層、八鄰域搜索層和多方向卷積層。與SA 模塊類似,DSA 模塊采用最遠點采樣算法確定點云多個采樣點Ns,并基于八鄰域搜索方法獲得采樣點Ns的鄰域點B,運用多方向卷積操作提取采樣點的空間結構信息。多方向卷積包含從單個方向到兩個方向、兩個方向到四個方向、四個方向再到八個方向提取空間信息,最后經過最大池化層后輸出點云局部特征的特征向量,該方法更加全面地提取了從點云局部結構到全局結構的空間結構特征。
SA 模塊的點云全局特征和DSA 模塊的點云空間結構特征進行對應拼接,經過全連接層實現三維人臉數據分類。
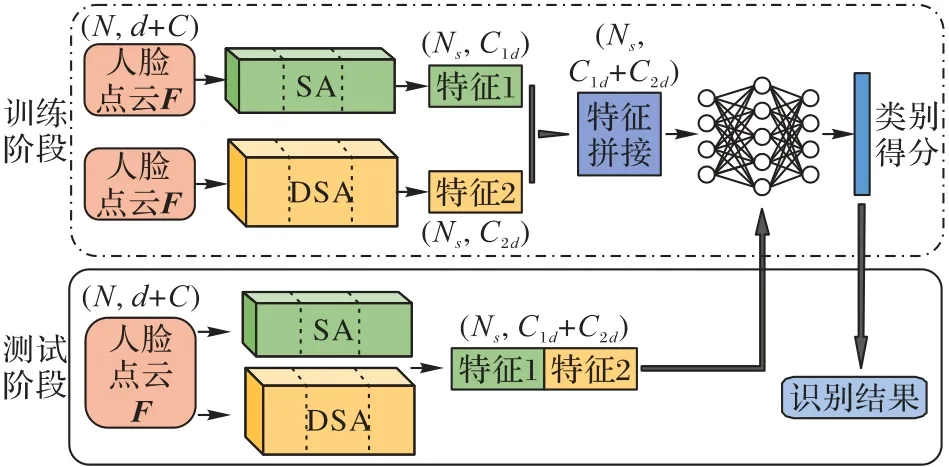
圖2 HFN結構Fig.2 Architecture of HFN
2.2 損失函數
損失函數用于衡量分類網絡的分類能力,表現預測類別與實際類別的差距程度,損失函數收斂時,值越小表明分類網絡的性能越好。為了衡量HFN 方法應用于三維人臉識別的分類性能,損失函數使用Softmax 的交叉熵函數,記為Loss:包含SA 模塊、DSA 模塊及HFN 方法的損失,并分配了相應的超參數:
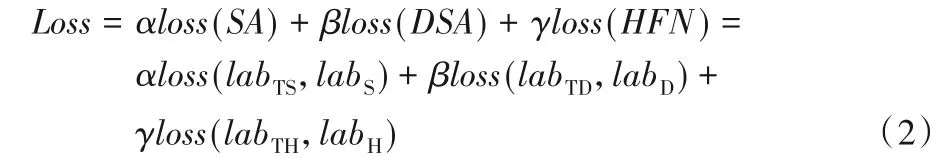
其中:labTS和labS分別為首次訓練SA 模塊所在網絡三維點云人臉數據標簽的預測值和真實值,labTD和labD分別為首次訓練DSA 模塊所在網絡三維點云人臉數據的預測標簽值和真實標簽值,labTH和labH分別為訓練特征融合框架HFN 方法時三維點云人臉數據標簽的預測值和真實值,α,β,γ為三部分損失函數對應的超參數。
3 實驗結果與分析
實驗主要分為兩個部分:第一部分是在CASIA 數據集及相關的姿態數據集上進行PointNet、PointNet++、PointCNN、SAN 分類網絡和HFN 方法的訓練和測試,并對識別結果進行相應分析;第二部分進行了兩種輸入方式下多種分類網絡的識別實驗,并進行了分析。
3.1 數據集
CASIA 三維人臉數據庫(http://biometrics.idealtest.org)是中國科學院自動化所采用Minolta Vivid910 三維數字掃描儀采集創建的,數據為WRL 三維圖像及對應的BMP 二維圖像,共包含123 個對象,每個對象有37 或38 張圖像,圖像中包含姿態、光照、表情、遮擋多種變化。本文使用WRL 三維圖像轉換的三維點云人臉圖像作為CASIA 數據集,在整個數據集及三種姿態的子數據集上(圖3 所示)進行三維人臉識別。數據庫中每個對象的數據以表1的規律分布。

圖3 CASIA數據庫的三維人臉姿態圖像Fig.3 3D face pose images of CASIA database
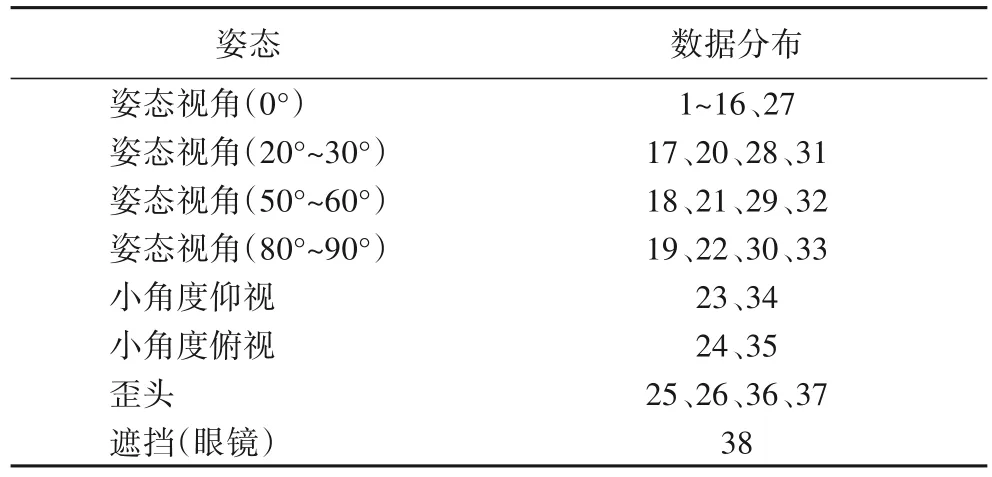
表1 CASIA數據庫的數據分布情況Tab.1 Data distribution of CASIA database
3.2 訓練集和測試集
CASIA 數據集中包含123個對象,4 624張三維人臉圖像。本文在CASIA數據集上進行人臉識別,作為平均識別率;同時將整個數據集按姿態劃分為Pose1 小姿態(頭部偏轉±20°~±30°)、Pose2 較大姿態(頭部偏轉±50°~±60°)、Pose3大姿態(頭部偏轉±80°~±90°)三個數據集。
CASIA 數據集:123 個對象,包含光照、表情、姿態變化每個對象的第1~26 張點云圖像作為訓練集,第27~37 張點云圖像作為測試集。
Pose1 數據集:123 個對象,包含多種光照、表情因素,頭部偏轉角度為+20~30°、-20~-30°以及仰視角度為+20~30°、俯視角度為-20°~-30°的864張點云圖像數據集。
Pose2 數據集:123 個對象,包含多種光照、表情因素,頭部偏轉角度為+50°~60°、-50°~-60°的369 張點云圖像數據集。
Pose3 數據集:50 個對象,包含多種光照、表情因素,頭部偏轉角度為+80°~90°、-80°~-90°的160張點云圖像數據集。
3.3 參數設置
實驗部分在Ubuntu16.04 系統下,搭載Python3.6 環境,基 于TensorFlow1.8 框 架,CUDA9.0,NVIDIA GEFORCE 1080Ti 的GPU 進行測試,對于CASIA 數據集中的點云圖像,在預處理后,每張圖像中點云數量約為5 000 左右,分類網絡輸入點云的數量設置為1 024,初始學習率設置為0.001,在微調網絡時為0.000 1;batchsize 設置為16,decay_rate 設置為0.7,初始epoch 設置盡量偏大,在預測結果穩定后進行調整。損失函數的超參數設置包括α、β、γ,監測訓練過程中損失函數的收斂速度調整α、β、γ的值,通過實驗取α=0.4,β=0.4,γ=0.2。
3.4 結果分析
在CASIA 相關數據集上進行了PointNet、PointNet++、PointCNN、SAN、HFN 等深度分類網絡的三維人臉識別實驗。從表2 中可以發現:與文獻[4]中的主成分分析(Principal Component Analysis,PCA)以及文獻[19]中的多種傳統方法相比,深度分類網絡PointNet 和PointCNN 方法識別率偏低,SAN方法由于從多個方向加強了對三維點云空間結構特征的捕捉,使得人臉的空間特征更加豐富,網絡的識別率已有大幅度提升,接近傳統方法的識別率,PointNet++在PointNet 分類網絡結構的基礎上增加局部區域的特征提取后,其識別結果已經高于文獻[19]方法3.94個百分點,本文提出的HFN方法在CASIA 數據集上的識別率為95.51%,高于已有的多個深度網絡方法和傳統方法的識別率。
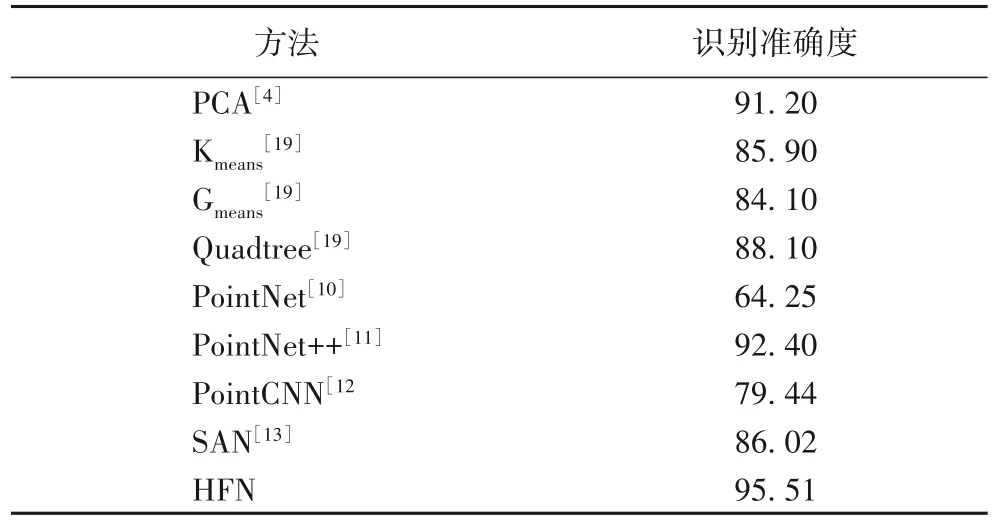
表2 不同方法在CASIA 數據集上的識別結果 單位:%Tab.2 Recognition results of different methods on CASIA dataset unit:%
表3 的識別結果表明,文獻[4]中頭部姿態對識別結果影響較大,在Pose1(頭部偏轉±20°~±30°)和Pose2(頭部偏轉±50°~±60°)數據集上,深度特征的識別率都高于強度特征的識別率,且Gabor 小波處理后的深度特征在Pose1 數據集上識別率最高,為82.4%,同時在Pose1 數據集上的識別率比Pose2 數據集最多高了34.5 個百分點,識別率相差較大,對于Pose3(頭部偏轉±80°~±90°)并未進行測試,由此可見,手工設計三維人臉的幾何特征受姿態影響較大。相比之下,PointNet系列的深度學習方法是直接以三維點云作為輸入,進而提取特征,受姿態變化的影響小,在Pose1、Pose2 的數據下識別率相差不大,PointNet++、SAN 分類網絡的方法均取得了高于文獻[4]的識別結果。同時,本文提出的HFN 方法在頭部偏轉±20°~±30°、±50°~±60°的數據集上取得了最高的識別率,分別為95.60%、96.48%。在Pose3 數據集中所有方法的識別率均偏低,其中,SAN 方法的識別率比PointNet++方法的高7.66個百分點,本文提出的HFN 方法在Pose3 數據集上的識別率比SAN 方法的高4.5 個百分點,但仍低于Pose1、Pose2 數據集上的識別率。可見,由于頭部大角度偏轉造成的點云數據大量缺失導致人臉點云空間結構的不完整仍會影響人臉識別結果。
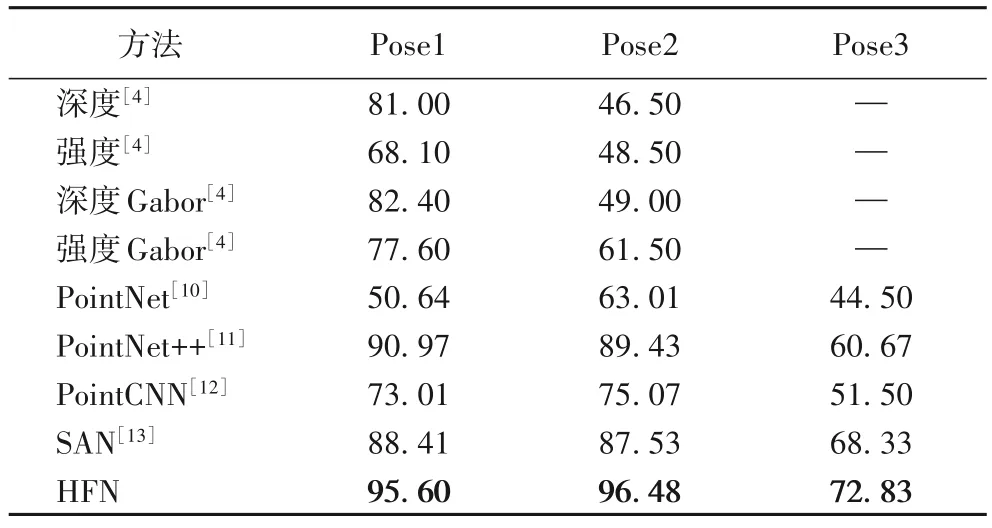
表3 不同方法在CASIA數據庫的姿態數據集上的識別結果 單位:%Tab.3 Recognition results of different methods on pose datasets of CASIA database unit:%
原始點云可以清晰地看出三維人臉的空間結構,如圖4(a),但是原始點云的數量均不相同,而深度網絡的輸入是采用了特定點數的點云。因此,為了探究點云數量對識別率的影響,本文測試了兩種點云數量的輸入方式并應用于PointNet系列的網絡進行了分類結果對比。一種是輸入點云數量為2 048,另一種是輸入點云數量為1 024,基于隨機下采樣算法將兩種輸入方式的點云進行可視化,點云數據更加稀疏,但整體空間結構仍保留,分別如圖4(b)和圖4(c)所示。

圖4 三維人臉點云隨機下采樣可視化結果Fig.4 Visualization results of random downsampling of 3D face point cloud
從表4的識別結果可以看出,對于PointNet++、SAN 方法,三維人臉點云采樣數量設置為1 024個點時,在多個數據集上的識別率略高,而HFN 方法,點云采樣數量為2 048 時,在各個數據集上的識別率均高于采樣點為1 024個點的識別率。

表4 不同方法采用兩種點云輸入方式的識別結果對比 單位:%Tab.4 Comparison of recognition results using two point cloud input methods in different methods unit:%
4 結語
本文針對人臉表情、姿態同時存在時,人臉非剛性區域存在形變且三維點云數據缺失的問題,探究性地將CASIA 數據庫的相關點云數據集在多個分類網絡中進行了訓練和測試,并提出了HFN 方法,HFN 中結合了SA 模塊和DSA 模塊中以不同方式獲取的兩種點云特征,加強了局部特征的優勢,并且克服了點云分布不均的影響。HFN方法不僅在整個數據庫上提高了平均識別率,在較小頭部姿態、較大頭部姿態以及極大頭部姿態數據集上都有良好的識別結果。在接下來的研究工作中,提升HFN 在大姿態數據集上的識別率仍需進一步探索。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
