保密風險指數評估與預測模型及應用
2020-09-29 06:55:08雷宇
科學技術創新 2020年29期
雷宇
(航空工業成都飛機工業(集團)有限責任公司,四川 成都610091)
1 概述
軍工單位的保密風險管理主要集中在建立適用于本單位保密風險管理體系,梳理單位各個作業面的風險點并進行風險評估,制定相應的風險控制措施,實現優化保密業務管理,以最小成本將失泄密風險控制在單位業務工作可以接受的水平,以此獲得最大的信息安全防護。
全面進行保密系統的風險評估的首要關鍵問題建立健全的指標體系并量化計算。當評估指標數量不太多的時候,傳統的數學模型能夠在定量分析上取得較合理的評估結果,例如采用定性和定量相結合的保密管理風險評估方法,計算出年度保密風險的分布狀態[1];采用歸一化、標準化及層次分析法等方法對模型指標進行求解,建立了保密工作風險評估模型[2]。但是當指標數量較多時,由于模型本身的局限性, 難以處理隨機干擾因素對風險評估數據的影響,因而很難正確反映風險評估數據或者風險指數本身的高度不確定性與非線性,導致在風險評估及風險指數預測方面產生較大的誤差。因此,本文從單位保密實際工作出發,對定期獲得的保密風險指數,采用K-means 聚類分析方法,識別出保密風險評估指標體系高風險指標集,將識別出來的高風險指標作為當前保密工作的防控重點;同時為了加強保密工作的風險預警,結合風險指數的歷史評估數據,采用Elman 神經網絡,預測各個指標在下一個時間段的風險指數值,并對預測為高風險的指標或者風險點采取主動預警防范措施,提高單位保密風險管理水平。
2 保密風險指數及K-Means 聚類評估
2.1 風險指數及風險等級
結合保密風險發生可能性大小、影響程度和管理改進迫切性三個維度[3],根據數學模型可以計算出單位的保密風險指數,并確定該單位的風險等級[4]。

表1 風險水平等級確定與排序列表
為了便于問題描述,本文假設風險評估指標數量為n,對于每個指標統計了第 1,2, ...,T個月的風險指數值
Xij, i =1,2,..., n, j =1,2,...,T 。
2.2 基于K-means 聚類的高危指標篩選
K-means 聚類算法基本思想是: 以空間中k 個點為形心進行聚類,以數據點到形心的歐式距離作為優化函數,利用函數求極值的方法得到迭代運算的調整規則[5]。通過迭代的方法,逐次更新各類的形心值,直至得到最好的聚類結果。結合保密風險水平數據,K-means 聚類的一般步驟可以歸納為:
(2)在第j 次迭代中,對任意一個樣本點 pt(t =1,2,..., n),求其到k 個形心的歐氏距離
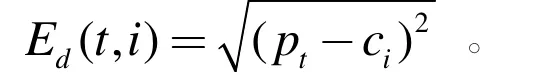
(3) 將該樣本歸類到與其距離最小的形心所在的類。
(4) 采用均值更新各類的形心值
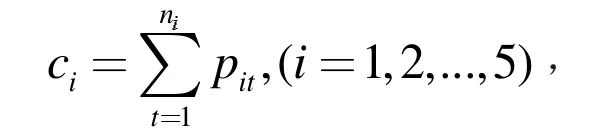
式中 ni表示類別序號。
(5) 重復步驟(2) - (4) , 直到各類的形心值不再變化。
3 基于Elman 神經網絡的風險指數預測
針對保密風險指數具有非線性動態變化的特點,本文采用具有“記憶”功能的Elman 神經網絡預測模型。這種連接方式使得Elman 神經網絡相較于其他神經網絡相比,具有自聯性和記憶功能,有助于增強對于動態數據的處理能力,以及建立動態模型[6]。Elman 神經網絡是一種計算能力很強的反饋性神經網絡,其具體的網絡結構如圖1 所示。
Elman 神經網絡結構一般分為四層:輸入層、隱含層、上下文層和輸出層。輸入層單元起信號傳輸作用,輸出層單元起線性加權作用,隱含層單元的傳遞函數可采用線性或非線性函數,上下文層則從隱含層接收反饋信號,其神經元輸出被前向傳輸至隱含層。
3.1 Elman 神經網絡結構
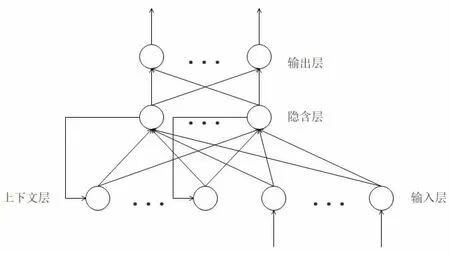
圖1 Elman 神經網絡結構圖
在Elman 神經網絡中,設上下文層的輸出為 yc( k),隱含層的輸出為 o ( k ),網絡在外部輸入時間序列 x ( k)作用下的網絡輸出序列為 y ( k),則有
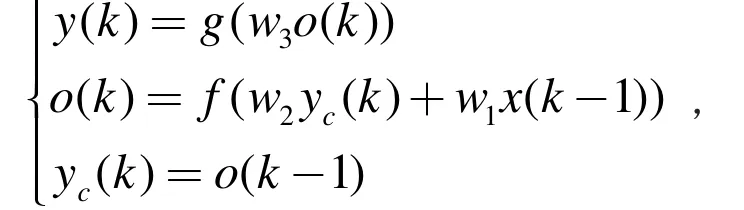
其中,k 表示時刻;w1為輸入層與隱含層間的連接權值;w2為上下文層與隱含層間的連接權值;w3為隱含層與輸出層間的連接權值;g (·)為輸出層傳遞函數,是隱含層輸出的線性組合;f (·)為隱含層傳遞函數,一般采用Sigmoid 激活函數:
f ( x) = 1/(1 +e-λx)。
網絡學習過程是一個不斷調整權值的過程,而Elman 神經網絡使用BP 算法來修正權值。設K 時刻的系統實際輸出值為Y(k),則Elman 神經網絡的目標函數為:通過調整w1、w2和w3的值,使得誤差E 最小,從而確定權值。
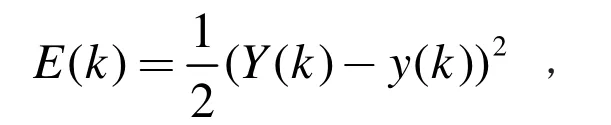
3.2 Elman 神經網絡的預測模型
3.2.1 輸入數據的處理
由于給定某個指標的歷史風險指數值本質上可以看成一個時間序列,作為Elman 神經網絡的輸入數據是多維的,因此需要將時間序列數據截取為多維向量組作為網絡訓練數據輸入,不防假設第i 個指標的歷史風險指數序列為:
Xi=( xi1, xi2, xi3,..., xiT),
設截取維數為l,如 ( xi1, xi2,..., xi,l-1, xil)就是一組訓練集,表示通過 xi1, xi2,...,xi,l-1共 l-1個數據可以預測到第l個數據xij,這樣Xi就可以轉化為T-l+1 個訓練數據
( xi1, xi2,..., xi,l-1, xil),...,( xi,T-l+1, xi2,..., xi,T-1, xiT)。
同時,由于該數據是已知數據,根據保密風險指數計算方法,所有的保密風險指數值均介于0-5 之間,因此無須對數據進行標準化或者歸一化處理。
3.2.2 網絡參數的選擇
神經網絡中隱含層的層數是非常重要的參數。在選取過程中,若選取的隱含層層數較小,則會導致產生的連接權組合數無法滿足樣本的學習,學習能力和處理信息能力降低。若選取的隱含層層數較大,則網絡學習的泛化能力較差,而且容易在計算過程中錯過最小值,因此選取合適的隱含層個數就成為一個重要的問題。通常隱含層層數的確定通過如下三個經驗公式確定,得出最大值和最小值,確定隱含層個數的范圍,然后在Elman 神經網絡模型中依次代入訓練,選擇最小值[6],
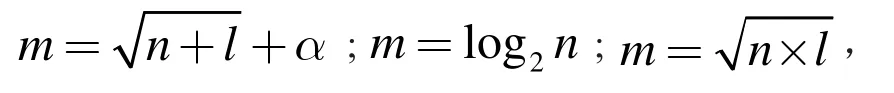
其中m 為隱含層結點數,n 為輸入層節點數,l 為輸出層節點數,α 為介于1-10 內的常數。
3.2.3 預測數據的后處理
將待預測的數據帶入訓練好的Elman 網絡即可得到預測結果,但是預測后的某些數據會超出風險指數值介于0-5 之間的約束條件。如果發生這種情況,還需要將數據校正,以便用于下一步的預測。本文采用最簡單的截斷處理方式,即如果風險指數值大于5,則該風險指數修正為上限值5;如果出現預測風險指數值小于0,則將其值校正為風險指數值的下限值0。
4 實例分析
風險評估指標數量為 n= 100,歷史數據為24 個月( T=24)的風險指數值。本文數據利用計算機隨機生成,得到相應的風險指數矩陣為 X100×24。
4.1 K-means 聚類的結果
在對保密風險指數的評估分類中,不需要考慮歷史數據,所以只選取最后一個月的風險指數值進行K-means 聚類,并計算每個類別的風險指數均值進行風險等價劃分。此處給出第24個月的100 個指標的風險指數值,如表2 所示。
利用K-means 聚類對該表的風險指數聚類,100 個指標的具體風險等級分類結果見表3。
根據表3 的結果,保密管理部門可以加強對屬于重大風險和高風險的指標實時重點監控,督促改進保密措施,降低保密風險水平。
4.2 Elman 神經網絡的預測結果
對于歷史風險指數數據,取l=4,也就是相鄰4 個數據作為一個樣本,其中前3 個設為已知的風險指數值,第4 個月為預測的風險指數值,以此類推,每個指標的24 個月的風險指標觀測數據最終可被分為21 個樣本。選擇前80%的數據作為訓練樣本,后20%的數據作為測試樣本。
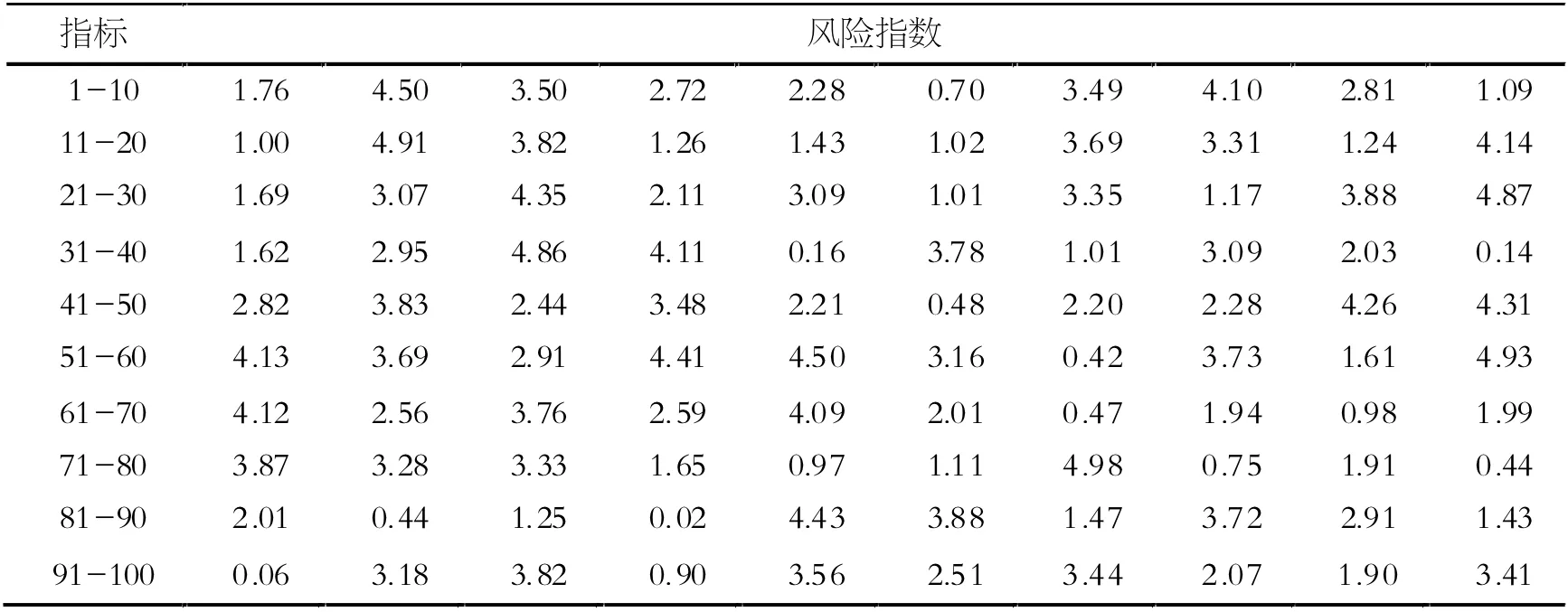
表2 100 個指標第24 月的風險指數
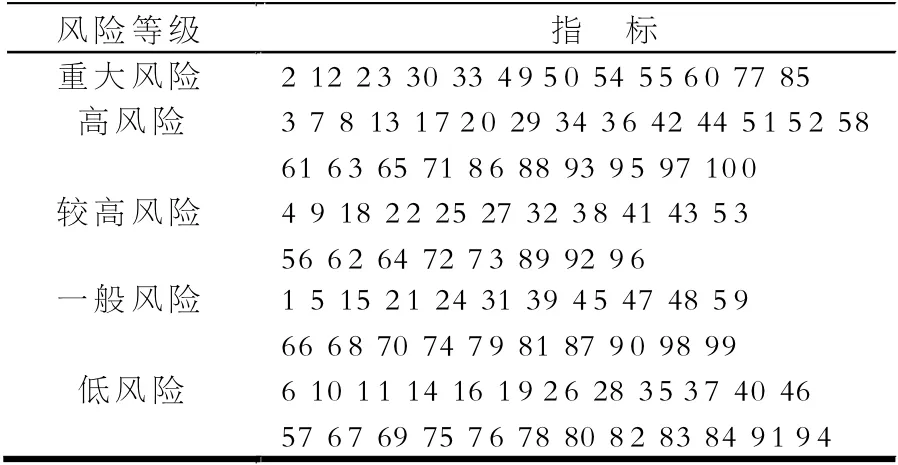
表3 第24 月風險指數分類結果
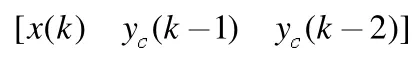
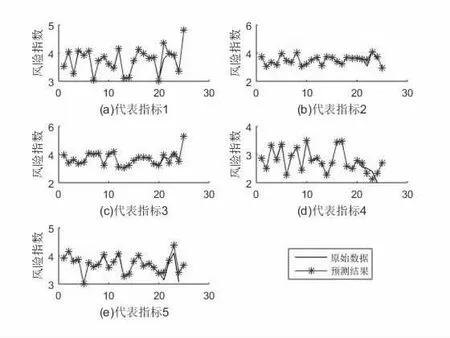
圖2 選取5 個具有代表性指標的預測結果
從圖2 可以看出,Elman 神經網絡預測效果較理想,預測結果表現出歷史數據的波動性和周期性特點。
4.3 預測結果再次聚類評估
對Elman 神經網絡的預測結果,利用K-means 聚類對第25月的風險指數再次進行聚類評估,100 個評價指標的風險指數值在預測后的風險等級詳細分類結果見表4:
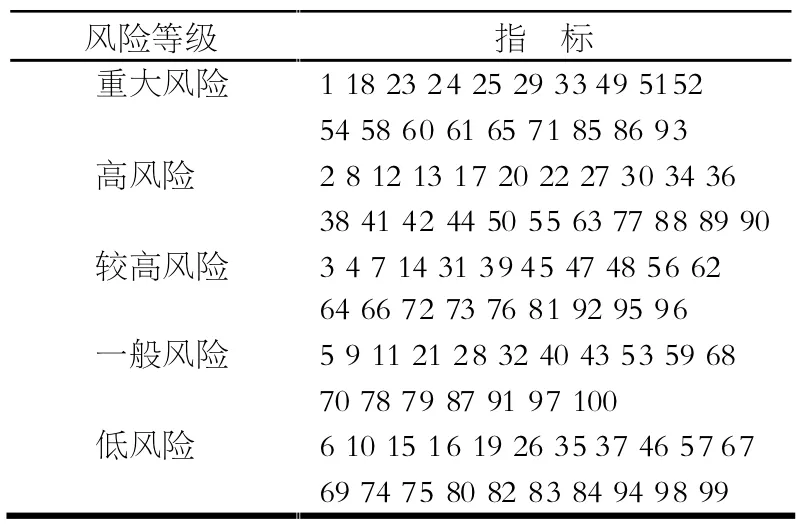
表4 第25 月風險指數分類結果
根據表4 中的結果,保密管理部門必須對重大風險和高風險指標發出風險預警,加強這些指標所對應的工作部門的風險管控。
5 結論
對保密管理工作中的大量風險評估指標以及保密風險指數數據,利用K-means 聚類算法對評估指標進行自動分類并確定風險等級,采用Elman 神經網絡進行保密風險指數的動態時序預測,所建立的模型能有效地應用到單位保密工作的信息化管理中。
