基于改進膠囊網絡的文本分類
2020-09-29 06:56:12尹春勇
計算機應用 2020年9期
尹春勇,何 苗
(南京信息工程大學計算機與軟件學院,南京 210044)
0 引言
文字作為傳播文化和溝通感情的橋梁,在人類社會發展的道路上一直起著至關重要的作用。隨著網絡的發展,大量的文字信息走進大眾的生活,新聞、微博、短信、網絡點評等不同形式的文本大量地涌現。文本信息中蘊含了很多重要信息,對文本的處理主要包括文本檢索、翻譯、文本分類等。如何快速而準確地獲取文本信息,文本分類技術發揮著重要的作用。
文本分類是指,對于給定的一些文本集D={d1,d2,…,dn}和一些類別C={c1,c2,…,cM},如何利用分類模型?將D中的文本映射到C中的某一個類別中。例如將淘寶的評論分為好評與差評;微博評論分為開心、憤怒、傷心等情感類型;新聞分為體育新聞、娛樂新聞、教育新聞、軍事新聞等。文本分類大致經過了3 個階段:第1 階段代表人物是Maron 和Borko,他們在20世紀60年代早期就提出了用標引詞代替文本,根據標引詞在類中出現的概率來確定類別,再將多個標引詞用少數因子來代表;第2 階段出現在20 世紀60 年代中期到70 年代中期,這一階段主要是探索各種可用的分類方法如圖論、統計、矩陣法等;第3階段就是現階段,將機器學習用于文本分類。
文本分類主要分為文本預處理和文本分類兩大部分。預處理就是將文本進行分詞,使得文本變成一個一個詞組成的數組,由于有一部分詞沒有實際意義,比如“的”“了”“在”“是”“地”等,這就需要建立停用詞庫,將這些停用詞放詞庫,進行分詞時,再將它們全部去除,這樣可以降低數組的維度,增強分類效果。將文本進行去停用詞后,所得的文本數組維度還是太高,這就需要對詞進行特征選擇,選擇出現頻率高或對文本類型具有意義的詞,能夠有效地降低數組的維度,減少計算量。由于計算機無法識別文本類型的數據,所以還需要對文本進行建模,使文本類型數據轉化成數值型數據。最后,就是選擇分類器對文本進行分類,傳統的機器學習方法如:王藝穎[1]和鐘磊[2]使用的樸素貝葉斯(Naive Bayesian,NB),殷亞博等[3]和Liu等[4]使用了K-近鄰(K-Nearest Neighbor,KNN),郭超磊等[5]使用了支持向量機(Support Vector Machine,SVM),姚立等[6]使用了隨機森林(Random Forest);深度學習方法,如:Wei 等[7]使用了卷積神經網絡(Convolutional Neural Network,CNN),Hu 等[8]使用了循環神經網絡(Recurrent Neural Network,RNN),馮國明等[9]使用了膠囊網絡(Capsule Network,CapsNet)等。
文本分類屬于自然語言處理范疇,一般是使用機器學習進行分類操作的,所以提出了很多關于機器學習模型和模型的改進算法。文本分類中一個很重要的發展是由原來僅通過簡單的提取關鍵字轉變為通過理解語義和聯系上下文而獲取文本信息。主題模型能根據一個文本提取出多個主題[5],不受文本的位置和詞語的數量影響。word2vec 對于文本分類來說是另一個重要的突破,Church[10]和薛煒明等[11]使用word2vec有效地解決了文本向量維度過大問題,通過CBOW(Continuous Bag of Words)或Skip-Gram模型,可以得到既定的詞語和既定詞語上下文中可能出現的詞語,word2vec使得每個詞語的向量表示具有了具體的意義。將word2vec 與CNN、長短記憶網絡(Long Short-Term Memory,LSTM)、支持向量機(SVM)相結合有效地提高了分類速度,也提高了準確度。近幾年又出現了膠囊網絡,它在CNN的基礎上進行了改進,用動態路由代替CNN中的池化操作。在實踐中,膠囊網絡更是適用于圖片分類和文本分類。Zhao等[12]最先將膠囊網絡用于文本分類,先使用一層卷積層對不同位置進行特征的提取,再使用兩層膠囊層進行訓練,最后使用全連接膠囊層輸出每個文本類型的概率進行softmax分類。本文在原有的膠囊網絡的基礎上進行了改進:先使用一層卷積層對不同位置的特征進行提取;然后使用一層膠囊層對上層的卷積操作的標量輸出替換為矢量輸出,從而保留了文本的詞語順序和語義;再使用一層卷積層對不同位置的特征再次進行特征的提取,提取完成后,再次使用膠囊層。
1 相關工作
2011 年,Hinton 等[13]首次引入膠囊網絡。其核心思想是使用膠囊來代替卷積神經網絡中的神經元,使網絡可以保留對象之間詳細的姿態信息和空間層級關系。2017 年,Sabour等[14]在神經信息處理系統大會上發表論文,進一步提出了膠囊間的動態路由算法與膠囊神經網絡結構。該論文介紹了一個在MNIST(著名的手寫數字圖像數據集)上達到最先進性能的膠囊網絡架構,并且朱娟等[15]在MultiMNIST(一種不同數字重疊對的變體)上得到了比卷積神經網絡更好的結果。張天柱等[16]將膠囊網絡進行改進用于圖像識別,在MNIST 數據集上準確率可達到99.37%。
膠囊網絡與卷積神經網絡不同的地方有:用向量膠囊代替卷積神經網絡中的神經元、動態路由代替池化操作、Squash函數代替ReLU 激活函數。膠囊網絡不同于卷積神經網絡的三大部分是標量到向量的轉化、Squash 壓縮激活函數和動態路由。膠囊網絡原理圖如圖1所示,其中,ui表示低層特征,wij表示低層特征與高層特征之間的關系,uj|i表示高層特征。

圖1 膠囊工作原理示意圖Fig.1 Schematic diagram of capsule working principle
1.1 從標量到向量的轉化
卷積神經網絡接收到神經元輸入的標量后,將標量乘以權重,然后相加得到總和,最后將總和傳遞給一個非線性激活函數,生成一個輸出標量,作為下一層的輸入變量。其工作原理可用3個步驟描述:
1)將輸入標量xi乘上權重wi;
2)對所有的xi×wi進行求和,得到S;
3)將S傳遞給非線性激活函數f(·),得到輸出標量y。
膠囊網絡不同于卷積神經網絡的是,在進行加權求和時增加了一步。其工作原理可用4個步驟描述:
1)將輸入向量ui乘上權重矩陣wij,得到了新的輸入向量uj|i。
2)將輸入向量uj|i乘上權重cj|i,其中cj|i由動態路由決定。
3)對所有的uj|i×cj|i進行求和,得到向量Sj。
4)用壓縮激活函數Squash,將Sj轉化向量vj。
1.2 Squash壓縮激活函數
激活層就是對卷積層的輸出結果做一次非線性映射。本文采用的是ReLU函數,表達式如式(1)所示:

當x大于0 時,ReLU 函數的導數恒等于1,所以在卷積神經網絡中不會導致梯度消失和爆炸問題。若負數值過多,由式(1)看來,這部分的值就都為0,這導致了相應的神經元無法激活,但是可以通過設置學習率來解決。
膠囊網絡使用的是壓縮激活函數Squash,Squash 函數的公式如式(2)所示:

式(2)簡寫為vj=A·B,Squash 函數還有功能是使得向量的長度不超過1,而且保持vj和Sj同方向。其中A項可以看出Sj的模長越長,則A項的值越大,則Sj代表的特征就越強,輸出值也就越大。B項是將Sj模長壓縮為1。由式(7)看來,vj的模長在0~1,方向同Sj同一個方向。
1.3 動態路由
卷積神經網絡的池化層又稱為下采樣或欠采樣,用于特征降維,減少參數,還起著加快計算速度和防止過擬合的作用。主要有最大池化和平均池化兩種方式。本文采用的是最大池化,原理圖如圖2所示。
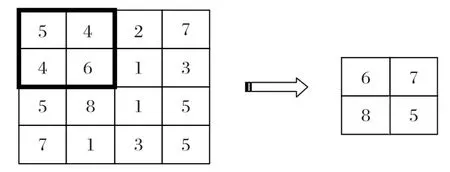
圖2 最大池化原理Fig.2 Maximum pooling principle
采用最大池化操作,通過調整池化窗口參數,提取出每張特征圖中最具有說服力的局部最優特征,從而生成每一行是每一篇文本進行一次最大池化抽樣的結果的矩陣。這樣也起到約減參數的作用,提高了模型的適應性。
膠囊網絡通過采用動態路由可代替卷積神經網絡中的池化層,對輸入的特征進行聚類,即相似特征越多,這類特征就越強,由此進行了一次特征選擇過程,達到池化層特征選擇的目的。
動態路由偽代碼如下所示。


2 改進膠囊網絡模型
膠囊網絡最先開始用在圖像上,Zhao 等[12]第一次將膠囊網絡用在文本分類上,在多分類標簽上的效果明顯優于卷積神經網絡和循環神經網絡。
該模型主要分為4 個部分:第1 部分是一個標準的卷積層,通過多個不同的卷積核在句子的不同位置提取特征;第2部分為主膠囊層,該層是將卷積操作中的標量輸出替換為矢量輸出,從而保留了文本的單詞順序和語義信息;第3 部分為卷積膠囊層,在這一層中,膠囊通過與變換矩陣相乘來計算子膠囊與父膠囊的關系,然后根據路由協議更新上層膠囊層的權重;第4 部分是全連接膠囊層,膠囊乘上變換矩陣,然后按照路由協議生成最終的膠囊及其對每個類的概率。4 個部分中包括1層卷積層和3次膠囊層。
本文在Zhao 等[12]的模型基礎上又增加了1 層卷積層,用來再次提取不同位置上的特征,使得特征提取更加地細致。基于改進膠囊網絡的文本分類模型如圖3所示。
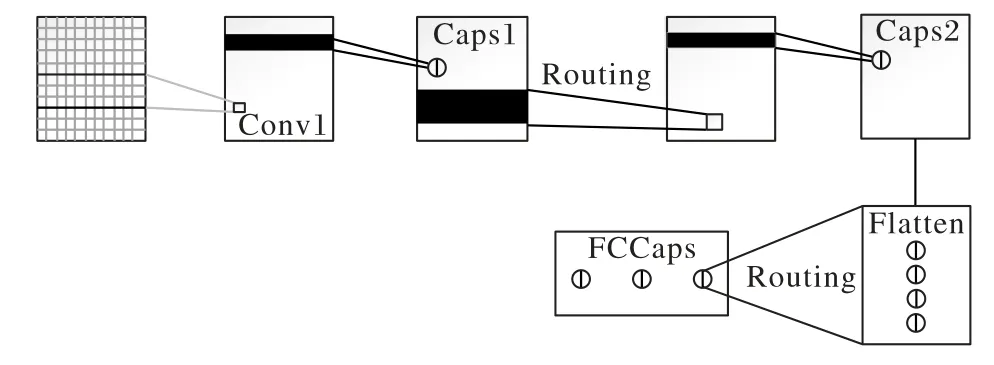
圖3 改進膠囊網絡的文本分類模型Fig.3 Text classification model of improved capsule network
模型主要分成了5 層,分別是N-gram 卷積層、主膠囊層、卷積層、卷積膠囊層和全連接膠囊層。
2.1 N-gram卷積層
該層卷積層通過卷積在文本的不同位置提取N-gram 特征,若X為文本中的一條文本,其長度為L,詞嵌入大小為V,即X的維度大小為L×V,Xi為文本X中的第i個詞語,Xi的維度為V。設N-gram 滑動大小為K1,Wα為卷積運算操作的濾波器,則Wα的維度為K1×V。濾波器每次移動的單詞窗口為Xi至Xi+K1-1,產生的特征為mα,其維度為L-K1+1,則每個單詞特征mi的特征如式(3)所示:
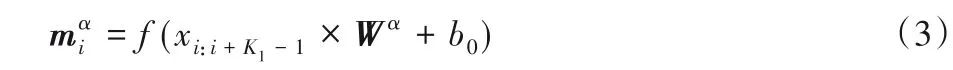
其中:b0為偏置項;?()為非線性激活函數。若有B個濾波器,即α=1,2,…,B,則所得的特征M的維度為(L-K1+1)×B。卷積操作工作原理如圖4所示,其中,w1、w2、w3為u1、u2、u3的權重系數,b為偏置項系數,這里的u1、u2、u3為底層特征ui的具體舉例。

圖4 卷積操作工作原理示意圖Fig.4 Schematic diagram of convolution operation working principle
2.2 主膠囊層
設膠囊的維度為d,pi為N-gram 產生的實例化參數,Mi為每個滑動窗口的向量,其維度為B,Wb表示為不同的滑動窗口的共享濾波器,其維度為B×d。生成膠囊P的維度為(L-K1+1)×d,則pi的表示如式(4)所示:

其中:g()表示非線性壓縮函數;b1為膠囊的偏置項。對于所有的濾波器C來說,膠囊特征P可以表示為式(5)所示結構:
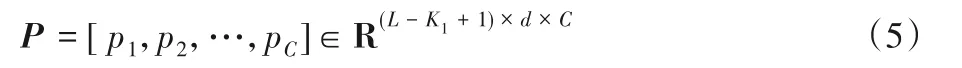
其中P的維度為(L-K1+1)×d×C。
2.3 卷積層
再次進行卷積操作時,可設置較少的濾波器的個數,一個濾波器提取一個特征,濾波器的個數減少后,特征的個數也隨之減少,訓練的維度就降低了,節約了時間成本。再次使用卷積操作更加細化了特征的提取過程,使得提取出來的特征更有利于文本的分類。
2.4 卷積膠囊層
卷積膠囊層的膠囊維度應與多標簽文本分類的分類數量相關,每一層都代表了每一個類型的概率,而主膠囊層的膠囊維度可任意設置。
2.5 全連接膠囊層
卷積膠囊層的被壓扁成一個膠囊列表,并送入到全連接膠囊層。
全連接層可以學習到局部和全局的特征,因為其輸入部分為卷積層和動態路由的輸出,卷積層提取的是局部特征,動態路由得到的是全局特征。全連接層的輸出如式(6)所示:

其中:x為神經元的輸入;hW,b(x)為輸出;T為W的轉置,將輸出節點送入softmax分類器進行概率預測,完成文本分類任務。
3 實驗與結果分析
3.1 實驗數據
實驗采用了兩組數據集:一組做多標簽分類;另一組做二分類問題。
多標簽分類實驗采用了搜狗實驗室的中文新聞數據集,該數據集包括了429 819 條新聞,能夠被標出類別的有320 045條新聞,共有13類,剔除掉2類因樣本數不足的數據,最后保留了其中的11 類作為分類數據文本。每類新聞選擇2 000條文本,訓練集、驗證集和測試集的劃分比例為16∶4∶5。數據集分布如表1所示。
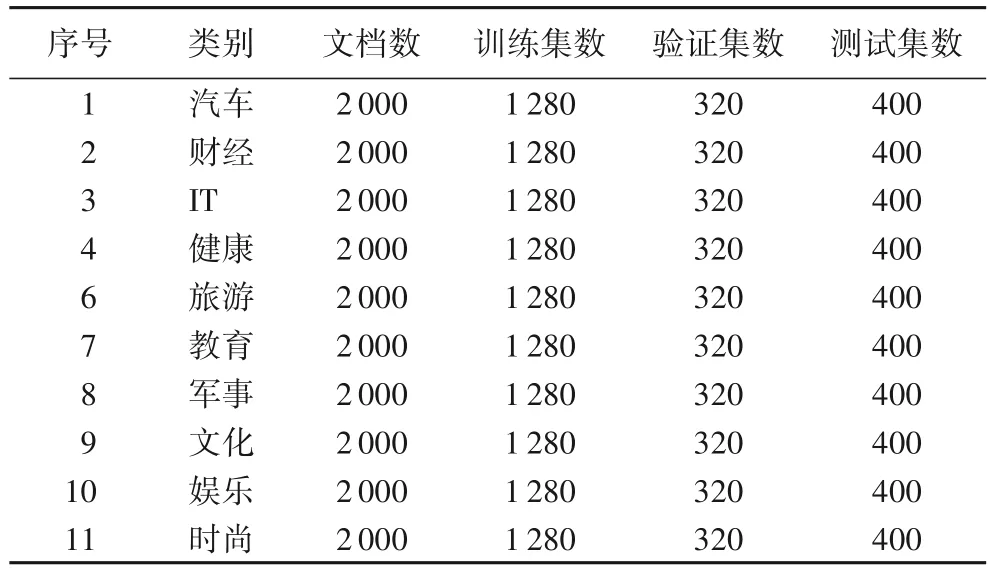
表1 數據集分布Tab.1 Dataset distribution
實驗的預處理部分先將下載好的數據進行轉碼,然后給文本加上標簽,分詞選用的是中文文本采用的jieba 分詞工具,由于有些新聞字數太多,為了減少維度的損失,固定文本長度為100個字符。
二分類實驗選用了IMDB 數據集包含來自互聯網電影數據庫12 500 個正面電影評論和12 500 個負面電影評論,每個句子的長度都固定為150 個字符,如果長度大于150 個字符,則將超過的部分截掉;如果小于150 字符,則在最前面用數字“0”填充。
3.2 多標簽分類實驗
實驗采用了python 作為算法的實現語言,由于CNN、LSTM 和CapsNet 是最常見的神經網絡模型。所以,先比較CNN、LSTM和CapsNet三種相關方法的分類效果,再進行比較改進后的膠囊網絡與Zhao 等[12]提出的膠囊網絡的分類效果,實驗最后加入word2vec進行文本向量建模,分析實驗結果。
3.2.1 相關實驗
在進行神經網絡對比實驗前,先對比了樸素貝葉斯、支持向量機、K-近鄰這三種傳統的機器學習方法,在多標簽的數據集下,樸素貝葉斯的準確率為84.38%,支持向量機的分類準確率為84.41%,而K-近鄰在K值為14 時的分類準確率僅為31.47%。實驗證明:K-近鄰明顯地不適合應用于文本分類。其他兩種傳統機器學習的方法,樸素貝葉斯和支持向量機在分類結果上占取了很大的優勢,不僅分類效果好,而且分類的時間較深度學習來說縮短了很多,但是需要人工進行特征構造,可擴展性差;而神經網絡能夠自動地學習構造特征,具有較強的適應能力。
CNN在搭建模型時,首先將文本處理成矩陣的形式,作為輸入層的輸入,本文將每個文本處理成100×200 的矩陣形式。因為文本長度不一致,所以選取100 作為統一的文本長度,超過100的文本截取前100個詞語,不足的長度的加零補齊。在進行詞語獨熱編碼時,形成了維度為200 的詞向量,這就形成100×200 的矩陣。再通過1 層卷積層與池化層來縮小向量長度,再加一層壓平層將2 維向量壓縮到1 維,最后通過兩層全連接層將向量長度收縮到12 上,對應新聞分類的12 個類(其中標簽0沒有用到)。CNN模型結構如表2所示。
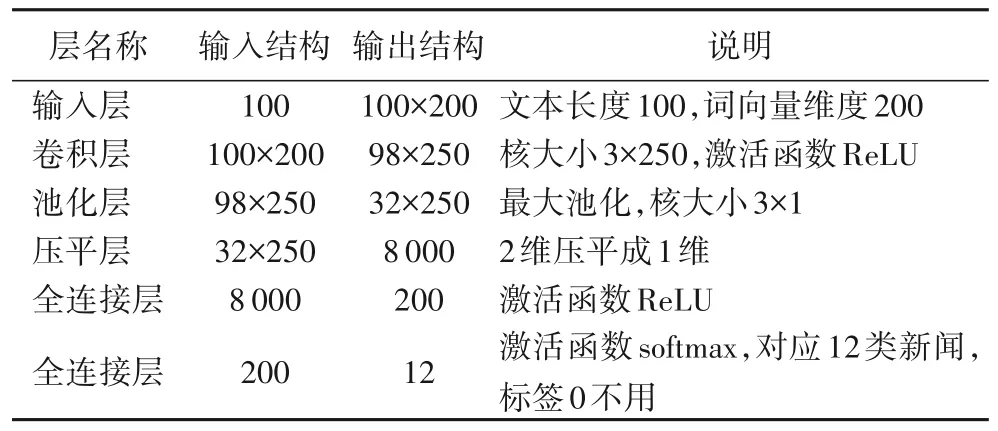
表2 CNN模型結構Tab.2 CNN model structure
由于RNN 只考慮到最近狀態,無法作用于前期狀態,使得分類效果不佳,后來進行了變形,能夠不僅能夠考慮到之前狀態,還能決定哪些狀態該保留,哪些狀態該遺棄,這就是長短期記憶(Long Short-Term Memory,LSTM)網絡。LSTM 模型結構如表3所示。
CapsNet 同CNN 一樣的是,都需要進行一層卷積層,不同的是經過膠囊層后,輸出的結構仍然是二維矩陣,不需要池化層進行池化操作,capsule 層里已經使用了動態路由操作,可代替池化操作進行特征選取,最后一層,同CNN 一樣,將全連接層輸出結構變成一維矩陣,不同的是使用的激活函數為Squash函數,該函數在應用中可自行構造。CapsNet模型結構如表4所示。
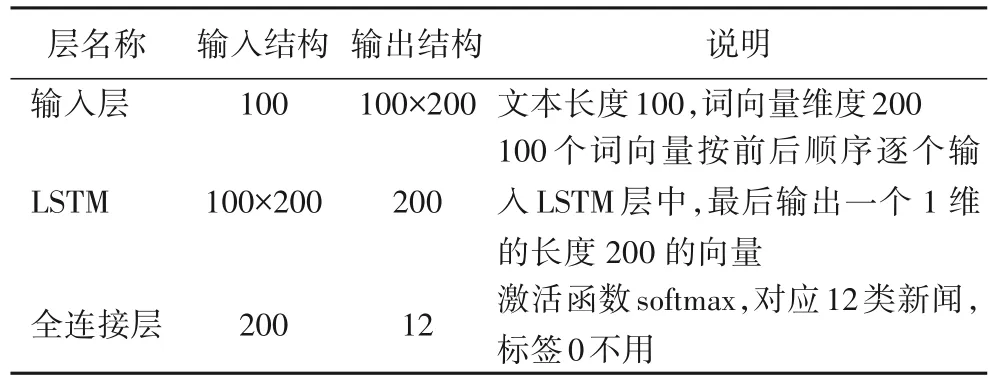
表3 LSTM模型結構Tab.3 LSTM model structure

表4 CapsNet模型結構Tab.4 CapsNet model structure
實驗從訓練集、驗證集和測試集三個方面比較分類效果,實驗結果如表5所示。
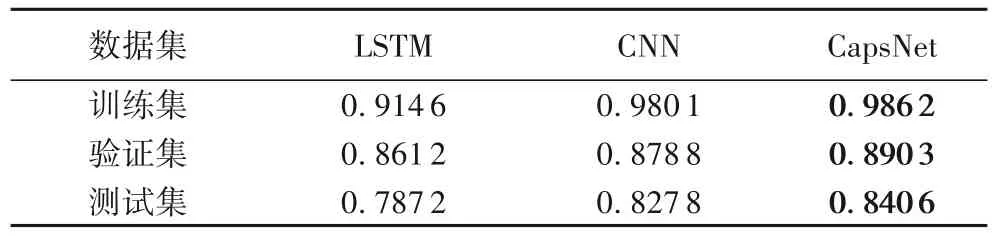
表5 不同神經網絡分類精度對比Tab.5 Classification precision comparison of different neural networks
三種方法都是經過了3 次迭代過程,在訓練集上的分類精度都達到了90%以上,其中膠囊網絡分類精度最高,達到了98.62%。在驗證集上的分類精度都達到了85%以上,其中還是膠囊網絡的精度最高,達到了89.03%。最后比較測試集,在測試集上的分類精度明顯低于訓練集和驗證集,但是,膠囊網絡的分類精度還是最高,達到了84.06%。由此可見,在文本分類中,膠囊網絡的分類效果要優于卷積神經網絡和循環神經網絡。
膠囊網絡是在卷積神經網絡的基礎上提出來,用來解決池化操作帶來的特征信息丟失問題的。考慮到卷積神經網絡缺失的相對位置、角度等其他信息的問題,膠囊網絡變標量信息為矢量信息,增加了對位置和角度等信息的提取,從而使得識別效果有所提升。卷積神經網絡能夠注意到各部分的局部特征,但是卻忽略了位置和角度等主要信息。以圖像人臉為例,卷積神經網絡能夠識別圖像中的各個局部特征,如鼻子、眼睛和嘴巴等,但是對其位置和角度卻不做考慮。若嘴巴在額頭上,眼睛在下巴上,只要鼻子眼睛嘴巴這些局部特征都在,卷積神經網絡會認為該圖片就是一張人臉。所以在進行文本分類的過程中卷積神經網絡只能聯系各個局部特征是否存在,并不會聯系其內部結構問題,這就使得了分類效果不如膠囊網絡。
3.2.2 改進膠囊網絡實驗
從訓練集、驗證集、測試集和時間4 個方面比較CapNet、文獻[12]模型和本文提出的CapNet 的分類精度,實驗結果如表6所示。

表6 不同膠囊網絡分類精度對比Tab.6 Classification precision comparison of different CapsNets
從表6 的實驗結果中可以看出,改進后的膠囊網絡比單純的膠囊網絡的分類精度提高了2.14個百分點,相較于Zhao等[12]提出的膠囊網絡的分類精度提高了1.17 個百分點。卷積操作的增加雖然增加了少量的訓練時間,但是特征的提取也更加地細致,使得分類精度有所增加。隨著卷積操作的一層一層加入特征提取得越來越細致。以圖片為例進行卷積操作,結果如圖5所示。
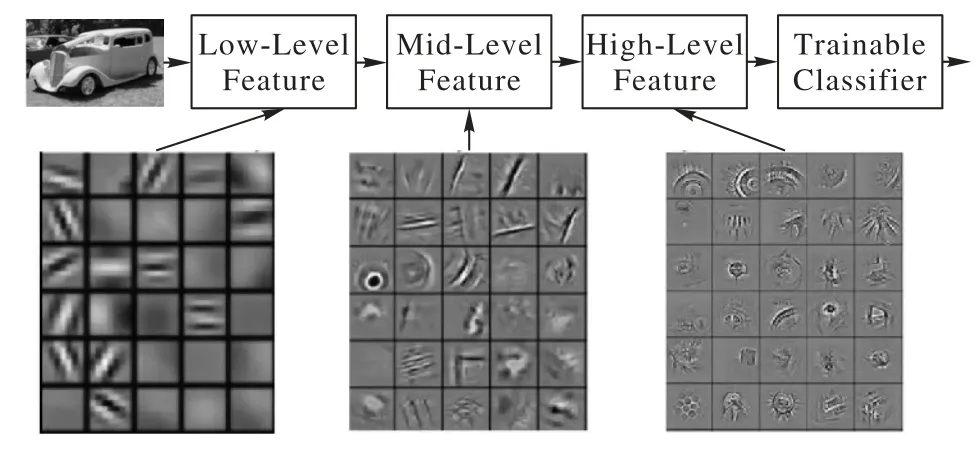
圖5 卷積操作特征提取Fig.5 Convolution operation for feature extraction
圖5 下方的3 張圖分別代表了第1 次卷積操作、第2 次卷積操作和第3次卷積操作后提取的特征。由圖5可以看出:第1次卷積可以提取出低層次的特征;第2次卷積可以提取出中層次的特征;第3 次卷積可以提取出高層次的特征。特征是不斷進行提取和壓縮的,最終能得到比較高層次特征。本文進行了兩次卷積操作,并沒有進行更加多次的卷積操作,是因為考慮到過多地卷積操作會造成訓練的過擬合現象,不僅增加了訓練時間還降低了分類精度。在本文提出的網絡模型中若再增加一層卷積操作會出現過擬合現象導致分類精度的降低,其在測試集上的分類精度僅達到了80.82%,相較于本文的改進模型分類精度降低了5.38個百分點。
3.2.3 加入word2vec擴展實驗
最后將word2vec加入到本文的方法中,再次進行實驗,實驗結果如表7所示。
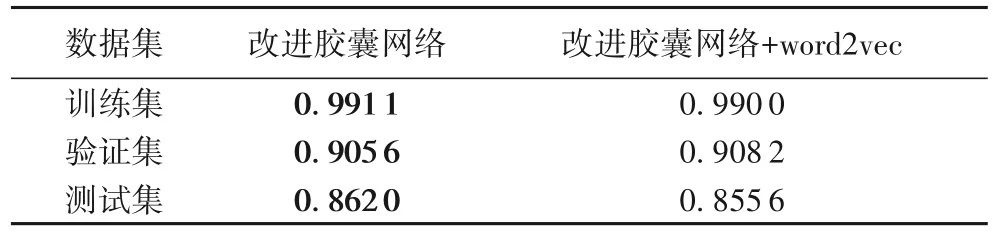
表7 word2vec實驗結果Tab.7 word2vec experimental results
從表7 中可以看出,word2vec 的加入使得了文本的分類精度不僅沒有增加反而減小了0.64 個百分點。word2vec 從大量文本語料中以無監督的方式學習語義信息,即通過一個嵌入空間使得語義上相似的單詞在該空間內距離很近。其基本思想是把自然語言中的每一個詞,表示成一個統一意義統一維度的短向量。但是由于語境的不完善,上下文的聯系不夠密切,并不能捕捉到全局的信息,這使得分類效果反而降低。
3.2.4 多標簽分類實驗結果總結
多標簽分類問題是文本分類的主要部分,本文實驗采用的是搜狗實驗室的中文新聞數據集,該數據集具有一定的代表性。其實驗結果總結如圖6所示。
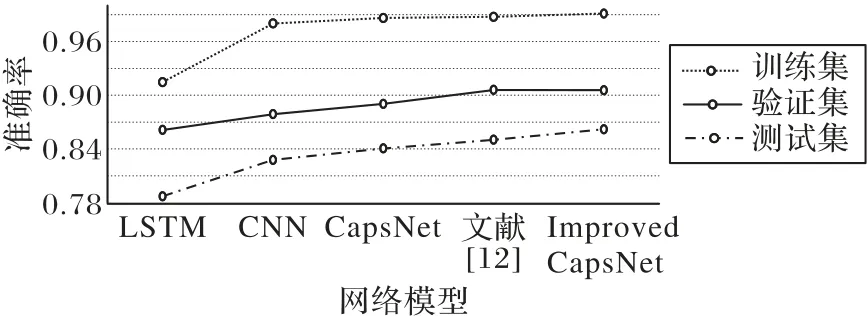
圖6 多標簽分類實驗結果Fig.6 Experimental results of multi-label classification
實驗對比了長短記憶網絡、卷積神經網絡、膠囊網絡、Zhao 等[14]提出的膠囊網絡和本文提出的改進膠囊網絡(Improved CapsNet)[12]的分類效果。實驗結果顯示,本文的改進膠囊網絡模型比多標簽實驗中的其他4 種模型來說效果更好。
3.3 二分類實驗
由于多分類實驗的結果顯示,LSTM并不適用于文本的分類問題,所以,二分類實驗并沒有考慮再次使用其方法進行實驗。二分類實驗進行了卷積神經網絡、膠囊網絡、Zhao 等[12]提出的膠囊網絡和本文改進的膠囊網絡分類實驗,其結果如圖7所示。
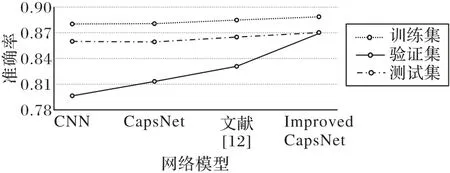
圖7 二分類實驗結果Fig.7 Experimental results of binary classification
從圖7 可以發現在二分類的電影評論數據集上,改進過后的膠囊網絡在測試集上的分類精度達到了87.03%,單純的卷積神經網絡和膠囊網絡分別是86%和85.94%,而Zhao等[12]提出的膠囊網絡的分類精度為86.50%。從測試集上來看,改進過后的膠囊網絡的分類效果還是優于其他三類網絡模型的分類效果。雖然測試集上的優勢不是很大,但是在驗證集上,本文改進過后的膠囊網絡明顯地優于其他網絡模型,比單純的卷積神經網絡和膠囊網絡提高了7.28 個百分點和5.6 個百分點,比Zhao 等[12]提出的膠囊網絡提高了3.84 個百分點。
4 結語
膠囊網絡有效地克服了卷積神經網絡的池化層操作的弊端,動態路由在效果和理論解釋性上都優于最大池化操作,但同時也增加了網絡的計算量。單獨的膠囊網絡在文本分類中的分類精度并沒有達到最大化,本文將卷積操作與膠囊網絡進行結合用于文本分類,實驗結果顯示,無論是多標簽分類還是二分類,本文的方法都比其他方法分類精度要高。膠囊網絡中的壓縮激活函數Squash,總體上能很好地解釋其原理,但是第一項中的“1”,并沒有解釋,在實驗過程中發現,可用其他小于1的非負小數代替“1”,比如0.5,其結果優于Hinton 設置的“1”。如何設置Squash 中的實數參數,在未來的研究中有待解決。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學教學參考(2015年20期)2016-01-15 08:44:38
