基于深度學習與超分辨率重建的遙感高時空融合方法*
2020-10-10 02:39:42張永梅滑瑞敏馬健喆
計算機工程與科學 2020年9期
張永梅,滑瑞敏,馬健喆,胡 蕾
(1.北方工業(yè)大學信息學院,北京 100144;2.香港理工大學電子與信息工程系,香港 00852; 3.江西師范大學計算機信息工程學院,江西 南昌 330022)
1 引言
受限于衛(wèi)星傳感器的硬件條件與發(fā)射成本,在可獲取的單一遙感數(shù)據(jù)中,其空間分辨率和時間分辨率成為一對矛盾體[1 - 3],若想要盡可能地提高遙感影像的空間分辨率,結果則可能引發(fā)“時間數(shù)據(jù)缺失”[4],反之難免又會犧牲影像的空間分辨率,制約了遙感影像的應用。在早期發(fā)射升空的衛(wèi)星傳感器所得到的數(shù)據(jù)中這種表現(xiàn)尤為明顯[5],造成了對一直以來積累下來的龐大數(shù)據(jù)難以直接利用。
多源遙感圖像融合是指將不同傳感器獲得的同一場景的圖像或者同一傳感器在不同時刻獲得的同一場景圖像,經(jīng)過相應處理后,再運用某種融合技術得到一幅合成圖像的過程[6],其為解決上述遙感影像時空矛盾問題提供了一條出路,即遙感影像的時空融合方法。
傳統(tǒng)的時空融合模型包括基于變換的模型和基于像元重構的模型[4]。基于變換的模型是指對遙感影像進行數(shù)據(jù)變換(如小波分解等)后,對變換所得數(shù)據(jù)進行融合處理,最后再進行反變換從而得到想要的未知時刻高分辨率影像。如Malenovsk等[7]利用小波變換對MODIS(MODerate-resolution Imaging Spectroradiometer)影像的低頻信息和Landsat影像的高頻信息進行融合,驗證了MODIS與Landsat影像融合的可能性,但其所得結果的分辨率只達到了240 m,且在有變化發(fā)生的區(qū)域效果較差;基于像元重構的模型主要是將低空間分辨率圖像進行像元分解,計算出不同時相上遙感影像的變化關系,同時還需求出不同分辨率影像間的變化關系,再通過插值得到未知時刻的高空間分辨率圖像。如在時空融合領域影響最為深遠的時空自適應反射率融合模型STARFM(Spatial Temporal Adaptive Reflectance Fusion Model)[8]屬于基于像元重構的模型,該模型在融合過程中不僅考慮了空間的差異性,而且還考慮了時間的差異性,是目前應用最廣泛的時空融合模型之一,但在地物覆蓋復雜、像元混合嚴重時往往精度較差。
隨著機器學習的蓬勃發(fā)展,基于學習的遙感影像時空融合模型應運而生,如趙永光等[9]提出了一種利用稀疏表示對低空間分辨率圖像進行超分辨率重建,再對數(shù)據(jù)進行高通濾波后融合的方法,取得了良好的融合效果。但是,通常基于學習的模型使用淺層學習較多,同時方法復雜度較高,運行效率低,較難實現(xiàn)大區(qū)域的融合,且在空間分辨率上不宜相差過大,一般只有4倍左右[2]。
為了實現(xiàn)融合質(zhì)量的進一步提升,本文選擇將學習能力更強、特征提取更有力的深度學習方式引入遙感時空融合中。在現(xiàn)有基于學習的遙感影像時空融合的基礎上,通過對SRCNN (Super Resolution Convolutional Neural Network)網(wǎng)絡進行二次學習的方法來重建低分辨率圖像。SRCNN網(wǎng)絡結構簡單,可以相對緩解本文方法復雜度的提升,而二次學習的方式可以緩解融合時分辨率差距過大的影響。本文基于STARFM的基本思想,在融合過程中采用神經(jīng)網(wǎng)絡自動提取特征,學習映射關系,代替原本在滑動窗口內(nèi)篩選相似像元與計算其權重的過程。實驗表明,本文方法改善了遙感影像時空融合的質(zhì)量。
2 基于改進STARFM的遙感高時空融合方法
2.1 基于深度學習的超分辨率重建方法
由于衍射現(xiàn)象的存在,通常成像系統(tǒng)所能達到的最高分辨率受限于成像光學器件本身,傳統(tǒng)改善圖像質(zhì)量方法難以復原出系統(tǒng)在截止頻率以外的信息[10],而超分辨率重建SR(Super resolution Restoration)技術采用信號處理方法,能夠重建出成像系統(tǒng)截止頻率之外的信息,從而得到高于成像系統(tǒng)分辨率的圖像[11]。
傳統(tǒng)的超分辨率重建技術分為基于重建的方法和基于淺層學習的方法[12]。基于重建的方法將多幅低分辨率圖像進行亞像素精度對齊來求出不同分辨率圖像之間的運動偏移量,從而構建出空間運動參數(shù),再通過各種先驗約束條件與最優(yōu)解來重建出高分辨率圖像[13]。基于淺層學習的方法旨在通過學習獲得高低分辨率圖像之間的映射關系來指導圖像的重建,通常分為特征提取、學習和重建3個階段,且各階段相互獨立[14],導致淺層學習特征提取與表達能力有限,有待進一步加強。
近年來,深度學習技術發(fā)展迅猛。在超分辨率重建問題中使用深度學習網(wǎng)絡,在結構上仍需參考傳統(tǒng)超分辨率重建方法的思想進行設計,使其作為預測器能夠輸出較為準確的預測值[15]。
香港中文大學Dong等人[16]于2016年首次將卷積神經(jīng)網(wǎng)絡CNN(Convolution Neural Network)應用于超分辨率重建中,提出了一種新的網(wǎng)絡SRCNN。首先從深度學習與傳統(tǒng)稀疏編碼SC(Sparse Coding)之間的關系入手,將網(wǎng)絡分為圖像塊提取、非線性映射和圖像重建3個階段,使其分別對應于深度卷積神經(jīng)網(wǎng)絡框架中的3個卷積層,統(tǒng)一于該神經(jīng)網(wǎng)絡之中,從而實現(xiàn)了由低分辨率圖像到高分辨率圖像的超分辨率重建。該網(wǎng)絡直接學習低分辨率圖像和高分辨率圖像之間的端到端映射,除了優(yōu)化之外,幾乎不需要預處理和后處理。
在SRCNN中使用的3個卷積層卷積核大小分別為9×9,1×1和5×5,前2個輸出的特征個數(shù)分別為64和32。SRCNN將稀疏編碼的過程視為一種卷積運算,網(wǎng)絡設計簡單,并且重建效果相比作為淺層學習代表的SCSR(Sparse Coding based Super Resolution)[17]方法也有較大改善,是一種具有參考性的超分辨率重建方法。本文將通過二次學習方式,將其引入遙感影像時空融合中,從而提高低分辨率遙感圖像重建效果。
本文采用SRCNN方法對低空間分辨率數(shù)據(jù)進行超分辨率重建,以代替STARFM方法中低空間分辨率圖像的重采樣過程,然而由于本文使用的MOD09Q1遙感影像只有250 m空間分辨率,像元混合現(xiàn)象嚴重,而Landsat8遙感影像具有30 m空間分辨率,二者之間的分辨率相差8~9倍,描述空間細節(jié)信息的能力差距較大;并且由于得到遙感影像的不同傳感器之間存在著各種差異(幾何誤差),使得圖像之間即使同一時刻同一位置的像素反射率也有較大差異,故將SRCNN直接引入至遙感影像的時空融合比較困難。
基于學習模型的融合方法中影像之間的空間分辨率差距不宜過大,一般在4倍左右,差距過大容易造成深度學習神經(jīng)網(wǎng)絡的訓練困難,對低分辨率圖像進行分辨率增強的效果欠佳,像元混合嚴重的現(xiàn)象較難緩解。
為解決上述問題,本文選擇了一種進行二次學習的方法,先將低空間分辨率遙感影像從250 m分辨率經(jīng)過學習重建至90 m分辨率,再重建至30 m分辨率,從而保證了2次學習過程中分辨率差距均在4倍之內(nèi)。超分辨率重建方法流程如圖1所示。
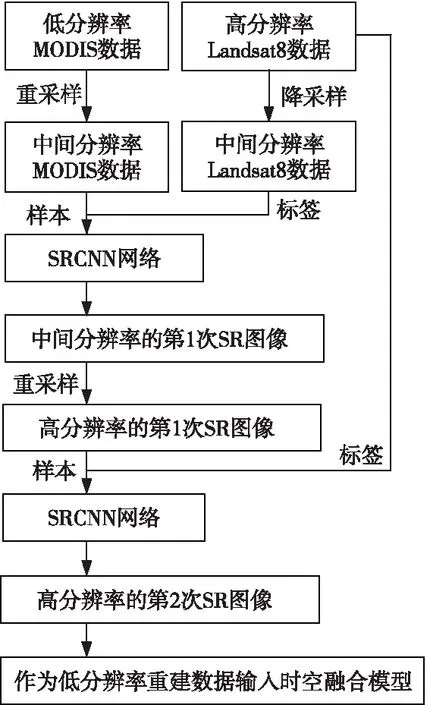
Figure 1 Flow chart of the super-resolution reconstruction method圖1 本文超分辨率重建方法技術路線
首先將具有30 m空間分辨率的Landsat8遙感影像使用最近鄰法降采樣到90 m分辨率,同時將具有250 m空間分辨率的MOD09Q1遙感影像使用雙三次插值法重采樣到90 m分辨率。如圖2所示,經(jīng)過采樣后的遙感影像雖然形式上具有了相同的分辨率,但在空間細節(jié)上差距仍較大。本文使用SRCNN對采樣后的2組數(shù)據(jù)進行第1次學習,得到90 m分辨率的MOD09Q1重建圖像。將得到的90 m分辨率重建圖像重采樣至30 m分辨率,與具有30 m分辨率的Landsat8原始數(shù)據(jù)一起利用SRCNN進行第2次學習,得到具有30 m分辨率的MOD09Q1重建圖像,本文將該重建圖像作為時空融合模型中的低分辨率輸入數(shù)據(jù)。

Figure 2 Comparison of MOD09Q1 and Landsat8 both converted to 90-meter resolution in the study area (2018.10.29)圖2 研究區(qū)域(2018.10.29)不同傳感器 采樣至90 m分辨率的遙感影像對比圖
傳統(tǒng)STARFM方法的輸入只將MODIS數(shù)據(jù)通過插值法重采樣到Landsat8數(shù)據(jù)的分辨率即可,本文在使用SRCNN網(wǎng)絡進行超分辨率重建時,將Landsat8數(shù)據(jù)作為MOD09Q1數(shù)據(jù)的先驗知識進行學習,一方面超分辨率重建的精度明顯優(yōu)于插值法重采樣結果,提升了STARFM的輸入質(zhì)量;另一方面,在學習過程中,能夠緩解由不同傳感器所造成的各種誤差,使重建得到的圖像在風格與相似性上也與作為輸入的高分辨率圖像更加接近。故該方法能夠盡可能還原出高低分辨率數(shù)據(jù)之間原本的差異信息,使得融合結果更加準確。
本文進行二次學習的2個SRCNN網(wǎng)絡具有相同的結構,區(qū)別只在于輸入和輸出不同,而且輸入和輸出的不同之處只體現(xiàn)在分辨率上,SRCNN網(wǎng)絡的訓練過程通過圖像切塊進行,故二次學習的2個網(wǎng)絡參數(shù)格式具有完全一致性,可以將訓練好的用于第1次學習的網(wǎng)絡參數(shù)遷移到用于第2次學習的網(wǎng)絡中,提高運行效率,緩解深度學習所帶來的時間復雜度的升高。
本文重建方法提高了高時間分辨率、低空間分辨率數(shù)據(jù)的空間分辨率,已得到了一定精度的高時空分辨率數(shù)據(jù),再將其輸入本文的改進STARFM方法中,相當于進行了雙層時空融合,從而保證了較好的融合效果。
2.2 時空自適應反射率融合模型
Gao等[8]提出的STARFM方法是遙感影像時空融合領域應用最廣泛的一種方法。該方法在忽略幾何誤差和大氣校正誤差的情況下,假設低空間分辨率(如MODIS)像元的反射率可以表示為高空間分辨率(如Landsat)對應像元反射率的線性組合。此時如果將低空間分辨率的遙感影像重采樣到分辨率相同的高分辨率遙感影像,則低空間分辨率像元與高空間分辨率對應位置像元存在如下關系:
M(x,y,t)=L(x,y,t)+ε
(1)
其中,M(x,y,t)、L(x,y,t)分別表示在t時刻MODIS影像和Landsat影像在坐標為(x,y)處像元的反射率,ε表示不同分辨率圖像由于傳感器不同等所造成的系統(tǒng)誤差。假設該ε不隨時間變化,若已有t0和tk時刻的MODIS數(shù)據(jù),以及t0時刻的Landsat數(shù)據(jù),則未知的tk時刻的MODIS數(shù)據(jù)可由式(2)求得:
L(x,y,tk)=
L(x,y,t0)+M(x,y,tk)-M(x,y,t0)
(2)
STARFM方法為避免假設所帶來的像元混合現(xiàn)象,通過滑動窗口技術引入了鄰近像元信息,即:
(L(xi,yj,tk)+M(xi,yj,t0)-M(xi,yj,tk))
(3)
其中,w是滑動窗口大小,n表示不同時間點的搖感影像進行融合的數(shù)量,wi,j,k為相應位置處像元對應的權值大小。在STARFM方法中,還需對上述滑動窗口中的相似像元進行搜索,并排除劣質(zhì)像元,只有篩選得到的像元才配置非零權重,而在對篩選后相似像元配置權重時,需要綜合考慮像元間的光譜距離Si,j,k、時間距離Ti,j,k和空間距離Di,j,k等,其計算公式分別如下所示:
Si,j,k=|L(xi,yj,tk)-M(xi,yj,tk)|
(4)
Ti,j,k=|L(xi,yj,t0)-M(xi,yj,tk)|
(5)
(6)
Di,j,k=1.0+di,j,k/A
(7)
其中,A是一個常量,定義了Si,j,k、Ti,j,k與Di,j,k之間重要程度的比例。該相似像元的權重wi,j,k計算公式為:
wi,j,k=Si,j,k×Ti,j,k×Di,j,k
(8)
或
wi,j,k=ln(Si,j,k×B+1)×
ln(Ti,j,k×B+1)×Di,j,k
(9)
其中,B是取決于傳感器分辨率間差距的比例因子。求出滑動窗口內(nèi)所有篩選后相似像元權重wi,j,k后,再對其進行歸一化處理,即可求得聯(lián)合權重矩陣W,從而預測出未知時刻高分辨率遙感影像像素的分辨率。
由于MODIS影像和Landsat影像間分辨率差距過大,在重采樣的過程中像元混合嚴重,制約了STARFM方法預測的準確率[9],本文將引入改進的SRCNN來克服這一現(xiàn)象,提高時空融合的質(zhì)量。
另外,STARFM在引入滑動窗口技術時權重的計算取決于光譜距離、時間距離與空間距離的組合,可視為一種根據(jù)專家經(jīng)驗知識提取的手工特征。本文基于STARFM的基本思想,采用SRCNN作為基本框架,利用神經(jīng)網(wǎng)絡來自動計算該特征,充分利用深度學習強大的特征提取與表達能力,進一步提高時空融合的質(zhì)量。
3 實驗結果與分析
3.1 研究區(qū)域及數(shù)據(jù)源
本文選擇在遙感時空融合領域中經(jīng)典的MODIS和Landsat數(shù)據(jù)進行融合,充分利用二者分別在時間分辨率和空間分辨率上的優(yōu)勢。MODIS數(shù)據(jù)選擇了空間分辨率為250 m、重訪周期為1天的MOD09Q1(8天合成數(shù)據(jù))的第1波段紅色波段和第2波段近紅外波段數(shù)據(jù);Landsat數(shù)據(jù)選取了空間分辨率為30 m、重訪周期為16天的Landsat8相應的第4、5波段[18],所舉圖例均以紅色波段實驗數(shù)據(jù)作為代表。本文的研究區(qū)域位于陜蒙交界一帶,地理坐標38°47′59″N ~ 39°12′5″N,110°20′35″E ~ 110°49′6″E,實驗截取的地理范圍為45 km×45 km。
本文實驗所用數(shù)據(jù)均來源于NASA官網(wǎng)USGS (https://earthexplorer.usgs.gov/),選取了2015年~2019年該研究區(qū)域內(nèi)所有云量少于1%的數(shù)據(jù)。使用MCTK (MODIS Conversion Toolkit)工具將MODIS數(shù)據(jù)從HDF數(shù)據(jù)格式轉換為TIF數(shù)據(jù)格式,并重投影到UTM-WGS84坐標系,所有數(shù)據(jù)均使用ENVI軟件根據(jù)對應坐標裁剪到指定區(qū)域并進行配準。從圖3可以看到,低分辨率的MOD09Q1影像在部分地區(qū)像元混合現(xiàn)象較嚴重。從圖4可以看到該研究區(qū)域地物類型復雜,包括水體、山脈、沙地、林地、耕地、建筑物、道路等,且部分地物相間分布。該研究區(qū)域?qū)儆谑褂脗鹘y(tǒng)時空融合方法較難處理的類型。

Figure 3 Comparison of MOD09Q1 and Landsat8 in the study area (2018.10.29)圖3 研究區(qū)域(2018.10.29)不同傳感器遙感影像對比圖

Figure 4 Landsat8 true color image in the study area (2019.04.23)圖4 研究區(qū)域(2019.4.23)Landsat8真彩色遙感影像圖
3.2 實驗方法
3.2.1 超分辨率重建實驗方法
傳統(tǒng)SRCNN在處理自然圖像時是一種單幅圖像超分辨率重建技術,即樣本和標簽是基于同一幅圖像變換所得,在訓練之前先將樣本圖像進行降采樣得到分辨率僅為原始圖像1/3的低分辨率圖像;再將該降采樣圖像使用雙三次插值法放大至原樣本圖像尺寸,此時仍視其為低分辨率圖像,并作為SRCNN的輸入樣本。在進行訓練時,SRCNN將沒有經(jīng)過降采樣處理的原樣本圖像作為高分辨率先驗知識進行學習,再把訓練得到的網(wǎng)絡作用于相同類型的測試集圖像上進行檢測[16]。
本文在引入SRCNN時,進行了2種嘗試。以上述第1次學習為例,方法1是直接使用高分辨率遙感影像進行單幅圖像超分辨率重建,即使用上述傳統(tǒng)的SRCNN只訓練降采樣后的90 m分辨率Landsat8圖像這一組數(shù)據(jù),再將所得到的網(wǎng)絡作用于同一時刻同一地區(qū)的低分辨遙感影像,即經(jīng)過重采樣的90 m分辨率MOD09Q1數(shù)據(jù),對比90 m分辨率的Landsat8數(shù)據(jù)檢測實驗結果;方法2是使用已有的高分辨率圖像作為同一時刻同一地區(qū)的低分辨率圖像的先驗知識進行學習,本文采用經(jīng)過采樣后所得同為90 m分辨率的Landsat8圖像和MOD09Q1圖像2組數(shù)據(jù)來訓練SRCNN,通過該網(wǎng)絡可以得到重建后90 m分辨率的MOD09Q1圖像,同樣對比降采樣的90 m分辨率Landsat8數(shù)據(jù)檢測實驗結果。
在測試集上得到的實驗結果對比圖如圖5所示(像素數(shù)沒對應是由于外圍元素卷積運算時不填充),從中可以看到,同樣以MOD09Q1數(shù)據(jù)信息作為基礎,相比方法1,方法2所得圖像在風格上與Landsat8數(shù)據(jù)更為接近。本文采用均方誤差MSE(Mean Squared Error)作為損失函數(shù)來訓練SRCNN。實驗結果中方法1的MSE值為0.087 575 69,方法2的MSE值為0.042 040 63,方法2相比方法1的實驗結果具有更豐富的空間細節(jié)信息。

Figure 5 Comparison of restructed images with 90-meter resolution by different methods in the study area (2015.7.1)圖5 研究區(qū)域(2015.7.1)不同方法重建得到 90 m分辨率的實驗結果對比圖
本文使用方法2在第1次學習后得到了具有較高質(zhì)量90 m分辨率的MOD09Q1重建圖像,將該圖像重采樣至30 m分辨率后,再次利用SRCNN網(wǎng)絡使用方法2進行第2次超分辨率重建。本次重建使用30 m分辨率的原始Landsat8遙感影像作為其先驗知識,得到如圖6c所示30 m分辨率的第2次超分辨率重建結果。對比相應的Landsat8數(shù)據(jù),其MSE值為0.029 617 50。本文將該結果作為STARFM模型中低分辨率遙感影像的輸入。
圖6所示為本文通過二次學習進行超分辨率重建得到的實驗結果與原始數(shù)據(jù)對比圖,從中可以看到,圖6a~圖6d空間細節(jié)逐漸豐富。從整體角度來看,可以認為實驗是以圖6d作為圖6a的先驗知識訓練神經(jīng)網(wǎng)絡的,中間先經(jīng)過圖6b最終得到圖6c。圖6d作為先驗知識空間細節(jié)信息最為豐富,但時間分辨率為16天,而實驗得到的圖6c在空間細節(jié)上僅次于圖6d,且時間分辨率只有1天,本文將其與圖6d進行時空融合,可以得到時間分辨率為1天、空間細節(jié)信息更為豐富的合成影像,進一步提升了遙感影像時空融合的精度。

Figure 6 Comparison of original data and reconstructed results in the study area (2018.10.29)圖6 研究區(qū)域(2018.10.29,紅色波段) 實驗數(shù)據(jù)與實驗結果對比圖
3.2.2 時空融合實驗方法
STARFM作為應用最為廣泛的時空融合模型,其基本原理經(jīng)過眾多實際應用的考驗,證實了其正確性與優(yōu)越性,并且在該過程中,其所存在的一些不足也被學者們加以改善。本文在3.2.1節(jié)通過二次學習使用SRCNN進行超分辨率重建的方法,改善了其在低空間分辨率數(shù)據(jù)重采樣過程中像元混合嚴重所導致的精度不足現(xiàn)象。本文采用SRCNN作為基本框架,通過深度學習神經(jīng)網(wǎng)絡方法來提取圖像特征,發(fā)現(xiàn)并學習高低分辨率數(shù)據(jù)之間的映射關系。
STARFM的基本思想就是利用已知時刻的高低空間分辨率數(shù)據(jù)和未知時刻的低空間分辨率數(shù)據(jù)來對未知時刻的高空間分辨率數(shù)據(jù)進行預測,如式(2)所示。STARFM在具體實現(xiàn)時為了減輕像元混合現(xiàn)象的影響,通過滑動窗口技術引入鄰近像元信息來計算中心像元的反射率,根據(jù)特定規(guī)則篩選出相似像元,并排除劣質(zhì)像元,根據(jù)圖像對間的光譜距離、時間距離以及窗口內(nèi)部的空間距離由特定的公式來計算出像元對應的權重,得到滑動窗口的權值矩陣[8]。
STARFM在實現(xiàn)過程中無論是在滑動窗口內(nèi)篩選或排除像元時所用的規(guī)則,還是計算權重時所用的特定公式,都屬于專家知識范疇,即手工提取的特征。本文采用神經(jīng)網(wǎng)絡進行深度學習來替代該過程,實現(xiàn)特征的自動提取。
基于STARFM的基本思想,在已知t0時刻高分辨率數(shù)據(jù)與tk時刻低分辨率數(shù)據(jù)時,通過式(2)計算所得到的數(shù)據(jù)可視為預測理論值,本文將其作為學習樣本,并將對應時刻的高分辨率實際數(shù)據(jù)作為標簽,輸入SRCNN中進行訓練,即可學習得到預測理論值與實際標簽間所存在的映射關系。STARFM所使用的滑動窗口計算方法也是對該映射的一種直接計算方式。
圖7a為STARFM方法融合所得預測結果,本文使用上述網(wǎng)絡進行實驗,得到的實驗結果如圖7b所示。

Figure 7 Comparison of fusion images by STARFM and the proposed method in the study area (2018.10.29)圖7 研究區(qū)域(預測2018.10.29,紅色波段) STARFM融合方法與本文改進融合方法對比圖
從圖7中可以明顯看出,原先在MOD09Q1及其重建圖像中只顯示為圖像斑塊的地方(像元混合嚴重),融合結果具有了與Landsat8原始影像相同的空間細節(jié)信息,預測結果對比真實結果MSE值為0.008 333 66。實驗中圖7a與圖7b都是基于同樣的數(shù)據(jù)進行融合,即低分辨率圖像均經(jīng)過本文2.1節(jié)超分辨率重建處理。可以看到,使用手工特征的STARFM方法融合預測的結果雖然也明顯呈現(xiàn)了更多的空間細節(jié),圖像風格也與Landsat8數(shù)據(jù)更加接近,但在部分區(qū)域圖像斑塊仍然較多,在細節(jié)上與本文的實驗結果(圖7b)仍有一定差距,其作為融合預測結果與真實數(shù)據(jù)相比的MSE值為0.017 497 47。故采用神經(jīng)網(wǎng)絡自動提取特征的方法相比利用滑動窗口手工提取特征的方法提升了融合質(zhì)量。
3.2.3 實驗結果與分析
本文已經(jīng)從主觀評價的角度對實驗結果進行了分析。此外,本文采用峰值信噪比PSNR(Peak Signal-to-Noise Ratio)和結構相似性SSIM(Structural Similarity Index)作為客觀評價指標來對實驗結果進行進一步分析,其計算公式分別如下所示:
(10)
(11)
其中,MSE(f1,f2)表示2幅圖像的均方誤差,μ1、μ2、σ1、σ2分別表示2幅圖像的均值和方差,σ12表示2幅圖像間的協(xié)方差,C1、C2是用來維持穩(wěn)定的常數(shù)。
PSNR是一種應用非常廣泛的圖像客觀評價指標,PSNR越大表示圖像的失真越小,然而其作為一種基于誤差敏感的圖像質(zhì)量評價指標,并未考慮到人眼的視覺特性(人眼對空間頻率較低的對比差異敏感度較高,對亮度對比差異的敏感度較色度高,對一個區(qū)域的感知結果會受到其周圍鄰近區(qū)域的影響等),因而經(jīng)常出現(xiàn)評價結果與人的主觀感覺不一致的情況。而SSIM分別從亮度、對比度和結構3方面來度量圖像相似性,SSIM值越大表示圖像相似性越高、失真越小,故本文采用PSNR和SSIM來衡量實驗結果的優(yōu)劣。
表1給出了本文的客觀指標評價結果。對比第2~4行數(shù)據(jù)可知,在重建至中間分辨率時,使用的2種重建方法的PSNR差距不大,但在SSIM上方法2優(yōu)勢明顯。通過對比第5行數(shù)據(jù)和第6行數(shù)據(jù)可知,本文采用的通過二次學習方式進行SRCNN重建方法相比STARFM所使用的簡單重采樣方法,PSNR和SSIM都高,尤其是在SSIM上提升效果顯著。通過對比最后2行數(shù)據(jù)可知,本文采用SRCNN自動提取特征進行融合的方法相比STARFM使用滑動窗口技術人工提取特征進行融合的方法,PSNR和SSIM都高,融合效果更好。通過對比客觀評價指標,表明本文改進方法提高了遙感數(shù)據(jù)時空融合的質(zhì)量。
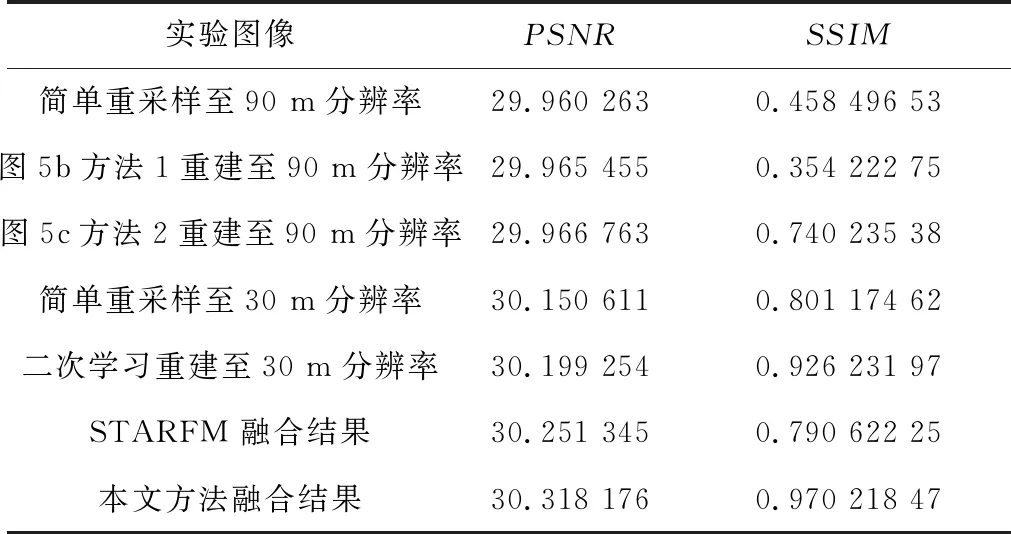
Table 1 Objective evaluation results表1 客觀指標評價結果
4 結束語
本文對傳統(tǒng)STARFM方法進行了2點改進,一方面基于學習的時空融合模型方法,對低空間分辨率數(shù)據(jù)進行超分辨率重建來代替原來的直接重采樣方法。本文為了緩解分辨率差距過大的影響,通過二次學習方式,利用SRCNN網(wǎng)絡實現(xiàn)了低空間分辨率數(shù)據(jù)的超分辨率重建,并且在重建過程中使用了不同傳感器的高分辨率數(shù)據(jù)作為先驗知識,豐富了低分辨率圖像的細節(jié)信息。另一方面,本文基于STARFM的基本思想,以SRCNN作為框架,在融合過程中采用深度學習自動提取特征,相比原來利用滑動窗口手工提取特征的方法,明顯改善了融合質(zhì)量。
本文提出的基于深度學習和超分辨率重建的時空融合方法,雖然取得了良好的融合結果,但算法時間復雜度較高。在進行超分辨率重建時,本文選取了網(wǎng)絡設計相對簡單的SRCNN,避免了其它更為復雜的網(wǎng)絡,在保證重建質(zhì)量的前提下不再提升復雜度。本文下一步將深入研究SRCNN的并行化方法,嘗試將2次超分辨率重建過程融入到深度學習中,并完善端到端的訓練網(wǎng)絡,以降低本文方法的時間復雜度。
本文在進行具體的時空融合時使用了神經(jīng)網(wǎng)絡自動提取特征,學習從預測理論值到對應標簽間的映射關系,前期雖然需要付出較多的時間成本進行學習,但在學習到映射關系后即可快速得到需要進行融合預測的圖像。相對而言,傳統(tǒng)STARFM方法雖然不需要前期學習的時間成本,但每次進行融合預測時都需要復雜度較高的大量計算,理論上,如若需要融合預測大量的數(shù)據(jù),本文方法在時間復雜度上相對而言具有優(yōu)勢。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
今日農(nóng)業(yè)(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數(shù)理化(高中版.高考數(shù)學)(2021年1期)2021-03-19 08:28:38
現(xiàn)代出版(2020年3期)2020-06-20 07:10:34
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
