純用戶態的網絡文件系統
——RUFS
2020-09-29 06:56:22董豪宇
計算機應用 2020年9期
關鍵詞:用戶
董豪宇,陳 康
(清華大學計算機科學與技術系,北京 100084)
0 引言
傳統的文件系統,例如Ext4[1],都實現在內核態;但內核態的編程需要具備內核相關的知識,有很高的開發門檻。內核態程序的錯誤常常會影響到整個操作系統穩定運行。如果程序使用到了內核的內部接口,整個程序會變得難以維護和移植。由于這些原因,將文件系統實現在用戶態成為了新的趨勢。分布式的文件系統,例如GlusterFS(Gluster File System)[2]、GFS(Google File System)[3],由于涉及到復雜的容錯策略和網絡通信,本身的邏輯很復雜,幾乎都實現在用戶態。本地文件系統添加某些功能(例如加密[4-5],檢查點(checkpoint)設置優化[6]等),也會優先考慮使用FUSE(File system in USErspace)[7]搭建堆棧文件系統,將額外的功能實現在用戶態,而不是直接在內核的文件系統上作改動。許多出于研究目的搭建的文件系統[8-10],也都通過FUSE 實現在了用戶態。
許多用戶態的文件系統,存儲過程基于本地的文件系統,在存儲的過程當中,會發生用戶態與內核態的切換。這種切換會引發系統調用、上下文切換、用戶態與內核之間內存的拷貝,這些過程為系統帶來了額外的軟件開銷。
新一代的存儲硬件——NVMe(Non-Volatile Memory express)固態硬盤(Solid State Drive,SSD),能夠提供10 μs 以下的延遲和高達3 GB/s 的帶寬。硬件速度的提高,使得存儲系統的軟件開銷成為了不可忽視的一部分[11]。如果將整個存儲過程遷移到用戶態,消除系統因為進入內核而產生的開銷,整個系統的性能就可能得到改善。
出于這樣的目的,Intel 開發了一套高性能的存儲性能開發 套 件(Storage Performance Development Kit,SPDK)[12]。SPDK 誕生于2015年,目前學術界已經有了一些基于SPDK 的研究[13-15]。由于繞過了內核,并采用了輪詢的事件處理方式,相較于內核驅動,SPDK 的NVMe 驅動能夠提供更低且更穩定的延遲。在用戶態驅動之上,SPDK還提供了具有不同語義的存儲服務,開發者可以在此基礎上進行存儲系統的開發,而無需關注驅動的實現細節。
在另外一個方面,隨著InfiniBand 等新硬件的成本下降[16],以及RoCE(RDMA over Converged Ethernet)[17]技術的成熟,RDMA(Remote Direct Memory Access)技術逐漸在數據中心中普及,學術界也誕生了許多基于RDMA 構建的系統[18-21]和相關的研究[22-24]。RDMA 技術允許機器在目標機器CPU 不參與的情況下,遠程地讀寫目標機器中的內存。相較于傳統的TCP/IP 網絡棧,RDMA 技術不僅能提供更低的延遲和更高的帶寬[25],還減少了CPU 的開銷。由于RDMA 協議工作在用戶態,使用RDMA進行數據傳輸,還能避免內核-用戶態切換、內存拷貝等過程帶來的開銷。
當前的用戶態文件系統,都依賴于本地文件系統進行實際存儲。由于內核-用戶態切換的開銷,無法充分地利用NVMe SSD 的性能。另外一方面,多數文件系統為了實現較高的性能,默認不保證數據實時保存到磁盤介質上。本文希望設計一個純用戶態的網絡文件系統,減少存儲過程中的軟件開銷,充分發揮NVMe SSD 的硬件性能,并提供同步語義,保證數據實時持久化。同時,利用RDMA進行網絡通信,對外提供一個高吞吐和低延遲的文件系統服務。
本文設計并實現了一個基于高速網絡與SSD的網絡文件系統——RUFS(Remote Userspace File System)。RUFS 遵循客戶端/服務器端架構,采用RDMA 協議進行通信。用戶可以利用客戶端提供的API,使用由服務器端提供的文件系統服務。服務器端是一個單機的文件系統,元數據管理基于鍵值存 儲RocksDB(Rocks DataBase),數據管理基于SPDK Blobstore,所有存儲過程都通過SPDK 提供的NVMe 驅動運行在用戶態。通常遵循POSIX(Portable Operating System Interface X)語義的文件系統,只能保證元數據操作的原子性。而RUFS 具備同步語義,能夠在遵循POSIX 語義基礎之上,保證已經完成的數據和元數據操作,在服務器掉電之后不丟失,而無需使用fsync進行持久化。
僅使用一塊SSD 作為數據盤,RUFS:在4KB 隨機訪問上,讀、寫操作就能獲得超過400 MB/s的性能,較默認配置下NFS+ext4 的性能提升了202.2%和738.9%;對于4MB 順序訪問,RUFS相較于NFS+ext4也有至少40%的性能提升。在元數據性能上,RUFS的文件夾創建性能,相較于NFS+ext4,有5 693.8%的性能提升,其他大部分元數據操作也有顯著的性能優勢。
本文主要有三個方面的貢獻:第一,為如何在用戶態完成文件系統所有存儲過程給出了詳細的方案;第二,在此基礎上,實現了一個網絡文件系統原型RUFS,并報告了數據和元數據性能;第三,改進了BlobFS 的緩存策略,使得工作在BlobFS 之上的鍵值存儲的讀性能有了非常明顯的提升,也間接提升了RUFS的元數據性能。
1 相關研究
1.1 基于鍵值存儲的文件系統元數據管理
鍵值存儲是一種NoSQL 存儲,一般基于LSM Tree(Log Structured Merged Tree)[26]構建,提供有序鍵到任意長度值的持久化存儲和查詢。通過將隨機寫入轉化為順序寫入,這種鍵值存儲通常能夠取得更好的性能。
2013 年,Ren 等[8]提出了TableFS(Table File System)。TableFS 利用LevelDB(Level DataBase)[27]構建了一個文件系統元數據模塊,以鍵值對的鍵描述父節點到子節點的關系,并將文件的元數據作為鍵值對的值存在LevelDB 中。在此基礎上,利用Ext4 作為對象存儲,為TableFS 提供數據的存儲服務。為了減少對下層Ext4 的訪問,TableFS 還將小于4 KB 的文件也放在了LevelDB當中。
在此基礎上,2014年,Ren等[28]提出了TableFS的分布式版本——IndexFS(Index File System),并在此基礎上做了一些相關的工作[29-30]。2017年,Li等[31]提出了LocoFS(Loco File System)。LocoFS改進了用鍵值存儲模擬目錄樹的方式,減少了元數據操作需要的網絡請求數量,提高了元數據操作的性能。
1.2 SPDK技術
存儲服務的性能由軟件與硬件共同決定。對于傳統存儲硬件(如機械硬盤),由于硬件性能較差,軟件上的開銷只占整個存儲服務開銷的一小部分。但隨著NVMe SSD 的出現,相當一部分存儲硬件,例如Z-SSD、Optane SSD等,已經能夠提供小于10 μs 的延遲和高達3 GB/s 的帶寬[11]。硬件性能的大幅提高,使得軟件棧的開銷成為了整個存儲服務開銷中不可忽視的一部分。
為了充分利用NVMe SSD的性能,減少存儲過程中的軟件開銷,Intel開發了SPDK。SPDK提供了一個純用戶態的NVMe驅動,消除了內核與系統中斷帶來的開銷。SPDK提供的NVMe驅動采用了無鎖的實現,支持多線程同時提交I/O請求。
根據SPDK 團隊的論文[12],對于NVMe SSD(實驗所用的SSD 型號為Intel P3700,容量為800 GB)的4 KB 隨機訪問。SPDK 的用戶態NVMe 驅動,能用1 塊SSD 提供450 kIOPS(Input/output Operations Per Second)的訪問性能,略高于Linux內核中的NVMe 驅動。得益于無鎖的實現方式,SPDK 提供的性能,能夠隨著SSD 的增多而線性增加,用8 塊SSD 提供約3 600 kIOPS 的訪問性能。而增加SSD 數量,對內核驅動提供的性能沒有提高。在4 KB 隨機讀的延遲上,SPDK 能夠將內核驅動造成的軟件開銷,降低約90%。
SPDK 為用戶提供了一套事件驅動的編程框架。在這套框架中,每個線程相互獨立,通過消息傳遞的方式進行線程間同步,線程間不共享任何資源。這種設計消除了資源共享帶來的數據競爭,使框架具有良好的可擴展性。這個編程框架定義了3個重要的概念,分別是reactor、event和poller。reactor是一個常駐的線程,持有一個無鎖的消息隊列;event 代表一個任務,可以通過reactor 的消息隊列在線程間傳遞;poller 與event 類似,也是一種任務,但需要注冊在一個reactor 上,reactor 會周期性地調用已注冊的poller。用戶可以使用poller在用戶態模擬系統中斷。
Blobstore和BlobFS(Blob File System)是SPDK提供的兩個存儲服務,前者提供對象(blob)存儲的語義,后者提供一個簡易的文件系統,用戶可以在此基礎上搭建存儲應用。Blobstore中最基礎的存儲單元被稱為page,每個page 4 KB大小。Blobstore可以保證每個page寫入的原子性。根據用戶配置,Blobstore會將連續的多個page組織在一起(通常大小為1 MB),這一段連續的空間被稱為一個cluster,而blob則是一個cluster的鏈表。用戶可以在blob上進行隨機、并發、無緩存的讀寫,還可以將鍵值對以元數據的形式存儲在blob當中,但元數據需要用戶自己手動調用sync md(同步元數據)操作才能持久化。
BlobFS是在Blobstore的基礎上構建的一個簡易的文件系統。每個文件都對應著Blobstore中的一個blob,文件的名字和長度,都以鍵值對的形式存儲在blob的元數據當中。BlobFS只能支持創建根目錄下的文件,不支持文件夾功能,不支持隨機位置的寫入,只支持增量寫。當前BlobFS 已經能夠作為鍵值存儲系統的存儲引擎,但由于不支持隨機位置的寫入,仍然不適合用于管理文件數據。BlobFS當中還實現了一個簡單的緩存模塊,可以為文件的順序讀和增量寫帶來一定的性能提升。
1.3 基于RDMA的RPC技術
RDMA 是指一種允許處理器直接讀寫遠程計算機內存的技術。相較于傳統網絡,RDMA 能夠提供極低的延時和很高的帶寬。最新商用的RDMA 網卡可以提供低至600 ns的延時和每端口高達200 Gb/s 的帶寬[25]。RDMA 編程一般使用verbs API,需要開發者自己控制網絡連接、任務輪詢等細節,編程復雜度較高。
RPC(Remote Procedure Call)技術[32],是一種允許本地機器透明地調用遠端函數或者過程的技術。RPC技術向用戶隱藏了數據的發送、接收、序列化、反序列化等細節,大大降低了編程復雜度。Mercury 是面向超算領域的RPC 框架,于2013 年由Soumagne等[33]提出。Mercury包含了一個網絡抽象層,可以通過不同的通信插件,在不同網絡硬件下進行數據傳輸。當前,Mercury 采用了OFI(Open Fabric Interface)[34]作為支持RDMA傳輸的通信插件。Mercury在常規的RPC接口之外,還提供了一組塊(bulk)傳輸接口。Bulk接口能夠充分利用RDMA單邊通信的性能,消除不必要的內存拷貝。用戶可以把一塊內存注冊為一個bulk,并將bulk句柄發送給其他機器,其他機器就能通過bulk句柄遠程地讀寫被注冊的內存。在Mercury的基礎上,Intel正在開發一套支持組通信的RPC 框架,CaRT(Collective and RPC Transport),作為其在新的存儲系統DAOS(Distributed Asynchronous Object Storage)[35-36]中的傳輸層。CaRT不僅支持傳統的點對點RPC通信,還能支持RPC的組播。
2 系統架構與設計
本章主要介紹了RUFS 的設計與實現,包括元數據管理的策略、數據管理的策略、保證元數據與數據的一致性策略。
2.1 系統架構
RUFS 是一個純用戶態的文件系統,采用客戶端/服務器端架構,服務器端是一個單機系統,可以同時支持多個客戶端。服務器端與客戶端通過CaRT進行通信。
RUFS客戶端為用戶提供了一套類POSIX語義的、并發安全的文件系統操作API(RUFS-API),支持的操作包括:access、mkdir、rmdir、stat、rename、opendir、readdir、closedir、open、creat、close、ftruncate、unlink、pread、pwrite、read、write,支持文件和文件夾操作。當用戶調用客戶端API 時,客戶端會將請求通過RPC的形式發送到RUFS服務器端,并等待請求返回。
RUFS 服務器端實現了一個純用戶態文件系統(RUFSserver)。系統需要至少兩塊SSD才能工作,其中一塊用來建立BlobFS 實例,用來支持RocksDB[37]的數據存儲。RUFS 將利用RocksDB 對元數據進行存儲和管理。剩下的每塊SSD 都會創建一個單獨的Blobstore 實例,用來存儲數據,其中的每個blob都包含著一個文件的數據。RUFS能利用多個SSD來提高服務器端的文件讀寫的吞吐能力。在RUFS服務啟動時,系統會為每一塊用于存儲數據的SSD 建立一個Blobstore 實例,同時,啟動一定數量的reactor線程,負責處理讀寫請求。reactor線程的數量可以自行配置,但不能超過Blobstore 的實例數量,每個Blobstore實例受一個固定的reactor線程的管理。
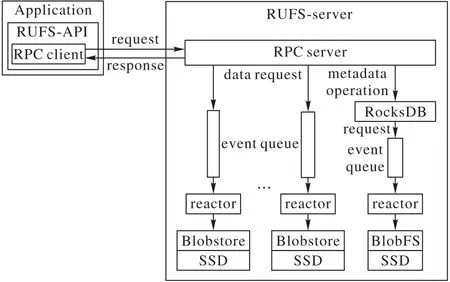
圖1 RUFS架構Fig.1 RUFS architecture
2.2 元數據管理
2.2.1 基于鍵值存儲與Blobstore的元數據協同管理
文件系統的元數據通常組織為目錄樹。目錄樹的節點存儲了文件的元數據,每一個節點都有一個唯一的編號(inode number),目錄樹的邊代表目錄對下一級節點的包含關系。RUFS利用鍵值存儲模擬目錄樹,同樣模擬了目錄樹的節點和邊,并為每個節點賦予了一個唯一的UUID(Universally Unique IDentifier)。目錄樹的節點和邊用不同的鍵值對模擬,前者稱為N型(node)鍵值對,后者稱為E型(edge)鍵值對。兩者在鍵值存儲中,有不同的前綴,N 型鍵值對模擬節點,鍵由前綴、節點UUID 拼接而成,值包含了該節點的一部分元數據(記為Meta-N),E 型鍵值對模擬父節點到子節點的邊,鍵由前綴、父節點UUID、子節點文件名拼接而成,值中包含子節點UUID 和子節點的一部分元數據(記為Meta-E)。基于鍵值存儲的鍵的有序性,擁有相同父節點的E 型鍵值對會聚合到一起,這方便了readdir 的實現。RUFS 可以將readdir 對子節點的遍歷,轉化為RocksDB對鍵值對的遍歷。
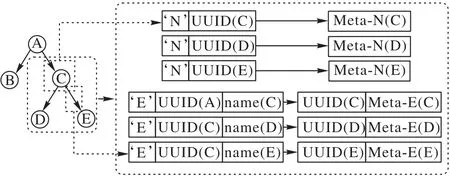
圖2 目錄樹與鍵值對的對應關系Fig.2 Relationship between directory tree and key-value pairs
在RUFS 中,一個文件/文件夾的元數據包括:mode(其中包含了節點類型、權限信息)、gid、uid、atime、ctime、mtime。對于文件,還包括文件的長度、文件對應的blob的相關信息。許多元數據操作的接口,都是基于路徑名的(例如creat、rmdir等),系統需要從根節點開始,通過文件名和E型鍵值對,順著目錄樹的樹邊逐層往下查找節點,直到找到路徑名對應的節點,再做相應的操作。在查找目標節點的過程中,根據POSIX語義的要求,系統同時要判斷操作對節點是否有訪問權限。這需要讀取節點元數據中的mode、gid 和uid。為了消除在權限判斷過程中,對N 型鍵值對的額外訪問,RUFS 將mode、gid和uid 劃分到了E 型鍵值對中。圖3 展示了節點元數據是如何存儲在不同的鍵值對中的。
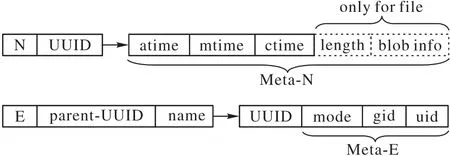
圖3 在鍵值對中存儲元數據的方式Fig.3 Method of storing metadata in key-value pairs
根據POSIX語義的要求,文件在被進行讀寫時,文件的時間戳需要被相應地改變,文件的長度也可能發生變化。如果要將這些改動同步到RocksDB 當中,當系統需要同時處理大量的讀寫請求時,RocksDB 的寫入性能就會成為整個系統的瓶頸。因此,在RUFS 中,文件的長度和時間戳還會存儲在對應的blob 的元數據中。當文件被讀寫時,文件長度和時間戳的變化只會存儲到blob的元數據中,當文件被關閉時,長度和時間戳才會被同步回RocksDB中。
2.2.2 元數據操作的原子性和并發安全性
某些元數據操作(例如rename)需要對目錄樹進行多次改動,為了保證操作的原子性,RUFS 中所有可能涉及目錄樹變化,或是在操作過程中默認目錄樹不發生結構變化的操作,都利用了RocksDB事務來保證元數據操作的原子性。
RUFS服務器端作為一個多線程的系統,能夠并發地更改目錄樹的結構,如果不進行并發控制,就會產生錯誤。而單純使用RocksDB事務,無法避免這樣的錯誤。圖4展示了一種出錯的情況。在目錄樹為初始狀態時,系統同時收到了creat 操作和rmdir操作,由于RocksDB 事務只處理寫-寫操作的沖突,因此兩個元數據操作事務得以并發地執行,并進行了事務提交,結果造成了creat 操作創建了一個空懸的節點。為了解決這一問題,RUFS 利用了RocksDB 事務中的get_for_update 操作。這一操作會促使RocksDB為目標鍵值對加上一個讀寫鎖,通過為目錄樹上的節點和邊上讀寫鎖,就能避免元數據的并發操作破壞目錄樹結構。在加鎖的順序上,RUFS總是遵循這樣的規則:對于兩個待加鎖的節點A 和B,若兩者在目錄樹中深度不同,那么RUFS會從較淺的節點到較深的節點加鎖。若兩者在目錄樹中的深度相同,RUFS會從UUID較小者到UUID較大者加鎖。RUFS通過有順序的加鎖,來避免死鎖問題。
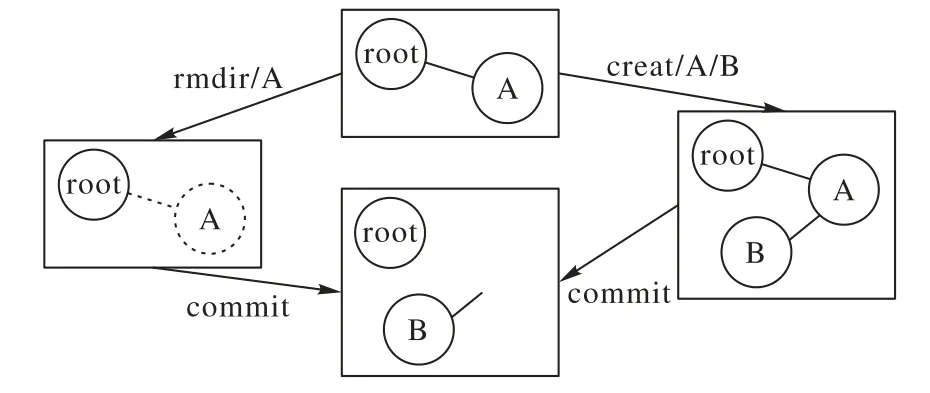
圖4 并發的元數據操作導致的錯誤Fig.4 Error caused by concurrent metadata operations
2.3 數據管理
SPDK 提供3 個存儲服務,分別是BDev(Block Device)、Blobstore 和BlobFS。其中:BDev 只提供塊設備的語義,過于簡單,不適合用作管理文件數據;BlobFS不支持對文件的隨機寫入;而Blobstore則能提供對象存儲的語義,提供針對blob的創建、刪除、隨機讀寫、長度變更等操作。RUFS容易將針對文件內容的操作,映射到Blobstore 中針對blob 的操作。因此,RUFS選擇將數據存儲在Blobstore中。
每創建一個文件,RUFS就在Blobstore中創建一個相應的blob。目錄樹中的文件節點與Blobstore 中的blob 一一對應。blob 的位置信息(blob 所屬的Blobstore 和blob ID),會成為文件元數據的一部分,存儲在RocksDB 當中。每一個Blobstore實例都由一個固定的reactor管理,對Blobstore的任何操作,包括blob 的創建、刪除、讀寫,都需要提交給對應的reactor,由reactor完成。
2.3.1 元數據與數據的一致性策略
當用戶創建或刪除一個文件時,RUFS不僅需要改變目錄樹的結構,還需要在Blobstore 上創建或者刪除相應的blob,維持文件節點與blob的一一對應。宕機會導致文件的創建或刪除執行不完整,破壞文件節點與blob一一對應的關系。如果產生了游離的blob(沒有對應文件節點的blob),則造成存儲空間的泄漏,如果文件節點沒有對應的blob,則意味著數據丟失。
RUFS利用了一種基于blob標記的手段來解決這個問題。基本的思路是,將沒有和元數據建立聯系的blob 標記為已解耦(detached),并將位置信息記錄到RocksDB 中,這樣即使服務器宕機,重啟RUFS之后,系統也能夠回收這些blob。
圖5(a)展示了文件的creat 過程,新創建的blob 會被標記為detached,并記錄在RocksDB 當中,只有在blob 元數據設置成功,并且將位置信息記錄在目錄樹上后,RocksDB 中的detached 記錄才會被刪除。如果因為宕機導致操作沒有完全執行,RUFS 在重新啟動時,通過檢查blob 的元數據和RocksDB中的記錄,就能回收游離的blob。Detached記錄的刪除過程與目錄樹的操作處于同一個RocksDB 事務中,能保證creat 成功后,被創建出的blob 不會被錯誤地回收。圖5(b)展示了文件的unlink 操作,標記blob 為detached 的過程會和刪除文件節點的過程放在同一個RocksDB 事務中。這能保證只要元數據的刪除操作成功,即使出現意外宕機,游離的blob也總能被回收。
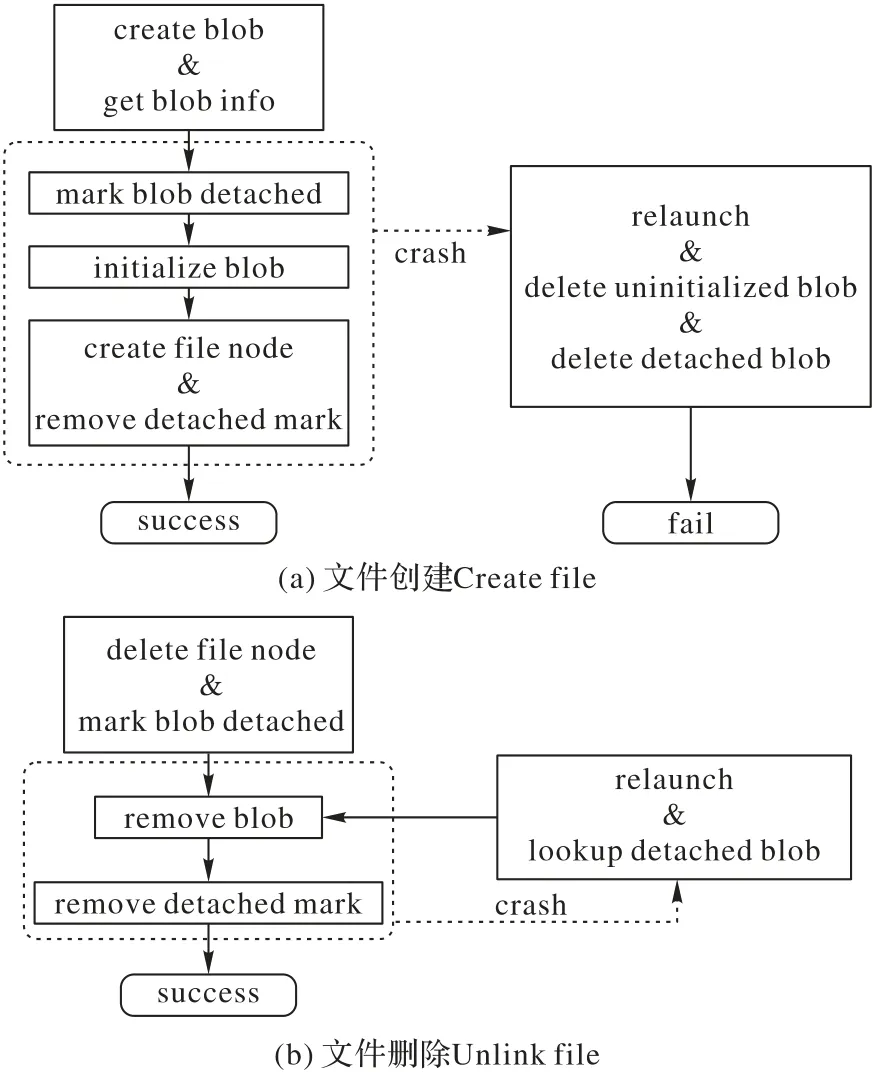
圖5 創建和刪除文件的流程Fig.5 Processes of file creation and deletion
2.3.2 句柄與讀寫狀態管理
根據POSIX 標準的要求,open、creat、opendir等操作,需要向調用者返回一個句柄。通過句柄,用戶可以進一步地對文件或文件夾進行其他操作,而不用再進行從路徑到文件節點的搜索和權限判斷。在RUFS 中,通過句柄,用戶可以讀寫文件(read、write、pread、pwrite),遍歷文件夾下的子項目(readdir)。
RUFS 的句柄包含兩個字段:一個字段是被打開節點的UUID,用來標示被打開的節點;另一個字段是一個唯一的64位無符號數(fd ID),用來標示打開同一個文件的不同句柄。通過句柄,RUFS-server能夠查找當前句柄對應的讀寫狀態。
RUFS-server采用了圖6中的數據結構來管理句柄的讀寫狀態,這個數據結構用了一個以UUID 為鍵的哈系表,來維持被打開文件/文件夾的內存節點。內存節點中包含了對其進行操作所需要的數據;文件內存節點中包含了文件對應的blob的位置信息,緩存了文件的長度和時間戳;文件夾內存節點,存儲了以該文件夾為父節點的E 型鍵值對的鍵的公共前綴(前綴E+文件夾UUID),這個前綴用來在遍歷E 型鍵值對時,判斷被訪問的鍵值對是否指向該文件夾的子節點。每個內存節點中包含了一條鏈表,鏈表上的每一個元素,都記錄了某個句柄對應的讀寫狀態,如果句柄屬于一個文件,那么讀寫狀態就是當前偏移(offset)的位置,如果句柄屬于一個文件夾,那么讀寫狀態就是readdir 操作所需的RocksDB 迭代器。利用圖6 中的數據結構,RUFS 還能通過哈希表快速地判斷某個節點是否被打開,阻止被打開的節點被刪除。
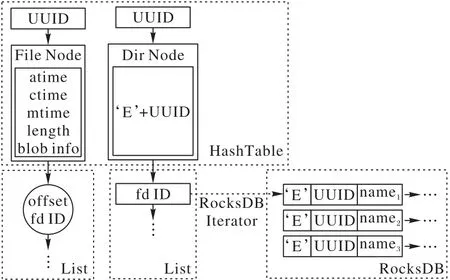
圖6 RUFS對句柄的管理Fig.6 Management of handles in RUFS
3 系統實現與優化
3.1 網絡傳輸優化
RUFS 采用了CaRT 作為客戶端與服務器端通信的手段。CaRT 為用戶提供了RPC 接口和bulk接口,bulk接口能夠充分利用RDMA 的單邊通信性能,避免不必要的內存拷貝。元數據操作需要傳輸的數據量通常很少,因此RUFS 只使用CaRT提供的RPC 接口來發送元數據操作。但讀寫操作,可能需要傳輸較多的數據,為了充分利用RDMA的單邊通信原語,提高傳輸性能,RUFS利用bulk接口來傳輸讀寫緩沖區中的內容。
但使用bulk接口,需要用戶自己申請內存,并將內存注冊為一個塊(bulk)。注冊bulk非常耗時,將一塊僅1 B的內存注冊為bulk,需要耗費大約60 μs,如果在客戶端和服務器端都進行內存的注冊,一次通信會產生額外的120 μs的開銷,隨著被注冊內存的增大,耗時還會增大。圖7 展示了發送不同大小的負載時復用bulk(記為reuse-bulk)和每次注冊新的bulk(記為register-bulk)在傳輸延遲上的性能差距。
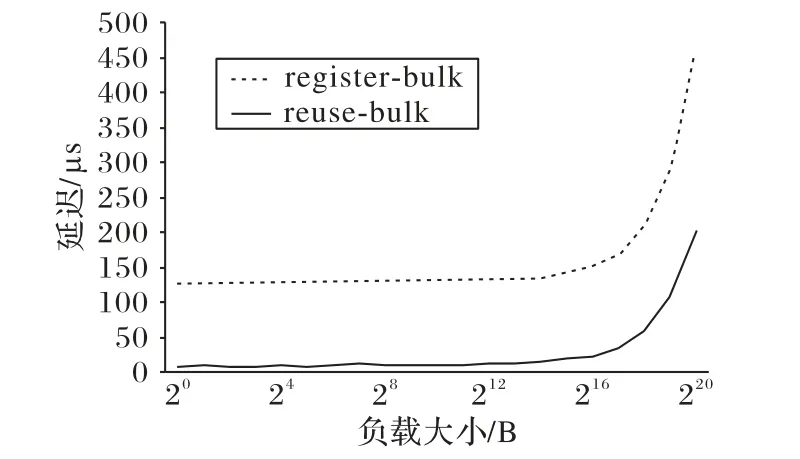
圖7 不同負載下bulk傳輸的延遲Fig.7 Bulk transfer latency with different payload sizes
為了解決這一問題,RUFS 設計了一個內存池,Bulk-Mempool。Bulk-Mempool 會提前將一些大塊的內存注冊為一個bulk,并在這塊內存上進行進一步的分配。在讀寫操作的過程中,服務器和客戶端用到的讀寫緩沖區就從這個內存池中分配,這就消除了RUFS 在每次讀寫操作時,將讀寫緩沖區所在的內存注冊為bulk而帶來的開銷。
Bulk-Mempool 并不是一個單一策略的內存池,而是由兩個不同策略的內存池BM-small 和BM-mid 組成的。BM-small實現比較簡單,分配開銷較小,只分配4 KB 大小的內存;BM-mid內部實現了一個buddy system 內存池,開銷相對較大。小文件讀寫通常觸發小于等于4 KB 的內存分配請求,此時由開銷較小的BM-small 進行內存分配,能夠保證小文件讀寫的性能;大于4 KB、小于等于4 MB 的內存分配請求,則由BMmid 負責。BM-mid 能夠分配不同大小的內存,提高內存的利用率。
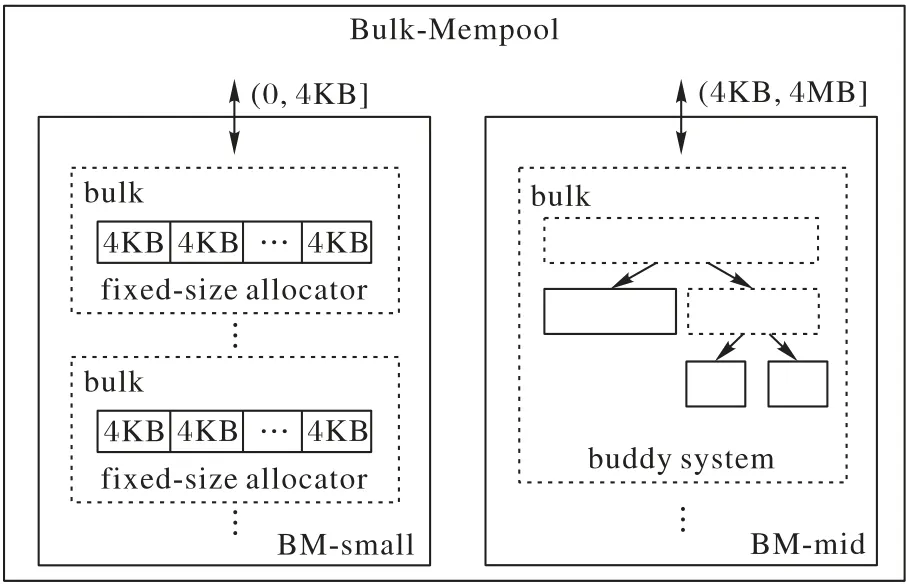
圖8 Bulk-Mempool的架構Fig.8 Architecture of Bulk-Mempool
Bulk-Mempool 沒有對大于4 MB 的內存分配進行優化,是因為以4 MB 為單位的數據傳輸,已經能夠充分地利用InfiniBand 的高帶寬,使數據傳輸不會成為整個系統的瓶頸,本文的實驗也說明了這一點(見4.3 節)。如果用戶需要傳輸大文件,將每次讀寫請求分割為4 MB大小即可。
Bulk-Mempool 提供get 和put接口。通過get 接口,調用者能夠獲得一個胖指針,其中包括了指向被分配內存的指針、被分配內存的大小、被分配內存在bulk 中的偏移,以及bulk 句柄。前兩者使得調用者可以在本地讀寫分配到的內存,后兩者使得遠端機器能夠正確在分配到的內存上進行讀寫。
3.2 讀寫吞吐能力優化
按照POSIX 語義的要求,文件的讀寫會導致文件的大小和時間戳發生變化,導致元數據的改動。這在Blobstore 中就表現為需要通過sync md(同步元數據)操作同步blob 的元數據,但sync md 操作非常耗時,甚至超過了一次4 KB 的讀或寫。如果每次文件讀寫都要更新時間戳或是文件長度,頻繁觸發sync md 操作,會讓整個系統的吞吐能力受到極大的影響。為此,RUFS提供了兩個優化策略,以減小sync md的觸發頻率。
第一個策略是,提供了ftruncate 操作,并鼓勵用戶盡可能在寫入數據前,將文件擴展到合適的大小,這樣能夠避免寫入操作“撐大”文件大小,進而觸發sync md。另一個策略是,放寬對時間戳更新的要求,每次進行讀寫時,將系統當前的時間,與文件當前的時間戳進行比較,只有文件需要更新的時間戳,與當前的時間相差多于5 ms 時,才選擇更新時間戳。考慮到系統本身就存在著時間上的誤差,這樣的放松策略是可以接受的。
3.3 可靠元數據性能優化
RocksDB 會將寫入操作記錄到日志里,但并不會立刻將日志寫入到磁盤中。在內存中緩存一定數量的日志之后,RocksDB 才會一次性地將所有內存中的日志寫到硬盤上。這個特性被稱作“組提交(group commit)”,組提交特性顯著地減少了向磁盤寫入數據的次數,對RocksDB 的寫入性能有很大的提升。但同時,由于寫入的數據不能被及時持久化,服務器斷電就可能導致元數據操作的丟失。考慮到Blobstore會保證數據持久化后再返回,為了使元數據與數據保持一致,提供同步的文件系統語義,RUFS 也需要保證元數據操作返回后,就已經持久化到了硬盤上。
為了提供這樣的保證,RUFS 打開了RocksDB 的同步模式。同步模式下,每次寫入操作后,RocksDB 都會調用fsync保證日志寫入硬盤,使數據在宕機后不丟失。然而,本地文件系統的fsync 性能很差,這導致了RocksDB 同步模式下的寫入性能也很差,降低了RUFS 整體的元數據性能。為了解決這個問題,RUFS采用了由SPDK團隊修改并開源的RocksDB[38]。這個版本的RocksDB 將底層的存儲環境更換為了BlobFS。BlobFS 有很好的同步寫入性能,能夠顯著提升RocksDB 在同步模式下的寫入性能。
RocksDB 的讀操作觸發的都是文件的隨機讀,而BlobFS當前僅針對順序讀進行緩存。緩存的缺失使RocksDB 的讀性能變得很差。為了解決這個問題,在BlobFS 中添加了一個支持緩存的隨機讀方法,當RocksDB 調用這個方法進行讀操作時,BlobFS 會預取所需數據所在的一個256 KB 的數據塊,并緩存在內存當中。利用緩存,相比以文件系統作為存儲環境,RocksDB 在BlobFS 上的寫性能能得到顯著提升,且保持讀性能基本相同。
3.4 統一的SPDK環境管理模塊
RUFS 利用一個或多個Blobstore 管理數據,利用由SPDK團隊提供的RocksDB 管理元數據。這兩者都需要工作在SPDK環境下。當前,由SPDK團隊提供的RocksDB,會在內部自行啟動一個SPDK 環境。由于一個進程只能啟動一個SPDK 環境,因此RocksDB 啟動的SPDK 環境,會和RUFS 啟動的SPDK環境產生沖突,導致整個系統啟動失敗。
為了解決這一問題,RUFS 去掉了RocksDB 中啟動SPDK環境的功能,并將這部分功能整合到了RUFS 中,再加上對Blobstore 依賴的SPDK 環境的管理功能,形成了統一的SPDK環境管理模塊(SPDK-env-mod)。系統啟動時,SPDK-env-mod會初始化SPDK 環境,同時創建BlobFS。在RocksDB 初始化時,SPDK-env-mod 會將BlobFS 暴露給RocksDB,使RocksDB順利在BlobFS上初始化和運行。
除了解決SPDK 環境沖突的問題,SPDK-env-mod 還方便了系統管理員對Blobstore 的管理。SPDK-env-mod 提供了一個配置文件,系統管理員可以通過該配置文件,指定用來管理數據的SSD,以及用于管理數據的reactor 線程的數量。系統啟動后,SPDK-env-mod 會根據配置文件,在每塊用于管理數據的SSD 上,建立Blobstore 實例。同時,根據配置文件,啟動一定數量的reactor 線程,并按照平均分配的原則,將Blobstore綁定到不同的reactor線程上。
除此之外,SPDK-env-mod 會給每一個Blobstore 賦予一個從0 開始的、單調遞增的唯一編號,同時在內存中維持一個計數器,每次系統需要創建一個blob 時,就將計數器的值對Blobstore 的數量取模,以此選出一個Blobstore 實例,在這個實例上創建blob,并將計數器原子地加1。由于Blobstore實例與用來管理數據的SSD 一一對應,這樣的分配方案,可以保證blob均勻地分布在各個SSD上。
4 測試與評估
本章將評估RUFS 在元數據、讀寫延遲和讀寫吞吐方面的性能。RUFS的總體性能會和NFS+ext4進行比較;而RUFSserver的性能會和ext4進行比較。本章還會討論SPDK對元數據的加速效果和多SSD對吞吐性能的提升。
4.1 測試配置
所有的測試都在兩臺服務器上進行,其中一臺作為RUFS的服務器,另一臺作為RUFS 的客戶端。RUFS 客戶端裝配了2 塊6 核CPU,128 GB 內存;RUFS 服務器端裝配了4 塊12 核CPU、768 GB 內存、8 塊容量為512 GB 的NVMe SSD。兩臺服務器通過56 Gb/s 帶寬的InfiniBand 網卡相連。表1 是測試環境的具體參數。
在所有測試中,NFS 與ext4 均采用默認配置,ext4 建立在服務器端,使用1塊SSD,利用NFS掛載到客戶端。RUFS使用2 塊SSD,分別用來管理數據和元數據,使用16 個RPC 處理線程,1 個reactor 線程。客戶端利用RUFS 客戶端提供的API 訪問RUFS服務器。

表1 測試環境設置Tab.1 Testing environment configuration
4.2 元數據性能
本文采用mdtest[39]對元數據性能進行測試,用每秒的操作數量(Operations Per Second,OPS)衡量性能。該測試對比了NFS+ext4 與RUFS 整體的元數據性能。在元數據性能測試中,客戶端使用8 個mdtest 進程,文件節點的最大深度為4,文件/文件夾總數大約為50 萬。如果測試對象為RUFS,需要將mdtest中的文件系統函數換成RUFS-API。
4.2.1 需要關注的元數據操作
在本節的測試中,主要關注如下的元數據操作:D-creat、D-stat、D-remove、F-creat、F-stat、F-read 和F-remove,表2 展示了它們的意義和在過程中會觸發的操作。
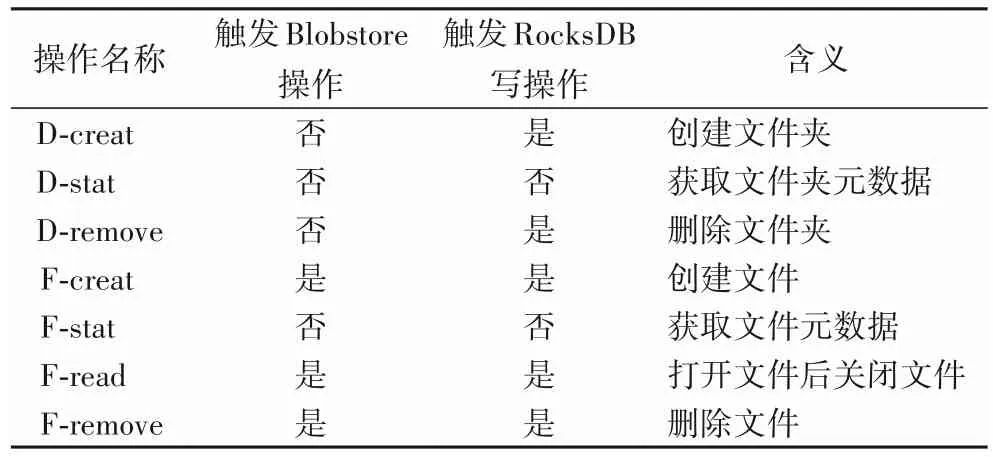
表2 元數據操作和它們的屬性和含義Tab.2 Metadata operations and their attributions and meanings
4.2.2 測試結果
從圖9 來看:RUFS 在F-creat 和F-remove 兩個操作上,與NFS+ext4 的性能大致相同;在其他元數據操作上,RUFS 都具有顯著的優勢,取得了至少70%的提升;特別對于D-creat 操作,RUFS 相對于NFS+ext4 有大約5 693.8%的性能提升。橫向對比RUFS各個元數據操作的性能,F-creat和F-remove由于需要在Blobstore 上進行多次操作,因此性能顯著低于其他元數據操作。F-read 操作包含了一次open 操作和一次close 操作,且需要訪問Blobstore,因此性能也同樣較差。
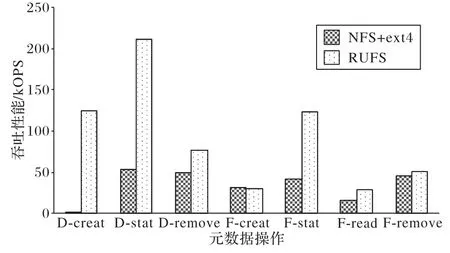
圖9 RUFS與NFS+ext4元數據性能的比較Fig.9 Metadata performance comparison of RUFS and NFS+ext4
4.2.3 SPDK為元數據帶來的性能提升
為了達到同步語義,RUFS在使用RocksDB 時會打開同步模式,這會導致RocksDB的寫入性能大幅下降。SPDK能夠為存儲應用帶來更低的延遲、更高的吞吐性能。通過將RocksDB 的存儲環境替換為優化后的BlobFS,RocksDB 的同步寫性能有了很大的提升,并且讀性能沒有受到影響。本節將展示BlobFS對元數據性能的影響。
圖10 展示了RUFS 元數據性能在RocksDB 在不同配置(同步模式或組提交模式,分別記為sync 和group-commit)、不同存儲環境下(文件系統或BlobFS,分別記為fs和SPDK)的結果。從非同步模式切換為同步模式,無論存儲環境是BlobFS還是文件系統,涉及到RocksDB寫入的元數據操作,都會有明顯的性能下降。在BlobFS 環境下,creat 操作性能損耗最大,大約為38.8%,但由于原本性能很好,因此性能依然可以接受。存儲環境為本地文件系統時,元數據操作的性能損耗變得不可接受,性能損耗最多的元數據操作依然是creat,損耗比例高達98.7%,基本處于不可用的狀態。其他元數據操作,除了D-stat 與F-stat 不發生RocksDB 寫入,不受同步模式的影響,其他操作的OPS都小于2 500。
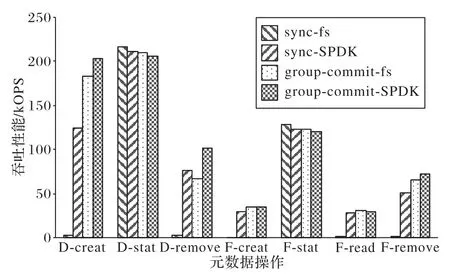
圖10 SPDK對元數據操作的性能的影響Fig.10 Impact of SPDK on metadata operation performance
4.3 數據性能
本節將討論RUFS、NFS-ext4、RUFS-server 和ext4 在4 KB隨機讀寫延遲、4 KB 隨機讀寫吞吐、4 MB 順序讀寫吞吐幾個場景上的性能。由于當前RUFS 還沒有加入對緩存的支持,因此在對ext4 進行測量時,盡量消除了緩存對ext4 的影響。ext4 的寫入包括兩個項目:ext4-direct 和ext4-sync。前者在打開文件時,使用了O_DIRECT 選項,避免數據寫入到緩存;后者在打開文件時使用了O_SYNC 選項,保證寫入數據能夠持久化到硬盤。需要說明的是,由于O_SYNC 選項不影響讀操作,因此在測試讀性能時,ext4-sync 與ext4-direct 會使用同一個數據。RUFS-server 仍然使用16 個RPC 處理線程,用1 塊SSD管理元數據,1塊SSD管理數據。
4.3.1 延遲
測量了RUFS-server、ext4-sync、ext4-direct、RUFS、NFS+ext4的4 KB 隨機讀寫的延遲,圖11展示了測試結果。從結果上來看,RUFS-server 的讀延遲,大約只有ext4 的20%。在網絡環境下,RUFS 總體的讀延遲,只有NFS+ext4 的26%左右。而對于本地寫性能,RUFS-server 僅略快于ext4-direct,但要注意,ext4-direct 并不保證操作返回時,能將數據持久化在硬盤上。提供這一保證的ext4-sync,寫延遲則是RUFS-server 的近60 倍,在網絡環境下,RUFS 總體的寫延遲也遠遠小過NFS+ext4。
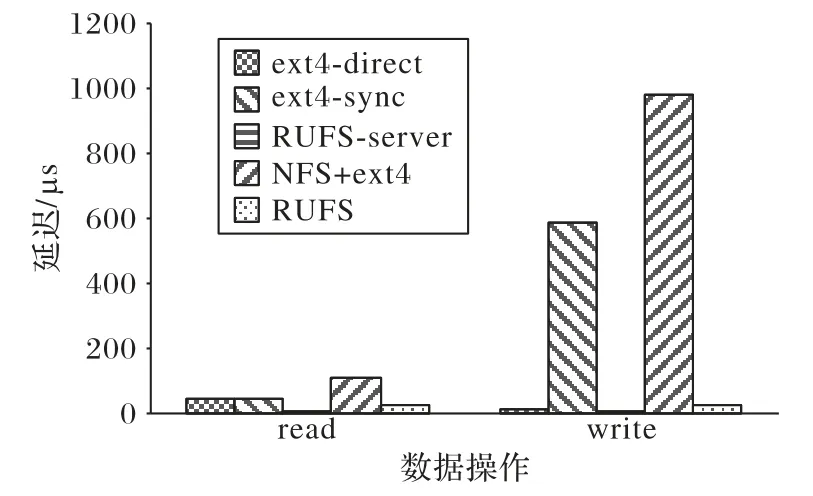
圖11 RUFS與NFS+ext4關于4 KB隨機訪問的延遲Fig.11 4 KB random access latency of RUFS and NFS+ext4
4.3.2 吞吐
吞吐性能測試包括了4 KB 隨機讀寫和4 MB 順序讀寫兩個項目。圖12 展示了4 KB 隨機讀寫吞吐性能的結果。這個結果和延遲測試類似,RUFS-server 在讀寫性能上,都遠遠地超過了ext4-sync,同時略強于不提供持久化保證的ext4-direct。總體性能上,RUFS 讀性能是NFS+ext4 的3 倍以上,寫性能是NFS+ext4的8倍以上。

圖12 NFS+ext4與RUFS關于4 KB隨機訪問的吞吐性能Fig.12 4 KB random access bandwidth of NFS+ext4 and RUFS
在4 MB 的順序讀寫上,ext4 與RUFS 的差距就相對小了一些。沒有網絡參與時,無論是讀還是寫,RUFS-server 均快于ext4,但性能提升不超過30%。但值得注意的是,在大文件的順序讀寫中,RUFS 的總體性能與RUFS-server 的吞吐性能幾乎持平,這意味著網絡傳輸提供了足夠高的帶寬,沒有成為整個系統的瓶頸。

圖13 RUFS與NFS+ext4關于4 MB順序訪問的吞吐性能Fig.13 4 MB sequential access bandwidth of RUFS and NFS+ext4
4.3.3 多SSD帶來的性能提升
RUFS-server默認只用1個SSD管理數據,因此也只使用1個reactor 線程管理讀寫請求。如果使用多個SSD 管理數據,RUFS-server 就能啟動多個reactor 處理讀寫請求,這能夠提升RUFS-server 的吞吐性能。圖14 展示了RUFS-server 在多塊SSD下吞吐性能的提升。當使用6塊SSD管理數據時,通過將文件分散到各塊SSD,并用6 個reactor 同時處理讀寫請求,RUFS-server的吞吐性能能獲得246%到450%的提升。
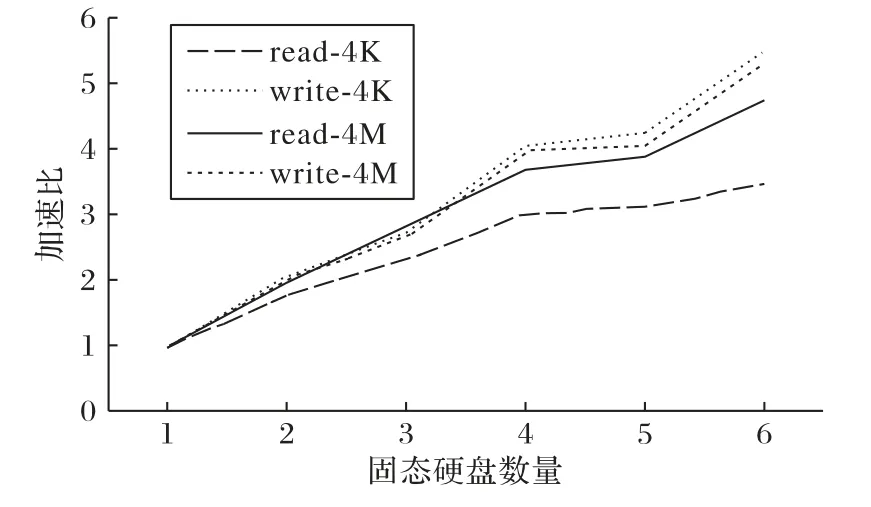
圖14 多SSD為RUFS-server帶來的加速比Fig.14 Speedup ratio brought by multi-SSD on RUFS-server
5 結語
本文設計并實現了一個基于高速網絡和NVMe SSD 的用戶態網絡文件系統,RUFS。RUFS 利用RocksDB 管理元數據,利用Blobstore 管理數據,使用RDMA 技術對外提供服務。RUFS 充分地利用了NVMe SSD 的性能,所有的存儲過程都通過SPDK 提供的NVMe 驅動運行在用戶態。RUFS 在隨機讀寫、順序讀寫和元數據性能上,相較于NFS+ext4 都有十分明顯的優勢。除此之外,RUFS 還具備同步語義,能夠保證用戶請求返回后,數據就已經被持久化到硬盤當中。
通過RUFS 的開發和測試,也充分證明了SPDK 在存儲領域的潛力,尤其是保證數據可靠寫入、并持久化在硬盤的性能,明顯地好于本地文件系統。因此SPDK 也十分適合于開發對存儲持久性要求較高的應用,例如關系型數據庫的存儲引擎。
猜你喜歡
車主之友(2022年4期)2022-08-27 00:58:26
知音·下半月(2022年5期)2022-05-23 23:17:04
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年5期)2016-11-28 09:55:15
非公有制企業黨建(2016年1期)2016-07-19 13:02:51
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
衛星與網絡(2016年12期)2016-02-05 09:23:23
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
