基于張量核范數與3D全變分的背景減除
2020-09-29 06:56:58陳利霞王學文
計算機應用 2020年9期
陳利霞,班 穎,王學文
(1.桂林電子科技大學數學與計算科學學院,廣西桂林 541004;2.廣西高校數據分析與計算重點實驗室(桂林電子科技大學),廣西桂林 541004;3.桂林電子科技大學計算機與信息安全學院,廣西桂林 541004)
0 引言
伴隨網絡技術和數字視頻技術的飛速發展,監控技術日益面向智能化、網絡化方向發展,這使得對視頻背景減除技術的要求越來越高。背景減除,即從視頻中準確檢測出運動目標而將不關心的背景完全或部分除去[1],是很多計算機視覺問題中的關鍵技術。
近年來,低秩稀疏分解在背景減除領域應用廣泛,典型的算法是魯棒主成分分析(Robust Principal Component Analysis,RPCA)[2-3]。該模型將視頻矩陣化并分解為背景和前景,其中低秩背景用核范數約束,稀疏前景用L1范數約束。進一步,為解決動態背景和噪聲干擾等問題,陳利霞等[4]分別用Schatten-p 范數和3D 全變分(3D Total Variation,3D-TV)代替核范數和L1范數來約束背景和前景,具體模型如下[4]:
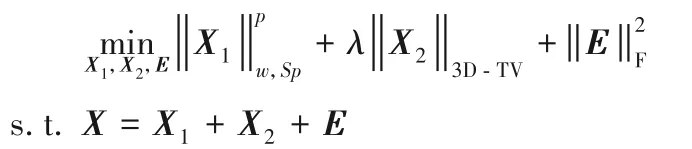
其中:E是噪聲項,λ為平衡前景與背景的權衡參數。
上述矩陣形式的RPCA 存在一個缺點:只能處理二維數據。而實際數據在本質上通常是高維的,所以要使用RPCA必須先將高維數據矩陣化,但矩陣化會破壞其固有的空間結構,導致一些信息丟失,性能下降;另外,視頻矩陣化后得到的結果由于幀數多而變得龐大,故占用較大的內存空間,計算復雜度變大。因此,上述的RPCA 模型進一步擴展到高維空間。Goldfarb 等[5]為減少高維信息的丟失,提出了高階魯棒主成分分析模型(High-order RPCA,HoRPCA)。Xie 等[6]提出了用張量稀疏檢測代替核范數建模背景——KBR-RPCA(Kronecker-Basis-Representation based RPCA),將每個維度的秩分配合適的權值,考慮了張量低秩的實際物理意義。Liu 等[7]基于核心張量的低秩分量提出了一種新的張量核范數對背景約束,提高了前景背景分離的準確性。為了更加精確地逼近低秩背景,Lu 等[8]提出了一種改進的張量核范數對背景建模——TRPCA-TNN(Tensor RPCA with Tensor Nuclear Norm),旨在加強背景的低秩性。上述方法對于前景大多采用L1范數約束,而L1范數獨立地對待每個像素點,沒有考慮前景目標在空間中的連續性以及時間上的持續性。
而對于前景約束,Yuan 等[9]用L2,1范數代替L1范數作為前景的稀疏性約束,實現了變量組水平的稀疏性。Xu等[10]進一步用L1,1,2范數代替L2,1范數,加強了前景的管稀疏性和時空連續性。Cao 等[11]提出使用全變分對前景建模,提高了視頻前景的時空連續性,抑制了動態背景造成的干擾。上述方法在一定程度上提高了對前景的約束,但對于背景的約束大部分采用張量核范數,其近似程度有待進一步提高。
文獻[4]等以矩陣為基礎的RPCA 模型導致了高維數據的結構破壞和信息丟失,因此本文以張量為工具提出了一種改進的基于張量魯棒主成分分析(Tensor RPCA,TRPCA)的背景減除模型。該模型把視頻當作三維張量來整體處理,保留了不同視頻幀之間的空間結構和信息,且以張量的形式進行存儲節約了內存空間,降低了計算復雜度,有效解決了文獻[4]耗時長的問題。矩陣Schatten-p 范數[4]約束的背景同樣由于信息的丟失而導致對實際視頻背景的近似程度不夠,因此本文利用改進的張量形式的核范數對背景成分進行低秩約束,考慮了視頻背景的時空連續性,且更加接近實際高維數據的秩函數(加強了視頻背景的低秩性),從而提高了前景背景分離的效果。同時,為解決L1范數約束前景不夠充分的問題,利用3D-TV正則化對前景成分進行稀疏性約束,加強了視頻前景的時空連續性,且對視頻中的不連續變化有較強的抑制作用,因此有效地抑制了動態背景對前景提取的干擾作用,使得前景背景分離更加準確。
1 基于張量核范數與3D-TV的背景減除
現有的模型在平穩背景下能實現較好的背景減除效果,但大多沒有考慮前景目標的時空連續性和局部結構,且在動態背景中提取目標的效果較差,基于此,提出了一種結合改進的張量核范數與3D-TV的TRPCA模型,下面詳細介紹。
1.1 前景建模
視頻前景的運動軌跡在第三維(時間)上通常是光滑的,故前景目標在時空域上具有光滑性和連續性的特征,而動態背景中微小物體的顯著變化呈現不連續的特性[4]。在數學上,全變分具有平滑信號的作用,對信號中的不連續變化具有較強的抑制作用[11]。因此,3D-TV 能有效地抑制由動態背景造成的噪聲干擾,其定義[4]如下:
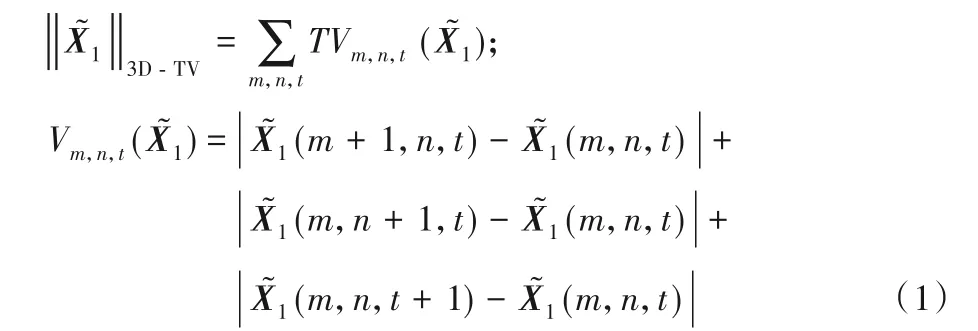
從上述定義可以看出,沿水平和垂直方向的差分算子表明3D-TV 考慮了前景目標在空間上的連續性;同時沿時間方向的差分算子表明其考慮了前景目標在時間上的持續性。
為計算方便[11],引入沿水平、垂直和時間方向的向量差分算子:

1.2 背景建模
在TRPCA 模型中,通常采用張量核范數代替秩函數來約束背景。但是一般的張量核范數是對張量進行矩陣化,然后用矩陣的奇異值來定義張量核范數,破壞了視頻的空間結構,對秩函數的近似程度不夠。基于t-product,Lu 等[8]提出了一種改進的張量核范數,定義如下:
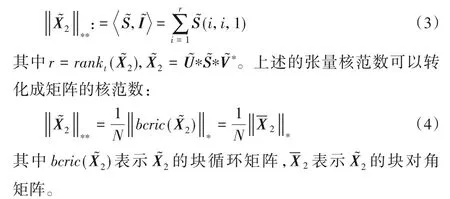
1.3 新模型的建立
基于以上討論,本文提出一種新的基于張量核范數和3D-TV的背景減除模型:

其中λ為平衡前景成分與背景成分的權衡參數。上述模型以TRPCA 為基礎,用改進的張量核范數加強背景的低秩性,以達到更加接近實際視頻背景的目的;用3D-TV來平滑信號,有效抑制動態背景的干擾作用。
2 模型的求解
為求解式(5),先引入輔助變量g,則上述模型變為:


3 實驗結果及分析
3.1 實驗數據和指標選取
為了驗證所提算法的效果,本文從CD.net數據庫[15]選取8 組大小為128×128×128 的視頻序列SnowFall 和Skating(復雜天氣)、Traffic 和Boulevard(相機抖動)、CopyMachine 和Backdoor(陰影)、PETS2006和Highway(基礎集),如圖1所示,并在相同的實驗環境下與HoRPCA[5]、IALM-RPCA(RPCA via Inexact Augmented Lagrange Multipliers)[3]、TRPCA-TNN[8]、KBR-RPCA[6]和文獻[4]算法從主觀和客觀兩方面進行比較。本文實驗的運行環境為Matlab 2014a,Inter Core i5-6500 處理器,8 GB的內存,Windows 10 64位操作系統。

圖1 實驗視頻集Fig.1 Experimental video set
為了在客觀上準確地評估本文算法的性能,采用查全率(recall)、查準率(precision)和綜合評判指標F-measure值(F值)來評價前景背景分離的效果,其定義[16]分別為:

其中:tp表示檢測出正確的前景像素點;fp表示誤檢為前景的背景像素點;fn表示誤檢為背景的前景像素點。其中recall、precision和F值均在0~1,且其值越大,得到的結果就越精確。
3.2 主觀分析
圖2前4行給出了復雜天氣和相機抖動的視覺效果,從中看出,對于復雜天氣和相機抖動,HoRPCA 和TRPCA-TNN 提取前景的效果較差;IALM-RPCA 對Skating 和Boulevard 的提取效果較好,但對SnowFall 和Traffic 目標的移動對前景提取產生較大的干擾,對前景的誤判較大;KBR-RPCA 由于飄落的雪花和白雪的覆蓋容易將把白色背景部分誤判為前景,且出現較大的空洞現象;對SnowFall 和Traffic 文獻[4]算法同樣由于目標的移動和復雜天氣而對前景提取產生較大的誤判,出現較大的運動軌跡;本文算法對前景目標提取的效果較好,對前景的誤判較小,有效抑制動態背景的干擾作用,雖然對Skating的前景提取效果較差,且出現少量的背景部分,但從表1知本文的F值要遠高于其他算法。
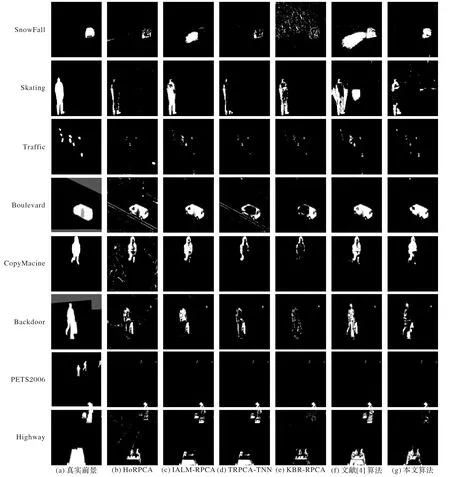
圖2 不同算法下的視頻集視覺效果對比Fig.2 Visual effect comparison of experimental video set by different algorithms
圖2 后4 行給出了陰影和基礎集的視覺效果。從圖2 看出,對于陰影和基礎集,HoRPCA 和KBR-RPCA 提取前景的效果較差,且易將背景誤判為前景;TRPCA-TNN 提取的目標存在著較大的空洞現象;IALM-RPCA、文獻[4]算法和本文算法提取前景的效果較好,且空洞現象和對前景的誤判較少,其中Backdoor和Highway,文獻[4]算法提取前景的效果優于其他2種算法,但在客觀評判指標上本文算法有較高的F值。
綜上所述,本文算法在前景背景分離中提取前景的效果較好,對前景的誤判和目標中的空洞現象較少,且有效抑制了動態背景和目標移動對前景提取的干擾。
3.3 客觀分析
將本文算法與其他5 種算法進行對比,其評判指標recall、precision和F值見表1。從表1 可以看出,本文算法的recall值基本上高于其他5 種算法,基本上處于最優的情況。因此,本文算法在前景背景分離中有較高的查準率,對運動目標有較為準確的提取效果。表1中文獻[4]算法的precision值在一些視頻上比本文算法占有一定的優勢,雖然HoRPCA、IALM-RPCA、TRPCA-TNN 和KBR-RPCA 算法的precision值有比本文算法高的情況,但由于recall只能反映丟失運動目標內部信息的相關性,precision只能反映丟失目標外部信息的相關性,且兩者指標值有時會出現矛盾的情況,因此采用它們的調和平均值F值來綜合判斷提取效果更準確。本文算法的F值均處于最優或次優的情況,因此本文算法在提取前景上有較高的準確率,且對前景的誤判較小。另外,表1 給出了5 種對比算法與本文算法的運行耗時,看出本文算法在運行耗時方面占有一定的優勢,雖然運行耗時高于IALM-RPCA 和TRPCA-TNN,但在客觀評判指標F值上均優于上述兩種算法(表1)。并且不同于文獻[4],本文算法把視頻當作張量來整體處理,故節約了內存,運行耗時上優于文獻[4]。
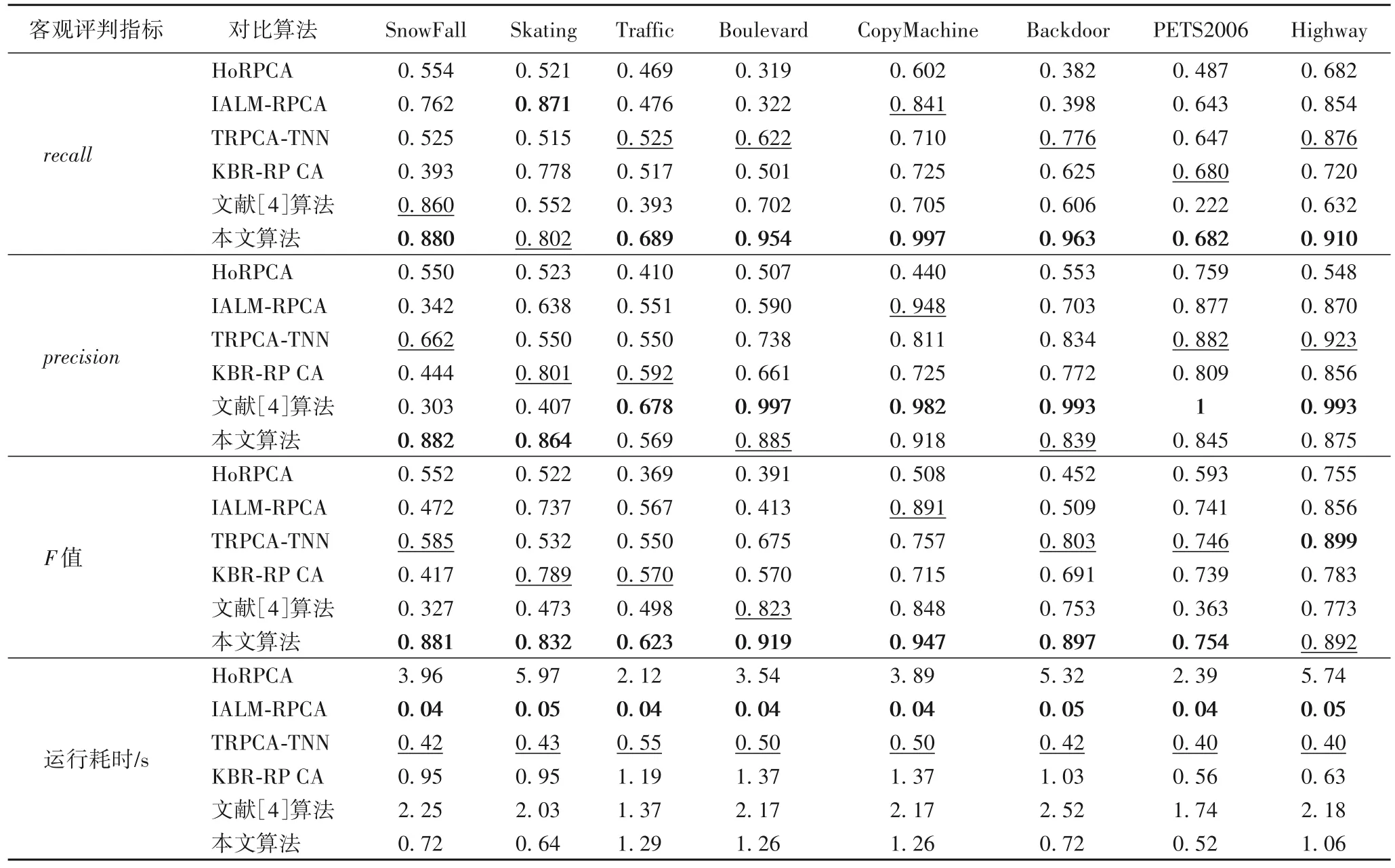
表1 不同算法下的客觀評判指標對比Tab.1 Comparison of objective evaluation indicators of different algorithms
4 結語
以TRPCA 模型為基礎,本文首先利用改進的張量核范數代替秩函數約束背景的低秩性,加強了視頻背景在時空上的連續性;再利用3D-TV 代替L1范數,有效抑制了動態背景的噪聲干擾。實驗結果表明,與經典算法以及目前最新算法相比,本文算法提取的前景目標空洞現象較小,有效抑制了動態背景和目標移動對前景提取造成的干擾作用,減少了對前景的誤判。
猜你喜歡
汽車工程師(2021年12期)2022-01-17 02:29:54
中老年保健(2021年12期)2021-11-30 02:58:01
建材發展導向(2021年6期)2021-06-09 05:57:08
現代國際關系(2021年2期)2021-04-13 01:59:16
當代陜西(2020年14期)2021-01-08 09:30:42
中國外匯(2019年11期)2019-08-27 02:06:32
攝影之友(影像視覺)(2019年2期)2019-03-05 08:27:14
中華詩詞(2018年11期)2018-03-26 06:41:34
貴州師范學院學報(2016年4期)2016-12-01 03:54:07
Coco薇(2016年8期)2016-10-09 02:11:50
